8 个 Token 搞定规划
想象一下,你走进一个陌生的商场,想去某个店铺。你不会在脑中逐像素地记住每一块地砖和每一盏灯的位置——你记住的是"向左转、经过中庭、第二个通道右转"。这种抽象的空间表征,就是人类在复杂环境中高效导航的秘密 #Kim et al., 2026。
在人工智能领域,这种能力被称为世界模型(World Model)——一个能够模拟环境动态的神经网络。它在强化学习中扮演着关键角色:通过"想象"未来状态,智能体可以在不与真实环境交互的情况下进行规划和决策 #Ha et al., 2018。
然而,现有的世界模型面临一个尖锐的矛盾:感知保真度 vs 规划效率。
当前的视觉生成模型(如 Stable Diffusion 的 SD-VAE)会将每帧图像编码为 784 个 token。一个最先进的导航世界模型 NWM(Navigation World Model),使用这些 token 进行单次轨迹优化需要 3 分钟的计算时间 #Bar et al., 2025。当规划需要实时响应时,3 分钟是不可接受的。
CompACT(Compact Action-Conditioned Tokenizer)的答案直接而有力:既然规划不需要像素级精度,那就把压缩推到极致。它将每帧图像压缩到仅仅 8-16 个离散 token(约 128-256 bits),同时在世界模型规划中达到与 784-token 基线相当的精度——40 倍的加速。
反直觉的洞察
极端压缩不是一种损失——它迫使世界模型学习更抽象、与动作直接相关的表示。当模型无法依赖像素级细节时,它必须学会理解"发生了什么"而非"看到了什么"。
Token 数量的平方代价
世界模型通常基于注意力架构(如 DiT、Transformer),其计算复杂度随 token 数量 $N$ 呈二次方增长 #Peebles et al., 2023。这意味着:
784 个 token 的平方是 614,656,而 8 个 token 的平方只有 64——差了四个数量级。在每次 rollout 需要处理数百帧的规划场景中,这种差距被急剧放大。
感知-规划目标错配
传统的图像 tokenizer 设计目标很明确:最小化重建误差。SD-VAE #Rombach et al., 2022、VQGAN #Chang et al., 2022 都力求输出与输入尽可能一致——纹理、光照、阴影、反射,一个都不能少。
但规划需要的是什么呢?物体在哪、空间布局如何、什么在移动。这些信息量远小于完整的图像熵。
NWM 的 3 分钟困境
论文 #Kim et al., 2026 给出了一个具体的基准:NWM 使用 SD-VAE(784 tokens)进行规划时,单次轨迹优化耗时 178.78 秒(约 3 分钟)。而补充材料中的延迟分解显示,其中 99.2% 的时间消耗在模型 rollout 上——即不断前向传播预测未来状态的过程。
这 3 分钟里,真正花在优化算法上的时间微乎其微。瓶颈赤裸裸地指向 token 数量。
| Tokenizer | Token 数 | 规划延迟 | 相对 NWM |
|---|---|---|---|
| SD-VAE | 784 | 178.78 s | 1× |
| FlexTok | 64 | 16.68 s | 10.7× |
| CompACT | 16 | 5.78 s | 30.9× |
| CompACT | 8 | 4.83 s | 37.0× |
CompACT 的整体架构分为三个阶段,如下图所示。
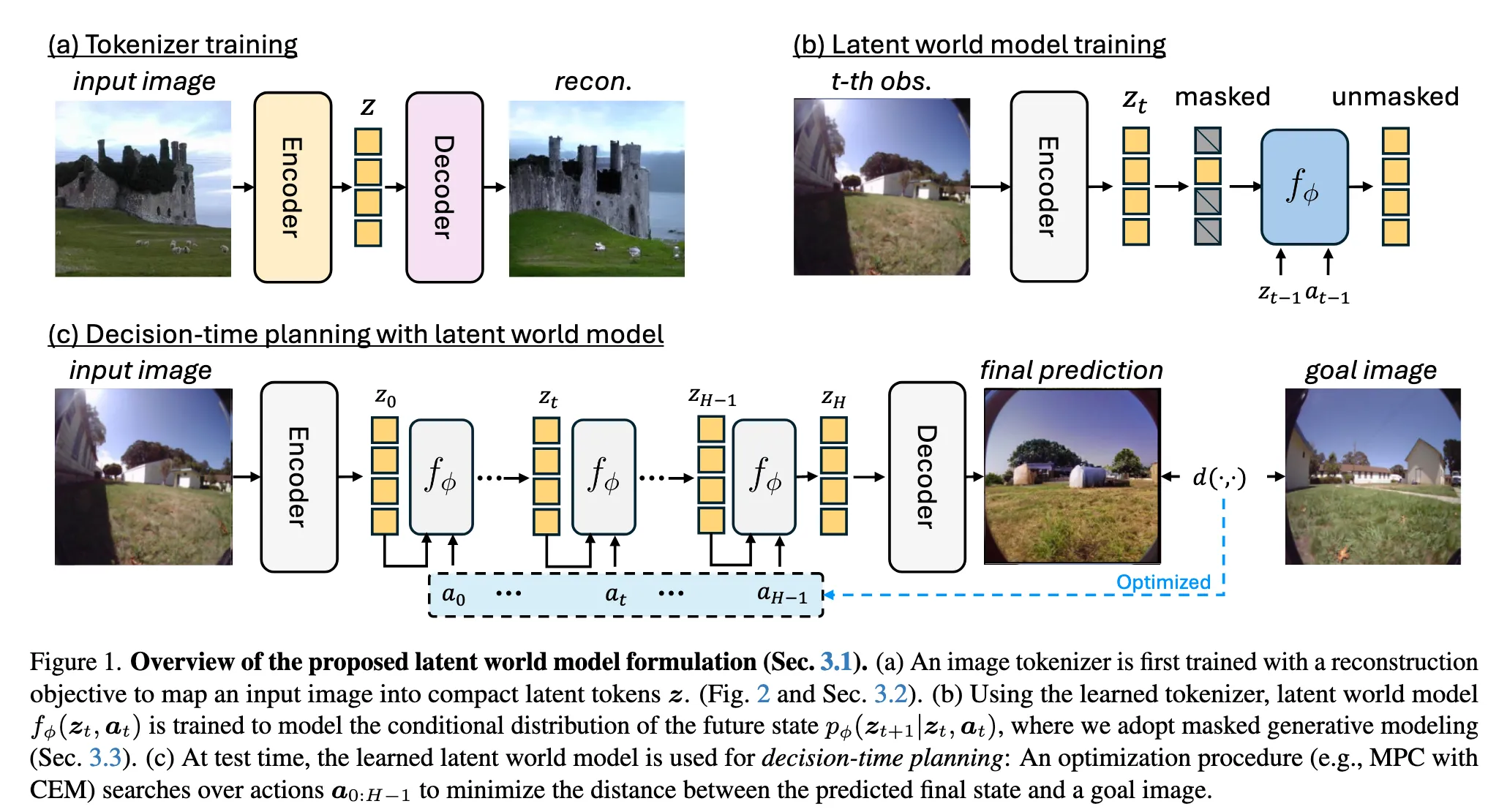
3.1 语义编码器 Ecompact
编码器的核心设计哲学:用冻结的语义特征,而非端到端训练的重建特征。
编码器架构
输入图像 $\mathbf{o}$ → DINOv3-B(冻结)→ 语义 patch 特征 → Latent Resampler(交叉注意力)→ FSQ 量化 → 离散 token $\mathbf{z}$
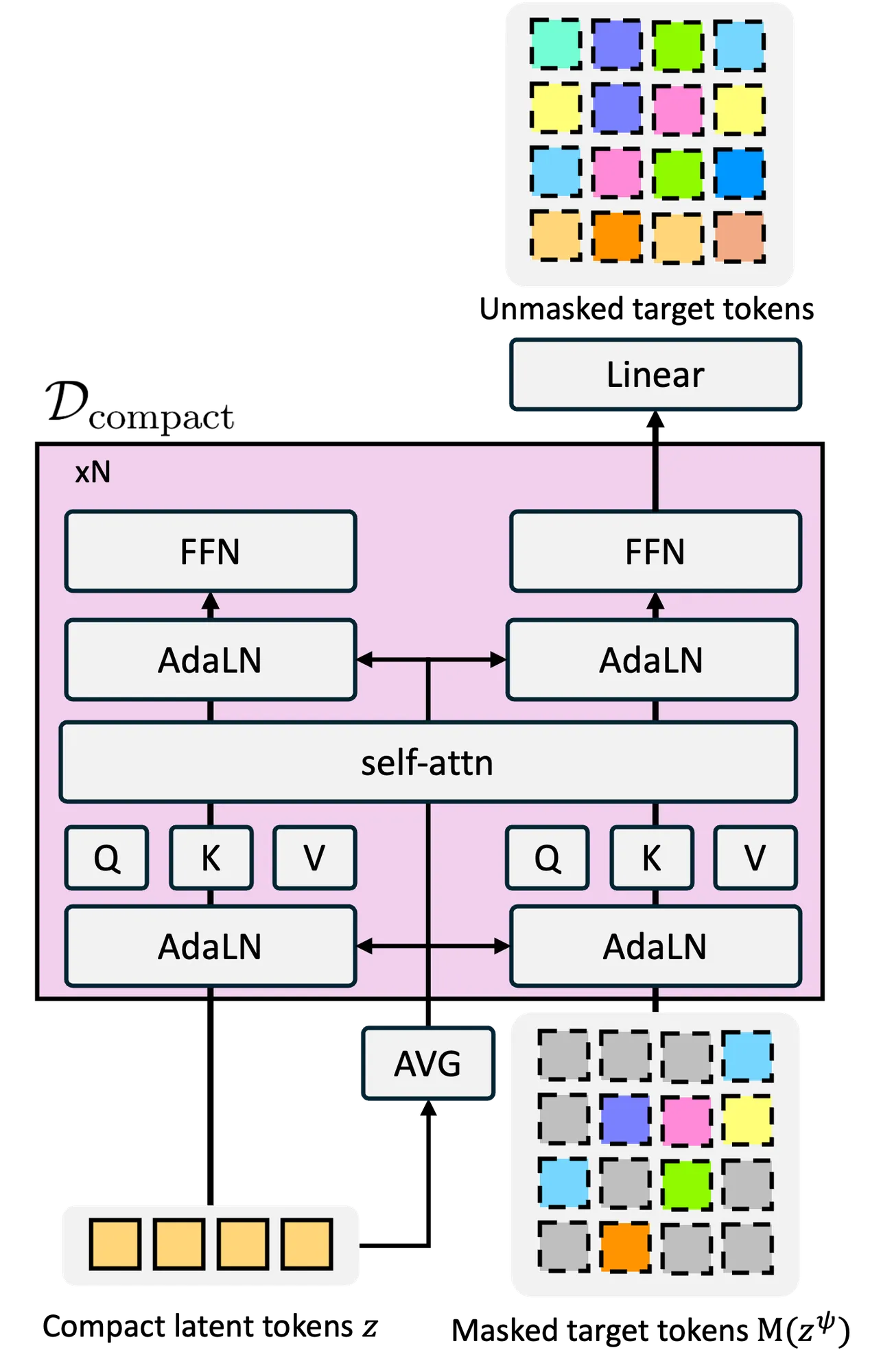
3.2 生成式解码器 Dcompact
从 8-16 个 token 直接重建像素是一个病态问题——信息瓶颈使确定性解压不可能。CompACT 的应对是:不解压,而是生成。
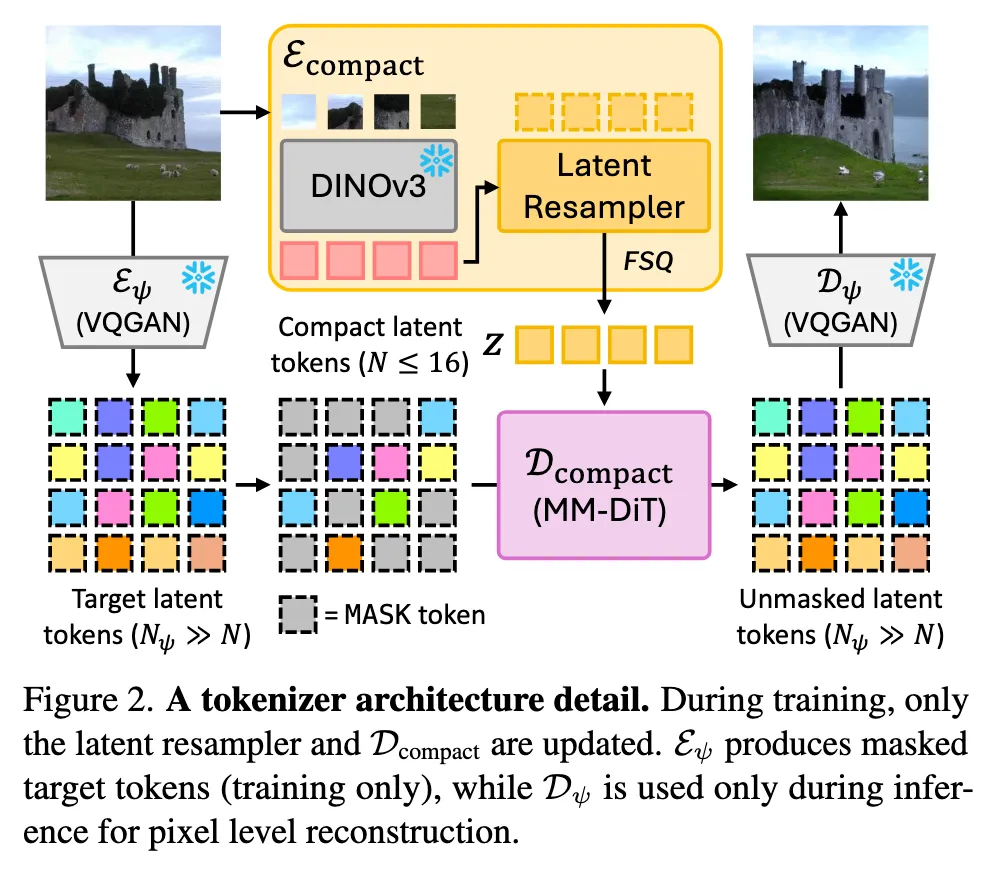
生成式解码的策略是引入一个中间表示——使用 MaskGIT-VQGAN #Chang et al., 2022 的 latent tokens($N_\psi = 196$ tokens)作为目标。具体来说:
- 编码:MaskGIT-VQGAN 的编码器 $\mathcal{E}_\psi$ 将图像编码为 196 个 token $\mathbf{z}^\psi$,这些 token 包含了紧凑 token 丢弃的高频细节
- 掩码生成:解码器 $\mathcal{D}_\text{compact}$ 以紧凑 token $\mathbf{z}$ 为条件,学习从掩码状态恢复 $\mathbf{z}^\psi$
- 像素重建:MaskGIT-VQGAN 的解码器 $\mathcal{D}_\psi$ 将重建的 196 个 token 解码为像素图像
训练目标是最小化掩码 token 的负对数似然:
其中 $M(\cdot)$ 表示随机掩码操作。注意:Tokenizer 的训练不涉及像素级重建损失——完全在潜空间中进行。
推理时,$\mathcal{D}_\text{compact}$ 从全部掩码开始,按置信度迭代 unmask(16 步采样,采用余弦调度),最终通过 $\mathcal{D}_\psi$ 重建像素。
| 超参数 | Tokenizer | Latent Resampler | Dcompact |
|---|---|---|---|
| 优化器 | AdamW ($\beta_1$=0.9, $\beta_2$=0.999) | — | — |
| 学习率 | 1e-4, Cosine + 10K warmup | — | — |
| Weight Decay | 0.01 | — | — |
| ImageNet 训练步数 | 500K | — | — |
| Batch Size | 512 | — | — |
| 深度 | — | 5 层 | 16 层 |
| 维度/注意力头数 | — | 768/8 | 1024/8 |
总参数量 775M(含 Ecompact、Dcompact、Dψ)[见补充材料]。Dcompact 采用 MM-DiT 架构 #Esser et al., 2024——一种针对多模态输入设计的 DiT 变体,包含两个并行处理流:一个处理 compact token,另一个处理 target token,通过自注意力融合。
范式转变
从"精确重建"到"条件生成"的转变,是 CompACT 突破信息瓶颈的关键。紧凑 token 只"提示"场景的语义骨架,解码器"想象"出合理的高频细节。这类似于人类从简笔画理解场景——不需要所有像素,就能想象出完整的画面。
3.3 离散化的几何意义
FSQ 的 level 配置 $[8,8,8,5,5,5]$ 产生了约 $2^{16}$ 的码本大小。这不仅是量化精度的选择,更巧妙的是:FSQ 的 radix 表示保留了嵌入空间的几何结构。这意味着在离散空间中计算两个 token 的 L1 距离是有意义的——它反映了语义差异的连续度量。
这一性质在规划中的 cost function 里得到了充分利用:在潜空间中直接计算距离(跳过解码)可实现近 80 倍的规划加速。
有了 CompACT Tokenizer,接下来的问题就是:如何在 8-16 个 token 的离散潜空间中训练世界模型?
4.1 潜空间世界模型形式化
世界模型在观测空间中的定义是:
将其映射到潜空间后,得到:
其中 $\mathbf{z}_t = \mathcal{E}_\text{compact}(\mathbf{o}_t)$。这里的 token 数量 $N$ 直接决定了计算成本——$N \le 16$ 意味着每步 rollout 的计算量仅为 784-token 基线的 $1/2400$。
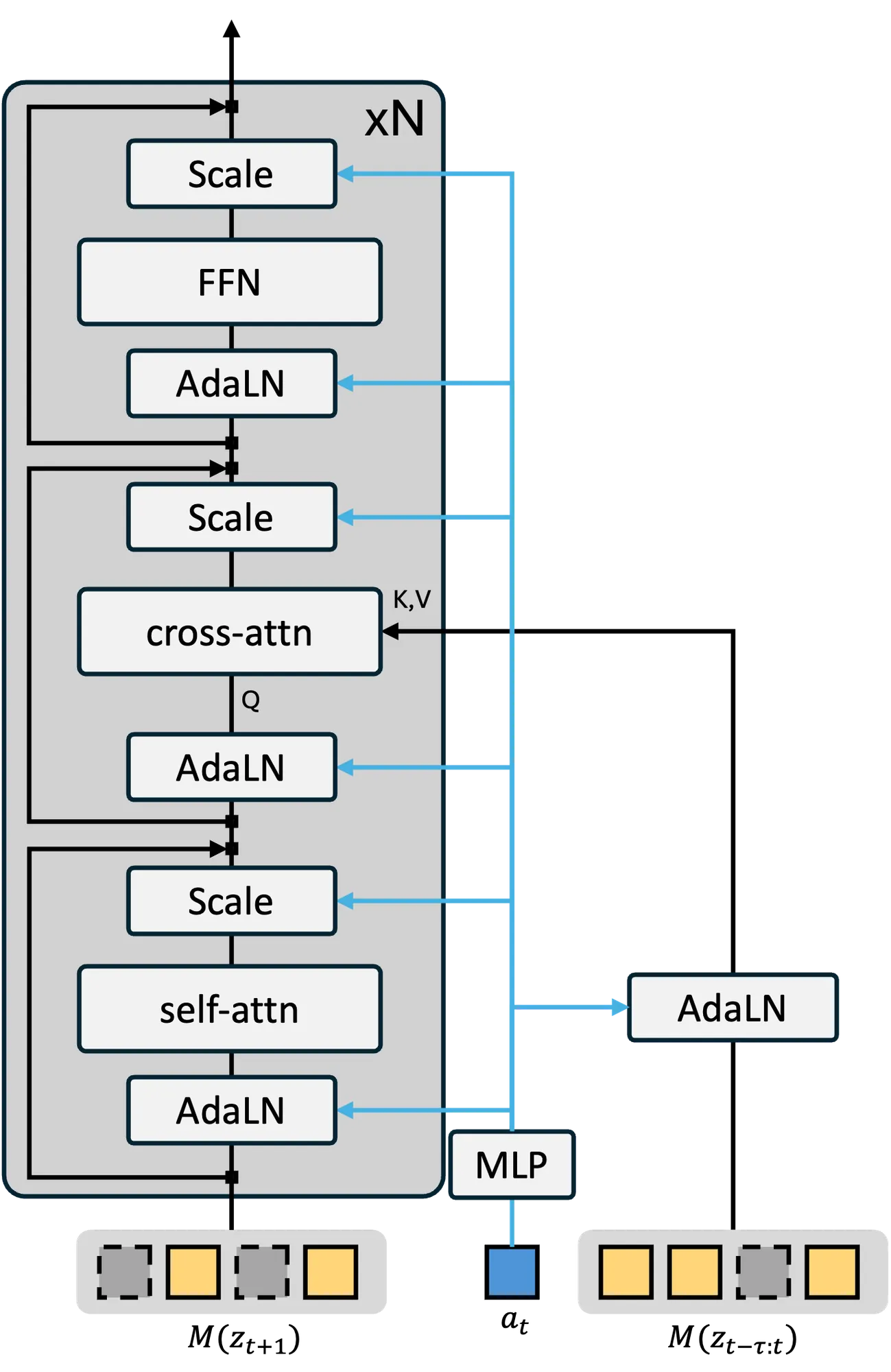
4.2 世界模型训练
训练目标同样采用掩码生成建模:
World Model 训练在 RECON/SCAND/HuRoN(导航)或 RoboNet(操作)数据集上进行。RoboNet 微调阶段使用 100K 步、256 步预热、学习率 1e-4 的 cosine 调度 [见补充材料]。
论文探索了两种世界模型架构,分别适配不同的任务:
| 任务 | 架构 | 参数量 | 特点 |
|---|---|---|---|
| 导航(RECON) | 自回归 DiT(CDiT) | 243M | 12 层, 768 维, 固定历史窗口 $\tau=4$ |
| 机器人操作(RoboNet) | Block-Causal Transformer | 270M | 16 层, 1024 维, 并行预测 14 帧 |
History Masking:从 Diffusion Forcing 的启发
训练时随机 mask 历史窗口中的 token,借鉴了 Diffusion Forcing 的思想 #Chen et al., 2024。这使得模型在不同噪声水平下都能进行鲁棒的时序依赖建模。推理时使用 20% 的 mask 率,消融实验证明 history masking 将规划精度从 ATE 1.480 提升到 1.330。
4.3 决策时规划
训练完成后,世界模型通过 MPC with CEM(交叉熵方法)进行规划:
- 从当前观测 $\mathbf{o}_0$ 编码得到 $\mathbf{z}_0$
- 初始化候选动作序列 $\mathbf{a} = [\mathbf{a}_0, \ldots, \mathbf{a}_{H-1}]$
- 使用世界模型 rollout 预测未来潜状态序列 $\mathbf{z}_1, \ldots, \mathbf{z}_H$
- 计算 cost:$C(\mathbf{a}) = d(\hat{\mathbf{o}}_H, \mathbf{o}_\text{goal})$
- 优化 $\mathbf{a}^* = \arg\min_\mathbf{a} C(\mathbf{a})$
- Pixel 空间:LPIPS 距离(需要解码,精度略高)
- Latent 空间:FSQ 反量化后的 L1 距离(跳过解码,速度提升近 80×)
潜空间 cost function 虽精度小幅下降(ATE 1.330 vs 1.379),但它将单次规划延迟从 5.78s 降至 2.15s——相比 SD-VAE 的 178.78s 是 约 83 倍的加速,这是一个在实际部署中极具吸引力的权衡。
5.1 重建性能:16× 更少 token,接近的重建质量
在 ImageNet 验证集上的重建实验,展示了 CompACT 的压缩能力:
| 方法 | Token 数 | rFID ↓ | IS ↑ |
|---|---|---|---|
| SD-VAE | 1024 | 0.64 | 223.8 |
| MaskGIT-VQGAN | 256 | 1.83 | 186.7 |
| CompACT | 16 | 2.40 | 209.0 |
| CompACT | 8 | 3.21 | 207.5 |
5.2 导航规划:40 倍加速,精度可比
这是论文最核心的实验——在 RECON 基准上的目标条件视觉导航:
| Tokenizer | Token 数 | ATE ↓ | RPE ↓ | 延迟 ↓ |
|---|---|---|---|---|
| SD-VAE | 784 | 1.262 | 0.354 | 178.78 s |
| FlexTok | 64 | 1.484 | 0.400 | 16.68 s |
| FlexTok | 16 | 1.625 | 0.446 | 14.48 s |
| CompACT | 16 | 1.330 | 0.390 | 5.78 s |
| CompACT | 8 | 1.373 | 0.401 | 4.83 s |
这个表格承载了论文的核心论点,值得深入解读:
- CompACT 16-token vs SD-VAE 784-token:ATE 差距仅 5.4%(1.330 vs 1.262),但延迟从 178.78s 降至 5.78s——约 31 倍的加速
- CompACT 8-token vs FlexTok 64-token:用 8 倍更少的 token 取得了更好的规划精度(ATE 1.373 vs 1.484),延迟仅为后者的 1/3
- SCAND 数据集上的一致表现:ATE 1.391 vs 1.578(FlexTok-64),验证了方法的泛化能力
核心结论
极端压缩在精心设计的架构下不仅能保持规划性能,还可以超越使用更多 token 的方法。压缩不是妥协,而是一种精炼。
5.3 动作条件视频预测:3 倍更好的动作建模
在 RoboNet 机器人操作数据集上,论文验证了 CompACT token 的动作相关信息保留能力:
| Tokenizer | Token 数 | APE ↓ | 延迟 |
|---|---|---|---|
| MaskGIT-VQGAN | 256 | 0.3383 | 3.826 s |
| CompACT | 16 | 0.1122 | 0.740 s |
APE(Action Prediction Error)是一个特别巧妙的指标:它使用逆动力学模型(IDM)来评估生成的视频帧中包含多少动作相关信息。如果模型生成的帧能准确反映驱动它的动作,说明 token 保留了规划必要的动态信息。
CompACT 的 APE 仅为 MaskGIT-VQGAN 的 1/3,同时生成速度提升 5.2 倍。这说明 CompACT 的模块化 token 更自然地捕捉了动态物体(末端执行器、操作目标)的状态变化——这是规划真正需要的信息。
5.4 消融实验:剥离每一层设计
编码器设计:| 变体 | rFID | 影响 |
|---|---|---|
| 完整模型(冻结 DINOv3) | 2.40 | 基线 |
| 微调 DINOv3 | 5.22 | ← 冻结特征提取器至关重要 |
| 从头训练 ViT | 7.28 | ← 缺少预训练语义先验 |
| 移除生成式解码 | 28.80 | ← 生成式解码不可或缺 |
- History masking:ATE 从 1.480 改善到 1.330(提升 10.1%)
- Latent space cost function:相比 pixel 空间,精度小幅下降但速度提升近 80×
- 不同骨干网络:SigLIP-2、MAE、DINOv3 均可获得良好性能,方法不依赖特定预训练模型
6.1 在地图上的位置
| 方法 | Token 类型 | Token 数 | 规划适用 | 延迟 |
|---|---|---|---|---|
| SD-VAE #Rombach et al., 2022 | 连续 | 784 | ✅ | 178.78 s |
| MaskGIT-VQGAN #Chang et al., 2022 | 离散 | 256 | ⚠️ | 3.83 s |
| FlexTok #Bachmann et al., 2025 | 离散 | 64 | ✅ | 16.68 s |
| CompACT #Kim et al., 2026 | 离散 | 8-16 | ✅ | 4.83 s |
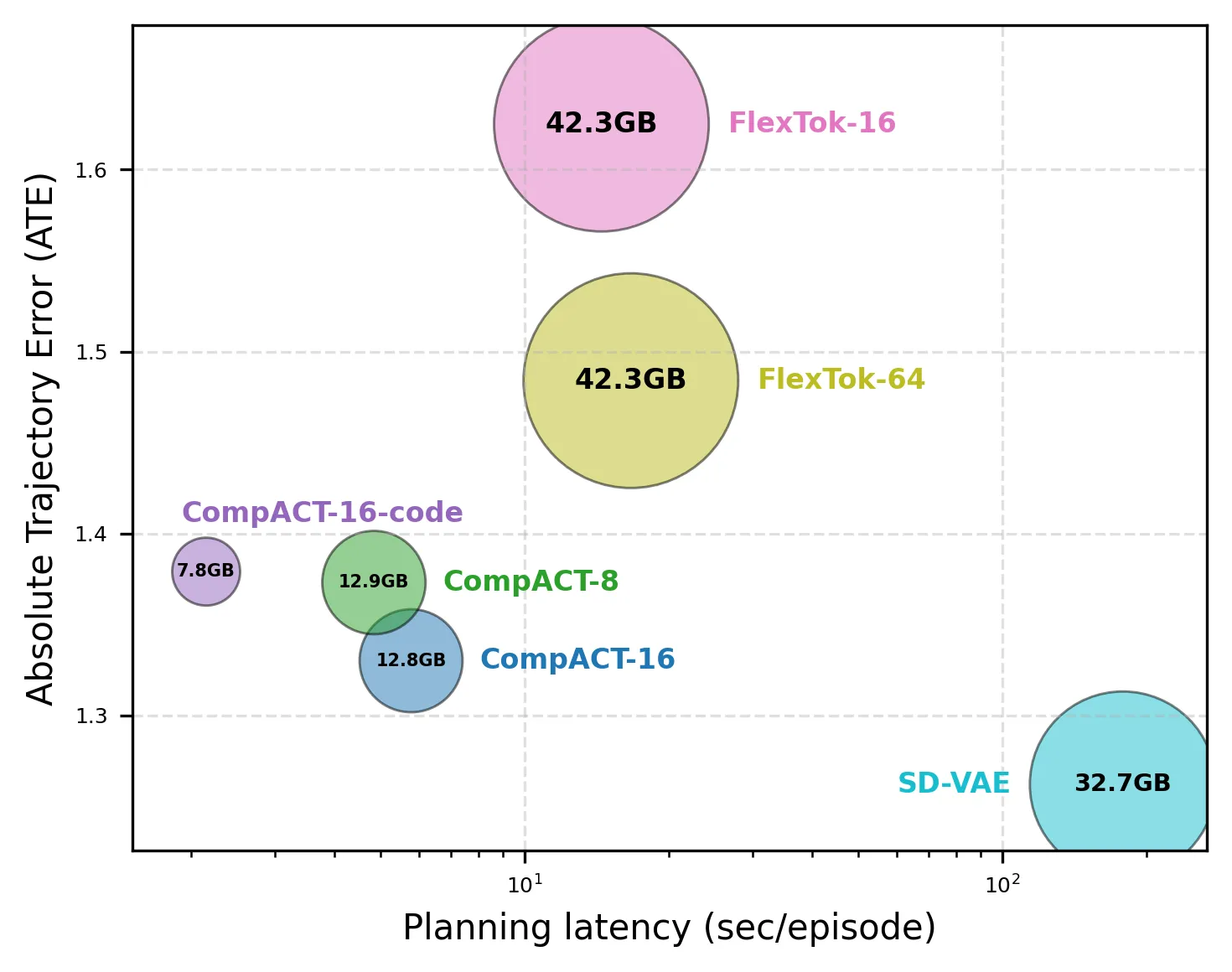
CompACT 位于 Token 压缩和规划效率的帕累托前沿上——它用最少的 token 换来了最好的规划精度和延迟组合。
6.2 局限性
- 重建质量不足:极端压缩导致纹理细节"幻觉化",不适合需要像素级精度的任务
- 任务范围有限:主要在导航(RECON)和简单操作(RoboNet)上验证,复杂机器人操作尚未测试
- 固定 token 预算:8 和 16 是预定义值,没有根据场景复杂度动态调整的机制
6.3 个人启发
- 表征学习的核心在于任务适配:Tokenizer 的设计不应该仅以重建质量为目标,下游任务的目标函数应该反向传播到表征设计中去。CompACT 为"规划专用 tokenizer"树立了一个范本。
- 预训练模型的复用哲学:冻结 DINOv3 的使用揭示了预训练基础模型的双重价值——不仅提供特征,其已学习的语义抽象本身就是"规划友好"表征的强先验。这种"借用而非重新学习"的范式值得借鉴。
- 离散表征 + 并行解码的工程优势:CompACT 采用离散 token + 掩码生成建模,在速度上显著优于连续潜空间 + 扩散模型的方案。在实时性要求高的场景中,这是一个值得优先考虑的工程选择。
- 模块化 token 的涌现性质:注意力可视化显示每个 compact token 自然关注语义一致的物体/区域——这种"无监督的物体分解"是冻结 DINO 特征与交叉注意力结构的涌现性质,为场景理解提供了新的视角。
6.4 开放问题
读完后,我认为以下几个方向特别值得跟踪和探索:
- 自适应 token 预算:能否根据场景复杂度动态调整 token 数量?简单走廊用 4 token,复杂场景用 16 token?
- 3D-aware 的极端压缩:如果 tokenizer 能理解 3D 结构(而非 2D 像素),压缩效率和规划精度能否再上一个台阶?
- 理论边界:从信息瓶颈角度,能否形式化证明"规划最优压缩率"的存在?8 是魔法数字还是可以更少?
参考来源
- Kim, D. et al. (2026). Planning in 8 Tokens: A Compact Discrete Tokenizer for Latent World Model. CVPR 2026. arXiv:2603.05438
- Bar, A. et al. (2025). Navigation World Models. ICLR 2025.
- Chang, H. et al. (2022). MaskGIT: Masked Generative Image Transformer. CVPR 2022.
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022.
- Bachmann, R. et al. (2025). FlexTok: Flexible Token Lengths for Image Generation. arXiv:2502.08897.
- Simeoni, O. et al. (2025). DINOv3: Self-Supervised Vision Transformers at Scale. ICLR 2025.
- Mentzer, F. et al. (2023). Finite Scalar Quantization: VQ-VAE Made Simple. ICLR 2023.
- Peebles, W. et al. (2023). Scalable Diffusion Models with Transformers. ICCV 2023.
- Ha, D. et al. (2018). World Models. NeurIPS 2018.
- Chen, B. et al. (2024). Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. NeurIPS 2024.
- Esser, P. et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML 2024.