EMO2
音频驱动数字人最常见的起点是嘴:语音和唇形有强同步关系,所以 talking head 可以把问题收缩为口型、表情和头动。但一旦画面扩展到半身或上半身,手势就成为新的难点。手势并不像嘴型那样逐音素对齐,它表达的是强调、节奏、意图和情绪;同时手部结构复杂、遮挡频繁、错误极其显眼。EMO2 把这个问题重新表述为:不要让音频直接预测所有身体关节,而是先预测最能表达意图的 end-effector,也就是双手。
这个想法借用了机器人和动画里的直觉:如果知道末端执行器要去哪里,身体其它关节可以围绕这个目标协同调整。人说话时,手经常承担“指出重点、划分节奏、表达情绪”的末端角色。EMO2 因此先生成手部运动,再让 ReferenceNet 视频扩散模型利用图像先验完成胳膊、躯干、脸部和整体画面的协调。论文把这个过程称为 pixel prior inverse kinematics:不是显式求解骨骼 IK,而是让预训练视频生成器在像素空间里学会“身体应该如何跟随手”。#Wang-et-al.-2025-EMO2
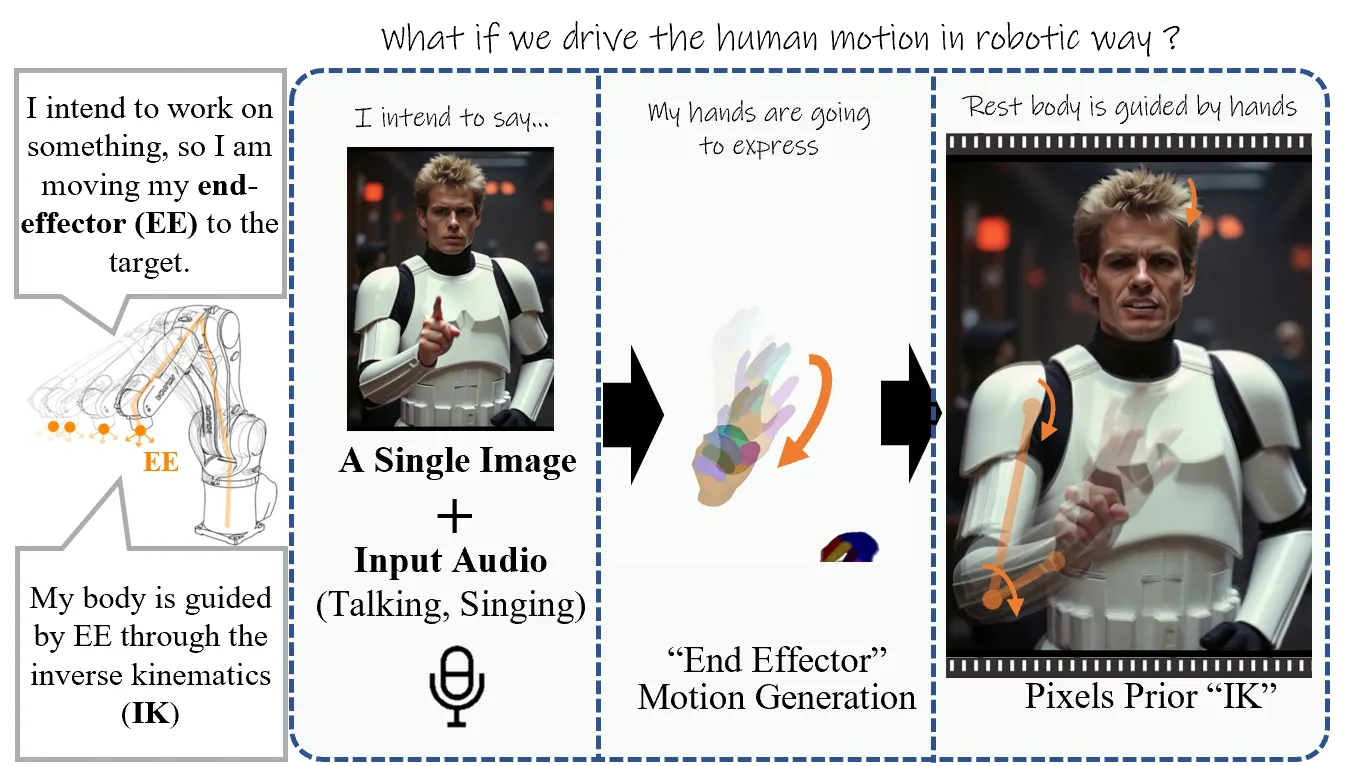
它和 ChatAnyone 的差别
ChatAnyone 同样关注上半身与手,但它的目标更偏实时工程:低维 motion diffusion 负责生成控制,warping GAN 负责 30 FPS 合成。EMO2 的目标不是实时,而是解释一种更强的手势建模原则:手部本身是语义驱动的末端表示,应该先被生成,再作为视频扩散的主控制信号。两者都使用 MANO,但 ChatAnyone 更像“用 MANO 给生成器补手部结构”,EMO2 更像“把 MANO 作为动作生成的主舞台”。
EMO2 第一阶段是 hand motion diffusion。模型从音频特征出发,生成双手 MANO 系数序列。论文使用 Wav2vec 提取音频嵌入,通过 cross-attention 注入 DiT;风格和速度嵌入加到 timestep 上;为了保持时序平滑,还会拼接前 12 帧运动作为历史条件。输出被 padding 到 300 帧,用于支持任意长度生成。#Wang-et-al.-2025-EMO2
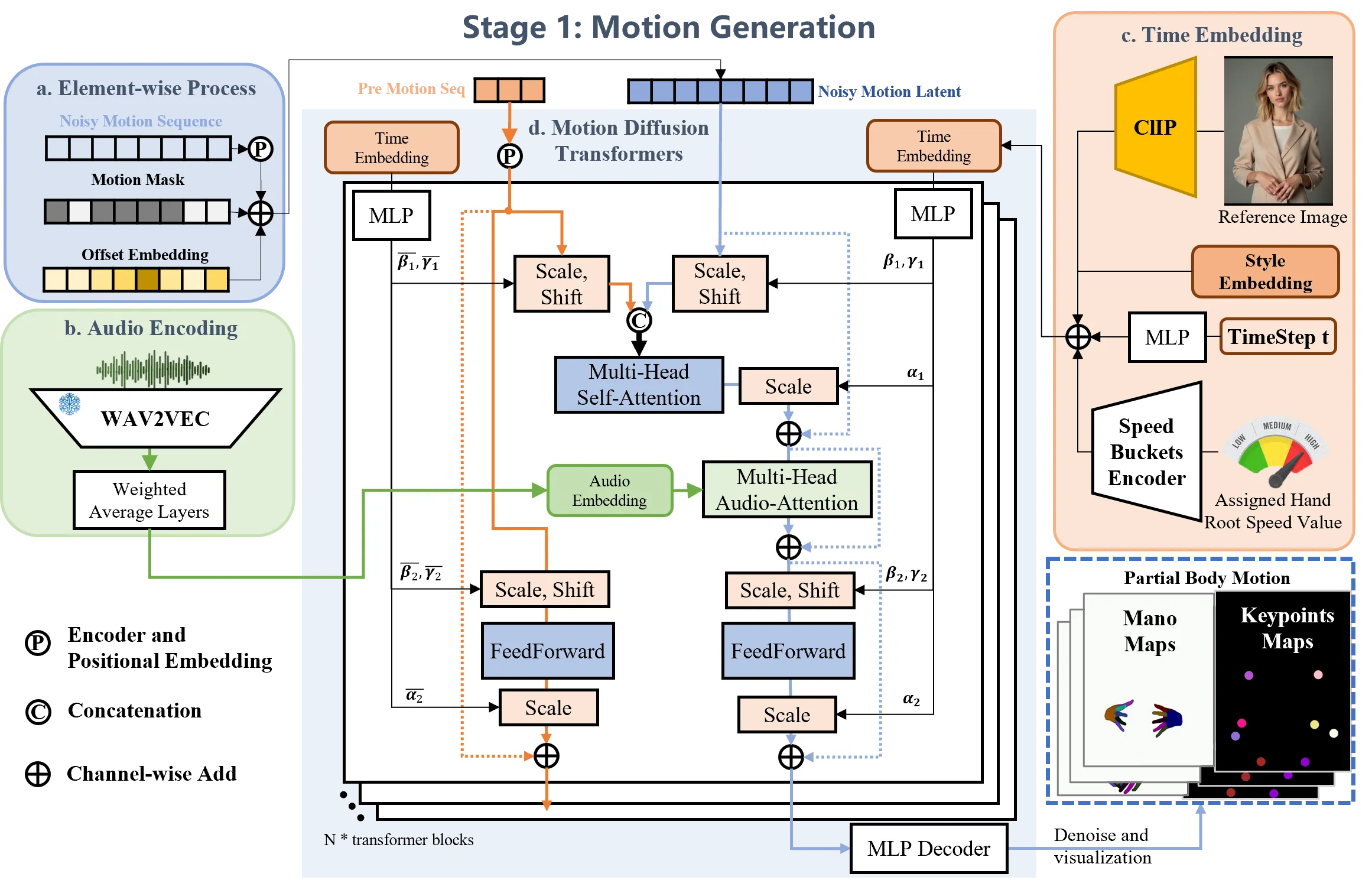
双手 MANO 表示
每只手由 48 维关节旋转和 3 维平移描述;EMO2 将 axis-angle 旋转转成 quaternion 后,双手合计形成 134 维运动表示。这个表示比 2D hand keypoints 更接近可控动画参数,也比完整 SMPL 身体姿态更聚焦于手势语义。#Wang-et-al.-2025-EMO2
运动扩散目标
这里 \(x_t\) 是加噪后的 MANO motion,\(c\) 包含音频、风格、速度、历史运动和参考图上下文。这个目标让模型学习“某段语音最可能对应什么手部节奏、幅度和轨迹”。#Wang-et-al.-2025-EMO2
论文还提供了风格和幅度控制:style embedding 区分说话、唱歌或 gesture dance;speed/amplitude bucket 控制手势速度和幅度;可选 CLIP 图像嵌入帮助模型理解参考图中的物体上下文,例如吉他或麦克风。这说明 EMO2 不是只做唇形同步,而是把手势看成一个可以受场景、风格和语音共同影响的运动过程。
第二阶段把 MANO 手部运动变成最终视频。EMO2 使用带 AnimateDiff temporal modules 的 denoising 2D-UNet,并配一个 ReferenceNet 分支编码参考图和 motion frames,以保持角色身份。Stage 1 生成的 MANO maps、额外身体 keypoint maps 和音频特征被注入 latent features,模型据此生成脸、身体、手和背景一致的 co-speech video。#Wang-et-al.-2025-EMO2
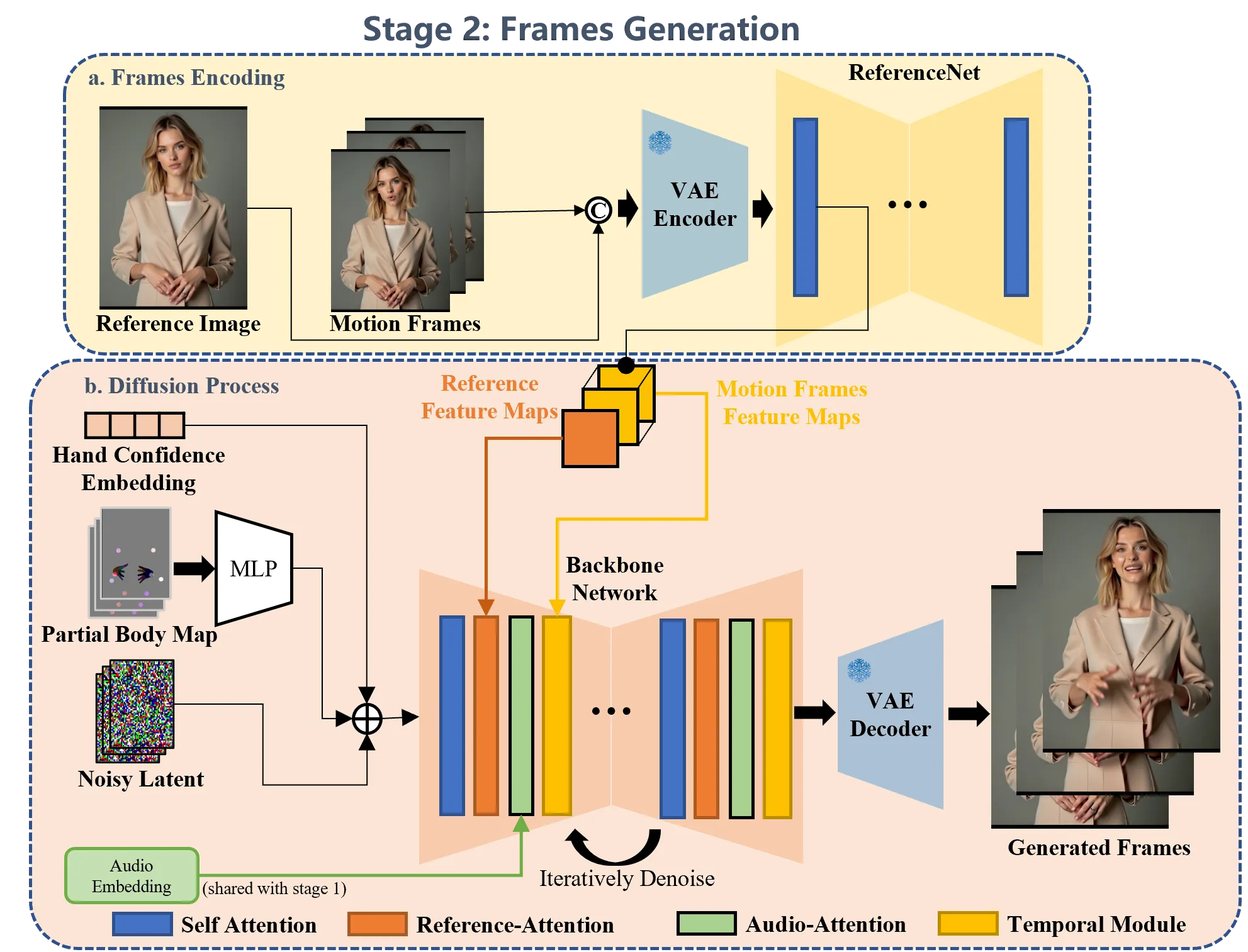
flowchart TD A["Reference image"] --> B["ReferenceNet identity features"] C["Audio"] --> D["Stage 1: MANO hand motion diffusion"] D --> E["MANO maps"] F["Body keypoint maps"] --> G["Motion guidance"] E --> G B --> H["Denoising UNet + AnimateDiff modules"] G --> H C --> H H --> I["Co-speech upper-body avatar video"]
Pixel prior IK 不是严格 IK
EMO2 的 pixel prior IK 是一个很有启发的说法,但不能把它理解成几何上有保证的逆运动学求解。传统 IK 会显式约束骨骼长度、关节角度和末端位置;EMO2 依赖的是视频生成器从大量上半身视频中学到的人体先验。换句话说,它相信模型见过足够多“手这样动时,肩膀和躯干应该怎样配合”的例子,于是可以在像素层面补全合理身体。这个设计很灵活,但也意味着极端手势、遮挡、持物和身体结构异常时仍可能失败。
Pose discriminator loss
其中 \(H\) 是真实身体 heatmap,\(\hat{H}\) 是由一阶段 latent 预测送入 ResNet pose discriminator 后得到的身体关键点/肢体 heatmap。这个辅助目标用于鼓励视频 latent 保留更合理的身体姿态结构。#Wang-et-al.-2025-EMO2
EMO2 的训练成本明显高于实时路线。Stage 1 手部运动模型使用 24 个 DiT blocks、hidden size 512,从零训练 400K steps,batch size 8,使用 1 张 A100。Stage 2 分成 image stage 和 audio-video stage:前者使用 704×512 crop、batch size 32、4 张 A100、100K steps;后者训练 24-frame clips、12 motion frames、冻结 ReferenceNet、batch size 4、4 张 A100、100K steps。训练数据包括 MOSEI、AVSPEECH 半身语音场景以及互联网视频,总时长约 275 小时。论文没有披露推理 FPS 或端到端 latency。#Wang-et-al.-2025-EMO2
| 维度 | 论文披露信息 | 解读 |
|---|---|---|
| Stage 1 运动模型 | 24 DiT blocks,hidden size 512,1×A100,batch size 8,400K steps | 手部运动生成是独立重训练模型,不是轻量后处理 |
| Stage 2 image stage | 704×512,batch size 32,4×A100,100K steps,lr \(10^{-5}\) | 先学参考图到目标帧的身份与外观保持 |
| Stage 2 audio-video stage | 24 frames,12 motion frames,batch size 4,4×A100,100K steps,lr \(10^{-5}\) | 再学习音频、MANO 和身体关键点共同驱动的视频时序 |
| 运动评测 | Talkshow:DIV 0.1345,BA 0.7626,PCK 0.8126,FGD 0.0373 | 证明手部运动分布、节拍一致性和关键点质量,而不只是视频画质 |
| 视频评测 | FID 27.28,FVD 129.41,SSIM 0.662,PSNR 64.62,Sync-C 4.58,HKC 0.553,HKV 0.198,CSIM 0.650 | 覆盖画质、视频分布、同步、手部一致性、身份保持等多个维度 |
| 推理效率 | 原文未明确给出 FPS / latency | 不能把 EMO2 写成实时方法;它更像质量与手势建模优先路线 |
EMO2 的训练配置与关键实验

这组实验对数字人评估很有参考意义。上半身 avatar 不能只看 FID/FVD,因为画面分布距离无法说明手是否跟语音节奏一致、身份是否保持、动作是否自然,也无法说明系统能否实时交互。EMO2 同时使用 motion metrics、Sync-C、HKC/HKV 和 CSIM,说明它关注的不是“视频像不像训练集”,而是“手、嘴、身份和身体是否协同”。
EMO2 应该放在“音频驱动的上半身手势 avatar”路线,而不是传统 talking head,也不是 full-body 3D avatar。它不输出可重用 3D asset,也不建模腿部、场景空间或可换视角渲染;它解决的是单图角色在半身画面里如何随语音产生更可信的手势和身体配合。与 ChatAnyone 相比,它不强调实时;与 OmniAvatar / HunyuanVideo-Avatar 相比,它不追求 full-frame 大模型通用生成;与 One Shot, One Talk 相比,它不是 3DGS-mesh 可渲染资产,而是 2D 视频扩散生成。
| 路线 | 代表方法 | 核心控制 | 优势 | 边界 |
|---|---|---|---|---|
| End-effector gesture avatar | EMO2 | MANO hand motion + pixel prior IK | 手势语义清晰,强调手带动身体 | 非实时,非 3D asset |
| Realtime upper-body avatar | ChatAnyone | face/body keypoints + MANO injection | 30 FPS 级实时,工程闭环强 | 手是结构补强,不是主运动空间 |
| Full-frame diffusion avatar | OmniAvatar / HunyuanVideo-Avatar | video latent audio injection / mask-localized attention | 场景、人物、情绪与多人控制更强 | 推理慢,实时交互困难 |
| 3D renderable avatar | One Shot, One Talk / AudioAvatar | SMPL-X、3DGS、mesh 或 Gaussian motion | 可重用资产与渲染控制更强 | 注册、训练、几何一致性成本高 |
EMO2 与邻近方法的路线边界

读完这篇论文应记住什么
- 任务边界:EMO2 是 upper-body / hand gesture avatar,不是完整 full-body 或 3D avatar。
- 核心思想:先生成手这个 end-effector,再让视频生成器补全身体。
- 技术路线:Stage 1 用 DiT 生成 MANO motion;Stage 2 用 ReferenceNet + AnimateDiff 风格视频扩散生成画面。
- 工程取舍:它强调手势质量和设计原则,论文未披露实时推理速度,不能归为实时系统。
参考来源
- Wang et al. (2025). EMO2: End-Effector Guided Audio-Driven Avatar Video Generation. arXiv:2501.10687