CliffordNet
如果你拆开任何一个现代视觉骨干网络——不管是 ViT、ConvNeXt 还是 MobileNetV2——你会看到同一个模式不断重复:空间混合器(Attention 或 Conv)后面跟一个通道混合器(FFN/MLP)。Yu et al. 在 MetaFormer #Yu et al., 2022 中把这个模式抽象为通用架构模板,并证明:只要保持这个模板,具体 mixer 长什么样不太重要。
这套范式已经统治了视觉骨干网络设计五年。但有没有人想过——为什么需要两个分开的模块?
作者 Zhongping Ji(杭州电子科技大学)在 CliffordNet #Ji, 2026 中给出了一个激进的回答:如果特征交互足够“代数完备”,那么标准 FFN 完全可以删除。他提出用 Clifford 几何积 $uv = u \cdot v + u \wedge v$ 统一替代 Attention 和 FFN 的功能,在 CIFAR-100 上以 1.4M 参数追平了 11.2M 的 ResNet-18——而整个网络 没有一个 FFN 层。
这篇论文最引人注目的实验数据是:如果把 ViT-Tiny 的 MLP ratio 压缩到 1.0(和 CliffordNet-Lite 同参数量),精度会直接崩溃到 65.87%——而 CliffordNet-Lite 在同一参数预算下达到 79.05%。这不是微小差异,而是 13 个百分点的鸿沟。
CliffordNet 揭示了一个被忽视的可能性:全局理解可以从严密的局部处理中涌现。你不需要 $O(N^2)$ 的全局 attention 来捕获长距离依赖,只需要用正确的数学工具把局部邻域的信息榨干。
Attention 的信息压缩
标准 Self-Attention 的核心运算是 $\mathbf{q}_i^\top \mathbf{k}_j$——两个 $D$ 维向量被压缩成一个标量。这个标量告诉你它们有多“相似”,但完全丢弃了它们在 $\mathbb{R}^D$ 中张成的有向平面(即两个向量如何正交、如何旋转)。
从 Clifford 代数的视角看,两个向量的完整交互应该是:
标准神经网络只用了第一项(内积),完全丢弃了第二项(外积)。论文把这种缺失称为“代数不完备”。
代数完备性(Algebraic Completeness)
一个架构如果在特征交互中显式同时建模标量相干项(Inner,度量对齐/相似度)和双向量结构项(Wedge,度量正交性/变化方向),则称其在该几何积下“代数完备”。标准 Attention、CNN、SSM 都只使用标量交互——它们都是代数不完备的。
论文引用了 Clifford 本人在 1878 年的洞见:
“Hamilton 的系统(四元数/内积)和 Grassmann 的系统(外积代数)不仅彼此兼容,它们实际上是一个更大整体的组成部分。”
— William Kingdon Clifford, 1878
19 世纪的代数学家已经看到内积和外积是同一枚硬币的两面。但 150 年后的深度学习——至少在视觉骨干网络设计中——只翻了正面。
一个崩溃实验
论文设计了一个巧妙的对照实验来验证这个假说。如果把 ViT-Tiny 的 FFN 压缩到和 CliffordNet-Lite 相同的参数预算(mlp\_ratio=1.0),ViT-Tiny 的精度从正常水平暴跌到 65.87% #Touvron et al., 2021。而 CliffordNet-Lite 在同样 2.6M 参数下保持 79.05%。
CliffordNet Block 的完整前向流保持 2D 特征图结构——不展平为 1D 序列。这是它与 ViT(flatten)和 Mamba(scan)的关键架构分歧。
flowchart TD
X["输入 X_{l-1}
B × H × W × C"] --> LN["LayerNorm"]
LN --> DS
subgraph DS["Dual-Stream 生成"]
D1["Detail Stream
Z_det = Linear(X)"]
D2["Context Stream
Z_ctx = SiLU(BN(DWConv(X)))"]
end
DS --> CM{"Context Mode"}
CM -->|"Differential"| DIFF["C = Z_ctx - Z_det ≈ ΔH"]
CM -->|"Absolute"| ABS["C = Z_ctx"]
DIFF --> SR
ABS --> SR
subgraph SR["Sparse Rolling Interaction"]
S1["For s in S:"]
S2["W^(s) = Z_det·T_s(C) - C·T_s(Z_det)
Wedge 分量 (反对称)"]
S3["D^(s) = SiLU(Z_det·T_s(C))
Inner 分量 (对称)"]
S1 --> S2 --> S3
end
SR --> CAT["Concat + Linear_proj
→ G_feat"]
CAT --> GGR
subgraph GGR["Gated Geometric Residual"]
G1["α = σ(Linear([X_ln, G_feat]))
门控"]
G2["H_mix = SiLU(X_ln) + α ⊙ G_feat"]
G1 --> G2
end
GGR --> OUT["X_l = X_{l-1} + γ ⊙ H_mix
无 FFN"]
Dual-Stream:状态与环境的对偶
CliffordNet 从同一个 LayerNorm 输出 $X_{ln}$ 生成两条互补流:
- Detail Stream:$Z_{det} = \text{Linear}(X_{ln})$——1×1 卷积保留高频特征本体
- Context Stream:$Z_{ctx} = \text{SiLU}(\text{BN}(\text{DWConv}_{3\times3}(\text{DWConv}_{3\times3}(X_{ln}))))$——两层 3×3 深度卷积聚合局部邻域
这个设计的灵感来自物理中的“粒子-场”对偶:$H$ 是粒子状态,$C(H)$ 是它周围的场。两层堆叠的 DWConv 等效感受野为 5×5,模拟了 Laplacian 算子的连续扩散性质。
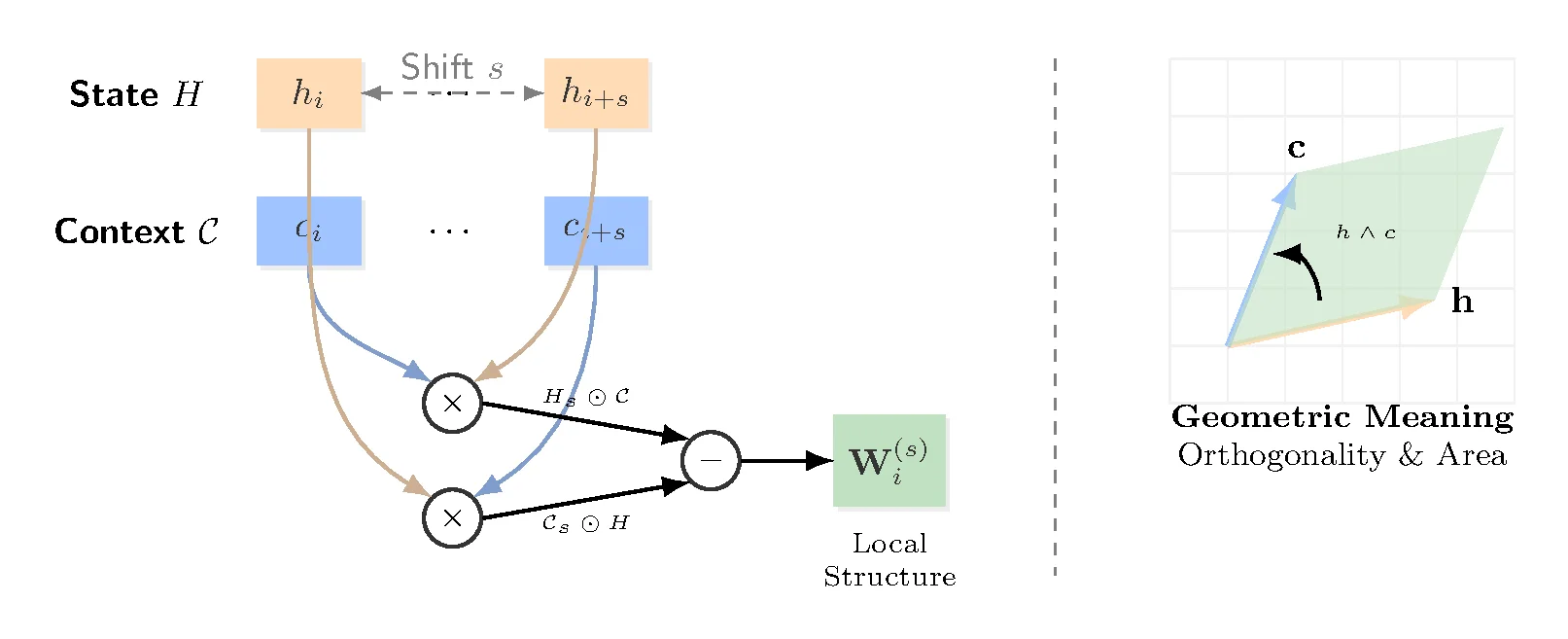
Sparse Rolling:如何用 O(|S|D) 近似 O(D²)
现在到了论文最核心的工程创新。如果朴素地计算所有 $\binom{D}{2}$ 个 wedge 系数和 $D$ 个 inner 系数,复杂度是 $O(D^2)$——对高维特征图不可接受。
CliffordNet 的解法:循环位移采样。对通道维度做位移 $s$(torch.roll),然后计算两个分量:
其中 $\mathcal{T}_s(\cdot)$ 是通道维度的循环位移 $s$,$\odot$ 是 Hadamard 积。
位移集 $\mathcal{S}$ 采用对数间距:$\{1, 2, 4, 8, 16, \ldots\}$。Nano 变体只用 2 个 shift,Lite 用 5 个。从矩阵视角看,这相当于从 $D \times D$ 稠密相关矩阵中只采样特定对角线——论文称为 Structured Circulant Sparsity。
每个 shift 上做 $|\mathcal{S}| \cdot D$ 量级乘法,总复杂度从 $O(D^2)$ 降到 $O(|\mathcal{S}|D)$。
Gated Geometric Residual:稳定的数值求解器
论文把网络深度视为连续 ODE 的离散时间步。朴素 Euler 离散化等价于标准残差连接:$H_l = H_{l-1} + \Delta t \cdot \mathcal{F}$。但作者发现直接加几何更新会引入高频噪声,于是设计了增强版:
其中 $\alpha = \sigma(\text{Linear}([X_{ln}, G_{feat}]))$ 是门控,$\gamma$ 是 LayerScale 可学习步长。这里 $\text{SiLU}(X_{ln})$ 不是激活函数,而是状态预条件子——抑制负值/背景噪声后再注入几何更新,相当于一个带预条件子的稳定积分器。
Clifford 几何积本身包含乘法二次项(如 $u_i v_j - v_i u_j$),结合 GGR 的门控与 SiLU 激活,单层已具备足够函数逼近能力。论文称这种性质为 “Internalized Non-linearity”——非线性被内化到交互中,外置 FFN 自然冗余。
论文选择 CIFAR-100 作为唯一评测平台。作者在文中明确承认这是 “proof-of-concept”——CIFAR-100 的类内多样性和数据稀疏性(每类仅 500 张训练图)对轻量模型的架构效率敏感,适合做架构验证。
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 数据集 | CIFAR-100 (50K train / 10K test) | ✅ 论文披露 |
| 输入分辨率 | 32 × 32 | ✅ 论文披露 |
| Patch size | 2(→ 16×16 特征图) | ✅ 论文披露 |
| Epochs | 200 | ✅ 论文披露 |
| 优化器 | AdamW(所有模型统一) | ✅ 论文披露 |
| 学习率调度 | Cosine Annealing,无 warm-up | ✅ 论文披露 |
| 数据增强 | AutoAugment + Random Erasing | ✅ 论文披露 |
| DropPath | 仅 CliffordNet 使用;CNN 基线不使用 | ✅ 论文披露 |
| 预训练 | 无(全部从零训练) | ✅ 论文披露 |
| GPU 型号与数量 | — | ❌ 未披露 |
| Batch size | — | ❌ 未披露 |
| 具体学习率 | — | ❌ 未披露 |
| Weight decay | — | ❌ 未披露 |
一个值得注意的公平性处理:CNN 基线(ResNet-18、MobileNetV2、ShuffleNetV2)不使用 DropPath,因为它们的 canonical 训练协议依赖 weight decay + 数据增强。CliffordNet 则使用 DropPath 来正则化更深的同构堆叠。这种区分确保了比较的公平性。
模型变体配置
| 变体 | 参数量 | Shifts (S) | cli_mode | MLP Ratio |
|---|---|---|---|---|
| CAN-Nano | 1.4M | 2 ([1,2]) | full | 0.0 |
| CAN-Lite | 2.6M | 5 ([1,2,4,8,16]) | full | 0.0 |
| CAN-32 | 4.8M | 3 | full | 0.0 |
| CAN-64 | 8.6M | 5 | inner | 0.0 |
cli_mode='inner' 而非 full。这意味着最大的变体只需要标量相干性(Inner Product),不再需要 Wedge 的额外结构信息——大容量模型自身的参数足以隐式编码结构关系。论文给出了 Algorithm 1 完整伪代码。以下是与 PyTorch 实现的逐行对应:
Input: X_{l-1} (B, H, W, C)
1. X_ln = LayerNorm(X_{l-1})
2. Dual-Stream:
Z_det = Linear_det(X_ln)
Z_ctx = SiLU(BN(DWConv(X_ln)))
Differential Mode: Z_ctx = Z_ctx - Z_det
3. Sparse Rolling (for s in S):
Z_d = Roll(Z_det, s)
Z_c = Roll(Z_ctx, s)
W = Z_det * Z_c - Z_ctx * Z_d (Wedge)
D = SiLU(Z_det * Z_c) (Inner)
4. Concat + Project:
G_feat = Linear_proj(Cat(F_list))
5. Gated Geometric Residual:
α = Sigmoid(Linear_gate(Cat[X_ln, G_feat]))
H_mix = SiLU(X_ln) + α * G_feat
6. Output (No FFN!):
X_l = X_{l-1} + DropPath(γ * H_mix)# 核心交互层 (来自 model.py)
class CliffordInteraction(nn.Module):
def forward(self, z1, z2):
C = z2 - z1 # Differential mode
feats = []
for s in self.shifts:
C_shifted = torch.roll(C, shifts=s, dims=1)
if self.cli_mode in ['wedge', 'full']:
z1_shifted = torch.roll(z1, shifts=s, dims=1)
wedge = z1 * C_shifted - C * z1_shifted
feats.append(wedge)
if self.cli_mode in ['inner', 'full']:
inner = self.act(z1 * C_shifted)
feats.append(inner)
return self.proj_(torch.cat(feats, dim=1))整个 Block 没有任何 FFN/MLP 层。特征从输入到输出只经过:LayerNorm → Dual-Stream → Rolling Interaction → GGR → 残差连接。这就是论文所说的 “No-FFN” 架构。
从 GitHub 源码可以看到,作者还提供了可选的 CUDA 加速核 clifford_thrust,在导入成功时自动替换 PyTorch 原生的 torch.roll 实现。
主实验:CIFAR-100 全档位对比
| 模型 | 参数量 | FFN? | Top-1 Acc | 训练时间(min) |
|---|---|---|---|---|
| Nano Scale (~1.5M) | ||||
| ShuffleNetV2 1.0× | 1.4M | Yes | 74.60% | 66.2 |
| CliffordNet-Nano | 1.4M | No | 77.82% | 79.9 |
| Tiny Scale (~2.5M) | ||||
| MobileNetV2 | 2.3M | Yes | 70.90% | 64.5 |
| ShuffleNetV2 1.5× | 2.6M | Yes | 75.95% | — |
| ViT-Tiny (ratio=1.0) | 2.7M | Yes | 65.87% | 149.9 |
| CliffordNet-Lite | 2.6M | No | 79.05% | 125.0 |
| Small Scale (>3M) | ||||
| ResNet-18 | 11.2M | — | 76.75% | — |
| ResNet-50 | 23.7M | — | 79.14% | — |
| DenseNet-121 | 7.0M | — | 80.20% | — |
| CliffordNet-32 | 4.8M | No | 81.42% | — |
| CliffordNet-64 | 8.6M | No | 82.46% | — |

消融实验:每个组件贡献多少
| 变体 | Shifts | 参数量 | Top-1 Acc | 变化 |
|---|---|---|---|---|
| CAN-Nano (abs) | 2 | 1.43M | 76.41% | 基准 |
| CAN-Nano (diff) | 2 | 1.43M | 77.82% | +1.41%(Differential Mode) |
| CAN-Lite (abs) | 5 | 2.61M | 77.63% | +1.21%(更多 shifts) |
| CAN-Lite (diff) | 5 | 2.61M | 79.05% | +1.42%(Differential) |
| CAN-Nano + gFFN-G | 2 | 2.22M | 78.22% | +0.40%(加全局上下文) |
| CAN-Lite + gFFN-G | 5 | 3.40M | 79.57% | +0.52% |
Differential Mode(离散 Laplacian / 高通滤波)一致优于 Absolute Mode 约 1.4%。添加全局上下文 gFFN-G 只带来 0.4-0.5% 的边际收益——No-FFN 变体已经足够强。
组件分析:Inner vs Wedge
这是最有理论趣味的消融。在相同设置下($\mathcal{S}=\{1,2,4,8,16\}$,Differential Mode)分别测试只用 Inner、只用 Wedge、以及完整 Clifford 积:
| 交互变体 | 代数类型 | 对角能量 | Top-1 Acc |
|---|---|---|---|
| Inner-Only | 对称 | ✓ 有能量 | 78.17% |
| Wedge-Only | 反对称 | ✗ 无能量 | 77.76% |
| CliffordNet (Full) | 几何完备 | ✓ | 79.05% |

训练效率:torch.roll 的代价
| 模型 | PyTorch 原生 (min) | CUDA 加速后 (min) |
|---|---|---|
| CAN-Nano (2 shifts) | 79.9 | 57.64 |
| CAN-Lite (5 shifts) | 125.0 | 58.27 |
CUDA 加速后 Nano 和 Lite 训练时间几乎相同(57.64 vs 58.27 min),证明 bottleneck 完全在 geometric sampling density(shift 数量)而非网络深度。当前 PyTorch 原生 torch.roll 是 memory-bound 操作,论文预期 Triton kernel 可再提速 2-3×。
Reaction-Diffusion:Turing Pattern 的高维推广
论文最浪漫的理论类比来自数学生物学中的 Turing Pattern。Alan Turing 在 1952 年提出,生物体表面的复杂图案(斑马纹、豹斑)源于两种物质的相互作用:扩散(平滑化)和反应(局部非线性增强)。
CliffordNet 可以被解读为这一过程的高维推广:
- 各向异性扩散($H \cdot \mathcal{C}$,Inner 项):在特征与上下文对齐的区域平滑噪声,类似 coherence-based gating
- 几何反应($H \wedge \mathcal{C}$,Wedge 项):在特征正交于上下文的边界处产生“几何涡旋”,增强结构边界
这种视角解释了为什么 No-FFN 能 work:网络不是在做简单的线性变换,而是在通过级联的几何模式形成步骤把原始像素演化为结构化语义表示——就像自然界中复杂结构从简单规则中涌现一样。
局限性:坦诚的 Proof-of-Concept
数据集单一:仅 CIFAR-100,未在 ImageNet-1K 上验证。No-FFN 范式在大规模数据上是否成立仍存疑——作者自己提出了这个问题。
任务单一:仅图像分类,未涉及检测/分割/生成。O(N) 线性复杂度在高分辨率密集预测上的潜力只是理论推测。
序列化批评缺乏严格证明:CliffordNet 认为 cross-scan 破坏 2D 流形连续性,但 VMamba 的四方向扫描已部分缓解单一路径偏置。当前 CIFAR-100 结果支持有效性,尚不足以完全证明理论解释的因果性。
工程瓶颈:PyTorch 原生 torch.roll 是 memory-bound,实际训练速度比 MobileNetV2 慢 24%(未加速时)。Triton kernel 尚未公开。
单作者预印本:尚未被正式会议接收,缺乏大型实验室的交叉验证。
对视觉骨干网络设计的启发
即使不考虑直接采用 CliffordNet,这篇论文也提供了几个可操作的启发:
- FFN 的必要性值得质疑:如果你的空间交互层信息密度足够高(比如包含二阶非线性项),FFN 的 channel mixing 功能可能是冗余的。可以尝试在你的架构中逐步减少 FFN ratio,观察精度变化。
- 外积(Wedge)是被忽视的信息源:标准 Hadamard 积 $u \odot v$ 只捕获对称交互。添加一个反对称分支 $u \odot v_{shift} - v \odot u_{shift}$ 几乎不增加参数,但可以捕获通道间的结构关系。
- 循环位移是对角采样的高效替代:如果你需要建模通道间的关系矩阵但付不起 $O(D^2)$,对数间距的循环位移是一种 principled 的稀疏化策略。
论文列出了 11 条未来方向,其中最值得关注的是:(1) ImageNet 扩展验证 No-FFN 范式的可扩展性;(2) 解耦 Inner 和 Wedge 的采样拓扑 $\mathcal{S}_{dot} \neq \mathcal{S}_{wedge}$;(3) 高阶几何积(向量 × 双向量);(4) Triton kernel 工程化。GitHub 仓库(ParaMind2025/CAN,149 stars)已在论文之外扩展了医学分类实验(Kvasir-Dataset-v2、ISIC2018),其中金字塔变体 CAN-2 仅用 0.36M 参数即保持竞争力——这是论文未报告的极端轻量数据点。
参考来源
- Ji, Z. (2026). CliffordNet: All You Need is Geometric Algebra. arXiv:2601.06793 · GitHub 代码
- Yu, W. et al. (2022). MetaFormer Is Actually What You Need for Vision. CVPR 2022. arXiv:2111.11418
- Touvron, H. et al. (2021). Training Data-Efficient Image Transformers & Distillation through Attention. ICML 2021. arXiv:2012.12877
- Brandstetter, J. et al. (2023). Clifford Neural Layers for PDE Modeling. ICLR 2023. arXiv:2209.04934
- Brandstetter, J. et al. (2023). Geometric Algebra Transformer. NeurIPS 2023. arXiv:2305.18415
- Ji, Z. (2025). RiemannFormer: A Framework for Attention in Curved Spaces. arXiv:2506.07405
- Gu, A. & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752
- Hestenes, D. (1966). Space-Time Algebra. Gordon and Breach.
- Dorst, L., Fontijne, D. & Mann, S. (2007). Geometric Algebra for Computer Science. Morgan Kaufmann.