数字人论文精读(四):SadTalker,用 3D 运动系数驱动单图说话人
给定一张人脸照片和一段语音,让照片里的人"开口说话",这是数字人最朴素的需求。它的应用面极广:视频会议里的虚拟形象、在线教育的 AI 讲师、影视配音的口型适配、数字人客服。但把这件事做自然,远比想象中难。
难点不在"让嘴动起来",而在"让整张脸协调地动起来"。真人说话时,不只是嘴唇在动:眉毛会挑、眼睛会眨、头会随语气轻轻摆动、脸颊会随发音鼓起。如果只驱动嘴唇而让其余部分僵死,观众会立刻察觉"不对劲"——这就是著名的恐怖谷效应。SadTalker 这篇 CVPR 2023 工作,正是试图系统性地解决"从单张图像 + 音频生成自然说话头"这一问题。#Zhang-et-al.-2023

阅读目标
- 核心问题:为什么直接从音频生成像素会导致脸部失真和头动不自然?
- 核心方法:SadTalker 如何用 3DMM 运动系数把"音频→表情"和"音频→头姿"解耦建模。
- 系列位置:本文是数字人系列的论文精读篇,对应总览中的 3DMM/显式运动系数路线。
前置术语
3DMM(3D Morphable Model,三维可变形人脸模型)
一种用低维参数表示三维人脸的统计模型。任意一张人脸可以被分解为一组系数:身份系数(脸型、五官比例)、表情系数(喜怒、张嘴程度)、纹理系数(肤色、光照),以及头部的旋转和平移。换句话说,它把"一张脸长什么样、在做什么表情、朝哪个方向"压缩成几百个数字。SadTalker 关注的是其中的表情系数和头部姿态。
有了 3DMM,"驱动一张脸说话"就被转化为"预测随时间变化的表情系数和头姿系数"。这比直接生成像素友好得多——模型不需要操心皮肤纹理、头发、背景,只需要预测一组低维、可解释的运动参数,再交给渲染器还原成图像。
为什么之前的方案不够好
在 SadTalker 之前,单图说话头主要有两条路线,各有硬伤:
- 直接生成像素的 2D 方法(如基于 2D landmark 或光流的方法):音频到像素的映射极度欠约束,同一段音频可以对应无数种合理的脸部图像。模型为了"安全"往往生成平均脸,表情寡淡;遇到大幅头动时还会出现背景扭曲、面部拉伸等伪影。
- 把表情和头姿混在一起预测:很多方法用一个网络同时输出嘴型、表情和头部运动。问题是这三者与音频的相关性完全不同——嘴型与音频强相关(音素几乎决定唇形),而头部运动与音频弱相关(同一句话可以点头说、可以摇头说)。用一个确定性网络硬学头动,结果要么是头一动不动(学了平均),要么是抖动失真。
SadTalker 的整体流程可以概括为三步:先从音频分别预测表情系数(ExpNet)和头部姿态(PoseVAE),再把这两组 3DMM 运动系数送入一个 3D-aware 面部渲染器,最终合成说话视频。整个过程的关键在于"解耦":让最适合的网络结构去学最适合它的子问题。
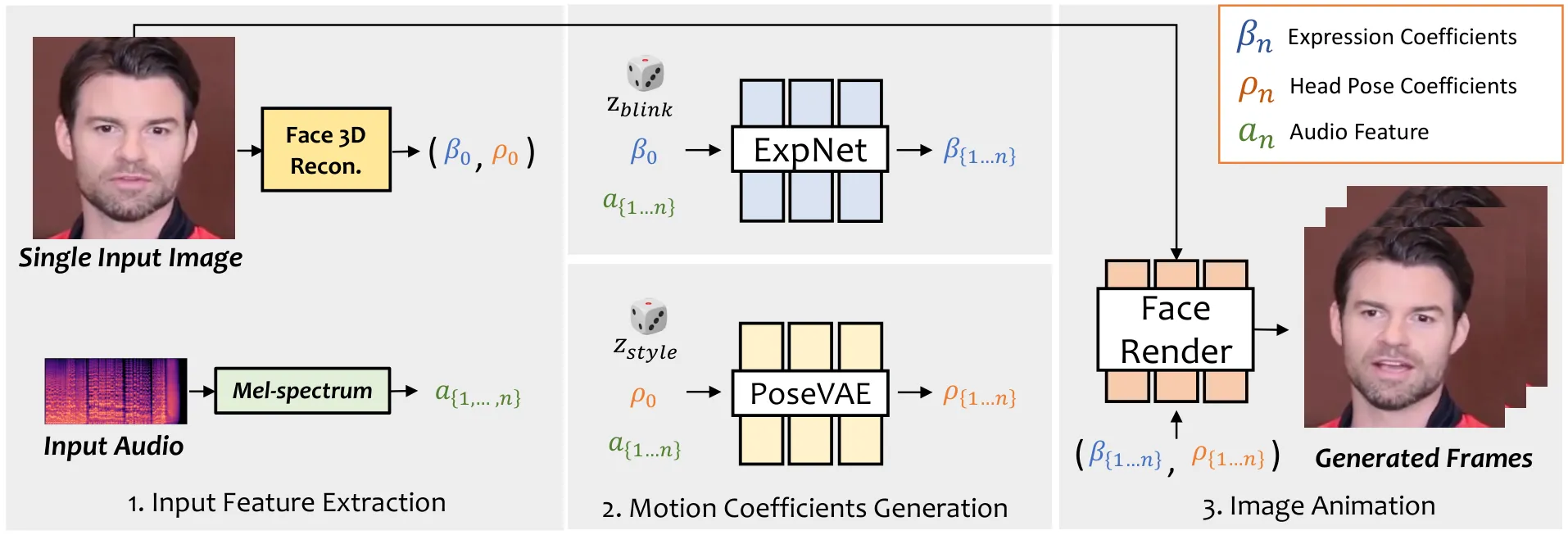
flowchart TD A["驱动音频"] --> B["音频特征 (mel / DeepSpeech)"] I["单张源人脸"] --> C["3DMM 系数提取
身份 / 初始表情 / 初始头姿"] B --> D["ExpNet
表情系数预测"] B --> E["PoseVAE
头姿系数生成"] C --> D C --> E D --> F["3DMM 运动系数序列
表情 + 头姿"] E --> F F --> G["3D-aware Face Render"] I --> G G --> O["说话视频"]
图 3:SadTalker 的数据流。音频被分流到两个独立子网络,分别负责强相关的表情和弱相关的头姿,再统一渲染。
ExpNet:把音频精确映射到表情系数
Motivation:表情(尤其是嘴型)与音频强相关,需要的是精确、确定的回归,而不是多样性。但直接学"音频→3DMM 表情系数"有两个干扰:一是 3DMM 表情系数里混入了身份相关的脸型信息,二是真实表情系数还包含与音频无关的眨眼等成分。
Mechanism:ExpNet 用一个音频编码器加映射网络,从源图像的初始表情系数出发,预测每一帧相对初始状态的表情残差。它只学习音频能解释的那部分表情变化(主要是嘴部和与发音联动的脸颊运动),并用一个预训练的唇形同步判别器(借鉴 Wav2Lip 的 SyncNet 思路)来约束嘴型与音频对齐。这样既保证了口型精度,又不破坏源人物的身份。
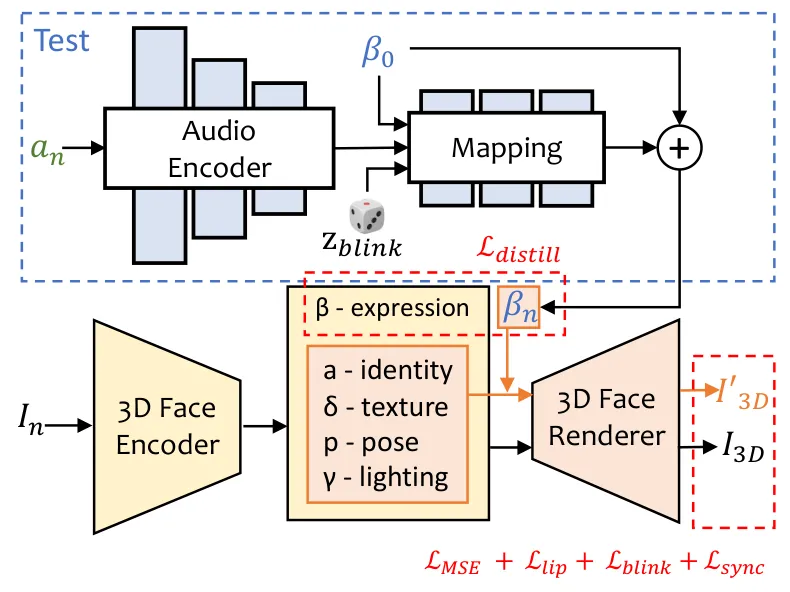
表情预测可以形式化为:给定音频特征序列 $a_{1:T}$ 与源图像的参考表情 $\beta_0$,ExpNet 输出逐帧表情系数
其中 $\beta_0$ 是源人脸的初始表情,网络学习的是音频驱动的表情残差,叠加到初始表情上得到每一帧的完整表情系数。这种"残差"设计让模型只需关注变化量,训练更稳定。
PoseVAE:用生成模型采样自然头动
Motivation:头部运动与音频只是弱相关——音频提供节奏和重音线索,但不唯一决定头怎么动。如果用确定性网络回归头姿,会得到"平均化"的僵硬头动。这正是头部运动应该用生成模型建模的原因:我们要的是"符合语音节奏的、多样且自然的"头动分布,而非单一答案。
Mechanism:PoseVAE 是一个条件变分自编码器(Conditional VAE)。它以音频特征和初始头姿为条件,在隐空间中采样,解码出一段连贯的头部姿态序列(旋转 + 平移)。训练时编码器把真实头姿编码到隐变量分布,推理时直接从先验分布采样,从而生成多样化但风格一致的头部运动。
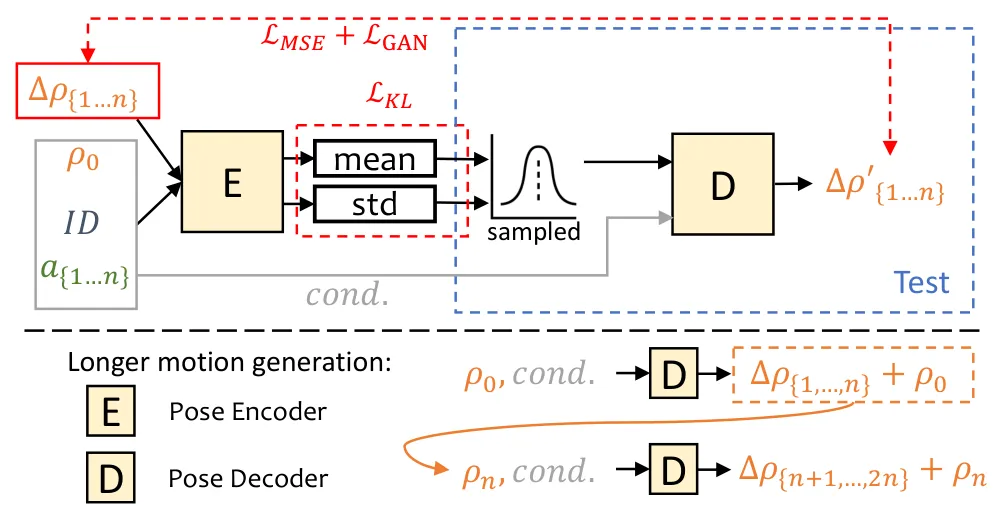
条件 VAE 的训练目标是标准的 ELBO(证据下界),即重构项与 KL 正则项之和:
其中 $\rho$ 是头姿序列,$a$ 是音频条件,$z$ 是隐变量。第一项保证解码出的头姿能重构真实运动,第二项把后验分布拉向条件先验,使推理时可以直接采样。
3D-aware Face Render:从系数回到像素
有了表情和头姿系数,最后一步是把它们变回真实图像。SadTalker 借鉴了 face-vid2vid 的思路,构建了一个 3D-aware 的渲染器:它从源图像学习一个隐式的 3D 表示(用一组 3D 关键点描述源人脸),再用预测出的 3DMM 运动系数去驱动这些关键点的形变和位移,最后 warp + 生成目标帧。

这一步是 SadTalker 相比纯 2D 方法的关键优势:因为运动建立在 3D 表示上,大幅度头部转动时不会出现 2D warp 常见的面部撕裂和背景拉伸,身份也更稳定。
SadTalker 的三个模块并非端到端联合训练,而是分阶段训练,这也是它工程上稳健的原因之一。
- ExpNet 训练:在 VoxCeleb 等说话人视频数据集上,用预训练 3DMM 提取每帧真实表情系数作为监督。损失包含表情系数的重构损失,以及唇形同步判别器提供的同步损失——后者是保证口型精度的关键。判别器本身在大规模唇读数据上预训练并冻结,避免被生成伪影"带偏"(这一点与 Wav2Lip 的设计哲学一致)。
- PoseVAE 训练:在真实视频的头姿序列上训练条件 VAE,优化上面的 ELBO 目标。训练完成后,推理时丢弃编码器,直接从条件先验采样。
- 渲染器训练:在自重演(self-reenactment)任务上训练,即用同一视频的不同帧互相驱动,使渲染器学会"用运动系数驱动源图像"而不改变身份。
复现时的关键点
3DMM 系数提取的质量直接决定上限。如果 3D 重建不准(例如侧脸、遮挡、极端光照),表情系数会带噪,下游再好的网络也救不回来。复现时建议先单独验证 3DMM 提取效果,再调 ExpNet/PoseVAE。
SadTalker 在多个 talking head 基准上与当时的代表方法对比,核心结论是:它在口型同步、身份保持和头动自然度之间取得了更好的综合平衡,尤其是头部运动的真实感明显优于确定性方法。
| 方法 | 口型同步 | 头部运动 | 身份保持 | 核心机制 | 主要短板 |
|---|---|---|---|---|---|
| Wav2Lip | 强(专门优化) | 无(复用原视频) | 强 | lip-sync expert | 只改嘴,需已有视频 |
| MakeItTalk | 中 | 有但偏抖动 | 中 | landmark 驱动 | 2D landmark,大头动易失真 |
| Audio2Head | 中 | 有 | 中 | RNN 预测头动 | 表情与头动耦合 |
| SadTalker | 强 | 自然且多样 | 强 | 3DMM 系数 + ExpNet/PoseVAE 解耦 | 受 3DMM 表达上限约束 |

消融实验进一步验证了解耦设计的价值:去掉 PoseVAE 改用确定性头姿回归后,头部运动的多样性和自然度指标明显下降,视频变得"呆板";去掉唇形同步判别器后,口型同步指标显著退化。这两个消融正好对应了第二章提出的两个 Insight——头动要生成式、口型要强约束。#Zhang-et-al.-2023
局限性
- 受 3DMM 表达上限约束:3DMM 是低维统计模型,对夸张表情、复杂肌肉运动、微表情的刻画能力有限。遇到强情绪语音时,生成的表情可能不够丰富。
- 依赖 3D 重建质量:侧脸、遮挡、极端光照会让 3DMM 系数失真,进而影响整个 pipeline。
- 实时性不是设计目标:SadTalker 更偏离线高质量生成。它的多阶段 pipeline(3DMM 提取 + 两个网络 + 渲染)没有为低延迟交互优化,不应直接按论文默认配置当作实时方案。这也是数字人系列总览中把它归为"单图友好、适合基线和离线生成"的原因。
- 牙齿与口腔内部细节:和多数 talking head 方法一样,牙齿、舌头等口腔内部区域容易出现模糊或不稳定。
工程启发
可迁移的设计原则
SadTalker 最值得借鉴的不是某个具体网络,而是它的解耦哲学:识别出子问题与条件信号的相关性强弱,强相关用确定性回归 + 强约束,弱相关用生成模型采样多样性。这个原则可以迁移到任何"一对多映射"的生成任务中——例如做实时 avatar 时,可以把"音频→嘴型"和"语义→手势"分开,前者精确回归,后者生成式采样。
对工程团队而言,SadTalker 适合作为单图说话头的可解释 baseline:它的中间表示是 3DMM 系数,每一步都能单独检查和可视化,非常适合用来分析"问题出在口型、头动还是渲染"。如果业务需要从单张照片冷启动生成离线说话视频,它是一个稳健的起点;但如果目标是低延迟实时交互或影视级表情,则需要转向后续的扩散类或 latent 类方法。
本文是数字人系列的论文精读篇,推荐结合以下内容阅读:
- 实时数字人路线总览:理解 SadTalker 在整个技术地图中的位置(3DMM/显式运动系数路线)。
- Wav2Lip 论文精读:SadTalker 的唇形同步约束正是借鉴了 Wav2Lip 的 lip-sync expert 思路。
- VASA-1 论文精读:对比 SadTalker 的显式 3DMM 路线与 VASA-1 的 latent dynamics 路线,理解两代方法的范式差异。
- face-vid2vid:SadTalker 的 3D-aware 渲染器借鉴了它的隐式 3D 关键点表示。
参考来源
- Zhang, W. et al. (2023). SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. CVPR 2023. arXiv:2211.12194
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. ACM Multimedia 2020. arXiv:2008.10010
- Wang, T.-C. et al. (2021). One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing (face-vid2vid). CVPR 2021. arXiv:2011.15126