InfiniteTalk 源码解读
上一篇我们读了 Ultralight-Digital-Human——一个不到 1M、能在手机上跑、靠「遮嘴重建」逐帧补口型的极简数字人。它代表了数字人的一个极端:越轻越好。
这一篇,我们走到光谱的另一端。主角是 MeiGen-AI/InfiniteTalk,一个由美团 + 中科院团队在 2025 年 8 月开源的框架。#IT-repo 它不满足于「只对口型」,而是要让人物的头、身体、表情都随音频自然动起来,还能生成无限长的视频。代价是:它直接站在一个 140 亿参数的视频扩散大模型(阿里通义万相 Wan2.1)肩膀上,吃显卡、吃算力。
| 维度 | 事实 |
|---|---|
| 一句话定位 | 稀疏帧视频配音(Sparse-Frame Video Dubbing)框架:给视频/图片 + 音频,合成无限长、全身同步的口播视频 |
| 团队 / 时间 | MeiGen-AI(美团 + 中科院 UCAS/CASIA + 中山大学 + HKUST),2025-08-19 开源,论文 arXiv:2508.14033 |
| 基座模型 | Wan2.1-I2V-14B(阿里通义万相的图生视频扩散大模型,DiT 架构) |
| 音频编码器 | chinese-wav2vec2-base(腾讯开源) |
| 自训部分 | 只训「音频条件权重」(audio condition weights),不重训整个视频大模型 |
| 输入模式 | 视频→视频(V2V,无限长)/ 图片→视频(I2V,1 分钟内最佳) |
| 许可证 | Apache 2.0(仓库带正式 LICENSE.txt) |
理解这个项目的一把钥匙
InfiniteTalk 的本质是「条件适配」而非「从头造模型」。它把一个已经很强的通用视频生成大模型(Wan2.1)拿过来,在它身上接两根「条件线」——一根喂音频、一根喂参考帧,再用一套滑窗策略把它的「短视频生成能力」接力成「无限长」。所有工程难点都围绕这三件事展开。
论文开篇就点出传统视频配音的死穴:只编辑嘴部区域,导致换了音频后,嘴在动、但表情和肢体还是原视频的样子,二者错位,观众一眼就觉得「假」。#IT-paper
那为什么不直接用一个图生视频(I2V)大模型,给张脸 + 音频让它全自由生成?论文给出了关键分析:朴素 I2V 模型做不到「自适应 conditioning」——要么条件太弱(人物乱动、丢失身份),要么条件太强(被原视频锁死、嘴动不起来)。
InfiniteTalk 的答案是稀疏帧配音:
稀疏帧配音 = 战略性地「只保留少数参考帧」
不再逐帧把原视频当条件,而是只战略性地保留稀疏的参考关键帧,用它们维持「这个人是谁、标志性手势、相机怎么运镜」;其余的画面,全部交给模型根据音频重新生成全身动作。「稀疏」二字的含义就在这里——参考是稀疏的,自由度是充足的。
论文把这套方案的成功归结为两个技术贡献,后面两章会逐一对应到代码:
- 时序上下文帧(temporal context frames):用上一块的尾帧做下一块的开头,实现块与块之间的无缝衔接——这是「无限长」的基础。
- 细粒度参考帧位置的采样策略:通过控制参考帧出现的位置/强度,在「听话」和「自由」之间找平衡。
仓库结构非常能说明它的设计哲学——大部分代码是借来的 Wan2.1 基座,自己的核心很薄。
flowchart TD CLI["generate_infinitetalk.py
推理入口 / app.py Gradio"] --> PIPE["wan/multitalk.py
InfiniteTalkPipeline"] PIPE --> AUD["src/audio_analysis/wav2vec2.py
音频编码"] PIPE --> DIT["wan/modules/multitalk_model.py
DiT + 双 cross-attention"] PIPE --> VAE["wan/modules/vae.py
视频 VAE 编解码"] PIPE --> T5["wan/modules/t5.py / clip.py
文本/图像编码"] PIPE --> VRAM["src/vram_management/
低显存管理"] DIT -.基座.-> WAN["Wan2.1-I2V-14B
阿里通义万相 权重"] AUD -.基座.-> W2V["chinese-wav2vec2-base
腾讯 权重"]
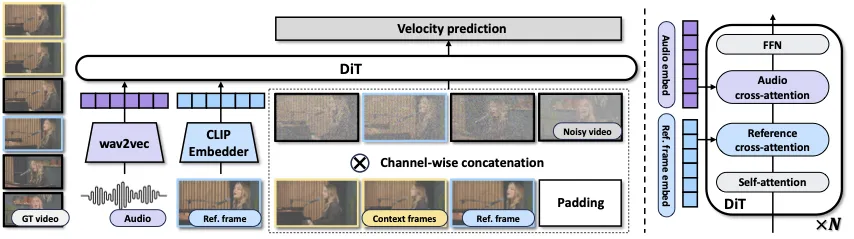
图 2:模块依赖。wan/ 目录几乎整个是 Wan2.1 的代码(版权头写着 Alibaba Wan Team),InfiniteTalk 真正自己的逻辑集中在 multitalk.py 的生成循环、multitalk_model.py 的条件注入,以及 src/ 下的音频与显存管理。
| 文件 | 职责 |
|---|---|
generate_infinitetalk.py | CLI 推理入口,解析参数、读取 json、调度 Pipeline(663 行) |
wan/multitalk.py | 核心:InfiniteTalkPipeline.generate_infinitetalk() 主生成循环(855 行) |
wan/modules/multitalk_model.py | 核心:在 Wan DiT 上加 audio/reference cross-attention(823 行) |
src/audio_analysis/wav2vec2.py | wav2vec2 音频特征提取 |
src/vram_management/ | 参数分级 offload,对应「极低显存运行」卖点 |
wan/utils/multitalk_utils.py | 分辨率桶、色彩校正、ffmpeg 存视频等工具 |
对照图 1,整个前向可以分成「编码 → 拼接 → DiT 去噪 → 解码」四步。
两个编码器 + 一次通道拼接
# wan/multitalk.py:参考帧的两种编码
# 1) CLIP 语义编码(提供"这个人长什么样"的高层身份)
clip_context = self.clip.visual(cond_image[:, :, -1:, :, :])
# 2) VAE 编码(把参考帧 + 零填充压到 latent 空间,与噪声同维度拼接)
padding_frames = torch.zeros(1, C, frame_num - 1, H, W)
y = self.vae.encode(torch.concat([cond_image, padding_frames], dim=2))
y = torch.concat([msk, y], dim=1) # 拼上 mask:第一帧已知、其余待生成
音频则由 wav2vec 编码后,按帧切成滑动窗口(每个目标帧取前后各 2 帧、共 5 帧的音频上下文)。这样图像和音频都准备成了 DiT 可以消费的条件。
DiT Block:两路 cross-attention 各管一摊
对照图 1 右侧,每个 DiT Block(共 N 层)的内部顺序是固定的四段:
flowchart TD X["视频 latent token"] --> SA["Self-attention
(帧内/帧间时空建模)"] SA --> RCA["Reference cross-attention
(注入参考帧 embed → 保身份)"] RCA --> ACA["Audio cross-attention
(注入音频 embed → 驱动口型/动作)"] ACA --> FFN["FFN"] FFN --> OUT["→ 下一层 / Velocity prediction"]
图 3:DiT Block 的条件注入顺序。Self-attention 负责时空一致性,然后先注入参考帧(管身份)、再注入音频(管动作),最后 FFN。两路 cross-attention 职责分离,是这套架构清晰的关键。
DiT 最终输出的不是图像,而是 velocity prediction——这是 flow matching / rectified flow 的训练目标(预测从噪声流向数据的「速度场」),比传统 DDPM 预测噪声更适合视频。采样时用 sample_shift(480P=7、720P=11)调整噪声调度。
扩散视频模型一次只能生成固定长度(这里是 81 帧)。InfiniteTalk 怎么把它接力成无限长?答案是 motion frame(运动帧)滑窗——也就是论文说的「时序上下文帧」。
核心思想:让相邻块「首尾相接」
flowchart LR C1["块 1
帧 0-80"] -->|尾部 N 帧
编码成 latent| C2["块 2
开头钉住这 N 帧
再续生成"] C2 -->|尾部 N 帧| C3["块 3
同样接力"] C3 --> DOTS["... 直到音频用完"]
图 4:滑窗接力。每一块生成完,把它结尾的 N 帧(N = motion_frame)作为下一块的「已知开头」钉死,下一块在此基础上续写。这样相邻块画面天然连续。
代码里的「钉帧」操作
关键在主循环里:非首块时,把上一块尾帧的 latent 在每一个去噪步都强行覆盖回当前块的开头,确保去噪全程不偏离衔接点:
# wan/multitalk.py:每个去噪步都"钉住"motion 帧
for i in range(len(timesteps) - 1):
# 用上一块尾帧 latent 覆盖当前块开头,强制连续
latent[:, :cur_motion_frames_latent_num] = latent_motion_frames
noise_pred = self.model(latent, t=timestep, **arg_c)[0]
...
latent = latent + noise_pred * dt # flow matching 更新
if not is_first_clip: # 非首块:把 motion 帧重新加噪钉回
add_latent = self.add_noise(latent_motion_frames, noise, timesteps[i+1])
latent[:, :T_m] = add_latent
拼接时去掉重叠,避免重复
既然下一块开头复用了上一块的尾帧,拼接成片时就要把这段重叠砍掉,否则画面会卡顿重复:
# wan/multitalk.py:拼接与滑窗前进
if is_first_clip:
gen_video_list.append(videos)
else:
gen_video_list.append(videos[:, :, cur_motion_frames_num:]) # 砍掉重叠的 motion 帧
# 滑窗前进:步长 = 块长 - 重叠
cur_motion_frames_num = motion_frame
cond_frame = videos[:, :, -cur_motion_frames_num:] # 取尾帧做下一块条件
audio_start_idx += (frame_num - cur_motion_frames_num)
match_and_blend_colors,拿原始参考帧的色彩分布去校正每一块的输出。这是个治标的补丁,但作者把它明明白白写进了代码和文档。数字人最怕两件事:嘴对不上(音频太弱)、人物变形乱动(条件太强)。InfiniteTalk 用两路独立的 Classifier-Free Guidance(CFG)分别给文本和音频装了「音量旋钮」。
推理时模型会跑多次前向,得到不同条件组合下的预测,再线性组合:
# wan/multitalk.py:文本 + 音频双路 CFG
# arg_c=全条件, arg_null_text=去文本, arg_null=全去
noise_pred = noise_pred_uncond \
+ text_guide_scale * (noise_pred_cond - noise_pred_drop_text) \
+ audio_guide_scale * (noise_pred_drop_text - noise_pred_uncond)
其中 audio_guide_scale(推荐 3~5)越大,口型跟音频越紧;text_guide_scale(推荐 5)控制文本提示的影响。README 直接给了调参建议:口型不准就调大 audio CFG。
项目还可选启用 APG(自适应投影引导,arXiv:2410.02416)#APG 替代朴素 CFG——它通过把引导方向投影、加动量,缓解高 CFG 下常见的「过饱和、画面发腻」问题。这是扩散生成里一个很实用的进阶技巧。
此外,多人动画靠 ref_target_masks 实现:用 bbox 把每个人的音频绑定到画面对应区域,让两个人各说各的、互不串台。
140 亿参数的视频扩散模型,显存和速度都是硬门槛。InfiniteTalk 给了一整套「省」和「快」的开关:
| 开关 | 作用 |
|---|---|
--num_persistent_param_in_dit 0 | 把 DiT 参数分级 offload 到 CPU,极低显存也能跑(src/vram_management/) |
--quant fp8 / int8 | 量化模型权重,进一步压显存 |
--use_teacache | TeaCache:缓存相邻去噪步的相似计算,加速采样 |
| FusioniX / lightx2v LoRA | 蒸馏 LoRA,把 40 步采样压到 4~8 步(代价:长视频色偏加剧、ID 保持下降) |
--dit_fsdp --t5_fsdp --ulysses_size | 多 GPU:FSDP 分片 + Ulysses 序列并行 |
这套优化矩阵本身就是一份「如何把大扩散模型工程化落地」的实践清单,值得单独学习。
优点
- 站在巨人肩上:复用 Wan2.1 的生成能力,只训音频条件,用相对小的代价拿到了高质量全身生成。
- 真无限长:motion frame 滑窗是干净利落的工程方案,理论上时长只受显存/时间限制。
- 控制粒度细:双路 CFG + APG + 多人 mask,给了使用者充足的调节手段。
- 落地友好:量化、低显存、多 GPU、加速 LoRA、ComfyUI/Gradio 一应俱全。
局限
- 重:14B 基座,和 Ultralight 完全不是一个算力量级,移动端无从谈起。
- 长视频色偏:超过 1 分钟颜色漂移,只能靠色彩校正缓解,未根治。
- 相机控制有限:V2V 能大致模仿原视频运镜但不精确,作者说长视频相机控制仍在改进。
- 加速有代价:FusioniX 等蒸馏 LoRA 提速明显,但会放大色偏、削弱身份保持。
复现风险
- 需要下载三套权重:Wan2.1-I2V-14B(数十 GB)、chinese-wav2vec2-base、InfiniteTalk 条件权重。
- 依赖 flash-attn、xformers 等对 CUDA 版本敏感的库,环境搭建门槛高。
- 真正流畅出片需要高端 GPU;低显存模式可跑但速度感人。
把上篇 Ultralight 和本篇 InfiniteTalk 并排,数字人这条光谱的两端就一目了然了:
| 维度 | Ultralight(第八篇) | InfiniteTalk(本篇) |
|---|---|---|
| 路线 | 遮嘴重建(Wav2Lip 一脉) | 稀疏帧配音 + 扩散生成 |
| 骨干 | 自研轻量 UNet(<1M) | Wan2.1-I2V 扩散大模型(14B) |
| 驱动范围 | 只重绘人脸下半部 | 头、身体、表情全身同步 |
| 身份方式 | per-person,一人一模型 | 稀疏参考帧,免重训 |
| 时长 | 逐帧合成,素材来回播 | motion frame 滑窗,无限长 |
| 算力 | 移动端可实时 | 高端 GPU,重算力 |
| 适用 | 端侧、低成本、实时口播 | 高质量内容生产、长视频 |
一条可迁移的核心经验
InfiniteTalk 最值得借鉴的,是它「不重造轮子,而是给大模型装条件接口」的思路:拿一个强通用模型(视频生成),通过 cross-attention 注入领域条件(音频),再用滑窗把单次能力接力成长序列。这套「基座大模型 + 轻量条件适配 + 滑窗续接」的范式,可以迁移到长音频生成、长文档处理、流式视频理解等一大批「单次有限、需求无限」的任务上。
回到系列:从轻到重,我们已经看完了数字人在算力光谱上的两个极端。下一步如果继续,可以往「评测与数据」或「实时交互系统」方向走。但仅就这两篇而言,你应该已经能回答那个最实际的问题——「我的场景该选轻的还是重的」。
参考来源
- MeiGen-AI. InfiniteTalk(源码、README、generate_infinitetalk.py / wan/multitalk.py). github.com/MeiGen-AI/InfiniteTalk
- Yang et al. InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing. arXiv:2508.14033
- Wan-AI / Alibaba. Wan2.1-I2V-14B(基座视频扩散模型). huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P
- MeiGen-AI. MultiTalk(InfiniteTalk 的前作). github.com/MeiGen-AI/MultiTalk
- TencentGameMate. chinese-wav2vec2-base(音频编码器). huggingface.co/TencentGameMate/chinese-wav2vec2-base
- Sadat et al. Eliminating Oversaturation and Artifacts of High Guidance Scales (APG). arXiv:2410.02416