Agent Attention
Transformer 进入视觉领域以后,最核心的矛盾一直没有消失:图像、视频和扩散模型里的 token 数会随分辨率迅速增长,而标准 Softmax attention 需要让每个 query 和每个 key 都做一次关系计算。这个设计表达力很强,因为每个位置都能看到全局;但在高分辨率视觉中,它也把计算和显存开销推向了 \(N^2\) 级别。Agent Attention 这篇 ECCV 2024 论文正是站在这个矛盾上:它要保留全局建模,又不想承担完整二次复杂度。#Han-et-al.-2024
已有路线各有代价。Swin Transformer 用窗口注意力把视野限制在局部,PVT 降低 key/value 分辨率,linear attention 改变计算顺序或替换 Softmax kernel。这些方法确实省算力,但常常会损失长距离关系、表达能力或通用替换性。Agent Attention 的思路更像一次“信息流重排”:不让所有 query 亲自访问所有 key/value,而是派出少量 agent tokens 作为中介。每个 agent token 先从全局收集一类语义信息,随后所有 query 再从这些 agent token 中取回自己需要的内容。#Liu-et-al.-2021 #Katharopoulos-et-al.-2020
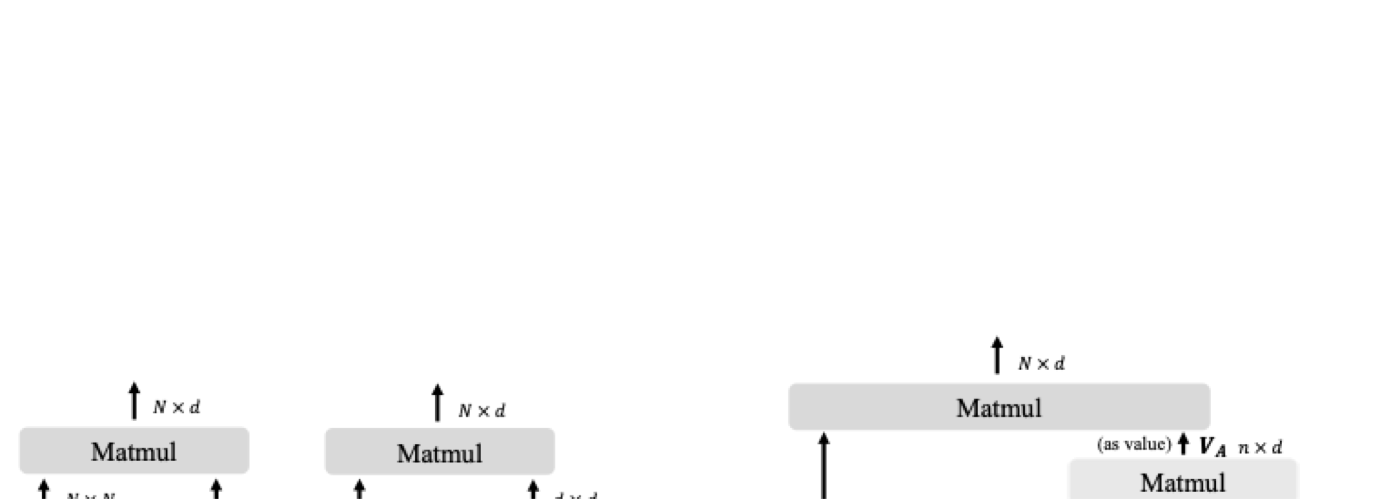
这篇论文有两个传播点。第一,它把 Agent Attention 写成了 generalized linear attention,从公式上解释为什么它既像 Softmax,又像 linear attention。第二,它把这个模块放进多种视觉模型和 Stable Diffusion 里验证:ImageNet 分类、COCO 检测、ADE20K 分割、Stable Diffusion 生成和 DreamBooth 微调都被覆盖。换句话说,作者不是只提出一个 attention trick,而是在回答一个更通用的问题:当 token 数越来越长时,视觉模型还能怎样保留全局信息?#Han-et-al.-2024
Softmax 强在全局,贵在全局
标准 self-attention 的形式非常熟悉:query 与 key 做相似度,经过 Softmax 归一化,再加权 value。它的强处恰好也是代价来源:每个 query 都和所有 key 交互,因此注意力矩阵大小是 \(N\times N\)。当 \(N\) 是文本长度时,这已经昂贵;当 \(N\) 来自高分辨率图像 patch、密集预测 feature map、扩散模型 latent token 或视频 token 时,二次复杂度会直接变成瓶颈。#Vaswani-et-al.-2017 #Han-et-al.-2024
Softmax Attention 的基本形式
这里 \(Q,K,V\in\mathbb{R}^{N\times d}\),\(\sigma(\cdot)\) 表示对注意力分数做 Softmax。完整的 \(QK^T\) 需要计算所有 token 两两关系,所以复杂度随 \(N\) 呈二次增长。
Linear Attention 快,但难在映射函数
Linear attention 的诱惑在于把计算顺序换掉。它通常用某个映射函数 \(\phi(\cdot)\) 替代 Softmax 相似度,让注意力写成 \(\phi(Q)\phi(K)^TV\)。这样可以先算 \(\phi(K)^TV\),再乘 \(\phi(Q)\),避免显式构造 \(N\times N\) 的注意力矩阵。问题是:映射函数一旦设计得太简单,模型表达能力就会明显下降;设计得太复杂,又可能把省下来的开销重新花回去。#Katharopoulos-et-al.-2020 #Choromanski-et-al.-2021
| 路线 | 核心做法 | 优点 | 主要代价 |
|---|---|---|---|
| Softmax attention | 所有 query-key pair 全交互 | 表达力强,全局上下文完整 | \(O(N^2)\) 计算与显存 |
| Window / sparse attention | 限制窗口或稀疏采样 | 工程成熟,计算可控 | 全局关系被削弱,依赖特定 pattern |
| Linear attention | 用 \(\phi(Q)\phi(K)^T\) 重排计算 | 关于 token 数近似线性 | 映射函数难设计,常有精度损失 |
| Agent Attention | 用 agent tokens 做聚合与广播 | 保留两段 Softmax,同时近似线性 | agent bottleneck 需要 Bias 与 DWC 补强 |
论文的关键洞察:attention weights 有冗余
Agent Attention 的起点不是“强行近似 Softmax”,而是一个观察:不同 query 的注意力权重并非完全独立,很多 query 会需要相似的全局语义信息。既然如此,就不必让每个 query 都亲自和所有 key 交互。可以先用少量 agent tokens 汇总若干类全局信息,再让 query 从这些汇总后的表示中读取。这个思路把二次交互拆成两个矩阵:\(Q\) 到 \(A\) 的 \(N\times n\),以及 \(A\) 到 \(K\) 的 \(n\times N\)。当 \(n\ll N\) 时,计算量就从 \(N^2\) 降到了 \(Nn\)。#Han-et-al.-2024

从四元组 \((Q,A,K,V)\) 开始
论文把 Agent Attention 记为四元组 \((Q,A,K,V)\)。这里 \(Q,K,V\) 仍来自普通 attention 的线性投影;新增的是 \(A\),也就是 agent tokens。\(A\) 的数量记为 \(n\),通常显著小于原始 token 数 \(N\)。默认实现里,作者用 pooling 从 \(Q\) 中得到 agent tokens;论文也讨论了 learnable parameters、convolution、deformed points 和 token merging 等来源。#Han-et-al.-2024
整个模块分成两步。第一步是 agent aggregation:agent tokens 作为 query,从全局 \(K,V\) 聚合信息。第二步是 agent broadcast:原始 query 从 agent tokens 汇总后的信息中读取内容。这个结构有一个非常直观的类比:如果原来是每个员工都去问全公司所有人,现在是先让少数项目经理汇总全公司信息,再把结果分发给每个员工。
Agent Attention 的核心公式
其中 \(\sigma(AK^T)V\) 是 agent aggregation,得到 agent features;\(\sigma(QA^T)\) 是 agent broadcast,把 agent features 分发给每个 query。两个阶段都使用 Softmax,因此权重仍有归一化选择性。
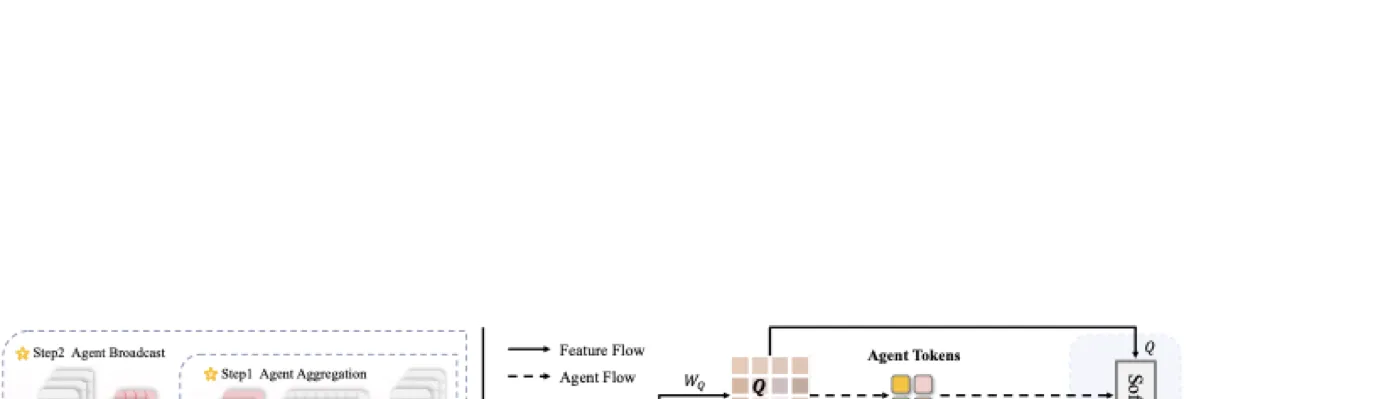
为什么它又是 generalized linear attention
这篇论文的一个关键贡献是,它没有只用图示解释“代理人”直觉,还给了一个形式上的桥接。令:
那么 Agent Attention 可以写成:
这正是 generalized linear attention 的形式。不同之处在于,传统 linear attention 往往需要手工设计 \(\phi\) 的具体函数,而 Agent Attention 的 \(\phi_q\) 与 \(\phi_k\) 是由 agent tokens 和两段 Softmax 自然产生的。也就是说,它的计算形式像 linear attention,但权重生成仍保留 Softmax 的归一化机制。#Han-et-al.-2024
完整模块:Agent Bias 与 DWC 为什么必要
如果只看 \(\sigma(QA^T)\sigma(AK^T)V\),它已经完成了信息重排;但视觉任务还需要位置结构和局部细节。作者因此加入了 Agent Bias 与 DWC。Agent Bias 分别加到 aggregation 和 broadcast 两段注意力中,让不同 agent tokens 更稳定地服务不同空间区域。DWC 是 depthwise convolution,它把局部 value 信息直接补回来,缓解 generalized linear attention 可能带来的 feature diversity 不足。#Han-et-al.-2024
可训练 Agent Attention Module
\(B_1\) 与 \(B_2\) 是两段 attention 的位置偏置;\(\mathrm{DWC}(V)\) 是局部卷积补充路径。这个公式适用于视觉 backbone 中从头训练或微调的 Agent Attention Module。
flowchart LR X["输入 tokens x"] --> P["线性投影"] P --> Q["Q"] P --> K["K"] P --> V["V"] Q --> Pool["Pooling 生成 A"] Pool --> A["Agent tokens A"] A --> Agg["Agent Aggregation: softmax(AK^T + B1)V"] K --> Agg V --> Agg Agg --> VA["Agent features"] Q --> Broad["Agent Broadcast: softmax(QA^T + B2)"] A --> Broad VA --> Broad V --> DWC["DWC(V)"] Broad --> Add["相加"] DWC --> Add Add --> O["输出 tokens O"]
复杂度:关键是 \(n\ll N\)
Softmax attention 的主要成本来自 \(QK^T\),大小为 \(N\times N\)。Agent Attention 改成两个矩阵:\(QA^T\) 的大小是 \(N\times n\),\(AK^T\) 的大小是 \(n\times N\)。因此核心注意力成本与 \(Nn\) 成正比。只要 agent token 数 \(n\) 远小于原始 token 数 \(N\),高分辨率输入越大,收益越明显。这也是为什么论文特别强调 high-resolution scaling:Agent-DeiT 在 \(1024^2\) 分辨率下能比 DeiT 节省大量 FLOPs。#Han-et-al.-2024
| 模块 | 形式 | token 维度成本 | 直觉 |
|---|---|---|---|
| Softmax attention | \(\sigma(QK^T)V\) | \(N^2\) | 每个 query 直接访问所有 key |
| Agent aggregation | \(\sigma(AK^T)V\) | \(nN\) | agent tokens 从全局收集信息 |
| Agent broadcast | \(\sigma(QA^T)V_A\) | \(Nn\) | query 从 agent features 取信息 |
| Agent Attention | 两段相乘 | \(2Nn\) | 当 \(n\ll N\) 时近似线性 |
Agent Attention 本身不是新的损失函数,而是 attention module 的替换。因此在 ImageNet、COCO、ADE20K 上,训练目标沿用原任务:分类仍是分类损失,检测与实例分割沿用 Mask R-CNN、Cascade Mask R-CNN、RetinaNet 等框架,语义分割沿用 UperNet 或 Semantic FPN。真正发生变化的是 Transformer block 内部的 attention 计算。#Han-et-al.-2024
Backbone 替换策略
论文把 Agent Attention 用到 DeiT、PVT、Swin、CSWin。对 DeiT/ViT 这类全局 attention backbone,替换最直接:用 Agent Attention Module 替代原来的 Softmax attention。对 Swin/CSWin,Agent Attention 的意义不只是省计算,还能在相似 FLOPs 下扩大 receptive field。论文的 stage 消融显示,Agent Attention 更适合早期高分辨率 stage;最后 stage 是否替换并不总是收益最大。#Dosovitskiy-et-al.-2021 #Liu-et-al.-2021 #Han-et-al.-2024
训练版与无训练版要分清
视觉 backbone 中的 Agent Attention Module 是可训练版本,包含 Agent Bias 和 DWC;Stable Diffusion 中的 AgentSD 是无训练替换版本,不能直接使用 Agent Bias 与 DWC。两者不能混写。
训练配置披露表
| 项目 | 论文披露情况 | 具体配置 | 解读 |
|---|---|---|---|
| ImageNet 数据集 | 已披露 | 1.2M training images,50K validation images,1,000 classes | 标准 ImageNet-1K 分类设置 |
| ImageNet 训练轮数 | 已披露 | 300 epochs;大分辨率 finetuning 30 epochs | 与 DeiT/Swin 系列公平比较 |
| 优化器 | 已披露 | AdamW | 视觉 Transformer 常用设置 |
| 学习率策略 | 已披露 | cosine decay,20 epochs linear warm-up | 避免训练初期不稳定 |
| batch size / LR | 已披露 | batch size 1024 时初始学习率 \(1\times10^{-3}\),按 batch size 线性缩放 | 可复现性较好 |
| 数据增强 | 已披露 | RandAugment、Mixup、CutMix、random erasing | 继承强 ViT 训练 recipe |
| COCO 训练 | 已披露 | ImageNet 预训练 backbone;1x 为 12 epochs,3x 为 36 epochs | 检测实验遵循常见 schedule |
| ADE20K 训练 | 已披露 | UperNet 160K iterations;Semantic FPN 40K iterations | 覆盖语义分割密集预测 |
| 训练 GPU 型号与数量 | 未完整披露 | 分类/检测/分割训练未系统列出 GPU 数量、训练时长 | 博客不能把 runtime 当作严格可复现 benchmark |
| 多 seed 方差 | 未披露 | 论文报告单点结果 | 小幅提升需要谨慎解读 |
这里最值得注意的是 Agent Bias 与 DWC 的消融。Vanilla Linear Attention 只有 77.8,Agent Attention 本体到 79.0,加入 Agent Bias 到 81.1,再加入 DWC 到 82.6。这个表说明,Agent Attention 的数学重排只是第一步;要在视觉任务中成为强模块,还需要位置偏置和局部多样性补偿。#Han-et-al.-2024
普通视觉模型:替换 attention 后直接推理
在分类、检测、分割模型里,推理流程很直接:输入图像经过 patch embedding 或 pyramid feature extractor,进入每个 Transformer stage;被替换的 block 用 Agent Attention Module 计算注意力,后续 MLP、residual、norm 和任务 head 保持原结构。高分辨率场景收益最大,因为原本 \(N^2\) 的注意力成本会随分辨率增长得更快。#Han-et-al.-2024

AgentSD:无训练替换 Stable Diffusion 的特殊版本
Stable Diffusion 场景更敏感,因为我们通常希望直接替换预训练模型中的 attention,而不是重新训练扩散模型。论文将 Agent Attention 应用于 ToMeSD:ToMeSD 已经通过 token merging 减少 attention 前的 token 数,但合并后的 token 仍然不少,Softmax attention 依旧是开销来源。AgentSD 进一步用 token merging 产生 agent tokens,并替换其中的 Softmax attention。#Bolya-et-al.-2023 #Rombach-et-al.-2022 #Han-et-al.-2024
AgentSD 的无训练公式
这里去掉了可训练版本中的 Agent Bias 与 DWC,改用 \(kV\) shortcut 保留直接 value 路径。论文消融中 \(k=0.075\) 表现最好,broadcast 阶段的 scale 采用 \(d^{-0.15}\) 更优。
AgentSD 还有一个重要策略:主要在 diffusion 早期 steps 使用 Agent Attention,后期保持原模型。原因是早期步骤决定大结构和语义布局,token 冗余更明显;后期步骤负责细节修复,过度替换会损害质量。论文的 steps 消融显示,early 40% 是速度与质量的较好折中;继续扩展到 early 60% 或 early 80% 虽然更快,但 FID 明显变差。#Han-et-al.-2024
DreamBooth:为什么只推理替换还不够
论文在 DreamBooth 上还展示了一个边界:如果只在 generation 阶段对所有 diffusion steps 使用 Agent Attention,质量会下降,比如图像变糊或细节错误。更稳定的做法是把 Agent Attention 同时纳入 finetuning 和 generation。论文报告,在 DreamBooth 中采用这种方式可以让生成达到原 DreamBooth 的 2.2× 速度,finetuning 时间和显存约降低 15%,单张 RTX4090 约 7 分钟且小于 12GB 显存。#Ruiz-et-al.-2023 #Han-et-al.-2024

ImageNet:不是单纯省 FLOPs,而是精度也上去了
Agent Attention 在 ImageNet 上最能说明它不是“只省计算”的方法。Agent-DeiT-T 在约 1.2G FLOPs 下从 DeiT-T 的 72.2 提升到 74.9;Agent-DeiT-S 在 FLOPs 从 4.6G 降到 4.4G 的同时,Top-1 从 79.8 提升到 80.5。Agent-PVT-S 20.6M / 4.0G 达到 82.2,超过 PVT-L 的 61.4M / 9.8G / 81.7。这些数字说明:agent tokens 并不是简单丢信息,而是在更低复杂度下保留了足够强的全局语义通道。#Han-et-al.-2024

| 模型 / 设置 | 参数 | FLOPs | Top-1 | 说明 |
|---|---|---|---|---|
| DeiT-T | 约 5.7M | 1.2G | 72.2 | Softmax baseline |
| Agent-DeiT-T | 约 6.0M | 1.2G | 74.9 | 同 FLOPs 明显提升 |
| DeiT-S | 约 22M | 4.6G | 79.8 | 小模型 baseline |
| Agent-DeiT-S | 约 22M | 4.4G | 80.5 | 更低 FLOPs 更高精度 |
| PVT-L | 61.4M | 9.8G | 81.7 | 更大 PVT baseline |
| Agent-PVT-S | 20.6M | 4.0G | 82.2 | 少参数少 FLOPs 反超 |
Dense prediction 与高分辨率:全局感受野更重要
COCO 检测、实例分割和 ADE20K 分割验证的是另一件事:Agent Attention 不只适合分类。密集预测需要在局部细节与全局上下文之间平衡,窗口注意力和稀疏 attention 常常要在感受野上做取舍。Agent Attention 通过 agent tokens 保留全局路径,因此在检测和分割上也能获得一致提升。论文还报告 CPU 推理快 1.7–2.1×,RTX3090/A100 上快 1.4–1.7×;不过训练和测速环境没有完整披露,因此更适合作为论文内报告结果,而不是严格可复现 benchmark。#Han-et-al.-2024
Stable Diffusion:加速之外还改善 FID
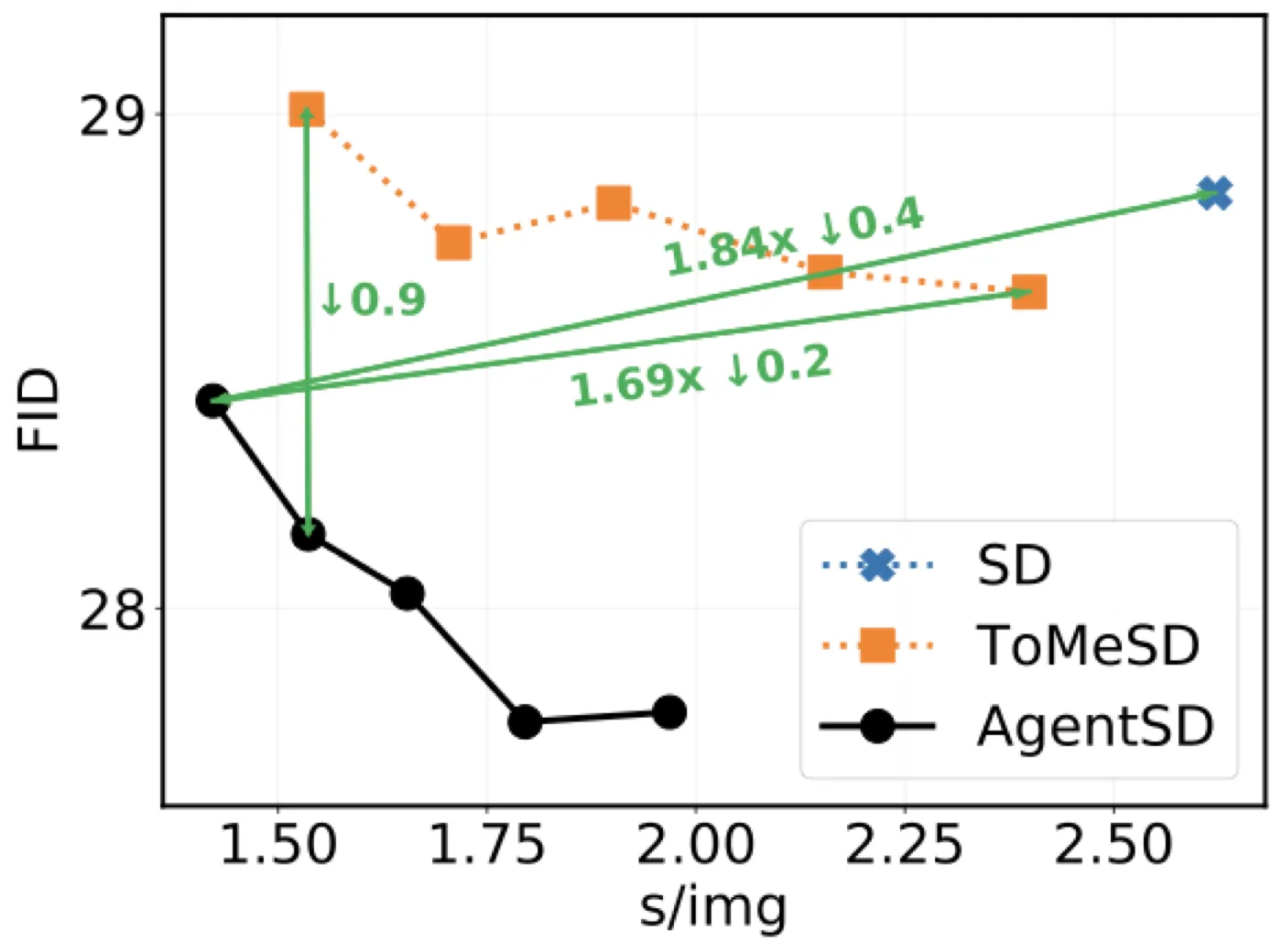
AgentSD 的结果最反直觉。许多生成加速方法会以质量下降为代价,但论文报告 AgentSD 在多个 merging ratio 下同时降低时间、显存和 FID。完整表中,SD v1.5 的 FID 为 28.84,速度 2.62 s/img,显存 3.13 GB/img;AgentSD r=0.2 的 FID 为 27.77,速度 1.80 s/img,显存 1.60 GB/img;AgentSD r=0.5 的速度进一步到 1.42 s/img,显存 1.21 GB/img,FID 仍为 28.42,优于原始 SD。#Han-et-al.-2024
| 模型 | merging ratio | FID | s/img | GB/img |
|---|---|---|---|---|
| Stable Diffusion v1.5 | 0 | 28.84 | 2.62 | 3.13 |
| ToMeSD | 0.4 | 28.74 | 1.71 | 1.69 |
| AgentSD | 0.2 | 27.77 | 1.80 | 1.60 |
| AgentSD | 0.4 | 28.15 | 1.54 | 1.55 |
| AgentSD | 0.5 | 28.42 | 1.42 | 1.21 |
消融:真正支撑方法的三个细节
第一,Agent Bias 和 DWC 不是装饰。消融显示 Agent Attention 本体只有 79.0,加入 Agent Bias 到 81.1,再加入 DWC 到 82.6。第二,agent token 数量不能盲目减少。\([9,16,49,49]\) 与 \([49,49,49,49]\) 都能达到 82.6,但 \([9,16,25,49]\) 会掉到 82.2,说明深层语义更复杂,需要更多 agent tokens。第三,AgentSD 的替换步数要控制:early 40% FID 28.42,early 60% 变 28.83,early 80% 变 29.77。速度提升不能无限扩展到所有步骤。#Han-et-al.-2024
Agent Attention 最适合三类场景。第一,token 数很大,标准 attention 真的成为瓶颈;第二,全局上下文仍然重要,不能简单用局部窗口切掉长距离关系;第三,任务允许引入少量中介 token 作为信息瓶颈。高分辨率分类、检测、分割、视频建模、扩散模型推理和多模态长序列都属于潜在受益场景。论文结论也提到,它的线性复杂度和表达力可能为 video modelling 与 multi-modal foundation models 这类长 token 任务打开空间。#Han-et-al.-2024
| 方法 | 适合场景 | 不适合或需谨慎处 |
|---|---|---|
| Softmax attention | token 不太长、表达力优先 | 高分辨率或长序列成本过高 |
| Window attention | 局部结构强、工程稳定优先 | 长距离关系依赖额外机制 |
| Linear attention | 极长序列、速度优先 | 映射函数可能损失表达力 |
| Agent Attention | token 长且仍需全局语义 | agent 数、Bias、DWC、替换 stage 需要调参 |
| ToMeSD / AgentSD | Stable Diffusion 推理加速 | 过多 diffusion steps 替换会损害质量 |
也要避免过度包装。Agent Attention 的有效性依赖 attention weights 存在冗余;如果某个任务每个 query 都需要高度独特的 key/value 关系,过少 agent tokens 可能成为瓶颈。论文自己的消融已经显示,深层减少 agent tokens 会掉点,最后 stage 全替换也不一定最佳。Stable Diffusion 版本更要谨慎:可训练模块中的 Agent Bias 和 DWC 不能直接无训练塞进预训练扩散模型,AgentSD 为此专门改成了 \(kV\) shortcut 与 scale 调整。#Han-et-al.-2024
复现时最容易误读的点
不要把 Agent Attention 的可训练版本和 AgentSD 的无训练版本混为一谈。前者有 Agent Bias 与 DWC,后者没有;前者主要服务视觉 backbone 替换,后者主要服务 Stable Diffusion / ToMeSD 推理加速。
这篇论文真正值得带走的,不只是一个模块公式,而是一种重新组织 attention 的方法论:当全连接关系太贵时,可以先问“有没有少量中介表示能承载大部分全局语义”。如果答案是肯定的,那么高效 attention 不必只能走局部窗口或手工 kernel 的路线,也可以通过可学习的代理 token,把强表达力和低复杂度接起来。
参考来源
- Han, Dongchen et al. (2024). Agent Attention: On the Integration of Softmax and Linear Attention. ECCV 2024. arXiv:2312.08874 · Official Code
- Vaswani, Ashish et al. (2017). Attention Is All You Need. arXiv:1706.03762
- Katharopoulos, Angelos et al. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML 2020. arXiv:2006.16236
- Choromanski, Krzysztof et al. (2021). Rethinking Attention with Performers. ICLR 2021. arXiv:2009.14794
- Dosovitskiy, Alexey et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021. arXiv:2010.11929
- Liu, Ze et al. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021. arXiv:2103.14030
- Bolya, Daniel and Hoffman, Judy. (2023). Token Merging for Fast Stable Diffusion. CVPRW 2023. arXiv:2303.17604
- Rombach, Robin et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. arXiv:2112.10752
- Ruiz, Nataniel et al. (2023). DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. CVPR 2023. arXiv:2208.12242