Huf-RLC 红外压缩论文解读
红外成像系统在安防、工业检测、遥感等领域越来越常见,而线扫(line-scanning)红外探测器又以高分辨率、大动态范围、连续推扫的方式工作,单帧数据量非常可观。论文作者来自中科院上海技物所红外探测与成像技术实验室,他们面对的实际问题是:这些图像冗余高、文件大,但后端往往要求实时或准实时处理,存储与带宽压力极大 #Zhu-2025。
传统方案中,JPEG 基于块 DCT,在低码率下会出现明显的块效应;JPEG2000 用lifting DWT 加 MQ 算术编码,质量更好,但 MQ 是上下文自适应的二进制熵编码,需要逐 bit 维护概率状态,复杂度远高于查表式编码 #Zhu-2025。深度学习压缩虽然 RD 性能可以超过 JPEG2000,却需要神经网络前向推理,对嵌入式或高速场景并不友好。
因此,作者没有走“更复杂模型”的路线,而是反其道行之:在经典的 transform–quantization–entropy 框架内部做工程优化,目标很明确——在尽量接近 JPEG2000 压缩效率的同时,显著降低编码复杂度。这篇 Sensors 2025 论文提出的 Huf-RLC(Run-Length-Enhanced Huffman Coding)就是这个思路的集中体现 #Zhu-2025。
要理解 Huf-RLC 的贡献,必须先回到 Huffman 编码的基本约束。Huffman 是最优前缀码,在“每个符号必须分配整数个 bit”的限制下,它能让平均码长最接近香农熵。但这个限制本身就是瓶颈:当某个符号概率不是 2 的负整数幂时,Huffman 分配的码长必然大于该符号的自信息 #Zhu-2025。
论文用零符号做了一个非常直观的量化。若零的概率为 \(p(0)=0.8\),它的自信息是:
但 Huffman 给最常见符号分配的最短码通常是 1 bit,于是零符号的码长误差为:
作为对比,一个概率 \(p(x_i)=0.01\) 的非零符号,自信息约为 6.644 bit,Huffman 通常分配 7 bit,误差只有 0.356 bit #Zhu-2025。也就是说,在稀疏分布里,零符号的码长浪费是最大的,而且零越多、浪费越被放大。
核心矛盾
Huffman 很快(查表 \(O(1)\)),但最短码长不能低于 1 bit;稀疏小波系数里零很多,而且常常连续出现。单个零用 1 bit 已经浪费,一长串零逐个编码,就把 Huffman 的整数码长缺陷成倍放大。
到这里,一个自然的思路浮现:如果能把连续零的“游程长度”也编码进去,就可以让一次 Huffman 码字携带多个零的信息,从而把平均到每个零上的 bit 数降到 1 以下。这正是 Huf-RLC 的出发点。
论文的整体框架仍属于经典 transform coding,但每个环节都针对红外图像的统计特性做了精细化设计 #Zhu-2025:
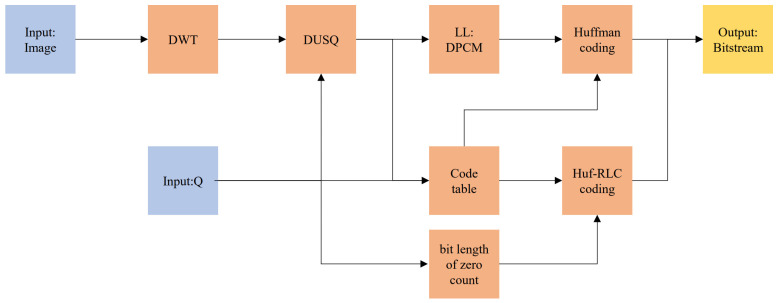
| 模块 | 作用 | 关键设计 |
|---|---|---|
| 5 级 lifting DWT | 把图像能量拆分到 LL/LH/HL/HH 子带 | Daubechies 9/7,整图无块划分,避免块效应 |
| DUSQ | 带死区的均匀标量量化 | 死区 \(T=1.7\Delta\),扩大零区间,增强稀疏性 |
| DPCM | 仅对 LL 子带做列向差分 | 去除低频空间冗余,同时避免高频噪声放大 |
| 概率模型 | 离线统计各子带量化系数分布 | 53 张图训练,16 子带 × 5 量化等级 |
| Huf-RLC | 把零游程长度附加到零的最短 Huffman 码后 | 每个子带/量化等级有独立最优零游程 bit 数 |
下面我们用 Mermaid 把这个 pipeline 画成一张可读性更强的流程图:
graph TD
A[原始红外图像] --> B[5级 lifting DWT]
B --> C[16 个子带系数]
C --> D[DUSQ 死区量化]
D --> E{子带类型}
E -->|LL| F[列向 DPCM]
E -->|LH/HL/HH| G[保持原系数]
F --> H[按子带/量化等级查概率模型]
G --> H
H --> I[预建 Huffman 码表]
I --> J[Huf-RLC 零游程增强编码]
J --> K[压缩码流]
可以看到,这条链路的复杂度主要集中在离线阶段(统计概率模型、建码表、选定零游程 bit 数),在线编码阶段几乎全是查表和单次扫描,因此速度非常快 #Zhu-2025。
4.1 为什么选择 DWT 而不是 DCT?
论文在引言部分花了相当篇幅比较 KLT、DCT 和 DWT。KLT 在 MSE 意义下是最优线性正交变换,但需要依赖数据统计,计算复杂;DCT 基函数固定,计算简单,但它是全局基函数,对非平稳图像的局部特征(边缘、纹理)捕捉不足,JPEG 的 \(8\times 8\) 块 DCT 又会在低码率下引入块效应 #Zhu-2025。
小波变换的基函数只在局部区域非零,因此可以整图做卷积式分解,不需要分块,自然避免块效应。同时 DWT 保留时域和频域信息,支持多分辨率渐进传输,这些特性让它成为 JPEG2000 的核心 #Zhu-2025。
论文采用 JPEG2000 中 lossy 模式常用的 Daubechies 9/7 DWT,并用 lifting 实现 #Taubman-2002。lifting 把传统 Mallat 滤波器组分解为预测(prediction)和更新(update)步骤,计算更高效、边界处理更友好,且与 Mallat 滤波器组在数学上等价 #Zhu-2025。
Lifting-based Daubechies 9/7 的核心步骤
设输入信号被拆分为偶序列 \(x_e[n]\) 和奇序列 \(x_o[n]\),lifting 的两步预测-更新与一次尺度归一化可写为:
其中 \(\alpha=-1.586134342\)、\(\beta=-0.05298011854\)、\(\gamma=0.8829110762\)、\(\delta=0.4435068522\)、\(\xi=1.149604398\) 是 JPEG2000 采用的标准参数 #Zhu-2025。
五级 DWT 后,一个图像会产生 \(3n+1=16\) 个子带:1 个 LL 子带保存主体能量,15 个高频子带(LH、HL、HH 各 5 级)保存方向细节 #Zhu-2025。
4.2 DUSQ:让高频系数更稀疏
不同子带的重要性不同:LL 决定整体结构,需要精细量化;高频细节对视觉影响较小,可以粗量化。JPEG2000 采用 Dead-Zone Uniform Scalar Quantization(DUSQ),它相比普通 USQ 在零附近设置了更大的量化区间,从而把更多小幅系数推向 0 #Zhu-2025#Taubman-2002。
DUSQ 量化公式
论文实际使用的量化规则为:
其中 \(c_j(k)\) 是子带 \(j\) 的第 \(k\) 个小波系数,\(\Delta_j=2\Delta\) 是与子带动态范围相关的量化步长,\(T=1.7\Delta\) 是死区半宽,\(\lfloor\cdot\rceil\) 表示四舍五入。反量化则为 \(\tilde{c}_j(k)=\operatorname{sign}(q)\cdot\Delta_j\cdot q\) #Zhu-2025。
死区的选择对 Huf-RLC 至关重要:只有零足够多、零游程足够长,后面的 run-length-enhanced Huffman 才能产生明显收益。论文用 \(T=1.7\Delta\) 这个经验值,在压缩效率和重建质量之间取得平衡 #Zhu-2025。
4.3 量化等级划分:一个参数 Q 控制码率
为了实现可变码率压缩,论文引入量化参数 \(Q\in(0,32]\),并把系数按 \(Q\) 缩放后再量化:
相近的 \(Q\) 会产生相似的概率分布,因此论文把 \(Q\) 分成 5 个等级,每个等级对应一套概率模型和码表 #Zhu-2025:
| Q 区间 | 量化等级 | 大致码率 |
|---|---|---|
| \((0,2]\) | 5 | 最高质量/最高码率 |
| \((2,4]\) | 4 | 高质量 |
| \((4,8]\) | 3 | 中等码率 |
| \((8,16]\) | 2 | 低码率 |
| \((16,32]\) | 1 | 最低码率 |
这意味着编码器只需要一个 \(Q\) 参数,就能自动选择对应的 5 级量化、16 个子带概率模型、16 个 Huffman 码表,以及每个高频子带对应的 Huf-RLC 零游程 bit 数。
5.1 DPCM 的方向选择
DWT 保留了时域信息,因此子带内部仍存在空间冗余。作者考虑对子带做 DPCM 差分来进一步降低熵。但不同子带的方向特性不同,差分方向选择错误反而会放大噪声 #Zhu-2025:
- LH(水平细节):沿水平方向变化大,行向差分理论上更合适,但线扫红外图像的 LH 子带能量低、易受噪声影响,差分后熵反而上升。
- HL(垂直细节):列向存在一定相关性,列向差分略有收益,但不显著。
- HH(对角细节):噪声敏感,任何差分都会放大噪声、增加熵。
- LL(低频近似):包含最多图像信息和空间冗余,列向差分收益最明显。
| 五级子带 | 初始熵 | 列向 DPCM | 行向 DPCM | 结论 |
|---|---|---|---|---|
| LH | 6.1932 | 6.9936 | 6.5551 | 差分反而增熵,不适合处理 |
| HL | 7.5204 | 6.9991 | 8.2336 | 列向略有收益,但不显著 |
| HH | 5.0752 | 5.8301 | 5.8806 | 噪声敏感,差分增熵 |
| LL | 9.7194 | 7.3093 | 8.5251 | 列向 DPCM 最有效 |
基于以上数据,论文只在 LL 子带上使用列向 DPCM,把熵从 9.7194 降到 7.3093,降幅达 2.4101 bit。这样既能去除冗余,又不会引入额外的复杂度和噪声放大 #Zhu-2025。
5.2 离线概率模型:用“训练集”换在线速度
传统 Huffman 编码需要对每个图像、每个子带在线统计符号概率并构建码表,这会显著拖慢编码速度。论文因此采用直接统计法:对 53 张红外线扫图像做五级 DWT,统计不同量化等级下各子带量化系数的概率分布,再按概率降序构建平均概率模型和预设 Huffman 码表 #Zhu-2025。
概率模型构建流程
- 对 53 张训练图像分别做 5 级 DWT;
- 对每个子带按 5 个量化等级做 DUSQ;
- 统计每个(子带,量化等级)组合下各量化符号的出现概率;
- 在 53 张图像上取平均,得到稳定的概率模型;
- 根据概率模型预建 Huffman 码表。
这个设计本质上是一个工程折中:它假设同类红外线扫图像在小波子带上有稳定统计规律,因此把“统计概率 + 建码表”的计算从在线编码阶段提前到离线阶段。实际编码时只需根据 \(Q\) 选择对应量化等级、子带概率模型、码表和零游程 bit length #Zhu-2025。
与学习式压缩的对比
学习式压缩中的 entropy model 也是在估计 latent 的概率分布,只是通常通过神经网络自适应预测。本文的概率模型更朴素:直接对同类数据做离线统计。前者更强但慢,后者更窄但快。可以把本文的概率模型理解为一种“手工设计的、针对红外图像的轻量 entropy model”。
对于超出概率模型边界的极少数符号,论文采用作者前期工作 #Zhu-2025-lossless 的方法:用最大码值统一编码,并把真实值单独存储。由于边界外概率极低,对整体压缩性能影响很小 #Zhu-2025。
6.1 再谈 Huffman 的整数 bit 限制
在深入 Huf-RLC 之前,我们用信息论语言再描述一次问题。设符号集为 \(X=\{x_0,x_1,\dots,x_{n-1}\}\),概率为 \(P=\{p(x_0),p(x_1),\dots,p(x_{n-1})\}\)。符号 \(x_i\) 的自信息为 \(I(x_i)=-\log_2 p(x_i)\),整个分布的香农熵为:
Huffman 编码给 \(x_i\) 分配的码长 \(n_i\) 满足 \(n_i\ge I(x_i)\),因此实际平均码长 \(L_{avg}=\sum_i p(x_i)n_i\ge H(X)\)。等号仅在所有概率都是 \(1/2\) 的整数幂时成立,而实际图像数据几乎不可能满足 #Zhu-2025。
DUSQ 之后,高频子带中零的概率可能高达 0.8 甚至更高。此时零的自信息约为 0.32 bit,但 Huffman 仍给零分配 1 bit,每个零浪费约 0.68 bit。当整幅图像有数百万个零时,这个浪费变得非常可观 #Zhu-2025。
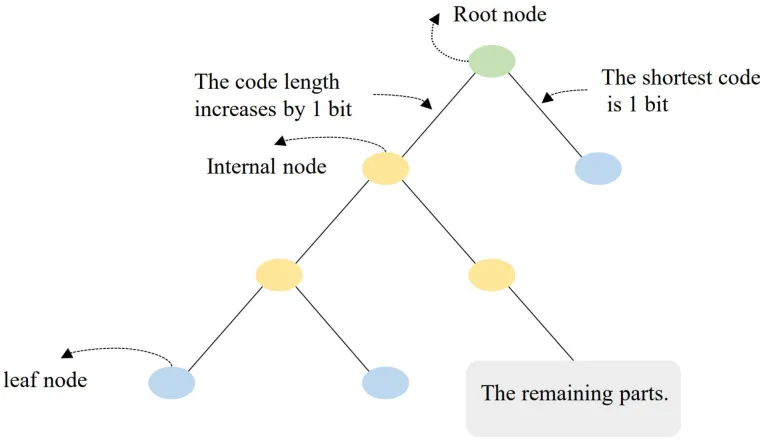
6.2 Huf-RLC 的核心思想
Huf-RLC 没有把 RLC 和 Huffman 简单串联。传统做法通常是对零使用 RLC、对非零符号使用 Huffman,但这需要额外 flag 或 prefix,增加码流开销并复杂化编解码逻辑。本文的做法是:保留 Huffman 码表,但修改最短的零符号码,在它后面追加固定 bit 数来记录连续零的长度 #Zhu-2025。
Huf-RLC 编码规则
设零游程用固定 \(k\) bit 表示,则可记录的游程长度范围为 \(1\sim 2^k-1\)。编码时:
- 顺序扫描量化系数;
- 遇到零时累加游程计数器 \(rlc\);
- 当 \(rlc=2^k-1\)(达到上限)或遇到非零系数时,输出零对应的 Huffman 码,再追加 \(k\) bit 的 \(rlc\);
- 非零系数按其值查 Huffman 码表编码;
- 扫描结束后,如果还有未输出的零游程,一并输出。
这样,一段长度为 \(L\) 的零游程所需 bit 数大约是 Huffman(0) 的码长加上 \(k\) bit。当 \(L\) 很大时,\(k\) 被分摊到 \(L\) 个零上,每个零的平均码长就可以低于 1 bit。论文因此称其能够在稀疏分布中把平均码长降到 1 bit 以下 #Zhu-2025。
Huf-RLC 与算术编码的关系
从信息论角度看,算术编码(如 JPEG2000 的 MQ)本质上打破了 Huffman 的整数 bit 限制,可以直接逼近自信息。Huf-RLC 并没有真正突破这个限制——它仍然给每个“零游程单元”分配整数个 bit,只是通过把多个零打包成一个单元,让每个零的平均码长降到 1 bit 以下。因此它是一种工程上的近似:实现比算术编码简单得多,压缩效率通常略逊一筹。论文的实验结果也印证了这一点:Huf-RLC 速度是 JPEG2000 的 3 倍以上,但 RD 性能有小幅损失。
6.3 算法伪代码与复杂度
论文给出了完整的 Algorithm 1。其核心逻辑可以概括如下(已根据原文整理为更易读的形式):
Algorithm 1:Run-Length-Enhanced Huffman Coding
输入:Quantized_coeff = [q₀, q₁, ..., qₙ],码表 C = [c₀, c₁, ..., c₂·pos]
输出:Bitstream
rlc = 0
overflow_buffer = []
Bitstream = []
for 每个系数 qᵢ in Quantized_coeff:
if qᵢ == 0:
rlc += 1
if rlc == 2^k - 1: // 游程达到上限
Bitstream += Huffman_encode(C[0]) // 零符号
Bitstream += RLC_encode(rlc, k) // k bit 游程长度
rlc = 0
else:
if rlc ≠ 0: // 先输出累积的零游程
Bitstream += Huffman_encode(C[0])
Bitstream += RLC_encode(rlc, k)
rlc = 0
// 非零系数索引
if qᵢ < 0:
index = 2·(0 - qᵢ) + 1
else:
index = 2·qᵢ
if index > 2·pos: // 超出边界,用溢出处理
index = 2·pos + 1
overflow_buffer += qᵢ
Bitstream += Huffman_encode(C[index])
Bitstream += encode(overflow_buffer)
其中符号索引规则是:0 对应零符号;正系数 \(k>0\) 对应索引 \(2k\);负系数 \(k<0\) 对应索引 \(2(0-k)+1\)。这种交替排列让概率相近的相邻绝对值共享相近的码长 #Zhu-2025。
论文还分析了复杂度:算法对量化系数数组做一次线性扫描,每个元素只做常数时间的计数、比较、索引计算和查表,因此时间复杂度为 \(O(n)\);除输入数据外只使用常数额外空间,输出 bitstream 规模为 \(O(n)\) #Zhu-2025。
6.4 最优零游程 bit 长度的存在唯一性
这是论文理论部分的一个亮点。作者证明了:对于给定的零游程序列,存在一个唯一的全局最优固定 bit 长度 \(k^*\),使得总编码代价最小。论文把证明放在了 Appendix A.1 #Zhu-2025。
Theorem A1:最优固定 bit 长度编码的存在唯一性
设 \(\{L_i\}_{i=1}^M\) 是某量化高频子带中零游程长度的序列,\(L_i\in\mathbb{N}^+\)。若每个游程用固定 \(k\) bit 表示(最大可记录长度为 \(2^k-1\)),则总编码代价
存在唯一全局最优解 \(k^*=\arg\min_{k\in\mathbb{N}^+}\operatorname{Total}(k)\),且对所有 \(k\neq k^*\) 都有 \(\operatorname{Total}(k)>\operatorname{Total}(k^*)\)。
证明思路很清晰:先定义单条游程的代价 \(f_i(k)=k\cdot\lceil L_i/(2^k-1)\rceil\)。当 \(k\) 较小时,\(2^k-1\) 指数增长,分母增大使上取整项快速下降,线性增长的 \(k\) 被“摊薄”,因此 \(f_i(k)\) 下降;当 \(k\) 超过某个临界值 \(k_i^*\) 后,\(\lceil L_i/(2^k-1)\rceil=1\),此时 \(f_i(k)=k\) 线性增长。所以每个 \(f_i(k)\) 都是单峰的 #Zhu-2025。
再考虑总代价的前向差分 \(\Delta\operatorname{Total}(k)=\sum_i\Delta f_i(k)\)。随着 \(k\) 增加,贡献负值的项越来越少、贡献非负值的项越来越多,因此 \(\Delta\operatorname{Total}(k)\) 至多从负变正一次。这保证了 \(\operatorname{Total}(k)\) 先严格下降、再严格上升,从而最小值唯一 #Zhu-2025。
把前面的模块串起来,整个编解码流程其实非常简洁。编码端只需要输入图像和量化参数 \(Q\),解码端只需要码流和同样的 \(Q\) #Zhu-2025:
| 步骤 | 编码端 | 解码端 |
|---|---|---|
| 1 | 对原图做 5 级 lifting DWT | —— |
| 2 | 由 \(Q\) 确定量化等级(1–5) | 由 \(Q\) 确定量化等级 |
| 3 | 对每个子带做 DUSQ | —— |
| 4 | 对 LL 子带做列向 DPCM | 解码后做反 DPCM |
| 5 | 按(子带,量化等级)选择概率模型、码表、\(k\) | 按同样规则选择码表和 \(k\) |
| 6 | Huf-RLC 编码并输出码流 | Huf-RLC 解码得到量化系数 |
| 7 | —— | 反量化、反 DWT 重建图像 |
注意,概率模型、码表、\(k\) 都是离线训练好的,在线阶段完全不需要统计概率或重新建表。这是 Huf-RLC 速度优势的重要来源 #Zhu-2025。
工程实现要点
论文强调 DWT 实现采用了与 OpenJPEG 相同的方式并启用 SIMD,以保证小波变换效率。但即便如此,整体压缩速度仍显著超过 OpenJPEG,说明速度优势主要来自熵编码端的 Huf-RLC。值得注意的是,Huf-RLC 在速度测试中用的是单核单线程、无 SIMD 优化,这意味着还有进一步加速空间 #Zhu-2025。
8.1 数据集与实验设置
论文使用 53 张红外线扫图像构成训练集,用于统计概率模型和选择零游程 bit length;另有 27 张来自不同红外线扫探测器工作场景的图像构成测试集,验证泛化性 #Zhu-2025。
| 配置项 | 论文披露内容 |
|---|---|
| 训练集 | 53 张红外线扫图像 |
| 测试集 | 27 张不同场景红外线扫图像 |
| 图像尺寸示例 | 2048 × 2048(Image A) |
| DWT 小波/级数 | Daubechies 9/7 lifting,5 级 |
| 量化参数 Q | (0,32],分 5 个量化等级 |
| 概率模型 | 16 子带 × 5 量化等级 |
| 测试硬件 | Intel i7-12700H,16 GB RAM(Windows 批处理脚本单图测试) |
| 对比 baseline | JPEG、JPEG2000(OpenJPEG) |
8.2 最优零游程 bit 长度的选择
在正式对比之前,论文先回答了“每个子带、每个量化等级应该用多长的 \(k\)”这个问题。实验在 53 张训练图像上,对五级 DWT 的 15 个高频子带,分别在 5 个量化等级下,测试 \(k=1\sim 20\) 的压缩增益。压缩增益定义为 Huf-RLC 压缩比除以标准 Huffman 压缩比 #Zhu-2025。
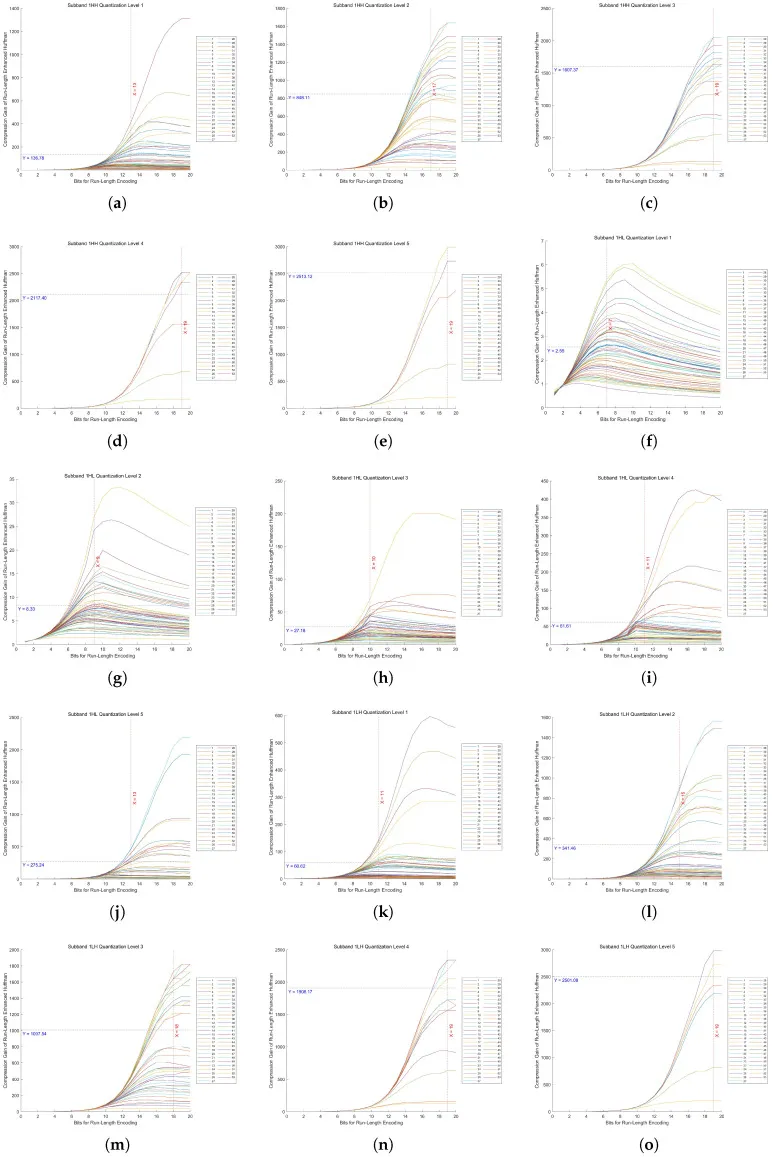
从图中可以观察到:\(k\) 较小时,记录能力弱,长游程需要频繁拆分;\(k\) 太大时,每个游程都多付出了不必要的 bit。曲线呈单峰形态,与 Appendix A.1 的理论证明一致。论文进一步规定:只有当某子带的压缩增益大于 2 时,才对该子带启用 Huf-RLC;否则退回到标准 Huffman 编码 #Zhu-2025。
8.3 与 JPEG、JPEG2000 的 RD 对比
主实验从训练集和测试集各选 3 张图像,在低码率(量化等级 1)和高码率(量化等级 5)下与 JPEG、JPEG2000 对比。定量结果见 Table 5 #Zhu-2025:
| 图像 | 方法 | 低码率(BPP/PSNR/SSIM) | 高码率(BPP/PSNR/SSIM) | ||||
|---|---|---|---|---|---|---|---|
| 1 | JPEG | 0.0387 | 27.37 | 0.8456 | 0.5282 | 50.84 | 0.9928 |
| JPEG2000 | 0.0381 | 43.41 | 0.9793 | 0.5000 | 52.40 | 0.9947 | |
| Proposed | 0.0380 | 40.57 | 0.9704 | 0.4983 | 51.63 | 0.9928 | |
| 均值 | JPEG | 0.0420 | 28.97 | 0.8484 | 0.702 | 49.67 | 0.9901 |
| JPEG2000 | 0.0380 | 43.17 | 0.9729 | 0.729 | 51.06 | 0.9926 | |
| Proposed | 0.0380 | 40.50 | 0.9649 | 0.701 | 49.95 | 0.9894 | |
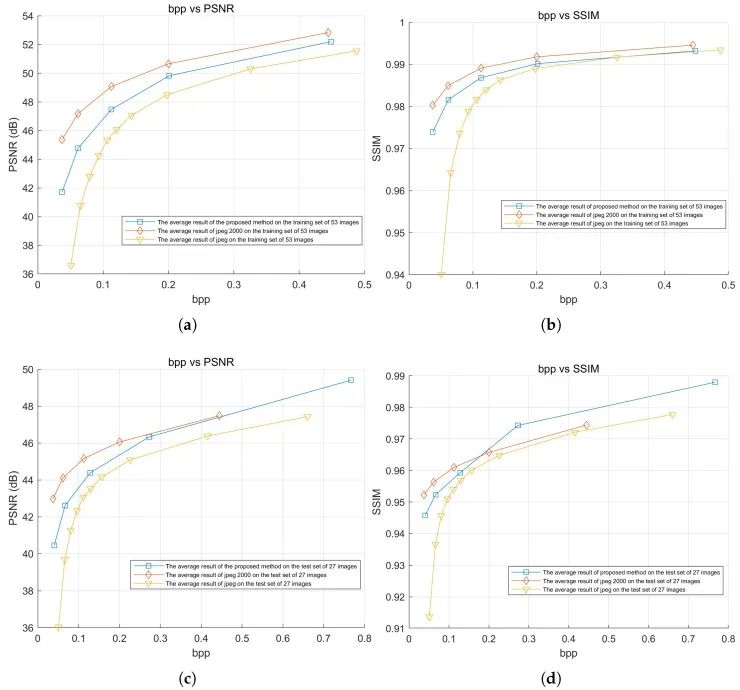
低码率下,JPEG 的平均 PSNR 仅 28.97 dB、SSIM 0.8484,而本文方法分别达到 40.50 dB 和 0.9649,与 JPEG2000(43.17 dB / 0.9729)的差距很小;高码率下三者差距进一步缩小。这说明本文方法在极低码率下也能保持接近 JPEG2000 的重建质量,同时避免了 JPEG 的块效应 #Zhu-2025。

在训练集和测试集全部图像上绘制的 RD 曲线(Figure 15)以及平均差距统计(Table 6)进一步验证了结论 #Zhu-2025:
| 对比对象 | 训练集平均 PSNR 差距 | 训练集低 BPP | 测试集平均 PSNR 差距 | 测试集低 BPP |
|---|---|---|---|---|
| Proposed vs JPEG2000 | −1.825 dB | −3.665 dB | −0.520 dB | −2.522 dB |
| JPEG vs JPEG2000 | −3.699 dB | −8.779 dB | −2.257 dB | −6.934 dB |
8.4 压缩速度
速度测试在 Intel i7-12700H、16 GB RAM 的 Windows 平台上进行,使用单图批处理脚本。Table 7 报告的平均速度为 #Zhu-2025:
| 方法 | 速度(MB/s) | 相对 JPEG2000 | 相对 JPEG |
|---|---|---|---|
| JPEG | 14.153 | 1.543× | — |
| JPEG2000 | 9.174 | — | 0.648× |
| Proposed | 28.944 | 3.155× | 2.049× |
这篇论文的贡献可以概括为三点。第一,作者针对红外线扫图像的小波子带统计规律建立了离线概率模型,避免在线统计和建表,把熵编码复杂度降到查表级别。第二,作者发现稀疏量化小波系数中零符号的 Huffman 最短码误差是压缩效率瓶颈,并用零游程增强修补这个问题,且给出了最优 bit 长度的存在唯一性证明。第三,作者对 LL 子带单独使用列向 DPCM,在不显著增加复杂度的情况下减少低频空间冗余 #Zhu-2025。
9.1 局限与适用范围
但它的局限也很明显。首先,概率模型依赖 53 张同类红外线扫图像的统计分布,泛化到其他红外成像模式、普通热成像阵列图像、RGB-T 数据集或医学热红外图像时需要重新验证。其次,论文主要比较 JPEG、JPEG2000 和本文方法,没有纳入 BPG/VVC intra、CCSDS 122.0 或现代 learned image compression baseline。第三,方法优化的是 PSNR、SSIM、BPP 和速度,并未评估红外下游任务,例如目标检测、测温误差或小目标保持能力 #Zhu-2025。
| 复现要素 | 论文披露状态 | 说明 |
|---|---|---|
| DWT 类型与滤波器系数 | 已披露 | lifting 9/7,Table 1/2 给出全部参数 |
| DUSQ 公式、死区 T=1.7Δ、Q 分级 | 已披露 | §2.1.2–2.1.3 给出 |
| DPCM 方向选择 | 已披露 | 仅 LL 子带列向 DPCM |
| Huf-RLC 算法伪代码 | 已披露 | Algorithm 1 完整给出 |
| 80 个概率模型 / 码表内容 | 未披露 | 仅 Figure 9–10 给出图示,无符号级数值 |
| 75 个 (子带, 量化等级) 的 k 值 | 未披露 | Figure 13/A1–A4 画了曲线,无精确峰值 |
| 代码与数据集 | 未公开 | 数据需向通讯作者申请 |
这意味着第三方可以独立复现算法框架和流程,但若要跑出与原文完全一致的 PSNR/SSIM,必须重新采集同类红外图像、重新统计概率模型并重新搜索最优 \(k\)。
需要注意的适用边界
Huf-RLC 的收益强烈依赖“DUSQ 后高频子带大量连续零”这一统计特性。如果图像内容不满足这个条件(例如纹理极其丰富的可见光图像),零游程增强的收益会大幅下降,甚至可能因额外的 \(k\) bit 开销而劣于标准 Huffman。
9.2 对学习式压缩的启发
虽然这篇论文不是 learned image compression,但它对红外 LIC 很有启发:红外图像压缩不一定要从更大的网络开始,很多收益来自对数据统计的准确理解。DWT 子带、DUSQ 零稀疏、LL 子带空间冗余、线扫方向相关性、零游程长度分布,这些都可以成为神经压缩模型里的 inductive bias。
一个自然的后续方向是把 Huf-RLC 的思想迁移到学习式熵模型:用小波域 latent 表示红外图像,用神经 entropy model 预测不同子带的概率参数,同时显式建模 zero-run 或 sparse token。这样可以在保留红外统计结构的同时,让模型适应更多场景。
- Zhu, Y., Liu, Y., Zhu, Y., Huang, M., Jiang, J., & Zhang, Y. (2025). Lossy Infrared Image Compression Based on Wavelet Coefficient Probability Modeling and Run-Length-Enhanced Huffman Coding. Sensors, 25(8), 2491. DOI: 10.3390/s25082491. MDPI; PMC full text
- Zhu, Y., Huang, M., Zhu, Y., & Zhang, Y. (2025). A Low-Complexity Lossless Compression Method Based on a Code Table for Infrared Images. Applied Sciences, 15(5), 2826. DOI: 10.3390/app15052826. MDPI
- Usevitch, B. E. (2001). A Tutorial on Modern Lossy Wavelet Image Compression: Foundations of JPEG 2000. IEEE Signal Processing Magazine. PDF
- Taubman, D. S., & Marcellin, M. W. (2002). JPEG2000: Image Compression Fundamentals, Standards and Practice. Springer.