ChatAnyone
传统 talking head 任务通常把注意力放在嘴型同步和头部姿态上:给一张头像和一段音频,生成一段会说话的视频。这个定义适合播报、客服和短视频口播,但一旦进入视频会议、直播互动或虚拟陪伴场景,头部之外的身体语言就开始变得重要。人说话时会点头、耸肩、挥手、比划重点;手势如果缺失,数字人会像贴在屏幕上的会动证件照;手势如果错乱,又会立刻破坏真实感。
ChatAnyone 把任务边界从 head-only talking animation 推到 upper-body portrait video generation。它的输入是一张角色图像和一段音频,输出可以是头部肖像视频,也可以是包含上半身和手势的 512×768 竖幅视频。论文特别强调 stylized portrait,即角色可以是非真实人脸、动漫风或夸张五官,这意味着系统不能完全依赖标准人脸模板,而需要把显式结构控制和隐式图像变形结合起来。#Zhang-et-al.-2025-ChatAnyone

实时性为什么改变模型设计
如果只追求单段视频质量,最自然的路线是端到端视频扩散:把参考图、音频、姿态或文本条件都塞进扩散模型,让模型直接生成 RGB 帧。但实时数字人有一个硬约束:每秒至少要生成几十帧,且最好在单张消费级显卡上运行。扩散模型在像素或视频 latent 里多步采样,通常很难直接满足这个要求。
ChatAnyone 因此采用两阶段拆分。第一阶段只在运动空间里扩散,生成脸部、身体和手的控制信号;第二阶段用 warping-based GAN 把参考图变形、补全并细化成最终视频帧。这个拆分的直觉很简单:运动序列的维度远低于像素视频,扩散模型适合在这里建模语音到动作的不确定性;而图像渲染需要高吞吐,GAN 与 image animation 框架更适合做实时推理。
ChatAnyone 的第一阶段是 hierarchical audio-to-motion diffusion。它没有试图从音频一次性预测所有控制量,而是先生成脸部运动,再把脸部运动、音频特征和源图外观特征一起作为条件,预测上半身 keypoints 与手部控制。这个顺序符合语义层级:语音首先强约束口型和表情,头部节奏又为肩颈、躯干和手势提供节拍参考。
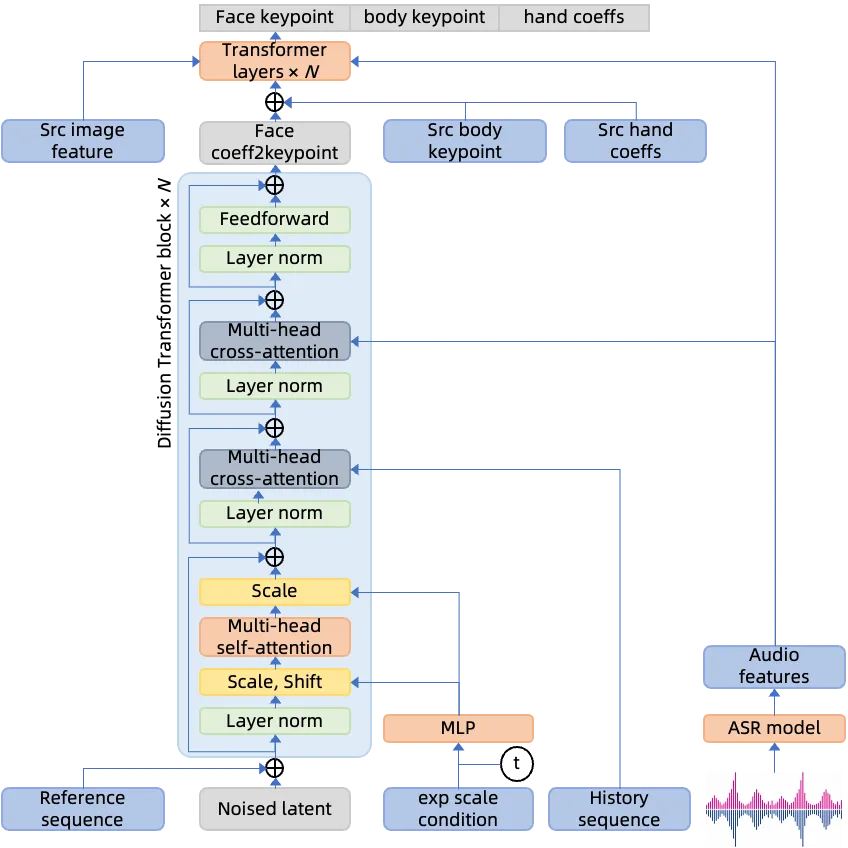
扩散运动预测目标
这里 \(x_t\) 是加噪后的运动表示,\(c\) 包含音频特征、历史运动和风格条件,\(\epsilon_\theta\) 预测噪声。这个目标不是直接生成图像,而是学习“给定音频时,合理的脸、身体和手部控制序列应该是什么”。#Zhang-et-al.-2025-ChatAnyone
显式与隐式控制的混合
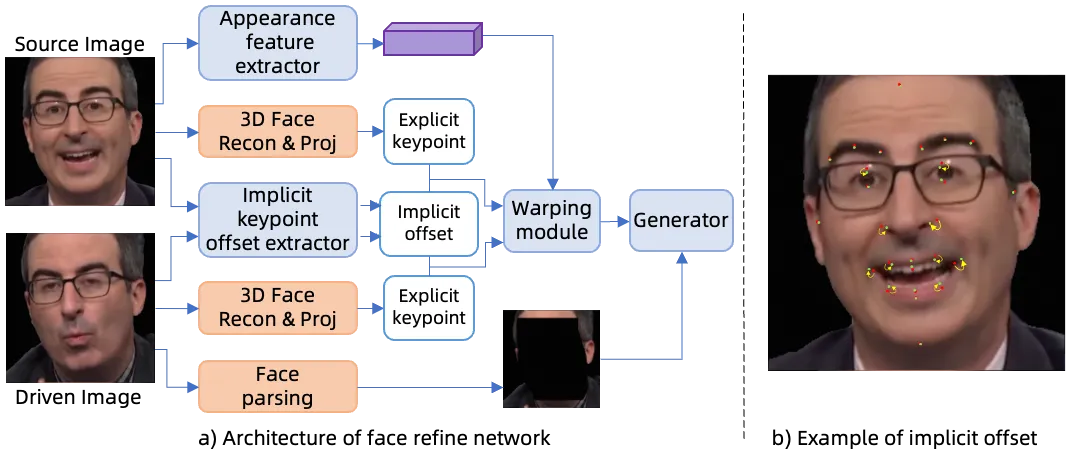
论文的控制表示不是单一的。脸部使用 3DMM / FaceVerse 风格的显式 3D keypoints,覆盖眼睛、嘴、眉毛和脸部轮廓;为了适配 stylized character,又额外预测隐式 keypoint offset,修正标准模板无法表达的夸张脸型。身体部分则更接近 LivePortrait 一类隐式 keypoint image animation,身体旋转被简化,主要学习平面运动、尺度和位移。手部使用 MANO 参数渲染成手部图像,再注入生成器。
这个混合设计的价值在于避免两种极端:纯显式模型可控但很难覆盖风格化角色;纯隐式模型灵活但难以编辑、难以保证嘴和手的结构。ChatAnyone 把“需要强结构的地方”显式化,把“风格差异很大的地方”留给隐式偏移和图像生成器。
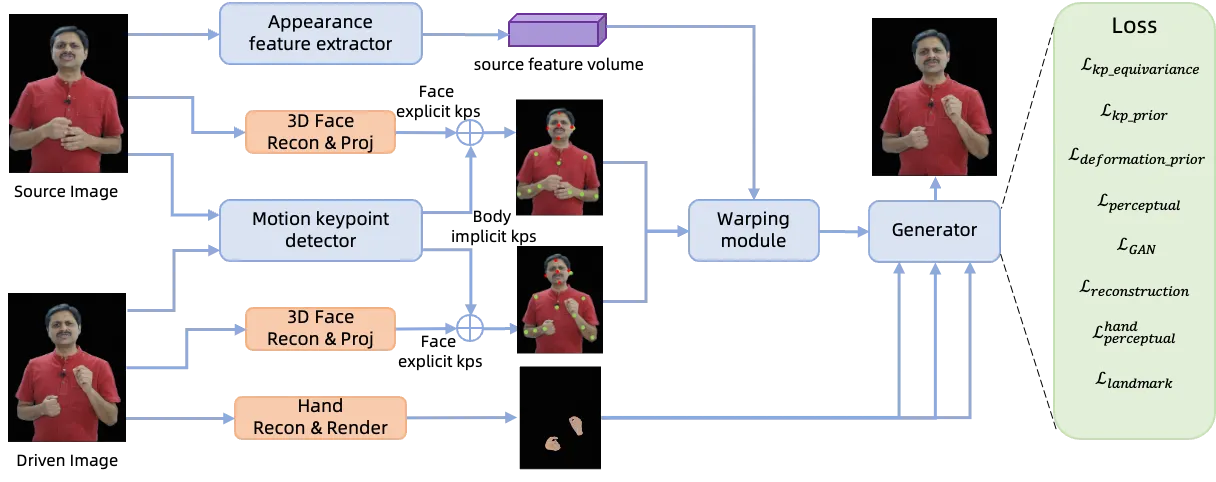
第二阶段负责把控制信号变成图像。ChatAnyone 使用 appearance feature extractor、keypoint detector、warping field estimator 和 generator 组成的 image animation 框架:先从源图抽取外观特征,再根据源/驱动 keypoints 估计变形场,把源特征扭曲到目标姿态,最后由生成器解码成视频帧。相比扩散视频模型,这条路线的优势是推理快、时序稳定、工程上更容易做到实时。
flowchart TD A["Reference image"] --> B["Appearance feature extractor"] C["Audio"] --> D["Hierarchical motion diffusion"] D --> E["Head keypoints + body keypoints + MANO hand controls"] B --> F["Warping field estimator"] E --> F F --> G["Warped source features"] E --> H["MANO hand rendering"] G --> I["Generator + AdaIN hand injection"] H --> I I --> J["512×768 upper-body portrait video"]
为什么手要单独注入
上半身数字人最容易露馅的部位通常不是脸,而是手。手指细、遮挡多、形变范围大,只用稀疏 keypoints 很难让生成器恢复清晰结构。ChatAnyone 的做法是把 MANO 系数渲染成手部图像,并通过 AdaIN 在多尺度生成特征中注入:
MANO hand injection
其中 \(f\) 是生成器中间特征,\(I_{hand}\) 是由 MANO 参数渲染出的手部控制图。这个设计等于告诉生成器:“这里不仅要有一只手,而且手的形状和朝向应该像这张控制图。”#Zhang-et-al.-2025-ChatAnyone
ChatAnyone 使用约 20,000 段清洗后的 YouTube talkshow clips,总时长约 30 小时,帧率为 30 FPS。音频到运动模型中,脸部系数模型是 6 层 diffusion transformer,上半身运动模型是 2 层 transformer,训练使用 1 张 A100、batch size 16、100K steps。视频生成部分输出上半身 512×768 或头部 512×512,使用 8 张 A100 训练 7 天,batch size 32。#Zhang-et-al.-2025-ChatAnyone
| 维度 | 论文披露信息 | 解读 |
|---|---|---|
| 训练数据 | 约 20K talkshow clips,30 小时,30 FPS | 更像面向演讲/访谈上半身场景的数据,而不是全身舞蹈或走路数据 |
| 运动模型 | 脸部 6 层 diffusion transformer;上半身 2 层 transformer | 扩散模型只处理低维 motion,因此推理负担可控 |
| 视频生成 | 8×A100,7 天,batch size 32,Adam lr \(10^{-4}\) | 主要训练成本在图像动画生成器,而不是运动扩散 |
| 上半身评测 | PSNR 24.88,SSIM 0.831,LPIPS 0.126,FID 5.505,FVD 33.349,CSIM 0.654,HKC 0.652 | 同时报告画质、视频分布、身份和手部关键点一致性,比只看 FID 更完整 |
| 速度 | 512×768 下表格报告 33 FPS,论文称 RTX 4090 上约 30 FPS | 这是它相对离线视频扩散 avatar 的主要竞争力 |
ChatAnyone 的关键实验与配置
论文还给出手部注入和风格迁移的消融。去掉 hand injection 后,手部清晰度和一致性会下降;去掉 style transfer 后,表达风格匹配明显变差。这些结果说明,上半身数字人的难点不是“让图像动起来”这么简单,而是不同身体区域需要不同的结构先验和控制入口。
ChatAnyone 不是完整 full-body avatar,也不是 3D 可渲染资产。它的范围是 2D portrait / upper-body avatar:适合视频会议、直播助手、客服形象和风格化角色互动;不适合需要腿部运动、全身空间位移、可换视角渲染或物理交互的场景。与 EMO2 相比,它更强调实时工程闭环;EMO2 更强调把手作为 end-effector 的概念和扩散视频质量。与 OmniAvatar / HunyuanVideo-Avatar 相比,它牺牲了一部分视频扩散大模型的生成能力,换来可部署的 FPS。
| 路线 | 代表方法 | 核心中间表示 | 优势 | 边界 |
|---|---|---|---|---|
| Realtime portrait / upper-body | ChatAnyone | 脸部 keypoints、身体隐式 keypoints、MANO 手部控制 | 30 FPS 级实时,上半身和手势可用 | 非 full-body,非 3D asset |
| Hand/end-effector diffusion | EMO2 | MANO hand motion + ReferenceNet video diffusion | 手势概念清晰,视频生成能力强 | 速度未披露,不是实时优先 |
| Full-frame diffusion avatar | OmniAvatar / HunyuanVideo-Avatar | 视频 latent + audio injection / face mask attention | 场景、人物和大幅运动生成能力强 | 推理慢,工程交互成本高 |
| Renderable 3D avatar | One Shot, One Talk | SMPL-X mesh + 3D Gaussian field | 最终得到可重用 3D avatar 表示 | 训练与注册复杂,音频同步评测不足 |
ChatAnyone 与邻近路线的边界

读完这篇论文应记住什么
- 任务边界:ChatAnyone 是 upper-body portrait avatar,不是 full-body avatar。
- 核心设计:低维 motion diffusion + 高效 warping GAN,是实时性的来源。
- 手部处理:MANO 渲染图通过 AdaIN 注入,比只用稀疏关键点更适合清晰手势。
- 工程取舍:它不是最通用的视频生成模型,但非常适合实时数字人产品链路。
参考来源
- Zhang et al. (2025). ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model. arXiv:2503.21144