AniPortrait
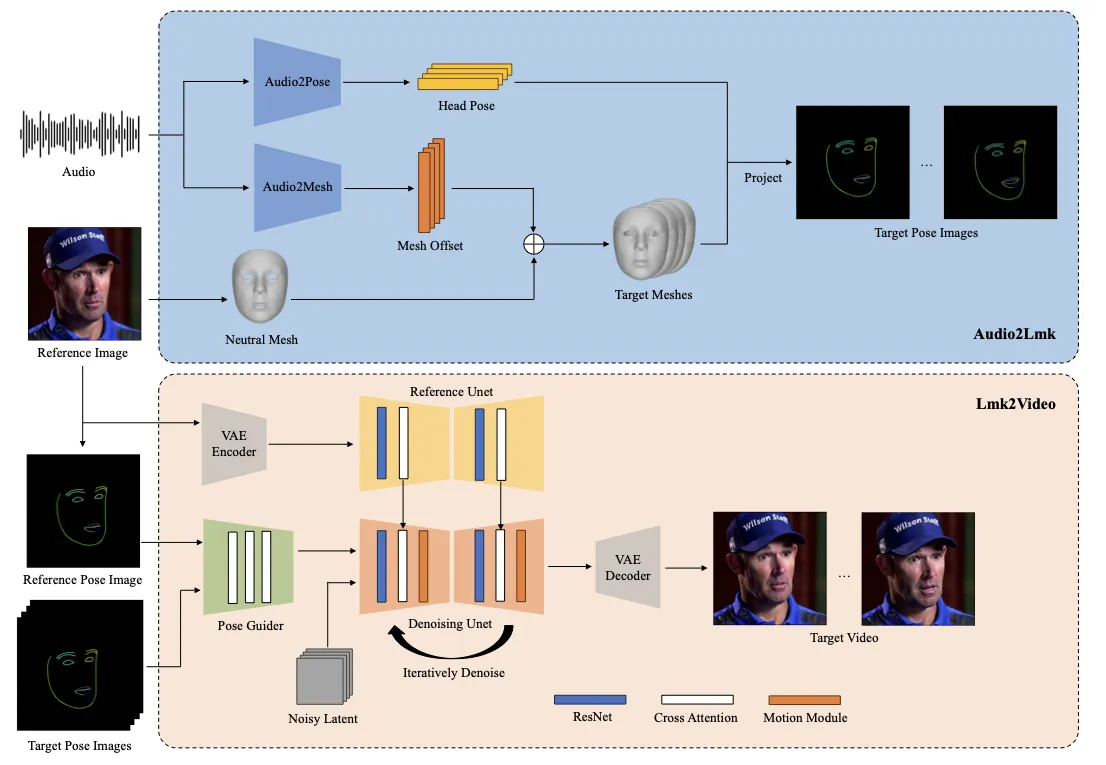
音频驱动肖像动画看起来像一个端到端生成问题:输入一张参考人像和一段语音,输出一段会说话的视频。但真正困难的地方不只是 lip-sync。一个可信的数字人需要嘴唇、表情、头部姿态和身份外观同时成立;嘴形要跟音素对齐,眉眼要有细微表达,头动要跟语音节奏自然同步,整段视频还不能闪烁或变脸。AniPortrait 把这个问题拆成两个更容易控制的子问题:先从音频估计运动,再从运动渲染视频。论文明确说框架分为两个阶段:第一阶段抽取 3D intermediate representations 并投影为 2D facial landmarks,第二阶段用 diffusion model 和 motion module 将 landmark sequence 转为 photorealistic 且 temporally consistent 的 portrait animation。#Wei-et-al.-2024
这个拆分的直觉很像电影制作里的“动作捕捉 + 渲染”。Audio2Lmk 不急着画最终像素,而是先预测“这张脸应该怎么动”;Lmk2Video 再负责把这套运动轨迹贴回参考身份,并补齐皮肤、光照、纹理和视频一致性。这样做牺牲了一部分端到端自由度,却换来了可解释、可编辑、可复用的运动空间:同一段 3D/2D 运动可以驱动不同身份,或用于 face reenactment。论文也将这种 3D 中间表示视为方法灵活性的来源。#Wei-et-al.-2024
形式化目标
Audio2Lmk 的输入是一段语音切片序列,输出不是视频帧,而是两条 3D 运动轨迹:面部 mesh 和头部 pose。论文把语音写作 \(\mathcal{A}^{1:T}=(\mathbf{a}^{1},\ldots,\mathbf{a}^{T})\),目标是预测 3D facial mesh \(\mathcal{M}^{1:T}=(\mathbf{m}^{1},\ldots,\mathbf{m}^{T})\) 与 pose sequence \(\mathcal{P}^{1:T}=(\mathbf{p}^{1},\ldots,\mathbf{p}^{T})\),其中每个 mesh \(\mathbf{m}^{t}\in\mathbb{R}^{N\times3}\),每个 pose \(\mathbf{p}^{t}\) 是表示 rotation 与 translation 的 6 维向量。#Wei-et-al.-2024
Audio2Lmk 的中间表示
3D facial mesh 负责细粒度表情和唇形;6D head pose 负责整体头部旋转和平移。二者经过 perspective projection 后变成 2D facial landmarks,作为视频扩散模型的控制信号。
为什么 mesh 和 pose 分开预测
论文使用预训练 wav2vec / wav2vec2.0 提取语音特征。音频到 mesh 的路径非常轻:wav2vec features 后接两层 fully connected layers。作者给出的理由是,wav2vec 已经能较好识别 pronunciation 与 intonation,而这些信息对 realistic facial animation 很关键;在强语音表征之上,简单结构既准确又利于推理效率。#Wei-et-al.-2024 #Baevski-et-al.-2020
音频到 pose 的路径则不同。头动更接近语音的 rhythm 和 tone,而不是单个音素对应的嘴形;同时头部姿态有明显的时间惯性,不能只看当前帧。因此 AniPortrait 用另一个不共享权重的 wav2vec backbone,并通过 Transformer decoder 结合 cross-attention 解码 pose sequence,用 previous states 保证连续性。两个 Audio2Lmk 子模块都用简单的 L1 loss 训练。#Wei-et-al.-2024 #Vaswani-et-al.-2017
从 3D 到 2D landmarks
得到 3D mesh 和 pose 后,AniPortrait 使用 perspective projection 将它们投影为 2D facial landmarks。官方代码的 audio-driven 推理脚本也印证了这条链路:scripts/audio2vid.py 加载 Audio2MeshModel 与 Audio2PoseModel,用 wav2vec 特征预测 mesh offsets 和 pose sequence,再调用 project_points(pred, face_result['trans_mat'], pose_seq, [height, width]) 投影 3D 顶点,并用 FaceMeshVisualizer.draw_landmarks 渲染 landmark images。#AniPortrait-Audio2Vid-Code
这里的 2D landmarks 不是普通可视化中间产物,而是下一阶段的条件控制图。论文还披露了一个很工程化的细节:从 2D landmarks 渲染 pose image 时,上唇和下唇使用不同颜色,以增强网络对 lip movements 的敏感性。这个细节解释了 AniPortrait 为什么强调 PoseGuider 改造——嘴唇运动太细,如果只把 sparse landmarks 当输入层条件,很容易被扩散 backbone 淹没。#Wei-et-al.-2024
Lmk2Video 的输入是参考图像 \(I_{ref}\) 与 2D landmark sequence \(\mathcal{L}^{1:T}=(\mathbf{l}^{1},\ldots,\mathbf{l}^{T})\),输出是 portrait frame sequence \(\mathcal{I}^{1:T}=(\mathbf{I}^{1},\ldots,\mathbf{I}^{T})\)。这个模块要同时满足两个条件:运动必须跟 landmarks 对齐,外观必须保持参考图身份一致。#Wei-et-al.-2024
flowchart TD A["Audio"] --> B["wav2vec / wav2vec2.0 features"] B --> C["Audio2Mesh: 3D facial mesh"] B --> D["Audio2Pose: 6D head pose"] C --> E["Perspective projection"] D --> E E --> F["2D facial landmark sequence"] G["Reference portrait image"] --> H["ReferenceNet / CLIP image encoder"] F --> I["Multi-scale PoseGuider"] H --> J["SD1.5 denoising UNet + motion module"] I --> J J --> K["Temporally consistent portrait video"]
扩散骨架来自哪里
AniPortrait 的视频生成部分借鉴 AnimateAnyone:使用 Stable Diffusion 1.5 作为 backbone,ReferenceNet 提取参考图 appearance information,temporal motion module 将 multi-frame noise 转成视频帧序列。这个组合的好处是把“画得像不像”和“动得连不连贯”分开:ReferenceNet 负责身份与外观一致性,motion module 负责跨帧时间一致性。#Wei-et-al.-2024 #Rombach-et-al.-2022 #Hu-et-al.-2023 #Guo-et-al.-2023
PoseGuider 的关键改造
论文明确指出,AnimateAnyone 原版 PoseGuider 只是几层卷积,并在 backbone 输入层合并 pose features;这种设计不足以捕捉复杂唇动。AniPortrait 因此采用类似 ControlNet 的 multi-scale strategy,把 landmark features 注入 backbone 的不同尺度 block,同时额外输入 reference image landmarks,并通过 cross-attention 建模 reference landmarks 与 target landmarks 的关系。#Wei-et-al.-2024 #Zhang-et-al.-2023-ControlNet
官方源码进一步支持这个说法。src/models/pose_guider.py 中的 PoseGuider.forward(x, ref_x) 会把 target pose sequence reshape 成 video batch,依次经过多组卷积下采样,收集多个尺度的 feature maps;当 use_ca=True 时,每个尺度都用 cross_attn 将 target pose features 与 reference pose features 交互,最后返回多尺度 fea 列表。src/pipelines/pipeline_pose2vid_long.py 则准备 pose_cond_tensor 和 ref_pose_tensor,调用 pose_guider(pose_cond_input, ref_pose_tensor),并把 pose_cond_fea 传给 denoising_unet。#AniPortrait-PoseGuider-Code #AniPortrait-Pose2VideoPipeline-Code
PoseGuider.forward(x, ref_x) 的双输入接口;它不是把参考 landmark 拼到第一层就结束,而是在多个尺度通过 cross-attention 反复对齐。AniPortrait 的训练可以分成 Audio2Lmk 与 Lmk2Video 两条线。Audio2Lmk 负责学“音频到 3D 运动”,Lmk2Video 负责学“2D landmark 到视频渲染”。论文 Fig.1 caption 说两个阶段在框架内 concurrently trained,但实现上训练目标和数据来源是分开的。#Wei-et-al.-2024
Audio2Lmk 训练
Audio2Lmk 使用 wav2vec2.0 作为 backbone,并用 MediaPipe 抽取 3D meshes 和 6D poses 作为监督。Audio2Mesh 的训练数据来自内部单说话人高质量语音数据,规模接近一小时;为了让 MediaPipe 抽取的 3D mesh 更稳定,演员被要求保持头部稳定并面向相机。Audio2Pose 则使用 HDTF 数据集训练。所有 Audio2Lmk 训练在单张 A100 上完成,优化器是 Adam,学习率为 \(1\times10^{-5}\)。#Wei-et-al.-2024 #Lugaresi-et-al.-2019 #Zhang-et-al.-2021-HDTF
Lmk2Video 两阶段训练
Lmk2Video 采用两步训练。第一步训练 backbone 的 2D component、ReferenceNet 和 PoseGuider,但不训练 motion module;第二步冻结其他组件,只训练 motion module。训练数据来自 VFHQ 与 CelebV-HQ 两个大规模高质量人脸视频数据集,全部视频用 MediaPipe 处理以抽取 2D facial landmarks,所有图像 resize 到 \(512\times512\)。论文披露 Lmk2Video 使用 4 张 A100,每一步训练 2 天,AdamW 优化器,学习率同样是 \(1\times10^{-5}\)。#Wei-et-al.-2024 #Xie-et-al.-2022-VFHQ #Zhu-et-al.-2022-CelebV-HQ
官方仓库的训练说明与配置让这条训练线更具体:README 要求先下载 VFHQ 和 CelebV-HQ,运行 scripts.preprocess_dataset 提取 keypoints 并生成 training json;Stage 1 命令是 accelerate launch train_stage_1.py --config ./configs/train/stage1.yaml,Stage 2 需要放入 AnimateDiff 的 mm_sd_v15_v2.ckpt,再运行 train_stage_2.py。配置文件显示 Stage 1 使用 sample_n_frames: 16、sample_stride: 4、train_bs: 2、max_train_steps: 300000;Stage 2 使用 sample_stride: 1、train_bs: 1、gradient_checkpointing: True、max_train_steps: 40000,并从 Stage 1 checkpoint 继续。#AniPortrait-README #AniPortrait-Training-Configs
| 配置项 | 披露状态 | 论文 / 官方代码中的信息 | 影响 |
|---|---|---|---|
| Audio2Mesh 数据 | 部分披露 | 内部单说话人高质量语音,近 1 小时 | 可复现性受限,外部无法完全复刻 mesh 监督数据 |
| Audio2Pose 数据 | 披露 | HDTF | 可替换复现,但具体划分未披露 |
| Lmk2Video 数据 | 披露 | VFHQ + CelebV-HQ,经 MediaPipe 提 2D landmarks | 数据源清楚,但清洗策略未完整披露 |
| 分辨率 | 披露 | 所有图像 resize 到 512×512 | 决定训练显存与最终细节上限 |
| Audio2Lmk 硬件 | 披露 | 单张 A100 | 训练门槛较低 |
| Lmk2Video 硬件 / 时间 | 披露 | 4×A100,每个阶段 2 天 | 主体成本在视频扩散训练 |
| 优化器 / 学习率 | 披露 | Audio2Lmk: Adam, 1e-5;Lmk2Video: AdamW, 1e-5 | 核心超参数可复现 |
| Batch size | 代码披露 | stage1 train_bs=2;stage2 train_bs=1 | 论文未写,但官方配置可查 |
| 训练步数 | 代码披露 | stage1 300000;stage2 40000 | 论文只写训练天数,代码补充步数 |
| CPU / 内存 | 未披露 | 论文与 README 未说明 | 大规模视频预处理成本难估计 |
| 推理耗时 | 未完整披露 | README 提供 -acc frame interpolation 加速,但没有标准耗时 | 产品实时性无法从论文直接判断 |
| 定量指标 / 消融 | 未披露 | 论文主要给定性结果图 | 难以判断每个模块的独立贡献 |
官方 GitHub 项目页给出了三类推理入口:self driven 的 pose2vid,face reenactment 的 vid2vid,以及 audio driven 的 audio2vid。其中 audio-driven 命令是 python -m scripts.audio2vid --config ./configs/prompts/animation_audio.yaml -W 512 -H 512 -acc;README 还说明可以用 -L 设置生成帧数,例如 -L 300,并可通过 film_net_fp16.pt 与 -acc 开启 frame interpolation 加速。#AniPortrait-GitHub #AniPortrait-README
Audio-driven 推理步骤
从官方 audio2vid.py 看,推理链路非常清晰。第一步加载基础模型:VAE、ReferenceNet、带 motion module 的 3D denoising UNet、PoseGuider、CLIP image encoder、Audio2Mesh 与 Audio2Pose。第二步对参考图做人脸 landmark 抽取,得到 ref_pose。第三步准备 wav2vec audio features,Audio2Mesh 预测 3D mesh offsets 并加到参考 3D landmarks 上。第四步生成 head pose:如果配置里有 pose_temp,就复用模板并镜像平铺;否则调用 Audio2Pose 分块预测,代码里当前按 5 秒 chunk 处理,并对 pose sequence 做 smooth。第五步把 3D mesh 与 pose 投影为 2D landmark images。第六步将 reference image、pose images、reference pose 和采样参数送进 Pose2VideoPipeline 进行扩散去噪生成。#AniPortrait-Audio2Vid-Code
Pose2VideoPipeline 内部又做了两件关键事。首先,ReferenceNet 在第一个 denoising step 读取 reference image latents,并通过 ReferenceAttentionControl 写入 appearance attention;随后 denoising UNet 以 read 模式读取这些 reference states。其次,pipeline 将每帧 pose image 预处理为 pose_cond_tensor,把 reference pose image 处理为 ref_pose_tensor,再由 PoseGuider 输出多尺度 pose_cond_fea,传给 denoising UNet。也就是说,推理阶段并不是简单“landmarks 拼进输入图”,而是 reference appearance 与 pose condition 两条控制流共同约束去噪过程。#AniPortrait-Pose2VideoPipeline-Code
可控性来自哪里
AniPortrait 的可控性主要来自两个位置:一是 3D intermediate representation 可以被编辑、替换或平滑;二是 2D landmark sequence 可以来自音频预测,也可以来自视频抽取。论文结果部分提到,可以从 source 中抽取 landmarks 并改变 ID,从而实现 face reenactment。官方 README 也给出 vid2pose 与 vid2vid 命令,说明项目确实把“先得到 pose / landmark,再驱动参考身份”作为统一接口。#Wei-et-al.-2024 #AniPortrait-README
论文实验部分非常短,主要展示生成样例。作者声称 AniPortrait 在 facial naturalness、pose diversity 和 visual quality 上表现更好,但正文没有提供常见的定量指标表、用户研究表或系统性 baseline 对比表。因此,这篇论文的证据强度更接近“方法展示 + 官方开源复现入口”,而不是完整 benchmark 论文。#Wei-et-al.-2024

已披露的实验信息
已披露的实现信息集中在训练资源与数据处理上:Audio2Lmk 使用 MediaPipe 生成 3D mesh 和 6D pose 标注;Audio2Mesh 用近一小时内部单说话人数据,Audio2Pose 用 HDTF;Lmk2Video 用 VFHQ 与 CelebV-HQ,图像统一为 512×512,4×A100 每阶段训练两天。官方仓库进一步披露了训练命令、配置文件、预训练权重组织方式和推理命令。#Wei-et-al.-2024 #AniPortrait-README #AniPortrait-Training-Configs
未披露与风险点
最大缺口是没有定量评测和消融。比如 PoseGuider 多尺度注入到底比原版几层卷积提升多少,reference landmark cross-attention 对嘴形和身份一致性的贡献多大,Audio2Pose 对自然头动贡献多少,论文都没有给出数字。其次,内部 Audio2Mesh 数据不可获得,且论文没有披露 CPU/内存、推理耗时、视频长度上限的系统评测。官方代码中 audio-driven inference 注释写到“Currently, only inference up to a maximum length of 10 seconds is supported”,这类工程限制需要读代码才能发现。#AniPortrait-Audio2Vid-Code
论文自己也承认局限:依赖 3D intermediate representations 意味着需要高质量 3D 数据,而大规模获取这类数据成本很高;最终生成的 facial expressions 与 head postures 仍然不能完全逃离 uncanny valley。作者未来工作指向 EMO 式直接从 audio 预测 portrait video 的路线,希望减少中间表示带来的上限。#Wei-et-al.-2024 #Tian-et-al.-2024
AniPortrait 的价值不在于提出一个复杂理论,而在于给出一条清楚的工程路线:用语音模型预测可控的 3D 运动,用 2D landmarks 作为跨模态中间接口,再用成熟扩散视频生成器做高质量渲染。这条路线特别适合需要编辑、复刻、换身份的数字人场景,因为 motion 与 appearance 被拆开了。#Wei-et-al.-2024
但如果目标是端到端情感表达、强泛化和低成本数据构建,AniPortrait 的中间表示路线也会显得笨重。它需要 MediaPipe 标注、内部高质量语音数据、HDTF/VFHQ/CelebV-HQ,以及多阶段训练。对工程复现者来说,最现实的策略不是盲目重训全套系统,而是先复用官方权重和 audio2vid / pose2vid 推理链路,观察自己的目标人像、语音长度、头动模板和 landmark 质量是否稳定;只有当 PoseGuider 或 motion module 明显不适配业务域时,再考虑针对性微调。
复习速查
- 核心结构:Audio2Lmk 预测 3D mesh + 6D pose;Lmk2Video 用 landmarks 控制扩散视频生成。
- 关键创新:多尺度 PoseGuider + reference landmarks cross-attention,加强细粒度嘴唇运动控制。
- 训练重点:Audio2Lmk 与 Lmk2Video 分开训练;Lmk2Video 再分 Stage 1 和 Stage 2。
- 最大风险:论文缺少定量对比/消融,内部 3D 数据不可复现,推理时长与长视频稳定性未完整披露。
参考来源
- Wei, H., Yang, Z., Wang, Z. (2024). AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. arXiv. arXiv:2403.17694
- Zejun-Yang/AniPortrait. Official GitHub repository. GitHub
- Zejun-Yang/AniPortrait README. Installation, weights, inference and training commands. README.md
- Zejun-Yang/AniPortrait.
scripts/audio2vid.py, official audio-driven inference implementation. audio2vid.py - Zejun-Yang/AniPortrait.
src/models/pose_guider.py, multi-scale PoseGuider implementation. pose_guider.py - Zejun-Yang/AniPortrait.
src/pipelines/pipeline_pose2vid_long.py, ReferenceNet and PoseGuider diffusion pipeline. pipeline_pose2vid_long.py - Zejun-Yang/AniPortrait. Stage 1 / Stage 2 training configuration files. configs/train
- Baevski, A. et al. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. NeurIPS. arXiv:2006.11477
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR. arXiv:2112.10752
- Guo, Y. et al. (2023). AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning. arXiv. arXiv:2307.04725
- Hu, L. et al. (2023). Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation. arXiv. arXiv:2311.17117
- Zhang, L., Rao, A., Agrawala, M. (2023). Adding Conditional Control to Text-to-Image Diffusion Models. ICCV. arXiv:2302.05543
- Lugaresi, C. et al. (2019). MediaPipe: A Framework for Building Perception Pipelines. arXiv. arXiv:1906.08172
- Zhang, Z., Li, L., Ding, Y., Fan, C. (2021). Flow-Guided One-Shot Talking Face Generation with a High-Resolution Audio-Visual Dataset. CVPR. HDTF / arXiv
- Xie, L. et al. (2022). VFHQ: A High-Quality Dataset and Benchmark for Video Face Super-Resolution. CVPR. Project page
- Zhu, H. et al. (2022). CelebV-HQ: A Large-Scale Video Facial Attributes Dataset. ECCV. GitHub
- Tian, L., Wang, Q., Zhang, B., Bo, L. (2024). EMO: Emote Portrait Alive. arXiv. arXiv:2402.17485
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS. arXiv:1706.03762