RPCASSM
红外小目标检测(ISTD)是军事侦察、海上搜救、边境监控等场景中的核心技术。它的任务是:在红外图像中找出仅占数个像素、缺乏形状纹理特征的远距离弱小目标。
三重核心挑战
极低信噪比(Low SNR):远距离红外成像条件下,目标信号强度与背景噪声接近,目标像素灰度值可能仅比周围背景高出数个量化级别。 背景杂波干扰:云层边缘、地表热辐射不均匀区域等背景结构在空间频率和局部对比度上与真实目标高度相似,产生大量类目标虚警源。 目标信息极度匮乏:目标仅占数个像素(典型 2×2 到 9×9),任何下采样操作都可能导致目标信号被完全抹除或与背景平均化;同时缺乏纹理、形状等高级语义线索。本文核心主张
RPCASSM 的核心洞察是:红外图像的物理成像特性天然满足鲁棒主成分分析(RPCA)分解假设——背景低秩、目标稀疏。这一先验不应仅作为正则化项,而应成为网络架构本身的归纳偏置。
基于此,RPCASSM 提出了双分支状态空间模型:BSSM 建模背景的全局低秩结构,TSSM 聚焦目标的稀疏结构。以仅 0.45M 参数在 NUDT-SIRST 上达到 mIoU 95.98%、Pd 98.62%、Fa 2.22×10⁻⁶,全面超越 10 个 SOTA 方法。
作者与机构
第一作者:Pingping Liu(刘萍萍,吉林大学计算机科学与技术学院教授)共同作者:Aohua Li、Yubing Lu、Jin Kuang、Tongshun Zhang、Qiuzhan Zhou
通讯作者:Pingping Liu(liupp@jlu.edu.cn)
机构:吉林大学计算机科学与技术学院、吉林大学软件学院、长江大学地球科学学院
代码:github.com/PepperCS/RPCASSM(承诺开源,截至撰写时仅有 README)
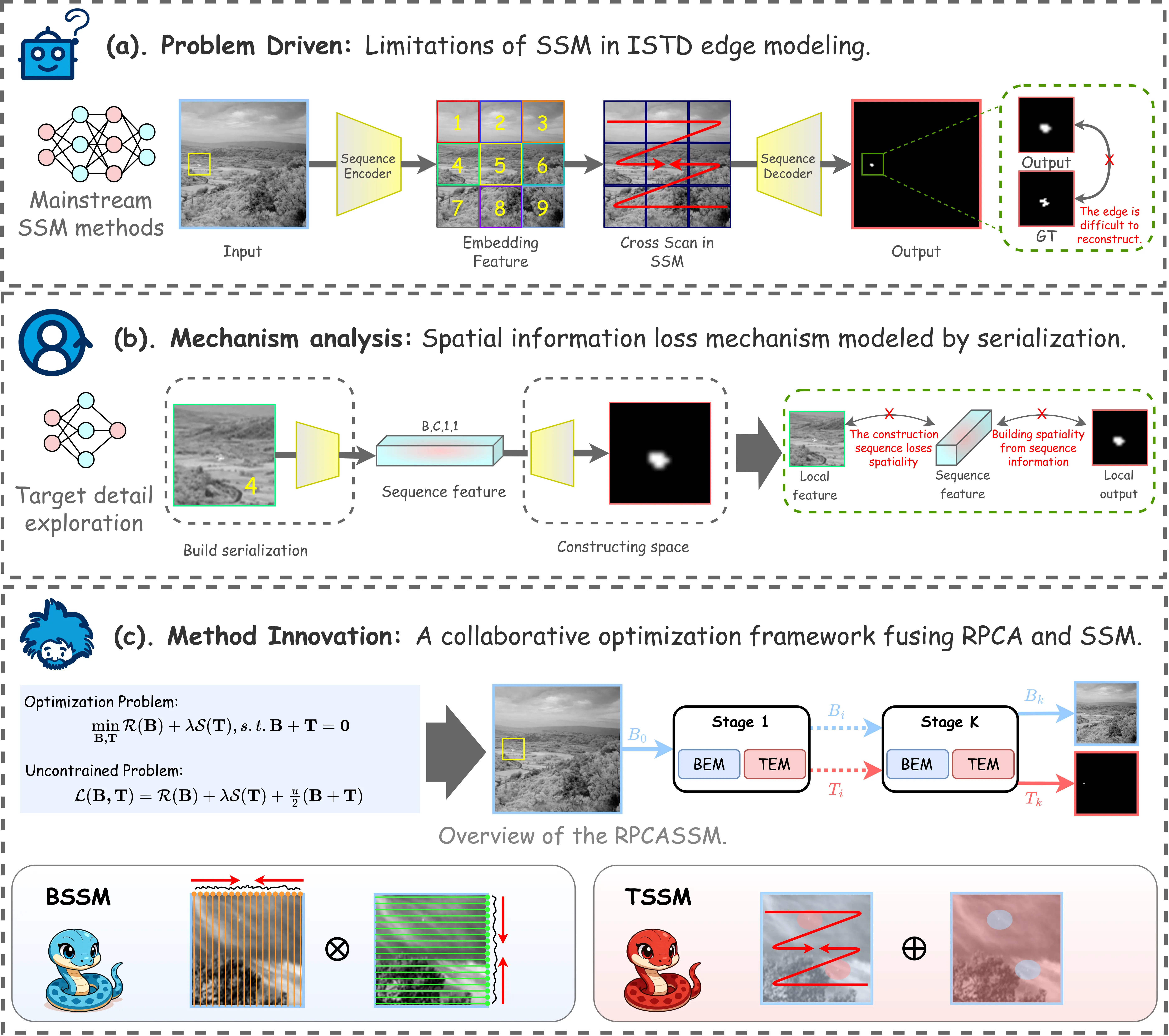
当前主流的视觉状态空间模型(如 VMamba、Vim)在设计上存在与 ISTD 任务的三重架构失配。
失配 1:下采样致命
现有 VSSM 通常在 stem 阶段通过步长大于 1 的卷积进行激进下采样以降低序列长度。这对通用视觉任务是合理的效率权衡,但对 ISTD 是致命的——几个像素的目标在下采样后要么完全消失,要么其关键的像素级对比度模式被周围背景平均掉。
失配 2:扫描模式不匹配
现有 VSSM 的扫描模式(如 VMamba 的 cross-scan)是为捕获语义级和结构级长程依赖而优化的,其序列化粒度与扫描顺序针对自然图像的物体边界和区域一致性设计,而非保留像素级极值信号。
失配 3:因果约束阻碍边缘重建
SSM 的因果约束意味着序列中后续位置无法影响先前位置的隐藏状态。当目标信号在序列化过程中被分散到不同时间步时,这种单向性进一步阻碍了完整目标边缘的重建。
RPCA 与红外图像的天然联系
红外背景在空间上呈现高度的平滑性和冗余性——相邻像素之间存在强相关性,整个背景矩阵可以用低秩结构良好近似;而红外小目标在空间上表现为孤立的、稀疏的高亮异常点,恰好对应 RPCA 框架中的稀疏分量。因此,将红外图像分解为低秩背景 $B$ 和稀疏目标 $T$(即 $D = B + T$)不仅是一个数学上的便利假设,而是有坚实物理基础的建模选择。
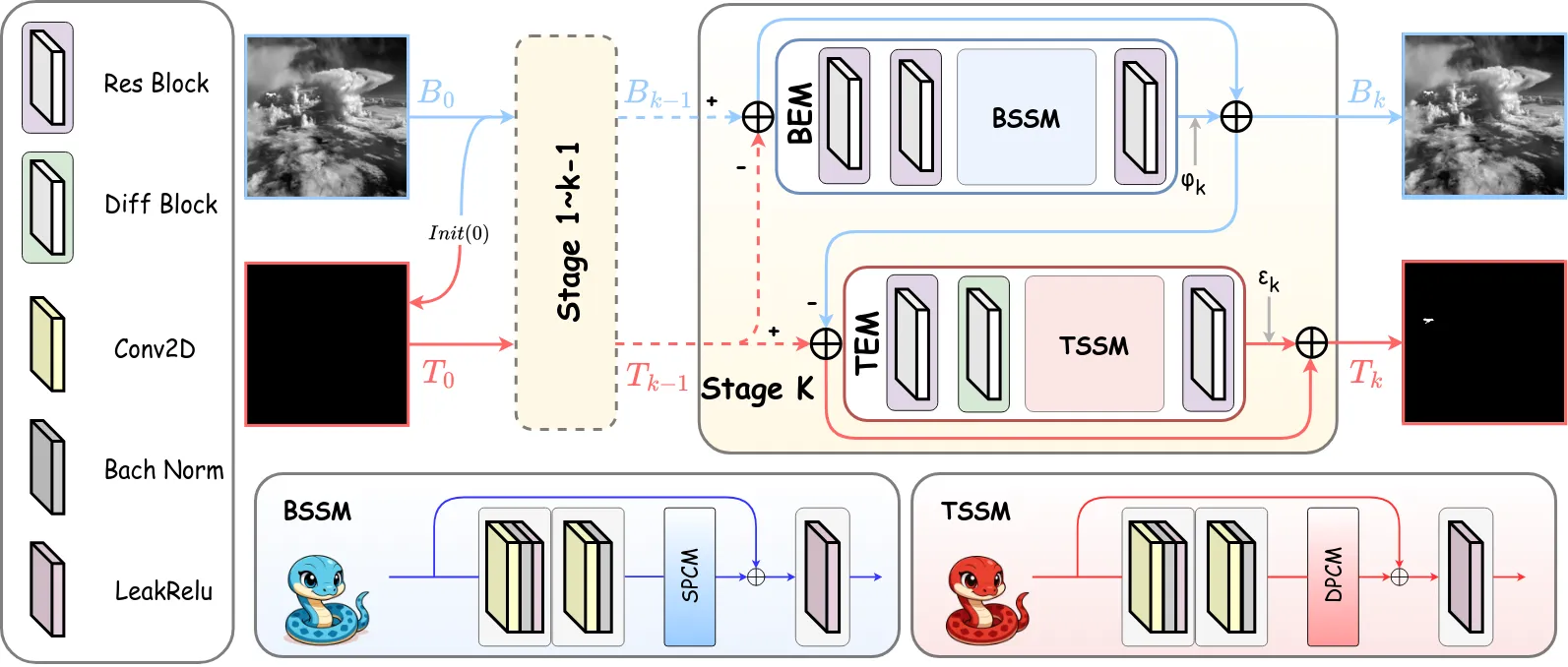
RPCASSM 的整体架构是对鲁棒主成分分析(RPCA)交替优化算法的深度展开(Deep Unfolding)。在经典 RPCA 框架中,红外图像 $D$ 被分解为低秩背景 $B$ 和稀疏目标 $T$,通过反复交替更新两个分量来逼近最优解。RPCASSM 将这一迭代过程直接映射为网络的层级结构:每个 stage 对应一次完整的 B-T 更新循环,$k$ 个相同结构的 stage 串联构成完整网络(最优 $k=3$)。
前置知识回顾
RPCA 原始优化目标
经典鲁棒 PCA 将矩阵分解为低秩分量 + 稀疏分量,优化目标为:
其中 $\mathcal{R}(\cdot)$ 和 $\mathcal{S}(\cdot)$ 分别是背景和目标的正则化项,$\lambda$ 和 $\mu$ 平衡各项贡献。RPCASSM 将这一优化问题的求解过程展开为神经网络的前向传播。
SSM 基本方程
状态空间模型(State Space Model)通过隐藏状态的递归演化捕获序列动态依赖,核心方程为:
其中 $\mathbf{h}_t$ 为隐藏状态,$\mathbf{x}_t$ 为输入,$\mathbf{y}_t$ 为输出。矩阵 $\mathbf{A}$、$\mathbf{B}$、$\mathbf{C}$、$\mathbf{D}$ 分别表示状态转移矩阵、输入矩阵、输出矩阵和前馈矩阵。Mamba 的选择性机制使 $\mathbf{B}$、$\mathbf{C}$、$\Delta$(离散化步长)变为输入依赖的时变参数。
交替迭代公式
这个公式是整个 RPCASSM 的数学骨架,定义了每个 stage 如何从上一阶段的估计出发,产生更精确的背景和目标表示。
符号解释
- $\mathbf{B}^k, \mathbf{T}^k \in \mathbb{R}^{H \times W}$:第 $k$ 个 stage 输出的背景和目标估计
- $\varphi^k, \psi^k$:可学习标量参数,控制每步更新的幅度(类似自适应学习率),初始化为 0.1
- $\mathcal{R}^k(\cdot)$:BEM 的整体映射(ResBlock + BSSM),提取输入中的低秩背景结构
- $\mathcal{S}^k(\cdot)$:TEM 的整体映射(ResBlock + DifBlock + TSSM),提取输入中的稀疏目标结构
BSSM/SPCM:空间探针扫描机制
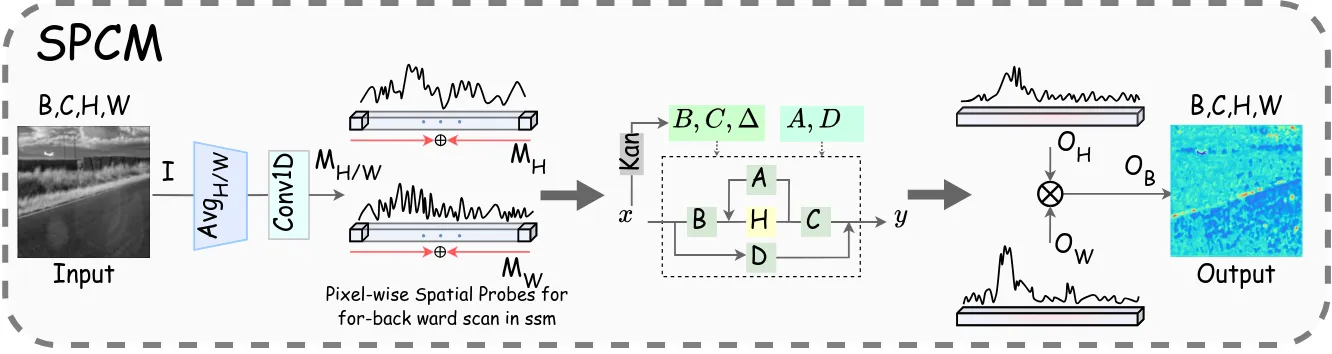
BSSM 的核心是空间探针扫描机制(SPCM),其设计动机是利用红外背景在空间轴上的异质性来定位和建模背景区域。SPCM 不直接在二维特征图上运行 SSM,而是将二维特征投影到一维空间轴上分别建模,再重新组合。
Step 1:空间轴投影对输入背景特征分别沿高度轴和宽度轴做全局平均池化,得到两条一维空间表示。平均池化保留了空间轴上的全局统计分布(如某一行整体偏亮或偏暗),这正是背景低秩特性的体现;而目标由于极度稀疏,在平均后被大幅稀释,从而实现了隐式的背景-目标分离。
Step 2:KAN 参数生成使用 Kolmogorov-Arnold Network(KAN)从空间轴表示中生成 SSM 的三个关键参数:$B$(输入矩阵)、$C$(输出矩阵)、$\Delta$(离散化步长)。KAN 相比传统 MLP 具有更强的函数逼近能力和参数效率。
Step 3:双向 SSM 扫描对每条空间轴表示分别进行正向和反向 SSM 扫描并相加,消除 SSM 因果约束带来的方向偏差。
Step 4:轴特征重组将两条轴的输出特征通过逐元素相乘重组为二维背景特征。这种分解-重组策略的计算复杂度远低于直接在 $H \times W$ 序列上运行 SSM,同时天然契合背景的低秩假设。
TSSM/DPCM:可变形提示扫描机制
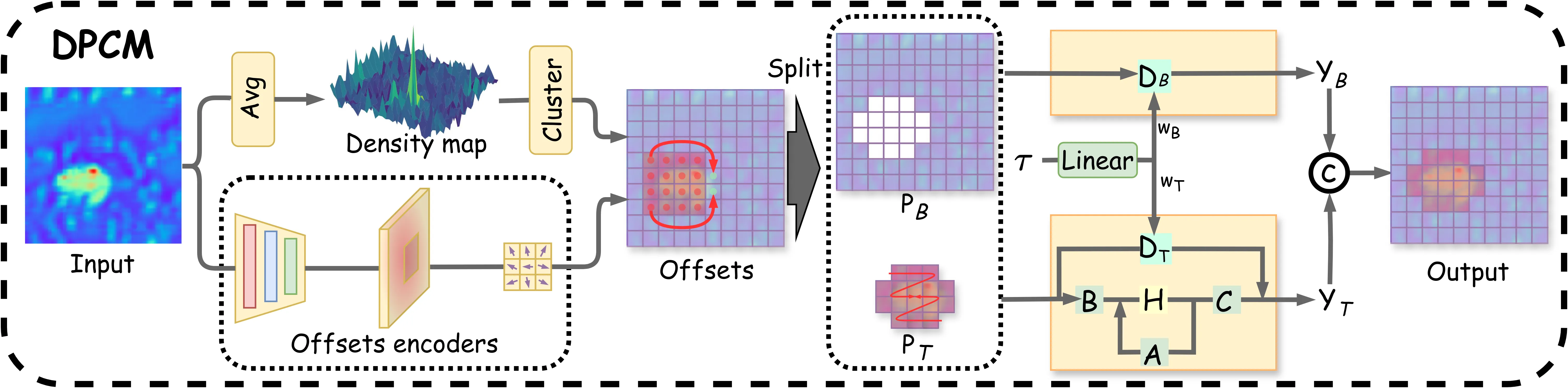
TSSM 的核心是可变形提示扫描机制(DPCM),其设计理念是利用目标的稀疏性和局部高亮特性,将计算资源集中到可能的目标区域,避免在全图均匀分配 SSM 算力造成的浪费和边缘模糊。
Step 1:密度图聚类与阈值分割对输入特征做平均池化得到密度热力图,通过自适应阈值将其二值化为目标区域掩码:
阈值从初始值 $T_{init}=0.7$ 开始,以步长 $\Delta T$ 递减,直到至少产生一个前景区域。这一自适应机制确保了即使在不同场景下目标亮度差异很大,也能可靠地提取出候选目标区域。
Step 2:可变形偏移学习引入可变形卷积的偏移学习机制 $G_{offsets}(\cdot)$,对目标区域的边界进行精细化调整,使网络能够学习到目标实际形状与初始矩形提示之间的几何偏差。
Step 3:协同控制矩阵协同控制矩阵 $\tau$ 作为共享的信息枢纽,同时调节目标和背景的前馈矩阵,防止目标区域因像素极少而在梯度更新中被背景区域淹没。
Step 4-5:分区差异化处理背景区域采用简单 Linear 映射:$\mathbf{Y}_B = \mathbf{D}_B \cdot \mathbf{P}_B$
目标区域使用带 Cross-Scan Module(CSM)的 SSM:$\mathbf{Y}_T = \mathbb{S}_{\mathbf{D}_T}^{CSM}(\mathbf{P}_T)$
Step 6:特征拼接将两个区域的输出在空间维度上拼接回完整的特征图。
DifBlock:差分卷积增强
DifBlock 位于 TEM 中 ResBlock 之后、TSSM 之前,通过空间差分运算初步增强目标的显著性。
括号内的表达式 $N^2 f_{ij} - \sum f_{i+k,j+l}$ 本质上是中心像素值的 $N^2$ 倍减去其 $N \times N$ 邻域内所有像素值之和,等价于 $(N^2-1) f_{ij} - \sum_{(k,l) \neq (0,0)} f_{i+k,j+l}$,即中心像素与邻域均值的加权差。对于均匀背景区域,该差值趋近于零;对于孤立的高亮目标像素,该差值显著为正。因此 DifBlock 起到了空间高通滤波器的作用。
| 维度 | RPCANet | LSDSSMs | VMamba | RPCASSM |
|---|---|---|---|---|
| 核心表示 | RPCA + CNN 正则化 | 低秩稀疏 + 单向 SSM | 通用 VSSM | RPCA + 双分支 SSM |
| 背景建模 | 核范数(CNN 实现) | SSM 隐式建模 | 无显式背景建模 | BSSM/SPCM 轴投影+双向SSM |
| 目标建模 | L1(CNN 实现) | 单向 SSM | 通用 token | TSSM/DPCM 可变形提示+CSM |
| RPCA 集成深度 | 浅层(仅正则化) | 中层(架构灵感) | 无 | 深层(迭代=网络stage) |
| 扫描策略 | 无(纯 CNN) | 单向扫描 | Cross-scan(4方向) | 分区差异化:目标CSM+背景Linear |
| 空间分辨率 | 全分辨率 | 全分辨率 | 下采样后处理 | 全分辨率(无下采样stem) |
| 参数量 | 0.67M | 0.37M | ~30M | 0.45M |
| NUDT mIoU | 91.30% | 94.59% | — | 95.98% |
| NUDT Fa ($10^{-6}$) | 17.99 | 3.77 | — | 2.22 |
| IRSTD-1K mIoU | 60.53% | 68.14% | — | 68.44% |
表 1:RPCASSM 与主要竞争方法的技术对比。
渐进式 IoU Loss
RPCASSM 由 k 个相同结构的 stage 串联而成,每个 stage 都会输出一个中间稀疏目标估计 $\mathbf{T}^i$。为了确保梯度在多层迭代结构中有效传播,论文采用了渐进式 IoU Loss 作为训练目标:
其中 $\mathcal{L}_{IoU}$ 是标准的 soft IoU loss,其像素级定义为:
其中 $\mathbf{Y}$ 为真实标签,$\mathrm{T}_n$ 和 $\mathrm{Y}_n$ 分别表示预测和标签在第 $n$ 个像素位置的值。
深层监督的必要性
如果仅对最终输出 $\mathbf{T}^k$ 施加监督信号,中间阶段的 BEM 和 TEM 模块可能学到无意义的表示,导致梯度在经过多个 stage 的反向传播后逐渐消失。渐进式 loss 为每个中间阶段提供了辅助梯度通路,确保每一级迭代都能产出有意义的目标估计,形成从粗到精的渐进细化过程。
训练配置
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 数据集 | NUDT-SIRST, IRSTD-1K | 论文披露 |
| 数据划分 | 1:1 随机分割 | 论文披露 |
| 输入分辨率 | 256×256(双线性插值) | 论文披露 |
| GPU | 单张 NVIDIA GeForce RTX 4070 Ti SUPER | 论文披露 |
| 深度学习框架 | PyTorch | 论文披露 |
| 优化器 | Adam | 论文披露 |
| 初始学习率 | 5×10⁻⁴ | 论文披露 |
| 学习率调度 | decay schedule | 未完整披露 |
| Batch size | 8 | 论文披露 |
| Epochs | 800 | 论文披露 |
| 数据增强 | random flipping, rotation | 论文披露 |
| 可学习参数初始化 $\varphi^k, \psi^k$ | 0.1 | 论文披露 |
| Stage 数 k | 3 | 论文披露(消融实验) |
| 损失权重 $\alpha$ | 0.01 | 论文披露(消融实验) |
| 阈值初始化 $T_{init}$ | 0.7 | 论文披露(消融实验) |
| 阈值递减步长 $\Delta T$ | 自适应 | 未完整披露 |
表 2:RPCASSM 训练配置及论文披露状态。
训练成本
- 硬件:单卡 NVIDIA GeForce RTX 4070 Ti SUPER(16GB VRAM)
- 训练时间:未披露。论文仅说明了 800 epochs 和 batch size=8,但未报告总训练时长
- FLOPs:未披露。Table 2 的 caption 明确提及"Flops(G)"作为评估指标之一,但实际表格中并未包含
- 参数效率:RPCASSM 以 0.45M 参数实现了 SOTA 性能,在所有对比方法中排名第三低(仅次于 LSDSSMs 的 0.37M 和 ALCNet 的 0.42M)
RPCASSM 的推理过程是其训练过程的确定性前向传播,无需额外的后处理或测试时增强。
推理步骤
- 初始化:给定输入红外图像 $I$,设置背景初始估计 $\mathbf{B}^0 = I$,目标初始估计 $\mathbf{T}^0 = 0$(零矩阵)。这对应 RPCA 分解的起点:假设整幅图像都是背景,尚无目标被检测到。
- 迭代 k=3 次(Stage i = 1, 2, 3):每个 stage 执行 Gauss-Seidel 型交替更新:
- BEM 更新(背景提取):计算残差 $\mathbf{R}_B = \mathbf{B}^{i-1} - \mathbf{T}^{i-1}$,将其送入 ResBlock 进行局部特征提取,再经 BSSM/SPCM 进行全局低秩建模,得到更新后的背景估计 $\mathbf{B}^i = \mathbf{B}^{i-1} - \mathbf{T}^{i-1} + \varphi^i \cdot \mathcal{R}^i(\mathbf{R}_B)$。
- TEM 更新(目标提取):使用本阶段已更新的 $\mathbf{B}^i$(而非上一阶段的 $\mathbf{B}^{i-1}$),计算残差 $\mathbf{R}_T = \mathbf{T}^{i-1} - \mathbf{B}^i$,依次经过 ResBlock(局部特征)、DifBlock(差分增强)和 TSSM/DPCM(稀疏建模),得到更新后的目标估计 $\mathbf{T}^i = \mathbf{T}^{i-1} - \mathbf{B}^i + \psi^i \cdot \mathcal{S}^i(\mathbf{R}_T)$。
- 输出:第 k=3 个 stage 的目标估计 $\mathbf{T}^3$ 即为最终检测结果。该结果是一个与输入同尺寸的概率图,高值区域对应检测到的红外小目标。
推理成本
- 参数量:0.45M。在所有 11 个对比方法中排名第三低,仅高于 LSDSSMs(0.37M)和 ALCNet(0.42M)
- 迭代次数:固定 3 次(k=3)。这是通过超参数实验确定的最优值,对应 RPCA 交替优化的典型收敛步数
- 推理时间:未披露。论文未报告 FPS、单张图片推理延迟或吞吐量等任何推理速度指标
- 内存占用:未披露。由于采用全分辨率(256×256)处理且无下采样 stem,SSM 的序列长度为 256×256=65536
主实验结果
| Method | Params(M) | NUDT mIoU | NUDT Pd | NUDT Fa(10⁻⁶) | NUDT F | IRSTD mIoU | IRSTD Pd | IRSTD Fa(10⁻⁶) | IRSTD F |
|---|---|---|---|---|---|---|---|---|---|
| ACM (WACV2021) | 0.52 | 66.80 | 95.24 | 22.52 | 80.09 | 52.70 | 84.54 | 65.86 | 69.03 |
| ALCNet (TGRS2021) | 0.42 | 71.08 | 95.24 | 19.32 | 83.10 | 57.82 | 89.00 | 52.47 | 73.27 |
| DNANet (TIP2022) | 4.69 | 92.14 | 97.64 | 9.39 | 95.91 | 62.87 | 91.13 | 55.63 | 77.20 |
| AGPCNet (TAES2023) | 12.36 | 83.72 | 97.14 | 17.67 | 91.14 | 61.41 | 89.69 | 26.62 | 76.09 |
| UIUNet (TIP2023) | 50.54 | 90.52 | 97.80 | 8.34 | 95.02 | 65.69 | 91.24 | 23.47 | 79.31 |
| MSHNet (CVPR2024) | 4.06 | 91.64 | 97.78 | 3.58 | 95.64 | 56.06 | 88.66 | 29.75 | 71.84 |
| RPCANet (WACV2024) | 0.67 | 91.30 | 97.46 | 17.99 | 95.45 | 60.53 | 88.66 | 37.80 | 75.41 |
| SCTransNet (TGRS2024) | 11.19 | 94.58 | 97.13 | 3.70 | 97.21 | 66.46 | 90.03 | 27.86 | 79.85 |
| LSDSSMs (TGRS2025) | 0.37 | 94.59 | 97.52 | 3.77 | 97.22 | 68.14 | 86.60 | 24.80 | 81.05 |
| DRPCA-Net (TGRS2025) | 1.16 | 94.19 | 97.41 | 13.71 | 97.01 | 65.23 | 90.72 | 23.09 | 78.95 |
| RPCASSM (Ours) | 0.45 | 95.98 | 98.62 | 2.22 | 97.95 | 68.44 | 92.44 | 22.31 | 81.26 |
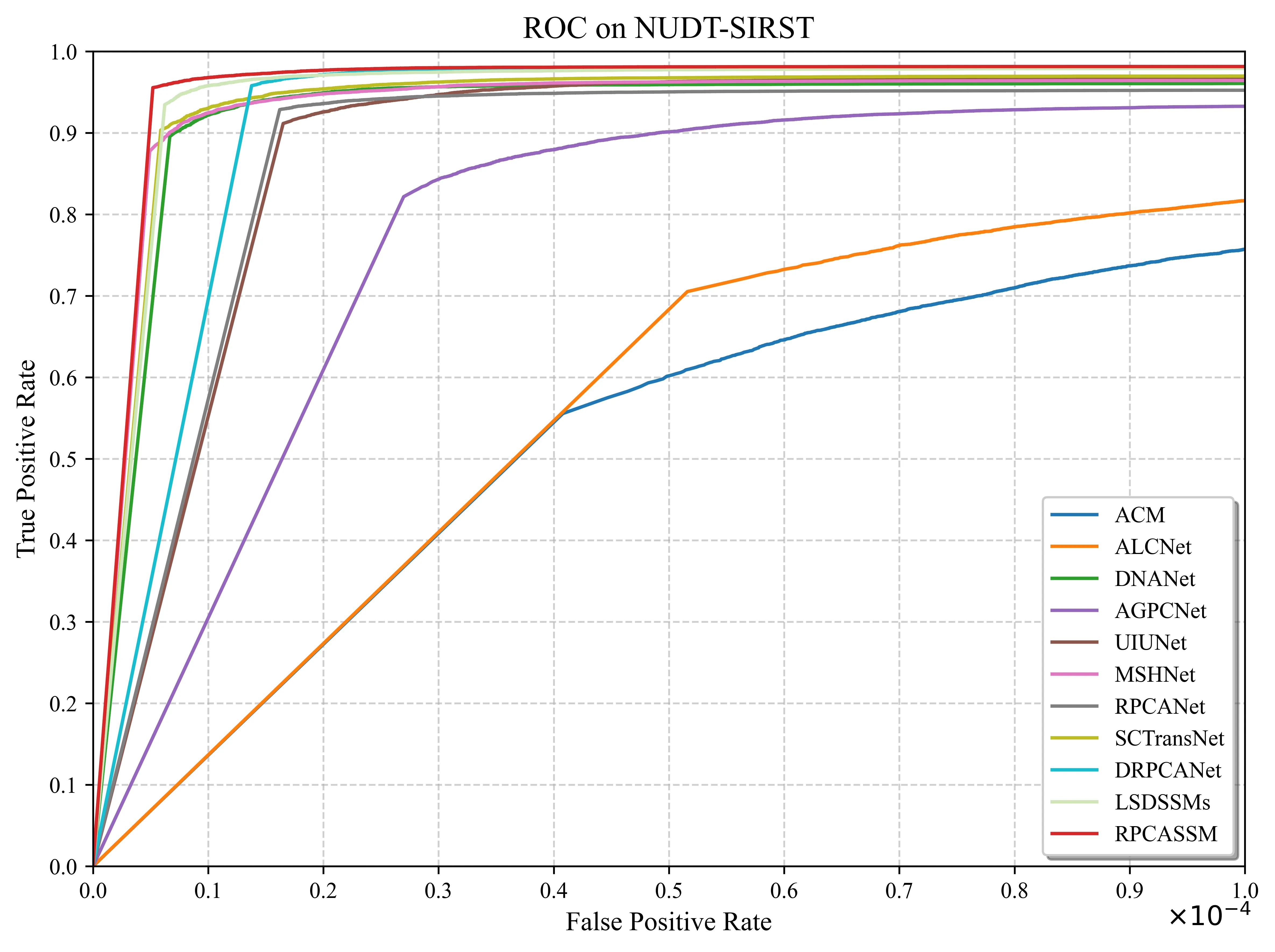
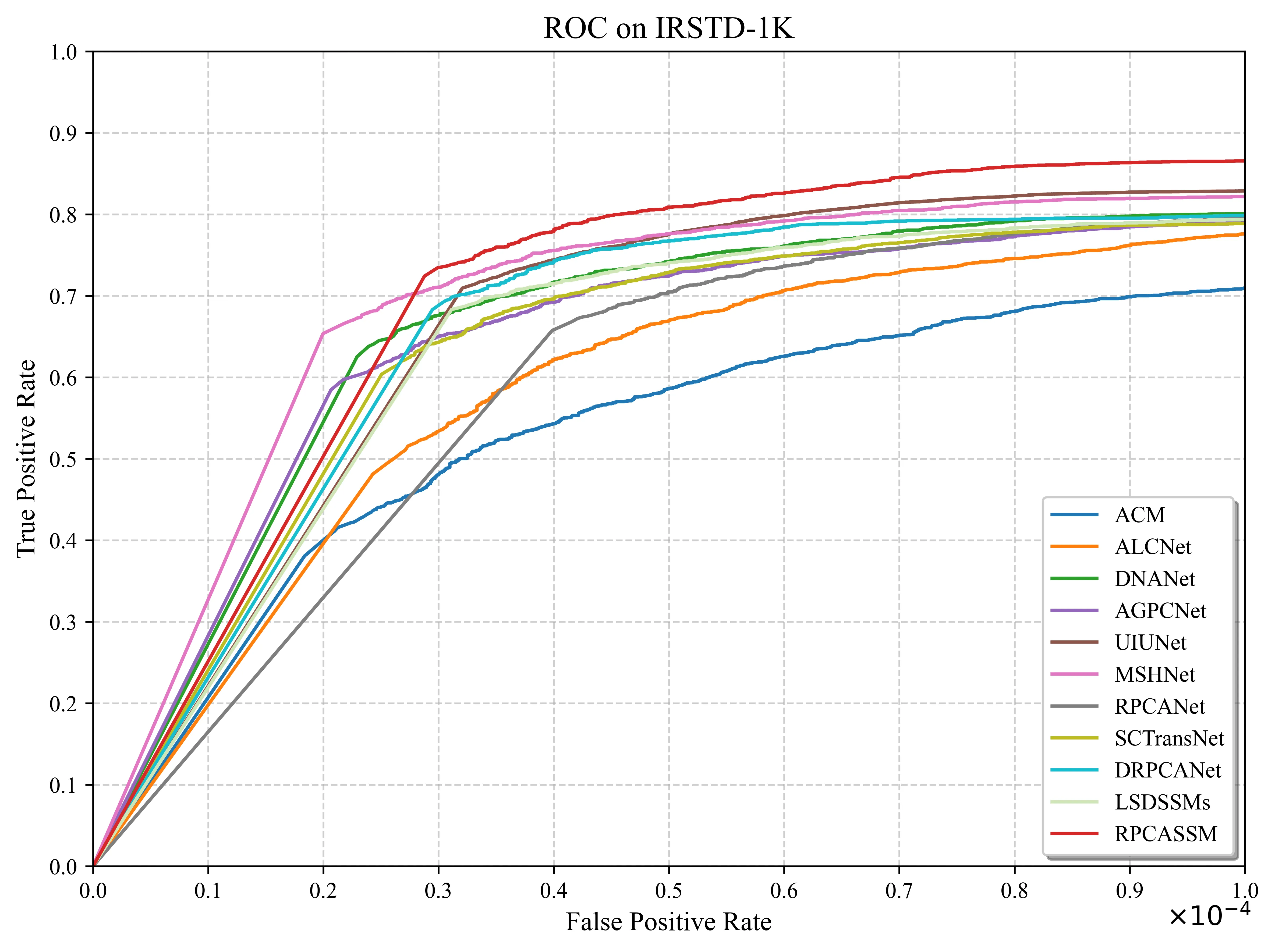
表 3:RPCASSM 与 10 个 SOTA 方法在 NUDT-SIRST 和 IRSTD-1K 上的定量对比。
NUDT-SIRST 数据集解读
RPCASSM 在 NUDT-SIRST 上实现了四项指标的全面领先:
- mIoU 95.98%:超越第二名 LSDSSMs(94.59%)1.39 个百分点,超越第三名 SCTransNet(94.58%)1.40 个百分点
- Pd 98.62%:所有方法中最高,意味着几乎不漏检任何目标像素
- Fa 2.22×10⁻⁶:所有方法中最低的虚警率,相比前代最佳 MSHNet(3.58×10⁻⁶)降低了 38%
- F-measure 97.95%:综合表现最优
从参数效率角度看,RPCASSM 以仅 0.45M 参数取得上述成绩。UIUNet 使用 50.54M 参数(RPCASSM 的 112 倍),mIoU 仅为 90.52%,说明单纯堆砌参数对 ISTD 任务收效甚微。与传统 RPCA 方法 RPCANet 相比,RPCASSM 的 mIoU 提升了 4.68 个百分点(91.30 → 95.98),Fa 从 17.99 降至 2.22(降低 87.7%)。
IRSTD-1K 数据集解读
IRSTD-1K 场景更多样、难度更高,所有方法的绝对性能均有下降。RPCASSM 在该数据集上同样取得四项指标第一:mIoU=68.44%(超越 LSDSSMs 的 68.14%),Pd=92.44%(大幅超越 LSDSSMs 的 86.60%,提升 5.84 个百分点),Fa=22.31×10⁻⁶(最低),F-measure=81.26%(超越 LSDSSMs 的 81.05%)。
消融实验
| 配置 | DifBlock | TSSM | BSSM | mIoU | Pd | Fa(10⁻⁶) | F-measure |
|---|---|---|---|---|---|---|---|
| Baseline | - | - | - | 91.60 | 97.41 | 18.49 | 95.61 |
| +DifBlock | + | - | - | 91.75 | 97.78 | 16.10 | 95.70 |
| +DifBlock+TSSM | + | + | - | 93.67 | 97.65 | 5.05 | 96.73 |
| Full (Ours) | + | + | + | 95.98 | 98.62 | 2.22 | 97.95 |
表 4:逐步添加组件的消融实验结果(NUDT-SIRST)。
- DifBlock:单独加入后,mIoU 从 91.60 提升至 91.75(+0.15%),Fa 从 18.49 降至 16.10(-2.39)。贡献幅度最小,但方向一致且稳定
- TSSM:在 DifBlock 基础上加入后,mIoU 从 91.75 跃升至 93.67(+1.92%),Fa 从 16.10 骤降至 5.05(-11.05,降幅 68.6%)。这是对 Fa 抑制效果最显著的一步
- BSSM:最后加入后,mIoU 从 93.67 跃升至 95.98(+2.31%),Pd 从 97.65 提升至 98.62(+0.97%),Fa 从 5.05 降至 2.22(-2.83,降幅 56%)。这是对整体性能贡献最大的组件
超参数敏感性
| k | mIoU | Pd | Fa(10⁻⁶) | F-measure |
|---|---|---|---|---|
| 1 | 94.09 | 97.67 | 5.49 | 96.96 |
| 2 | 95.01 | 98.20 | 4.62 | 97.44 |
| 3 | 95.98 | 98.62 | 2.22 | 97.95 |
| 4 | 95.42 | 98.52 | 2.94 | 97.66 |
| 5 | 95.85 | 98.61 | 2.71 | 97.80 |
表 5:Stage 数 k 的影响。k=3 为性能峰值。
| α | mIoU | Pd | Fa(10⁻⁶) | F-measure |
|---|---|---|---|---|
| 0.01 | 95.98 | 98.62 | 2.22 | 97.95 |
| 0.03 | 95.33 | 98.33 | 6.66 | 97.61 |
| 0.05 | 95.18 | 98.10 | 3.78 | 97.53 |
| 0.07 | 95.45 | 98.41 | 3.11 | 97.67 |
| 0.10 | 95.02 | 98.21 | 2.88 | 97.45 |
表 6:损失权重 α 的影响。α=0.01 为最优值。
| $T_{init}$ | mIoU | Pd | Fa(10⁻⁶) | F-measure |
|---|---|---|---|---|
| 0.1 | 95.70 | 98.10 | 2.13 | 97.80 |
| 0.3 | 95.46 | 98.54 | 3.36 | 97.68 |
| 0.5 | 95.39 | 98.46 | 4.64 | 97.64 |
| 0.7 | 95.98 | 98.62 | 2.22 | 97.95 |
| 1.0 | 95.50 | 98.31 | 2.55 | 97.70 |
表 7:阈值初始化 $T_{init}$ 的影响。$T_{init}=0.7$ 为综合最优。
AUC 结果
| Dataset | Index | RPCASSM | 最优竞争者 | 排名 |
|---|---|---|---|---|
| NUDT-SIRST | AUC_FPR=0.5 | 0.9340 | LSDSSMs: 0.9196 | 第 1 |
| NUDT-SIRST | AUC_FPR=1.0 | 0.9529 | LSDSSMs: 0.9432 | 第 1 |
| IRSTD-1K | AUC_FPR=0.5 | 0.5371 | MSHNet: 0.5683 | 第 2 |
| IRSTD-1K | AUC_FPR=1.0 | 0.6916 | MSHNet: 0.6872 | 第 1 |
表 8:不同假警率区间下的 ROC 曲线下面积(AUC)。
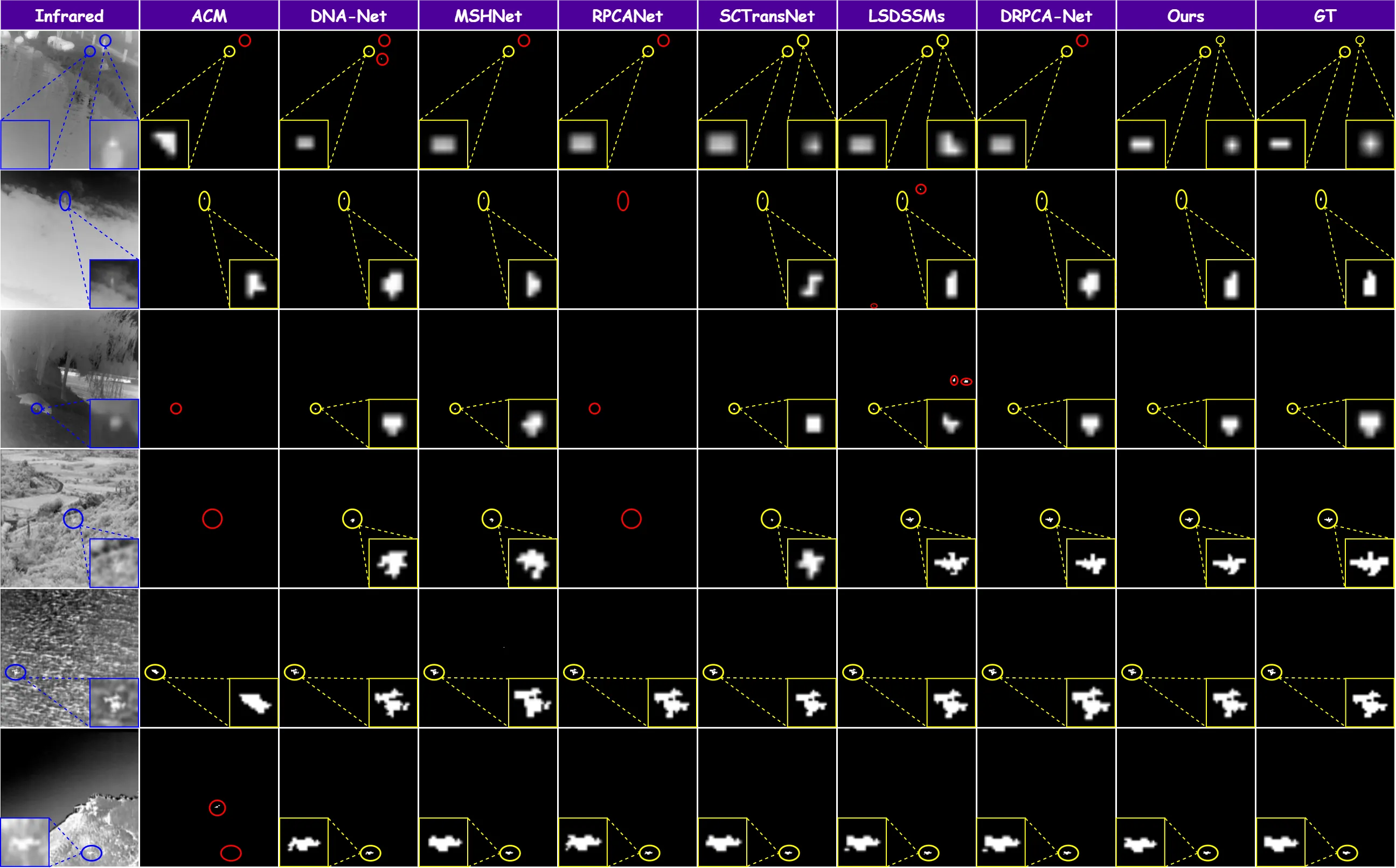
失败案例与局限
- BSSM 移除后 Fa 恶化 127%:去掉 BSSM 后 Fa 从 2.22 上升至 5.05(增幅 127%),mIoU 下降 2.31 个百分点。这说明 RPCASSM 的背景抑制能力高度依赖 BSSM 模块
- IRSTD-1K AUC_FPR=0.5 不如 MSHNet:在极低假警率区间,RPCASSM 的 AUC 为 0.5371,落后于 MSHNet 的 0.5683,差距达 5.5%
- 代码未开源:论文摘要中承诺"Our code will be made public at https://github.com/PepperCS/RPCASSM",但截至撰写时该仓库仅有 README 文件,未包含实际代码
- 仅在两个数据集上验证:实验仅覆盖 NUDT-SIRST 和 IRSTD-1K 两个基准数据集。缺少对不同传感器类型、不同气候条件、不同时序数据的测试
- 推理速度未报告:论文未提供任何推理速度指标(FPS、延迟、吞吐量)
- FLOPs 数据缺失:Table 2 的 caption 明确列出"Flops(G)"作为评估指标,但实际表格中未包含该列
论文结论
RPCASSM 的核心贡献在于首次从红外图像的空间域异质性出发,设计了基于 RPCA 范式的双分支状态空间模型。
- 架构层面:针对主流 VSSM 与 ISTD 任务之间的三重架构失配,RPCASSM 提出了两条互补的解决路径。BSSM/SPCM 通过空间轴投影和双向 SSM 建模背景的全局低秩结构;TSSM/DPCM 通过密度聚类定位候选区域、可变形偏移贴合目标边界、分区差异化处理将 SSM 算力集中到目标区域
- 性能层面:以仅 0.45M 参数在 NUDT-SIRST 上达到 mIoU 95.98%、Pd 98.62%、Fa 2.22×10⁻⁶,在 IRSTD-1K 上达到 mIoU 68.44%、Pd 92.44%、Fa 22.31×10⁻⁶,四项指标在两个基准上均取得最优
- 方法论层面:验证了"将物理先验作为网络架构的归纳偏置而非仅作为正则化项"这一设计哲学的有效性
局限性分析
局限 1:代码未开源为什么会
论文 README 声明"接收后一个月内公开实验代码",但截至 2026-06-18 已超过该时限,仓库仍仅有 README 文件。最可能的原因是工程整理未完成——研究代码通常包含大量硬编码路径、临时调试脚本、未文档化的依赖版本锁定等,清理到可复现状态需要投入数周甚至数月的额外工作量。
需要什么
作者需要投入专门时间进行代码清理、编写安装和使用文档、提供预训练权重和推理脚本、明确标注所有依赖版本。社区也可以主动联系作者询问进展。
为什么会
ISTD 领域的高质量标注数据集极度稀缺。NUDT-SIRST 和 IRSTD-1K 是目前使用最广泛的两个基准,其他数据集要么规模过小、要么标注质量参差不齐、要么获取受限。
需要什么
更全面的评估应覆盖不同传感器类型(制冷型 vs 非制冷型焦平面阵列)、不同气象条件(晴天、薄雾、雨雾、沙尘)、不同背景类型(天空、海面、地面复杂背景、城市环境)以及更大规模的数据集。
为什么会
论文的评估重心完全放在精度指标上,未涉及任何效率指标。这可能反映了作者的研究定位——本文的目标是探索 ISTD 精度的上限,而非面向实时部署的工程优化。
需要什么
至少应报告单张图片推理延迟(ms)、吞吐量(FPS)、GPU 显存占用峰值。理想情况下还应在嵌入式平台(如 Jetson Orin)上测试部署可行性。
具体可操作的启发
启发 1:RPCA 先验在视觉任务中的普适性- 学习率调度策略未完整披露:论文仅提及"learning rate decay schedule was implemented",但未说明具体是 step decay、cosine annealing 还是 exponential decay。建议尝试 cosine annealing with warmup
- $\Delta T$ 的具体值未给出:DPCM 的自适应阈值公式 $T_s = T_{init} - \gamma \cdot \Delta T$ 中,$T_{init}=0.7$ 已知,但 $\Delta T$ 缺失。建议通过消融实验在 {0.05, 0.1, 0.15, 0.2} 范围内搜索
- KAN 的配置细节不明:BSSM 中使用 KAN 替代 Linear 生成 SSM 参数,但 KAN 的具体配置(网格点数、样条阶数、隐藏层宽度)未披露。建议参考 pykan 库的默认配置
- SSM 变体选择:论文使用的是 Mamba 的选择性 SSM(S6),建议优先参考 VMamba 的开源实现,因为 RPCASSM 的 TSSM 直接使用了 VMamba 的 CSM 模块
上游传承
经典 RPCA(IPI Model, Gao 2013)→ RPCANet(RPCA + CNN 深度展开, Wu WACV 2024)→ LSDSSMs(RPCA + 单向 SSM, Lu TGRS 2025)→ RPCASSM(RPCA + 双分支 SSM, 2026)。这条线的演进逻辑是:保持 RPCA 分解范式不变,持续升级子网络的表达能力(CNN → 单向 SSM → 双分支 SSM),同时不断深化 RPCA 与网络架构的集成程度(正则化 → 架构灵感 → 迭代=stage)。
延伸阅读
- RPCANet: Deep Unfolding RPCA Based Infrared Small Target Detection (Wu et al., WACV 2024) — RPCA 深度展开范式的开创性工作。如果你想理解 RPCASSM 的"骨架"从何而来,这是必读文献。代码已开源(fengyiwu98/RPCANet),适合动手实践
- LSDSSMs: Infrared Small Target Detection Network Based on Low-Rank Sparse Decomposition State Space Models (Lu et al., TGRS 2025) — RPCASSM 同组的前序工作,也是最直接的 baseline。读完你会理解 RPCASSM 为什么要从单向 SSM 升级到双分支设计
- VMamba: Visual State Space Model (Liu et al., NeurIPS 2024) — 定义了"Visual SSM"标准范式的工作。RPCASSM 既借用了它的 CSM 模块,又批判了它的整体架构哲学
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Gu & Dao, COLM 2024) — 整个 SSM 视觉应用浪潮的理论基石。如果你对 SSM 还不熟悉,这是最好的入门文献
- DRPCA-Net: Dynamic RPCA with Residual Grouping for Infrared Small Target Detection (Xiong et al., TGRS 2025) — 另一条改进 RPCANet 的技术路线,侧重于动态参数生成而非扫描机制设计。代码已开源(GrokCV/DRPCA-Net)

