Avatar 类型数字人
Avatar 类型数字人不是“能说话的脸”这么窄的任务。它可以是一张照片驱动出的 talking head,也可以是带手势的上半身主播、音频驱动的全身人物视频、多人对话场景中的 full-frame video avatar,还可以是一个能被反复驱动和渲染的 3DGS / mesh 身份资产。把这些都叫 talking head,会直接误导方法选择、指标解读和算力预算。
任务 taxonomy 回答的是:输入是什么、输出是什么、系统要服务哪类产品。一个任务类型必须有明确的评测重点。否则很容易把只改嘴的视频配音模型、全身 motion 模型、整帧视频大模型和 3DGS avatar asset 放在一张榜单里比较。
| 任务类型 | 典型输入 | 典型输出 | 代表工作 | 评测重点 | 边界 |
|---|---|---|---|---|---|
| Head / portrait talking video | 参考图或参考视频 + 音频 | 头肩或肖像视频 | SadTalker、MuseTalk、RAD-NeRF、ER-NeRF | Sync-C / Sync-D、身份、表情、头动、实时性 | 不负责手势、全身动作和可复用 3D 资产 |
| Upper-body co-speech avatar | 参考图 + 音频 + 手/身体条件 | 脸、手、躯干协同的上半身视频 | ChatAnyone、EMO2 | 手部结构、手势节奏、唇音同步、身份、FPS | 只看 FID/FVD 会漏掉手势是否自然 |
| Full-body motion generation | 音频 + speaker / style / hints | SMPL-X、FLAME、MANO 或骨骼动作 | EMAGE、Audio2Photoreal motion module | FGD、BC、Diversity、face MSE、gesture realism | 输出是 motion,不是最终 photoreal pixels |
| Full-frame avatar video generation | 参考图 + 音频 + prompt / mask | 场景中的单人或多人 avatar video | OmniAvatar、HunyuanVideo-Avatar | FID/FVD、Sync、IQA/ASE、prompt control、多角色控制 | 质量强但推理慢,通常不是低延迟交互答案 |
| Renderable avatar asset creation | 单图、多视角或视频 + pose/audio | 3DGS、NeRF 或 mesh avatar asset + 渲染视频 | One Shot, One Talk、AudioAvatar、GaussianTalker | 几何一致性、身份复用、novel pose/view、渲染速度 | 适合复用身份资产,不适合只做一次性短视频 |
| Streaming / realtime avatar | 音频流、视频流或对话流 | 低延迟连续输出 | ChatAnyone、Live Avatar、StreamAvatar | 首帧延迟、FPS、吞吐、漂移、端到端延迟 | 论文 FPS 不等于完整产品 SLA |
表 1:Avatar 任务分类。这里按输入输出与产品约束划分,不按论文标题或模型名字划分。
这个分类解释了为什么不同论文不能直接横比。EMAGE 主要评动作分布,OmniAvatar 主要评 full-frame 视频质量,One Shot, One Talk 评 self-driven reconstruction 和 3D asset 表达,ChatAnyone 则强调上半身实时输出。它们都属于 avatar,但不是同一个 benchmark 问题。
技术路线 taxonomy 回答的是:系统用什么中间表示、什么生成器、什么资产结构来完成任务。一个任务可以由多条路线完成,同一条路线也可以服务多个任务。
| 技术路线 | 核心表示 | 适配任务 | 代表工作 | 优势 | 限制 |
|---|---|---|---|---|---|
| 2D talking-head / latent inpainting | face landmarks、mask、latent feature | head / portrait | MuseTalk、SadTalker | 简单、快、生态成熟 | 身体和手势弱,3D 一致性弱 |
| Structured motion policy | SMPL-X、FLAME、MANO、VQ motion token | full-body motion、upper-body gesture | EMAGE、Audio2Photoreal、EMO2 | 可解释、可控、动作可单独评估 | 仍需要 renderer 才能变成 photoreal video |
| Motion diffusion + fast renderer | 低维 motion + warping GAN / renderer | 实时上半身 avatar | ChatAnyone | 实时性强,工程闭环清晰 | 画面自由度低于 full-frame 大模型 |
| Video foundation model adaptation | video latent、DiT/MM-DiT、ReferenceNet、LoRA | full-frame avatar video | OmniAvatar、HunyuanVideo-Avatar | 场景、prompt、全画幅表达强 | 训练和推理重,资产不可复用 |
| 3DGS / NeRF / mesh asset | Gaussian particles、NeRF field、SMPL-X mesh | renderable avatar | One Shot, One Talk、AudioAvatar、GaussianTalker | 身份可复用,渲染控制和几何一致性更强 | 注册难、训练成本高,极端动作风险大 |
| Mask-localized multi-character control | face mask + localized audio cross-attention | 多人 avatar video | HunyuanVideo-Avatar | 可指定说话人,适合多人场景 | 仍依赖 mask,复杂互动尚未完全解决 |
表 2:Avatar 技术路线分类。分类依据是表示和生成机制,不是论文题目。
路线之间可以组合。EMAGE 输出的 motion 可以进入 photoreal renderer;Audio2Photoreal 把音频生成的 face/body/hand motion 接到 personalized renderer;One Shot, One Talk 把 2D diffusion 伪视频和 SMPL-X / 3DGS-mesh asset 结合;AudioAvatar 则进一步用 video diffusion teacher 的先验来训练 audio-driven Gaussian particle motion。
ChatAnyone:实时上半身 Avatar
ChatAnyone 的关键不是再做一个 talking head,而是把脸、身体和手部拆成层级运动控制,再用 fast renderer 输出上半身视频。它代表“motion diffusion + fast renderer”路线:把扩散留在紧凑运动空间,把实时性留给渲染系统。论文报告的 30 FPS 级结果说明,这条路线更接近互动主播和客服 avatar,而不是离线高质量视频生成。#Qi-et-al.-2025-ChatAnyone

EMO2:把手当成语音表达的末端执行器
EMO2 的判断是:上半身 avatar 的难点不只是嘴,而是手势。它先预测 MANO hand end-effector,再让 ReferenceNet 视频扩散补全脸、身体和手势。这个结构把“手势是否自然”从附属问题变成核心变量,也提醒我们:upper-body avatar 的评估不能只看同步和 FID。#EMO2-2025
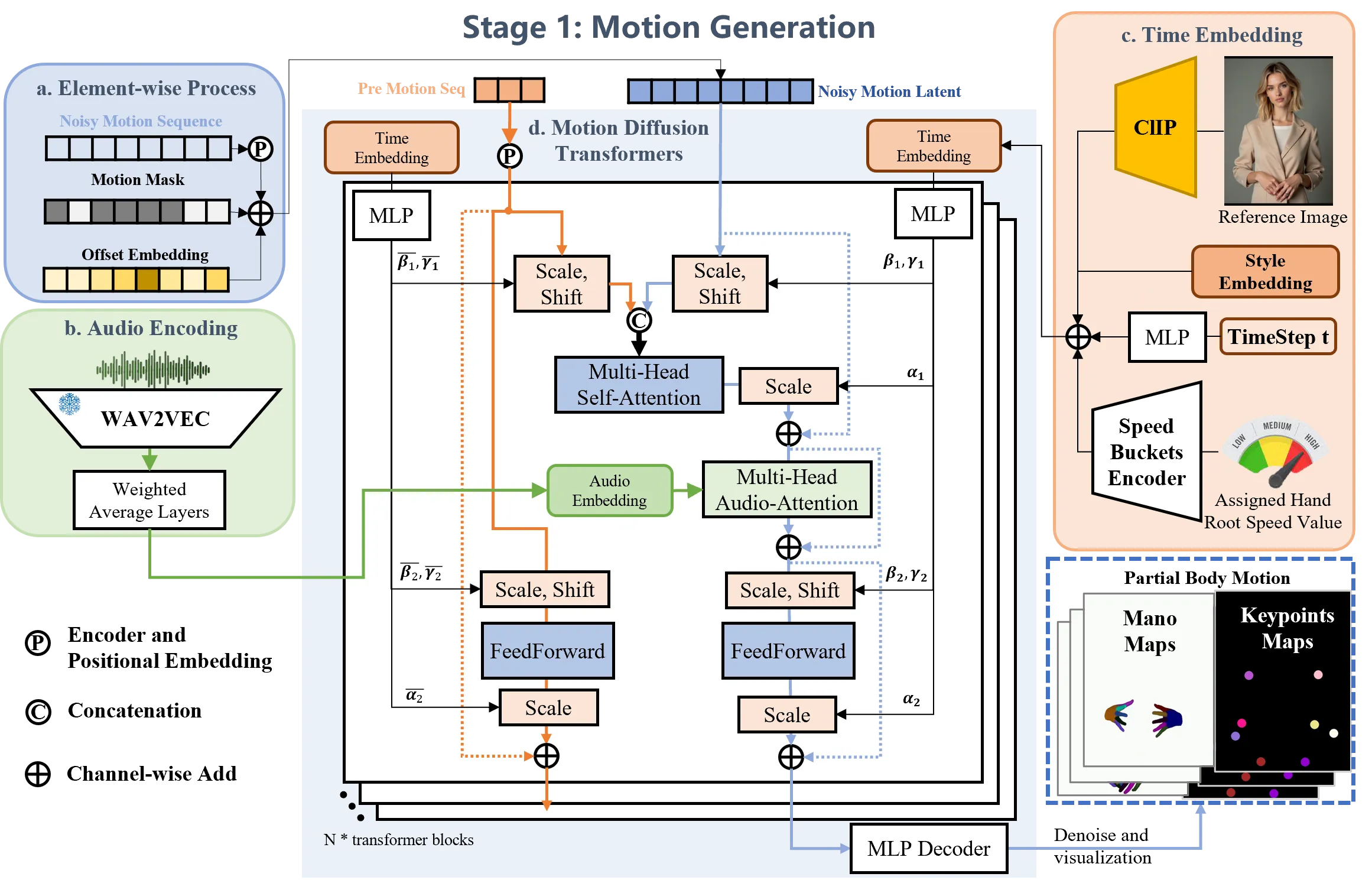
OmniAvatar:把音频注入视频 latent 的 full-frame 路线
OmniAvatar 基于 Wan2.1,把音频打包后以逐像素、多层方式注入视频 DiT,并用 LoRA 保留文本 prompt 控制。它代表 full-frame avatar video generation:模型在同一视频生成空间里决定脸、身体、背景和文本风格。代价也明确:25 denoising steps 和大视频基座意味着它不是实时交互的默认方案,而是质量优先的 full-frame baseline。#Gan-et-al.-2025-OmniAvatar
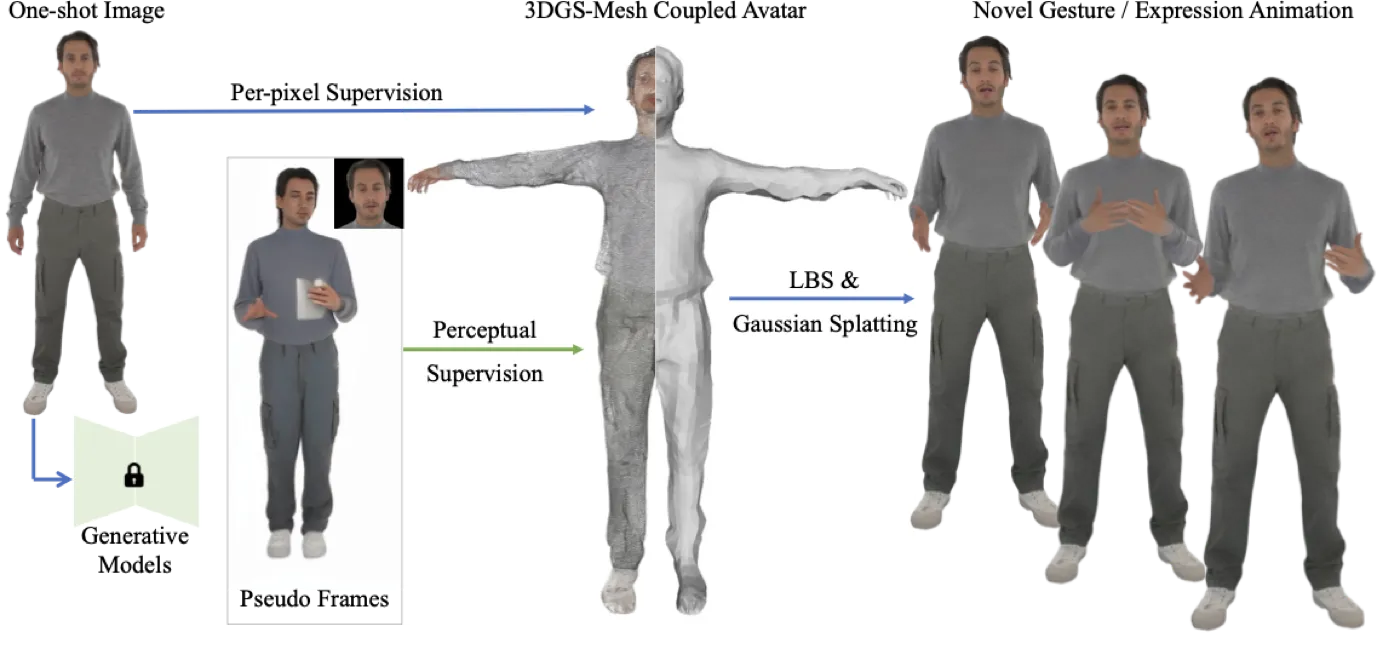
One Shot, One Talk:从单图生成可渲染全身资产
One Shot, One Talk 选择的是 asset 路线:从单张全身图出发,结合 SMPL-X、3D Gaussian 和 2D 视频扩散伪标签,训练一个可复用、可驱动的 full-body talking avatar。它不是一次性生成 RGB 视频,而是在构建可反复渲染的身份资产。这条路线适合 AR/VR、远程会议和需要长期复用角色的产品,但单图恢复完整可动人体仍然不适定。#One-Shot-One-Talk-2024
| 论文 | 任务定位 | 技术路线 | 核心输入 | 核心输出 | 关键代价 |
|---|---|---|---|---|---|
| ChatAnyone | 实时上半身 avatar | hierarchical motion diffusion + warping GAN + MANO | 音频 / 参考图 | 30 FPS 级上半身视频 | 画面自由度低于整帧视频基模 |
| EMO2 | 上半身手势 avatar | MANO hand diffusion + ReferenceNet video diffusion | 音频 / 参考图 | 脸、身体、手势协同视频 | 非实时,手势语义仍难完全评估 |
| OmniAvatar | full-frame audio-driven avatar | Wan2.1 + Audio Pack + latent injection + LoRA | 参考图 / 音频 / prompt | 整帧 avatar video | 推理慢,不是资产复用路线 |
| One Shot, One Talk | 单图全身可渲染 avatar | SMPL-X + 3DGS + pseudo video supervision | 单张全身图 / 姿态 | 可驱动 3D avatar asset | 训练成本和几何注册风险更高 |
表 3:四篇重点论文分别代表实时上半身、手势优先、整帧视频基模和 3D 可渲染资产四个分叉。
2021—2023:头部同步与神经渲染头像
这一阶段先解决嘴型、表情、头动和身份保持。AD-NeRF、RAD-NeRF、ER-NeRF 等音频驱动 NeRF talking portrait 把神经渲染引入头像数字人;SadTalker、MuseTalk 等工具化路线则把 2D/latent talking head 推向更低成本的内容生产。多数工作仍集中在头肩,手势和全身动作不是主问题。
2024:从“脸会说话”扩展到“身体会表达”
EMAGE 把 face、body、hands、global motion 统一到 SMPL-X / FLAME motion benchmark;Audio2Photoreal 把音频生成的 face/body/hand motion 接到 personalized photoreal renderer;One Shot, One Talk 则用 2D diffusion 伪视频监督 3DGS-mesh avatar asset。Avatar 的问题从 lip-sync 扩展到身体表达和资产复用。
2025:视频基础模型接管 full-frame avatar,实时路线同时分化
OmniAvatar 和 HunyuanVideo-Avatar 表明,大视频模型可以把参考图、音频、prompt、背景、身体动作放进同一个 full-frame 生成空间。与此同时,ChatAnyone 代表另一条工程分化:不追求最自由的整帧生成,而是用紧凑 motion space 与 fast renderer 换取实时交互。
2026:3DGS asset 与 diffusion teacher 融合
AudioAvatar 展示了 diffusion teacher 与显式 3DGS asset 的融合方向:用 video score distillation、trajectory alignment 和局部 face/hand refinement,把大视频模型的自然动作先验蒸馏进 audio-driven Gaussian particle motion。它报告 125-frame end-to-end synthesis 约 70 秒 on A100,并称相较同长度 video diffusion 约快 50 倍。#AudioAvatar-2026
| 转变点 | 之前 | 之后 | 推动力 |
|---|---|---|---|
| 画面范围扩大 | head / portrait | upper-body / full-body / full-frame | 产品需要手势、场景和身体表达 |
| 输出形态分化 | 一次性 RGB 视频 | RGB 视频、motion 参数、3D asset 并存 | 复用、交互、渲染控制需求不同 |
| 控制信号丰富 | 音频驱动嘴型 | 音频 + prompt + mask + emotion reference + body priors | 多人、情绪、动作和场景控制 |
| 实时与质量分流 | 统一看生成质量 | 实时系统和离线高质量系统分道 | 端到端延迟与大模型推理成本冲突 |
表 4:Avatar 领域的演进不是单纯画质提升,而是任务、输出形态和工程约束同时分化。
Avatar 的算力不能用一个数字概括。motion benchmark、局部换嘴、full-frame DiT、3DGS asset 是四种完全不同的成本结构。训练时长受数据规模、分辨率、batch size、是否微调基座和是否 person-specific 影响;推理速度受采样步数、渲染器、分辨率、是否包含音频编码和媒体链路影响。
| 工作 | 数据 | 训练配置 / 成本 | 推理配置 / 成本 | 解读 |
|---|---|---|---|---|
| EMAGE | BEAT2 60h | batch size 64;400 epochs;lr 2.5e-4;single L4/V100/4090 约 26.5h/17.2h/8.0h;5×VQ-VAE 预训练约 22.4h on 5×4090 | 输出 motion,不是最终视频 | 适合作为 co-speech motion benchmark |
| Audio2Photoreal | 8h 多视角对话 | single A100;face 8h、VQ/coarse 5h、pose 8h | 依赖 personalized renderer | 成本来自 per-subject photoreal renderer |
| EMO2 | 275h | Stage1 1×A100;Stage2 4×A100;Stage1 400K steps;Stage2 100K+100K | 非实时扩散视频生成 | 强调手势结构,不是低延迟系统 |
| OmniAvatar | 1320h AVSpeech | 64×A100 80GB;lr 5e-5;max latent 30k | 25 denoising steps;论文未披露标准 FPS | full-frame 质量优先,算力重 |
| HunyuanVideo-Avatar | 1250h | 160×96GB GPUs;global batch 40;lr 1e-5 | 720×1216 10s 视频约 60min | 多人和情绪控制强,但远离实时 |
| One Shot, One Talk | 单图 + 伪视频 | 150K Gaussians;UV 512;完整训练时长未披露 | 完整 FPS 未披露 | 重点是 asset 质量和可复用性 |
| AudioAvatar | synthetic + conversation data | 完整训练 GPU-hour 未披露 | 125-frame end-to-end synthesis 约 70s on A100 | 显式 3DGS 比同长度 video diffusion 更快,但不是 30 FPS 实时 |
表 5:Avatar 代表工作的训练与推理资源。未披露项必须明确标注,不能用猜测填充。
不要把不同路线的算力数字排成绝对榜单
EMAGE 的训练资源对应 motion generation;OmniAvatar 的资源对应 full-frame DiT 适配;One Shot, One Talk 的成本对应 asset optimization;AudioAvatar 的 70 秒对应 125-frame end-to-end synthesis。这些数字说明路线量级,不说明谁在所有任务上更好。
数字人实验最容易出现的误读,是用 FID/FVD 一句话概括所有质量。Avatar 至少包含同步、身份、运动、稳定性、效率和资产可复用六类目标。不同任务应该读不同指标。
| 指标 | 衡量对象 | 适用任务 | 局限 | 常见误用 |
|---|---|---|---|---|
| FID / FVD | 图像或视频分布距离 | full-frame video | 不能说明手势、同步、身份和实时性 | 用一个数断言 avatar 整体更好 |
| Sync-C / Sync-D | 音视频同步 | talking head、full-frame avatar | 主要看唇音,不覆盖手势语义 | 忽略身体自然度 |
| CSIM / identity similarity | 身份保持 | reference-based avatar | 对手、衣服、身体漂移不敏感 | 当成整体一致性指标 |
| HKC / HKV / hand metrics | 手部一致性和速度 | upper-body hand gesture | 不一定反映语义合适性 | 只看手,不看全身配合 |
| FGD / BC / Diversity | 动作分布和 beat correlation | co-speech motion | 不评价 photoreal rendering | 和 RGB 视频指标混比 |
| PSNR / SSIM / LPIPS | 重建质量和感知距离 | reconstruction、3D avatar | 不等于开放生成自然度 | 把重建指标当生成质量 |
| FPS / latency | 系统效率 | realtime / streaming | 依赖硬件、分辨率和 pipeline | 不披露硬件时直接横比 |
表 6:Avatar 指标必须和任务绑定。同步、身份、运动、稳定性和效率都要单独看。
数据集也有同样边界。HDTF、CelebV-HQ 更常用于 talking face 和 portrait;BEAT / BEAT2 更适合 co-speech full-body gesture;AVSpeech 支撑大规模 audio-video 训练但身体标注弱;ActorsHQ、Casual Conversations 和多视角自建数据更接近 3D avatar 或 photoreal renderer 评估。所有实验数字都必须放回这些数据语境里。
| 产品目标 | 优先路线 | 可读论文 | 原因 | 风险 |
|---|---|---|---|---|
| 低成本视频配音或会议头像 | 2D talking-head / latent inpainting | MuseTalk、Wav2Lip、SadTalker | 速度快,工程生态成熟 | 表情、身体和手势弱 |
| 实时上半身互动主播 | motion diffusion + fast renderer | ChatAnyone、EMO2 | 把动作和渲染拆开,有机会控制延迟 | 手势语义和长时稳定仍难 |
| 离线高质量全画幅视频 | video foundation model adaptation | OmniAvatar、HunyuanVideo-Avatar | 画面、prompt、场景和身体表达强 | 训练推理重,不适合低延迟 |
| 固定角色长期复用 | 3DGS / mesh renderable asset | One Shot, One Talk、AudioAvatar、GaussianTalker | 身份资产可复用,可被多次驱动 | 建模、注册和授权成本高 |
| 多人对话视频 | mask-localized audio control + video foundation model | HunyuanVideo-Avatar | 能指定说话人与局部音频控制 | 复杂交互、视线和空间关系仍不成熟 |
表 7:Avatar 产品选型。先看实时性、画质、资产复用、多角色和授权约束,再决定技术路线。
实时交互优先时,ChatAnyone 或流式蒸馏类系统更接近落地;可复用身份资产优先时,3DGS / mesh 路线更合理;高质量离线内容优先时,OmniAvatar、HunyuanVideo-Avatar 这类 full-frame video foundation model 更有表达上限。没有单一最优 avatar 模型,只有任务约束匹配。
如何统一评估“会说话”和“会表达”
Sync-C 看嘴,FID/FVD 看分布,FGD 看动作,CSIM 看身份,FPS 看系统,但没有一个指标能同时衡量语音语义、手势意图、身体自然度和长期身份稳定。上半身和全身 avatar 需要更完整的综合评测。
Full-frame diffusion 和实时交互之间仍有鸿沟
OmniAvatar 和 HunyuanVideo-Avatar 说明大视频模型能增强场景、prompt 和身体表达,但 HunyuanVideo-Avatar 10 秒视频约 60 分钟的速度锚点也说明它们离实时系统很远。未来需要蒸馏、缓存、稀疏帧、流式去噪或 motion-to-render 混合系统。
3DGS / mesh asset 的单图泛化仍不可靠
单图恢复完整可动人体本质上不适定。注册误差、手指自交、衣服拓扑、遮挡和大视角缺失都会造成失败。One Shot, One Talk 和 AudioAvatar 展示了方向,但还不是通用可靠的消费级资产生成器。
动作生成还没有真正理解语义
很多动作主要由韵律、风格和历史运动驱动,而不是完整语义理解。真实 avatar 应该理解“这里”“那边”“这个数字很大”等指代,并和语言、场景对象、视线和手势 grounding 结合。
Avatar 类型数字人的主线,是从“脸会说话”走向“身体会表达、资产可复用、系统可交互”。任务上,它分成 head/portrait、upper-body、full-body motion、full-frame video、renderable asset 和 streaming avatar;技术上,它分成 2D inpainting、structured motion、fast renderer、video foundation model、3DGS/mesh asset 和 multi-character localized control。
因此,读 avatar 论文时要先问四个问题:输出是一次性视频还是可复用资产?目标是实时交互还是离线质量?评估重点是嘴、脸、手、身体、身份还是系统延迟?论文披露的训练和推理成本是否覆盖完整 pipeline?只有这些问题都回答清楚,模型比较才有意义。
参考资料
- Qi et al. (2025). ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion. 站内精读
- EMO2 (2025). Audio-driven upper-body avatar generation with MANO hand end-effectors and ReferenceNet video diffusion. 站内精读
- Gan et al. (2025). OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation. 站内精读
- One Shot, One Talk (2024). Single-image full-body talking avatar with SMPL-X and 3D Gaussian representation. 站内精读
- EMAGE (2024). Towards unified holistic co-speech motion generation with face, body, hands and global motion. 本地 synthesis:
/Users/tangwen/Org/roam/raw/emage-2024/synthesis.md - Audio2Photoreal (2024). Audio-driven photorealistic conversational avatars. 本地 synthesis:
/Users/tangwen/Org/roam/raw/audio2photoreal-2024/synthesis.md - HunyuanVideo-Avatar (2025). Audio-driven single and multi-character avatar video generation with MM-DiT. 本地 synthesis:
/Users/tangwen/Org/roam/raw/hunyuanvideo-avatar-2025/synthesis.md - AudioAvatar (2026). Audio-driven whole-body 3D Gaussian talking avatar with video diffusion distillation. 本地 synthesis:
/Users/tangwen/Org/roam/raw/audioavatar-2026/synthesis.md - 数字人系列:算力、训练资源与 Benchmark 总结。站内专题