One Shot, One Talk
很多音频驱动或姿态驱动数字人方法,最后都直接输出 RGB 视频。这样做可以很快看到效果,但它很难变成一个可重用的 avatar:换视角困难,身份和衣服纹理容易漂移,动作控制依赖 2D landmark 或 pose map,长视频中还会出现时间不一致。One Shot, One Talk 的目标更像“从一张全身照片造一个可驱动资产”,而不是“每次给 prompt 重新生成一段视频”。#One-Shot-One-Talk-2024
这也是它在 avatar 调研里特别重要的原因。它把 2D human video diffusion 放在教师位置:MimicMotion 生成身体伪帧,Portrait4D-v2 生成头脸伪帧;但最终产品不是这些伪视频,而是一个绑定身份的 3DGS-mesh hybrid avatar。也就是说,2D 扩散负责补足单图看不到的动作样本,3D 表示负责把这些样本沉淀成可渲染资产。

论文的表示是显式 hybrid:SMPL-X mesh 提供全身几何结构,包括身体、手和脸;3D Gaussians 初始化在 canonical mesh surface 上,通过 UV parameterization 分布到人体表面。两者不是完全刚性绑定,而是通过 Gaussian deformation \(dX\) 和 mesh deformation \(dT\) 两个变形场共同学习。#One-Shot-One-Talk-2024
3DGS-mesh hybrid avatar
3D Gaussian Splatting 负责高效、可微的外观渲染;SMPL-X 负责人体拓扑、关节、手和脸的可控参数。One Shot, One Talk 使用 mesh-Gaussian consistency、normal consistency、mask loss 和 Laplacian smoothing,让 Gaussian field 不至于脱离人体 mesh 的几何结构。#One-Shot-One-Talk-2024
论文实现上使用 isotropic Gaussian field,固定 opacity 和 rotation,UV resolution 为 512,约 150,000 个 Gaussians。这个配置说明它不是简单把 3DGS 当场景点云,而是在人体 mesh 表面组织一个可驱动、可正则的外观场。
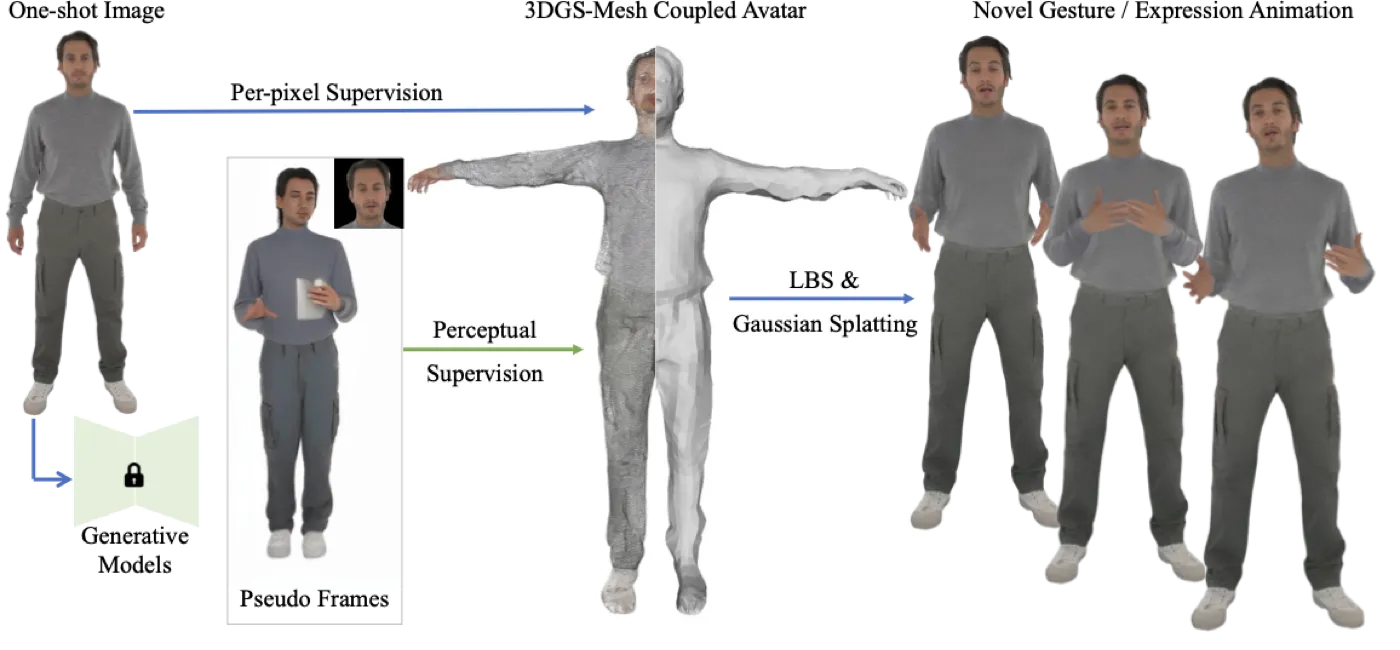
整个流程可以拆成八步:先把输入图像注册到 SMPL-X;再从 100 个 TED Gesture Dataset 视频收集姿态和表情序列;用 MimicMotion 根据 DWPose control 生成 body pseudo frames;用 Portrait4D-v2 生成 head / facial expression pseudo frames;再重新 tracking 伪帧得到更准确的 pose/expression 参数,同时固定 source shape;最后用单张原图和这些不完美伪帧训练 3DGS-mesh avatar。#One-Shot-One-Talk-2024
flowchart TD A["Single full-body image"] --> B["SMPL-X registration"] C["TED Gesture pose/expression sequences"] --> D["MimicMotion body pseudo frames"] C --> E["Portrait4D-v2 face pseudo frames"] D --> F["Re-tracking pose and expression"] E --> F B --> G["Coupled SMPL-X + 3D Gaussian avatar training"] F --> G G --> H["Gaussian splatting renderable talking avatar"]
这个设计解决了单图训练的核心矛盾:真实输入图只有一个视角和一个姿态,无法覆盖说话、手势和表情变化;扩散伪帧可以提供运动多样性,但会带来身份漂移、姿态错位和手脸失真。One Shot, One Talk 不盲信伪帧,而是对原图使用逐像素 source-image losses,对伪标签使用 LPIPS perceptual supervision,并通过 mesh constraints 约束几何。
这篇论文不是 benchmark paper。它使用 TED Gesture Dataset 的姿态和表情作为训练 motion source,评估输入和驱动姿态主要来自 ActorsHQ 与 Casual Conversations Dataset。视频预处理包括 9:16 crop/resize、30 FPS、BiRefNet foreground segmentation 和 ExAvatar-style pose tracking。量化指标主要是 reconstruction-like metrics:MSE、L1、PSNR、SSIM、LPIPS。论文报告 Ours 相比 ELICIT、ExAvatar 和 MimicMotion 有更好重建质量,例如 PSNR 29.31、LPIPS \(2.99\times10^{-2}\)。#One-Shot-One-Talk-2024
| 维度 | 论文覆盖 | 调研写作时的边界 |
|---|---|---|
| 重建/画质 | MSE、L1、PSNR、SSIM、LPIPS | 可以说明 3D avatar 训练质量 |
| 身份保持 | 定性展示和 source-image/perceptual loss 支撑 | 没有完整 identity benchmark 表 |
| 音频同步 | 不是主要评估项 | 不能写成 audio-lip-sync 强基线 |
| 运动/动作 | cross-identity pose reenactment 与 novel gestures | 强调可驱动资产,而非端到端音频动作预测 |
| 效率 | 3DGS 暗示渲染高效 | 论文未披露完整 runtime / FPS |
One Shot, One Talk 的评估边界

限制也很清楚:方法依赖单图与 parametric mesh 的准确注册;手指和自交会导致优化与纹理错误;由于 human motion diffusion 缺少大视角数据,完整 360° reconstruction 仍然困难;论文没有给出完整训练/推理效率,也没有专门 audio sync 或 full-body benchmark schema。#One-Shot-One-Talk-2024
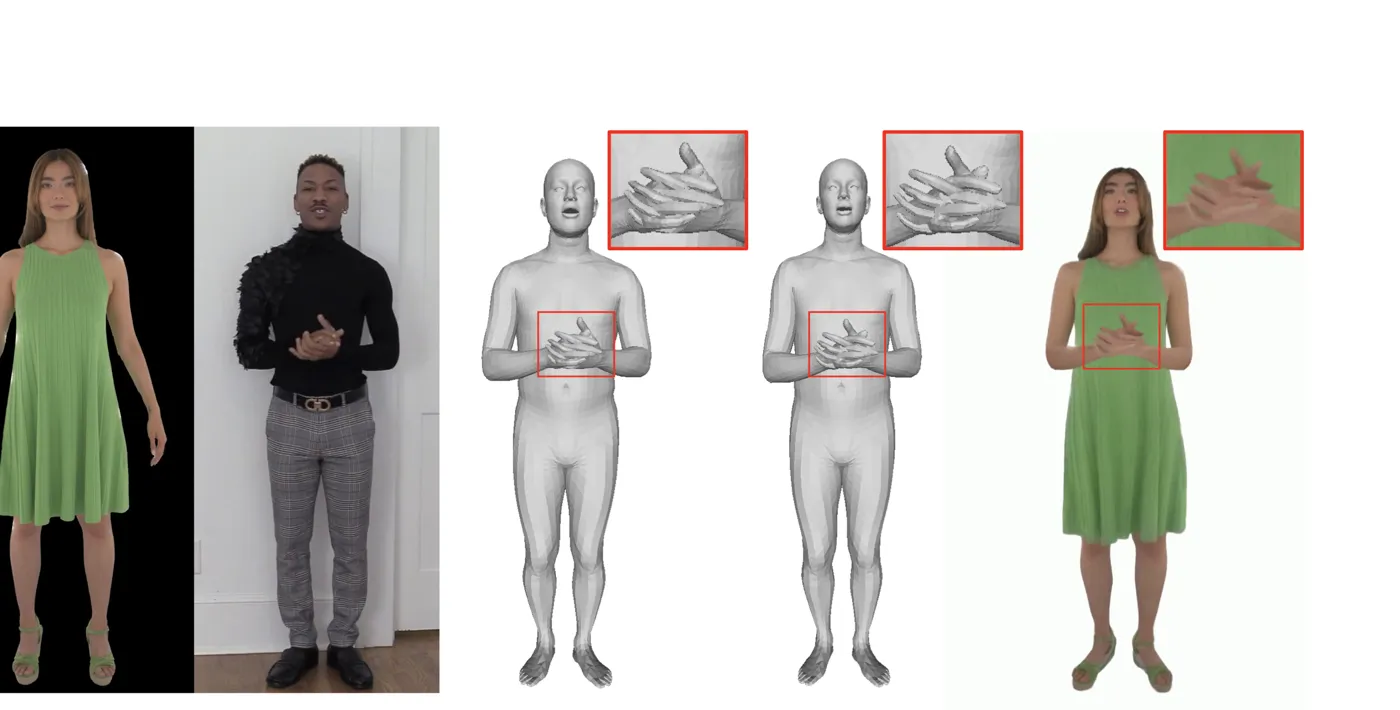
在 avatar 调研里,One Shot, One Talk 应放入“3D renderable full-body avatar”路线。它与 OmniAvatar、EMO2、ChatAnyone 的根本区别不是画面是否全身,而是最终产物是否可复用。OmniAvatar 输出 full-frame video,EMO2 输出 upper-body video,ChatAnyone 输出实时 upper-body portrait video;One Shot, One Talk 则训练一个绑定身份、可用 SMPL-X 控制并通过 Gaussian splatting 渲染的 avatar asset。
| 维度 | One Shot, One Talk | 2D video avatar 路线 |
|---|---|---|
| 最终产物 | 可复用的 3DGS-mesh avatar asset | 每次直接生成 RGB 视频帧 |
| 控制方式 | SMPL-X pose/expression + Gaussian deformation | 音频、文本、2D pose、landmarks 或 latent condition |
| 身份稳定 | 通过单图 source loss 与 3D 表示约束身份 | 依赖视频模型隐式保持身份,容易漂移 |
| 主要风险 | 注册错误、mesh prior mismatch、手指自交、视角缺失 | 时序闪烁、手脸失真、不可复用、3D 不一致 |
One Shot, One Talk 与 2D video avatar 路线对比
读完这篇论文应记住什么
- 路线定位:这是 3D renderable avatar,不是普通 2D talking video generator。
- 核心表示:SMPL-X 提供人体结构,3D Gaussians 提供可渲染外观。
- 关键策略:MimicMotion 和 Portrait4D-v2 只提供伪监督,最终资产由 3DGS-mesh 训练得到。
- 不能过度声明:论文没有完整 audio sync benchmark,也没有披露完整运行 FPS。
参考来源
- Zhang et al. (2024). One Shot, One Talk: Whole-body Talking Avatar from a Single Image. arXiv:2412.01106