U-Net
如果只看今天的深度学习教材,U-Net 很容易被一句话概括成“encoder-decoder 加 skip connection”。这个说法没有错,但太浅了。U-Net 真正重要的地方,是它在 2015 年把三个医学图像分割的老问题放进同一个系统里解决:标注很少、边界很细、图像很大。论文开头就指出,当时大家普遍认为训练深网络需要成千上万张标注样本;但在显微图像和医学图像里,逐像素标注往往需要专家完成,数据规模远达不到 ImageNet 式监督学习的条件。#Ronneberger-et-al.-2015-UNet
这篇论文要解决的任务不是图像级分类,而是 dense prediction:给输入图像中的每个像素分配类别。医学图像里的像素级错误也不只是“错几个点”那么简单。细胞之间一条很窄的背景边界如果被抹掉,两个实例就会被连成一个;神经膜分割里一处断裂,后续拓扑和追踪都可能错。也就是说,U-Net 关心的不是抽象语义标签,而是要在有限标注下保住局部结构。
从历史位置看,U-Net 站在 FCN 之后。FCN 已经证明分类网络可以改成全卷积网络,直接输出像素级预测;U-Net 继承了这个 fully convolutional 思想,但把它改造成更适合小样本、强边界和大图推理的形态。#Long-et-al.-2015-FCN #Ronneberger-et-al.-2015-UNet
U-Net 论文直接对比的强基线,是 Ciresan 等人在 EM 神经膜分割中使用的 sliding-window CNN。它的思路很直观:围绕每个待分类像素取一个 patch,把 patch 输入 CNN,预测中心像素属于什么类别。这个方法在 ISBI 2012 EM segmentation challenge 中很强,说明 CNN 确实能学到显微图像里的局部纹理和边界模式。#Ciresan-et-al.-2012-EMSegmentation
但滑窗方法有两个结构性缺陷。第一是慢:相邻像素的 patch 大量重叠,却要反复做相似的卷积计算。第二是上下文与定位的冲突:patch 太小,网络看不到足够上下文;patch 太大,又需要更多 pooling 或更大计算量,定位精度和效率都会受影响。U-Net 的第一步,就是把逐像素 patch 分类改成一次前向传播输出一片 segmentation map。
| 方法 | 优势 | 关键短板 | U-Net 的改造 |
|---|---|---|---|
| Sliding-window CNN | 局部 patch 分类直接,能利用 CNN 纹理特征 | 重叠 patch 计算冗余;上下文与定位难兼顾 | 改为 tile-level fully convolutional dense prediction |
| FCN | 端到端像素级输出,共享卷积计算 | 主要面向自然图像语义分割;医学小样本和接触边界不是核心设计目标 | 加入对称 decoder、skip concatenation、elastic augmentation 与边界权重 |
| U-Net | 上下文、定位、少样本训练、大图推理一起处理 | 原文 2D 为主;大量工程超参数未披露;缺系统消融 | 成为后续医学分割模型的起点而非终点 |
一个自然的问题是:既然 FCN 已经可以做 dense prediction,为什么还需要 U-Net?答案在 decoder 的容量和跨尺度融合。U-Net 不只是把深层特征上采样回原图尺寸,而是在上采样路径中保留大量 feature channels,并在每个尺度拼接对应的 encoder feature map。这样,网络既能利用深层上下文判断“这是什么”,又能用浅层高分辨率特征回答“边界在哪里”。#Long-et-al.-2015-FCN #Ronneberger-et-al.-2015-UNet
U-Net 的左半边叫 contracting path,右半边叫 expansive path。左边反复执行两次 \(3\times3\) unpadded convolution + ReLU,再接 \(2\times2\) max pooling;每次下采样后,feature channels 翻倍。它的工作像传统分类 CNN:逐渐降低空间分辨率,扩大感受野,让高层特征看到更大的上下文。#Ronneberger-et-al.-2015-UNet
右边则反过来:每一步先上采样,再用 \(2\times2\) up-convolution 将通道数减半,然后把左边对应尺度的 feature map 裁剪后拼接过来,接两次 \(3\times3\) convolution + ReLU。最后用 \(1\times1\) convolution 把 64 维 feature vector 映射到目标类别。论文明确说整个网络有 23 个 convolutional layers。#Ronneberger-et-al.-2015-UNet
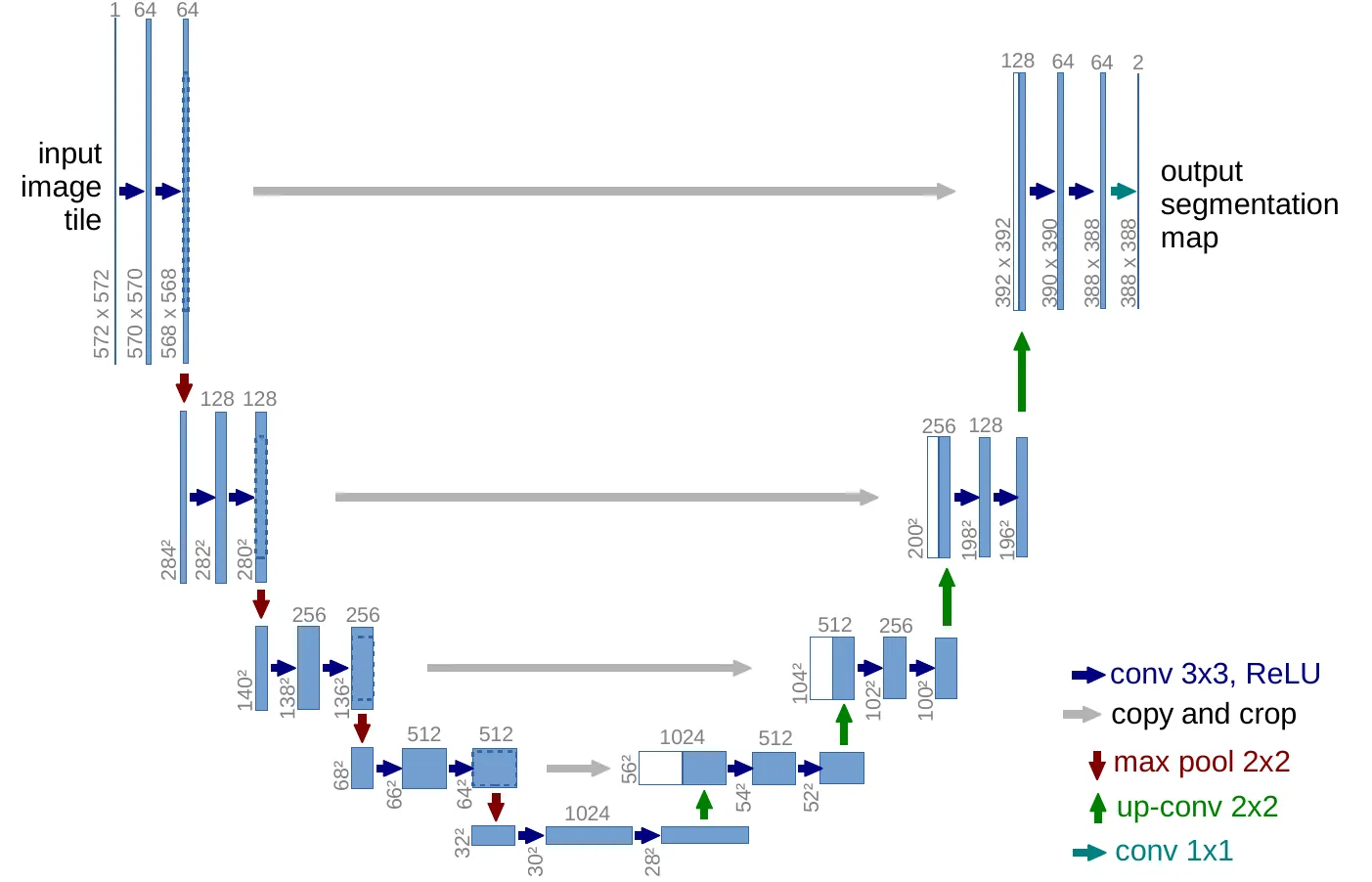
这里最容易被忽略的是“裁剪”。U-Net 使用 valid convolution,也就是不在输入边界补零。因此每做一次 \(3\times3\) 卷积,feature map 的边界都会缩小。decoder 中的上采样特征和 encoder 中的高分辨率特征尺寸并不天然相同,必须把 encoder feature map 裁剪到对齐后再 concatenation。这个选择比 padding 麻烦,却让输出像素都基于完整上下文,而不是依赖人工填充的边界值。
U-Net 的跨尺度融合
可以把第 \(l\) 层的 decoder 融合理解为:先把上采样语义特征 \(U_l\) 与裁剪后的 encoder 定位特征 \(crop(F_l)\) 拼接,再由后续卷积学习融合函数。
其中 \([\cdot,\cdot]\) 表示通道维拼接。它不要求浅层和深层特征逐通道相加,而是保留两路信息,让卷积自己学习哪些边界、纹理和语义上下文应该被保留。
这个设计解决的不是“如何把图像变回原大小”这么简单,而是重新分工:contracting path 负责理解局部区域在更大上下文里的意义;expansive path 负责把这个意义变成像素级输出;skip concatenation 负责把高分辨率定位信息送回决策层。医学图像分割之所以需要这种结构,是因为很多错误都发生在边界:只靠深层语义,边界会糊;只靠浅层纹理,又容易把噪声当边界。
U-Net 的训练从图像和 ground-truth segmentation map 开始。由于医学图像标注少,论文没有寄希望于大 batch 或大数据,而是把显存优先用于大 input tile。因为 valid convolution 会让输出小于输入,如果 tile 太小,边界开销占比会很高;作者因此把 batch size 降到单张图像,并使用很高的 momentum,数值为 0.99,来稳定 noisy update。#Ronneberger-et-al.-2015-UNet
flowchart TD
A["少量标注显微图像"] --> B["同步增强图像与标签"]
B --> C["Elastic deformation / rotation / shift / gray variation"]
C --> D["U-Net forward: tile to segmentation map"]
D --> E["Pixel-wise softmax"]
E --> F["Weighted cross entropy"]
G["Ground truth instance borders"] --> H["Class balance + border-aware weight map"]
H --> F
F --> I["Caffe SGD, batch size 1, momentum 0.99"]论文的第一个核心公式是逐像素 softmax。对输出区域 \(\Omega\) 中的每个像素 \(\mathbf{x}\),网络把每个类别通道的 activation 转成概率:
其中 \(a_k(\mathbf{x})\) 是像素 \(\mathbf{x}\) 上第 \(k\) 个类别通道的 activation,\(K\) 是类别数。
更关键的是 weighted loss。论文希望网络不仅把前景和背景分开,还要特别重视 touching cells 中间那条很窄的背景分隔线。原文给出能量函数:
按常见最小化 cross entropy 写法,这里机制上可理解为加权负对数似然;需要注意,原文公式本身没有显式写负号。权重图定义为:
这里 \(w_c\) 平衡类别频率,\(d_1\) 和 \(d_2\) 分别是到最近和第二近 cell border 的距离。论文设置 \(w_0=10\),\(\sigma\approx5\) pixels。当一个背景像素夹在两个细胞之间时,它离两个 cell border 都近,\(d_1+d_2\) 小,指数项就大,网络会更用力学习这条分隔边界。
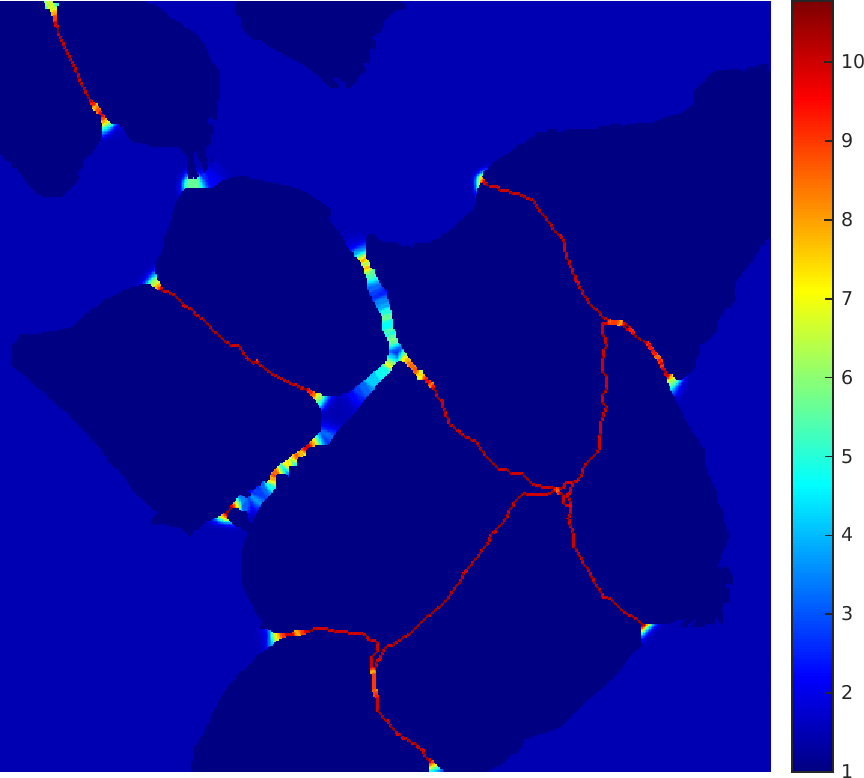
数据增强是另一个关键先验。论文特别强调 random elastic deformation:在 \(3\times3\) coarse grid 上采样随机 displacement vectors,位移来自标准差 10 pixels 的 Gaussian distribution,再用 bicubic interpolation 得到逐像素位移场。这个选择非常医学图像化:细胞和组织形态本来就有非刚性变化,弹性形变比普通平移、旋转更像真实分布。#Dosovitskiy-et-al.-2014-ExemplarCNN #Ronneberger-et-al.-2015-UNet
| 项目 | 论文披露 | 说明 |
|---|---|---|
| 框架/优化 | Caffe SGD | 官方实现基于 Caffe |
| Batch size | 1 image | 优先使用大 tile 而非大 batch |
| Momentum | 0.99 | 缓解 batch size 1 的 noisy update |
| Elastic deformation | \(3\times3\) grid, Gaussian std 10 pixels, bicubic interpolation | 小样本训练的核心增强 |
| Weight map | \(w_0=10\), \(\sigma\approx5\) pixels | 强调 touching cells 的分隔边界 |
| 训练成本 | Nvidia Titan 6GB, about 10 hours | 论文结论披露 |
| 论文与官方页面未列出 | learning rate, schedule, weight decay, dropout rate, epochs/iterations, FLOPs | 本文不臆造这些数值;严格复现实验时应以官方 release 包内配置为准 |
推理时,U-Net 不是对每个像素取 patch,也不是强行把整张大图塞进 GPU。它把图像切成重叠 tiles,每个 tile 输入网络后,只取中间那块有完整上下文的有效输出,再把所有有效输出拼起来。这个流程叫 overlap-tile strategy。#Ronneberger-et-al.-2015-UNet
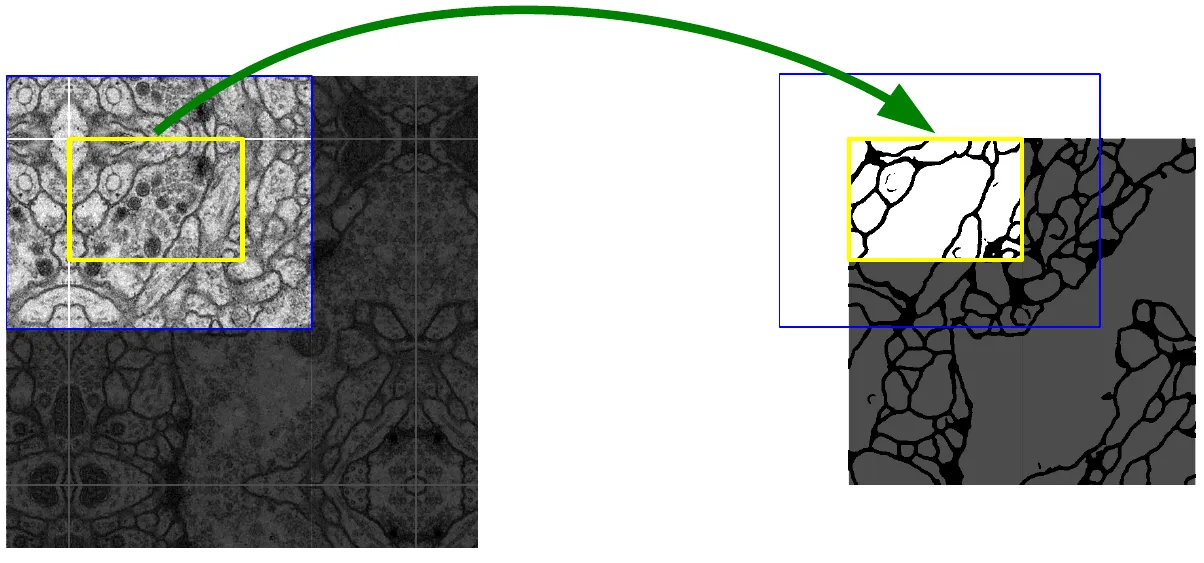
为什么要这么麻烦?原因仍然是 valid convolution。U-Net 不希望边界像素依赖 zero padding 这种人工上下文,所以输出只保留网络真正看完整输入上下文的位置。大图最外侧没有真实像素,论文用 mirroring extrapolation,也就是镜像图像边缘来补足上下文。相比补零,镜像更符合局部连续性,不容易制造黑边伪影。
Overlap-tile 推理链路
- 把大图切成互相重叠的输入 tile。
- 对每个 tile 执行 U-Net 前向传播。
- 只取每个 tile 的中心有效输出区域。
- 将有效区域无缝拼接成整图 segmentation map。
- 图像边界处使用 mirror extrapolation 补足缺失上下文。
论文还提醒输入 tile 尺寸必须让所有 \(2\times2\) max-pooling 都作用在偶数 x/y 尺寸上。这个细节看似琐碎,实际关系到 encoder-decoder 的网格对齐:某一级尺寸如果是奇数,下采样、上采样和 crop concat 就容易出现一两个像素的错位。
官方页面补充了工程形态:U-Net release 包包含 trained network、source code、modified Caffe Matlab binaries、overlap-tile segmentation 的 Matlab interface,以及用于 ISBI Cell Tracking submission 的 greedy tracking algorithm;测试环境是 Ubuntu Linux 14.04 与 Matlab 2014b x64。#Freiburg-UNet-Official 这说明 U-Net 原文里的“分割网络”和 cell tracking 提交里的完整系统不是一回事:后者还包含分割后的 tracking 流程。
U-Net 的第一个核心实验是 ISBI 2012 EM segmentation challenge。数据是 Drosophila first instar larva ventral nerve cord 的 serial section transmission EM;训练集只有 30 张 \(512\times512\) 图像,测试标签由组织方隐藏。论文报告 U-Net 对 7 个 rotated versions 的输入取平均,在没有额外 pre/postprocessing 的情况下达到 warping error 0.0003529、Rand error 0.0382。#Ronneberger-et-al.-2015-UNet
| 方法 | Warping Error ↓ | Rand Error ↓ | Pixel Error ↓ | 解读 |
|---|---|---|---|---|
| Human values | 0.000005 | 0.0021 | 0.0010 | 人类标注一致性上限参考 |
| U-Net | 0.000353 | 0.0382 | 0.0611 | 按 warping error 排名第一 |
| DIVE-SCI | 0.000355 | 0.0305 | 0.0584 | 非常接近 U-Net |
| IDSIA / Ciresan | 0.000420 | 0.0504 | 0.0613 | sliding-window CNN prior best |
| IDSIA-SCI | 0.000653 | 0.0189 | 0.1027 | Rand error 更低但 warping error 较差 |
这张表要谨慎解读。U-Net 不是每个指标都第一:IDSIA-SCI 的 Rand error 更低,DIVE 的 pixel error 也略好。论文强调的是 warping error 的新最佳,以及不依赖 dataset-specific 后处理仍能取得强结果。这个细节很重要,因为它说明 U-Net 的优势更接近“泛化的分割 pipeline”,而不是为某个 benchmark 写死的后处理技巧。
第二组实验是 ISBI Cell Tracking Challenge 2015 中两个 transmitted light microscopy 数据集:PhC-U373 与 DIC-HeLa。PhC-U373 有 35 张 partially annotated training images,DIC-HeLa 只有 20 张。U-Net 在 PhC-U373 上 IOU 为 0.9203,在 DIC-HeLa 上 IOU 为 0.7756,显著高于 2015 second-best 的 0.83 和 0.46。#Ronneberger-et-al.-2015-UNet #Freiburg-UNet-Official
| 方法 | PhC-U373 IOU ↑ | DIC-HeLa IOU ↑ | 说明 |
|---|---|---|---|
| Second-best 2015 | 0.83 | 0.46 | 同期第二名 |
| U-Net | 0.9203 | 0.7756 | 两个类别都大幅领先 |
论文没有系统消融
原文没有报告去掉 skip concatenation、elastic deformation、weighted loss、overlap-tile 或 dropout 后的掉点。因此正式解读只能说这些组件在机制上共同构成 U-Net pipeline,不能编造某个模块带来多少百分点提升。
U-Net 后来成为医学图像分割的默认起点,是因为它给出了一个可迁移的结构范式:下采样路径负责语义和上下文,上采样路径负责定位和生成,skip concatenation 负责跨尺度融合。后续 3D U-Net、V-Net、Attention U-Net、U-Net++、nnU-Net 等工作,基本都在这个范式上扩展:有的改 3D 体数据,有的加残差或注意力,有的把整个训练配置自动化。#Cicek-et-al.-2016-3DUNet #Isensee-et-al.-2021-nnUNet
但原始 U-Net 的适用边界也很清楚。第一,它主要验证的是 2D biomedical segmentation,不是 3D 体数据端到端建模。第二,它输出的是 segmentation map;Cell Tracking Challenge 的完整提交还包含 greedy tracking algorithm,不能把 tracking 全部归功于 U-Net 本身。第三,它依赖高质量 mask 和合理的数据增强。如果标注边界很粗糙,border-aware weight map 可能放大错误;如果目标形变不符合 elastic deformation 的建模前提,增强也可能引入偏差。
读完 U-Net 应该带走的 5 个判断
- 历史判断:U-Net 是 FCN 思想在少样本医学分割场景下的系统化改造。
- 结构判断:U 形结构的重点不是对称美观,而是上下文与定位的分工。
- 训练判断:少样本能力来自 elastic deformation、border-aware loss、大 tile 和高 momentum 等强先验组合。
- 推理判断:overlap-tile 与 mirroring 是 valid convolution 能处理大图的关键工程机制。
- 复现判断:原文和官方页面披露了核心架构、关键训练参数、发布包内容与运行环境;学习率、schedule、dropout rate、迭代数等没有出现在论文正文和官方页面中,本文不补写未经核验的数值。
对今天的研究者来说,U-Net 最值得学习的不是“把浅层特征 concat 到深层”,而是如何把任务约束写进模型 pipeline:医学图像标注少,就用符合形态学直觉的增强;细胞容易粘连,就在 loss 里强化分隔边界;图像太大,就用 overlap-tile 而不是牺牲上下文。好的架构往往不是单个模块的胜利,而是问题、数据、训练目标和工程边界之间的对齐。
论文与资料
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015 / arXiv:1505.04597.
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully Convolutional Networks for Semantic Segmentation. CVPR 2015.
- Ciresan, D. C., Giusti, A., Gambardella, L. M., & Schmidhuber, J. (2012). Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. NeurIPS 2012.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS 2012.
- Simonyan, K., & Zisserman, A. (2015). Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015.
- Dosovitskiy, A., Springenberg, J. T., Riedmiller, M., & Brox, T. (2014). Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks. arXiv:1406.6909.
- University of Freiburg LMB. U-Net official page and release package.
- Çiçek, Ö. et al. (2016). 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. MICCAI 2016.
- Isensee, F. et al. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods.