ML Visualized
ML Visualized 是一本由 Gavin H(University of Maryland)创建的 Jupyter Notebooks 电子书。它的核心理念是:从第一性原理出发,用数学推导 + 代码实现 + 可视化动画三者结合,彻底理解机器学习算法的本质。
核心特色
- 第一性原理:每个公式都有完整推导过程
- 纯 NumPy:不依赖 sklearn/TensorFlow,从零构建
- 训练动画:每个 Notebook 输出 GIF,观测收敛行为
- 开源共建:接受 PR,任何人都可贡献新的算法章节
每个 Notebook 的输出都是一个训练过程动画 GIF — 从随机初始化的权重开始,逐步迭代,最终收敛到最优解。这个过程比任何静态图表都更能建立直觉。
第一章从最简单的线性回归出发,理解机器学习的核心范式:找到使损失函数最小的权重参数。
损失函数:Mean Squared Error
模型预测 $\hat{y} = wx + b$,损失函数定义为:
梯度下降更新规则
核心思想:沿着损失函数梯度的反方向迭代更新参数。
其中 $\eta$ 是学习率(learning rate),控制每一步更新的幅度。
偏导数推导
对权重 $w$ 的偏导:
对偏置 $b$ 的偏导:
NumPy 实现
def mse_loss(x, y, w, b):
return np.mean(np.square(y - (w * x + b)))
def mse_loss_dw(x, y, w, b):
return -2 * np.mean(x * (y - (w * x + b)))
def mse_loss_db(x, y, w, b):
return -2 * np.mean(y - (w * x + b))
def update_w_and_b(x, y, w, b, learning_rate):
w = w - mse_loss_dw(x, y, w, b) * learning_rate
b = b - mse_loss_db(x, y, w, b) * learning_rate
return w, b
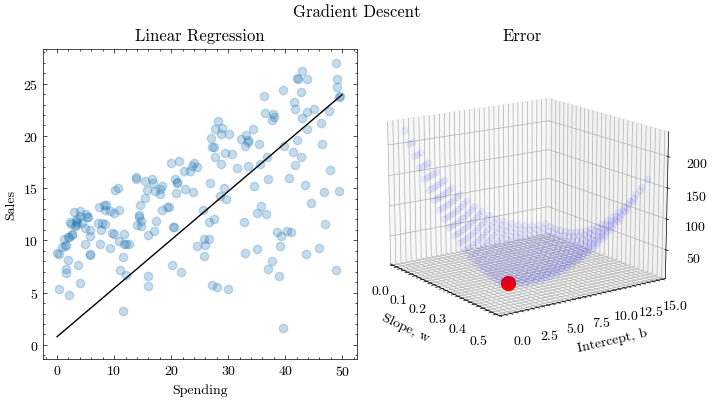
可视化输出
该 Notebook 输出一个 GIF 动画,包含两个视图:
- 左图:线性回归拟合散点数据,线条逐渐逼近最优解
- 右图:3D 误差曲面(w-b 平面上的损失函数),红点追踪梯度下降轨迹
4000 epochs 后收敛到 $w \approx 0.456, b \approx 1.026$,loss 从 197.25 降到 39.06。
在训练模型之前,先要理解数据。第二章介绍两种无监督学习方法,用于数据探索和预处理。
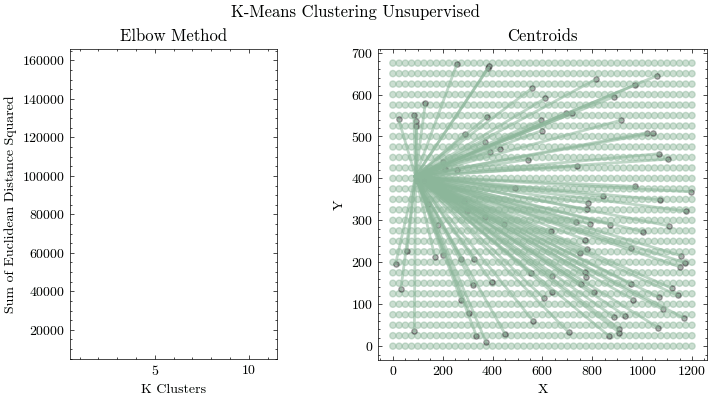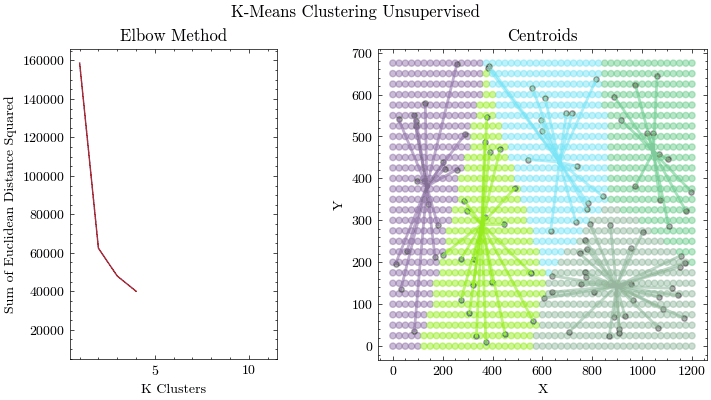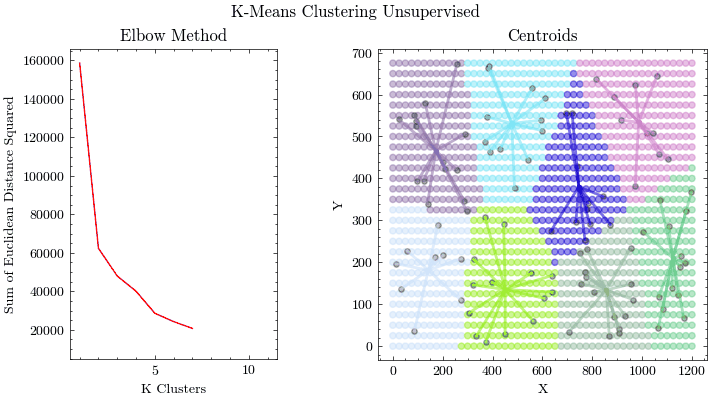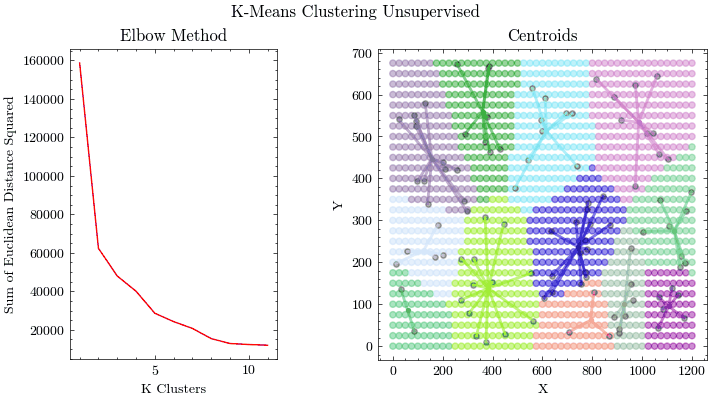
K-Means Clustering
无监督聚类算法,将数据点分组到 K 个簇中。
算法步骤
- 随机初始化 K 个质心位置
- 将每个数据点分配给最近的质心(欧几里得距离)
- 更新质心为该簇所有点的均值
- 重复 2-3 直到收敛(质心不再移动)
距离函数
可视化特点
- 动态展示质心移动轨迹
- Voronoi 图显示决策边界
- Elbow Method 图表辅助选择最优 K
Principal Component Analysis (PCA)
降维技术,找到数据中方差最大的方向(主成分)。
核心思想
将高维数据投影到低维空间,同时尽可能保留信息(方差)。
数学基础
- 协方差矩阵:$\Sigma = \frac{1}{n} XX^T$
- 特征值分解:找到方差最大的正交方向
- 投影:$X_{reduced} = X \cdot V_k$,其中 $V_k$ 是前 k 个特征向量
第三章从最简单的单层模型出发,引入激活函数的概念,展示如何从线性分类器扩展到非线性模型。
Perceptron(感知机)
最简单的神经网络单元,无激活函数。
更新规则
若预测错误:$W := W + yx^T$
局限性:只能处理线性可分数据,且收敛性依赖数据分布。
Logistic Regression
引入激活函数,将二分类问题转化为概率输出。
Sigmoid 激活函数
将任意实数映射到 $(0, 1)$ 区间,表示属于正类的概率。
Binary Cross Entropy Loss
核心改进
| 特性 | Perceptron | Logistic Regression |
|---|---|---|
| 输出 | 0/1 分类 | 概率 $[0, 1]$ |
| 激活函数 | 无(线性) | Sigmoid |
| 损失函数 | 0-1 Loss | Cross Entropy |
| 优化方法 | 感知机规则 | 梯度下降 |
第四章是全书核心,介绍如何堆叠多层线性变换 + 非线性激活函数,构建能逼近任意复杂函数的神经网络。
网络结构
3 层全连接网络:Input → Hidden 1 → Hidden 2 → Output
前向传播
矩阵形式:$Z = WX + B$(线性变换),$A = g(Z)$(激活函数)。
Tanh 激活函数
梯度:$\tanh'(z) = 1 - \tanh^2(z)$,计算高效。
损失函数
反向传播(Backpropagation)
核心思想:用链式法则从后向前计算每个参数的梯度,然后梯度下降更新。
链式法则推导
对输出层的权重 $W_3$:
三个分量的含义:
- $\frac{\partial J}{\partial A_3}$:损失函数对输出的梯度(MSE 梯度)
- $\frac{\partial A_3}{\partial Z_3}$:激活函数的梯度(tanh 梯度)
- $\frac{\partial Z_3}{\partial W_3} = A_2$:输入(上一层的激活输出)
梯度更新公式
# 输出层梯度
dZ3 = (y_pred - y_true) * tanh_prime(Z3)
dW3 = np.dot(dZ3, A2.T) / n
dB3 = np.mean(dZ3, axis=1, keepdims=True)
# 隐藏层梯度(反传)
dA2 = np.dot(W3.T, dZ3)
dZ2 = dA2 * tanh_prime(Z2)
dW2 = np.dot(dZ2, A1.T) / n
dB2 = np.mean(dZ2, axis=1, keepdims=True)
# 更新权重
W3 = W3 - learning_rate * dW3
B3 = B3 - learning_rate * dB3
四个可视化部分
| 部分 | 内容 | 目的 |
|---|---|---|
| Loss Landscape | 权重空间的损失函数曲面 | 理解收敛行为和局部最小值 |
| Transformations | 每层如何变换数据空间 | 直觉理解特征提取过程 |
| Function Approximation | 验证通用近似定理 | 理解网络的表达能力 |
| Backpropagation | 链式法则和梯度计算 | 理解优化过程的核心机制 |

核心公式表
| 概念 | 公式 | 代码实现 |
|---|---|---|
| MSE Loss | $\frac{1}{n}\sum(y_i-\hat{y}_i)^2$ | np.mean(np.square(y-y_pred)) |
| Sigmoid | $\frac{1}{1+e^{-z}}$ | 1/(1+np.exp(-z)) |
| Tanh | $\frac{e^z-e^{-z}}{e^z+e^{-z}}$ | np.tanh(z) |
| BCE Loss | $-\sum[y\log\hat{y}+(1-y)\log(1-\hat{y})]$ | -np.mean(ynp.log(p)+(1-y)np.log(1-p)) |
| 链式法则 | $\frac{\partial f}{\partial x} = \frac{\partial f}{\partial u} \cdot \frac{\partial u}{\partial x}$ | 逐层反向传播 |
| 矩阵求导 | $\frac{\partial}{\partial W}(WX+B) = X^T$ | np.dot(dZ, A_prev.T) |
代码基础模式
# 训练循环模板
for epoch in range(epochs):
# Forward
Z, A = forward(X, W, B)
# Compute Loss
loss = compute_loss(y, A)
# Backward
dW, dB = backward(y, A, Z, X)
# Update
W = W - learning_rate * dW
B = B - learning_rate * dB
核心数据结构
- 权重矩阵 W:形状 (output_dim, input_dim)
- 偏置向量 B:形状 (output_dim, 1)
- 层输出 A:形状 (batch_size, output_dim)
- 梯度 dZ:与 Z 同形状的反向传播信号
| 资源 | 特点 | 适合人群 |
|---|---|---|
| ML Visualized | 公式推导 + 代码实现 + 可视化 | 初学者想深入理解 |
| Stanford CS229 | 数学严谨,涵盖面广 | 学术方向 |
| 3Blue1Brown | 直觉可视化,动画精美 | 建立直观理解 |
| fast.ai | 实践导向,快速上手 | 工程应用 |
- 每个公式都有完整推导过程(不只是结论)
- 代码可以直接运行复现(纯 NumPy)
- 训练过程动画展示收敛行为(不只是最终结果)
ML Visualized 是一套优质的机器学习入门资源,特别适合:
- 想要从数学层面理解 ML 算法的人
- 想要亲手实现经典算法(不依赖框架)的人
- 需要可视化辅助建立直觉的视觉型学习者
- 先看动画了解整体流程(网站直接浏览)
- 再读数学推导理解原理(讲义 PDF)
- 最后跑代码亲手实验(Colab 或本地)