UniLS:首个端到端统一说-听数字人
← 上一篇:Flow-Guided One-Shot Talking Face(CVPR 2021)——用稠密光流替代稀疏关键点的突破。
本篇定位:数字人论文精读第二十六篇。如果说 Flow-Guided 解决了"从稀疏到稠密"的运动表示问题,那么 UniLS 则解决了一个更根本的挑战:如何让数字人在倾听时也自然地"动"起来。论文揭示了 audio-motion correlation imbalance 这一根因,并通过两阶段训练范式首次实现了纯音频驱动的端到端统一说-听生成。
P1: 对话式数字人(Speaking vs Listening)
对话式数字人需要在双人对话场景中同时具备两种能力:speaking(根据自身语音生成匹配的唇形和表情)和 listening(在对方说话时生成自然的倾听反应——眨眼、微点头、眼神跟随)。传统方法只做了 speaking,完全忽略了 listening。真人在倾听时并非静止不动:平均每 3-4 秒眨眼一次,偶尔微微点头,嘴角有细微表情变化。如果数字人在倾听时变成"扑克脸",交互体验将极不自然。
P2: FLAME 3D 人脸参数化模型
#Li-et-al.-2017FLAME 是语音驱动面部动画的事实标准表示,将人脸分解为三组低维参数:形状参数 β(身份特征,固定不变)、表情参数 ψ(50 维,动态表情)、姿态参数 θ(头部旋转、下颌开合、眼球注视)。通过这组参数可重建 5,023 个顶点的 3D 人脸网格。UniLS 的所有面部运动生成都在 FLAME 参数空间(ψ + θ)中进行。
P3: wav2vec 2.0 音频特征
#Baevski-et-al.-2020wav2vec 2.0(Meta AI, NeurIPS 2020)通过掩码预测自监督预训练,学到了一套强大的通用语音表示。UniLS 使用冻结的 wav2vec2-xls-r-300m 编码器将双轨音频转换为特征序列,作为 Stage 2 中 dual cross-attention 的条件输入。wav2vec 特征同时也是论文核心动机分析(audio-motion correlation t-SNE 可视化)的基础工具。
P4: 自回归 Transformer 与 Chunk-based 生成
自回归 Transformer 按时间顺序逐步预测下一个时间步的输出,每一步以之前所有内容作为条件。UniLS 采用 chunk-based 设计:每次预测一整块 100 帧(4 秒)的运动,而非逐帧预测。一段 60 秒的视频只需 15 步而非 1500 步,大幅减少误差累积并提升推理效率(560.6 FPS)。代价是 chunk 边界处可能出现微妙不连续。
P5: VQ-VAE 与 Multi-scale Codec
VQ-VAE 将连续数据编码为离散码本索引(如 256 entries × 64 dim),实现运动离散化。UniLS 的 Multi-scale VQ Codec 在 5 个时间尺度 [1, 5, 25, 50, 100] 上逐级残差量化:粗尺度捕获全局运动趋势(头部转动),细尺度捕获局部细节(唇形变化),每一级只编码前一级未能表达的额外信息。
对话式数字人正在成为人机交互的核心界面。虚拟助手需要在用户发言时展现自然的倾听姿态;视频会议中的 3D 化身需要在说与听之间无缝切换;游戏 NPC 的交互真实感直接决定了用户沉浸体验。这些场景的共同需求是:数字人必须同时具备说话和倾听两种能力。
然而,现有研究长期停留在单向生成。#Fan-et-al.-2022FaceFormer(CVPR 2022)、CodeTalker(CVPR 2023)、#Chu-et-al.-2025ARTalk(SIGGRAPH Asia 2025)仅关注 speaking;#Ng-et-al.-2022Learning2Listen(CVPR 2022)、DIM(ECCV 2024)仅建模 listening。这种"单向性"意味着实际部署时需要拼接两套独立模型,无法保证角色在说-听转换时的时序连贯性。
#Peng-et-al.-2025DualTalk(Peng et al., CVPR 2025)是首个尝试统一 speak-listen 的框架,但存在架构层面的根本缺陷:它不是端到端的。DualTalk 需要先获取或预生成 speaker-A 的面部运动序列,再以此为条件生成 speaker-B 的运动。这带来了三重问题:(1) 无法实时部署(FPS = N/A);(2) 误差从 speaker-A 级联传导到 speaker-B;(3) 在纯音频驱动的交互场景中根本无法提供所需的视觉输入。
那么,直接做端到端联合训练行不行?这恰恰触发了本文要解决的核心问题——listening stiffness(听者僵硬)。当以端到端方式联合训练时,模型在 speaking 分支上能快速学到强 audio-motion 映射,但在 listening 分支上,由于缺乏足够的音频指导信号,模型退化为安全的、低方差的静态面部——缺乏眨眼、微表情和头部运动的"扑克脸"。
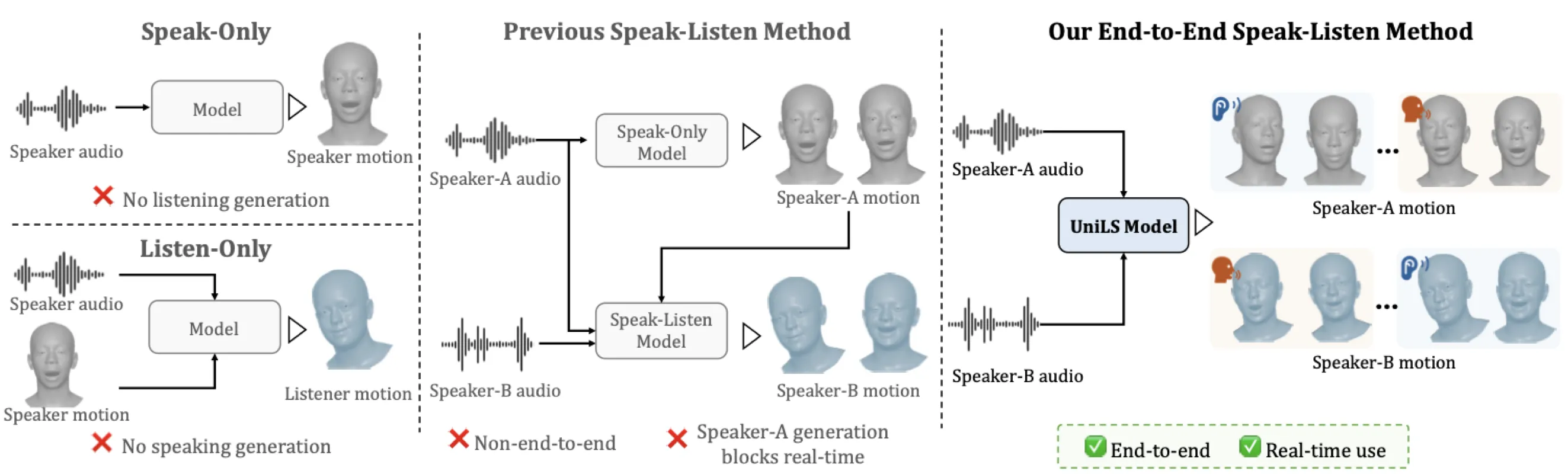
UniLS 的核心贡献是:首个端到端音频驱动的统一 speak-listen 生成框架,仅凭双轨音频即可同时生成双方的说-听运动。通过两阶段训练范式,论文报告听者分布指标提升达 44.1%(其中 F-FID 单项从 13.143 降至 4.304,降幅 67.3%),实时推理达 560.6 FPS,完整开源代码、模型和数据集。
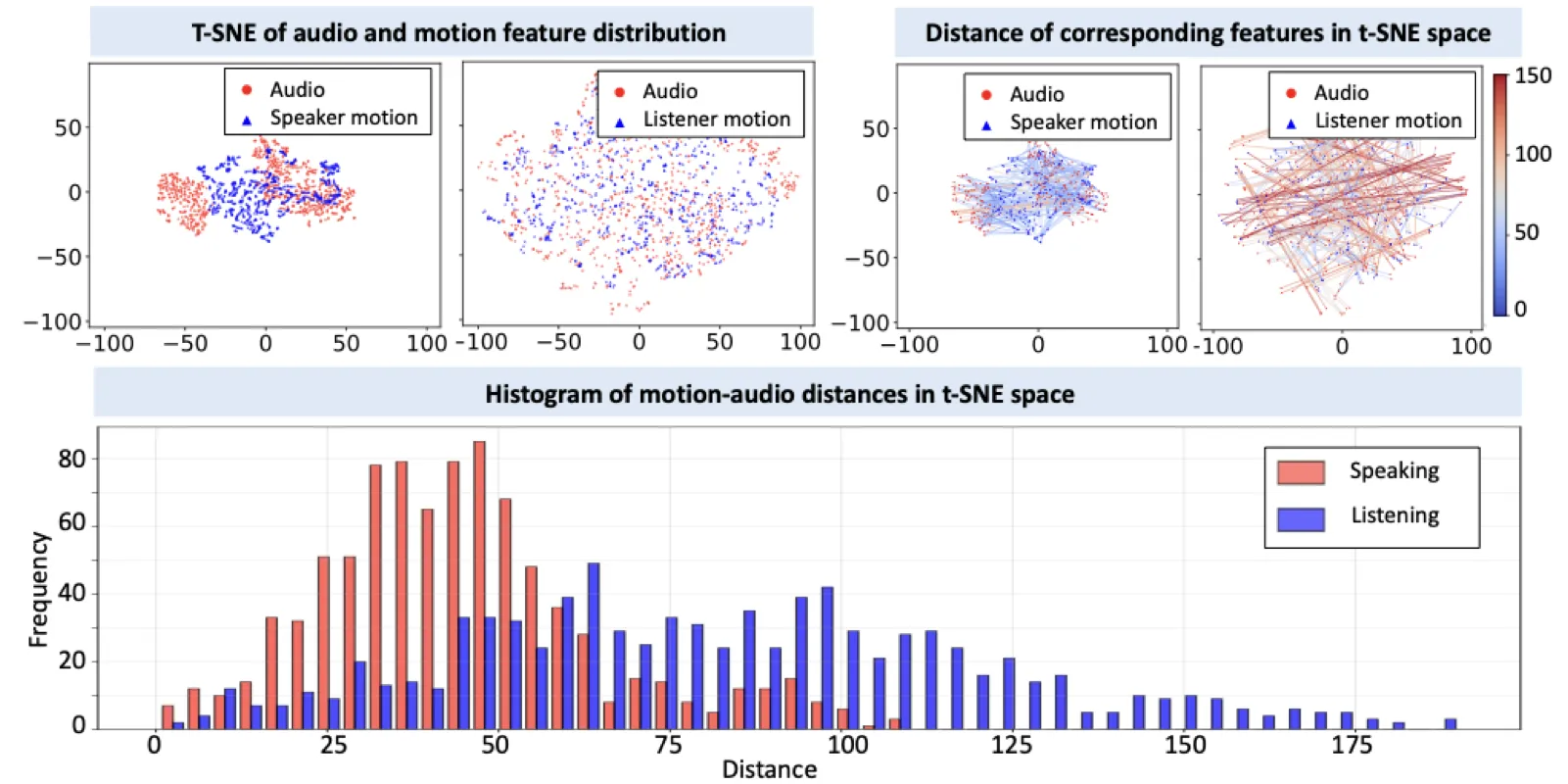
论文通过一项关键的定量分析揭示了 listening stiffness 的根本原因:audio-motion correlation imbalance(音频-运动关联不平衡)。
分析方法:使用 wav2vec 2.0 提取音频特征,使用 FLAME 提取表情参数,对 speaking 和 listening 场景分别计算 t-SNE 联合分布可视化(Figure 2)。结果呈现出清晰的不对称模式:
- Speaking 场景:音频特征和运动嵌入紧密聚集,成对距离小且一致。音素与唇形有明确对应,韵律与头部运动也有统计显著相关——speaking motion 的信息大部分可从 audio 中恢复(高互信息)。
- Listening 场景:运动嵌入分散在远离音频特征的区域,分布松散。大量听者行为(自发眨眼、微表情)与对方语音几乎无关——listening motion 的信息主要来自 internal prior(低互信息)。
这一发现的深层含义是:speaking 是良定义的(well-posed)audio-to-motion 映射,而 listening 是病态的(ill-posed)映射。当模型用同一个 loss 同时优化两个分支时,梯度主要由 speaking 分支主导(loss 下降更快、信号更强),listening 分支被"淹没",最终收敛到最小化风险的平凡解——静止面部。
基于此分析,论文提出关键洞察:listening behavior 不应被学习为直接的 audio-to-motion 映射,而应被重新理解为两个分量的组合:
其中 Internal Motion Prior(内部运动先验)是人在没有外部语音刺激时的自然动态模式——自发眨眼、微表情、头部微动等;Weak Audio Modulation(弱音频调制)是对方语音对听者行为的微弱影响——在对方语气加重时微微点头、在停顿时更大概率眨眼等。
这一洞察直接导出了 UniLS 的方法设计:将内部运动先验的学习与音频调制分离到两个训练阶段。Stage 1 在无音频条件下训练,专门学习 internal motion prior;Stage 2 在此基础上引入双轨音频进行微调。这样,listening 分支不再需要从零学习一个 ill-posed 的映射,而是在已有的高质量 motion prior 基础上叠加微弱调制——这正是自然倾听行为的真实构成方式。
消融实验提供了决定性证据:去掉 Stage 1 后,listening FDD 从 17.12 退化到 25.64(+49.8%),F-FID 从 4.30 退化到 5.97(+38.8%)。补充材料显示,即使完全没有音频,Stage 1 的 audio-free generator 仍能产生 FDD=21.83(listen)的动态变化,证明内部运动先验确实被有效学习了。
3.0 整体 Pipeline 概览
UniLS 的核心是一个 two-stage training paradigm。整个系统从原始视频到最终输出的数据流如下:
graph TD
subgraph S1["Stage 1: Audio-free Generator"]
V1["Multi-scenario Videos
(546.5h)"] --> FT1["FLAME Tracker"]
V2["Conversational Data
(622.5h, audio ignored)"] --> FT1
FT1 --> MC1["Motion Chunking
M ∈ R^{T×D}, T=100"]
MC1 --> SE1["Style Embedding s"]
MC1 --> Codec["Multi-scale VQ Codec
levels=[1,5,25,50,100]
codebook: 256×64"]
Codec --> AR1["AR Transformer G
(self-attention only)"]
SE1 --> AR1
AR1 --> L1["L1 Reconstruction Loss"]
L1 --> Result1["✅ Internal Motion Prior
(blinking, micro-expressions,
head dynamics)"]
end
Result1 -->|"Pretrained weights"| AR2
subgraph S2["Stage 2: Audio-driven Finetuning"]
CD["Conversational Data
(Seamless Interaction)"] --> FT2["FLAME Tracker"]
CD --> W2V["Frozen wav2vec 2.0"]
FT2 --> MC2["Motion Chunks M + Style s"]
W2V --> DA["Dual Audio Features
a^A, a^B"]
MC2 --> AR2["AR Transformer G
+ Dual Cross-Attention
+ LoRA fine-tuning"]
DA --> CA_A["Cross-Attn Track A ← a^A"]
DA --> CA_B["Cross-Attn Track B ← a^B"]
CA_A --> AR2
CA_B --> AR2
AR2 --> L2["L1 Reconstruction Loss"]
L2 --> Result2["✅ Unified Speak-Listen Generator
560.6 FPS real-time"]
end
classDef stage1 fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef stage2 fill:#fce4ec,stroke:#c62828,stroke-width:2px
classDef result fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px
class S1 stage1
class S2 stage2
class Result1,Result2 result
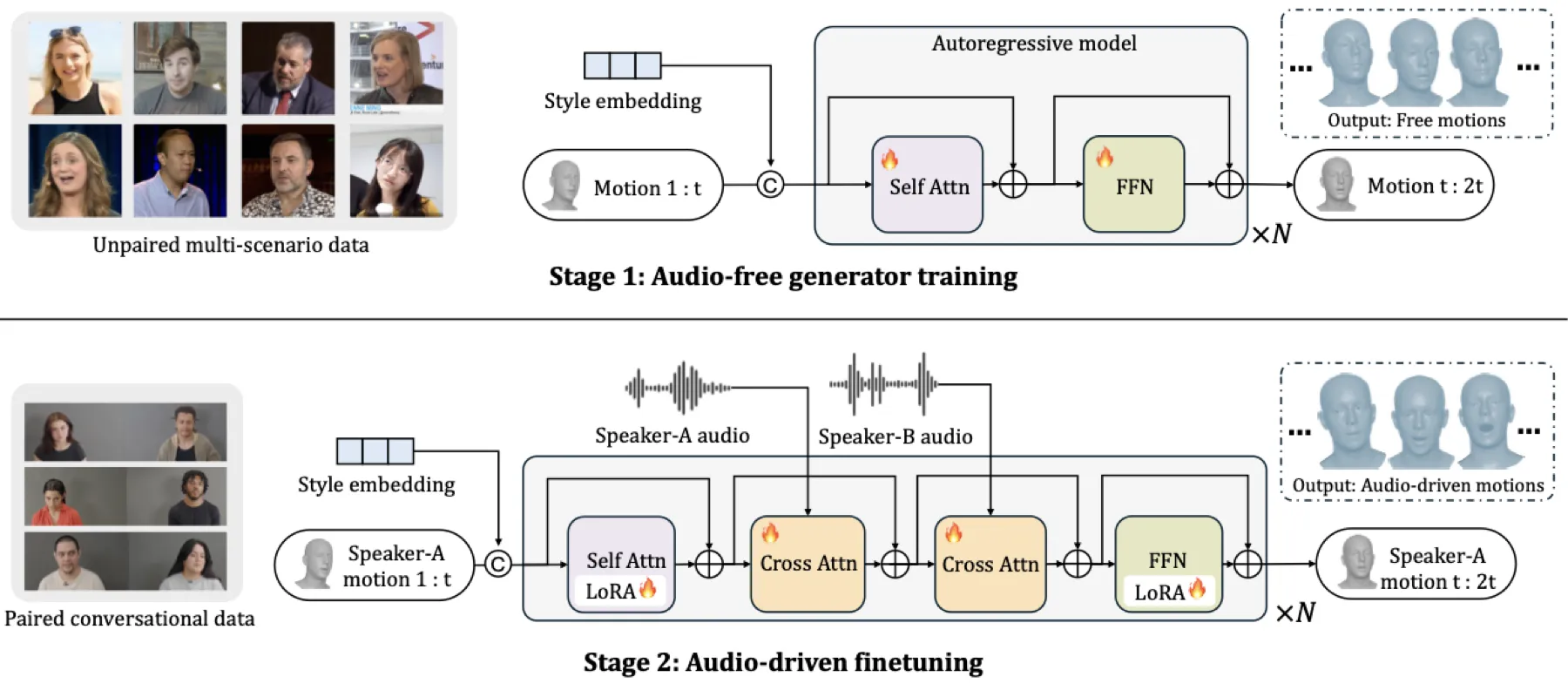
3.1 Stage 1: Audio-free Generator — 学习内部运动先验
Motivation:listening motion 与对方语音的互信息极低,直接的 audio-to-motion 映射是 ill-posed 的。但 listening behavior 的主体成分并不是由音频驱动的——真人在倾听时的眨眼、微表情主要由自身内部运动模式决定。如果能在无音频条件下先学会"人脸在没有外部刺激时应该怎么自然地动",就等价于学会了 listening behavior 的主体部分。
Intuition:就像教演员表演"倾听"。直接让演员听对手台词来练习反应(端到端训练),演员会因找不到明确的"台词→反应"对应关系而僵住。更好的方法是:先在没有台词的环境下练习自然的肢体语言(Stage 1),建立扎实的身体语言基础;然后再加入台词,学会根据对方语气微调动作(Stage 2)。
Mechanism:给定历史运动序列 $M_{1:t}$ 和风格嵌入 $\mathbf{s}$,生成器预测下一个 chunk:
其中 $M_{1:t} \in \mathbb{R}^{t \times D}$ 是历史运动序列(每个 chunk 包含 $T=100$ 帧的 FLAME 参数 $\psi + \theta$),$\mathbf{s}$ 是 speaker-specific 的 style embedding(继承自 ARTalk),$\hat{M}_{t:2t}$ 是预测的下一个 chunk。
生成器 $\mathcal{G}$ 是基于 Transformer 的自回归模型(8 层 self-attention + FFN,hidden dim 512,8 heads),Stage 1 中没有 cross-attention 层。训练数据包括 546.5 小时多场景非对话视频(CelebV、TalkingHead-1KH、TEDTalk、VFHQ)+ 622.5 小时对话数据(音频被忽略)。补充材料中 free-running 评估显示,即使完全没有音频,模型仍能产生 FDD=21.83(listen)的动态变化。
3.2 Stage 2: Audio-driven Finetuning — 注入双轨音频调制
Motivation:一个朴素做法是将两路音频混合后通过单个 cross-attention 注入。但消融实验给出了毁灭性的否定:使用 single cross-attention + 混合音频导致 LVE 从 5.83 飙升到 11.48(+96.9%),MHD 从 1.89 到 3.00(+58.7%)。混合音频使模型无法区分哪些声学特征来自说话人(应驱动唇形同步)、哪些来自听话人(应仅做微弱调制)。
Intuition:UniLS 为两路音频分配了各自独立的 cross-attention 通道——Track A attend to speaker-A 音频(驱动 speaking),Track B attend to speaker-B 音频(驱动 listening)。两条 track 拥有独立的可学习投影矩阵,模型可以为 speaking 和 listening 学到完全不同的 attention pattern。
Mechanism:Stage 2 的生成过程形式化为:
在每个 Transformer block 中,除了标准 self-attention,还增加了两个 cross-attention 层:
LoRA 微调策略:Stage 2 中,新增的 cross-attention 层从头训练,而 Stage 1 继承的 backbone 权重仅通过 LoRA 微调(rank=32, alpha=32, dropout=0.1)。低秩约束限制了参数更新幅度,防止 audio-driven loss 覆盖已学到的 internal motion prior(catastrophic forgetting)。代码显示 LoRA 不仅应用于 self-attention,还应用于 FFN、code_token_embed、logits_head 和 sos_embed。
对称性设计:生成 speaker-A 运动时,$\mathbf{a}^A$ 作为 Track A(speaking drive),$\mathbf{a}^B$ 作为 Track B(listening drive)。生成 speaker-B 运动时,只需交换两路音频角色。同一模型通过输入交换生成任一方运动,无需训练两个独立模型。
3.3 Multi-scale VQ Codec — 层次化离散运动表示
传统的单尺度 VQ 面临根本 trade-off:码本大小有限(256 entries),如果时间分辨率高则难以捕获长程模式,如果分辨率低则丢失高频细节。Multi-scale codec 通过逐级残差量化巧妙解决:粗尺度用少量码字覆盖大范围时序模式,细尺度只编码局部偏差。
配置:codebook 256 entries × 64 dim,multi-scale levels [1, 5, 25, 50, 100],time window 100 frames。解码时将所有尺度的码累加并通过 Transformer decoder 重建运动。
3.4 训练损失函数
生成器训练使用 chunk-wise 自回归重建损失:
为什么选择 L1 而非 L2?(1) L1 对异常值更鲁棒,面部运动中的快速变化(突然张嘴、快速眨眼)在 L2 下会产生过大梯度导致过度平滑;(2) L1 产生更锐利的预测,L2 倾向于预测均值导致模糊;(3) L2 会加剧 listening stiffness——在 listening 场景中 audio-motion 关联弱,L2 的条件均值估计更容易退化为零方差常数预测。
值得注意的是,没有额外的 audio-alignment loss(如 lip-sync loss 或 adversarial loss)。模型完全依靠 dual cross-attention 的结构设计和 two-stage 训练策略来实现 audio-motion alignment。
训练配置
| 配置项 | Codec | FreeGen (Stage 1) | LoRAGen (Stage 2) | 披露状态 |
|---|---|---|---|---|
| Optimizer | AdamW | AdamW | AdamW | 论文披露 |
| Learning Rate | 1.0e-4 | 1.0e-4 | 1.0e-4 | 论文披露 |
| LR Schedule | Linear warmup (0.1→1.0, 1K iter) + Linear decay (1.0→0.1) | 同 | 同 | 代码补全 |
| Batch Size | 64 | 128 | 128 | 论文披露 |
| Iterations | 200K | 600K | 400K | 代码补全(论文声称 generator 合计 200K,实际 1000K) |
| EMA | — | decay=0.9999 | decay=0.9999 | 代码补全 |
| GPUs | 4× NVIDIA H200 | 论文披露 | ||
| GPU Hours | — | ~10h | ~30h | 论文披露 |
| Audio Encoder | Frozen wav2vec2-xls-r-300m (output dim=1024) | 代码补全 | ||
数据集
| 数据集 | 用途 | 规模 | 说明 |
|---|---|---|---|
| Seamless Interaction | 对话数据(train/val/test) | 657.5h (622.5/4.8/30.2h) | Meta 发布,含 4000+ 参与者;listening motions 406h (36.5M frames) > speaking 251.5h (22.6M frames) |
| CelebV + TalkingHead-1KH + TEDTalk + VFHQ | 多场景非对话数据(Stage 1) | 546.5h | 新闻播报、访谈、直播等多样化场景,增强 motion prior 泛化性 |
代码揭示的论文未明确细节
代码分析揭示了几个论文正文未明确说明的关键设计选择:
量化方案偏差:论文描述为标准 VQ(256 entries),代码实际使用 Binary Spherical Quantization (BSQ),32 维二值球面量化,有效码本大小 2^32 ≈ 4.3 billion,远超标准 VQ 的 256。BSQ 使用 straight-through estimator 进行梯度传播,包含 entropy penalty。这可能是论文写作时的简化描述,或从早期版本演进后未同步更新文字。
训练迭代数不一致:论文声称 generator 总共 200K iterations,代码配置为 1,000K(600K freegen + 400K loragen)。可能论文报告的是早期实验配置,最终提交版本使用了更长的训练。
Generator loss 实际为 CE:论文 Eq.3 写 L1 重建损失,但代码中 generator(freegen 和 loragen)实际使用 Cross-Entropy Loss 对离散 BSQ bits 进行预测($F.cross\_entropy(pred\_motion\_logits, gt\_motion\_bits)$)。这是因为 generator 在离散码空间操作,预测的是 BSQ bit 的概率分布,而非直接回归连续运动参数。只有 codec 训练使用了 L1 loss。
Codec loss 更丰富:实际 codec loss 包括 VQ loss (1.0) + expression L1 (1.0) + pose L1 (8.0) + head velocity MSE (5.0) + head smoothness MSE (0.5) + mesh L2 (2.0) + lips L2 (0.1)。head velocity 和 head smoothness loss 在论文正文中完全没有提及。
论文与代码的不一致
代码分析揭示了三处重要的论文-代码不一致:(1) 量化方案:论文写标准 VQ (256 entries),代码用 BSQ (32-dim binary);(2) 训练迭代数:论文写 200K,代码为 1000K;(3) Generator loss:论文写 L1,代码为 CE。复现者应以代码为准,论文文字描述可能存在简化或过时。
推理流程
UniLS 的推理流程是一个 chunk-level 的自回归生成过程:
- 初始化:如果未提供初始运动 chunk,使用全零 tensor;如果未提供 style embedding,也使用全零
- 音频切分:双轨音频按 chunk 对齐切分,每个 chunk 对应 100 帧运动
- Classifier-Free Guidance (CFG):batch 翻倍,一半用真实条件,一半用零条件,CFG scale 默认 1.5
- Temperature scaling:logits 除以 tau(默认 1.0)
- Top-p sampling:top_p=0.97,nucleus sampling
- Chunk-based autoregressive:逐 chunk 生成,每个 chunk 内部按多尺度逐级预测(从粗到细)
- 解码:将离散码通过 Multi-scale VQ Codec 解码为 FLAME 参数序列
实时性能
| Method | Real-time | FPS↑ | GFLOPS | #Params |
|---|---|---|---|---|
| ARTalk* | Yes | 357.7 | 720.7 | 489.5M |
| DualTalk | No | N/A | 348.1 | 647.3M |
| UniLS (ours) | Yes | 560.6 | 739.4 | 421.3M |
UniLS 以 560.6 FPS 的推理速度位居首位,比 ARTalk*(357.7 FPS)快 56.7%,同时参数量仅 421.3M(三者中最小)。远超实时需求(25-30 FPS)的性能余量意味着可以嵌入消费级硬件或边缘设备。DualTalk 因非端到端设计完全不支持实时推理(FPS = N/A),尽管其 GFLOPS(348.1)看似最低,但这仅反映单次前向传播,未计入多阶段串行推理的实际延迟。
6.1 主结果对比
| Method | LVE↓ | MHD↓ | FDD↓(S) | PDD↓(S) | JDD↓(S) | FDD↓(L) | PDD↓(L) | JDD↓(L) | F-FID↓ | P-FID↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| DiffPoseTalk | 9.48 | 2.96 | 32.66 | 7.89 | 1.40 | — | — | — | — | — |
| ARTalk | 7.46 | 2.12 | 31.64 | 7.66 | 1.19 | — | — | — | — | — |
| ARTalk* | 6.79 | 2.02 | 27.41 | 8.55 | 0.81 | 30.62 | 9.52 | 1.53 | 10.779 | 0.072 |
| DualTalk | 6.35 | 1.95 | 37.46 | 9.70 | 1.02 | 43.58 | 10.71 | 2.02 | 13.143 | 0.079 |
| UniLS | 5.83 | 1.89 | 18.41 | 4.67 | 0.71 | 17.12 | 4.75 | 0.98 | 4.304 | 0.038 |
Speaking 侧全面提升:LVE=5.83,比 DualTalk(6.35)降低 8.2%;上半脸 FDD 从 37.46 降至 18.41(降幅 50.9%);头部姿态 PDD 从 9.70 降至 4.67(降幅 51.9%)。
Listening 侧实现质变:这才是 UniLS 最核心的突破。Listening FDD 从 DualTalk 的 43.58 降至 17.12(提升 60.7%),F-FID 从 13.143 降至 4.304(提升 67.3%)。F-FID 降低到原来的三分之一意味着 UniLS 生成的听者表情不再坍缩为"扑克脸"模式,而是呈现多样化的自然反应。P-FID 从 0.079 降至 0.038(提升 51.9%),头部姿态分布也更贴近真实。
6.2 用户研究
| 对比对象 | Sync (%) | Exp (%) | React (%) | Pose (%) |
|---|---|---|---|---|
| vs. DiffPoseTalk | 55.34 | 61.65 | — | 58.25 |
| vs. ARTalk | 75.36 | 75.36 | — | 71.98 |
| vs. ARTalk* | 76.92 | 77.88 | 79.80 | 74.52 |
| vs. DualTalk | 86.06 | 90.38 | 91.35 | 89.42 |
vs. DualTalk 时 listening reaction 偏好率高达 91.35%——超过九成参与者认为 UniLS 的倾听反应更自然,与客观指标高度一致。
6.3 消融实验
| Method | LVE↓ | MHD↓ | FDD↓(S) | FDD↓(L) | F-FID↓ | 掉点幅度 |
|---|---|---|---|---|---|---|
| Single cross-attn | 11.48 | 3.00 | 31.35 | 27.46 | 5.97 | LVE +96.9% |
| w/o Stage 1 | 6.32 | 2.02 | 25.10 | 25.64 | 5.97 | FDD(L) +49.8% |
| w/o Multi-scenario | 6.26 | 1.99 | 18.77 | 17.81 | 4.62 | LVE +7.4% |
| UniLS (full) | 5.83 | 1.89 | 18.41 | 17.12 | 4.30 | — |
第一名:Single cross-attention(破坏性最大)。LVE 从 5.83 飙升至 11.48(+96.9%),说明双轨音频分离是整个方法的基石——混合音频使 attention 无法建立准确的 phoneme-viseme 映射。
第二名:Without Stage 1(主要影响 listening)。Listening FDD 从 17.12 升至 25.64(+49.8%),F-FID 从 4.30 升至 5.97(+38.8%),而 Speaking LVE 仅从 5.83 升至 6.32(+8.4%)。这种不对称影响精确印证了论文动机:speaking 的 audio-motion 关联强,即使没有先验也能学到合理映射;listening 关联弱,缺少先验就退化为静态输出。
第三名:Without multi-scenario data(温和但全面)。Speaking LVE 从 5.83 升至 6.26(+7.4%),Listening F-FID 从 4.30 升至 4.62(+7.4%)。多样化场景数据增强 motion prior 泛化性,但提供的是增益而非决定性作用。
6.4 Audio-free Generator 评估
补充材料中的 Table 5 专门评估了 Stage 1 训练的 audio-free generator 的输出质量,验证内部运动先验是否被有效学习。评估采用 free-running 模式:仅提供初始运动 chunk,后续所有运动完全由模型自主生成,不接收任何音频输入。
| Method | FDD↓(S) | PDD↓(S) | JDD↓(S) | FDD↓(L) | PDD↓(L) | JDD↓(L) | F-FID↓ | P-FID↓ |
|---|---|---|---|---|---|---|---|---|
| Audio-free (Stage 1 only) | 23.97 | 5.61 | 1.34 | 21.83 | 5.17 | 1.59 | 6.45 | 0.053 |
| UniLS (Stage 1+2) | 18.41 | 4.67 | 0.71 | 17.12 | 4.75 | 0.98 | 4.30 | 0.038 |
无音频仍有合理动态:即使完全没有音频输入,Stage 1 模型仍能产生 FDD=21.83(listen)的动态变化。作为参照,DualTalk 在有音频条件下的 listening FDD 为 43.58,反而比无音频的 Stage 1 模型差了一倍。这有力地证明了内部运动先验的有效性——模型确实学到了人脸在无外部刺激时的自发动态模式。
Stage 2 带来进一步提升:完整模型相比 Stage 1 only,Listening FDD 从 21.83 降至 17.12(提升 21.6%),F-FID 从 6.45 降至 4.30(提升 33.3%)。两阶段的协同效应清晰可见。

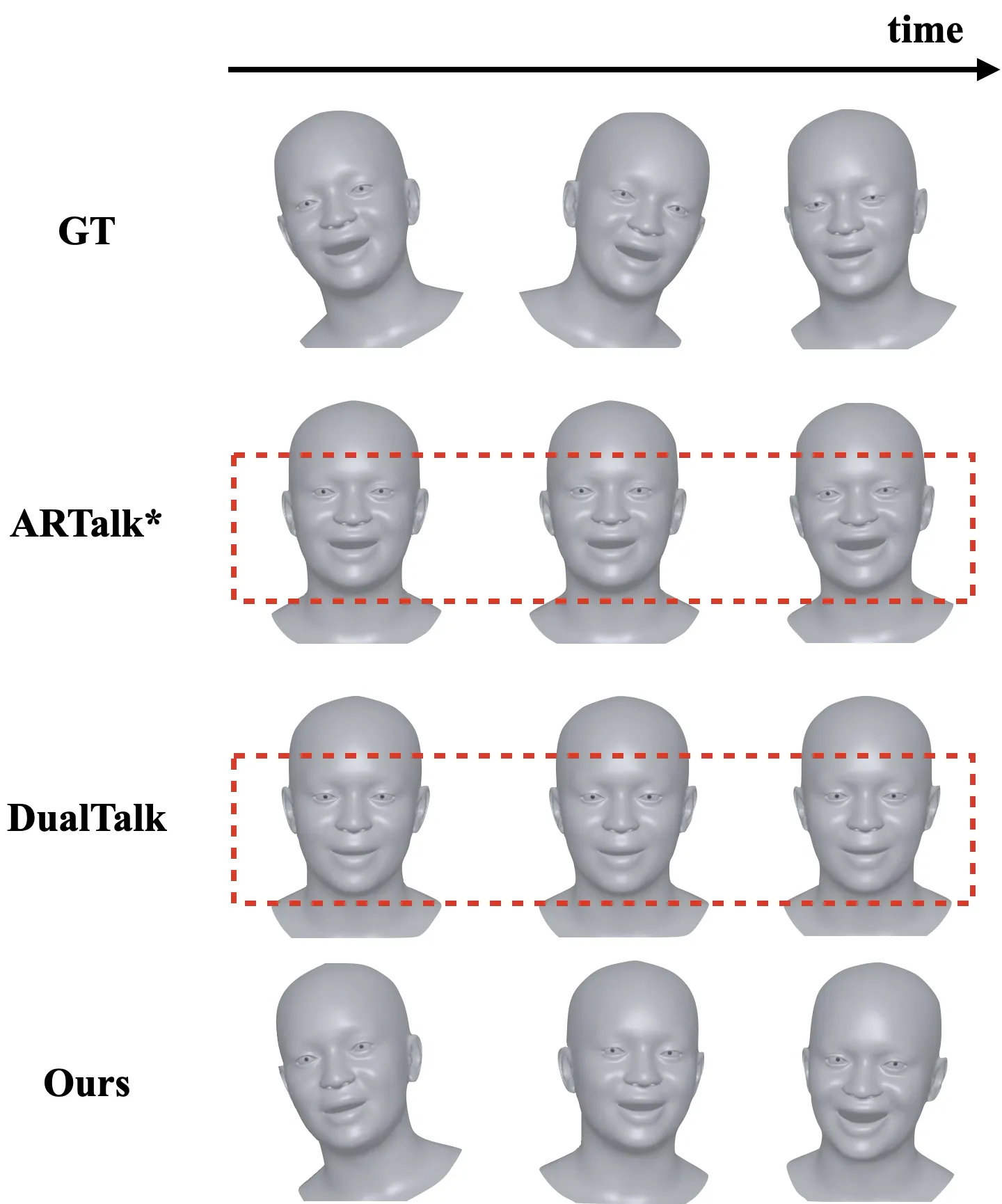
局限性分析
缺乏语义理解:当前听者行为由声学线索(节奏、重音)驱动,无法产生语义相关反应——如在对方表达赞同时点头、听到否定观点时摇头。wav2vec 2.0 主要编码声学和音素信息,对高层语义(意图、情感、论点结构)编码能力有限。
Chunk-based 生成的不连续性:100 帧 chunk 边界处偶尔出现微妙运动不连续。虽然 chunk 级别建模大幅减少了误差累积,但离散化的时序分割与人类面部运动的连续性存在张力。
仅限双人场景:当前框架针对严格双人对话设计。多人场景需要解决注意力分配、轮流发言检测、多听者差异化反应等新问题。
评估指标缺乏语义标准:当前评估体系完全基于统计分布指标(FID、动态偏差、顶点误差),缺乏语义层面的恰当性评估。
未来方向
- 融入语义信息:将 LLM 文本理解能力引入生成管线,先转文本再提取语义标签作为额外条件信号;或使用情感识别模型驱动更具共情力的听者反应。
- Continuous long-horizon models:探索 state-space model(如 Mamba)或 linear attention 的无限上下文建模,消除 chunk 边界不连续性。
- 多人场景扩展:使用 speaker diarization 自动识别当前说话人,为每个听者分配独立 cross-attention track。
- 多语言支持:wav2vec2-xls-r-300m 本身是多语言预训练的,但不同语言的音素-视素映射差异和文化特定的非语言行为差异需要针对性适配。
对数字人产业的启发
端到端实时系统的可行性已被证实。560.6 FPS 和 421.3M 参数证明高质量说-听统一生成不需要庞大模型或复杂串行管线。性能余量意味着可以在同一 GPU 上并行运行语音识别、语义理解等其他模块。
Two-stage training 范式具有通用迁移价值。"先学内部先验、再叠加外部调制"的策略并非面部动画专属——任何涉及弱信号驱动的任务都可能受益:手势生成中先学自发肢体运动先验再用语音微调;全身动画中先学物理合理的运动动力学再用高层指令做任务适配。
从"能说"到"会听"的范式转移。数字人的自然度瓶颈不在"说话"而在"倾听"。过去十年的技术进步主要集中在 speaking 质量,但真实对话体验的一半以上来自倾听时的非语言反馈。UniLS 证明了高质量 listening 生成的技术可行性,将推动产业界重新审视交互体验的设计重心。
伦理防护
论文专门讨论了生成式数字人技术的潜在滥用风险,并提出了三层防护措施:(1) 可见水印——在生成的视频帧中嵌入人眼可见的标识,提醒观众该内容由 AI 生成;(2) 不可见水印——在像素中嵌入不可见的数字签名,可用于溯源和鉴定;(3) 受限身份使用——限制模型对特定身份的使用,防止冒充真实人物。这些措施反映了该领域对负责任 AI 开发的重视,也为后续工作提供了伦理防护的参考范式。
参考来源
- Chu, X. et al. (2026). UniLS: End-to-End Audio-Driven Avatars for Unified Listening and Speaking. CVPR 2026. arXiv:2512.09327
- Peng, Z. et al. (2025). DualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations. CVPR 2025. CVPR 2025
- Chu, X. et al. (2025). ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model. SIGGRAPH Asia 2025. ACM DL
- Fan, Y. et al. (2022). FaceFormer: Speech-Driven 3D Facial Animation with Transformers. CVPR 2022. CVPR 2022
- Li, T. et al. (2017). Learning a Model of Facial Shape and Expression from 4D Scans. SIGGRAPH Asia 2017. FLAME Project
- Baevski, A. et al. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. NeurIPS 2020. NeurIPS 2020
- Sun, Z. et al. (2024). DiffPoseTalk: Speech-Driven 3D Facial Animation with Diffusion Models. SIGGRAPH 2024. ACM DL
- Ng, Z. et al. (2022). Learning2Listen: Evolving Listener Motion with Cross-Modal Attention. CVPR 2022. CVPR 2022
本篇小结
UniLS(CVPR 2026)是首个端到端音频驱动的统一 speak-listen 数字人框架。论文揭示了 listening stiffness 的根因——audio-motion correlation imbalance,并通过两阶段训练范式(Stage 1 无音频先验学习 + Stage 2 双轨音频微调)从根本上解决了这一问题。论文报告听者分布指标提升达 44.1%(F-FID 单项从 13.143 降至 4.304,降幅 67.3%),实时推理达 560.6 FPS。代码分析揭示了论文与代码的三处重要不一致(量化方案、训练迭代数、Generator loss),复现者应以代码为准。
继续阅读
UniLS 代表了对话式数字人从"能说"到"会听"的范式转移。下一步可以关注:
- 语义感知的听者反应:将 LLM 文本理解引入生成管线,实现语义相关的听者反应
- 多人场景扩展:从双人到多人的扩展,解决注意力分配和差异化反应
- 实时交互式数字人系统:将 UniLS 与语音识别、语义理解等模块集成,构建完整的对话系统