EmoTaG
EmoTaG 的全名是 Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization。它的目标是在只给新身份一段 5 秒视频的情况下,生成带情绪表达、口型同步、几何稳定的 3D talking head。论文作者是 Haolan Xu、Keli Cheng、Lei Wang、Ning Bi 和 Xiaoming Liu;机构包括 Michigan State University、Qualcomm Technologies Inc. 和 University of North Carolina at Chapel Hill。arXiv 当前版本为 v2,提交于 2026-03-22,最后修订于 2026-03-28;项目页标注论文已被 CVPR 2026 接收。#Xu-et-al.-2026-EmoTaG #EmoTaG-Project-2026
| 项目 | 信息 |
|---|---|
| 论文 | EmoTaG: Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization |
| 作者 | Haolan Xu、Keli Cheng、Lei Wang、Ning Bi、Xiaoming Liu |
| 机构 | Michigan State University;Qualcomm Technologies Inc.;University of North Carolina at Chapel Hill |
| 状态 | CVPR 2026 accepted;arXiv:2603.21332v2 |
| 项目页 | emotag26.github.io;页面列出 Paper / arXiv / Video / Code 入口,但当前未在静态 HTML 中解析到可直接核验的 GitHub URL |
这篇论文的位置很清楚:它站在 NeRF / 3D Gaussian Splatting talking head 路线之上,也站在 few-shot Pretrain-and-Adapt 路线之上。传统 person-specific NeRF 或 3DGS talking head 往往要对每个身份做分钟级视频训练;InsTaG、MimicTalk 这类方法把适配成本降了下来,但多集中在 neutral speech,情绪语音下的面部运动仍然容易变硬、过平滑或几何不稳。#Li-et-al.-2023-ER-NeRF #Li-et-al.-2024-TalkingGaussian #Li-et-al.-2025-InsTaG #Ye-et-al.-2024-MimicTalk
EmoTaG 的核心判断是:few-shot talking head 不能只学“音素到嘴型”的映射。情绪语音会改变 mouth opening、jaw movement、upper-face action units 和整体表情强度;如果模型仍然把这些变化压进一个混杂的 deformation latent,就很难同时做到表达力和稳定性。因此,论文把运动预测放到 FLAME 参数空间,再用 rigged 3D Gaussians 渲染;同时用 Gated Residual Motion Network 把 phonetic base motion、emotion residual 和 emotion intensity 分开建模。#Xu-et-al.-2026-EmoTaG #Qian-et-al.-2024-GaussianAvatars
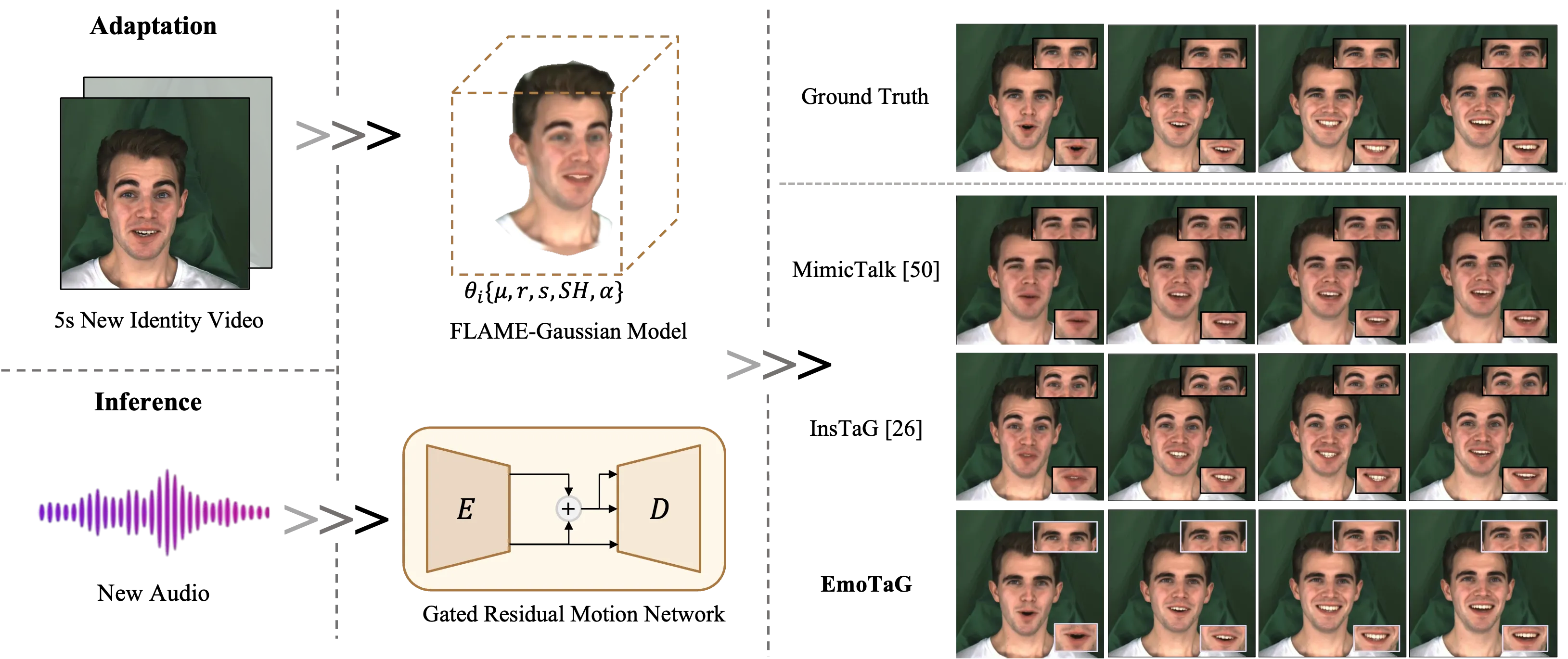
读 EmoTaG 前,先要区分两个目标。Audio-driven talking head 只要求模型根据语音生成同步的人脸动画;emotion-aware talking head 还要求模型识别语音里的情绪韵律,并把它转化为嘴角、下颌、眉眼和上半脸的动态变化。前者主要关注 lip synchronization,后者还关注 affective expression。#Xu-et-al.-2026-EmoTaG
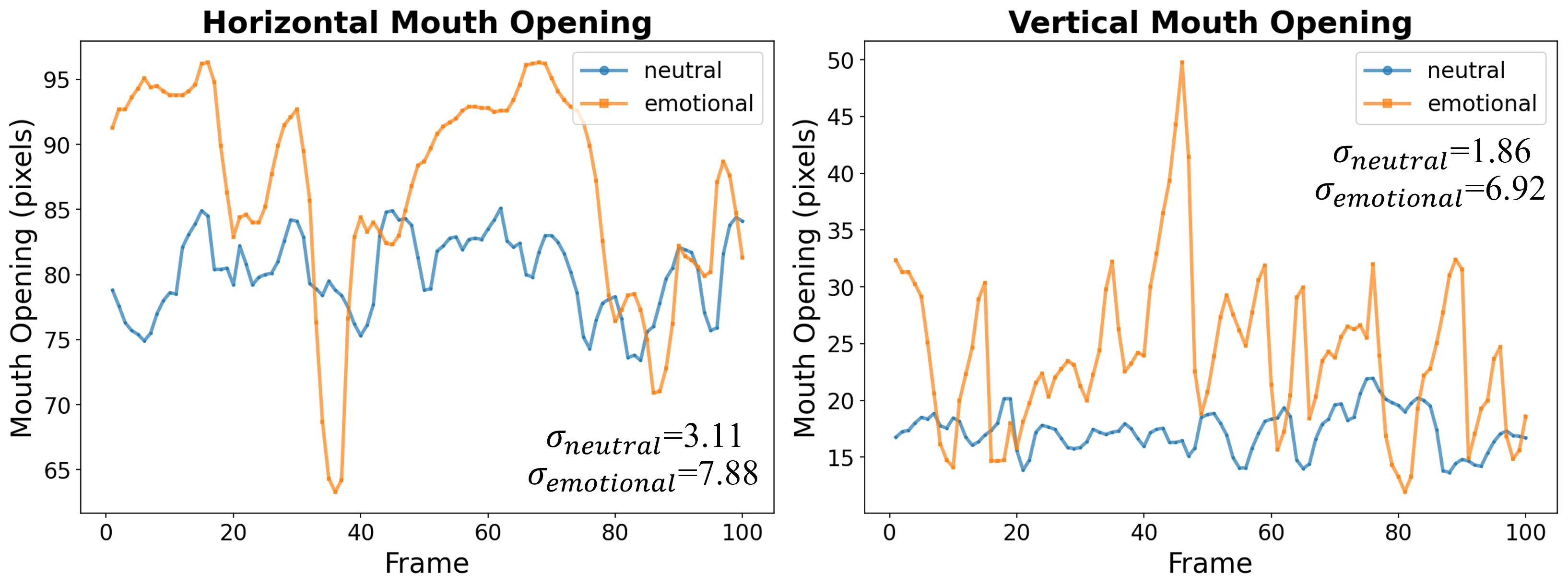
论文用一个很直接的动机实验说明差别:在 neutral audio 和 emotional audio 中,嘴部开合轨迹的波动显著不同。情绪语音的水平和垂直 mouth opening 标准差分别是 \(7.88\) 与 \(6.92\),而 neutral audio 只有 \(3.11\) 与 \(1.86\)。这说明 emotional articulation 不只是“嘴张得更大”,而是时间波动更强、轨迹更复杂。#Xu-et-al.-2026-EmoTaG
难点有两层。第一层是语义层:模型要知道现在是 happy、sad、surprised、angry 还是 fear,并且区分同一情绪的强弱。第二层是几何层:3DGS 的每个 Gaussian 都有位置、旋转、尺度、不透明度和颜色系数,如果网络直接预测 unconstrained Gaussian deformation,夸张表情很容易带来局部漂移、口腔塌陷或表情过冲。#Kerbl-et-al.-2023-3DGS #Xu-et-al.-2026-EmoTaG
核心术语
Few-shot personalization 指只用几秒目标人物视频完成身份适配;Pretrain-and-Adapt 指先在多身份语料上学通用 audio-motion prior,再对新身份做短时优化;FLAME-Gaussian 指把 3D Gaussians 绑定到 FLAME mesh 的三角面片上,让 Gaussian 跟随可解释的人脸参数运动。
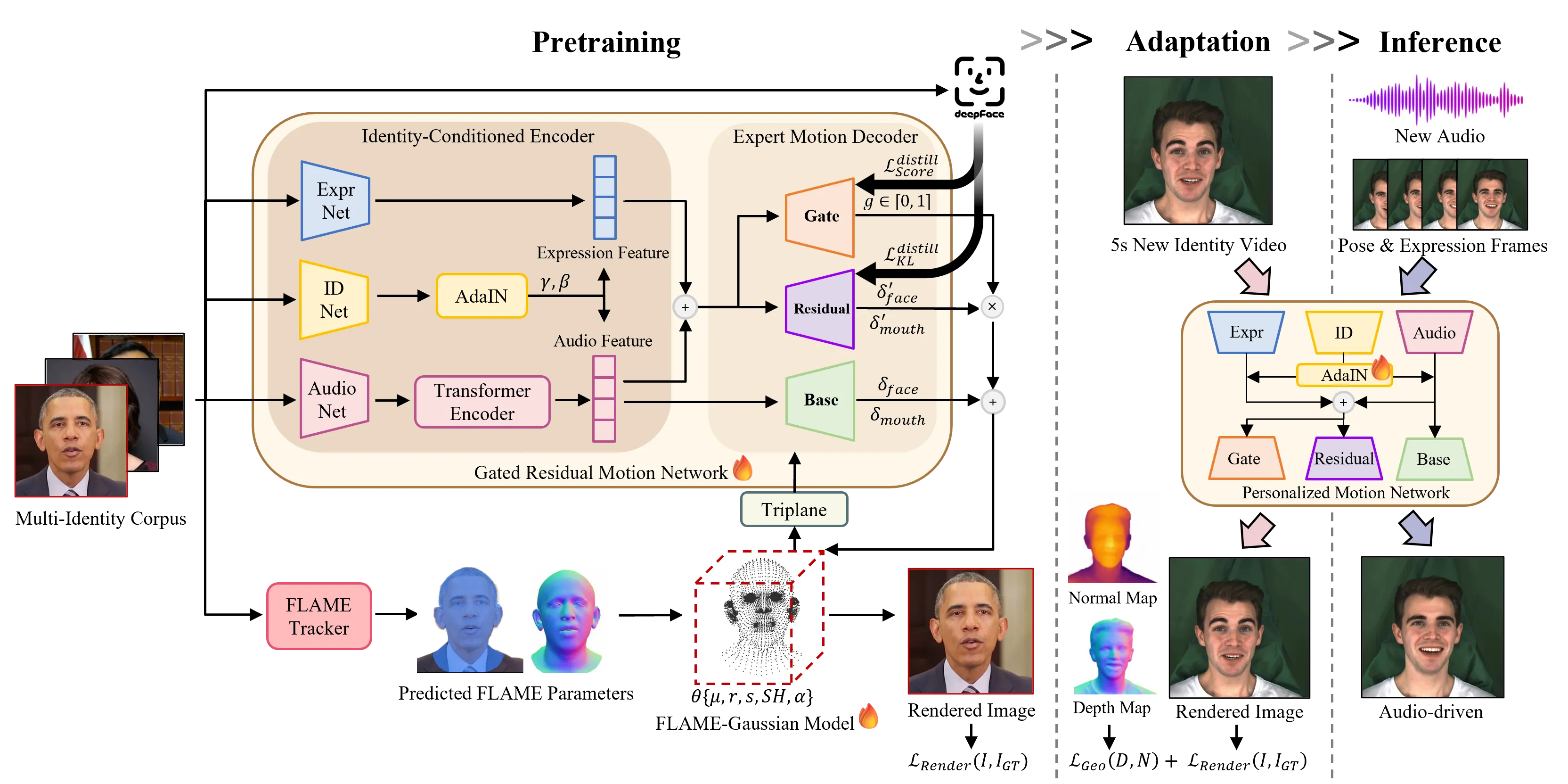
EmoTaG 可以被概括成三件事。第一,用 FLAME-Gaussian Model 提供几何底座:网络不直接任意形变所有 3D Gaussians,而是预测 FLAME expression 与 jaw pose,再把 mesh deformation 传播到 Gaussian。第二,用 GRMN 预测运动:base branch 学中性音素运动,residual branch 学情绪偏差,gate branch 控制情绪 residual 注入强度。第三,用 Semantic Emotion Guidance 从 DeepFace teacher 蒸馏情绪分布和情绪强度,避免人工情绪标签。#Xu-et-al.-2026-EmoTaG #Serengil-et-al.-2024-DeepFace
这套设计里最容易被误读的是推理输入。EmoTaG 不是纯 audio-only 系统。论文明确说明,由于音频本身很难提供 upper-face expression 和 head pose,推理时仍额外输入 pose 与 expression frames;在 self-reconstruction 和 emotion-intensity 设置中,这些 cues 来自 test clip,在 OOD audio-driven 设置中来自 adaptation clip。#Xu-et-al.-2026-EmoTaG
| 设置 | 音频来自哪里 | Pose & Expression Frames 来自哪里 | 含义 |
|---|---|---|---|
| Self-reconstruction | 同一身份、同一情绪的测试片段 | test clip | 用于衡量少样本适配后的重建质量,允许使用目标测试视频中的姿态和表情线索。 |
| Emotion-intensity | 同一身份、同一情绪但不同强度的测试音频 | test clip | 用于测试情绪强度变化下的表现,因此仍可从目标测试片段取得对应 pose/expression cues。 |
| OOD audio-driven | 不同说话人或不同语言的新音频 | 5 秒 adaptation/reference clip | 更接近真实新音频驱动:没有目标新视频可取帧,只能从参考/适配视频中提供头姿和上半脸表情线索。 |
flowchart LR A["新音频
Wav2Vec 2.0 + temporal CNN + Transformer"] --> B["Identity-Conditioned Encoder"] E["Expression cues
OpenFace AU"] --> B S["Identity feature
AdaFace neutral frames"] --> M["AdaIN modulation"] M --> B B --> C["Base branch
phonetic motion"] B --> D["Residual branch
emotion deviation"] B --> G["Gate branch
emotion intensity"] C --> F["δ = δ_b + g · δ_r"] D --> F G --> F F --> H["FLAME expression + jaw pose
mouth Gaussian residual"] H --> R["Rigged FLAME-Gaussian rendering"]
从工程角度看,这张图的关键不是模块多,而是职责被拆得很干净:身份特征通过 AdaIN 调制音频和表情流;音素主运动和情绪偏差分支分开;强弱控制由 gate scalar 处理;最终输出再被 FLAME-Gaussian 结构约束。这样做的目标是让模型既能对情绪敏感,又不因为情绪强度变大而几何失控。#Xu-et-al.-2026-EmoTaG
FLAME 是一个参数化三维人脸模型,输入 identity shape、expression 和 pose 后输出 mesh。EmoTaG 固定 shape 参数 \(\boldsymbol{\beta}\) 来保持身份,把运动预测定义为回归 expression \(\boldsymbol{\Psi}\) 和 jaw pose subset \(\boldsymbol{\Theta}_{\text{jaw}}\in\mathbb{R}^{3}\)。#Li-et-al.-2017-FLAME #Xu-et-al.-2026-EmoTaG
3DGS 则把头像表示为一组三维 Gaussian primitives,每个 primitive 包含中心、旋转、尺度、不透明度和球谐颜色系数。EmoTaG 用 FLAME mesh 三角面均匀采样初始化 \(60K\) 个 Gaussians,并用 barycentric weights 把每个 Gaussian 绑定到父三角面。#Kerbl-et-al.-2023-3DGS #Xu-et-al.-2026-EmoTaG
真正起稳定作用的是 rigged mapping。每个 Gaussian 在父三角面的局部坐标系中定义,三角面变形后,再通过对应的旋转 \(\mathbf{R}^{j}\)、中心 \(\mathbf{C}^{j}\) 和尺度 \(k^{j}\) 映射回全局空间。这个机制继承自 GaussianAvatars,它让 Gaussian 像贴在人脸 mesh 上一样移动,而不是在三维空间里自由漂移。#Qian-et-al.-2024-GaussianAvatars #Xu-et-al.-2026-EmoTaG
口腔区域又是特殊情况。牙齿、舌头和内口腔不是标准 FLAME face surface 最容易表达的部分,所以 EmoTaG 从 augmented FLAME mesh 中根据嘴部 landmarks 选出 intra-oral Gaussian subset,并额外预测 \(\Delta\boldsymbol{\mu}\)、\(\Delta\boldsymbol{r}\)、\(\Delta\boldsymbol{s}\) 来补细节;opacity 和 SH 仍保持固定,因为它们主要承载静态外观。#Xu-et-al.-2026-EmoTaG
GRMN 的第一部分是 Identity-Conditioned Encoder。音频流先经 Wav2Vec 2.0 提取 frame-level speech embeddings,再通过 temporal 1D CNN、MLP 和 4-layer Transformer 获取更长程的韵律特征;表情流来自 OpenFace 提取的 Action Units,用来补充 brow raise、eye squeeze 这类音频缺失的上半脸信息;身份流则取 DeepFace 排名最中性的 top-50 frames,平均 AdaFace features 得到身份 descriptor。#Baevski-et-al.-2020-Wav2Vec2 #Baltrusaitis-et-al.-2015-OpenFace #Kim-et-al.-2022-AdaFace #Xu-et-al.-2026-EmoTaG
身份注入通过 AdaIN 完成。给定音频或表情特征 \(\mathbf{F}\) 和身份特征 \(\mathbf{s}\),MLP 预测调制参数 \(\boldsymbol{\gamma}\) 与 \(\boldsymbol{\beta}\),再对特征做 instance normalization 与 affine transform。论文在方法概述中写明,GRMN 对新身份的高效适配通过 tuning AdaIN modulation parameters 完成;实现细节又提到 Gaussian parameters 与 GRMN 的联合优化,因此本文把它理解为“以 AdaIN 调制为核心的高效身份适配”,而不扩写成未经代码核验的完整冻结策略。#Huang-et-al.-2017-AdaIN #Karras-et-al.-2019-StyleGAN #Xu-et-al.-2026-EmoTaG
Expert Motion Decoder 有三条分支。Base branch 预测中性、跨身份共享的 phoneme-driven deformation;Residual branch 预测 emotion-driven 和 identity-specific residual motion;Gate branch 输出 \(g\in[0,1]\),逐帧决定 residual 该注入多少。最终运动是 base 加 gated residual。#Xu-et-al.-2026-EmoTaG
这个公式看起来很简单,但它解决的是情绪建模里最麻烦的控制问题。没有 residual branch,模型只能生成平均化、偏中性的动作;没有 gate branch,情绪残差可能过强,导致夸张或不稳定;没有身份调制,不同人的说话风格会纠缠在一起。消融实验也支持这个解释:去掉 Identity Modulation 掉点最大,去掉 Residual 或 Gate 都会明显损害 LMD 与 Sync-C。#Xu-et-al.-2026-EmoTaG
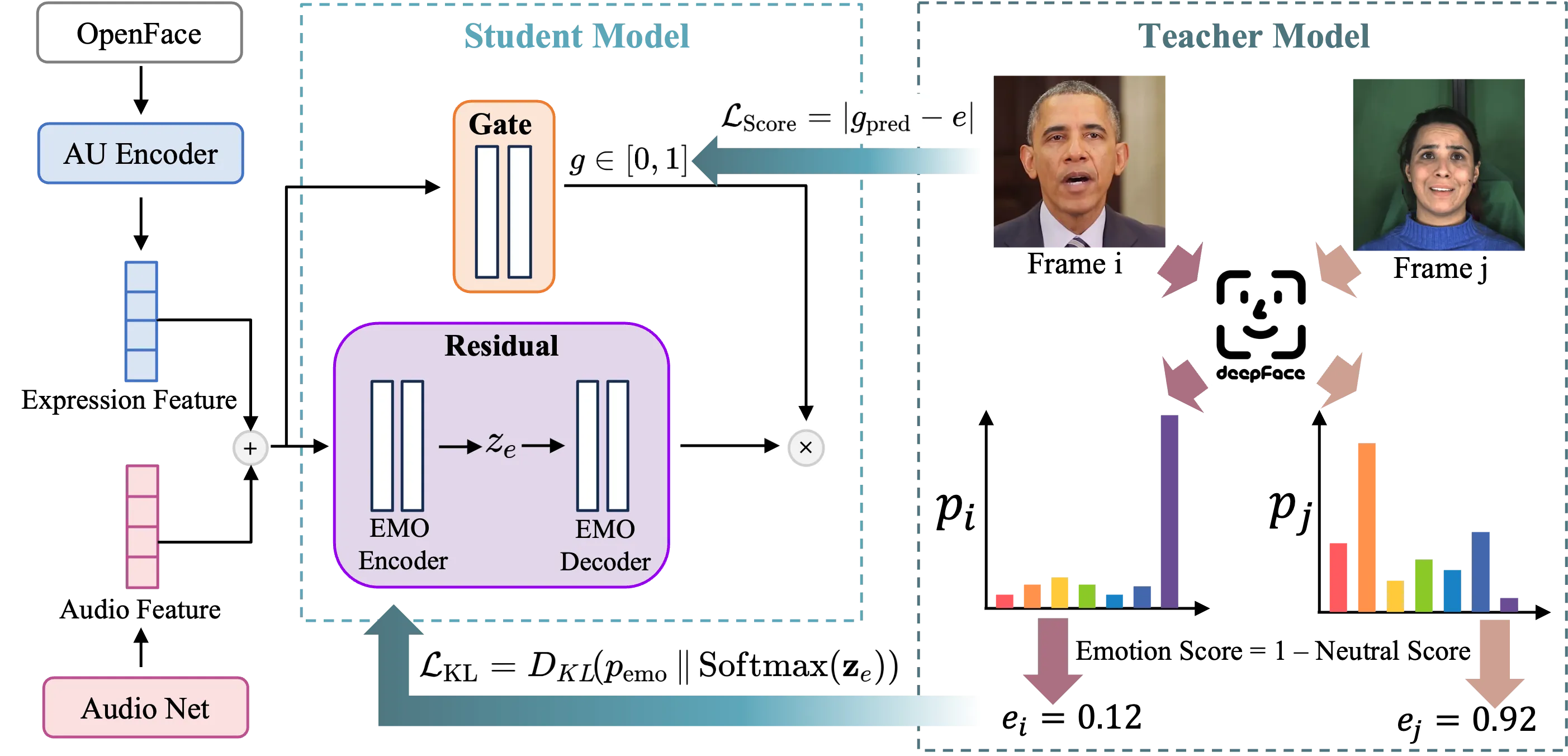
Semantic Emotion Guidance 是这篇论文最关键的情绪监督机制。EmoTaG 不使用人工情绪标签,而是用 DeepFace 作为 teacher。DeepFace 输出七类基本情绪概率 \(p_{\text{emo}}\),同时定义情绪强度分数 \(e=1-p_{\text{emo}}(\text{neutral})\)。Residual branch 的 emotion latent \(\mathbf{z}_{e}\) 用 KL loss 对齐 teacher emotion distribution;gate branch 用 score loss 回归情绪强度。#Serengil-et-al.-2024-DeepFace #Xu-et-al.-2026-EmoTaG
因此,“无需人工情绪标签”不等于没有情绪监督。更准确的说法是:EmoTaG 用预训练 emotion recognizer 自动产生 teacher signal,从而把类别语义和强度控制分别蒸馏到 residual 与 gate。这个边界很重要,因为 DeepFace 的识别偏差、类别定义和 domain gap 都会影响最终情绪表达。#Xu-et-al.-2026-EmoTaG #Serengil-et-al.-2024-DeepFace
训练阶段分成 pretraining 和 adaptation。预训练使用 HDTF 中 70 个身份、70 段视频,每段 90–240 秒,用来学习 identity-agnostic audio-motion prior。评估时,neutral set 包含 10 个公开身份视频;emotional set 来自 MEAD,覆盖 happy、sad、surprised、angry、fear 五类情绪,每类 3 个强度等级、2 个身份。所有视频 face-centered crop 到 \(512\times512\),帧率为 25 FPS。#Zhang-et-al.-2021-HDTF #Wang-et-al.-2020-MEAD #Xu-et-al.-2026-EmoTaG
训练课程也很具体。每个身份先用前 1,000 iterations 只优化 static appearance;之后 jointly optimize Gaussian parameters 与 GRMN。预训练总计 250K iterations,adaptation 20K iterations;优化器是 AdamW,预训练学习率 \(5\times10^{-3}\),适配学习率 \(5\times10^{-4}\)。实验在单张 NVIDIA RTX A6000 上完成。#Loshchilov-Hutter-2017-AdamW #Xu-et-al.-2026-EmoTaG
完整训练目标由渲染、情绪蒸馏和几何监督组成。前三项用于 pretraining 和 adaptation,几何损失 \(\mathcal{L}_{\text{Geo}}\) 只在 adaptation 使用;深度与法线伪真值来自 Sapiens。#Khirodkar-et-al.-2024-Sapiens #Xu-et-al.-2026-EmoTaG
| 项目 | 论文披露内容 | 说明 |
|---|---|---|
| 预训练数据 | HDTF,70 identities,每段 90–240 秒 | 用于通用 audio-motion prior |
| Gaussian 初始化 | 60K Gaussians sampled from FLAME mesh | 每个 Gaussian 绑定到 FLAME triangle |
| 训练轮数 | 1,000 static warm-up;250K pretraining;20K adaptation | 5 秒个性化输入与 11 分钟适配是两个概念 |
| 优化器与学习率 | AdamW;\(5\times10^{-3}\) / \(5\times10^{-4}\) | 分别对应 pretraining / adaptation |
| 损失权重 | \(\lambda_{\text{D-SSIM}}=2\times10^{-1}\),\(\lambda_D=1\times10^{-2}\),\(\lambda_N=1\times10^{-3}\) | KL / Score 未披露额外权重 |
| 硬件 | single NVIDIA RTX A6000 | 未披露 CPU、内存、batch size |
| 未披露项 | batch size、LR schedule、AdamW betas、模型维度、参数量、pretraining wall-clock | 不能根据常见设置补写 |
推理阶段可以拆成四步。第一步,整段音频先做一次 audio encoding,论文给出的耗时约 25 ms。第二步,逐帧读取辅助 pose 与 expression cues;pose 由 FLAME Tracker 处理,upper-face cues 由 Expression Network 提供。第三步,适配后的 GRMN 预测 FLAME expression、jaw pose 和 mouth Gaussian residual,每帧约 6 ms。第四步,3DGS renderer 渲染动态头像,每帧约 7 ms。#Xu-et-al.-2026-EmoTaG
| 阶段 | 输入 | 输出 | 论文披露耗时 |
|---|---|---|---|
| Audio encoding | 新音频 waveform | frame-level audio features | 约 25 ms / sequence |
| Auxiliary cue extraction | pose & expression frames | head pose / upper-face cues | 未完整披露 |
| GRMN inference | audio + pose/expression + identity modulation | FLAME / mouth Gaussian motion | 约 6 ms / frame |
| 3DGS rendering | dynamic FLAME-Gaussians | rendered frame | 约 7 ms / frame |
| 总体速度 | adapted identity + driving audio | emotion-aware talking head video | 76.4 FPS |
这里要诚实写清边界:EmoTaG 的实时性是强结论,但 audio-only 是弱结论甚至不成立。论文沿用 Real3DPortrait、MimicTalk 和 InsTaG 的做法,在推理中引入 pose & expression frames,因为音频不能可靠决定头姿和上半脸表情。OOD audio-driven 设置中,这些 cues 来自 adaptation clip,而不是目标 audio 本身。#Ye-et-al.-2024-Real3DPortrait #Ye-et-al.-2024-MimicTalk #Li-et-al.-2025-InsTaG #Xu-et-al.-2026-EmoTaG
EmoTaG 的实验分三组。Self-reconstruction:每个模型用 5 秒视频适配,然后在同一身份、同一情绪的另一段 3–10 秒 clip 上测试。Emotion-intensity:模型在 Level-2 medium intensity 适配,再分别测试 Level-1 weaker 和 Level-3 stronger audio。OOD audio-driven:固定已适配身份,测试 cross-identity 和 cross-language unseen audio。#Xu-et-al.-2026-EmoTaG

主表最强的证据是 emotional set。在 5 秒训练数据下,EmoTaG 的 PSNR / LPIPS / SSIM / LMD / AUE-L / AUE-U 分别为 29.95 / 0.022 / 0.877 / 2.456 / 0.702 / 0.236,均优于 InsTaG 的 27.82 / 0.040 / 0.851 / 3.428 / 0.995 / 0.651,也优于 TalkingGaussian 的 27.84 / 0.042 / 0.836 / 4.392 / 1.213 / 0.618。#Xu-et-al.-2026-EmoTaG
| 方法 | Emotional PSNR ↑ | LPIPS ↓ | SSIM ↑ | LMD ↓ | AUE-L ↓ | AUE-U ↓ | Sync-C ↑ | Train | FPS |
|---|---|---|---|---|---|---|---|---|---|
| Real3DPortrait | 25.16 | 0.063 | 0.815 | 3.642 | 1.183 | 1.149 | 6.583 | -- | 8.9 |
| TalkingGaussian | 27.84 | 0.042 | 0.836 | 4.392 | 1.213 | 0.618 | 3.059 | 27 min | 118.4 |
| MimicTalk | 25.13 | 0.079 | 0.842 | 3.577 | 0.961 | 0.913 | 6.113 | 17 min | 8.6 |
| InsTaG | 27.82 | 0.040 | 0.851 | 3.428 | 0.995 | 0.651 | 4.828 | 13 min | 82.5 |
| EmoTaG | 29.95 | 0.022 | 0.877 | 2.456 | 0.702 | 0.236 | 6.147 | 11 min | 76.4 |
不过 Sync-C 要诚实看。Self-reconstruction 中 EmoTaG 不是 Sync-C 第一,neutral set 上 Real3DPortrait 为 6.719、MimicTalk 为 6.341,EmoTaG 为 6.212;emotional set 上 Real3DPortrait 为 6.583,EmoTaG 为 6.147。论文的结论不是“所有指标都第一”,而是“在视觉质量、运动误差、情绪表达和几何稳定性上整体更强,同时同步指标保持竞争力”。#Xu-et-al.-2026-EmoTaG
Emotion-intensity 设置更能体现情绪建模。强情绪 Level-3 下,EmoTaG 的 LMD / AUE-L / AUE-U 为 2.522 / 0.721 / 0.244,而 InsTaG 是 3.559 / 1.144 / 0.704。也就是说,越到强情绪,GRMN + SEG 相对 neutral few-shot prior 的优势越明显。#Xu-et-al.-2026-EmoTaG
OOD audio-driven 中,EmoTaG 在 lip synchronization 指标上反而全部第一:cross-identity Sync-E / Sync-C 为 9.133 / 5.814,cross-language 为 9.662 / 5.432,均优于 InsTaG 的 9.921 / 4.722 与 10.033 / 4.391。这说明它在 unseen speaker 和 unseen language 的音唇泛化上确实更稳。#Xu-et-al.-2026-EmoTaG
用户研究也支持主观质量结论。20 名参与者在 self-reconstruction setting 的匿名结果上按 1–5 Likert 打分;EmoTaG 在 emotional expressiveness、lip synchronization、visual realism 上分别为 4.50、4.70、4.60,三项均最高。论文未披露每位参与者观看的样本数量、随机化细节和显著性检验,因此这些主观分数应作为感知证据,而不是统计显著性结论。#Xu-et-al.-2026-EmoTaG
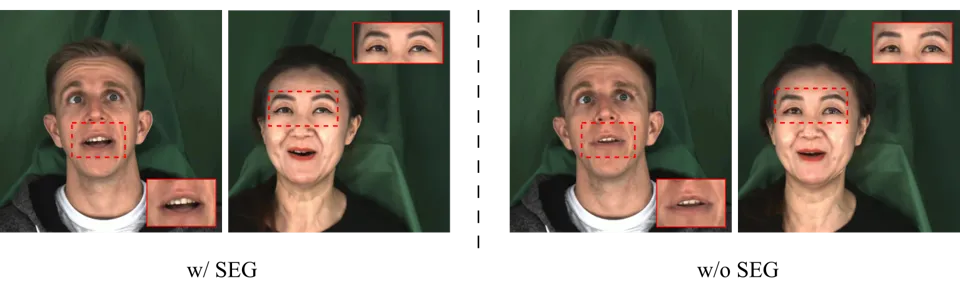
| 变体 | PSNR ↑ | LPIPS ↓ | LMD ↓ | Sync-C ↑ | 解读 |
|---|---|---|---|---|---|
| Full EmoTaG | 29.95 | 0.022 | 2.456 | 6.147 | 完整模型 |
| w/o Score Distill | 29.52 | 0.026 | 2.731 | 5.874 | 情绪强度监督削弱,同步下降 |
| w/o KL Distill | 29.36 | 0.031 | 2.985 | 5.712 | residual 失去情绪语义监督 |
| w/o SEG | 29.01 | 0.034 | 3.067 | 5.541 | 情绪建模整体退化 |
| w/o Gate Branch | 28.77 | 0.036 | 3.358 | 5.004 | 残差注入失控,时序稳定性变差 |
| w/o Residual Branch | 28.52 | 0.038 | 3.572 | 4.896 | 表情过平滑,情绪变化不足 |
| w/o Identity Modulation | 28.38 | 0.040 | 4.021 | 4.621 | 掉点最大,说明身份调制对 few-shot 适配很关键 |
EmoTaG 的贡献不是“首次把 3DGS 用到 talking head”,TalkingGaussian、GaussianTalker、GSTalker 等工作已经建立了这条路线。它的更准确位置是:在 few-shot Pretrain-and-Adapt 框架中,把 emotional speech 的运动建模拆成结构约束、情绪残差和强度门控三件事,并证明这种拆法在 5 秒个性化输入下有效。#Li-et-al.-2024-TalkingGaussian #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker #Xu-et-al.-2026-EmoTaG
与 GaussianAvatars 的关系是几何底座关系:EmoTaG 借用 rigged 3D Gaussian 的思想,把动态头像固定在可解释的 FLAME mesh 运动上。与 InsTaG 的关系是任务范式关系:两者都追求 few-second personalization,但 EmoTaG 额外显式建模情绪语义与情绪强度。与 Real3DPortrait、MimicTalk 的关系是强预训练参照关系:这些模型在同步上有竞争力,但 EmoTaG 试图减少刚性和过平滑表情。#Qian-et-al.-2024-GaussianAvatars #Li-et-al.-2025-InsTaG #Ye-et-al.-2024-Real3DPortrait #Ye-et-al.-2024-MimicTalk
限制也要写清。第一,论文没有独立 limitations section,也没有明确 failure cases;因此最终读者不能从正文得到系统失败边界。第二,方法依赖多个外部模型:Wav2Vec 2.0、OpenFace、AdaFace、DeepFace、VHAP、Sapiens,这些工具链的误差会向后传播。第三,推理仍需要 pose & expression frames,不是纯音频驱动全部头姿和上半脸。第四,训练细节仍有未披露项,包括 batch size、模型维度、参数量、LR schedule、pretraining wall-clock 与用户研究显著性检验。第五,项目页列出 Code 入口,但当前静态页面没有解析到可直接核验的 GitHub URL;代码 license、star 数和完整实现状态需要等官方仓库稳定后再补。#Xu-et-al.-2026-EmoTaG #EmoTaG-Project-2026
读完可以带走什么
- 运动空间很重要:情绪说话头不宜只做 unconstrained 3DGS deformation,结构化 FLAME space 能提供稳定边界。
- 情绪要拆成类型和强度:Residual branch 负责情绪偏差,Gate branch 负责强度控制,比单一 latent 更可解释。
- few-shot 不等于零优化:EmoTaG 的输入是 5 秒视频,但仍做 20K iterations adaptation,主表训练耗时为 11 分钟。
- 实时不等于纯 audio-only:76.4 FPS 是渲染/推理速度结论,但系统仍使用 pose 与 expression auxiliary cues。
参考来源
- Xu, H. et al. (2026). EmoTaG: Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization. arXiv:2603.21332
- EmoTaG Project Page (2026). Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization. Project page
- Qian, S. et al. (2024). GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians. arXiv:2312.02069
- Kerbl, B. et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. Project page
- Li, T. et al. (2017). Learning a model of facial shape and expression from 4D scans. FLAME project
- Li, J. et al. (2023). Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis. arXiv:2307.09323
- Li, J. et al. (2024). TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting. arXiv:2404.15264
- Li, J. et al. (2025). InsTaG: Learning Personalized 3D Talking Head from Few-Second Video. arXiv:2502.20387
- Ye, Z. et al. (2024). MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes. arXiv:2410.06734
- Ye, Z. et al. (2024). Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis. arXiv:2401.08503
- Cho, K. et al. (2024). GaussianTalker: Real-Time Talking Head Synthesis with 3D Gaussian Splatting. arXiv:2404.16012
- Chen, Y. et al. (2024). GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting. arXiv:2406.02516
- Serengil, S. I. and Ozpinar, A. (2024). A Benchmark of Facial Recognition Pipelines and Co-Usability Performances of Modules. DeepFace GitHub
- Baevski, A. et al. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv:2006.11477
- Baltrušaitis, T. et al. (2015). OpenFace: An open source facial behavior analysis toolkit. OpenFace GitHub
- Kim, M. et al. (2022). AdaFace: Quality Adaptive Margin for Face Recognition. arXiv:2204.00964
- Huang, X. and Belongie, S. (2017). Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. arXiv:1703.06868
- Karras, T. et al. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv:1812.04948
- Zhang, Z. et al. (2021). Flow-Guided One-Shot Talking Face Generation with a High-Resolution Audio-Visual Dataset. arXiv:2109.11562
- Wang, K. et al. (2020). MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation. Project page
- Loshchilov, I. and Hutter, F. (2017). Decoupled Weight Decay Regularization. arXiv:1711.05101
- Khirodkar, R. et al. (2024). Sapiens: Foundation for Human Vision Models. arXiv:2408.12569