Live Avatar 精读
音频驱动的数字人生成——给一张人像照片和一段语音,合成会说话的逼真视频——在离线场景已经做得足够漂亮。但一旦要求它边听边生成、长对话不崩,就暴露出两个根本矛盾。#Huang et al., 2025
第一个矛盾是实时与质量的对立。大模型(如 Wan-S2V 14B)画质好但天然慢——扩散模型的多次去噪是串行过程,单卡跑不到 5 FPS;想做到实时,要么把模型缩到很小(Ditto 仅 0.2B,21.8 FPS),要么大幅牺牲画质。#Gao et al., 2025 #Li et al., 2024
第二个矛盾是长时一致性的崩塌。自回归生成越长,误差越累积——几分钟就会出现身份漂移、色差和视觉崩坏。Self-Forcing 修复了训练-推理的分布偏移,但推到分钟级仍然快速退化;LongLive 做了原生长视频训练,但仅适用于文本驱动且训练成本极高,无法扩展到 14B 量级。#Huang et al., 2025 #Yang et al., 2025
Live Avatar 正是这样一个算法-系统协同设计的框架:它把 14B 双向扩散模型蒸馏成因果、4 步的流式模型,用三个互补策略消灭长时漂移,再通过 Timestep-forcing Pipeline Parallelism 把串行去噪变成异步流水线,最终在 5 张 H800 上实现 45 FPS 实时推理、10,000+ 秒稳定推演。#Huang et al., 2025
论文链接:Live Avatar
长时生成的三重崩塌
Live Avatar 的作者明确归因了长时自回归生成失败的三个内部现象:#Huang et al., 2025
长时漂移三因子
- (i) 条件漂移(conditioning drift):推理时 sink 帧与当前块之间的 RoPE 相对位置持续增长,远超训练所见范围 → 注意力对 sink 帧的权重衰减 → 身份线索失效。
- (ii) 分布漂移(distribution drift):用户提供的真实参考帧与模型生成帧处于不同分布 → 持续偏差推动后续生成偏离真实视频分布 → 色差、曝光、风格畸变累积。
- (iii) 误差累积(error accumulation):clean KV cache 逐帧继承前序块的所有细节——包括瑕疵 → 误差像滚雪球一样指数级放大 → 快速质量崩塌。
一个关键实验:OmniAvatar 从短视频的 ASE 3.53 / IQA 4.49 降到长视频的 ASE 2.36 / IQA 2.86,Dino-S 从 0.95 跌到 0.66——这就是长时崩塌的典型数据。而 Live Avatar 在长视频上几乎不掉点(ASE 3.44→3.42,Dino-S 0.96→0.97),差异一目了然。#Gan et al., 2025
实时推理的瓶颈在哪
即便做了 DMD 蒸馏把 80 步降到 5 步,14B 模型单卡仍然只有 3.66 FPS;加 4 卡序列并行也只有 4.50 FPS。这是因为每个 block 只有 3 个 latent 帧,注意力计算不是主要瓶颈——瓶颈在串行去噪步骤本身。5 步去噪意味着 5 次前向传播串行叠加,这才是延迟的来源。#Huang et al., 2025
Live Avatar 的方法可以拆成三个层次:训练框架(如何把双向教师变成流式学生)、长时策略(如何抑制漂移让推演超过 10,000 秒)、推理并行(如何把串行去噪变成流水线)。
两阶段训练框架
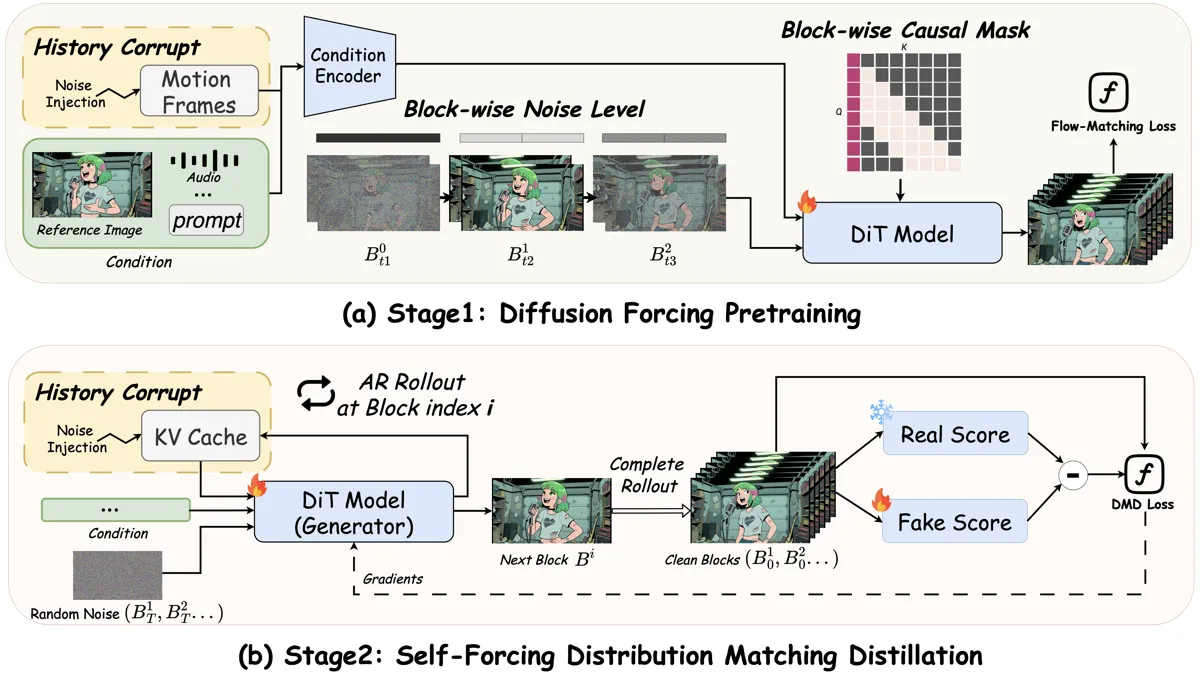
为什么这样做?因为加噪 motion frame 和 Stage 2 的加噪 KV cache 功能类比——都是为续写生成提供带噪的历史上下文。这意味着 Stage 1 就在低成本地学习"动态-身份解耦",不需要昂贵的 self-forcing rollout。Stage 2 把 motion frame 替换为 KV cache 时,模型已经学会了相似的条件模式,从而获得 5× 收敛加速。#Huang et al., 2025
Stage 2:Self-Forcing DMD 蒸馏。把双向教师蒸馏成因果、4 步的流式学生。关键修改是History Corrupt:去掉 Self-Forcing 原本的 clean-cache refresh 前向传播,让 KV cache 始终保持加噪状态。#Huang et al., 2025核心自回归方程
其中 \(B\) 是 block(3 个 latent 帧),\(w=4\) 是 KV cache 窗口大小,\(I\) 是 sink 帧,\(a^i\) 是音频嵌入,\(t^i\) 是 prompt 嵌入。注意 KV cache 与当前 noisy block 共享相同噪声水平——这是 timestep-forcing 的核心设计。
策略一:History Corrupt——加噪缓存实现动态-身份解耦
数字人场景有个天然先验:主体和背景几乎不变。这意味着 sink 帧可以为每一帧提供足够的身份和外观信息,而 KV cache 的角色缩减为只传递运动动态。#Huang et al., 2025
History Corrupt 的核心操作极为简洁:只存储加噪表示在 KV cache 中。直觉上,高斯噪声充当低通滤波器——抑制高频细节(包括累积的瑕疵),保留低频运动结构。这迫使模型从加噪历史提取动态线索,从 clean sink 帧获取身份和外观,实现有效的动态-身份解耦。#Song et al., 2025
更深层的意义:加噪 KV cache 还抑制了分布漂移。在更高噪声水平上,边际分布 \(p_t(\mathbf{x}_t)\) 向 Gaussian 先验收敛,占据 latent space 更紧凑的区域——加噪 cache 远比 clean cache 更不容易漂入 OOD 区域。#Song et al., 2019
消融数据说话:去掉 History Corrupt,ASE 从 3.42 降到 2.90,Dino-S 从 0.97 降到 0.81——这是三个策略中影响最严重的一个。#Huang et al., 2025
策略二:Adaptive Attention Sink(AAS)——用模型自己的生成帧替换参考帧
用户提供的真实参考帧和模型生成帧之间存在微妙的分布差异——这个持续偏差在长推演中累积为色差和曝光偏移。AAS 的做法是:第一个 block 生成完毕后,立刻用模型自己的生成 latent 替换 sink 帧,并作为后续所有 block 的持久身份锚点。#Huang et al., 2025
关键工程细节:替换完全在 latent space 完成,不需要额外的 VAE 编码/解码。这让 sink 帧始终停留在模型的生成分布上,消除了真实数据和生成数据之间的分布鸿沟。
消融数据:去掉 AAS,ASE 从 3.42 降到 3.13,出现明显的灰化/去饱和现象。#Huang et al., 2025
策略三:Rolling RoPE——动态位置对齐防止注意力衰减
标准 AR 推理中,sink 帧的 RoPE 位置固定在 0,而当前 block 的位置单调增长(1, 2, 3, ...)。随着生成推进,两者之间的相对位置距离变得任意大——远超训练所见——导致注意力对 sink 帧的权重退化。#Huang et al., 2025
Rolling RoPE 的做法:在每个 block 步动态重设 sink 帧的 RoPE index,让它保持略超前于当前 noisy block 的 index(落在训练时的偏移范围内)。这通过重新计算 sink 缓存的 KV 条目的 RoPE 嵌入来实现,标记为 \(\Phi(\mathbf{Sink})\)。
消融数据:去掉 Rolling RoPE,Dino-S 从 0.97 骤降到 0.86,出现可见的头发细节和面部特征变化。#Huang et al., 2025

Timestep-forcing Pipeline Parallelism(TPP)
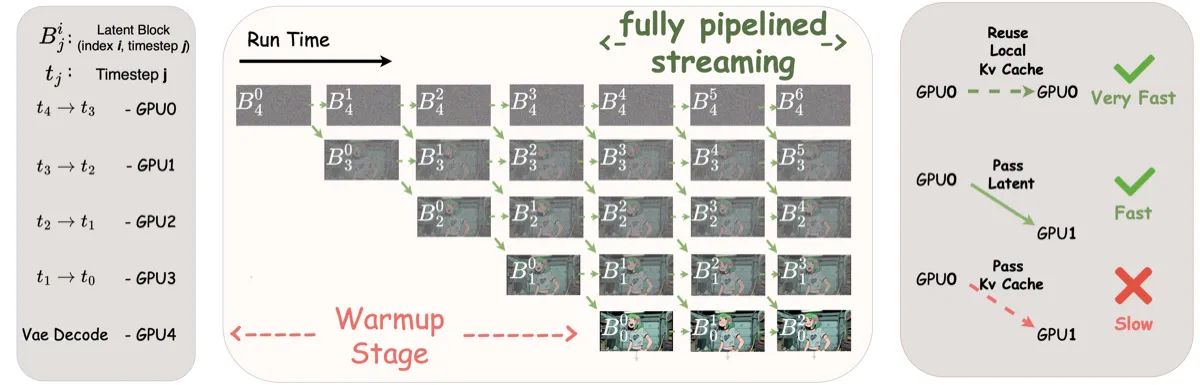
TPP 的核心思想极为优雅:给每个 GPU 分配一个固定的去噪时间步。4 步去噪需要 4 个 GPU(加 1 个做 VAE 解码),每张 GPU 反复执行 \(t_i \rightarrow t_{i-1}\) 的变换。#Huang et al., 2025
这把串行扩散链变成了异步空间流水线:吞吐量由单个去噪前向传播决定,而非所有步骤之和。理想加速等于去噪步数——4 步就是 4× 加速。warm-up 期间第一个 block 串行流过所有步骤填充流水线,之后进入全流水线阶段:每张 GPU 同时处理不同 block 的不同步骤。
两个关键工程优势:
1. 每张 GPU 维护本地 rolling KV cache,不需要跨 GPU 通信——timestep-forcing 的"相同噪声水平"约束天然对应到"相同 GPU";
2. GPU 间只传递 compact latent,通信开销可忽略。
flowchart LR GPU0["GPU0
t₃→t₂"] -->|latent| GPU1["GPU1
t₂→t₁"] GPU1 -->|latent| GPU2["GPU2
t₁→t₀"] GPU2 -->|latent| GPU3["GPU3
VAE解码"] GPU0 -.->|本地KV| KV0["KV₀"] GPU1 -.->|本地KV| KV1["KV₁"] GPU2 -.->|本地KV| KV2["KV₂"]
图 4:TPP 流水线示意。各 GPU 独立维护本地 KV cache,只需传递 latent 到下游设备。warm-up 后所有 GPU 同时工作,吞吐量由单步延迟决定。
训练数据与规模
训练数据来自 AVSpeech(大规模音视频数据集),沿用 OmniAvatar 的预处理,只保留 >10 秒的片段,最终得到 400K 训练样本。#Gan et al., 2025
| 阶段 | 初始化来源 | 步数 | GPU 数 | 学习率 | batch/GPU |
|---|---|---|---|---|---|
| Stage 1(Diffusion Forcing) | Wan-S2V 权重 | 25K | 128 H800 | student: 1e-5 | 1 |
| Stage 2(Self-Forcing DMD) | Stage 1 → student, Wan-S2V → teacher/fake score | 500 | 128 H800 | student: 1e-5, fake score: 2e-6 | 1 |
损失函数
Stage 1 使用标准 flow-matching loss:
Stage 2 使用 DMD loss,最小化学生与教师分布之间的反向 KL 散度:
其中 \(s_{\mathrm{real}}\) 来自教师模型,\(s_{\mathrm{fake},\phi}\) 是在学生输出上训练的 score 网络。两者都从 Wan-S2V 初始化。#Yin et al., 2024
关键超参数
| 参数 | 值 | 说明 |
|---|---|---|
| Block size | 3 latent 帧 | 每个 AR block 包含 3 个 latent 帧 |
| KV cache 窗口 \(w\) | 4 blocks | rolling cache 保留最近 4 个 block |
| Sink 帧 | 1 帧 | 单帧身份锚点 |
| LoRA rank / alpha | 128 / 64 | 蒸馏阶段用 LoRA 微调 |
| 分辨率 | 720×400 | 固定训练和推理分辨率 |
| 训练帧数 | 84 | 所有训练视频 clip 帧数 |
| 去噪步数 | 4 | 推理默认 4 步采样 |
算力成本
推理侧的 kernel 优化组合:FP8 量化(~80GB → <48GB VRAM)、FlashAttention-3、cuDNN fused attention、torch.compile、LoRA weight merging、streaming VAE feature caching。这些优化带来约 2.5× 峰值和 3× 平均 FPS 提升。#Huang et al., 2025
GenBench:新的长视频评测基准
论文提出了 GenBench 评测集,用 Gemini-2.5 Pro、Qwen-Image 和 CosyVoice 生成多样化的测试样本。GenBench-Short 包含 100 个约 10 秒的样本;GenBench-Long 包含 15 个超过 5 分钟的样本,涵盖真人、卡通、拟人化角色、正面/侧面、半身/全身多种视角。#Huang et al., 2025
主实验:短视频与长视频对比
| 模型 | 规模 | ASE↑ | IQA↑ | Sync-C↑ | Dino-S↑ | FPS↑ | 长视频 ASE | 长视频 Dino-S |
|---|---|---|---|---|---|---|---|---|
| Ditto | 0.2B | 3.31 | 4.24 | 4.09 | 0.99 | 21.80 | 2.90 | 0.97 |
| OmniAvatar | 14B | 3.53 | 4.49 | 6.77 | 0.95 | 0.16 | 2.36 | 0.66 |
| Wan-S2V | 14B | 3.36 | 4.29 | 5.89 | 0.95 | 0.25 | 2.63 | 0.80 |
| Live Avatar | 14B | 3.44 | 4.51 | 7.03 | 0.96 | 45.2 | 3.42 | 0.97 |
几个值得指出的数字含义:
- 45.2 FPS vs 0.16 FPS:Live Avatar 比 OmniAvatar 快 282 倍,但用的是同量级的 14B 模型。这证明蒸馏 + TPP + kernel 优化组合的威力。
- Dino-S 0.97 vs 0.66:OmniAvatar 在长视频上的身份一致性几乎崩塌;Live Avatar 短视频和长视频之间几乎不掉点。
- IQA 4.51 > 4.29:蒸馏后的学生反而超过了教师 Wan-S2V——这与 DMD 蒸馏模型的已知倾向一致:分布集中化有时带来更高的感知评分。#Luo et al., 2025
推理效率消融
| 配置 | GPU | NFE | FPS↑ | TTFF↓ |
|---|---|---|---|---|
| 基线(无 DMD) | 1 | 80 | 0.29 | 45.50 |
| +DMD | 1 | 5 | 3.66 | 4.56 |
| +SP₄ | 4 | 5 | 4.50 | 3.94 |
| +TPP | 4 | 4 | 10.16 | 4.73 |
| +VAE并行 | 5 | 4 | 20.88 | 2.89 |
| +Kernel优化 | 5 | 4 | 45.2 | 1.21 |
逐层解读:
- DMD 把 NFE 从 80 降到 5——这是最大的单步加速。
- 序列并行在短 block 上收益极小(4→4.5 FPS)——再次印证瓶颈不在注意力而在步骤维度。
- TPP 在同 GPU 数下从 4.5 提升到 10.16 FPS——步骤维度并行化才是真正的加速路径。
- Kernel 优化从 20.88 提升到 45.2 FPS——FP8 量化、FlashAttention-3 等底层优化对实际部署不可或缺。
10,000 秒超长推演
模型只在 5 秒短视频上训练,RoPE 位置只在几分钟范围内随机偏移。但推理被推到 10,000 秒——RoPE index 达到约 40,000,比训练时大了两个数量级。结果令人震撼:#Huang et al., 2025
| 时间片段 | ASE↑ | IQA↑ | Sync-C↑ | Dino-S↑ |
|---|---|---|---|---|
| 0-10 秒 | 3.41 | 4.77 | 7.10 | 0.97 |
| 100-110 秒 | 3.43 | 4.75 | 7.22 | 0.96 |
| 1000-1010 秒 | 3.40 | 4.73 | 6.98 | 0.96 |
| 10000-10010 秒 | 3.42 | 4.76 | 7.14 | 0.96 |
四个时间片段的指标几乎完全一致——没有任何可观测的质量衰减或身份不稳定。相比之下,Self-Forcing++ 的最长推演大约 4 分钟,Live Avatar 把这个数字推到了近 3 小时。
去噪步数消融
TPP 的一个重要特性:FPS 与步数无关——因为流水线填充后每步都在并行执行。只有 TTFF 随步数增长。#Huang et al., 2025
| 步数 | ASE↑ | Sync-C↑ | TTFF↓ | FPS↑ |
|---|---|---|---|---|
| 2 | 3.37 | 6.41 | 0.68 | 45.2 |
| 3 | 3.41 | 6.58 | 0.95 | 45.2 |
| 4 | 3.44 | 7.03 | 1.21 | 45.2 |
从 2 步到 4 步,画质提升有限,但音视同步显著改善(Sync-C 6.41→7.03)。4 步在运动关键去噪阶段留出了更多预算,因此默认选择 4 步。
与核心竞品的技术对比
| 维度 | Ditto | OmniAvatar | Wan-S2V | LongLive | Live Avatar |
|---|---|---|---|---|---|
| 模型规模 | 0.2B | 14B | 14B | 1.3B | 14B |
| 流式推理 | ✓ | ✗ | ✗ | ✓ | ✓ |
| 实时 | ✓(21.8 FPS) | ✗ | ✗ | ✓(低画质) | ✓(45.2 FPS) |
| 无限长 | ✗ | ✗ | ✗ | ✓ | ✓(10,000+秒) |
| 蒸馏方法 | 无(原生轻量) | 无 | 无 | DMD | DMD + Self-Forcing |
| 长时策略 | 无 | 无 | 无 | attention sink | History Corrupt + AAS + Rolling RoPE |
| 推理并行 | 单卡 | SP | SP | SP | TPP |
局限性
论文明确承认两个局限:#Huang et al., 2025
1. 静态场景先验依赖:History Corrupt、AAS 和 Rolling RoPE 都依赖数字人场景的"主体和背景基本不变"先验。一旦场景发生剧烈变化(如全身动作场景切换),这些策略可能不再适用。
2. 首帧延迟仍然偏高:TTFF 1.21 秒加上网络传输约 3 秒端到端延迟,距离双向实时交互的严苛要求仍有差距。
个人启发
- 算法-系统协同设计的范式值得复制:很多团队把模型优化和推理优化分开做,但 Live Avatar 证明二者可以互相支撑——timestep-forcing 既是算法设计(改善闪烁),也是系统设计(自然映射到 GPU 流水线)。
- "加噪作为低通滤波"是一个通用思路:History Corrupt 的噪声注入本质上是在说"历史信息不需要全精度保留"。这个思路可以迁移到其他长序列生成场景——如长文本生成中的 KV cache 压缩。
- TPP 不只适用于蒸馏模型:论文指出 TPP 是 model-agnostic 的——任何因果扩散模型都可以用。这为非蒸馏场景(如原始多步推理)也提供了加速路径,只要步数和 GPU 数匹配。
- 5×H20 的 18 FPS 说明部署门槛可以更低:不一定要顶级数据中心硬件。中端 GPU 集群也能跑出实用帧率,这对创业公司和小团队是好消息。
参考来源
- Huang, Y. et al. (2025). Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length. arXiv:2512.04677
- Gao, X. et al. (2025). Wan-S2V: Audio-Driven Cinematic Video Generation. arXiv:2508.18621
- Li, T. et al. (2024). Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis. arXiv:2411.19509
- Gan, Q. et al. (2025). OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation. arXiv:2506.18866
- Yang, S. et al. (2025). LongLive: Real-time Interactive Long Video Generation. arXiv:2509.22622
- Yin, T. et al. (2024). One-step Diffusion with Distribution Matching Distillation. arXiv:2311.18828
- Luo, Y. et al. (2025). Learning Few-Step Diffusion Models by Trajectory Distribution Matching. arXiv:2503.06674
- Song, K. et al. (2025). History-Guided Video Diffusion. arXiv:2502.06764
- Song, Y. & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. arXiv:1907.05600