VFHQ
视频人脸超分辨率(Video Face Super-Resolution, VFSR)旨在从低质量视频帧中恢复高保真的人脸图像——一个在视频通话增强、老视频修复和数字人训练中极为关键的技术。然而,截至 2022 年,这个领域面临着一个尴尬的结构性矛盾:单帧人脸 SR 已经能生成 1024×1024 的逼真人脸,而视频人脸 SR 的输出质量却远远落后。
问题的根源不在模型架构,而在数据。
现有 VFSR 方法几乎全部依赖 VoxCeleb1 #Nagrani et al., 2017 进行训练和评估。VoxCeleb1 最初是为说话人识别设计的,包含 1,251 位名人的视频片段,虽然空间分辨率可达 800×800,但内容普遍模糊,带有严重的视频压缩伪影。用这样的数据训练超分辨率模型,就像用低像素手机拍的照片去教一个画家如何画出高清肖像——模型不可避免地会保留甚至放大那些伪影。
与此同时,单帧人脸 SR 领域拥有 FFHQ #Karras et al., 2019(70,000 张 1024×1024 的高质量人脸图像),这使得 GFPGAN #Wang et al., 2021、GPEN #Yang et al., 2021 等方法能够恢复极其逼真的面部细节。但 FFHQ 是静态图像数据集,直接用于视频会导致帧间不一致——每帧独立处理的结果会在播放时产生闪烁和抖动。
VFHQ 的核心立场很清晰:要推动 VFSR 发展,首先需要一个兼具 FFHQ 级别单帧质量和 VoxCeleb 级别时序连贯性的视频数据集。
在深入 VFHQ 的构建方法之前,我们先看一组反直觉的实验结果,它会清楚地告诉你:为什么在 VoxCeleb1 上做评估是靠不住的。
PSNR 的陷阱
论文用同一个模型(BasicVSR #Chan et al., 2021)分别在 VoxCeleb1 和 VFHQ 上训练,然后在两个测试集上评估:
| 训练数据 | VoxCeleb-Test PSNR | VoxCeleb-Test SSIM | VFHQ-Test PSNR | VFHQ-Test SSIM |
|---|---|---|---|---|
| VoxCeleb1 | 43.367 | 0.9829 | 36.064 | 0.9410 |
| VFHQ | 42.760 | 0.9817 | 36.399 | 0.9429 |
这意味着,此前在 VoxCeleb1 上报告的 PSNR 数值可能严重失真。那些看似 43 dB 的"好成绩",实际上只是在衡量模型有多擅长复制低质量的 GT。
视觉差异一目了然


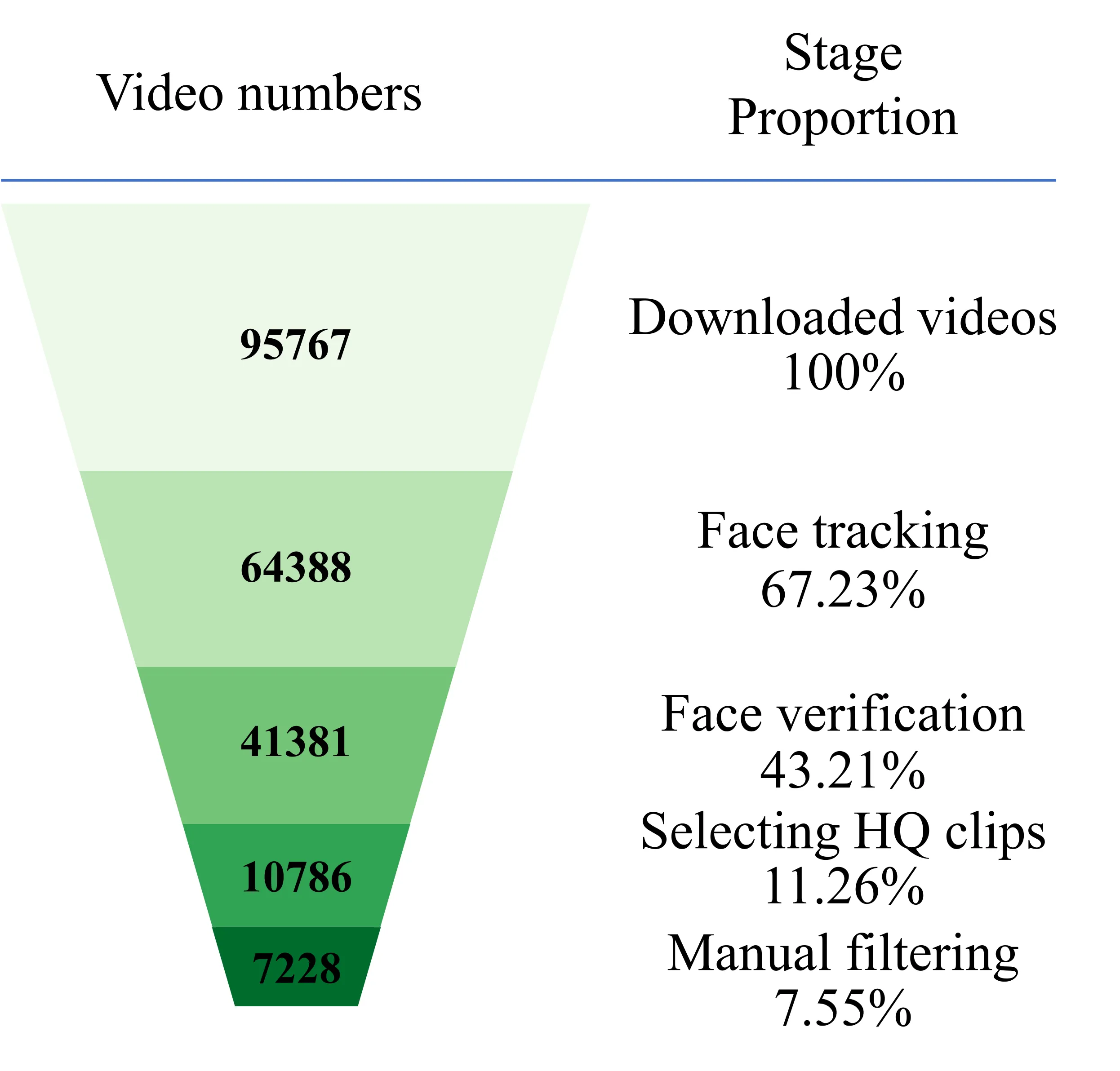
VFHQ 的核心贡献是一个可扩展的、自动化的数据收集 pipeline。它从 YouTube 视频出发,经过五个精心设计的过滤阶段,最终从 95,767 个原始视频中筛选出 16,827 个高质量人脸 clip——仅保留约 7.55%。
flowchart TD S1["Stage 1
YouTube 下载
95,767 videos"] --> S2["Stage 2
人脸追踪
RetinaFace + SORT"] S2 --> S3["Stage 3
身份验证
ArcFace L2 阈值 1.24"] S3 --> S4["Stage 4
质量筛选
HyperIQA ≥ 45"] S4 --> S5["Stage 5
人工兜底
5 帧抽检"] S5 --> OUT["16,827 clips
from 7,228 videos"] style S1 fill:#e8f4fd style S2 fill:#e8f4fd style S3 fill:#e8f4fd style S4 fill:#fff3e0 style S5 fill:#fce4ec style OUT fill:#e8f5e9
Stage 1 · YouTube 视频下载
数据源来自 VoxCeleb1(1,251 人)和 VGGFace2 #Cao et al., 2018(9,131 人)提供的名人名单。对每位名人,使用搜索关键词 "celebrity name + interview 4K" 在 YouTube 上检索,下载排名前 20 的视频。
选择 "interview" 是因为采访视频中人脸通常居中、正面、光照稳定;选择 "4K" 确保源视频分辨率足够高。这一简单但有效的策略保证了数据的基础质量。
Stage 2 · 人脸检测与追踪
对每帧使用 RetinaFace #Deng et al., 2019a 检测人脸边界框,过滤掉尺寸小于 500×500 的检测结果——这一阈值确保裁剪后的人脸具有足够的像素信息用于后续超分辨率训练。随后用 SORT #Bewley et al., 2016(Simple Online and Realtime Tracking)追踪算法将逐帧检测结果关联为连续轨迹。SORT 基于卡尔曼滤波预测目标位置,并用匈牙利算法做最优匹配,能在遮挡和快速运动下保持稳定追踪。只保留帧数在 100 到 2000 之间的 track:下限 100 帧确保 clip 有足够的时间跨度用于训练,上限 2000 帧避免过长的片段可能包含场景切换。
Stage 3 · 身份一致性验证
即使追踪保证了时间连续性,同一 track 仍可能出现身份切换(如采访中镜头切换到另一个人)。此阶段使用 ArcFace #Deng et al., 2019b 提取每个检测框的特征向量,计算帧间特征的 L2 距离(原文称为 "L2 similarity")。当距离 > 1.24 时判定为不同身份,在该位置切分 clip。切分后,如果子 clip 的帧数少于 100,也会被丢弃——这一步确保了每个 clip 不仅身份一致,而且有足够的时间长度用于训练。
Stage 4 · 质量筛选(核心阶段)
这是整个 pipeline 中最精密的质量控制环节,使用 HyperIQA #Su et al., 2020 无参考图像质量评估模型。
首先进行帧级过滤:连续超过 4 帧 AS 分数 < 42 时,在该处切断 clip。然后计算 clip 的平均分 $AS_{clip}$,要求 $AS_{clip} \geq 45$。两个阈值之间的差值(45 - 42 = 3)体现了"局部容忍但全局严格"的设计哲学:个别帧质量略低可以接受(视频中的瞬时模糊很正常),但整段平均质量必须达标。
最后,为了在质量和运动多样性之间取得平衡,使用综合评分选取每个视频的 top-3 clip:
Clip 综合评分公式
其中 $\alpha = 0.5$,$\beta = 0.2$。$\hat{M}_{clip}$ 是归一化后的 landmark 运动分数。
Landmark motion 通过 98 个人脸关键点(由 AWing #Wang et al., 2019 检测)的帧间位移计算:
Landmark Motion 与归一化
$M_{clip}$ 衡量面部运动幅度;归一化将运动值映射到与 HyperIQA 分数相当的量级(截距 42.5 位于帧阈值 42 和 clip 阈值 45 之间)。这种设计使得仅依据质量分选出的 clip 不会全是"大头照"式的静止视频。
Stage 5 · 人工兜底
作为自动化 pipeline 的最后安全网,均匀抽取 5 帧进行人工检查。只有全部 5 帧都明显低质量时才丢弃。这种宽松策略避免了过度剔除,但也意味着可能存在漏网之鱼——只要 5 帧中有 1 帧看起来还行就保留。
HyperIQA 的泛化问题
归一化公式的设计逻辑
一个自然的疑问是:为什么需要 $\hat{M}_{clip} = 0.25 \cdot M_{clip} + 42.5$ 这个看似随意的线性变换?答案在于量纲对齐。原始 landmark motion $M_{clip}$ 的数值范围与 HyperIQA 分数(0-100)不在同一量级,直接相加没有物理意义。截距 42.5 的选择非常精妙:它恰好位于帧级阈值 42 和 clip 级阈值 45 之间,意味着当 $M_{clip} = 0$(完全静止)时,$\hat{M}_{clip} = 42.5$,略低于 clip 级质量阈值。斜率 0.25 则压缩了运动分数的动态范围,确保运动项不会主导评分。从统计角度看,在论文报告的运动分布(large 23.6% / middle 32.2% / slow 44.2%)下,$\hat{M}_{clip}$ 大致落在 42-55 的区间,与 $AS_{clip}$ 的有效范围(45-70)有良好的重叠。
数据集特性总览
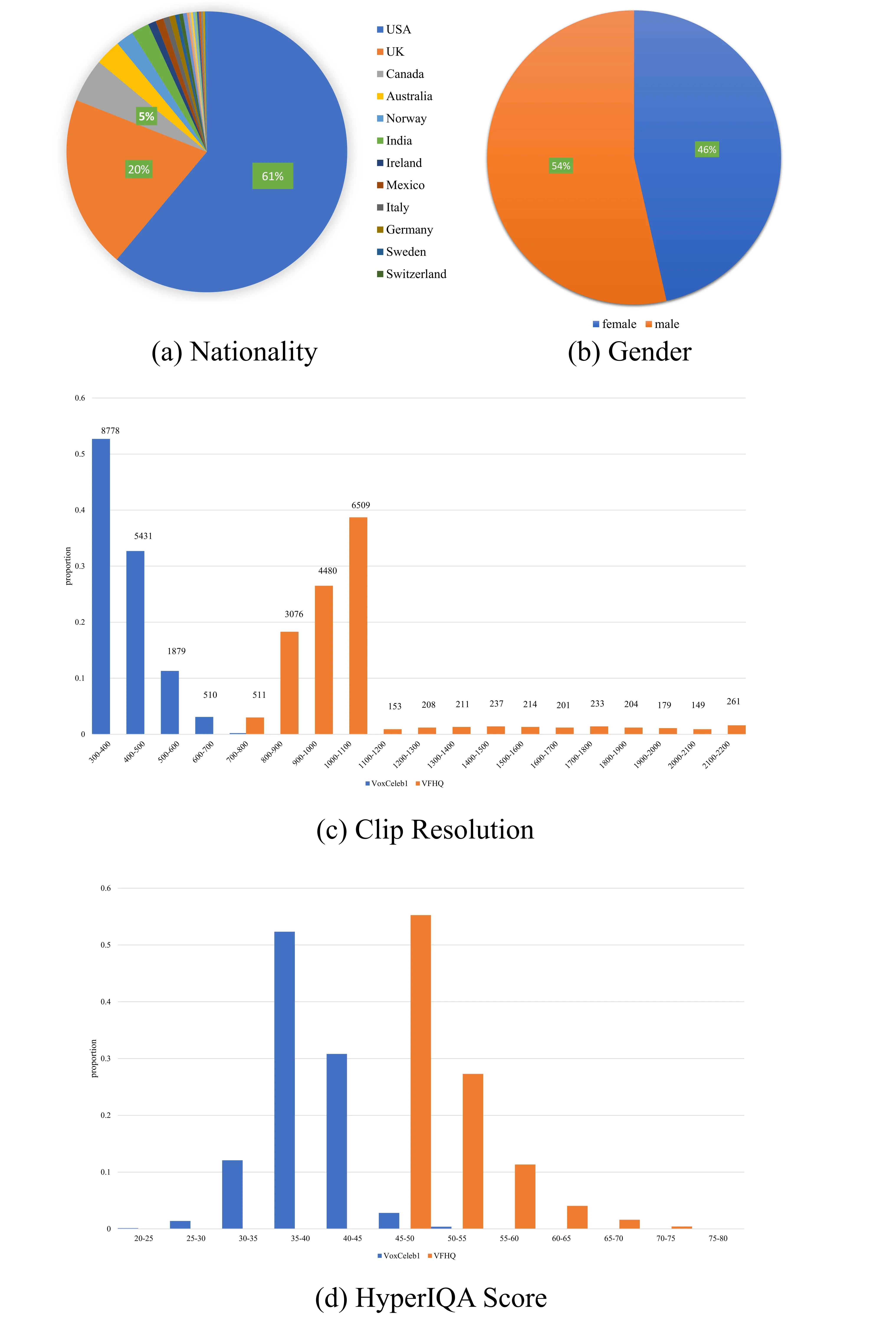
| 属性 | 值 | 备注 |
|---|---|---|
| 总 clips 数 | 16,827 | 来自 7,228 个视频 |
| 分辨率范围 | 700×700 ~ 1000×1000 | 接近 FFHQ 的 1024×1024 |
| 国籍多样性 | 20+ 国家 | — |
| 性别比例 | 大致均衡 | — |
| 运动分布 | 大 23.6% / 中 32.2% / 慢 44.2% | 按平均像素位移划分 |
| 原始爬取量 | 95,767 视频 | 保留率 7.55% |
VFHQ vs VoxCeleb1:训练数据质量的影响
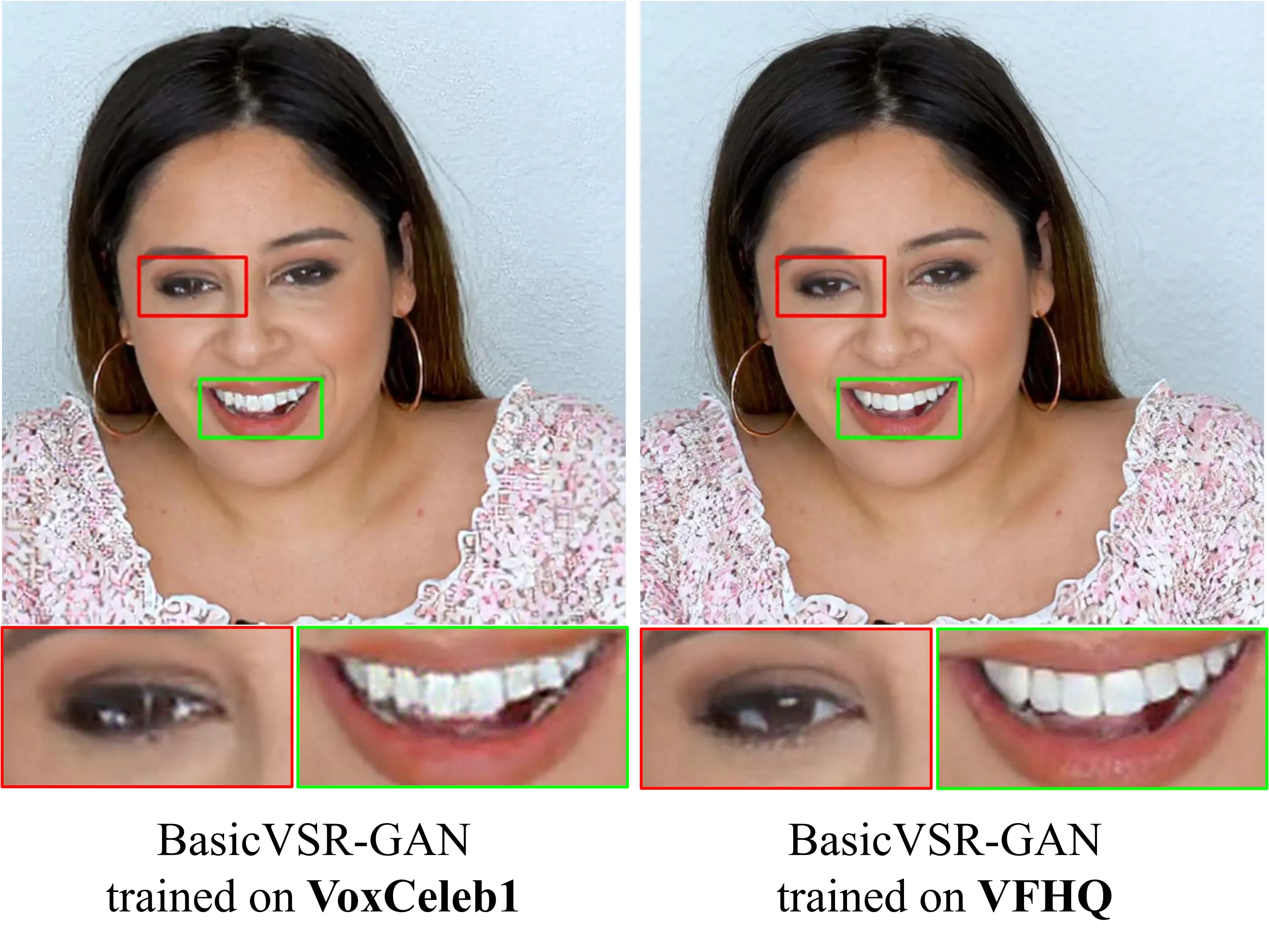
论文通过一系列视觉对比,清晰地展示了训练数据质量如何直接影响模型的输出质量。

当引入 GAN 训练(BasicVSR-GAN)时,差异更加明显:VoxCeleb1 训练的模型在牙齿区域产生伪影,而 VFHQ 训练的模型保持了完整的牙齿形状和忠实的眼睛细节。
VFHQ vs FFHQ:质量可比,但多了时序
为了验证 VFHQ 的单帧质量是否与 FFHQ 相当,论文分别在两个数据集上训练 ESRGAN #Wang et al., 2018,结果显示两者恢复的面部细节质量相当。这证明了 VFHQ 在单帧质量上已经达到了 FFHQ 的水准。

时序信息:消除帧间闪烁的关键
但 VFHQ 相对 FFHQ 的独特价值在于时序信息。论文通过一个直接对比揭示了这一点:将 ESRGAN(单帧方法)和 BasicVSR-GAN(多帧方法)分别应用于同一段视频——

量化实验进一步证实了这一点:
| 方法 | 输入帧数 | PSNR (dB) | SSIM |
|---|---|---|---|
| BasicVSR | L=1(退化为单帧) | 35.213 | 0.9293 |
| BasicVSR | L=7(多帧) | 36.258 (+1.045) | 0.9412 (+0.0119) |
基于 VFHQ,论文在两种退化设置下对多个 SOTA 方法进行了系统评测。所有实验将图像统一 resize 到 512×512 作为 HR,使用 ×4 下采样获得 LR。
Bicubic 退化(经典设置)
Bicubic 退化使用 MATLAB imresize 进行 ×4 下采样,是最经典的 SR 评估协议。
| 指标 | Bicubic | RRDB | EDVRM | BasicVSR | ESRGAN | EDVRM-GAN | BasicVSR-GAN |
|---|---|---|---|---|---|---|---|
| PSNR | 31.964 | 35.332 | 36.090 | 36.258 | 32.803 | 33.592 | 32.327 |
| SSIM | 0.8939 | 0.9302 | 0.9399 | 0.9412 | 0.8961 | 0.9089 | 0.8869 |

Blind 退化(真实世界设置)
Blind 退化模型模拟了更贴近真实场景的复合退化:
其中高斯模糊核 $\sigma \in [0.1, 10]$,下采样 $r = 4$,噪声 $\delta \in [0, 10]$(帧间变化),FFMPEG 压缩 $\text{crf} \in [18, 25]$。特别值得注意的是,论文使用 FFMPEG 而非 JPEG 来模拟压缩——因为视频编码引入的块效应和振铃效应与 JPEG 伪影有本质区别。#Xie et al., 2022
| 指标 | Bicubic | EDVRM | BasicVSR | EDVRM-GAN | BasicVSR-GAN | DFDNet | GFPGAN | GPEN |
|---|---|---|---|---|---|---|---|---|
| PSNR | 26.842 | 29.457 | 29.472 | 26.682 | 25.813 | 25.178 | 25.978 | 26.672 |
| SSIM | 0.7909 | 0.8428 | 0.8430 | 0.7638 | 0.741 | 0.7560 | 0.7723 | 0.7768 |
| LPIPS ↓ | 0.4098 | 0.3288 | 0.3309 | 0.3076 | 0.3214 | 0.4008 | 0.3446 | 0.3607 |
Blind 设置下所有方法的 PSNR 比 bicubic 下降约 6-7 dB(~36 → ~29),说明真实退化远比理想 bicubic 困难。BasicVSR 在 PSNR/SSIM 上仍最优,但与 EDVRM 的差距从 bicubic 下的 0.168 dB 缩小到 0.015 dB——复杂退化削弱了纯像素级优化的收益。EDVRM-GAN 在 LPIPS 感知指标上取得最优(0.3076),说明 GAN 方法在视觉质量上仍有优势。
MSE + GAN-prior 组合实验:pipeline 拼接的局限
一个直觉上合理的策略是:先用 MSE 方法(如 EDVRM)做初步恢复,再用 GAN-prior 方法(如 GFPGAN)提升面部细节。论文测试了这种两阶段组合:
| 指标 | EDVRM+GFPGAN | BasicVSR+GFPGAN | EDVRM-GAN(端到端) |
|---|---|---|---|
| PSNR | 27.879 | 27.868 | 26.682 |
| SSIM | 0.8198 | 0.8195 | 0.7638 |
| LPIPS ↓ | 0.3265 | 0.3266 | 0.3076 |
两个值得注意的发现:首先,两种组合方案的指标几乎相同(差异 < 0.01),说明 MSE 阶段的选择对最终结果影响极小——误差在第二阶段被 GFPGAN 的处理逻辑"覆盖"了。其次,尽管组合方案的 PSNR 更高(27.87 vs 26.68),但在感知质量(LPIPS)上却不如端到端训练的 EDVRM-GAN(0.3265 vs 0.3076),差距约 0.019。这说明两阶段 pipeline 存在误差累积和输入分布不匹配问题——GFPGAN 的 generative prior 在 EDVRM 输出上的分布与训练时的退化输入分布不同。
训练配置披露
| 配置项 | 值 | 披露状态 |
|---|---|---|
| HR 图像尺寸 | 512 × 512 | ✅ 论文披露 |
| SR 倍率 | ×4 | ✅ 论文披露 |
| LR 生成方式 | MATLAB bicubic / blind degradation | ✅ 论文披露 |
| 训练采样间隔 | {3:7}(增加运动多样性) | ✅ 论文披露 |
| 测试采样间隔 | 5 | ✅ 论文披露 |
| VFHQ-Test 规模 | 50 sequences(从 VFHQ 随机选取) | ✅ 论文披露 |
| VoxCeleb1-Test 规模 | 20 sequences(从 VoxCeleb2 随机选取) | ✅ 论文披露 |
| 训练硬件(GPU 型号与数量) | — | ❌ 未披露 |
| 优化器 + 学习率 + schedule | — | ❌ 未披露 |
| batch size + epoch + 训练时长 | — | ❌ 未披露 |
| checkpoint 选择策略 | — | ❌ 未披露 |
复现障碍
已知失败案例

论文识别了以下主要局限:
- BasicVSR-GAN:在严重 blind 退化下无法恢复真实人脸细节,可能产生伪影
- GFPGAN:对大姿态(large pose)人脸产生不自然结果,其 generative prior 主要基于正面人脸训练
- ESRGAN(单帧方法):导致帧间牙齿形状变化和眼睛高光闪烁
- MSE + GAN-prior 组合:不如端到端训练,可能存在两阶段误差累积
- ×8 scale:论文主要关注 ×4,但提到 ×8 下性能差距更大
VFHQ 发表后,迅速成为 VFSR 及相关领域的事实标准数据集。根据 Semantic Scholar 数据(2026-06-17 查询),截至 2026 年 6 月已被引用 191 次,其中 20 次为有影响力引用 #Xie et al., 2022。
引用分布与研究生态
| 研究方向 | 估计占比 | 代表性工作 |
|---|---|---|
| Talking Head / 肖像动画 | ~40% | EMO, LivePortrait, AniPortrait, OmniHuman |
| 3D Head Avatar 重建 | ~20% | GPAvatar, CAP4D, Avat3r, Portrait4D |
| 视频人脸复原/SR | ~15% | KEEP (ECCV 2024), PGTFormer (IJCAI 2024) |
| 人脸交换 | ~8% | Canonswap, HiFiVFS |
| Deepfake 检测 | ~7% | DF40, Veritas |
| 其他(视线估计/Re-Aging 等) | ~10% | OmniGaze, Video Face Re-Aging |
核心启发与未来方向
局限与未来方向
数据集的局限
- 场景单一:仅覆盖 interview 场景,缺乏户外、运动、多人互动等多样性
- 规模有限:16,827 clips 相比 VoxCeleb 的百万级规模仍显不足
- 无代码开源:Pipeline 代码未发布,数据集需自行从 YouTube 下载
- Generative prior 未探索:论文将"generative facial prior 融入多帧 VFSR"列为 future work,直到 KEEP/PGTFormer 才开始系统探索
- 评估指标局限:PSNR/SSIM/LPIPS 不能完全反映人脸视频的感知质量,缺乏身份保持度、表情准确度等人脸特定指标
论文作者团队值得特别关注:Xintao Wang(ARC Lab, Tencent PCG)是 BasicVSR #Chan et al., 2021、EDVR #Wang et al., 2019、ESRGAN #Wang et al., 2018、GFPGAN #Wang et al., 2021 等里程碑工作的共同作者,其开源项目(GFPGAN 37K+ stars、Real-ESRGAN 35K+ stars)构成了图像/视频复原领域的事实标准工具链。Chao Dong(SIAT CAS)是 SRCNN 的原作者——深度学习超分辨率领域的奠基人。这种"学术深度 + 工程完备性"的组合,使得 VFHQ 虽然只是一个数据集论文,却在过去 4 年中被广泛采用为事实标准。
参考来源
- Xie, L. et al. (2022). VFHQ: A High-Quality Dataset and Benchmark for Video Face Super-Resolution. CVPR 2022 Workshop (NTIRE). arXiv:2205.03409
- Chan, K.C.K. et al. (2021). BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond. CVPR 2021. arXiv:2012.02181
- Wang, X. et al. (2018). ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. ECCVW 2018. arXiv:1809.00219
- Nagrani, A. et al. (2017). VoxCeleb: A Large-Scale Speaker Identification Dataset. Interspeech 2017. arXiv:1706.08612
- Karras, T. et al. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019. arXiv:1812.04948
- Wang, X. et al. (2021). Towards Real-World Blind Face Restoration with Generative Facial Prior. CVPR 2021. arXiv:2101.04061
- Yang, T. et al. (2021). GAN Prior Embedded Network for Blind Face Restoration in the Wild. CVPR 2021.
- Cao, Q. et al. (2018). VGGFace2: A Dataset for Recognising Faces across Pose and Age. FG 2018.
- Deng, J. et al. (2019). RetinaFace: Single-stage Dense Face Localisation in the Wild. arXiv:1905.00641
- Deng, J. et al. (2019). ArcFace: Additive Angular Margin Loss for Deep Face Recognition. CVPR 2019.
- Bewley, A. et al. (2016). Simple Online and Realtime Tracking. ICIP 2016.
- Su, S. et al. (2020). Blindly Assessing Image Quality in the Wild Guided by a Self-Adaptive Hyper Network. CVPR 2020.
- Wang, X. et al. (2019). Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression. ICCV 2019.