EGSTalker:实时音频驱动 3D Gaussian 数字人
EGSTalker 是一篇面向实时 audio-driven talking head generation 的 3D Gaussian Splatting 论文。它的任务不是 zero-shot 生成任意人的视频,而是给定目标人物约 3–5 分钟训练视频,先建立这个人的静态三维头部表示,再用新音频驱动每一帧的 Gaussian 属性变形,最终合成会说话的头像视频。论文提交于 2025 年 10 月,并注明被 IEEE International Conference on Systems, Man, and Cybernetics 2025 接收。#Zhu-et-al.-2025-EGSTalker
这篇论文容易被一句“实时 3DGS 数字人”概括掉,但真正的问题比这更具体:3DGS 的 rasterization 已经能把渲染速度推得很高,瓶颈转移到了 audio-to-motion mapping。也就是说,系统要回答的问题变成:音频特征如何高效地控制大量 3D Gaussian 的位置、尺度、旋转、不透明度和颜色系数?如果只是用 MLP 做逐点调制,表达力不够;如果对所有空间点和音频条件做完整 cross-attention,计算成本又会压垮实时性。#Zhu-et-al.-2025-EGSTalker #Kerbl-et-al.-2023-3DGS
Audio-driven talking head 大致可以沿三条路线理解。第一类是 2D 图像或视频编辑,例如 Wav2Lip 和 IP-LAP。这类方法直接在图像空间或局部嘴部区域做同步,推理链路相对轻,但头姿、身份一致性、牙齿细节和三维一致性更依赖训练数据与后处理。#Prajwal-et-al.-2020-Wav2Lip #Zhong-et-al.-2023-IP-LAP
第二类是 NeRF talking portrait。AD-NeRF、RAD-NeRF、ER-NeRF 这条线用隐式辐射场建模人物头部,优点是三维一致性更强,但训练和渲染成本明显更高。EGSTalker 的实验表中,AD-NeRF 训练时间为 167.6h、FPS 只有 0.04;ER-NeRF 训练时间为 8.9h、FPS 为 15.21。这个数量级说明,NeRF 路线即使画质稳定,也很难直接满足高帧率交互系统。#Guo-et-al.-2021-AD-NeRF #Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF
第三类就是 3DGS talking head。3D Gaussian Splatting 把场景表示为一组可学习的 Gaussian primitives,每个 Gaussian 携带位置、尺度、旋转、opacity 和 spherical harmonics 颜色参数,再通过高效 rasterization 渲染。TalkingGaussian、GaussianTalker、GSTalker 都在探索如何让这些 Gaussian 随音频动态变化。EGSTalker 正是这条线的后续:它吸收 GaussianTalker 的“静态 Gaussian + 音频驱动 deformation”范式,但把空间编码、音频空间融合和属性预测重新做轻量化。#Kerbl-et-al.-2023-3DGS #Li-et-al.-2025-TalkingGaussian #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker
| 路线 | 代表方法 | 优势 | 主要瓶颈 | EGSTalker 的关系 |
|---|---|---|---|---|
| 2D lip editing / video dubbing | Wav2Lip, IP-LAP | 链路轻,直接优化唇形同步 | 三维一致性、头姿和身份细节受限 | 作为低成本基线比较 |
| NeRF talking portrait | AD-NeRF, RAD-NeRF, ER-NeRF | 隐式三维表示,画面稳定 | 训练慢、渲染慢 | 提供 audio-spatial decomposition 与 region-aware 思路 |
| 3DGS talking head | TalkingGaussian, GaussianTalker, GSTalker | 渲染快,适合实时系统 | 音频如何控制 Gaussian 仍然困难 | EGSTalker 直接在这一线改进效率和融合机制 |
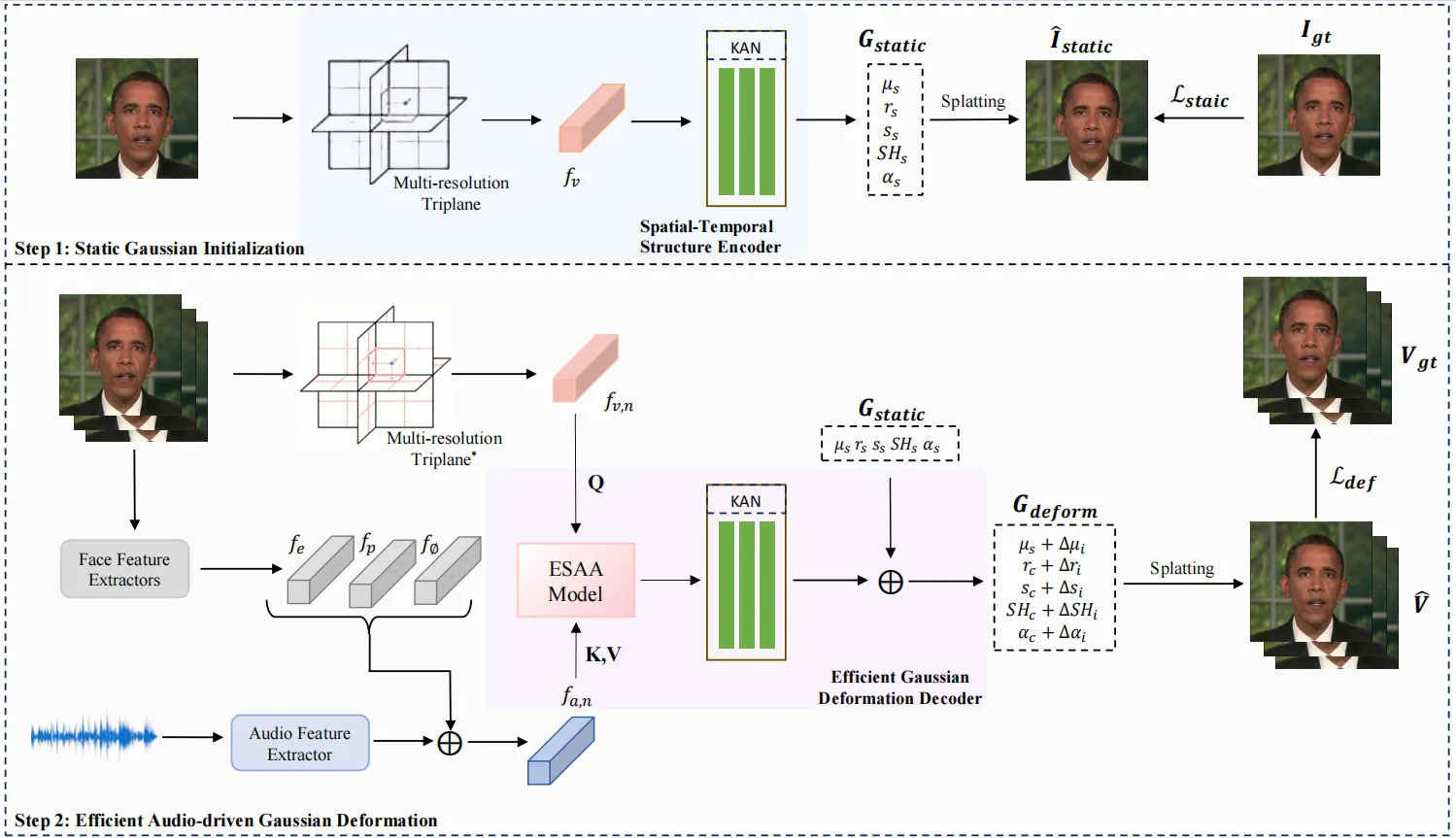
EGSTalker 的 pipeline 分成两个阶段。第一阶段叫 Static Gaussian Initialization,目标是从训练视频中建立目标人物的静态 3D Gaussian 表示;第二阶段叫 Efficient Audio-driven Gaussian Deformation,目标是在每一帧根据音频、眼部特征和相机姿态预测 Gaussian 属性偏移。最终输出不是直接生成像素,而是先得到动态 Gaussian,再用 3DGS rasterization 渲染出视频帧。#Zhu-et-al.-2025-EGSTalker
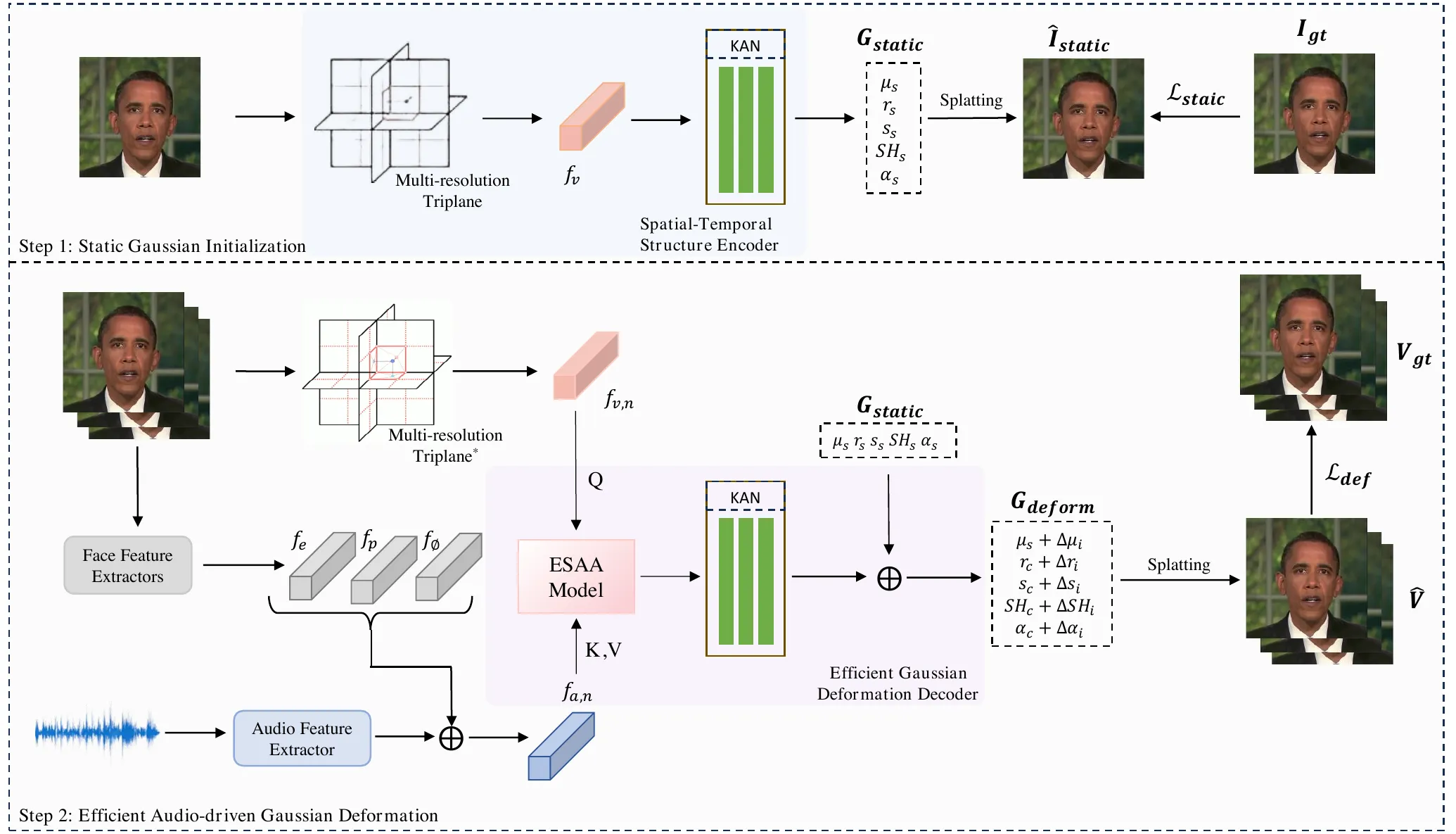
用公式概括,静态阶段把空间点 \(\mathbf{x}=(x,y,z)\) 编码为空间特征 \(f_v(\mathbf{x})\),再映射为静态 Gaussian 参数:
动态阶段则基于融合后的音频感知空间特征 \(f_d(\mathbf{x}_n)\),预测第 \(n\) 个 Gaussian 的属性偏移:
最后渲染视频帧:
flowchart LR V["3–5 分钟目标人物视频"] --> S["Static Gaussian Initialization"] S --> G["静态 3D Gaussian: 位置 / 尺度 / 旋转 / SH / opacity"] A["驱动音频"] --> AN["AudioNet + AudioAttNet"] E["眼部特征"] --> ESAA["ESAA: agent aggregation + broadcast"] C["相机姿态"] --> ESAA G --> ESAA AN --> ESAA ESAA --> D["Gaussian deformation offsets"] D --> R["3DGS rasterization"] R --> O["Talking head video"]
Static Gaussian Initialization:triplane 负责空间结构,代码里的静态头其实是 MLP heads
静态阶段的动机是脸部运动具有区域性。嘴唇附近的点在发音时高度相关,眼周、脸颊、下巴又有不同的运动模式。普通 3DGS 可以表示一个静态头,但它不天然知道这些 intra-region 与 inter-region spatial relationships。EGSTalker 采用 multi-resolution hash triplane:把三维点投影到三个正交二维平面,在多分辨率网格上插值,再用 Hadamard product 融合成紧凑空间特征。#Zhu-et-al.-2025-EGSTalker #Cao-and-Johnson-2023-HexPlane
这里有一个必须保真的细节:论文公式把空间特征到 Gaussian 参数的映射写成 KAN,但官方仓库当前实现中,静态分支 scene/canonical_tri_plane.py 使用 HexPlaneField(args.bounds, args.kplanes_config, args.multires) 生成特征,随后 feature_out、scales、rotations、opacity、shs 都是 Linear/ReLU MLP heads,而不是 scene/networks.py 中封装的 Taylor-KAN。也就是说,论文方法描述和开源实现存在细节差异;最终读法应区分“论文公式中的 KAN 映射”和“仓库里静态/动态分支的实际实现”。#Zhu-et-al.-2025-EGSTalker #EGSTalker-GitHub
论文公式和开源实现的差异
静态阶段不要笼统写成“代码完全用 KAN 输出所有 Gaussian 参数”。源码里的静态参数头是 Linear/ReLU MLP heads;最终动态 deformation offset heads(pos_deform、scales_deform、rotations_deform、opacity_deform、shs_deform)也是 Linear/ReLU MLP heads。KAN 主要出现在动态条件编码与注意力投影相关模块,例如 audio_mlp、eye_mlp、cam_mlp、enc_x_mlp、aud_ch_att_net 和 eye_att_net。
ESAA:用 agent token 把昂贵的空间—音频交互拆成“聚合”和“广播”
EGSTalker 最关键的模块是 Efficient Spatial-Audio Attention。普通 cross-attention 的直觉很直接:每个空间点都去看音频条件,得到和当前发音相关的运动信息。但对 3DGS 来说,空间点数量很大,如果做 dense interaction,复杂度会随空间序列长度快速增长。ESAA 的思路是引入少量 agent tokens \(\mathcal{A}\):先让 agent 从音频条件中聚合信息,再让空间特征向 agent 查询并广播回每个空间点。#Zhu-et-al.-2025-EGSTalker #Han-et-al.-2025-AgentAttention
论文把这个过程写成:
其中 scaled dot-product attention 是:
这个式子的读法是:里面的 \(SDP(\mathcal{A},f_a,f_a)\) 是 Agent Aggregation,agent tokens 从音频特征中提取代理值;外面的 \(SDP(f_v,\mathcal{A},\cdot)\) 是 Agent Broadcast,空间特征向 agent 查询,把音频驱动信息分发到每个空间位置。复杂度从 \(O(N^2d)\) 降到 \(O(Nnd)\),其中 \(N\) 是空间长度,\(n\) 是 agent token 数,\(d\) 是特征维度。#Zhu-et-al.-2025-EGSTalker
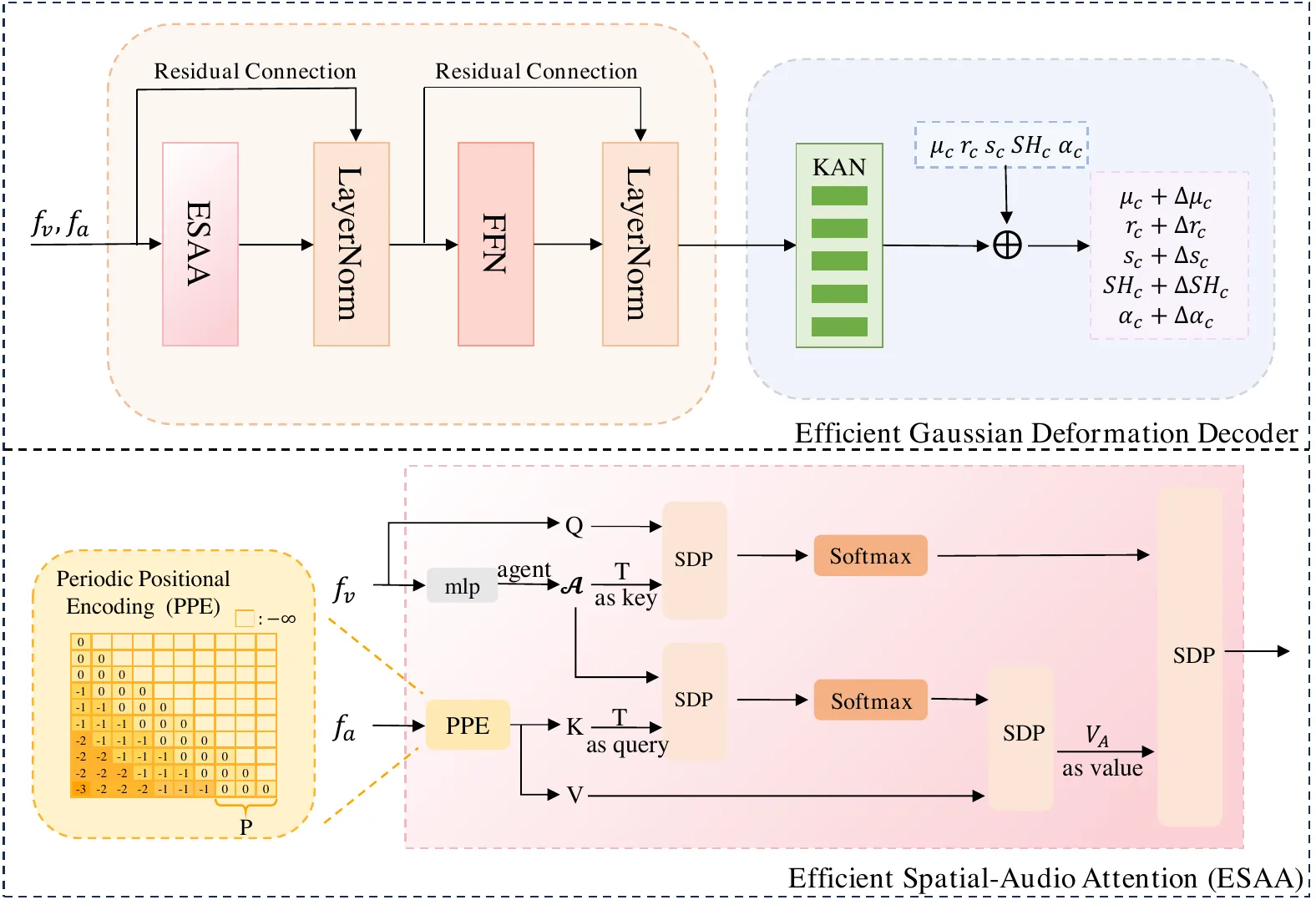
官方代码中,这一机制对应 scene/transformer/agent_attention_t.py 的 AgentScaleDotProductAttention:先用 agent_linear(q[:, :self.agent_num, :]) 生成 agent tokens,再计算 agent_attn_scores 聚合 value,最后用 q_attn_scores 把聚合后的 agent_values 广播回 query。scene/transformer/transformer.py 的 Spatial_Audio_Attention_Layer 在 attention 前对 enc_source 加 PeriodicPositionalEncoding,然后做残差、LayerNorm 和 FFN。#EGSTalker-GitHub
EGSTalker 还加入 Periodic Positional Encoding,用来表达音频驱动面部运动的周期性:
源码里 PeriodicPositionalEncoding(d_model=args.d_model, period=25, max_seq_len=600) 对应 25 FPS 视频条件下的周期编码设定。音频之外,代码还把 eye feature、camera pose 和一个 learnable null vector 拼入 enc_source,说明它并不把所有面部运动都归因于音频。#Zhu-et-al.-2025-EGSTalker #EGSTalker-GitHub
作为系统型/工程型论文,训练链路必须单独看。论文给出两类训练目标。静态阶段使用重建、结构相似性和 perceptual loss:
动态阶段额外加入嘴部区域约束:
论文正文没有逐项列出优化器和学习率 schedule,官方代码补足了可复现实现:train.py 中先训练 coarse stage,再训练 fine stage;arguments/args.py 把 coarse_iterations 设为 100、iterations 设为 1000、batch_size 设为 8,并开启 lip_fine_tuning=True 与 depth_fine_tuning=True。优化器在 scene/gaussian_model.py 中使用 Adam,eps=1e-15;实验覆盖配置包含 deformation_lr_init=0.0001 与 deformation_lr_final=0.00001。#Zhu-et-al.-2025-EGSTalker #EGSTalker-GitHub
| 项目 | 论文正文 | 官方代码补充 |
|---|---|---|
| 训练数据 | 4 个高分辨率视频,三男一女,每段约 6500 帧,25 FPS | 数据加载由 scene/provider.py 处理 |
| 硬件 | 单张 NVIDIA Tesla T4,16GB VRAM | 代码自动选择 CUDA;CPU 与系统内存未在论文正文披露 |
| 阶段 | Static initialization + audio-driven deformation | train.py 中 coarse 后 fine |
| 迭代 | 正文未逐项披露 | coarse_iterations=100, iterations=1000;epoch 数未披露 |
| batch size | 正文未披露 | batch_size=8,coarse 内部强制 batch size 1 |
| 学习率 | 正文未披露 | deformation_lr_init=0.0001, deformation_lr_final=0.00001;通用默认值还含 position/grid/feature/opacity/scaling/rotation 学习率 |
| 损失实现 | 符号化 \(\lambda\) 权重 | \(0.8L_1+0.01L_{perceptual}+0.2(1-SSIM)\),另加 lip/depth fine-tuning 各 0.4 |
| 优化器 | 正文未披露 | Adam, eps=1e-15 |
| 推理设置 | 论文报告 FPS,但未逐项披露推理 batch、CPU、编码环境 | render.py 以 batch 调用 render_from_batch;only_infer=True 时缓存静态空间特征 |
| 训练耗时 | 表 1 报告 EGSTalker 训练 3.7h | 源码不硬编码耗时,取决于数据与硬件 |
推理入口是官方仓库的 render.py。流程是加载训练好的 GaussianModel 和 Scene,如果提供 custom_aud 就创建 custom cameras;然后按 batch 调用 render_from_batch(..., stage='fine', only_infer=True),把每一帧渲染出来,最后用 ffmpeg 合成带音频的视频。#EGSTalker-GitHub
这里有一个容易误读的地方:EGSTalker 的推理并不是纯 audio-only。论文方法图里出现的 facial attribute / face feature,在开源代码中主要对应 eye_f 这类辅助条件;它不是由音频网络在线生成,而是从目标人物视频预处理结果里读出来。具体说,数据读取阶段从 au.csv 读取 AU45_r 作为眨眼/眼部 Action Unit,再归一化为 eye_f;custom audio 推理时只替换 aud_features,eye_f、相机姿态和头部轨迹仍来自目标人物的预处理序列。#EGSTalker-GitHub
推理条件不是纯音频
如果只给一段新音频,EGSTalker 可以替换音频特征来做 cross-driven talking head;但眼部 blink/AU 信号和 camera/head trajectory 仍需要来自目标人物数据或外部驱动序列。它没有在论文和代码中给出一个“音频自动生成完整表情特征”的模块。
实时代码里最值得注意的是缓存。Deformation.forward_dynamic 在 only_infer=True 时缓存 point positional encoding、scale/rotation embedding 和 triplane features,避免每一帧重复计算静态空间部分。也就是说,实时性不是只靠 ESAA,还是三件事叠加:3DGS 本身 rasterization 快;person-specific 静态头部可以提前训练好;推理时只动态预测 offsets,并缓存可复用空间特征。#EGSTalker-GitHub #Kerbl-et-al.-2023-3DGS
| 链路段 | 对应模块 | 是否可缓存 | 实时性影响 |
|---|---|---|---|
| 目标人物静态表示 | canonical_tri_plane + GaussianModel | 训练后固定 | 把人物身份和基础纹理提前固化 |
| 音频特征 | AudioNet, AudioAttNet | 离线音频可预处理;在线语音需流式窗口 | 决定唇形响应延迟 |
| 空间特征 | self.tri_plane(..., only_feature=True) | only_infer=True 时缓存 | 减少每帧重复计算 |
| 跨模态融合 | AgentScaleDotProductAttention | 不可完全缓存 | ESAA 降低 attention 成本 |
| 属性偏移 | pos_deform, scales_deform, rotations_deform, opacity_deform, shs_deform | 逐帧预测 | 决定嘴部和面部动态 |
| 渲染合成 | render_from_batch + ffmpeg | 逐帧执行 | 3DGS rasterization 是高 FPS 的底座 |
这也解释了 EGSTalker 的适用边界:它适合目标人物固定、需要高帧率音频驱动的数字人,不适合直接作为“任意人物、任意风格、零样本生成”的通用视频模型。线上交互系统还要额外计算 ASR/TTS、网络传输、编码、WebRTC 和客户端缓冲,论文的 FPS 不能直接等价为端到端延迟。#Zhu-et-al.-2025-EGSTalker
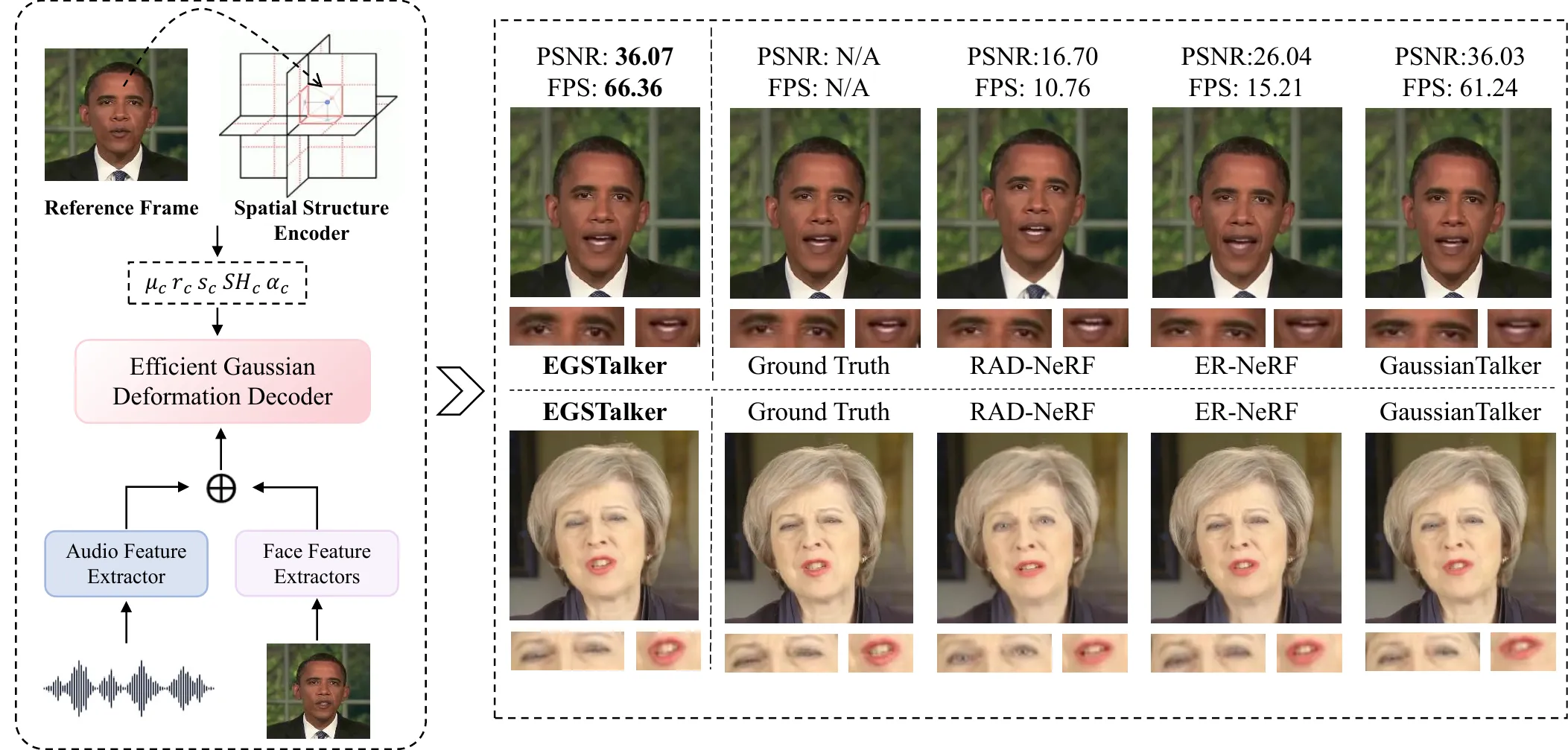
Self-driven 实验中,EGSTalker 在 PSNR、SSIM、FID、LMD、LSE-C 等指标上表现很强:PSNR 36.070、SSIM 0.992、LPIPS 0.0223、FID 2.424、LMD 2.536、LSE-D 8.237、LSE-C 6.966、训练时间 3.7h、FPS 68.51。对比 GaussianTalker,EGSTalker 的 PSNR、LPIPS、FID、LMD、LSE-C 和 FPS 都略好,训练时间从 4.5h 降到 3.7h;对比 TalkingGaussian,EGSTalker 的 FPS 略低于 70.42,LPIPS 也不如 0.0189,但 PSNR、SSIM、FID 和 LMD 更好。#Zhu-et-al.-2025-EGSTalker #Li-et-al.-2025-TalkingGaussian #Cho-et-al.-2024-GaussianTalker
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FID ↓ | LMD ↓ | LSE-D ↓ | LSE-C ↑ | Time ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|
| AD-NeRF | 25.794 | 0.9643 | 0.0842 | 18.289 | 2.932 | 9.839 | 5.105 | 167.6h | 0.04 |
| ER-NeRF | 26.047 | 0.961 | 0.0635 | 7.637 | 2.547 | 7.913 | 7.054 | 8.9h | 15.21 |
| TalkingGaussian | 35.21 | 0.990 | 0.0189 | 3.398 | 2.538 | 8.051 | 6.963 | 1.5h | 70.42 |
| GaussianTalker | 36.034 | 0.992 | 0.0224 | 2.431 | 2.614 | 8.274 | 6.964 | 4.5h | 59.24 |
| EGSTalker | 36.070 | 0.992 | 0.0223 | 2.424 | 2.536 | 8.237 | 6.966 | 3.7h | 68.51 |
Cross-driven 实验进一步考察“用非目标人物音频驱动目标身份”时的同步稳定性。EGSTalker 在 Testset A 上达到 LMD 7.459、LSE-C 6.945、LSE-D 8.470;在 Testset B 上达到 LMD 8.224、LSE-C 6.461、LSE-D 8.862。它不是每项都领先:Testset A 的最低 LMD 属于 TalkingGaussian,最低 LSE-D 属于 ER-NeRF;Testset B 的最高 LSE-C 与最低 LSE-D 也属于 ER-NeRF。EGSTalker 的优势更准确地说是,在 LMD 和 LSE-C 两个口型/同步指标上维持强竞争力,同时保持 3DGS 路线的高质量重建与实时渲染能力。#Zhu-et-al.-2025-EGSTalker
| Method | Testset A LMD ↓ | Testset A LSE-C ↑ | Testset A LSE-D ↓ | Testset B LMD ↓ | Testset B LSE-C ↑ | Testset B LSE-D ↓ |
|---|---|---|---|---|---|---|
| AD-NeRF | 7.716 | 4.932 | 10.547 | 8.379 | 4.443 | 10.707 |
| RAD-NeRF | 7.575 | 6.697 | 8.665 | 8.562 | 6.669 | 8.620 |
| ER-NeRF | 7.458 | 6.865 | 8.361 | 8.362 | 7.061 | 8.269 |
| TalkingGaussian | 7.450 | 6.136 | 9.265 | 8.323 | 6.381 | 8.637 |
| GaussianTalker | 7.994 | 6.260 | 9.523 | 8.687 | 6.618 | 8.950 |
| EGSTalker | 7.459 | 6.945 | 8.470 | 8.224 | 6.461 | 8.862 |

消融实验更有意思。去掉 ESAA 和 PPE 后,PSNR 反而从 36.070 升到 36.415,LPIPS 也从 0.0223 降到 0.0218;但 LMD 从 2.536 变差到 2.638,LSE-C 从 6.966 掉到 6.430。这个反直觉结果说明,像素重建质量不等于嘴形同步质量。模型如果只追求重建指标,可能更擅长复原平均脸部纹理,却不一定能把当前音频的细微口型变化表达出来。#Zhu-et-al.-2025-EGSTalker
| Variant | PSNR ↑ | LPIPS ↓ | LMD ↓ | LSE-C ↑ | 解读 |
|---|---|---|---|---|---|
| w/o KAN, ESAA, PPE | 36.034 | 0.0224 | 2.614 | 6.964 | 接近 GaussianTalker 基线 |
| w/o ESAA, PPE | 36.415 | 0.0218 | 2.638 | 6.430 | 像素指标更好,同步明显变差 |
| w/o PPE | 36.104 | 0.0218 | 2.537 | 6.851 | 周期信息对置信同步有帮助 |
| w/o Step 1 | 35.865 | 0.0248 | 2.651 | 6.461 | 静态初始化缺失会破坏基础表示 |
| All | 36.070 | 0.0223 | 2.536 | 6.966 | 综合同步与质量最稳 |
Agent token 数量也不是越多越好。论文报告 0.16% agent token 时 FPS 可达 74.1,但 LMD 为 2.610;0.5% 时 LMD 为 2.536、LSE-C 为 6.966、FPS 为 68.5;1.0% 时 LMD 进一步到 2.508,但 FPS 降到 65.6,LSE-C 也没有继续提升。论文最终选择 0.5%,本质上是在同步质量和实时性之间取折中点。#Zhu-et-al.-2025-EGSTalker
EGSTalker 的局限首先来自 person-specific 设定。它需要目标人物短视频训练,因此更适合固定主播、客服数字人、虚拟形象和可预训练角色,不适合用户随手上传一张图就立即生成完整数字人的场景。其次,它的泛化高度依赖训练视频覆盖。论文没有逐项报告头发、torso、极端表情、遮挡、侧脸和大幅头动的失败案例;这些是从 person-specific 训练设定推导出的工程风险,真正落地前需要用目标业务视频单独压测。#Zhu-et-al.-2025-EGSTalker
第二个局限是评测数字需要放回系统边界看。68.51 FPS 证明其渲染与变形链路满足实时潜力,但真实交互还包含音频采集、语音识别、LLM/TTS、视频编码、网络传输和客户端播放缓冲。如果接入在线数字人系统,应该单独压测端到端 p50/p95 延迟,而不能把论文 FPS 当成产品延迟。#Zhu-et-al.-2025-EGSTalker
第三个启发来自代码:论文提出 KAN 作为重要组件,但开源实现里静态 Gaussian 参数头和最终动态 deformation offset heads 都是 Linear/ReLU MLP heads,KAN 主要用于动态条件编码与注意力投影相关模块。这不是小瑕疵,而是复现和二次研究时很重要的事实。若后续要做改进,值得单独比较三种版本:完全 MLP、只在动态条件投影中用 KAN、静态参数头和最终 deformation heads 也全部改成 KAN。#EGSTalker-GitHub
读完这篇论文应保留的 5 个判断
- 范式判断:EGSTalker 属于 person-specific 3DGS talking head,不是 zero-shot video generation。
- 核心模块:ESAA 是最关键创新,用 agent tokens 降低 spatial-audio attention 成本。
- 指标判断:它不是所有指标第一,而是在质量、同步和 FPS 间取得稳定折中。
- 工程判断:实时性来自 3DGS rasterization、静态特征缓存和轻量 attention 的组合。
- 复现判断:论文 KAN 叙述与开源代码静态参数头、最终动态 offset heads 的实现存在差异,写作和复现都要明确标注。#EGSTalker-GitHub
论文与代码
- Zhu, T., Yu, Y., Wang, L., Sun, F., & Zheng, W. (2025). EGSTalker: Real-Time Audio-Driven Talking Head Generation with Efficient Gaussian Deformation. arXiv:2510.08587
- ZhuTianheng. EGSTalker official code repository. GitHub
- Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics.
- Cao, A., & Johnson, J. (2023). HexPlane: A Fast Representation for Dynamic Scenes. CVPR 2023.
- Han, D. et al. (2025). Agent Attention: On the Integration of Softmax and Linear Attention. ECCV 2025.
- Guo, Y. et al. (2021). AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis. ICCV 2021.
- Tang, J. et al. (2022). Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition. arXiv:2211.12368.
- Li, J. et al. (2023). Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis. ICCV 2023.
- Li, J. et al. (2025). TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting. ECCV 2025.
- Cho, K. et al. (2024). GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting. arXiv:2404.16012.
- Chen, B. et al. (2024). GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting. arXiv:2404.19040.
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation in the Wild. ACM Multimedia 2020.
- Zhong, W. et al. (2023). Identity-Preserving Talking Face Generation With Landmark and Appearance Priors. CVPR 2023.