Ditto
Ditto 这篇论文要解决的是一个很工程、也很产品的问题:给定一张人像和一段语音,如何实时生成一个能自然说话、还能被控制的数字人视频。过去两年,扩散模型让 talking head 的表情、头动和细节真实感提升很快,EMO、EchoMimic、Hallo 这类方法把“会动的嘴”推进到“会有表情和节奏的脸”。但论文指出,这条路线仍然卡在两个关键问题上:一是推理慢,很多扩散式方法在单 GPU 上远慢于实时;二是控制弱,用户很难直接指定 gaze、emotion、pose 或修复局部表情缺陷,只能靠重采样碰运气。#Li-et-al.-2025
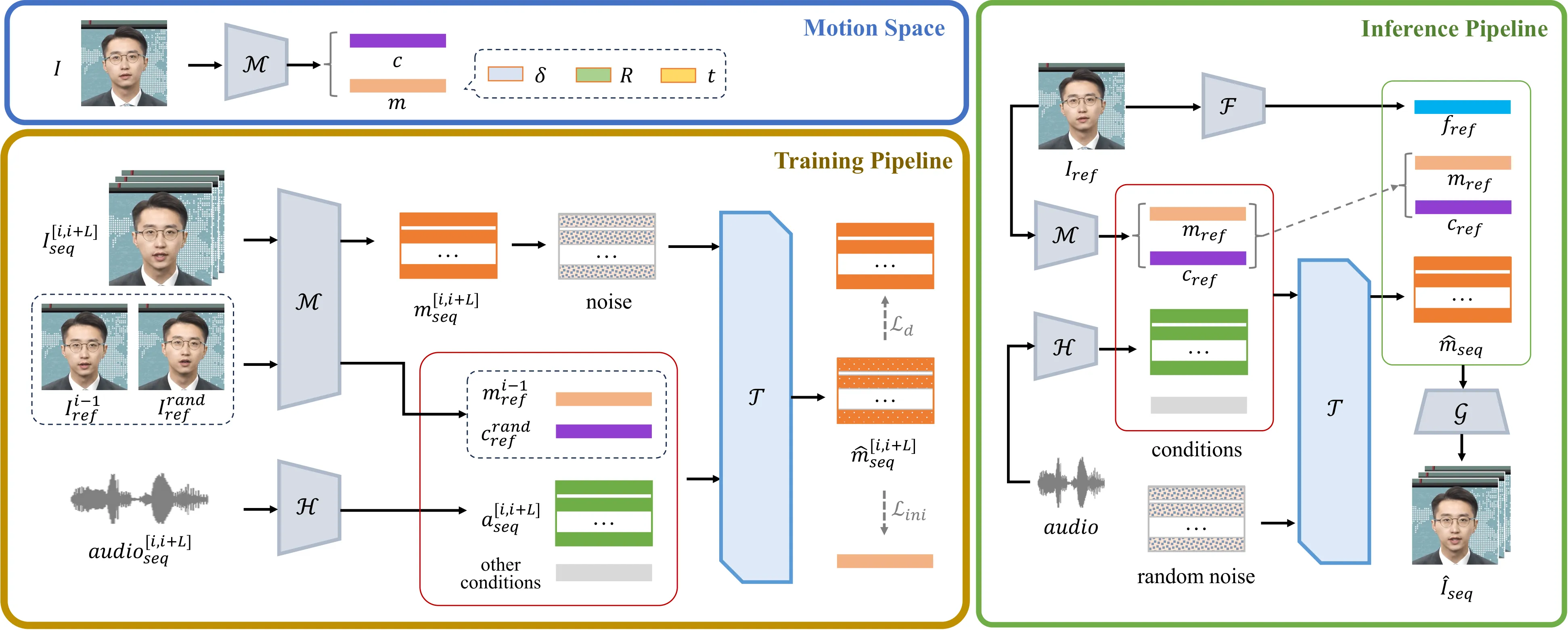
这正是实时数字人与离线视频生成的根本差异。离线生成可以等待,也可以重试;交互式 AI assistant、直播数字人或视频通话中的 avatar 不行。用户说一句话,系统必须在几百毫秒内回第一帧,并且在流式音频持续输入时稳定输出。如果生成结果眼神乱飘、表情过度、头动与躯干接不上,用户也不能接受“再生成一次”。所以 Ditto 的切入点很清晰:不要让扩散模型直接在冗余的视频/图像潜空间里解决所有问题,而是把扩散任务缩小到更适合 talking head 的运动空间。
这使 Ditto 与 VASA-1 形成了直接对话。VASA-1 证明了 motion-space diffusion 可以做到实时高质量,但其代码不可用,且隐式运动表示不方便做细粒度控制。Ditto 则基于 LivePortrait 风格的 motion extractor 构建运动空间,引入 Conditional DiT、运动语义映射、gaze correction 与流式推理优化,并开源推理代码。换句话说,它把 VASA-1 的“方向正确”进一步落到了可控性、工程部署和开源复现上。#Xu-et-al.-2024 #Guo-et-al.-2024
任务到底是什么
Audio-driven talking head synthesis 的输入通常是一张参考人像 $I_{ref}$ 和一段音频序列,输出是一段与音频同步的说话视频。传统方法会把问题理解成“音频到像素”或“音频到视频 latent”的生成任务,但 Ditto 把它拆成两层:第一层是音频到面部运动;第二层是运动到目标身份的视频渲染。这样一来,模型不需要在扩散阶段同时学习身份纹理、背景、头发、牙齿、口型、眨眼和头姿,而只需预测一串紧凑运动参数。
Motion Space(运动空间)
Ditto 中的 motion space 来自 LivePortrait 风格的 motion extractor。单帧图像经过 $\mathcal{M}$ 后得到 canonical keypoints $\mathbf{c}$、expression deformation $\boldsymbol{\delta}$、head rotation $\mathbf{R}$ 与 translation $\mathbf{t}$。其中 $\mathbf{m}=\{\boldsymbol{\delta},\mathbf{R},\mathbf{t}\}$ 被视为要生成的 identity-agnostic motion representation。
ECS 与 ICS
Enhanced Conditional Signals(ECS)包括音频特征 $\mathbf{a}$、眼部状态 $\mathbf{e}$、canonical keypoints $\mathbf{c}_{ref}$ 和 emotion label $\mathbf{s}$,用于在 cross-attention 中持续引导生成。Initial Conditional Signal(ICS)是 reference initial motion $\mathbf{m}_{ref}$,通过复制并与噪声序列拼接,主要影响片段初始阶段,帮助长序列保持连续。
RTF 与 FFD
Real-Time Factor(RTF)表示处理一段音视频所需时间与该段真实时长的比值。$\text{RTF}<1$ 才意味着速度超过实时。First-Frame Delay(FFD)表示流式系统从收到输入到输出第一帧的延迟,是交互数字人非常关键的体验指标。
为什么已有扩散路线不够好
| 路线 | 代表方法 | 优势 | 瓶颈 |
|---|---|---|---|
| GAN / NeRF / 显式系数 | Wav2Lip、SadTalker、早期 NeRF talking head | 速度较快,部分表示可解释 | 表情和头动自然度不足,整体面部动力学较弱 |
| 像素或通用 VAE latent 扩散 | EMO、EchoMimic、Hallo | 表情丰富,视觉质量提升明显 | 空间冗余,推理慢,控制通常依赖弱条件或重采样 |
| 运动空间扩散 | VASA-1、Ditto | 扩散目标低维,适合实时;更容易做运动控制 | 运动表示质量决定上限,高频自然性可能受压缩影响 |
Ditto 的判断是:对实时数字人而言,“生成空间”比“生成模型”本身更重要。即便同样使用 diffusion transformer,如果目标空间太冗余,模型就会把大量算力花在身份纹理和背景细节上;如果目标空间太隐式,又难以控制和修复。运动空间正好处在中间:足够低维,便于实时;又保留表情、头姿、眼神等可被解释和干预的结构。
Ditto 的完整链路可以概括为三步:先用 Motion Extractor 把图像投到运动空间;再用 Conditional DiT 根据音频和控制信号生成运动序列;最后用 Appearance Feature Extractor 与 Face Renderer 把运动渲染回目标身份的视频。这个拆分最重要的好处,是把“谁在说话”和“怎么动”分开处理。
flowchart TD A["参考人像 I_ref"] --> B["Motion Extractor M"] A --> C["Appearance Extractor F"] D["音频流"] --> E["HuBERT H"] B --> F["c_ref / m_ref"] E --> G["audio feature a"] H["eye state / emotion / initial motion"] --> I["Conditional Signals C"] F --> I G --> I J["random noise"] --> K["Conditional DiT T"] I --> K K --> L["motion sequence m_hat"] C --> M["appearance feature f_ref"] F --> N["reference keypoints x_ref"] L --> O["generated keypoints x_hat"] M --> P["Face Renderer G"] N --> P O --> P P --> Q["talking-head video"]
Motion Space:让扩散模型只学“怎么动”
论文首先定义了运动表示。给定单帧 $I$,Motion Extractor $\mathcal{M}$ 输出 canonical keypoints $\mathbf{c}\in\mathbb{R}^{K\times3}$、expression deformation $\boldsymbol{\delta}\in\mathbb{R}^{K\times3}$、head rotation $\mathbf{R}\in\mathbb{R}^{3\times3}$ 和 translation $\mathbf{t}\in\mathbb{R}^{3}$。Ditto 让扩散模型预测的是 $\mathbf{m}=\{\boldsymbol{\delta},\mathbf{R},\mathbf{t}\}$,而不是图像 latent。
从运动到隐式 3D keypoints
参考图像与生成运动分别对应两组 keypoints:
其中 $\mathbf{c}_{ref}$ 仍来自参考身份,$\hat{\mathbf{R}}$、$\hat{\boldsymbol{\delta}}$、$\hat{\mathbf{t}}$ 来自生成运动。这样做的直觉是:身份几何锚点不变,运动在其上发生。
Renderer 的角色
Face Renderer $\mathcal{G}$ 根据 appearance feature、reference keypoints 和 generated keypoints 合成当前帧:
这一步把运动空间重新映射回像素空间。扩散模型不需要记住参考人的皮肤纹理、发型或背景,renderer 负责保留这些身份与外观信息。
Conditional DiT:哪些条件在控制运动
如果只把音频喂给 DiT,模型仍然会遇到两个问题:同一句话可以配多种合理头动,眨眼和眼神与音频相关性很弱;同时,LivePortrait 的 motion representation 并非完美 identity-agnostic,里面仍可能残留身份几何信息。Ditto 因此把条件信号设计成多源输入。
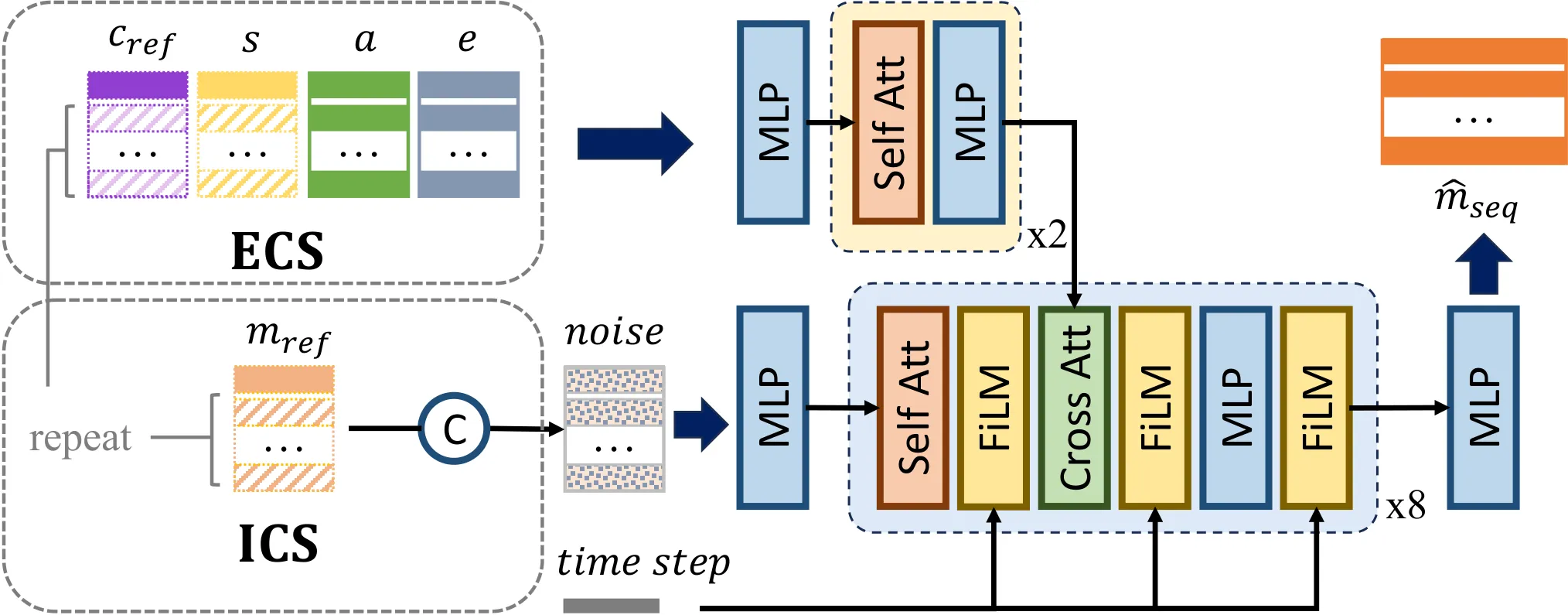
- 音频特征 $\mathbf{a}$:由 HuBERT 提取,是 lip movement 和 speech rhythm 的主条件。
- canonical keypoints $\mathbf{c}_{ref}$:提供目标身份的几何适配,缓解 motion extractor 中运动与身份没有完全解耦的问题。
- emotion label $\mathbf{s}$:在 clip 级别提供情绪条件,避免模型只从音频中隐式猜表情。
- eye state $\mathbf{e}$:包含眼部 aspect ratio 与相对 pupil position,控制眨眼和 gaze。
- reference initial motion $\mathbf{m}_{ref}$:作为片段初始状态,增强跨片段连续性,也可周期性把长序列拉回目标状态。
把 Ditto 讲清楚,不能只讲模型结构,还必须把训练流水线单独拆开。因为这篇论文的核心不是“拿一个 DiT 去生成脸”,而是先用一个已训练好的 one-shot talking-head 系统定义 motion space,再把真实视频全部投影到这个运动空间中,让扩散模型只学习 motion trajectory。也就是说,训练阶段的目标不是合成像素,而是学习“给定音频和控制条件时,下一段人脸应该如何运动”。#Li-et-al.-2025
flowchart TD A["清洗后训练视频\n约 50h / 330 identities"] --> B["抽帧与音频对齐"] B --> C["Motion Extractor M"] C --> D["canonical keypoints c"] C --> E["真实运动序列 m0 = delta / R / t"] B --> F["HuBERT audio feature a"] B --> G["eye state e / emotion label s"] D --> H["Enhanced Conditional Signals ECS"] F --> H G --> H E --> I["Initial Conditional Signal ICS\nreference initial motion"] E --> J["前向加噪得到 mt"] H --> K["Conditional DiT T"] I --> K J --> K K --> L["预测 clean motion m_hat"] L --> M["diffusion loss + temporal loss + initial loss"] M --> N["渲染验证集并用 lipsync score 选 checkpoint"]
第一步:把真实视频压到 motion space
训练数据来自约 50 小时、330 个 identities 的清洗视频。每个视频片段都会经过两类特征抽取:图像侧用 Motion Extractor 得到 canonical keypoints、expression deformation、head rotation 和 translation;音频侧用 HuBERT 得到帧级音频特征。这样,原本高维的视频监督信号被转成了低维运动序列 $\mathbf{m}_0=\{\boldsymbol{\delta},\mathbf{R},\mathbf{t}\}$。这一步很关键:DiT 不再学习 RGB 像素,而是学习 LivePortrait 风格 renderer 能理解的动作指令。
第二步:构造两类条件信号
训练样本并不只是 $(\text{audio},\text{motion})$ 对。Ditto 把条件拆成 ECS 和 ICS。ECS 包含音频特征 $\mathbf{a}$、眼部状态 $\mathbf{e}$、canonical keypoints $\mathbf{c}_{ref}$ 与 emotion label $\mathbf{s}$,负责在整个片段中通过 cross-attention 持续约束运动生成。ICS 则来自 reference initial motion $\mathbf{m}_{ref}$,会被复制到序列长度后与噪声 motion 拼接,主要负责片段起点和跨片段连续性。
| 训练信号 | 来源 | 作用 |
|---|---|---|
| Audio feature | HuBERT | 决定口型、语速和说话节奏 |
| Canonical keypoints | Motion Extractor | 把 motion 适配到目标身份几何,缓解身份与运动未完全解耦的问题 |
| Eye state | 眼部 aspect ratio 与 pupil position | 控制眨眼和 gaze,补足音频无法解释的眼部运动 |
| Emotion label | Clip-level 情绪标注 | 给表情强度和风格提供显式条件 |
| Initial motion | 参考初始帧运动 | 稳定片段开头,降低长序列拼接跳变 |
第三步:用训练技巧处理 motion representation 的偏差
论文专门强调,motion representation 虽然比像素空间紧凑,但它本身也有训练难点。首先,野外视频中的头部朝向分布并不均衡,如果直接训练,模型可能学到偏向某一侧的运动习惯;Ditto 因此对人脸图像做 horizontal flip,让左右朝向的 audio-to-motion 关系更平衡。其次,嘴部、眼部、表情和头姿的运动幅度、收敛速度、与音频的相关性都不同,统一 loss 权重会让某些区域训练不足。Ditto 按控制区域对 motion representation 分组,并根据当前 epoch 与上一 epoch 的平均 loss 差异动态调整各组权重,再经过 softmax 得到 adjustment coefficients,这就是消融中影响很大的 adaptive loss weights。
| 训练策略 | 解决的问题 | 论文给出的机制 |
|---|---|---|
| Horizontal Flip | 野外数据头部朝向分布不均,可能导致生成运动偏向某一侧 | 水平翻转人脸图像,平衡左右两侧 audio-to-motion 对应关系 |
| Adaptive Loss Weights | 嘴部、眼部、表情、头姿收敛速度不同,统一权重会破坏同步与动态质量 | 按控制区域分组,根据相邻 epoch 的平均 loss 差异动态调整组权重 |
| Validation by Lipsync Score | diffusion loss 曲线不能准确代表最终视频质量 | 把验证集 motion 渲染成视频后,用 lipsync score 辅助选择 checkpoint |
实现配置也很关键。论文披露,Ditto 使用 8 张 NVIDIA A100 GPU 训练,batch size 为 1024,优化器是 Adan,学习率为 1e-4,weight decay 为 0.02,总共训练 500 epochs。训练时,音频特征、视频帧和条件信号按 25 fps 对齐,每次从视频片段中采样 $L=80$ 帧,也就是 3.2 秒的训练 segment;$\mathbf{m}_{ref}$ 来自当前 segment 的前一帧,$\mathbf{c}_{ref}$ 来自同一视频 clip 的随机帧。论文没有给出总 wall-clock 训练时间,因此这里不编造训练小时数。
第四步:训练 DiT 从噪声还原 clean motion
训练时先对真实运动 $\mathbf{m}_0$ 做 diffusion 前向加噪得到 $\mathbf{m}_t$,再让 Conditional DiT 根据 $\mathbf{m}_t$、时间步 $t$ 和条件 $\mathbf{C}$ 预测 clean motion。主损失是 clean motion 的均方误差:
只匹配每一帧的位置还不够,因为 talking head 最怕的是嘴角、眼睛和头姿抖动。Ditto 因此加入速度和加速度约束:
最终训练目标为:
推理阶段要回答的是另一个问题:训练好的 motion generator 如何进入实时系统。Ditto 的推理链路分成两种形态:离线推理一次性处理完整音频,适合生成视频文件;流式推理按音频 chunk 连续输出,适合实时对话、直播和交互数字人。两者共用 source image 预处理、Conditional DiT 和 renderer,但流式版本额外引入 cache、causal mask 与片段融合来控制首帧延迟。
离线推理:单张图和整段音频如何变成视频
离线推理可以理解为训练 pipeline 的反向使用。系统先读取 source image,缓存 appearance feature、reference keypoints 与 initial motion;再把整段音频送入 HuBERT 得到音频特征;随后 Conditional DiT 从随机噪声开始,在 ECS 与 ICS 条件下迭代去噪,得到完整 motion sequence;最后 renderer 对每一帧执行 $\mathcal{G}(\mathbf{f}_{ref},\mathbf{x}_{ref},\hat{\mathbf{x}})$,输出 talking-head video。
flowchart TD A["source image"] --> B["Appearance Extractor\ncache f_ref"] A --> C["Motion Extractor\nc_ref / m_ref / x_ref"] D["full audio"] --> E["HuBERT audio features"] C --> F["ECS + ICS"] E --> F G["Gaussian noise"] --> H["Conditional DiT denoising\n50-step or 10-step"] F --> H H --> I["generated motion sequence"] C --> J["generated keypoints x_hat"] I --> J B --> K["Face Renderer"] C --> K J --> K K --> L["talking-head video"]
Streaming Inference:三个模块分别降延迟
流式推理比离线推理多了一个约束:音频不是一次性给完,而是按小块持续到达。Ditto 的实时性不是单点优化,而是 Audio2Feat、Motion DiT 和 Face Rendering 三段分别降延迟。音频侧,HuBERT 用 KV cache 提供伪上下文,并加入 causal mask,使 0.4 秒音频流片段也能在 CPU 上实时提特征。运动生成侧,音频特征被对齐到视频帧率并切成固定长度片段,片段间有 overlap,再用 segment-wise fusion 平滑拼接。为了速度,DiT 推理从 50 步降到 10 步,并转 TensorRT。渲染侧,目标身份外观特征预先提取缓存,renderer 也转 TensorRT;需要视频文件时,FFmpeg 在 CPU 并行压缩。
sequenceDiagram participant Audio as "Streaming audio chunk" participant Hub as "HuBERT + KV cache" participant DiT as "10-step DiT TensorRT" participant Fuse as "Segment-wise fusion" participant Render as "Renderer TensorRT" participant Out as "Video stream" Audio->>Hub: "0.4s chunk + causal mask" Hub->>DiT: "frame-aligned audio feature" DiT->>Fuse: "overlapped motion segment" Fuse->>Render: "smoothed motion frame" Render->>Out: "first frame / continuous frames"
| 模块 | 关键优化 | 论文报告结果 |
|---|---|---|
| Audio2Feat | HuBERT KV cache + causal mask | 23ms,RTF 0.115 |
| Motion DiT | 10-step denoising + TensorRT + segment fusion | 62ms,RTF 0.310 |
| Face Rendering | 预提取 appearance feature + TensorRT renderer | 15ms,RTF 0.375 |
Motion Control:把隐式 keypoint 变得像 blendshape
Ditto 的运动表示仍然是 implicit keypoints,并不像 ARKit blendshape 那样天然写着“jaw open”或“left eye blink”。论文的做法很直接:把 expression deformation 看成 63 维向量,即 21 个 3D keypoints 的 $x,y,z$ 坐标。然后逐维施加正负小偏移,渲染固定身份下的变化,观察每一维主要影响哪个局部区域。通过这种 probing,Ditto 建立了 deformation dimension 到 facial semantics 的映射。

这个映射带来两类控制:一类是 regional control,例如限制靠近脖子的区域运动,方便把头部与躯干拼接;另一类是 magnitude control,例如约束某些 deformation 值,避免嘴型或眼部表情过度造成伪影。这是 Ditto 相比许多端到端扩散视频方法更适合产品调参的地方:它可以把“哪里不自然”映射到“哪个运动维度要收紧”。
Gaze Correction:眼神为什么会跟着头乱跑
论文提到一个很真实的工程缺陷:早期测试中,生成 gaze 与 head pose 绑定,头像转头时眼睛也跟着漂,无法稳定看向摄像头。原因在于训练时 eye state 是逐帧加入的,但推理时 eye state 固定来自单张参考图,模型容易把 gaze variation 学进 head pose。Ditto 的修复方案是录制一个模板视频:让演员平滑转头,同时眼睛始终看向摄像头、表情保持不变。这样抽取出的 motion variation 主要就是“为了抵消头动而发生的 gaze 修正”。
Gaze 修正映射
设头姿变化为 $\mathbf{R}_e$,对应的 gaze deformation variation 为 $\boldsymbol{\delta}_e$,论文用回归函数 $\mathcal{K}$ 学习二者关系:
推理时用它修正生成 deformation:

实验配置:先看结果是在什么条件下得到的
论文的实验配置需要单独看,否则很容易误读实时性。训练侧,作者收集并清洗了约 50 小时 broadcast scene videos,覆盖 330 个 identities,平均视频长度约 150 秒;模型用 8 张 NVIDIA A100 GPU 训练,batch size 1024,Adan optimizer,learning rate 为 1e-4,weight decay 为 0.02,训练 500 epochs。训练样本按 25 fps 对齐,采样 80 帧也就是 3.2 秒片段训练 DiT。推理侧,RTF/FFD 测试环境是 12-core Intel Xeon Platinum 8369B CPU @ 2.90GHz、1 张 NVIDIA A100 GPU 和 100G memory;因此这些实时指标不能直接等价外推到消费级 GPU。论文没有披露总 wall-clock 训练时间,这一点需要明确记住。#Li-et-al.-2025
| 配置项 | 论文披露值 | 解读 |
|---|---|---|
| 训练数据 | 约 50 小时、330 identities、平均 150 秒视频 | 内部清洗数据,限制严格复现 |
| 训练硬件 | 8 × NVIDIA A100 GPU | 训练成本不低,论文未披露总训练耗时 |
| 优化配置 | Adan,lr 1e-4,weight decay 0.02,batch size 1024,500 epochs | 这些配置决定 motion DiT 的收敛条件 |
| 训练片段 | 25 fps 对齐,$L=80$ 帧,约 3.2 秒 | 片段长度影响口型、头动和跨片段连续性 |
| 推理测试环境 | 12-core Xeon Platinum 8369B CPU、1 × A100、100G memory | RTF/FFD 是在服务器级环境下测得 |
主实验:Talk9 与 HDTF100
论文主要在 Talk9 和 HDTF100 上做定量对比。Talk9 上,Ditto-s10 的 FID 为 17.060、FVD 为 231.182、CSIM 为 0.861、Sync-C 为 8.111、RTF 为 0.635。值得注意的是,Ditto-s10 的 Sync-C 甚至略高于 Ditto-s50,说明在这个运动空间里,10 步去噪已经能保留足够质量。相比之下,EchoMimic、Hallo、Hallo2 的 RTF 分别是 35.528、53.082、56.838,远远不能实时。#Li-et-al.-2025
| Method | FID↓ | FVD↓ | CSIM↑ | Sync-C↑ | Sync-D↓ | RTF↓ |
|---|---|---|---|---|---|---|
| MuseTalk | 21.445 | 436.862 | 0.807 | 5.586 | 8.400 | 2.248 |
| EchoMimic | 42.554 | 395.754 | 0.840 | 5.733 | 9.204 | 35.528 |
| Hallo2 | 22.899 | 245.236 | 0.806 | 7.737 | 7.608 | 56.838 |
| Ditto-s50 | 17.254 | 219.368 | 0.864 | 8.069 | 7.114 | 2.121 |
| Ditto-s10 | 17.060 | 231.182 | 0.861 | 8.111 | 7.291 | 0.635 |
HDTF100 上,Ditto 的 FVD 降到 134.640,明显低于 Hallo2 的 239.517;SyncC 达到 8.939,也高于对比方法。这个结果支持论文的核心论点:motion representation 不仅让速度变快,也降低了 diffusion 学习难度,改善跨帧连续性和身份保持。

消融:哪些组件最关键
| Setting | FID↓ | FVD↓ | CSIM↑ | SyncC↑ | SyncD↓ | 解读 |
|---|---|---|---|---|---|---|
| Full Model | 17.254 | 219.368 | 0.864 | 8.069 | 7.114 | 基准 |
| w/o C-kp | 17.438 | 261.693 | 0.849 | 6.932 | 8.476 | 身份几何适配变差,动态质量和同步下降 |
| w/o Emo | 23.036 | 324.078 | 0.792 | 6.310 | 8.990 | 只靠音频学表情更难,质量和身份一致性都掉 |
| w/o Ada-w | 18.978 | 588.821 | 0.844 | 0.289 | 14.992 | 姿态/表情收敛严重失衡,几乎破坏同步 |
局限:自然性仍有代价
用户研究里,Ditto 在 visual quality 和 lipsync 上分别达到 84.0% 与 80.7%,明显领先 EchoMimic、Hallo、Hallo2;但在 naturalness of facial expressions and head movement 上,Ditto 为 48.7%,低于 Hallo2 的 59.3%。论文解释说,motion representation 可能削弱部分 high-frequency motion information。这个局限很重要:紧凑运动空间提升了速度和可控性,但也可能压掉一些微小而真实的自然抖动、表情细节和说话节奏变化。

Ditto 的 GitHub 仓库公开在 antgroup/ditto-talkinghead。README 显示主分支是 inference branch,训练代码在 train 分支;模型权重托管在 HuggingFace。仓库提供 TensorRT 与 PyTorch 两种推理路径,但论文中的实时结果依赖 A100、TensorRT 8.6.1 以及 Ampere Plus 兼容 engine,这一点对复现速度很关键。
| 工程要素 | README 信息 | 对复现的含义 |
|---|---|---|
| 环境 | CentOS 7.2、A100、Python 3.10、TensorRT 8.6.1 | 实时性能强依赖 GPU 与 TensorRT 版本 |
| 模型文件 | ONNX、TensorRT engine、PyTorch weights、cfg pkl | 推理链路模块化,便于替换 engine 或调试 PyTorch |
| 推理入口 | inference.py,输入 audio、source image、cfg、data_root | 适合快速验证单图 + 音频生成效果 |
| 训练代码 | train branch,README 标注可能与论文版本略有差异 | 能研究训练细节,但严格论文复现实验仍需谨慎 |
复现注意
论文训练数据是约 50 小时、330 个 identities 的内部清洗数据;实时指标基于 A100 + TensorRT。开源推理代码能帮助理解工程链路,但不能直接保证在消费级 GPU 上得到同等 RTF 与 FFD。
从代码角度看,Ditto 对数字人工程最大的启发,是把系统拆成可替换的模块:音频特征、motion generator、renderer、stitching/full-body 输出都可以独立优化。相比一个端到端视频扩散大模型,这种模块化系统更容易做延迟预算、降级策略和局部质量修复。
如果从产品视角看,Ditto 说明了一件事:实时数字人的核心不只是“生成质量”,而是“可预测地按时生成”。用户会容忍一点点画质损失,却很难容忍首帧等待、口型错位、眼神乱飘和无法控制的表情。Ditto 把生成问题约束到 motion space,牺牲了一部分端到端视频扩散的自由度,但换来了延迟、控制和可调试性。
本文要点复盘
- 核心问题:扩散式 talking head 质量提升明显,但慢且不可控,难以进入实时交互。
- 核心方案:用 LivePortrait 风格 motion space 作为扩散目标,Conditional DiT 生成运动,renderer 保留身份与纹理。
- 关键工程:HuBERT streaming、10-step DiT、TensorRT、appearance cache、segment-wise fusion。
- 实验结论:RTF 与 FFD 已满足实时交互要求;消融显示 emotion、canonical keypoints 和 adaptive weights 都非常关键。
- 主要局限:紧凑运动表示可能削弱高频自然性;训练数据和硬件条件限制严格复现。
对后续工作而言,一个自然方向是把 motion space 做得更分层:低频头姿、嘴型、眼神、微表情分别用不同频带或不同控制头建模,既保留 Ditto 的实时优势,又减少高频自然性的损失。另一个方向是把控制接口产品化:把 gaze、emotion、pose、regional constraints 暴露为可配置 API,让上层对话系统能根据语义和场景动态控制数字人状态。
参考来源
- Li, Tianqi, Ruobing Zheng, Minghui Yang, Jingdong Chen, and Ming Yang. “Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis.” ACM MM 2025. arXiv:2411.19509
- Xu, Sicheng et al. “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time.” 2024. arXiv:2404.10667
- Guo, Jianzhu et al. “LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control.” 2024. arXiv:2407.03168
- Ant Group. “ditto-talkinghead.” GitHub repository
- Ditto Project Page. Project website