Avatar Forcing
Talking Head 生成经历了从"唇形同步"到"全脸动画"再到"实时交互"三个明确阶段。Wav2Lip 开创了音频驱动唇形同步,SadTalker 引入 3DMM 实现全脸表情,VASA-1 和 FLOAT 在 motion latent space 中实现实时生成。然而,这些工作本质上都是单向的——给定音频驱动生成视频,avatar 无法对用户的行为做出反应。
Avatar Forcing 识别出实现真正交互式数字人面临的两个根本性挑战。
挑战一:因果约束下的实时生成
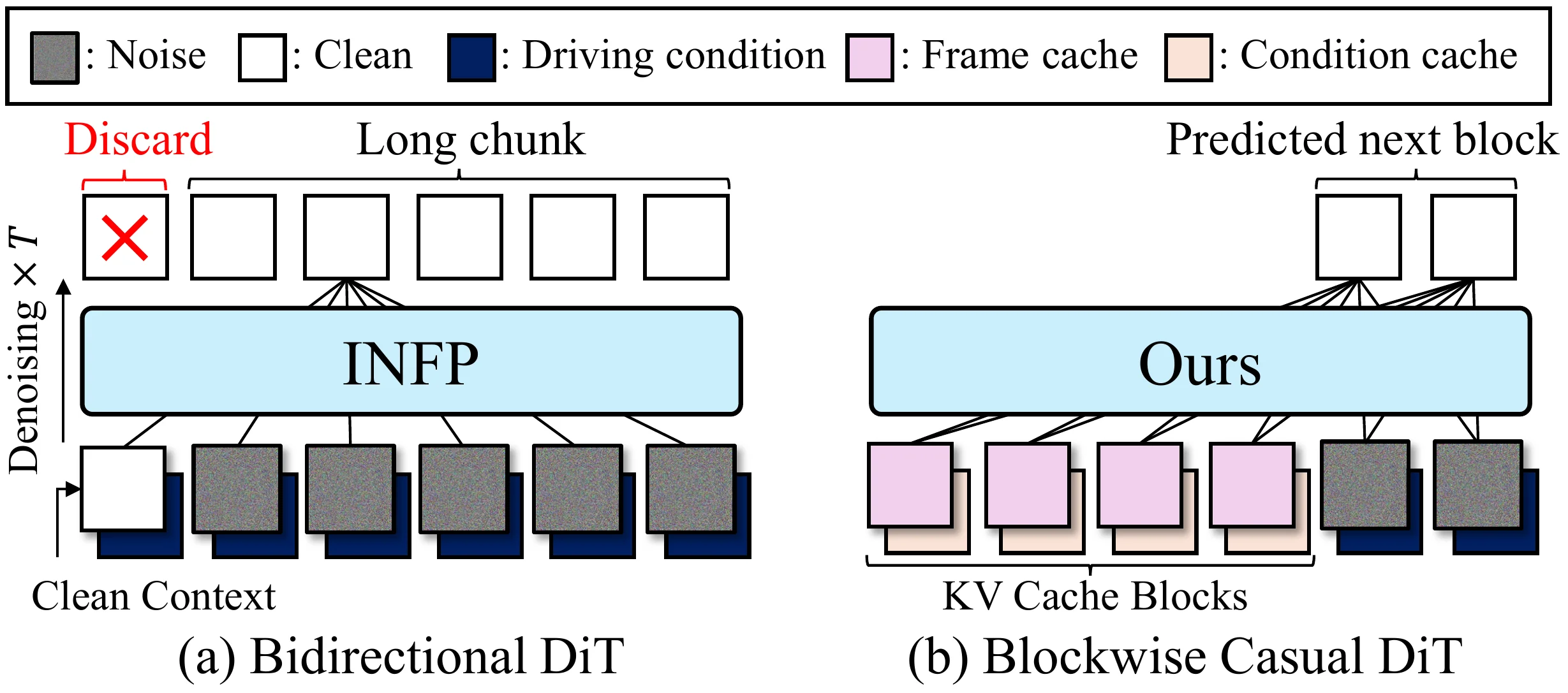
交互式 avatar 系统必须持续接收并响应用户的多模态信号(语音、头部运动、面部表情),这要求同时具备低推理时间和低延迟。INFP 虽然能在 motion latent space 中实现快速推理,但因为需要完整对话上下文(包括未来帧),延迟高达 3.4s。模型必须等待足够长的音频片段后才能生成运动,导致用户交互中的显著延迟。
挑战二:无标注数据下的表达性反应学习
人类交互中的表达性(expressiveness)本质上难以定义和标注。与唇形同步不同——唇形与音频有近乎确定性的对应关系——对用户行为的"正确"反应是高度模糊的一对多映射:同一个点头可以对应 avatar 的多种合理反应。
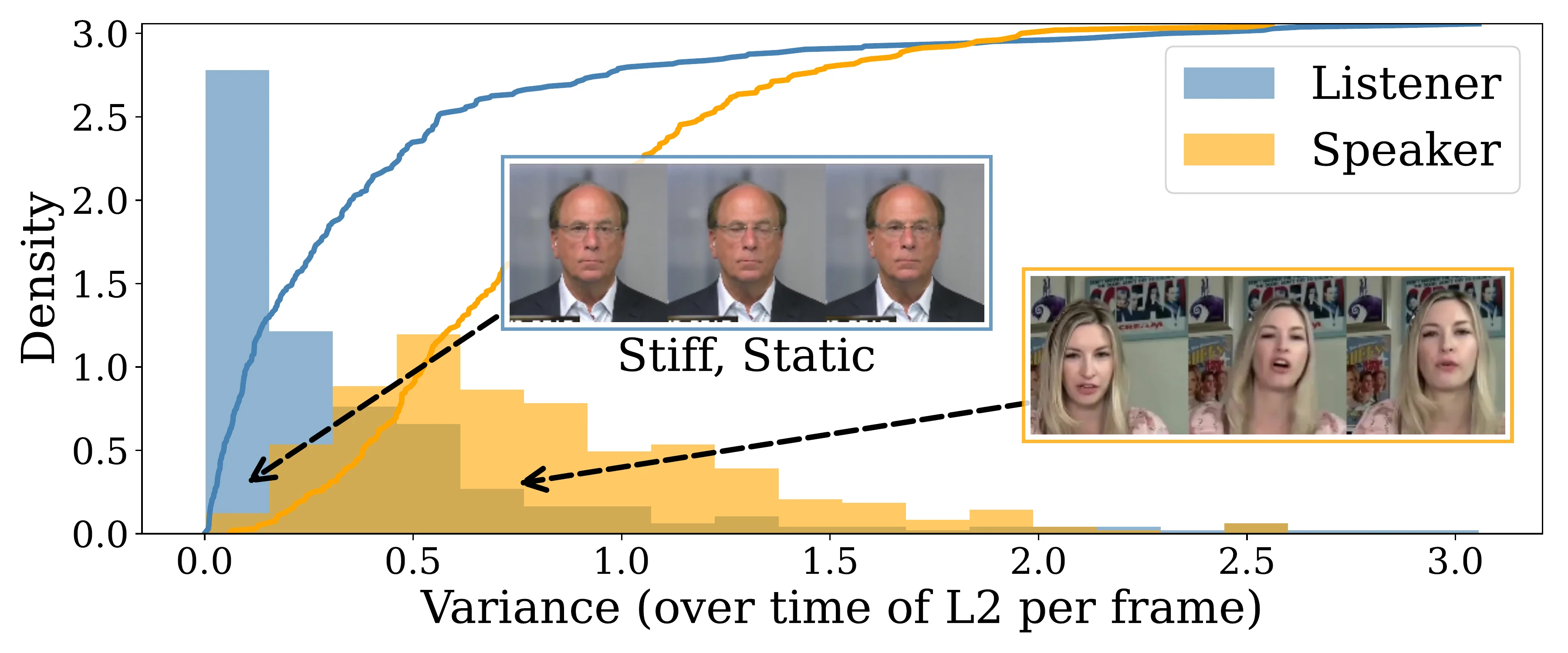
论文用量化数据证实了这一观察:在 ViCo 数据集中,listener 的 3DMM 表情方差远低于 speaker。这意味着训练数据本身就缺乏表达性,模型容易学到被动、僵硬的倾听行为。传统 DPO 需要人工标注的偏好对来解决这一问题,但标注成本高昂。Avatar Forcing 的关键洞察是:drop 用户条件 = 低表达性——仅以 avatar audio 为条件生成的运动天然缺乏交互性,可以作为 losing sample,无需额外标注。
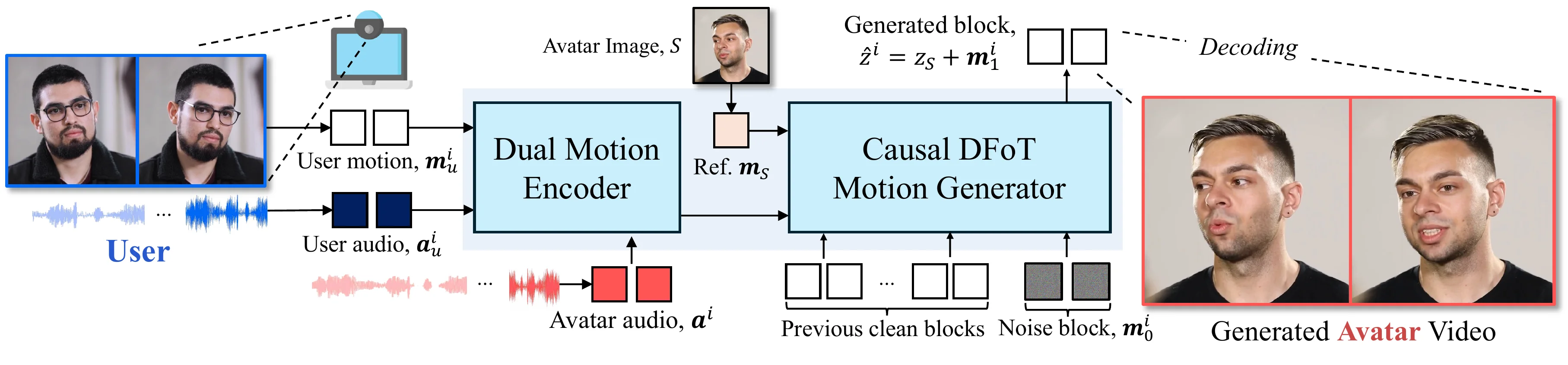
Avatar Forcing 的整体架构围绕三个核心模块构建:Motion Latent Encoding(运动编码)、Dual Motion Encoder(条件编码)、Causal DFoT Motion Generator(因果生成)。
3.1 Motion Latent Encoding
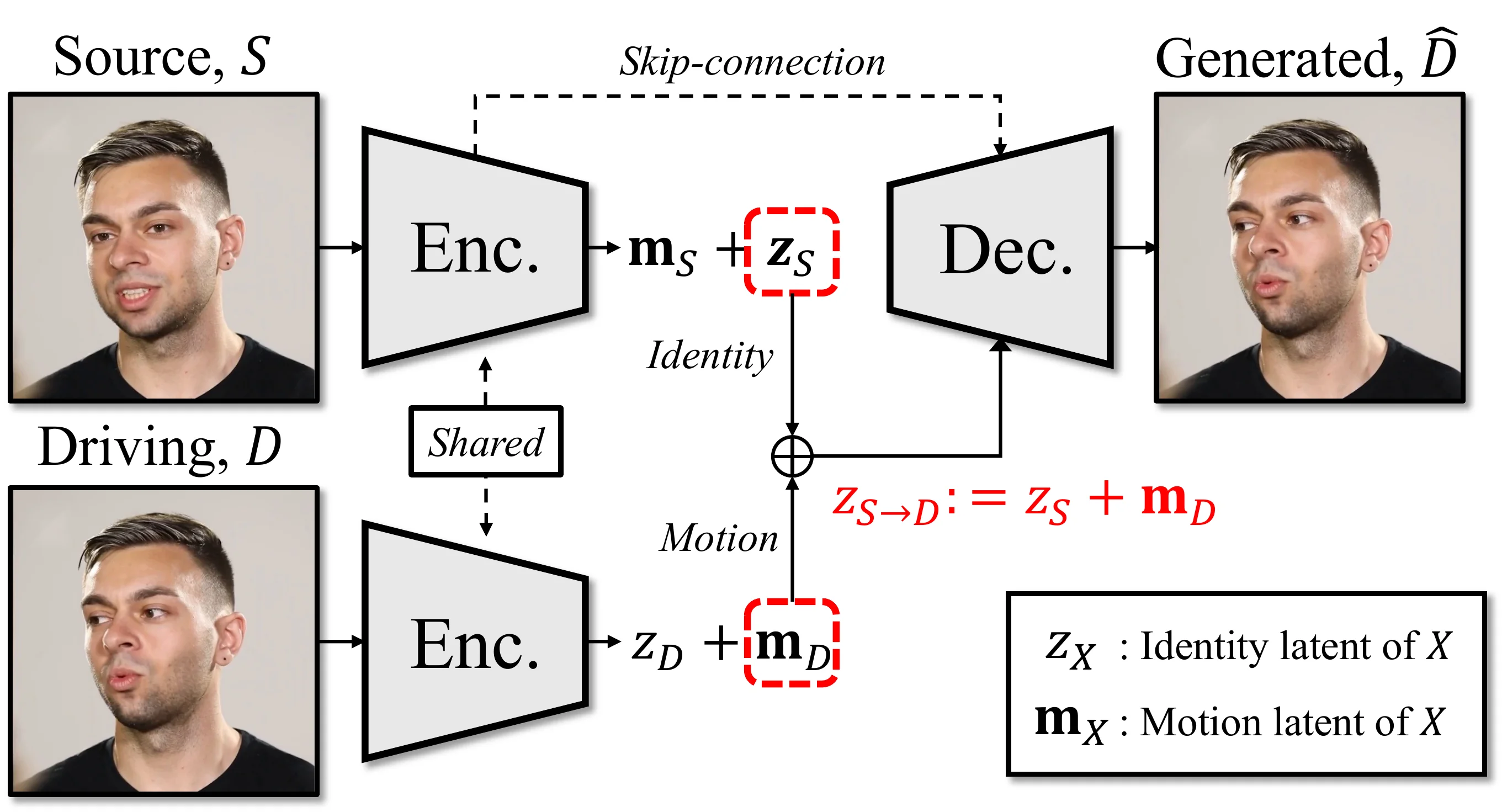
Motivation:直接在像素空间建模不仅计算量巨大(每帧 512×512×3),而且身份信息与运动信息高度耦合。我们需要一个低维、解耦的运动表示。 Intuition:人脸视频可以自然地分解为两个独立因素——身份(这个人长什么样)和运动(在做什么表情)。类比来说,就像一张照片可以拆成"底片"和"滤镜"两张透明片叠在一起——换表情只需替换滤镜,底片保持不变。 Mechanism:#float FLOAT motion latent autoencoder 将输入图像 $S$ 编码为 latent $z$,具有显式的 identity-motion 分解:其中 $z_S \in \mathbb{R}^d$ 是 identity latent(外观/身份),$\mathbf{m}_S \in \mathbb{R}^d$ 是 motion latent(面部表情 + 头部姿态),$d = 512$。生成时 identity latent $z_S$ 在整个对话中保持固定,模型只需逐帧预测 $\mathbf{m}^i$,再与 $z_S$ 相加后送入 decoder。
3.2 Dual Motion Encoder
Motivation:avatar 的运动取决于三路信号的协同——用户在说什么($\mathbf{a}_u$)、用户在做什么表情($\mathbf{m}_u$)、以及 avatar 自己要说什么($\mathbf{a}$)。直接拼接无法捕获语义关联。 Intuition:类似同声传译员——先听懂说话人的语气和内容(第一层对齐),再结合自己要说的话组织回应(第二层融合)。 Mechanism:两层 cross-attention 逐步融合三路信号:- 第一层:$Q = \mathbf{m}_u^i$, $K/V = \mathbf{a}_u^i$ → 对齐用户运动与用户音频,产出"对齐用户表示"
- 第二层:$Q = \mathbf{a}^i$, $K/V = \text{aligned\_user}$ → 融合 avatar 音频,产出统一条件 $\mathbf{c}_{\text{unified}}^i$
3.3 Causal DFoT Motion Generator
这是整个方法的核心创新。#infp INFP 使用双向 DiT 需要完整上下文,延迟 3.4s。Avatar Forcing 改用 blockwise causal #diffusion-forcing Diffusion Forcing Transformer(DFoT),但面临新挑战:由于 motion latent 无时序压缩,严格因果 mask 在 block 边界处产生严重运动抖动。
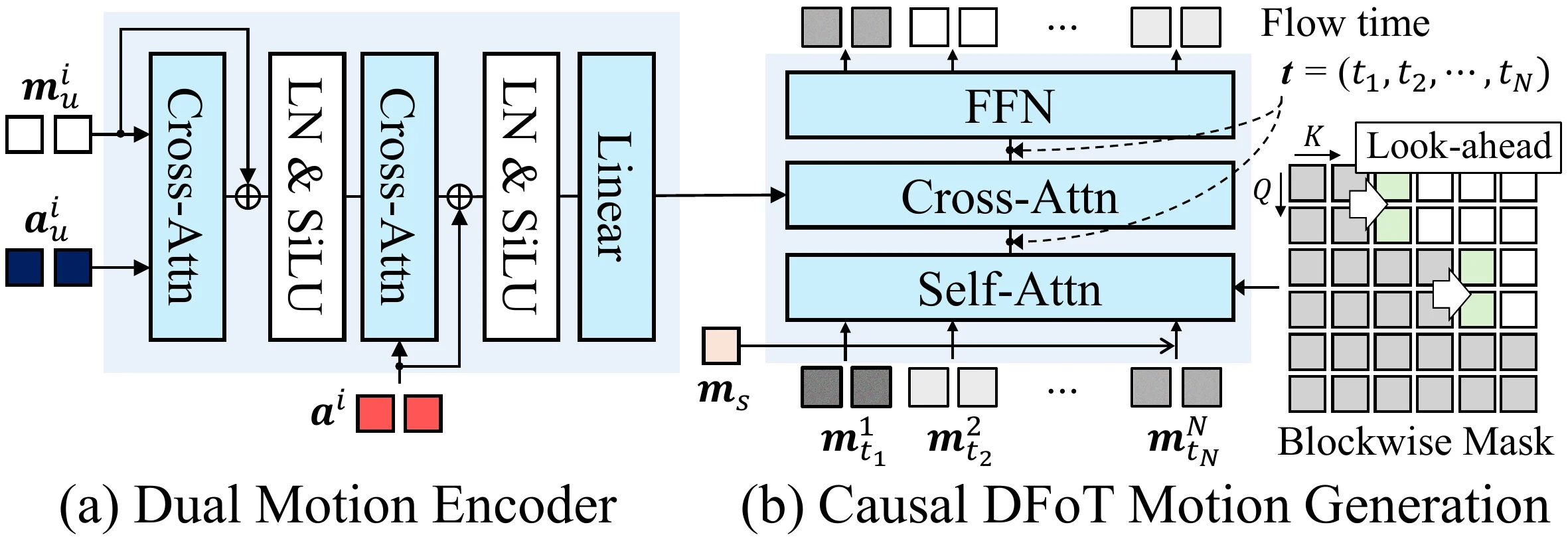
实际实现中以 block 为粒度:$N=50$ 帧分为 $L = N/B = 5$ 个 block,每个 block $B=10$ 帧。
Look-ahead Causal Mask:允许每个 block 额外关注未来 $l=2$ 帧,缓解跨 block 边界的运动抖动。数学定义为:其中 $i, j$ 为帧索引,$B=10$ 为 block 大小,$l=2$ 为前瞻帧数。
推理时的 Offset 机制
Look-ahead 需要 $l$ 个未来帧,但推理时未来不可用。解决方案是引入 offset $\mathbf{O}^{i+1} = (\mathbf{m}_1^{i}[-l:], \mathbf{c}^{i}[-l:])$,由上一个 block 最后 $l=2$ 个 clean motion latent 和对应 condition 组成。将这些 offset 与当前 noisy block 拼接,对 offset 帧设 $t=1$(clean),对当前 noisy block 设 $t=t_j$。这样既满足 look-ahead mask 的需求,又不增加实际延迟。
其中 $n$ 为帧索引,$t_n \in [0,1]$ 为 per-frame noise timestep,$\mathbf{c}^n = (\mathbf{a}_u^{n}, \mathbf{m}_u^n, \mathbf{a}^n)$ 为条件三元组。同一 block 内的帧共享噪声时间步。
3.4 DPO 偏好优化
Motivation:现有 listening 数据集的表情丰富度远低于 speaking 数据集(图 3 已证实),模型容易学到被动、缺乏表达力的倾听行为。人工标注偏好对成本高昂。 Insight:drop 用户条件 = 低表达性。仅以 avatar audio 为条件生成的运动天然缺乏交互性,可以作为"less-preferred sample",无需额外标注。 偏好对构造:- Preferred sample $\mathbf{m}^w$:来自 ground-truth 视频的 motion latent
- Less-preferred sample $\mathbf{m}^l$:由一个单独训练的 talking avatar model(FLOAT)仅以 avatar audio 为条件生成——即 drop 掉所有 user conditions
其中 $\lambda = 0.1$,$\mathcal{L}_{DPO}$ 为 #diffusiondpo DiffusionDPO 的损失函数。
| 维度 | INFP | FLOAT | Self-Forcing | CausVid | Avatar Forcing |
|---|---|---|---|---|---|
| 核心表示 | 双向 DiT | Flow Matching | Causal Diffusion | Blockwise Causal DF | Causal DFoT + Look-ahead |
| 操作空间 | Motion Latent | Motion Latent | Pixel Latent | Pixel Latent | Motion Latent |
| 因果性 | 双向 | 非自回归 | 因果 | Blockwise 因果 | Blockwise 因果 + l=2 |
| 时序压缩 | 无 | 无 | 4-8× | 4× | 无(1:1 帧对应) |
| 交互性 | 双向 | 单向 | 单向 | 单向 | 双向 |
| 延迟 | 3.4s | ~100ms | 实时 | 实时 | ~500ms |
| 偏好优化 | 无 | 无 | 无 | 无 | 免标注 DPO |
表 1:Avatar Forcing 与核心竞争方法的技术对比。
数据预处理
论文使用 #realtalk RealTalk 和 #vico ViCo 两个 dyadic conversation 数据集。预处理流程为:PySceneDetect 场景切割 → Face-Alignment 人脸追踪与裁剪(512×512)→ IIANet 视觉引导语音分离(区分 speaker/listener 音频)→ 视频转 25fps,音频重采样 16kHz。此外,从 HDTF 中随机选取 50 个 talking-head 视频用于评估说话能力。Motion latent autoencoder 在此数据集上重新训练(非直接使用 FLOAT 原权重)。
Stage 1:Diffusion Forcing 训练
在 motion latent space 中学习条件自回归生成。训练序列 $N=50$ 帧,划分为 5 个 block(10 帧/block)。同一 block 内帧共享噪声时间步,不同 block 独立采样——这是 diffusion forcing per-token independent noising 的核心体现。Motion latent autoencoder 全程冻结,仅训练向量场预测器 $v_\theta$。总训练步数 2000k steps。
Stage 2:DPO 微调
以 Stage 1 收敛的 $v_\theta$ 权重同时初始化当前模型和冻结的 reference model $v_{\text{ref}}$,以总目标 $\mathcal{L}_{ft} = \mathcal{L}_{DF} + \lambda \mathcal{L}_{DPO}$ 微调。$\lambda = 0.1$,$\beta = 1000$。Less-preferred sample 由单独训练的 FLOAT 模型仅以 avatar audio 为条件生成。微调仅需 5k steps——作者明确指出"additional tuning does not yield further performance gains"。
训练配置披露表
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 数据集 | RealTalk + ViCo(dyadic conversation) | 论文披露 |
| GPU | 单张 NVIDIA H100 | 论文披露 |
| 优化器 | Adam | 论文披露 |
| 学习率 | $10^{-4}$ | 论文披露 |
| Batch size | 8 | 论文披露 |
| Latent dimension $d$ | 512 | 论文披露 |
| Attention heads | 8(DFoT)/ 4(Dual Encoder) | 论文披露 |
| Hidden dimension $h$ | 1024(DFoT)/ 512(Dual Encoder) | 论文披露 |
| 位置编码 | 1D RoPE | 论文披露 |
| 音频特征 | Wav2Vec2.0 的 12 multi-scale features | 论文披露 |
| DFoT blocks | 8 | 论文披露 |
| 训练帧数 | $N=50$, 5 blocks, 10 frames/block | 论文披露 |
| Look-ahead $l$ | 2 帧 | 论文披露 |
| Stage 1 训练步数 | 2000k steps | 论文披露 |
| DPO 微调步数 | 5k steps | 论文披露 |
| DPO $\lambda$ / $\beta$ | 0.1 / 1000 | 论文披露 |
| 训练时长(wall clock) | 未披露 | — |
| Checkpoint 选择 | 未披露 | — |
| 模型总参数量 | 未披露 | — |
| FLOPs | 未披露 | — |
表 2:训练配置披露状态。绝大多数超参数已完整披露,但训练实际时长、checkpoint 选择策略、总参数量和 FLOPs 未给出。
Blockwise Rollout
Avatar Forcing 的推理以 block 为单位进行自回归生成:
- 初始化:帧缓存 $\mathbf{KV}$ 和条件缓存 $\mathbf{cKV}$ 均为空。Offset $\mathbf{O}^1$ 为空。
- 逐 block 生成(对每个 block $i = 1, \dots, L$):
- 采样噪声 block $\mathbf{m}_{t_0}^i \sim \mathcal{N}(0, I)$,shape $10 \times 512$
- 获取实时用户输入 $(\mathbf{a}_u^i, \mathbf{m}_u^i)$ 和 avatar audio $\mathbf{a}^i$
- 合并 offset:$\mathbf{O}^i$ 与当前 noisy block 拼接,形成 $l + B = 12$ 帧
- ODE 求解:Euler solver 执行 10 步 NFE,利用已缓存的 KV 避免重复计算
- 解码输出:$\mathbf{x}_1^i \leftarrow \texttt{Dec}(z_S, \mathbf{m}_1^i)$
- 更新缓存:生成的 clean block 计算 KV 并 append;若 $|\mathbf{KV}| > M$ 则 pop 最旧的
- 更新 offset:$\mathbf{O}^{i+1} \leftarrow (\mathbf{m}_1^i[-l:], \mathbf{c}^i[-l:])$
独立 CFG 的三路缓存
由于使用 independent classifier-free guidance,需要分别缓存三路向量场的 KV:
- $v_\theta(\cdot; \mathbf{c}_{\{\emptyset, \emptyset\}})$:无条件
- $v_\theta(\cdot; \mathbf{c}_{\{\mathbf{a}, \emptyset\}})$:仅 avatar audio
- $v_\theta(\cdot; \mathbf{c}_{\{\emptyset, \mathbf{u}\}})$:仅 user conditions
这三路 KV 通过复用已生成的 motion block 和已有 KV 缓存来计算,避免重复前向传播。最大缓存大小 $M = 38$ blocks。
延迟拆解
- 总延迟:~500ms(vs INFP* 3.4s,6.8× 加速)
- 推理配置:10 NFEs + Euler solver + independent CFG
- 延迟来源:block 内 10 帧的 ODE 求解(主要开销)+ Dual Motion Encoder 的条件编码 + FLOAT decoder 的解码
- 实时性:500ms 延迟已进入人类自然对话的停顿容忍范围
主实验:RealTalk 交互式头像
| 方法 | 交互 | 反应性 ↓ | 运动丰富度 ↑ | 视觉质量 | 唇同步 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| User Input | Latency ↓ | rPCC-Exp | rPCC-Pose | SID | Var | FID ↓ | FVD ↓ | CSIM ↑ | LSE-D ↓ | LSE-C ↑ | |
| FLOAT | ✗ | 2.4s | 0.054 | 0.182 | 2.785 | 2.778 | 81.297 | 438.817 | 0.845 | 8.135 | 6.361 |
| INFP* | ✓ | 3.4s | 0.035 | 0.064 | 2.343 | 1.638 | 24.551 | 159.000 | 0.867 | 8.027 | 6.536 |
| Ours | ✓ | 0.5s | 0.003 | 0.036 | 2.442 | 1.734 | 24.328 | 170.874 | 0.833 | 8.060 | 6.723 |
表 3:RealTalk 数据集上的定量对比。灰色行为非交互式 talking head 模型(FLOAT),仅作参考。* 表示复现版本。
关键发现:- 延迟 6.8× 加速:0.5s vs 3.4s,首次实现实时交互式 avatar
- 反应性提升 10×:rPCC-Exp 0.003 vs 0.035(越低越好),avatar 对用户表情的同步程度大幅改善
- 运动丰富度更高:SID 2.442 vs 2.343,Var 1.734 vs 1.638
- Trade-off:FVD 170.874 vs 159.000(略差),CSIM 0.833 vs 0.867(略差)——DPO 提升表达性但牺牲了部分时序一致性和身份保持

Talking Head 对比(HDTF)
| 方法 | FID ↓ | FVD ↓ | CSIM ↑ | LSE-D ↓ | LSE-C ↑ |
|---|---|---|---|---|---|
| SadTalker | 64.744 | 342.996 | 0.697 | 8.046 | 7.171 |
| Hallo3 | 32.794 | 184.341 | 0.865 | 8.498 | 7.487 |
| FLOAT | 25.110 | 167.463 | 0.881 | 7.553 | 8.006 |
| INFP* | 27.155 | 187.977 | 0.840 | 7.810 | 7.325 |
| Ours | 20.332 | 149.798 | 0.870 | 7.700 | 7.560 |
表 4:HDTF 数据集 Talking Head 对比。Avatar Forcing 在 FID/FVD 上最优,CSIM/LSE 略逊于 FLOAT(非交互式 baseline)。
Listening Head 对比(ViCo)
| 方法 | FD ↓ | rPCC ↓ | SID ↑ | Var ↑ | ||||
|---|---|---|---|---|---|---|---|---|
| Exp | Pose | Exp | Pose | Exp | Pose | Exp | Pose | |
| RLHG | 39.02 | 0.07 | 0.08 | 0.02 | 3.62 | 3.17 | 1.52 | 0.02 |
| L2L | 33.93 | 0.06 | 0.06 | 0.08 | 2.77 | 2.66 | 0.83 | 0.02 |
| DIM | 23.88 | 0.06 | 0.06 | 0.03 | 3.71 | 2.35 | 1.53 | 0.02 |
| INFP* | 17.52 | 0.07 | 0.01 | 0.07 | 2.19 | 3.20 | 2.10 | 0.03 |
| Ours | 16.64 | 0.05 | 0.01 | 0.01 | 3.12 | 3.00 | 2.80 | 0.03 |
表 5:ViCo 数据集 Listening Head 对比。8 项指标中 Avatar Forcing 在 6 项取得最优或并列最优。
消融实验
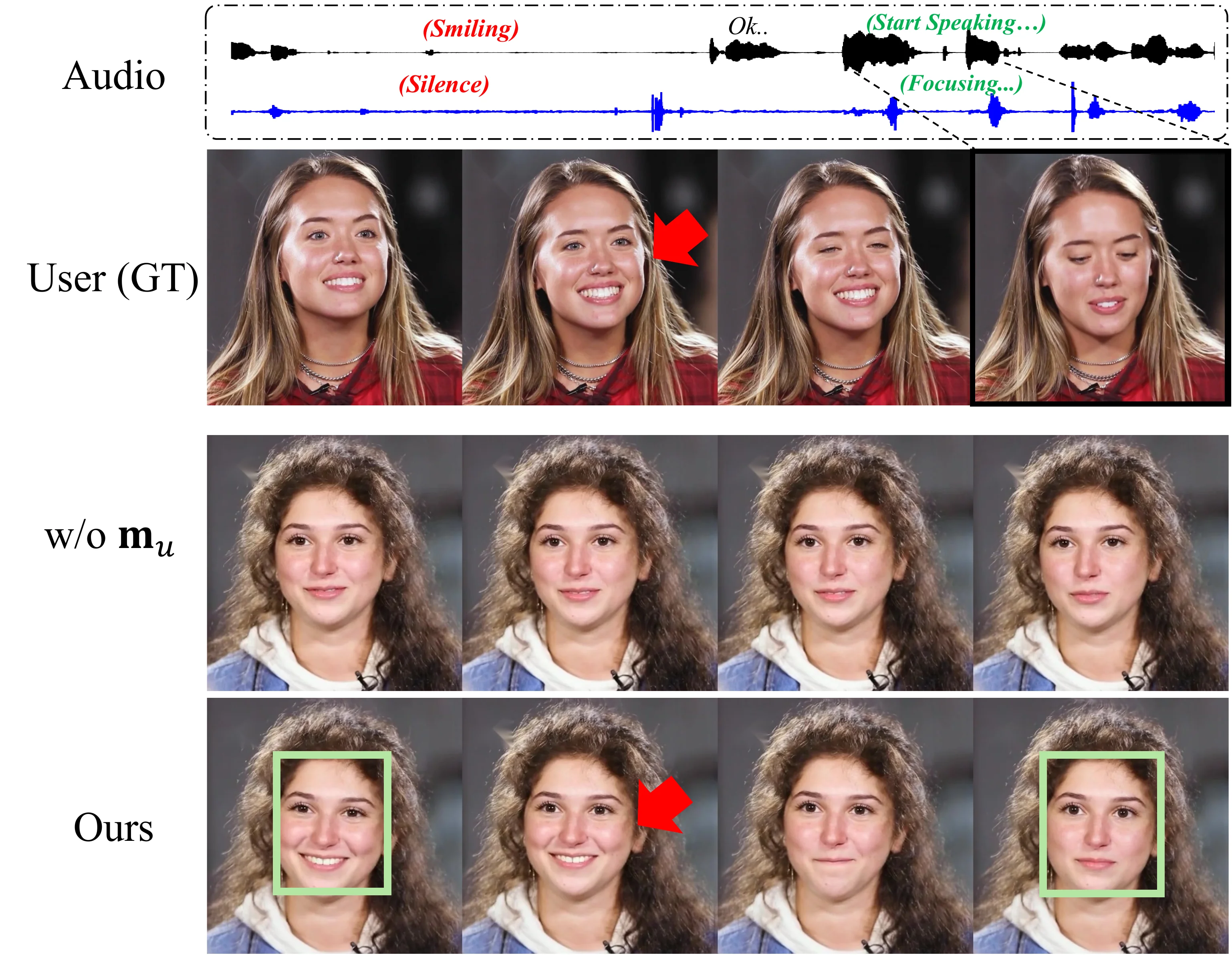

失败案例
- FVD 不如 INFP*:170.874 vs 159.000。DPO 推动更丰富的表情变化,但可能引入更多帧间时序波动。
- CSIM 下降:0.833 vs 0.867(vs INFP*),且 DPO 前为 0.854。DPO 推动模型"大胆"偏离安全均值,有时偏离源图像身份特征。
- 仅限头部:缺乏手势和身体语言,FLOAT AE 仅编码人脸区域。

核心贡献回顾
Avatar Forcing 在三个层面做出了贡献:
- 架构层面:首次在 motion latent space 中使用 diffusion forcing 实现因果实时交互,延迟从 3.4s 降至 500ms(6.8× 加速),look-ahead mask 解决了无时序压缩下的帧间抖动问题
- 目标函数层面:提出免标注 DPO,通过"drop 用户条件 = 低表达性"构造偏好对,rPCC-Exp 改善约 17 倍,>80% 人类偏好率
- 系统层面:统一框架覆盖交互式头像、talking head、listening head 三种任务
局限性分析
- 仅头部运动:FLOAT AE 仅编码人脸区域,缺乏手势和身体语言。需要扩展到上半身 motion latent space 和全身对话数据集。
- 缺乏显式可控性:motion latent space 是端到端黑箱表示,无法编辑特定表情/动作。需要语义解耦或额外控制信号接入。
- Exposure Bias 未完全消除:Diffusion forcing 大幅缓解但未根本消除 train-test gap。极长序列(远超 50 帧训练长度)下的表现未被验证。可借鉴 Self-Forcing 的自校正训练策略。
- FVD/CSIM Trade-off:DPO 提升表达性但牺牲时序一致性和身份保持。需要 multi-objective 偏好优化。
- INFP* 复现偏差:baseline 非官方实现,对比存在不确定性。
- 代码未开源:截至撰写时仅有 README。
具体可操作的启发
启发 1:Diffusion Forcing 在因果实时序列生成中的迁移延伸阅读
- Diffusion Forcing(Chen et al., NeurIPS 2024)— 理论基础。理解 per-token independent noising 如何统一 teacher forcing 和 full-sequence diffusion。
- FLOAT(Ki et al., ICCV 2025)— Motion latent autoencoder 来源。同一第一作者的前作,Avatar Forcing 直接复用其 identity-motion 分解。
- Self-Forcing(Huang et al., NeurIPS 2025)— Blockwise causal + KV cache 的先行工作。解决自回归视频扩散中 train-test gap 的关键参考。
- INFP(Zhu et al., CVPR 2025)— 最直接 baseline。首个 dyadic interactive head generation 方法,理解其 3.4s 延迟的来源才能体会 Avatar Forcing 的突破。
- CausVid(Yin et al., CVPR 2025)— Pixel-space blockwise causal diffusion forcing。与 Avatar Forcing 在 latent space 选择上形成有趣对比(pixel vs motion)。
参考来源
- Diffusion Forcing: Next-token Prediction Meets Full-sequence Diffusion (Chen et al., NeurIPS 2024)
- FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait (Ki et al., ICCV 2025)
- INFP: Interactive Non-verbal Facial expression generation for real-time conversational avatars (Zhu et al., CVPR 2025)
- Self-Forcing: Bridging Train-Test Gap in Autoregressive Video Diffusion (Huang et al., NeurIPS 2025)
- CausVid: From Full-sequence to Real-time Streaming Video Diffusion (Yin et al., CVPR 2025)
- Direct Preference Optimization (Rafailov et al., NeurIPS 2023)
- DiffusionDPO: Aligning Diffusion Models via Preference Optimization (Wallace et al., CVPR 2024)
- RealTalk: Real-time Interactive Talking Video Generation
- ViCo: A Large-scale Video Conversation Dataset (Zhou et al., ECCV 2022)
- Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation (Ki et al., 2026)