RAWIC 深度解读
Raw 图像是相机传感器直接捕获的未经处理的线性测量值。与经过 ISP(Image Signal Processing)管线渲染的 sRGB 图像不同,raw 数据保留了与场景辐照度的线性关系、高位深信息(通常 10-14 bit)以及传感器特有的噪声特性。这些特性使其成为图像去噪 #Zhang et al., 2021、超分辨率 #Xu et al., 2019、低光增强 #Huang et al., 2022 等底层视觉任务不可或缺的数据源。
然而,raw 图像的存储和传输面临严峻挑战。以一张 Canon 600D 拍摄的 raw 图像为例,其分辨率为 $3464 \times 5202$,位深 14 bit,单张文件大小约 36 MB。相比之下,同一场景的 JPEG 图像仅约 3-5 MB。更大的问题在于异构性:不同相机传感器的位深不同(12 bit 或 14 bit),甚至同一张 raw 图像内不同区域的像素值范围也差异巨大——暗区可能只用到 8 bit,而亮区占满 14 bit。
现有的学习型无损压缩方法几乎全部针对 8-bit sRGB 图像设计。当它们试图处理 raw 数据时,要么需要 MSB/LSB 字节拆分这种工程 trick,要么根本不适用。另一条技术路线——raw 图像重建 #Punnappurath & Brown, 2021 #Nam et al., 2022 #Wang et al., 2023——则从 sRGB 图像反向恢复 raw 数据,但这条路线本质上是有损的,会破坏 raw 数据赖以存在的线性辐射关系。
理解 RAWIC 的创新之前,我们需要先看清它要解决的真正难题:可变位深。
传统有损压缩(如 JPEG、JPEG2000)和传统无损压缩(如 PNG、FLIF)都假设输入图像的位深是固定的。对于 8-bit sRGB 图像,每个通道 256 个离散值,概率模型可以在这 256 个值上完整定义。但 raw 图像打破了这一假设。
同一张图内的位深差异
论文 Figure 2 给出了一个直观的可视化:对一张 raw 图像逐像素计算 $\lceil \log_2(\text{value}+1) \rceil$,得到一张"位深地图"。暗区(如阴影、天空)的有效位深可能只有 8-10 bit,而亮区(如直射光源)占满 14 bit。如果对整张图像统一使用 14 bit 建模,概率质量会大量浪费在暗区根本不会出现的值域上。

跨相机的位深差异
不同相机传感器的 ADC(模数转换器)精度不同。在论文使用的 NUS 数据集中,Canon 1Ds MkIII 和 Canon 600D 的 raw 数据为 14 bit,而 Olympus EPL6、Panasonic GX1 和 Samsung NX2000 则为 12 bit。如果为每种位深训练一个独立模型,不仅增加维护成本,还丧失了跨相机数据共享的潜力。
论文 Figure 1 直观对比了传统方法与 RAWIC 的区别:传统方法为每个位深训练独立模型,而 RAWIC 用单一模型适配所有位深。
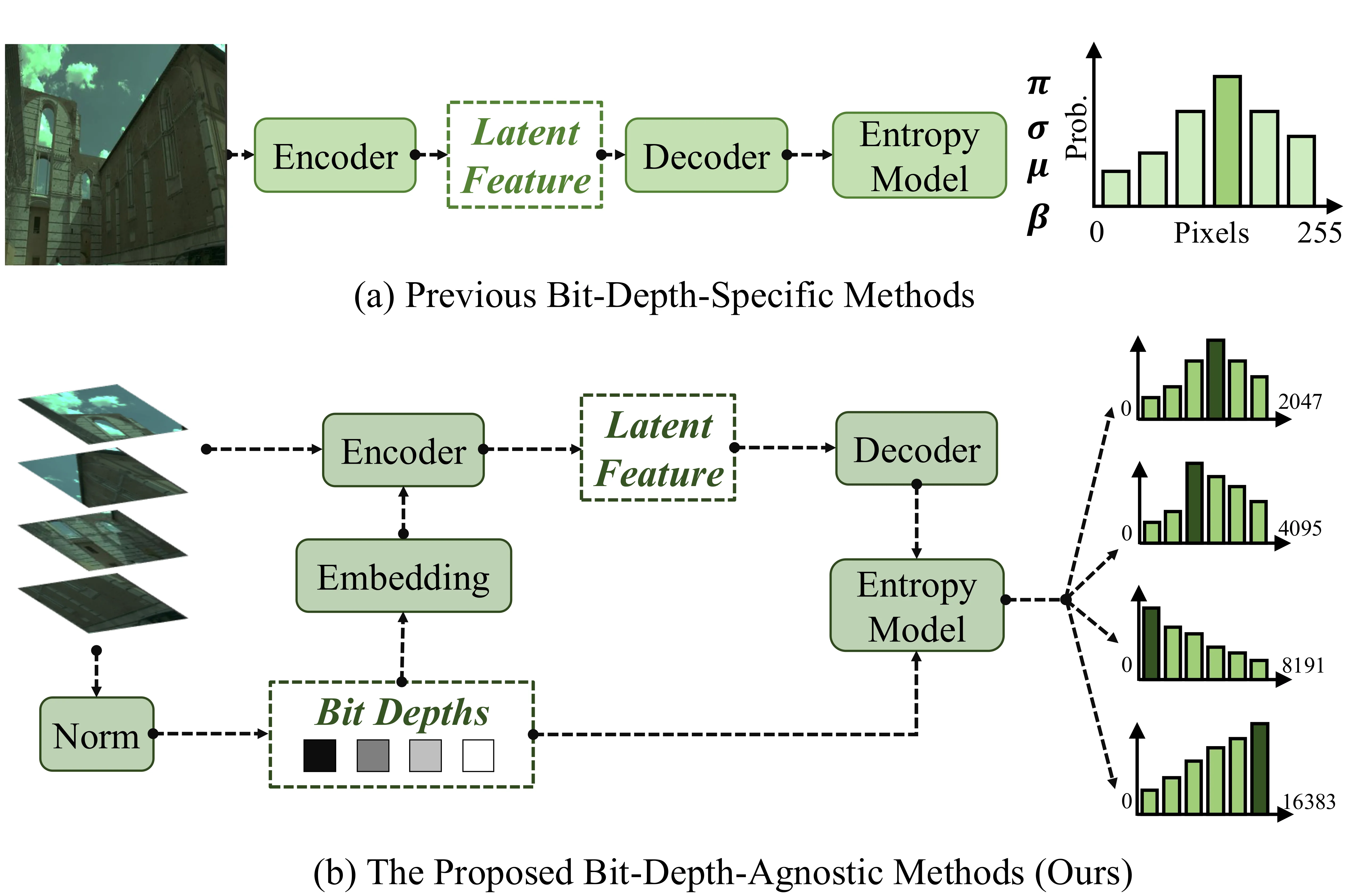
RAWIC 的核心思想可以用一句话概括:将位深作为条件信号注入熵模型,使单一网络能够适配任意位深的 raw 数据。下面我们从输入到输出逐模块展开。
Bayer 转 RGGB 四通道
Raw 图像以 Bayer pattern 排列——单通道传感器数据中,像素按 R-G-G-B 的马赛克排列。传统做法是先做 demosaicing 插值为三通道 RGB,但这会引入非线性失真,破坏 raw 数据的无损性。
RAWIC 采用了一种更优雅的转换:将单通道 Bayer 数据直接重排为 RGGB 四通道格式。具体来说,将相邻 $2 \times 2$ 像素块中的 R、G1、G2、B 分别提取为独立通道,空间分辨率减半,通道数变为 4。这样做的好处是既保留了原始传感器测量值(没有任何插值),又使标准卷积网络能够直接处理。
这是首个直接压缩单通道 Bayer pattern raw 图像的学习型无损框架 #Zheng et al., 2026。
Patch 分割与位深计算
RGGB 四通道图像被分割为 $N$ 个不重叠的 patch $\{\boldsymbol{x}_i\}_{i=1}^N$。对每个 patch,计算其位深 $\boldsymbol{b}_i = \lceil \log_2(\max(\boldsymbol{x}_i)+1) \rceil$,即该 patch 内最大像素值所需的比特数。位深通过 embedding layers 映射为稠密向量 $\boldsymbol{e}_i$,作为条件信号注入后续的压缩网络。
ELIC Backbone + Hyper-prior
RAWIC 的主干架构基于 ELIC #He et al., 2022(Efficient Learned Image Compression),结合 Ballé 等人的变分超先验框架 #Ballé et al., 2018。编码流程如下:
1. Analysis transform(编码器):$\boldsymbol{y}_i = g_a(\boldsymbol{x}_i, \boldsymbol{e}_i)$,以位深 embedding 为条件将输入 patch 变换为 latent representation
2. 量化:推理时使用 round 操作;训练时用均匀噪声 $\mathcal{U}(-\frac{1}{2}, \frac{1}{2})$ 模拟,使梯度可反向传播
3. Hyper analysis:$\boldsymbol{z}_i = h_a(\boldsymbol{\hat{y}}_i)$,提取 side information
4. Hyper synthesis:$\boldsymbol{\mu}_i, \boldsymbol{\sigma}_i = h_s(\boldsymbol{\hat{z}}_i)$,预测 latent 的高斯分布参数
5. Synthesis transform:$\boldsymbol{f}_i = g_s(\boldsymbol{\hat{y}}_i)$,生成 prior features
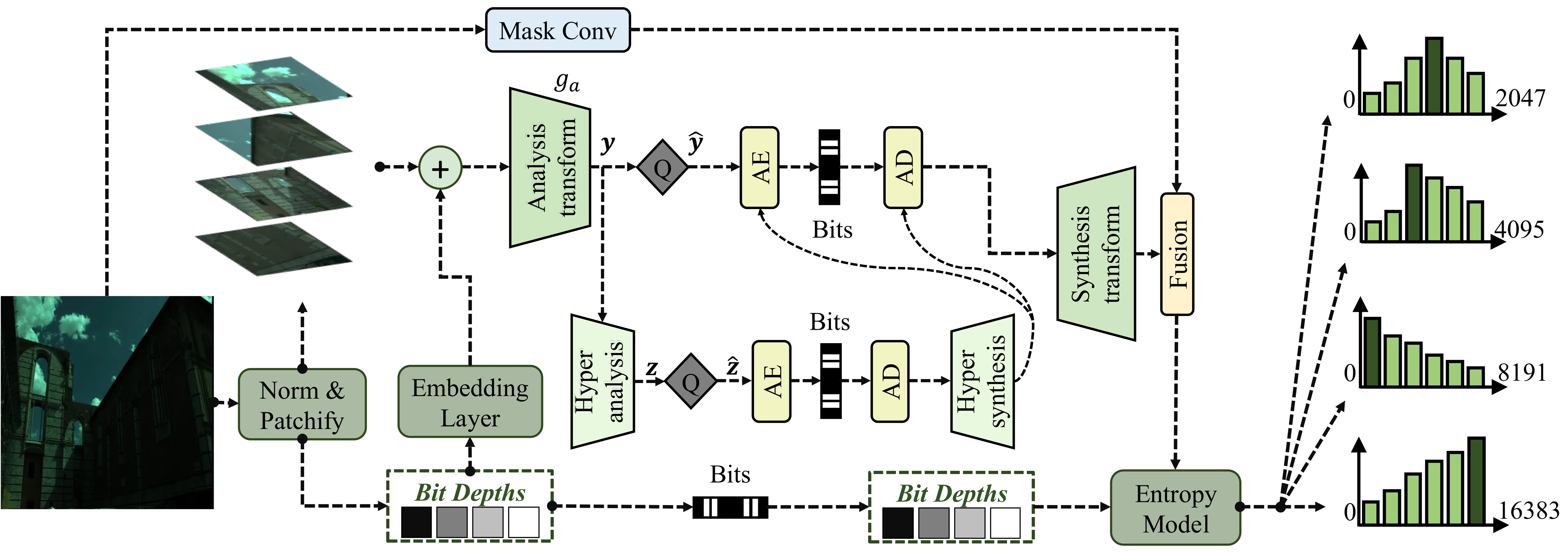
位深自适应熵模型(核心创新)
这是 RAWIC 最关键的创新。传统熵模型对像素值定义一个固定的概率质量函数(PMF),比如在 $[0, 2^{14}-1]$ 上建模。但如果一个 patch 实际只用到 10 bit,那么 $[1024, 16383]$ 区间内的概率质量完全是浪费。
RAWIC 的解决方案是位深自适应 PMF:给定基础 PMF $p(\boldsymbol{x}_{ij}^c)$ 和 patch 的位深 $\boldsymbol{b}_{ij}^c$,通过 indicator masking 和 renormalization 将概率截断到有效范围:
其中 $\mathbb{I}(\cdot)$ 是 indicator function,将无效区间的概率置零;分母重新归一化确保概率和为 1。这个公式看似简单,但它是实现"单一模型适配多位深"的数学核心。
RGGB 离散 Logistic 混合似然
为了精确建模 raw 像素的离散分布,RAWIC 将 PixelCNN++ #Salimans et al., 2017 的离散 logistic 混合(Discrete Logistic Mixture, DLM)从 RGB 3 通道扩展到 RGGB 4 通道。每个通道的像素值 PMF 为 $K$ 个 logistic 分量的混合:
其中 $\sigma(\cdot)$ 是 sigmoid 函数,$\boldsymbol{\mu}_{ij}^{ck}$、$\boldsymbol{s}_{ij}^{ck}$、$\boldsymbol{\pi}_{ij}^{ck}$ 分别是第 $k$ 个分量的均值、尺度和权重。关键设计是量化 bin 宽度 $\boldsymbol{\Delta}_{ij}^c = 1/(2^{\boldsymbol{b}_{ij}^c} - 1)$ 随位深自适应变化——位深越高,bin 越窄,概率估计越精细。
通道自回归建模
在同一空间位置内,四个通道按 R → G1 → G2 → B 的顺序进行自回归分解:
通道间的依赖通过均值的线性调整实现——后续通道的均值会注入已解码通道的像素值,由可学习系数 $\boldsymbol{\beta}$ 控制权重。注意 B 通道同时依赖 R 和 G1+G2 的平均值,这反映了 Bayer pattern 中蓝色像素被绿色像素对角环绕的空间结构。
训练目标
无损压缩的损失函数极其简洁——没有失真项,只最小化总码率:
其中 $\mathcal{R}_{\text{latent}}$ 是 latent representation 和 hyper latent 的码率开销,$\mathcal{R}_{\text{pixel}}$ 是像素数据的码率。两者都由熵模型估计的负对数似然给出。
训练数据与配置
| 配置项 | 值 | 状态 |
|---|---|---|
| 训练数据集 | NUS 5 相机 + RAISE 5% 采样 | 论文披露 |
| 训练图像数 | 1088 张 | 论文披露 |
| 划分比例 | 80% train / 10% val / 10% test(per camera) | 论文披露 |
| 初始 patch size | 128 × 128 | 论文披露 |
| 最终 patch size | 64 × 64(随机裁剪) | 论文披露 |
| 数据增强 | 水平/垂直翻转 p=0.5 | 论文披露 |
| 训练轮数 | 200 epochs | 论文披露 |
| 优化器 | Adam(β₁=0.9, β₂=0.999 推测默认值) | 论文部分披露 |
| Batch size | 128 | 论文披露 |
| 初始学习率 | 1 × 10⁻⁴ | 论文披露 |
| 学习率调度 | ReduceLROnPlateau, patience=10, factor=0.1 | 论文披露 |
| 训练硬件 | NVIDIA A100(数量未明确) | 论文部分披露 |
| 实现框架 | CompressAI (PyTorch) | 论文披露 |
| DLM 分量数 K | 未披露 | 未披露 |
| 模型参数量 | 未披露 | 未披露 |
表 1:训练配置披露表。逐项标注论文披露状态。
训练技巧
编码端
flowchart TD
A["Raw Bayer 图像"] --> B["Bayer → RGGB\n四通道转换"]
B --> C["分割为 N 个\n不重叠 patch"]
C --> D["计算每个 patch\n的位深 bᵢ"]
D --> E["位深 Embedding\neᵢ = embed(bᵢ)"]
E --> F["Analysis Transform\nyᵢ = gₐ(xᵢ, eᵢ)"]
F --> G["量化\nŷᵢ = round(yᵢ)"]
G --> H["Hyper Analysis\nzᵢ = hₐ(ŷᵢ)"]
H --> I["算术编码\n输出比特流"]
I --> J["压缩文件"]解码端
解码是编码的精确逆过程。首先从比特流中解码 hyper latent $\boldsymbol{\hat{z}}_i$,通过 hyper synthesis 恢复 latent 分布参数;然后逐 patch 解码 $\boldsymbol{\hat{y}}_i$ 和像素数据。像素解码按 RGGB 四通道自回归顺序进行:R → G1 → G2 → B。最后将所有 patch 拼回 RGGB 四通道图像,再重排为单通道 Bayer pattern。
位深信息的存储
每个 patch 的位深 $\boldsymbol{b}_i$ 本身也需要编码到比特流中。论文在 Table I 的注释中明确指出:"our method includes the bitrates for storing bit depths"。由于位深只有有限的几种取值(10-14 bit),其编码开销极小。
计算代价
实验设置
| 维度 | 详情 | 披露状态 |
|---|---|---|
| 测试数据集 | NUS 5 相机测试集 + RAISE | 论文披露 |
| 评估指标 | bits per pixel (bpp) | 论文披露 |
| 传统 baseline | QOI, PNG, WebP, FLIF, JPEG2000, JPEG-LS, JPEG-XL(共 7 个) | 论文披露 |
| 学习型 baseline | L3C, RC, SReC, iVPF, iFlow, Near-Lossless, ArIB-BPS, DLPR(共 8 个,sRGB 实验) | 论文披露 |
| 推理硬件 | NVIDIA A100 | 论文披露 |
表 2:实验配置总表。
主实验:Raw 图像无损压缩
| Codec | Canon 1Ds MkIII (14-bit) | Canon 600D (14-bit) | Olympus EPL6 (12-bit) | Panasonic GX1 (12-bit) | Samsung NX2000 (12-bit) | RAISE (14-bit) |
|---|---|---|---|---|---|---|
| QOI | 11.36 | 12.09 | 10.22 | 10.97 | 10.73 | 12.86 |
| PNG | 10.28 | 10.96 | 8.13 | 9.45 | 9.16 | 11.37 |
| WebP | 7.80 | 8.44 | 5.88 | 7.07 | 6.66 | 8.82 |
| FLIF | 7.82 | 8.34 | 6.12 | 7.02 | 6.86 | 8.86 |
| JPEG2000 | 7.34 | 8.04 | 5.70 | 6.67 | 6.58 | 8.58 |
| JPEG-LS | 7.25 | 7.87 | 5.67 | 6.54 | 6.49 | 8.38 |
| JPEG-XL | 7.29 | 7.95 | 5.60 | 6.57 | 6.46 | 8.29 |
| RAWIC | 6.79 | 7.47 | 5.11 | 5.99 | 5.83 | 7.80 |
表 3:Raw 图像无损压缩性能对比(bpp,越低越好)。RAWIC 在全部 6 个数据集上一致最优。
sRGB 扩展实验
RAWIC 的框架不仅限于 raw 图像。将模型在 DIV2K 数据集上重新训练后,也可以用于 8-bit sRGB 图像压缩。在 DIV2K、CLIC、Kodak 三个测试集上,RAWIC 分别达到 7.54、6.42、8.47 bpp,均优于 L3C #Mentzer et al., 2019、SReC #Cao et al., 2020、iFlow #Zhang et al., 2021、DLPR #Bai et al., 2024 等方法,但优势幅度较小(与 DLPR 差距仅 0.9-1.5%)。
消融实验
| 数据集 | Bit-Depth Adaptive | Fixed Bit Depth | 差距 |
|---|---|---|---|
| Canon 1Ds MkIII (14-bit) | 6.79 | 8.78 | +29.3% |
| Canon 600D (14-bit) | 7.47 | 8.77 | +17.4% |
| Olympus EPL6 (12-bit) | 5.11 | 8.98 | +75.7% |
| Panasonic GX1 (12-bit) | 5.99 | 9.20 | +53.6% |
| Samsung NX2000 (12-bit) | 5.83 | 9.37 | +60.7% |
| RAISE (14-bit) | 7.80 | 9.29 | +19.1% |
表 4:位深自适应消融。Fixed bit depth 对所有 patch 使用同一个位深(推测为 14 bit)。百分比表示 fixed 相对于 adaptive 的码率增加。
All-in-One vs Camera-Specific
另一个反直觉的发现:跨相机联合训练的 all-in-one 模型在大多数数据集上优于为每个相机单独训练的 camera-specific 模型。Canon 1Ds MkIII 上降低 16.5%(7.91→6.79),Olympus EPL6 上降低 32.9%(6.79→5.11)。仅在 Samsung NX2000 上两者持平(5.83 vs 5.82),RAISE 上两者几乎持平(all-in-one 7.79 vs camera-specific 7.80,差距仅 0.1%)。这说明跨相机的知识共享确实提升了压缩性能。
RUNTIME 对比:压缩率的代价
| Codec | Canon 600D 编码 | Canon 600D 解码 | Olympus EPL6 编码 | Olympus EPL6 解码 |
|---|---|---|---|---|
| PNG | 4.55s | 0.59s | 4.56s | 0.46s |
| JPEG-XL | 6.08s | 1.38s | 6.62s | 1.46s |
| FLIF | 25.97s | 9.36s | 20.41s | 9.36s |
| RAWIC | 45.7s | 119.3s | 37.1s | 98.4s |
表 5:Raw 图像编解码时间对比(秒)。RAWIC 编码慢 7-8x、解码慢 67-86x(vs JPEG-XL)。
核心局限
1. 速度瓶颈:解码 119s/image(Canon 600D)使其完全不适合实时场景。作者明确承认这一局限,并将加速列为未来工作方向。
2. 仅测试 RGGB pattern:其他 Bayer 排列(BGGR、GRBG、GBRG)未验证。
3. 位深范围有限:训练和测试数据仅覆盖 12-14 bit,10-bit 和 16-bit 未涉及。
4. 泛化性待验证:仅 5 台 NUS 相机 + RAISE 数据集,工业级应用(如自动驾驶、卫星遥感)的 raw 数据分布可能显著不同。
可操作的启发
RAWIC 的核心贡献不只是压缩率数字,更在于一个方法论层面的洞察:当数据的统计特性具有已知的结构化变化(如可变位深)时,将这个变化作为显式条件注入熵模型,比让网络自己去"发现"这个变化更有效。
这个思路可以迁移到其他场景:
- 医学图像:不同设备(CT、MRI)的动态范围不同,可用类似方式条件化
- 科学成像:天文望远镜、电子显微镜的数据位深和噪声模型各异
- 视频压缩:帧间 bit depth 或动态范围变化(如 HDR 内容)
参考来源
- Zheng, C. et al. (2026). RAWIC: Bit-Depth Adaptive Lossless Raw Image Compression. ICME 2026. arXiv:2603.28105
- He, D. et al. (2022). ELIC: Efficient Learned Image Compression with Unevenly Grouped Space-Channel Contextual Adaptive Coding. CVPR 2022. CVPR
- Ballé, J. et al. (2018). Variational Image Compression with a Scale Hyperprior. ICLR 2018. arXiv:1802.01436
- Salimans, T. et al. (2017). PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications. ICLR 2017. arXiv:1701.05517
- Alakuijala, J. et al. (2019). JPEG XL Next-Generation Image Compression Architecture and Coding Tools. SPIE 2019. JPEG XL
- Bai, Y. et al. (2024). Deep Lossy Plus Residual Coding for Lossless and Near-Lossless Image Compression. IEEE TPAMI. DOI
- Mentzer, F. et al. (2019). Practical Full Resolution Learned Lossless Image Compression. CVPR 2019. arXiv:1811.06387
- Cao, S. et al. (2020). Lossless Image Compression through Super-Resolution. arXiv. arXiv:2004.02872
- Zhang, S. et al. (2021). iFlow: Numerically Invertible Flows for Efficient Lossless Compression via a Uniform Coder. NeurIPS 2021. arXiv:2103.01451
- Zhang, Y. et al. (2021). Rethinking Noise Synthesis and Modeling in Raw Denoising. ICCV 2021. arXiv:2107.13686
- Xu, X. et al. (2019). Towards Real Scene Super-Resolution with Raw Images. CVPR 2019. arXiv:1905.12156
- Huang, H. et al. (2022). Towards Low Light Enhancement with Raw Images. IEEE TIP. DOI
- Punnappurath, A. & Brown, M.S. (2021). Spatially Aware Metadata for Raw Reconstruction. WACV 2021. arXiv:2011.06994
- Nam, S. et al. (2022). Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata. CVPR 2022. arXiv:2203.08617
- Wang, Y. et al. (2023). Raw Image Reconstruction with Learned Compact Metadata. CVPR 2023. arXiv:2303.01923