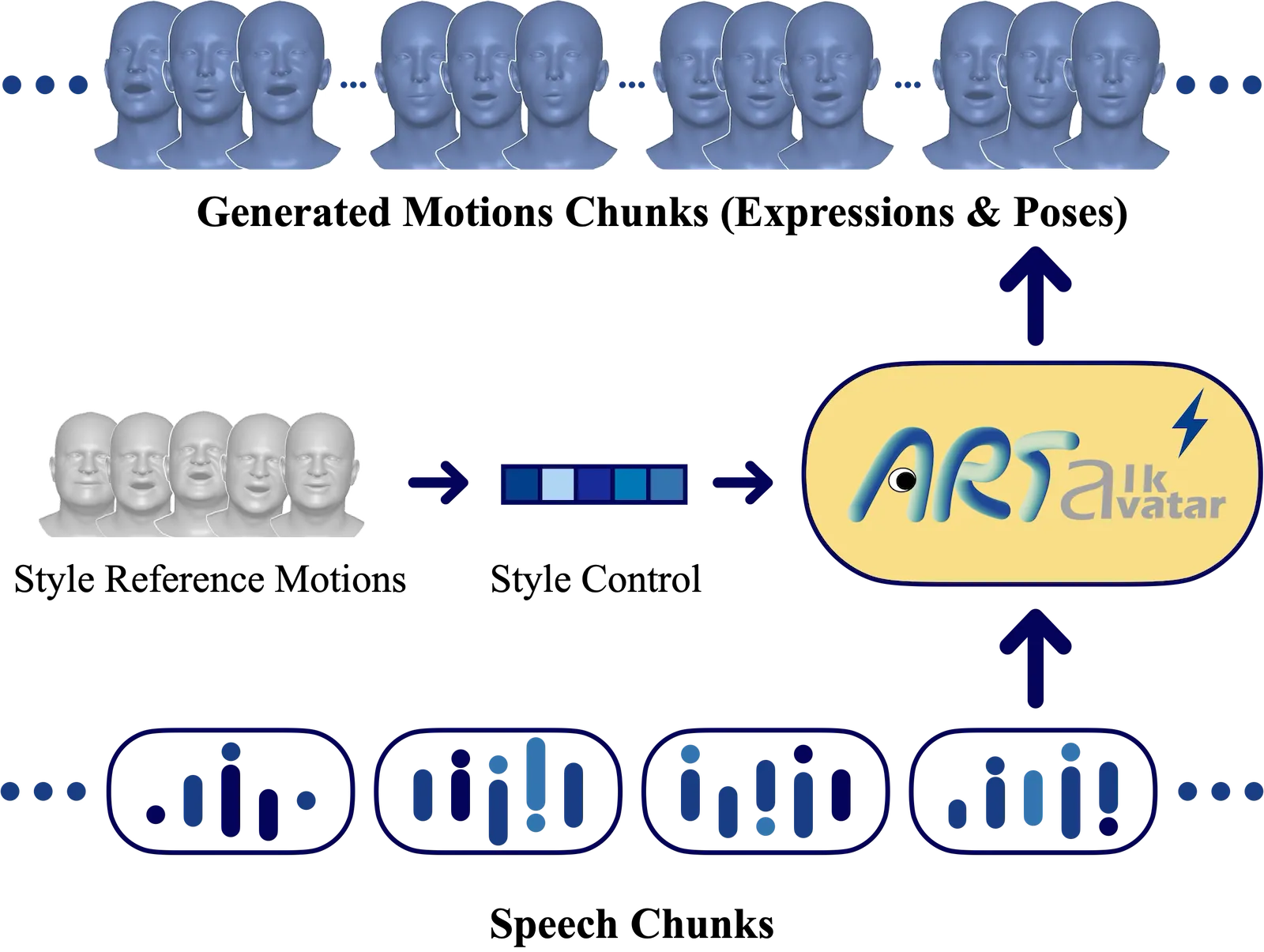
ARTalk
当我们谈论 LLM 驱动的数字人对话系统时,一个关键瓶颈始终存在:语音到 3D 面部运动的生成速度跟不上实时对话的节奏。用户在电话那头说了一句话,系统需要在毫秒级别内生成对应的 3D 头像动画——而不是等上几秒让 diffusion model 慢慢去噪。
这个领域(speech-driven 3D facial animation)的目标很明确:从任意语音音频自动生成逼真的 3D 人脸运动,包括唇形同步(lip sync)、面部表情、头部姿态和眨眼。输出通常是 FLAME #Li et al., 2017 参数化模型的 expression $\psi$ 和 pose $\theta$ 参数,采样率 25fps,可以直接导入游戏引擎或实时渲染管线。
截至 2025 年,这个领域有三条主要技术路线,但每条都有自己的硬伤:
- Diffusion 路线(DiffPoseTalk #Sun et al., 2024, FaceDiffuser #Stan et al., 2023):生成质量高,能产生自然的运动和风格化表达,但推理需要数十步去噪迭代,无法满足实时需求
- Autoregressive 路线(FaceFormer #Fan et al., 2022, CodeTalker #Xing et al., 2023, MultiTalk #Sung-Bin et al., 2024):天然支持流式生成,但早期方法存在 over-smoothing 问题——非唇部区域细节不足,头部姿态缺失
- Real-time 声称(SelfTalk #Peng et al., 2023):声称实时但未公开具体数据,且不支持 style adaptation 和 head pose
ARTalk 的核心立场很清晰:首次打破"质量 vs 速度"的 trade-off。通过 temporal multi-scale VQ autoencoder + two-level autoregressive model,在超越 DiffPoseTalk 质量的同时,实现 A100 上 0.01s/s 的推理速度——100 倍实时。
在 ARTalk 之前,这个领域最好的方法是 DiffPoseTalk #Sun et al., 2024(SIGGRAPH 2024)。它是首个同时支持 expression + head pose + style 的 diffusion-based 方法,在 TFHP 数据集上取得了 LVE=10.39 / FFD=20.15 / MOD=2.07 的优秀指标。但 diffusion 的代价是推理速度:需要多步去噪迭代,生成 1 秒运动可能需要数秒时间,完全无法用于实时对话场景。
另一方面,autoregressive 路线的代表 CodeTalker #Xing et al., 2023(CVPR 2023)首次将 VQ-VAE tokenization 引入该任务,用离散码字替代连续空间回归,理论上支持流式生成。但它有两个关键缺陷:
1. 单尺度 VQ 的 over-smoothing:CodeTalker 使用单尺度 VQ-VAE(codebook 1024 entries × 256 dim),无法捕获从粗到细的运动层次,导致非唇部区域过于平滑(FFD=20.39)
2. 缺乏时序因果建模:没有跨窗口的依赖机制,长序列生成容易出现时序不连续
这个看似简单的迁移带来了两个关键突破:(1) multi-scale residual VQ 解决了 over-smoothing(FFD 从 20.39 降至 18.15);(2) temporal causal masking + cross-window AR 保证了长序列的时序一致性。最终结果:ARTalk 在 TFHP 上取得 LVE=9.34 / FFD=18.15 / MOD=1.81,全面超越 DiffPoseTalk,同时推理速度达 0.01s/s(A100),是 diffusion 方法的数十倍。
ARTalk 的方法由两个核心模块组成,分工明确。在深入架构之前,需要先理解 ARTalk 的运动表示基础——FLAME 参数化模型 #Li et al., 2017。
前置:FLAME 参数化模型
FLAME 将 5,023 顶点的高维 3D 人脸网格压缩为低维混合形状参数:
其中 $\bar{T}$ 为模板网格,$BS(\beta; S)$ 为身份形状混合形状,$BP(\theta; P)$ 为关节姿态修正(下颌和颈部),$BE(\psi; E)$ 为表情混合形状(闭眼、微笑等)。ARTalk 固定 $\beta$(目标身份已知),仅生成 expression $\psi$ 和 pose $\theta$,将问题维度从完整的 3D 重建降低到约 150+ 维的参数预测。#Chu et al., 2025
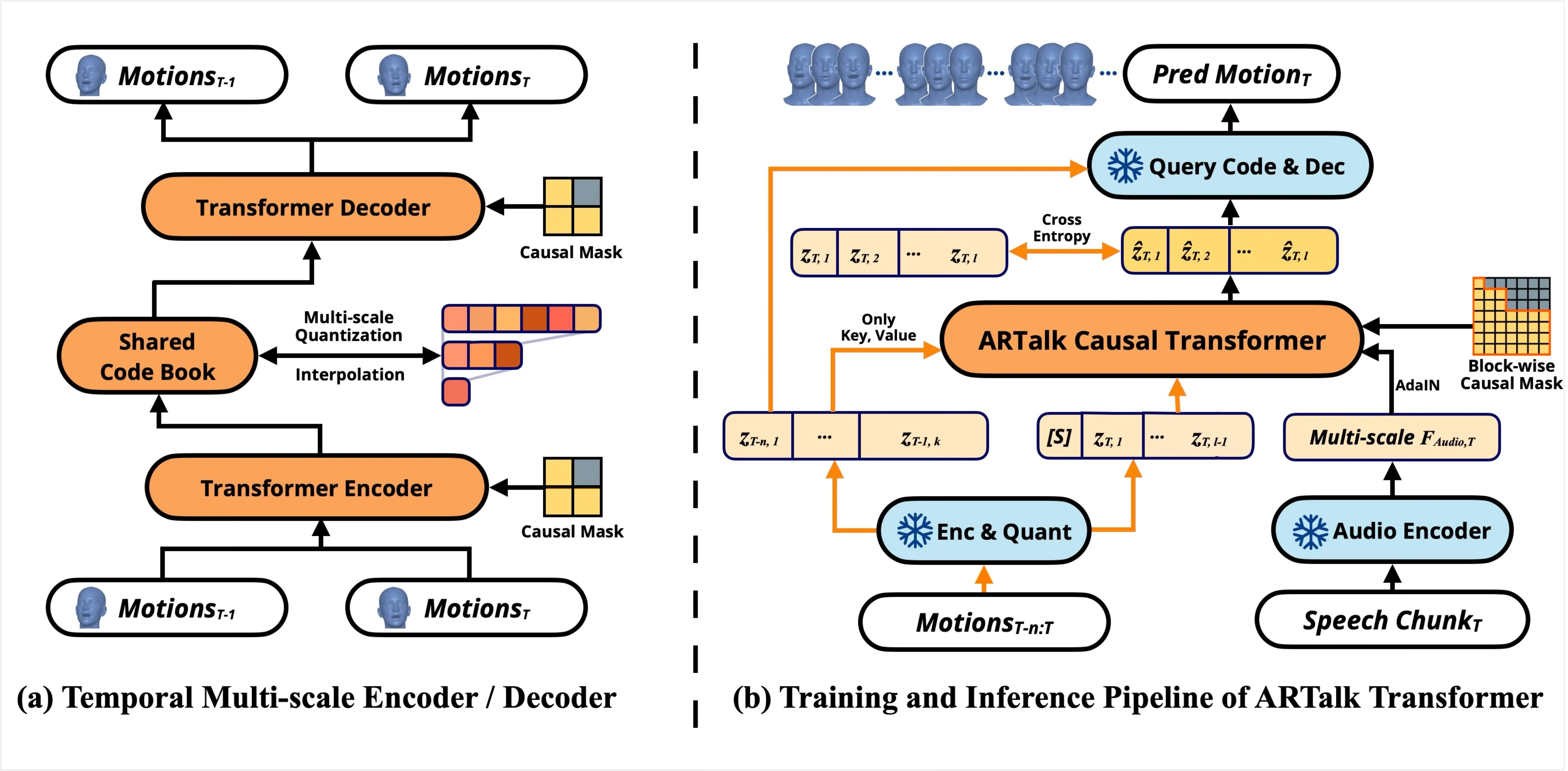
Part A: Temporal Multi-scale VQ Autoencoder
该模块的核心创新是 multi-scale residual VQ。输入为 $K=100$ 帧的运动序列(4 秒,25fps),经过 Transformer encoder(8 层 8 头,hidden dim 512)映射到潜在空间后,通过 5 个尺度层级 $k_l \in [1, 5, 25, 50, 100]$ 逐步细化重建:
Multi-scale Residual VQ
其中 $l = 1, \ldots, L$,$r^{(0)}$ 为编码器输出。$\text{Quant}(\cdot)$ 将特征分配到共享码本(256 entries × 64 dim)中最近的条目;$\text{Interp}(\cdot, k_l)$ 通过插值调整到当前尺度的分辨率。
这个设计的精妙之处在于三点:
1. 残差累积实现频率分层:粗尺度($k_1=1$)用单个码字捕获整个窗口的全局运动均值;中等尺度($k_3=25$)捕获段落级别的运动变化;细尺度($k_5=100$)捕获逐帧细节。类似小波分解,低频先编码,高频在残差中逐步提取。
2. 共享码本:所有尺度共用同一个 256×64 的码本,保证不同粒度的运动信息在同一语义空间中表达,使得后续 AR 模型可以在统一的 token 词汇表上跨尺度预测。
3. Temporal causal masking:自编码器同时处理两个连续时间窗口 $T-1$ 和 $T$,通过因果掩码确保 $T$ 的编码仅依赖 $T-1$,不泄露未来信息。这为推理时的跨窗口预测提供了训练-推理一致性——推理时 $z_{T-1}^{(L)}$ 已经生成完毕可供使用,但 $z_{T+1}$ 尚不存在,因果掩码将编码器的注意力矩阵约束为下三角分块结构,消除了 exposure bias 的一个来源。
为什么共享码本而非独立码本? 如果每个尺度使用独立码本,不同尺度的码字将存在于不同的语义空间中,跨尺度的自回归预测将面临语义不对齐的问题。共享码本强制所有尺度的运动信息在同一离散空间中表示,使得 AR 模型可以在统一的 token 词汇表上进行跨尺度预测。从信息论角度看,共享码本相当于对所有尺度的运动模式施加了一个共同的离散先验,有助于正则化并防止过拟合。#Chu et al., 2025
VQ 自编码器的训练目标包含四项损失:
VQ 训练损失
其中重建损失 $\mathcal{L}_{recon} = \|\hat{M} - M\|_1 + w_{lips}\|\hat{V}_{lips} - V_{lips}\|^2 + \|\hat{V} - V\|^2$(参数 L1 + 唇部加权 L2 + 全顶点 L2);速度损失 $\mathcal{L}_{vel}$ 约束相邻帧差分一致性;平滑度损失 $\mathcal{L}_{smooth} = \|\hat{V}_{2:} - 2\hat{V}_{1:-1} + \hat{V}_{:-2}\|^2$ 惩罚加速度突变;$\mathcal{L}_{cb}$ 为标准 VQ commitment + codebook loss。#Chu et al., 2025
Part B: Speech-to-Motion AR Model
AR 模型以冻结的 HuBERT #Hsu et al., 2021 语音编码器提取的语音特征 $a_T$ 为条件,通过重采样对齐到每个尺度 $k_l$ 的时间分辨率。风格信息通过 Transformer style encoder 从示例运动片段中提取风格 token $s$,实现对任意说话风格的适配(无需在训练集中见过该身份)。
核心生成策略是 two-level autoregression:
Two-level AR 概率分解
第一级是跨尺度 AR:从最粗尺度 $l=1$ 到最细尺度 $l=L$ 依次生成。第二级是跨窗口 AR:当前窗口 $T$ 以上一窗口 $T-1$ 的最细尺度码字 $z_{T-1}^{(L)}$ 为条件。在每个尺度内部,所有 token 采用块级并行预测(blockwise parallel),大幅提升推理效率。语音条件通过 AdaIN #Huang & Belongie, 2017 注入 Transformer 各层。#Chu et al., 2025
AR 模型的训练使用标准交叉熵损失:
训练时使用 ground truth 码字作为 teacher forcing。AR Transformer 配置为 12 层 12 头 hidden dim 768,输出经 FC 映射到 256 维 + softmax 计算码本概率分布。
ARTalk 的训练分为两个独立阶段,每阶段各自训练 50K iterations。
Stage 1: VQ Autoencoder(~5 hours on 1× A100)
目标是学习高质量的 temporal multi-scale motion codebook。训练数据为 TFHP 数据集 #Sun et al., 2024(1,052 video clips, 588 subjects, ~26.5 hours, 25fps, ~2.38M action frames)。
Stage 2: AR Model(~8 hours on 1× A100)
冻结 VQ autoencoder,训练 speech-to-motion autoregressive generation。使用 frozen HuBERT 作为语音编码器。语音条件通过 Adaptive Instance Normalization (AdaIN) #Huang & Belongie, 2017 注入 Transformer 各层——这一机制允许音频特征动态调节生成过程的均值和方差,实现细粒度的条件控制。
VQ 损失的物理含义
Stage 1 的四项损失各有明确的物理动机:$\mathcal{L}_{recon}$ 中的参数 L1 损失保证 FLAME 参数空间的基本对齐,唇部加权 L2 体现对 lip-sync 精度的特别关注(唇部是语音驱动最敏感的区域),全顶点 L2 则约束整体几何保真度。$\mathcal{L}_{vel}$ 约束相邻帧速度一致性,防止生成结果出现不自然的抖动。$\mathcal{L}_{smooth}$ 使用二阶差分(加速度)惩罚运动突变,保证物理合理性——真实的面部运动不会在瞬间改变加速度。$\mathcal{L}_{cb}$ 为标准 VQ commitment + codebook loss,确保编码器输出与码本条目紧密对齐。#Chu et al., 2025
训练配置披露
| 配置项 | Stage 1 (VQ AE) | Stage 2 (AR) | 披露状态 |
|---|---|---|---|
| 优化器 | AdamW | AdamW | ✅ 论文披露 |
| 初始学习率 | 1e-4 | 1e-4 | ✅ 论文披露 |
| LR schedule | — | Linear decay to 1e-5 | ✅ 论文披露 |
| Batch size | 64 | 64 | ✅ 论文披露 |
| Iterations | 50,000 | 50,000 | ✅ 论文披露 |
| 训练硬件 | 1× A100 | 1× A100 | ✅ 论文披露 |
| 训练时间 | ~5 hours | ~8 hours | ✅ 论文披露 |
| Codebook | 256 × 64-dim | —(frozen) | ✅ 论文披露 |
| Multi-scale levels | [1, 5, 25, 50, 100] | —(同上) | ✅ 论文披露 |
| Encoder/Decoder | 8L 8H hidden 512 | —(frozen) | ✅ 论文披露 |
| AR Transformer | — | 12L 12H hidden 768 | ✅ 论文披露 |
| Speech encoder | — | Frozen HuBERT | ✅ 论文披露 |
| $w_{lips}$(唇部损失权重) | — | — | ❌ 未披露 |
| $\lambda_{vel}$(速度损失权重) | — | — | ❌ 未披露 |
| $\lambda_{smooth}$(平滑损失权重) | — | — | ❌ 未披露 |
| Style encoder 架构 | — | — | ❌ 未披露 |
ARTalk 的推理流程完全前向传播,无迭代采样:
1. 输入:一段语音音频 + 一个示例运动片段(用于 style adaptation)+ 前一窗口的最细尺度码字 $z_{T-1}^{(L)}$
2. Speech encoding:Frozen HuBERT 提取语音特征,重采样到各尺度分辨率
3. Style encoding:Transformer style encoder 从示例片段提取 style token $s$
4. Two-level AR generation:从 $l=1$ 到 $l=L$ 逐尺度生成码字,每个尺度内部 blockwise parallel
5. VQ decoding:Multi-scale VQ decoder 从离散码字重建 FLAME $\psi + \theta$ 参数
6. FLAME rendering:FLAME 模型将参数转换为 5,023 顶点的 3D mesh
实时性能
| 硬件 | 生成 1s 运动耗时 | 实时倍率 | 适用场景 |
|---|---|---|---|
| NVIDIA A100 | 0.01s | 100× real-time | 云端服务 |
| Apple M2 Pro | 0.057s | 17.5× real-time | 本地桌面应用 |

Streaming 的矛盾:Window length vs Latency
ARTalk 的一个设计权衡是时间窗口长度。Ablation 显示更长的窗口带来更好的性能(clip 150: LVE=7.98 vs clip 100: LVE=9.34),但 streaming 应用要求先收集完整个窗口才能开始生成。100 帧(4 秒)是论文选择的折中点——与 DiffPoseTalk 的配置一致,且在质量和延迟之间取得了良好平衡。对于需要更低延迟的场景,窗口可以缩短到 50 帧(LVE=9.78)甚至 25 帧(LVE=10.20)。
VQ Autoencoder:性能的隐形天花板
一个容易被忽视的洞察是:VQ autoencoder 的重建质量构成了最终模型的性能上界。论文报告 VQ AE 在不同 clip length 下的重建 LVE 仅为 ~2.0(8 帧: 1.96, 100 帧: 2.08),而完整 AR 模型的 LVE 为 9.34——两者之间约 7 个点的差距全部来自 AR 生成阶段的误差累积。这意味着未来提升空间主要在 AR 模型侧,而非 VQ 编码质量。有趣的是,clip length 对 VQ AE 性能的影响很小(LVE 在 1.96-2.19 之间波动),但对 AR 模型影响巨大(LVE 从 11.73 到 9.34),进一步证实了 AR 生成是瓶颈所在。#Chu et al., 2025
另一个有趣的发现是 audio encoder 的选择与窗口长度相关:MIMI(Moshi 的 audio tokenizer #Defossez et al., 2024)在短窗口(8 frames = 320ms)下优于 HuBERT(LVE 11.01 vs 11.73),因为 MIMI 专为流式短音频设计;但 HuBERT 在长窗口(≥25 frames)下全面胜出。#Chu et al., 2025
TFHP 主实验:LVE/FFD/MOD 三项全优
| Method | LVE ↓ | FFD ↓ | MOD ↓ | Style | Pose | Real-time |
|---|---|---|---|---|---|---|
| FaceFormer #Fan et al., 2022 | 12.72 | 22.06 | 2.73 | ❌ | ❌ | ❌ |
| CodeTalker #Xing et al., 2023 | 11.78 | 20.39 | 2.43 | ❌ | ❌ | ❌ |
| SelfTalk #Peng et al., 2023 | 12.07 | 23.74 | 2.57 | ❌ | ❌ | ✅ |
| FaceDiffuser #Stan et al., 2023 | 11.92 | 22.17 | 2.55 | ❌ | ❌ | ❌ |
| MultiTalk* #Sung-Bin et al., 2024 | 12.23 | 24.42 | 2.48 | ✅ | ❌ | ❌ |
| ScanTalk* #Nocentini et al., 2024 | 12.14 | 21.02 | 3.20 | ❌ | ❌ | ❌ |
| UniTalker* #Fan et al., 2024 | 11.61 | 29.31 | 2.07 | ✅ | ❌ | ❌ |
| DiffPoseTalk #Sun et al., 2024 | 10.39 | 20.15 | 2.07 | ✅ | ✅ | ❌ |
| ARTalk (Ours) | 9.34 | 18.15 | 1.81 | ✅ | ✅ | ✅ |

VOCASET 零样本泛化:未训练也赢了大多数
ARTalk 未在 VOCASET 上训练或微调,但在该数据集的零样本评估中取得 LVE=7.57 / FFD=15.49 / MOD=1.78,优于大多数专门在 VOCASET 上训练的 baseline(包括 FaceFormer、CodeTalker、FaceDiffuser 等)。仅 ScanTalk 在 LVE 上略优(7.15),但 ScanTalk 是在 VOCASET 上训练过的。
User Study:28 人 × 96 题 × 2688 次对比
| Method | Sync (%) | N-Exp (%) | Style (%) | N-Pose (%) |
|---|---|---|---|---|
| FaceFormer | 75.0 [70.4, 79.6] | 89.3 [86.3, 92.8] | 88.1 [85.0, 91.8] | — |
| CodeTalker | 84.5 [80.7, 88.4] | 86.9 [83.3, 90.5] | 92.9 [90.5, 95.9] | — |
| SelfTalk | 85.7 [82.0, 89.5] | 89.3 [86.3, 92.8] | 91.7 [89.1, 94.9] | — |
| FaceDiffuser | 88.1 [85.0, 91.8] | 90.4 [87.3, 93.6] | 86.9 [83.3, 90.5] | — |
| MultiTalk | 78.6 [74.5, 83.2] | 76.2 [72.0, 81.0] | 78.6 [74.5, 83.2] | — |
| ScanTalk | 88.1 [85.0, 91.8] | 90.5 [87.7, 93.9] | 90.5 [87.7, 93.9] | — |
| UniTalker | 81.8 [77.7, 86.0] | 83.6 [79.7, 87.6] | 81.3 [77.4, 85.7] | — |
| DiffPoseTalk | 63.1 [58.2, 68.5] | 59.5 [54.3, 64.8] | 60.7 [55.5, 65.9] | 58.3 [53.1, 63.6] |
百分比表示偏好 ARTalk 的用户比例(>50% 即表示 ARTalk 胜出)。28 名受访者,每人回答 96 题(84 对 pairwise comparison),总计 2,688 次对比。N-Pose 仅对 DiffPoseTalk 评估(唯一支持 head pose 的 baseline)。#Chu et al., 2025
Ablation Study:每个组件都不可或缺
| Variant | LVE ↓ | FFD ↓ | MOD ↓ |
|---|---|---|---|
| w/o Multi-Scale AR | 14.14 (+51.4%) | 22.04 | 3.06 |
| w/o Temporal VQ | 9.82 | 18.60 | 1.86 |
| w/o Temporal AR | 9.97 | 18.71 | 1.99 |
| w/o Style Embedding | 11.80 (+26.3%) | 21.46 | 2.37 |
| Clip Length 8 (Layer 5) | 11.73 (+25.6%) | 24.89 | 2.25 |
| Clip Length 25 (Layer 5) | 10.20 | 19.00 | 1.97 |
| Clip Length 50 (Layer 5) | 9.78 | 18.03 | 1.89 |
| ARTalk (Full) | 9.34 | 18.15 | 1.81 |
Multi-scale 层数探索
| 配置 | Scale Levels | LVE ↓ | FFD ↓ | MOD ↓ |
|---|---|---|---|---|
| Clip 100, 3 layers | [1, 50, 100] | 11.03 | 20.82 | 2.01 |
| Clip 100, 4 layers | [1, 20, 60, 100] | 9.58 | 17.26 | 1.89 |
| Clip 100, 5 layers (baseline) | [1, 5, 25, 50, 100] | 9.34 | 18.15 | 1.81 |
| Clip 100, 6 layers | [1, 5, 25, 50, 75, 100] | 9.81 | 18.46 | 1.92 |
| Clip 150, 5 layers | [1, 20, 50, 100, 150] | 7.98 | 14.09 | 1.66 |
层数对性能的影响不是特别显著——只有当层数显著减少(如从 5 层降到 3 层)时才出现明显退化。相比之下,窗口长度的正面效应更为清晰:clip 150 + 5 layers 在所有指标上全面优于 clip 100(LVE 7.98 vs 9.34),但过长的窗口对流式应用不实用。#Chu et al., 2025
跨数据集零样本泛化
ARTalk 在多个未训练数据集上的零样本评估进一步验证了泛化能力:
| 数据集 | ARTalk LVE ↓ | ARTalk FFD ↓ | ARTalk MOD ↓ | 最佳 baseline LVE |
|---|---|---|---|---|
| TFHP(训练集) | 9.34 | 18.15 | 1.81 | 10.39 (DiffPoseTalk) |
| VOCASET(零样本) | 7.57 | 15.49 | 1.78 | 7.15 (ScanTalk, 已训练) |
| VFHQ(零样本) | 6.92 | 21.19 | 1.53 | 7.59 (SelfTalk, 已训练) |
| MEAD(零样本) | 8.64 | 26.33 | 1.89 | 9.83 (ScanTalk, 已训练) |
| MultiTalk(零样本) | 7.40 | 23.78 | 1.64 | 9.09 (MultiTalk, 已训练) |
下游集成:GAGAvatar

实用场景评估
| 场景 | 适配度 | 说明 |
|---|---|---|
| 虚拟主播/VTuber | ⭐⭐⭐⭐⭐ | 实时性是刚需,0.01s/s 完美满足 |
| 游戏 NPC 对话 | ⭐⭐⭐⭐⭐ | FLAME 参数可直接导入 Unity/Unreal |
| 数字人客服 | ⭐⭐⭐⭐⭐ | LLM 语音→ARTalk→3D 头像,端到端延迟可控 |
| 在线教育/培训 | ⭐⭐⭐⭐ | Style adaptation 支持不同教学风格 |
| 影视后期/预演 | ⭐⭐⭐ | 快速原型可用,最终制作可能仍需高精度离线方法 |
已知局限与未来方向
核心局限
- Head motion 受 prosody 驱动而非 semantic:无法生成语义相关的文化特定手势(如肯定时点头、否定时摇头)。未来方向:将 semantic information 纳入 head motion generation。
- Single style embedding 无法处理情感剧变:当语音从平静突然转为激动时,单一 embedding 难以捕捉动态变化。
- FLAME 拓扑限制:仅适用于 FLAME 兼容的人脸拓扑,不支持任意 mesh。
- 开源代码与论文版本不完全一致:GitHub README 注明 "This version modifies the VQVAE part compared to the paper version"。
后续工作:UniLS (CVPR 2026)
ARTalk 一作 Xuangeng Chu 的下一篇工作 UniLS(CVPR 2026)已将 ARTalk 的语音→运动映射扩展为统一的 listening+speaking 框架,支持双人对话场景(dyadic conversation)。UniLS 继承了 ARTalk 的 VQ codec + AR generator 架构思想,合作单位新增 Shanda AI Research Tokyo(盛大 AI 研究院东京分部),显示产业化推进。
作者团队与研究脉络
参考来源
- Chu, X. et al. (2025). ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model. SIGGRAPH Asia 2025. arXiv:2502.20323
- Li, T. et al. (2017). Learning a Model of Facial Shape and Expression from 4D Scans. SIGGRAPH Asia 2017. Project Page
- Sun, Z. et al. (2024). DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models. ACM TOG. arXiv:2404.10087
- Xing, J. et al. (2023). CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior. CVPR 2023. arXiv:2301.05991
- Fan, Y. et al. (2022). FaceFormer: Speech-Driven 3D Facial Animation with Transformers. CVPR 2022. arXiv:2112.02244
- Tian, K. et al. (2024). Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. NeurIPS 2024. arXiv:2404.02893
- Hsu, W.-N. et al. (2021). HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM TASLP. GitHub
- Stan, S. et al. (2023). FaceDiffuser: Speech-Driven 3D Facial Animation Synthesis Using Diffusion. MIG 2023. arXiv:2309.08834
- Sung-Bin, K. et al. (2024). MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset. Interspeech 2024.
- Peng, Z. et al. (2023). SelfTalk: A Self-Supervised Commutative Training Diagram to Comprehend 3D Talking Faces. ACM MM 2023.
- Nocentini, F. et al. (2024). ScanTalk: 3D Talking Heads from Unregistered Scans. ECCV 2024.
- Fan, X. et al. (2024). UniTalker: Scaling up Audio-Driven 3D Facial Animation through A Unified Model. ECCV 2024.
- Huang, X. & Belongie, S. (2017). Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. ICCV 2017.
- Défossez, A. et al. (2024). Moshi: A Speech-Text Foundation Model for Real-time Dialogue. Kyutai Technical Report.
- Chu, X. & Harada, T. (2024). Generalizable and Animatable Gaussian Head Avatar. NeurIPS 2024. GitHub