Ensemble Learning
参考资料
boosting与bagging
决策树
sklearn 实现
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
可以方便地输出成可视化图像:
tree.plot_tree(clf)
如果想要将决策树用于回归问题,如下文所示,使用:
from sklearn import tree
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X, y)
clf.predict([1, 1](./1-1.html))
adaboost
可以表示为基分类器的线性组合。
第个基分类器的权重在训练中根据其错误率调整。
其权重$alpha_i=\frac 1 2 ln(\frac {1 - \epsilon_i}{\epsilon_i})$
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
wine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")
## AdaBoost
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"AdaBoost的准确率:{accuracy_score(y_test,y_pred):.3f}")
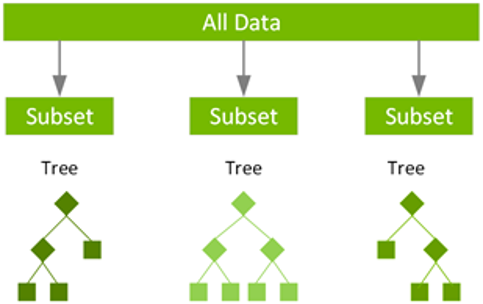
随机森林
一组决策树。
随机森林使用名为bag的技术,通过数据集和特征的随机自助抽样样本并行构建完整的决策树。虽然决策树基于一组固定的特征,而且经常过拟合,但随机性对森林的成功至关重要。
特点
- non-parametric
- supervised
优点
- il peut traiter les données avec des valeurs absentes et garder une haute précision
- difficile à être overfitting
defaute
- précision plus basse que XGBoost
- vitesse plus basse que XGBoost
参考资料
boosting与bagging
决策树
sklearn 实现
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
可以方便地输出成可视化图像:
tree.plot_tree(clf)
如果想要将决策树用于回归问题,如下文所示,使用:
from sklearn import tree
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X, y)
clf.predict([1, 1](./1-1.html))
adaboost
可以表示为基分类器的线性组合。
第个基分类器的权重在训练中根据其错误率调整。
其权重$\alpha_i=\frac 1 2 ln(\frac {1 - \epsilon_i}{\epsilon_i})$
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
wine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")
## AdaBoost
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"AdaBoost的准确率:{accuracy_score(y_test,y_pred):.3f}")
随机森林
一组决策树。
随机森林使用名为bag的技术,通过数据集和特征的随机自助抽样样本并行构建完整的决策树。虽然决策树基于一组固定的特征,而且经常过拟合,但随机性对森林的成功至关重要。
特点
- non-parametric
- supervised
优点
- il peut traiter les données avec des valeurs absentes et garder une haute précision
- difficile à être overfitting
defaute
- précision plus basse que XGBoost
- vitesse plus basse que XGBoost