SPIRE
红外小目标检测(IRSTD)是红外搜索与跟踪系统的基础模块,在军事侦察、边境监控、海上救援中承担着"从杂波背景中找到几个像素大小的热目标"的任务。这些目标极小(典型 2×2 到 9×9 像素)、极暗(信噪比可能仅几个量化级)、极稀疏(一张 640×640 的图上可能只有 1-3 个目标),使得 IRSTD 成为计算机视觉中最具挑战性的检测任务之一 #Ni-2026。
主流 IRSTD 方法沿用了语义分割的 encoder-decoder 范式:用密集的像素级掩码标注训练一个 U-Net 风格的分割网络,推理时再通过连通域聚类把分割掩码转换为检测坐标。DNANet #DNANet-2023 用密集嵌套注意力做多尺度融合,SCTransNet #SCTransNet-2024 引入空间-通道交叉 Transformer 建模长程依赖。这些方法的 F1 不断刷新纪录,但代价是越来越重的架构——SCTransNet 用 11.19M 参数、63.22 GFLOPs 换来 F1=97.09%。
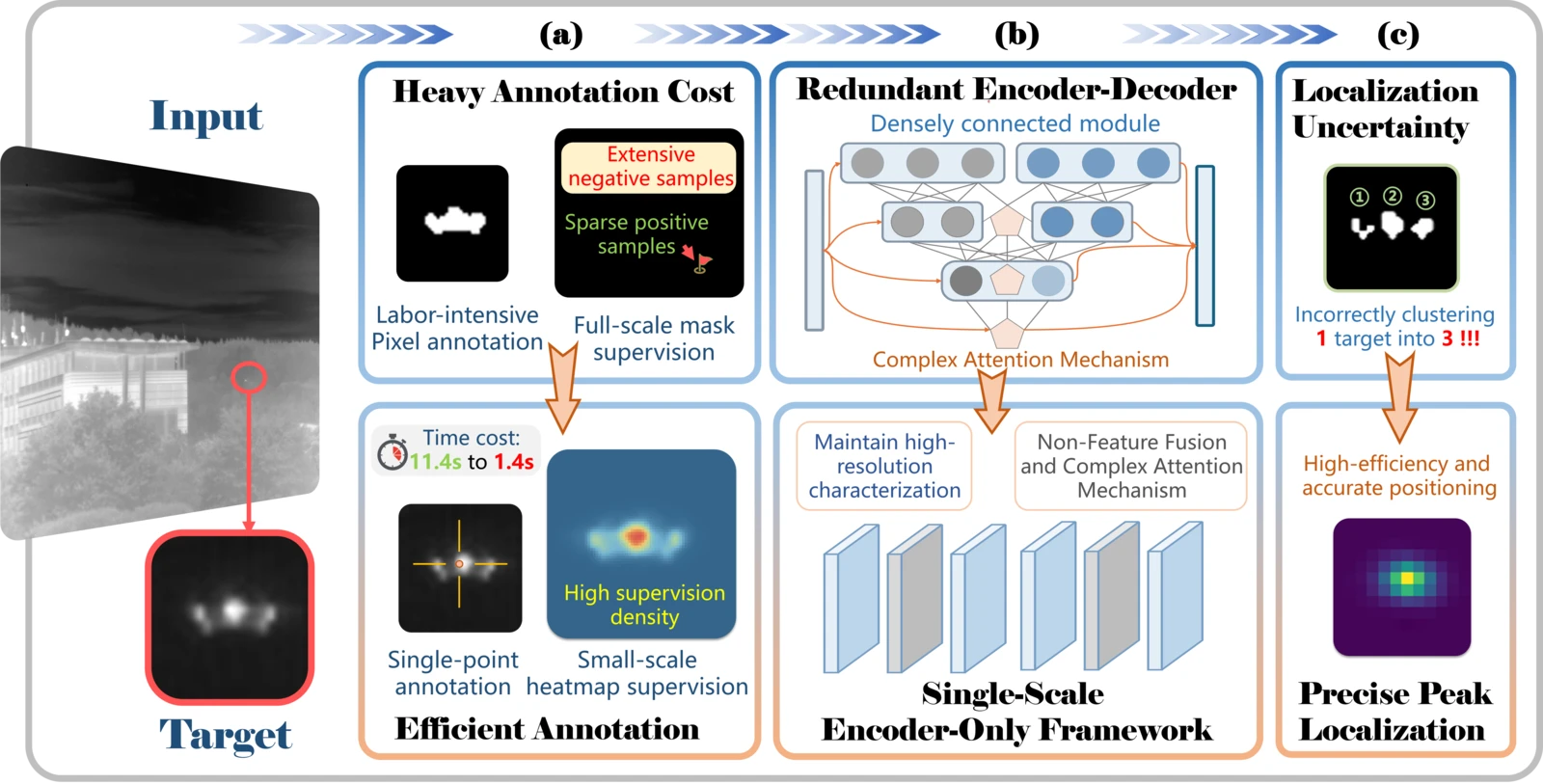
SPIRE 的作者(国防科技大学 NUDT 团队)提出了一个尖锐的问题:IRST 系统真正需要的是可靠的目标定位,而不是精确的轮廓重建。既然小目标只占几个像素,且边界被杂波模糊,那么强迫网络去分割每一个目标像素——然后再把这些像素聚类回坐标——不仅标注昂贵(每张图 11.4s),而且引入了不必要的架构复杂度和定位误差累积 #Ni-2026。
理解 SPIRE 的价值,需要先看清现有 IRSTD 范式的三重耦合瓶颈。
瓶颈 1:标注成本与监督稀疏
像素级掩码标注面临两个问题。第一是标注成本:MCLC #MCLC-2023 报告,单张红外图像的像素级标注平均需要 11.4 秒,而单点标注(只标注目标质心)仅需 1.4 秒——减少 87.72%。第二是监督稀疏:在 640×640 的输入上,典型目标仅占 4-81 个像素(0.001%-0.02%),极端的前景-背景不平衡导致 BCE 损失的梯度几乎完全被背景主导。
瓶颈 2:架构冗余
为了补偿监督信号的稀疏性,现有方法不得不堆叠多尺度融合和密集连接模块。DNANet 使用密集嵌套注意力在 5 个分辨率尺度间反复融合特征,SCTransNet 引入 Transformer 的长程注意力来抑制背景干扰。这些设计在通用视觉任务中是合理的,但对 IRSTD 来说是"用复杂性补偿监督不足"的间接路线——如果监督信号本身就足够稠密,就不需要这么重的架构来稳定优化。
瓶颈 3:定位不确定性
分割范式还有一个工程层面的隐患:检测坐标不是网络的直接输出,而是分割掩码经过 8-连通域聚类后的副产物。当一个真实目标在掩码上产生多个相邻连通块时(这在低 SNR 条件下非常常见),聚类可能把一个目标拆成多个检测,或者把噪声斑块聚成一个虚假检测——这种从"分割到定位"的转换引入了额外的误差和不稳定性。
| 维度 | 分割范式 (DNANet, SCTransNet) | 单点监督分割 (LESPS, MCLC) | SPIRE 概率回归 |
|---|---|---|---|
| 标注形式 | 像素级掩码 | 单点 → 伪掩码 | 单点 → PRPS 热图 |
| 架构 | Encoder-Decoder | Encoder-Decoder | Encoder-Only |
| 推理 | 掩码 → 连通域聚类 | 掩码 → 连通域聚类 | 热图 → 峰值提取 |
| 物理先验 | 无 | 无 | 红外 PSF 扩散 + 辐射梯度 |
| 定位路径 | 间接(分割→聚类) | 间接(分割→聚类) | 直接(峰值→坐标) |
SPIRE 的整体框架由三个模块组成:PRPS(离线构造监督信号)、HRPE(在线前向预测)、峰值提取(确定性推理)。三者的关系是:PRPS 把单点标注膨胀为与红外物理一致的概率响应图,HRPE 学习从红外图像到概率响应图的回归映射,峰值提取从预测响应图中提取目标质心坐标。
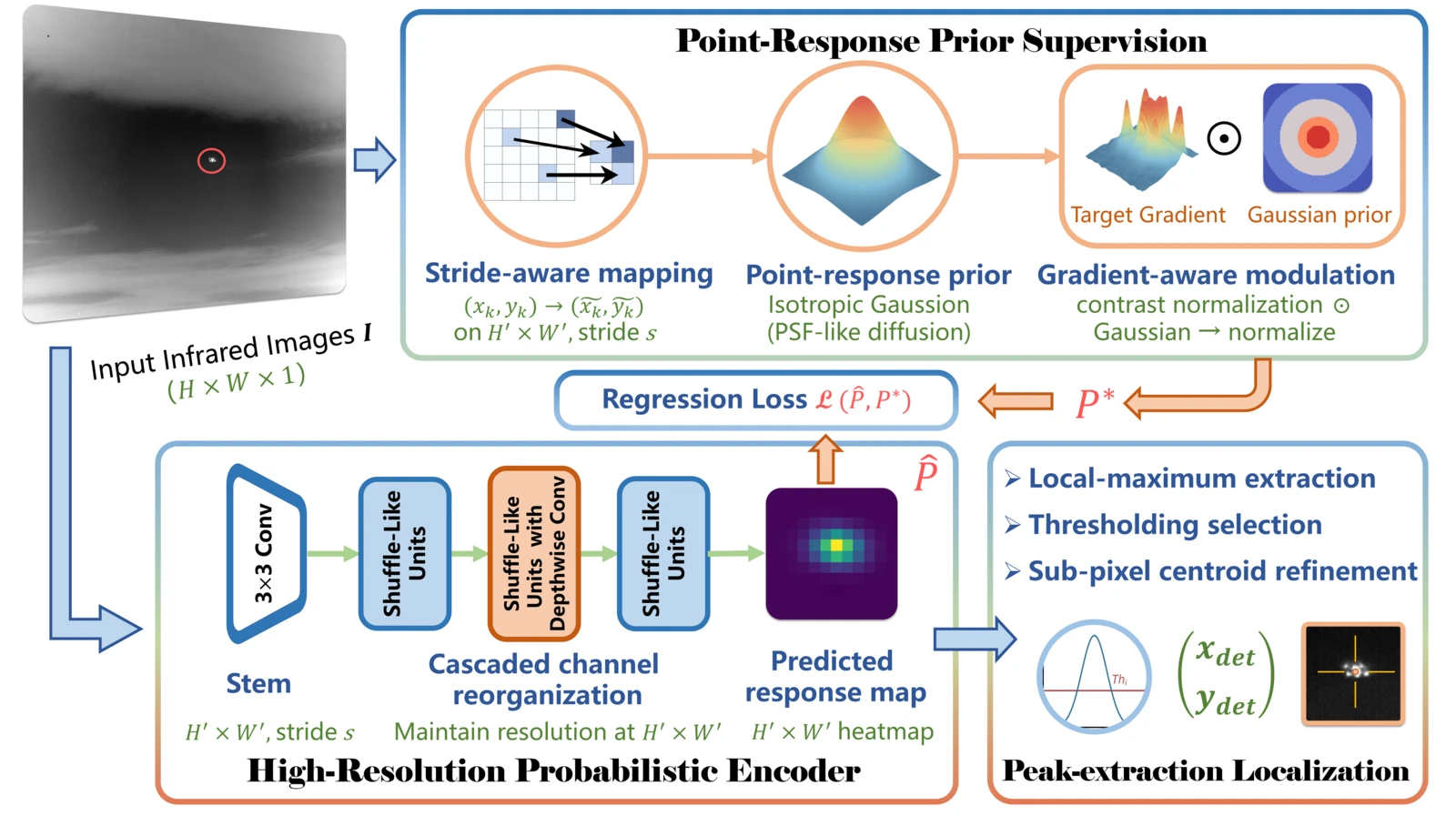
PRPS:将单点标注变成物理一致的概率响应
PRPS(Point-Response Prior Supervision)是 SPIRE 的第一个核心创新。它要解决的问题是:单点 impulse 监督的梯度太稀疏(在 stride=4 的 160×160 热图上,单个正样本占比仅 0.004%),直接训练会导致梯度饥饿。
PRPS 的思路不是简单地用 Gaussian 替代 impulse,而是把红外小目标的物理成像特性编码进监督信号。具体分三步:
第一步:坐标映射 + 辐射峰值对齐。将原图坐标 $(x_k, y_k)$ 映射到热图网格:然后在原图局部邻域中搜索最大强度位置 $(\tilde{x}_k^*, \tilde{y}_k^*)$,使监督中心对齐真实辐射峰值而非标注者的目测位置。
第二步:高斯先验。以辐射峰值为中心构造截断各向同性高斯,模拟红外 PSF(Point Spread Function)的能量扩散:其中 $\sigma=2$ 控制扩散范围,$r=3\sigma=6$ 定义截断边界。高斯核不归一化(峰值保持为 1),核的有效覆盖面积约 $\pi r^2 \approx 113$ 个热图像素——将监督密度从 0.004% 提升到 0.44%,足以维持稳定的梯度信号。
第三步:梯度感知调制。这是 PRPS 与普通 Gaussian heatmap 的关键区别。从原图提取以目标为中心的 $(2r+1) \times (2r+1)$ patch,做对比度归一化:然后将高斯先验与对比度图逐元素相乘:
梯度感知调制的物理含义
$C_k$ 捕获了目标周围的真实辐射强度分布。在均匀背景上,$C_k$ 近似常数,PRPS 退化为标准 Gaussian;在梯度大的边缘(如目标靠近云层边界或热源附近),$C_k$ 使监督信号的形状沿梯度方向变形——更精确地匹配真实目标的能量分布,而非用固定圆形去近似。
多个目标的响应图通过确定性聚合(取逐像素最大值)合并为最终监督图 $\mathbf{P}^*$。即使两个目标的高斯支撑区域重叠,质心回归仍保留各自独立的局部最大值。
HRPE:不需要 Decoder 的高分辨率编码器
HRPE(High-Resolution Probabilistic Encoder)是 SPIRE 的第二个核心创新——一个纯编码器、单分支、单分辨率的轻量网络。
HRPE 的结构简洁到可以用一段话描述:
Stem:两个 stride-2 的 3×3 卷积(+BN+ReLU),将分辨率降到 $H/s \times W/s$($s=4$),通道扩到 $C_0=64$。之后接一个 Bottleneck 残差块做初步特征精炼。 Transition:1×1 卷积将通道从 64 降到 $C=32$。 级联通道重组:在恒定分辨率 $H' \times W'$ 上级联多个 ShuffleNet 风格的通道重组单元。每个单元将 $C$ 通道特征对半拆分为 $F_a$ 和 $F_b$:$F_a$ 做 identity,$F_b$ 经过 depthwise separable convolution + SE-style channel attention,然后拼接并做 channel shuffle:这个 split–process–shuffle 设计借鉴自 ShuffleNet #ShuffleNet-2018,在极低参数量下实现了有效的跨通道信息交换。
预测头:单个 1×1 卷积将 $C=32$ 通道映射到 1 通道输出 $\hat{\mathbf{P}} \in \mathbb{R}^{H' \times W'}$,不加激活函数,直接回归到 PRPS 目标。graph LR A["输入 I
H×W×1"] --> B["Stem
2× stride-2 conv
C₀=64"] B --> C["Bottleneck
Residual Block"] C --> D["Transition
C=32"] D --> E["Channel
Reorganization
×N"] E --> F["1×1 Conv
→ P̂"] F --> G["峰值提取
→ 检测坐标"] style B fill:#ff8a65,color:#fff style E fill:#ffd54f,color:#333 style F fill:#81c784,color:#fff style G fill:#64b5f6,color:#fff
关键设计选择:为什么 stride=4?
HRPE 在整个网络中保持恒定的 output stride $s=4$。这个选择经过了严格的消融验证:stride=8 时 F1 从 97.05 暴跌到 86.91(-10.14),Fa 从 1.02 飙升到 22.38(+22 倍);stride=2 时 F1 反而下降到 95.25,且 FLOPs 增加到 26.77G。
SPIRE 的训练管线出奇地简单——不需要多阶段训练、伪掩码生成或课程学习策略。
监督信号离线构造
PRPS 监督图在数据预处理阶段离线构造,不参与网络的前向计算。对于每张训练图像,从单点标注出发,按 stride 映射 → 辐射峰值对齐 → Gaussian 先验 → 对比度调制 → 多目标聚合的顺序生成 $\mathbf{P}^* \in \mathbb{R}^{H' \times W'}$。这个监督图在训练过程中保持固定。
损失函数
SPIRE 使用标准的像素级 MSE 回归损失:
论文特别强调:不需要特殊的 imbalance-aware loss(如 Focal Loss 或 Dice Loss)。原因在于 PRPS 已经通过 Gaussian-like 监督将正样本占比从 0.004% 提升到 0.44%,提供了足够稠密的梯度信号。这与分割范式形成鲜明对比——分割方法必须依赖 weighted BCE 或 Focal Loss 来应对极端不平衡。
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 数据集 | SIRST-UAVB (3000: 2400/600), SIRST4 (3352: 2285/1067) | ✅ 论文披露 |
| 训练 GPU | RTX 4090 × 1 | ✅ 论文披露 |
| 优化器 | Adam, lr=0.01 | ✅ 论文披露 |
| LR 调度器 | ReduceLROnPlateau (factor=0.01, patience=3) | ✅ 论文披露 |
| Batch size | 10 | ✅ 论文披露 |
| Epochs | 400 | ✅ 论文披露 |
| 输入分辨率 | 640×640 (UAVB), 512×512 (SIRST4) | ✅ 论文披露 |
| PRPS σ / r | 2 / 6 | ✅ 论文披露 |
| Output stride s | 4 | ✅ 论文披露 |
| BN momentum | 0.1 | ⚠️ 代码披露(论文未提及) |
| 训练总时间 | — | ❌ 未披露 |
| Checkpoint 选择策略 | — | ❌ 未披露 |
代码与论文的不一致
论文声称使用单通道输入 $\mathbf{I} \in \mathbb{R}^{H \times W \times 1}$,但开源代码中 SPIRENet 的 stem 层实际使用 nn.Conv2d(3, 64, ...)(3 通道输入)。此外,预训练权重文件名标注为 epoch230-lr0.005,与论文声称的 400 epochs + lr=0.01 不一致。复现时需注意这些差异。
SPIRE 的推理过程不涉及掩码重建、连通域分析或任何学习型后处理——目标坐标通过纯确定性的峰值提取从预测响应图 $\hat{\mathbf{P}}$ 中获取。
四步峰值提取
Step 1:局部最大值提取。用 3×3 max-pooling NMS(stride=1)保留空间局部最大值,抑制邻域内的冗余响应:偏移幅度固定为 $1/s$(stride=4 时为 0.25 像素)。这是一种极度简化的亚像素估计——不如抛物面拟合精确,但计算开销几乎为零。
Step 4:坐标逆映射。将热图坐标通过逆仿射变换 $\mathbf{T}^{-1}$ 映射回原图空间:评估协议
SPIRE 采用质心级评估:预测检测与真实质心的欧氏距离 $\le \delta=5$ 像素则判为 TP。所有方法(包括分割方法)的输出都被转换为质心坐标后统一评估,确保比较的公平性。报告指标包括 Precision、Recall(即检测概率 Pd)、F1 和虚警率 Fa($= FP / N_{pixels}$)。
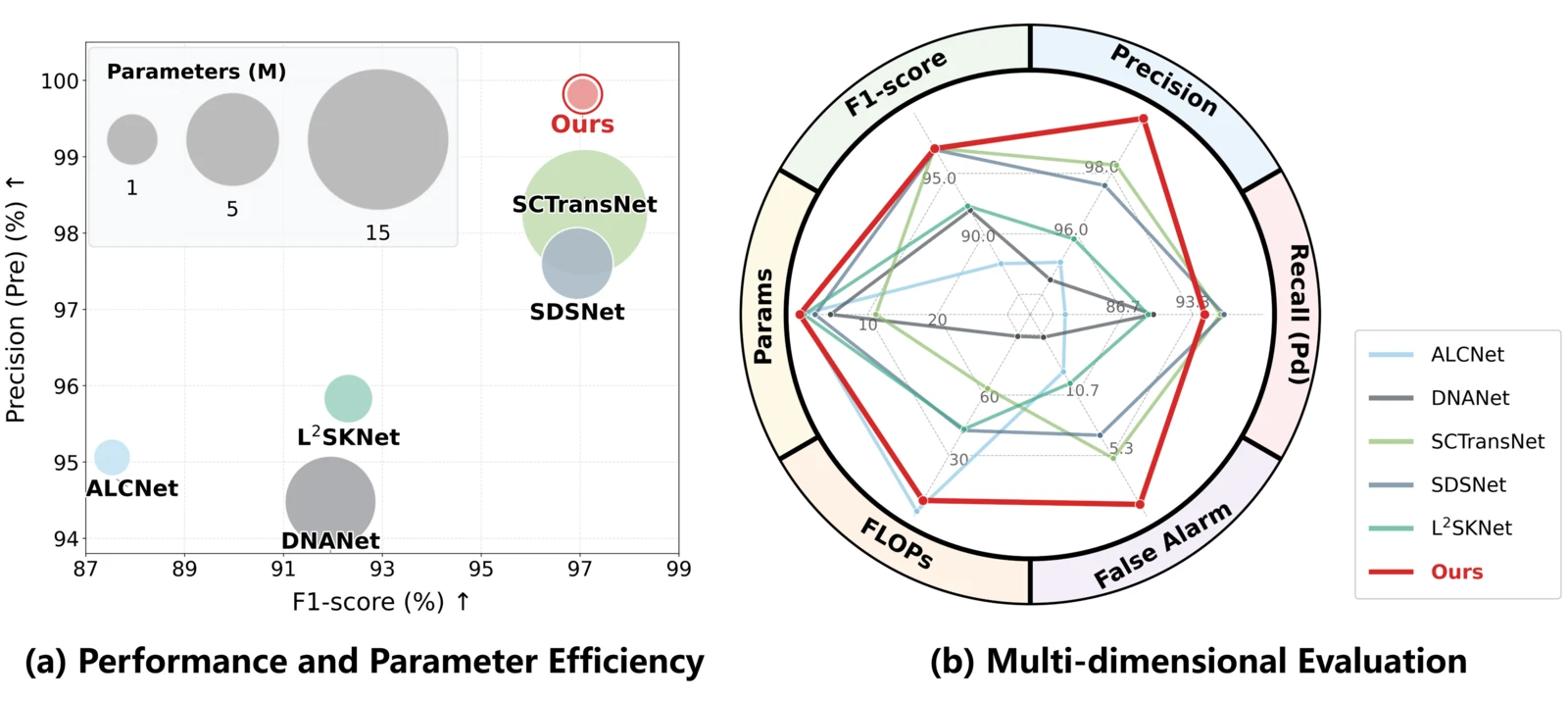
主实验:SIRST-UAVB + SIRST4
| 方法 | 会议 | SIRST-UAVB | SIRST4 | FLOPs(G) | Params(M) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Fa | Pre | Rec | F1 | Fa | ||||
| ACM | WACV'21 | 87.01 | 71.16 | 78.29 | 34.04 | 90.17 | 70.38 | 79.05 | 44.08 | 2.51 | 0.40 |
| DNANet | TIP'23 | 94.48 | 89.54 | 91.95 | 15.77 | 93.99 | 81.20 | 87.13 | 29.82 | 89.13 | 4.70 |
| SCTransNet | TGRS'24 | 98.27 | 95.95 | 97.09 | 5.09 | 81.20 | 86.39 | 83.72 | 114.98 | 63.22 | 11.19 |
| SDSNet | TGRS'25 | 97.60 | 96.29 | 96.94 | 7.12 | 87.35 | 88.27 | 87.81 | 73.48 | 42.42 | 2.49 |
| L²SKNet | TGRS'25 | 95.83 | 89.04 | 92.31 | 11.70 | 92.89 | 91.42 | 92.16 | 40.20 | 43.09 | 0.90 |
| SPIRE | — | 99.82 | 94.44 | 97.05 | 1.02 | 95.00 | 94.21 | 94.60 | 28.53 | 7.68 | 0.29 |
消融实验 1:PRPS 监督形式
| 监督形式 | Pre | Rec | F1 | Fa |
|---|---|---|---|---|
| PRPS (σ=2, r=6) | 99.82 | 94.44 | 97.05 | 1.02 |
| 单点 impulse | 98.71 | 90.22 | 94.27 | 2.85 |
| 无约束 Gaussian | 98.93 | 93.76 | 96.28 | 2.44 |
PRPS 比 impulse 监督高 2.78 个 F1,Fa 低 2.8 倍;比纯 Gaussian 高 0.77 个 F1,Fa 低 2.4 倍。Impulse 的梯度饥饿导致 Recall 下降 4.22 个点;纯 Gaussian 缺乏辐射梯度调制,虚警控制不如 PRPS。

消融实验 2:HRPE 分辨率与组件
| 变体 | Pre | Rec | F1 | Fa | FLOPs | Params(10⁻²M) |
|---|---|---|---|---|---|---|
| HRPE (s=4) | 99.82 | 94.44 | 97.05 | 1.02 | 7.68 | 29.47 |
| s=2 | 99.63 | 91.23 | 95.25 | 0.81 | 26.77 | 26.56 |
| s=8 | 90.05 | 83.98 | 86.91 | 22.38 | 3.05 | 33.27 |
| w/o channel reorg | 97.70 | 93.90 | 95.76 | 5.33 | 7.70 | 29.45 |
| w/o reweighting | 96.52 | 93.71 | 95.09 | 8.15 | 7.72 | 29.63 |
定性对比

SPIRE 在研究版图上的位置
SPIRE 站在三条研究线索的交汇点上:单点监督(LESPS #LESPS-2023、MCLC #MCLC-2023 验证了标注效率的可行性)、热图回归(HRNet #HRNet-2019 确立了峰值提取范式)、轻量架构(ShuffleNet #ShuffleNet-2018 提供了通道重组组件)。它的创新不在于任何一条线索的深化,而在于将三者同时做到极致,并彻底删除 decoder——这种"减法"在当前"加法为主"的 IRSTD 领域是反直觉的。
可操作的研究启发
第一,物理先验应该编码进监督信号而非网络结构。PRPS 的对比度调制比在 encoder 中加入物理约束更简单、更可控。这一思路可以迁移到其他有物理成像模型的任务中(如 SAR 目标检测、医学影像定位)。
第二,encoder-only 在"回归型"任务上有天然优势。当输出不是密集分割而是稀疏坐标/热图时,decoder 的多尺度融合收益有限,甚至引入冗余。这对设计实时 IRST 系统有直接的工程价值。
第三,centroid-level 评估改变了 IRSTD 的竞争格局。SPIRE 的 Precision 99.82% 和 Fa 1.02 在像素级 IoU 评估下可能不占优势,但在"能否准确定位目标"这一下游任务的核心需求上,它的优势非常明显。
局限与开放问题
局限性
1. 代码与论文不一致:输入通道数(1 vs 3)、训练配置(400 epochs/lr=0.01 vs 权重文件名标注的 230 epochs/lr=0.005)存在矛盾,影响精确复现。
2. 评估协议的宽容性:δ=5 像素的质心匹配阈值对 2-9 像素的目标来说相当宽松,可能掩盖定位精度的真实差异。
3. 跨域泛化未验证:仅在两个数据集上测试,未评估跨传感器、跨场景的泛化能力。PRPS 的 σ 和 r 是否需要在新的红外成像条件下重新标定,是一个开放问题。
4. 亚像素精度有限:sub-pixel refinement 使用 ±1/stride 的固定偏移,不如抛物面拟合精确。对于需要亚像素定位精度的应用(如目标测距),可能不够。
与红外图像压缩系列的关联
红外图像压缩系列 的核心主张之一是:红外压缩需要在低码率下保留对下游任务(检测、识别、测温)真正重要的信息。SPIRE 的 centroid-level 概率回归为"什么信息是重要的"提供了一个精确答案——目标质心位置的可靠估计比像素级轮廓重建更重要。这意味着一个面向 IRSTD 的压缩系统不需要保留目标的精确形状,只需要保证热图响应的主峰位置不被偏移——这是一个比 PSNR/MSSIM 更符合下游任务需求的压缩目标。
上一篇精读 RPCASSM 从稀疏-低秩分解角度解决 IRSTD,SPIRE 则从概率回归角度切入——两者代表了 IRSTD 领域"轻量化"浪潮的两种不同哲学。
参考来源
- Ni, R. et al. "Rethinking IRSTD: Single-Point Supervision Guided Encoder-only Framework is Enough for Infrared Small Target Detection." arXiv:2604.05363, 2026. arXiv · Code
- Li, B. et al. "Dense Nested Attention Network for Infrared Small Target Detection." IEEE TIP, 2023.
- Chen, M. et al. "SCTransNet: Spatial-Channel Cross Transformer for Infrared Small Target Detection." IEEE TGRS, 2024.
- Wang, R. et al. "MCLC: Multi-level Constraints for Single-point Supervised Infrared Small Target Detection." 2023.
- Wu, X. et al. "LESPS: Label-efficient Infrared Small-target Detection via Single-point Supervision." CVPR, 2023.
- Sun, K. et al. "Deep High-Resolution Representation Learning for Visual Recognition." CVPR, 2019.
- Ma, N. et al. "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design." ECCV, 2018.