FLAP
过去两年,扩散式 audio-driven portrait animation 已经把唇形同步、面部表情和头部运动的自然度推高了很多。但 FLAP 指出,真实生产场景不只需要“这张脸自然地说话”,还需要“这张脸按脚本转头、抬头、点头、眨眼,且这些动作可以被人精确控制”。电影制作里,角色可能要先转向对话对象再开口;电商直播里,数字人可能要在介绍商品时按导演要求点头、看向屏幕某个方向或保持固定机位。论文把这个缺口概括为:现有方法自然度提升了,但 controllability 不足。#Mu-et-al.-2025
FLAP 选择的中间表示是 FLAME 风格的 3D head coefficients。这个选择非常关键:2D landmark 或 2D motion field 容易丢失 3D 姿态结构,而且常常和身份形状纠缠;纯 latent motion 又不一定可解释。FLAME 系数虽然来自传统 3DMM 路线,却有清楚的语义:全局头部旋转、眼睛、下颌、眼睑和表情 blendshape 都可以单独读写。FLAP 的核心主张是,把这些显式、可编辑、身份相对无关的参数作为扩散模型条件,就能在 end-to-end 视频生成质量和传统 3D 控制能力之间搭桥。#Li-et-al.-2017-FLAME #Mu-et-al.-2025
它和 VASA-1、LivePortrait 等工作的关系
FLAP 与 VASA-1 的对话最直接:两者都相信“先进入一个运动/头部表示空间,再生成视频”比直接在像素里盲目扩散更适合 talking head。不同点在于,VASA-1 生成 motion latent,并依赖 FaceVid2Vid / MegaPortrait 类 motion-to-video 模块渲染最终视频;FLAP 则把显式 3D head coefficients 直接作为扩散视频生成条件。作者认为这能避免 VASA-1 这类 FaceVid2Vid-backed 模型可能出现的 mean face / mean head 问题。需要注意的是,论文对 VASA-1 的附录比较主要基于公开论文/演示图,而不是复现实验,因为 VASA-1 未开源。#Xu-et-al.-2024-VASA #Mu-et-al.-2025
LivePortrait 则代表另一条工程化路线:用隐式关键点、stitching 和 retargeting 控制把肖像动画做得很快、很稳,但它通常需要驱动视频或明确运动来源。FLAP 的目标不是取代 LivePortrait 的高效推理范式,而是解决“没有驱动视频时,如何从音频自动生成运动;有控制需求时,又如何用角度/系数精确干预”的问题。#Guo-et-al.-2024 #Mu-et-al.-2025
EchoMimic、AniPortrait、Hallo、Hallo2 更接近扩散肖像动画主流。EchoMimic 和 AniPortrait 倾向于把 landmark / 2D motion field 作为控制条件;Hallo 系列强调层级音频视觉合成、长时高分辨率或额外文本指导。FLAP 对它们的批评集中在两点:一是 2D 条件损失 3D 结构、需要对齐且可能携带身份信息;二是许多端到端扩散模型不支持用户指定的细粒度控制。#Chen-et-al.-2024-EchoMimic #Wei-et-al.-2024-AniPortrait #Xu-et-al.-2024-Hallo #Cui-et-al.-2024-Hallo2 #Mu-et-al.-2025
FLAP 使用的 3D head condition 来自 FLAME。FLAME 将人脸建模为形状参数 \(\boldsymbol{\beta}\)、姿态参数 \(\boldsymbol{\theta}\) 和表情参数 \(\boldsymbol{\psi}\),输出 5023 个顶点和 9976 个面片的 3D mesh。FLAP 并不直接渲染这个 mesh,而是把其中可编辑的头部和表情系数拿来控制扩散视频模型。#Li-et-al.-2017-FLAME #Mu-et-al.-2025
FLAP 的 3D head condition
其中 \(\theta_{globalR}\) 是全局头部旋转,用于 head pose control;\(\theta_{eyes}\)、\(\theta_{jaw}\)、\(\psi_{eyelids}\) 和 \(\psi_{exp}\) 分别描述眼睛、下颌、眼睑和表情。论文实验实现中,头部条件维度分别披露为 3、12、3、2、100,总计 120 维。#Mu-et-al.-2025
从生成建模角度看,FLAP 仍然是 latent diffusion:训练时把加噪 latent、时间步和条件输入 denoising network,让网络预测噪声。区别在于,Stable Diffusion 原本最常见的条件是文本或图像 embedding;FLAP 的条件变成了逐帧 3D head coefficient sequence 与参考图编码。#Rombach-et-al.-2022 #Mu-et-al.-2025
条件扩散目标
这里 \(c_{ref}\) 来自 ReferenceNet,承载参考头像身份和外观;\(C_{3Dhead}=\{c_{3Dhead_1},\ldots,c_{3Dhead_n}\}\) 是每一帧的 3D 头部控制序列。DenoisingNet 的目标是生成同时匹配参考外观和 3D 头部运动/表情的视频帧。#Mu-et-al.-2025
pose / expression decoupling 的真正难点
FLAME 本身在参数语义上区分了 pose 与 expression,但训练视频里的系数来自单目重建,这会引入新的耦合:当一个人脸只露出左侧时,重建器很难准确估计右侧不可见区域,于是某些异常 expression coefficients 可能反过来暗示“头朝某个方向”。模型如果直接吃全部系数,就可能学到一条捷径:从 expression 里猜 pose。这样表面上训练损失下降了,真正推理时却无法独立控制表情和头姿。#Mu-et-al.-2025
这就是 FLAP 要提出 Progressively Focused Training 的原因。作者的直觉是,生成模型通常先学习全局结构,再学习局部细节;因此训练也应该先让模型专注头部全局运动,再学习表情细节,而不是把所有条件一次性灌进去。#Mu-et-al.-2025
Progressively Focused Training(PFT)把训练拆成三个阶段。第一阶段是 head motion stage:做 image training,所有层可训练,只提供 head motion condition 和 reference condition,强迫模型学习参考图与目标图之间的头部姿态变化。第二阶段是 expression stage:条件换成 \(c_{exp}=[\theta_{eyes},\theta_{jaw},\psi_{eyelids},\psi_{exp}]\),并冻结与 head motion 相关的 attention layers,避免 expression 条件继续泄漏或重写 pose。第三阶段是 video training:按近期 portrait diffusion 方法进入连续帧训练,学习时序一致性、唇动和视频自然度。#Mu-et-al.-2025
flowchart TD A["训练视频"] --> B["MICA-style tracker 拟合 FLAME coefficients"] B --> C["Stage 1: head motion image training"] C --> D["学习 global head rotation"] D --> E["Stage 2: expression image training"] E --> F["冻结 head-motion attention,学习 eyes/jaw/eyelids/expression"] F --> G["Stage 3: video training"] G --> H["ReferenceNet + DenoisingNet 条件视频生成"]

这张消融图是理解 FLAP 的关键证据。没有 PFT 时,模型能拟合训练样本的 pose 和 expression,但它是通过“错误的耦合线索”做到的:expression 里藏着 pose 信息。一旦把 expression 换成 idle expression,头部运动范围就缩水。使用 PFT 后,表达变化不再明显影响头部姿态,这说明模型学到的是更独立的控制通道。#Mu-et-al.-2025
FLAP 的训练流水线可以拆成四步。第一步,收集公开视频数据:论文披露使用 HDTF、CelebV-HQ 和 VFHQ,所有视频帧 resize 到 512×512。第二步,对训练视频进行人脸重建和 tracking:作者重实现 MICA 风格 tracker 来拟合 FLAME coefficients。第三步,按 head motion variance 过滤出头部运动系数方差 top 20% 的视频,用于 head motion stage,这一步训练 150,000 steps。第四步,对全部数据进行 expression stage 与 video stage,分别训练 150,000 steps 与 50,000 steps。#Mu-et-al.-2025
| 项目 | 披露状态 | 论文信息 | 影响 |
|---|---|---|---|
| 训练数据集 | 论文披露 | HDTF、CelebV-HQ、VFHQ | 覆盖 talking head / celebrity / high-quality face videos,但具体清洗规则未详述 |
| 分辨率 | 论文披露 | 512×512 | 与 SD/AnimateDiff 风格视频扩散设置一致 |
| 3D 系数拟合 | 论文披露 | 重实现 MICA tracker 拟合 FLAME coefficients | 拟合质量决定控制条件上限 |
| Head stage 数据筛选 | 论文披露 | head motion coefficient variance top 20% | 增强模型对大幅头动的学习 |
| 训练步数 | 论文披露 | 150k / 150k / 50k | 三阶段成本不均,前两阶段最重 |
| 初始化 | 论文披露 | Stable Diffusion 1.5 与 AnimateDiff 权重 | 复用图像/视频生成先验 |
| 优化器、学习率、batch size | 未披露 | 未披露 | 复现训练时需要额外试参 |
| GPU 型号与数量 | 未披露 | 未披露 | 无法估算完整训练成本 |
| 训练时长 | 未披露 | 未披露 | 无法评估工业可复现门槛 |
| 推理采样步数与速度 | 未披露 | 未披露 | 无法与实时系统直接比较 |
从训练设计看,FLAP 的核心成本不在一个神秘模块,而在把“可控条件”做干净:先从视频里拟合每帧 FLAME 系数,再让扩散模型分阶段学习头动、表情和视频时序。论文没有披露优化器、学习率、batch size、GPU 与训练时间,这是复现风险最高的部分。#Mu-et-al.-2025
推理时,FLAP 有两条输入线。第一条是身份/外观线:给定一张任意身份的 portrait image,ReferenceNet 输出 \(c_{ref}\),后续视频生成保持这个人的外观。第二条是运动/表情线:如果只有音频,Audio-to-FLAME 模块从 speech audio 生成逐帧 FLAME coefficients;如果用户有脚本控制,可以直接修改 head rotation angles,固定头姿,或叠加 turning、tilting、looking around、jerking 等动作;如果用户有外部图片或视频,也可以提取其 head/expression coefficients 作为驱动。#Mu-et-al.-2025
flowchart TD A["Reference portrait"] --> B["ReferenceNet"] --> C["c_ref"] D["Speech audio"] --> E["Audio-to-FLAME"] --> F["audio-generated FLAME sequence"] G["User control: angles / fixed pose / image-video coefficients"] --> H["modify or overlay coefficients"] F --> H H --> I["C_3Dhead"] C --> J["DenoisingNet"] I --> J J --> K["controllable talking-head video"]
Audio-to-FLAME 是 FLAP 推理链里最有意思的模块。许多扩散方法直接用 \(c=[c_{audio},c_{ref}]\) 训练 DenoisingNet,作者认为这会造成 reference-expression bias:参考图中的表情比音频更容易被模型利用,所以给一张笑脸参考图和一段愤怒语音,模型可能生成半笑半怒的混合表情。FLAP 让 Audio-to-FLAME 单独从音频生成表情与头动系数,再把这些系数喂给扩散模型,目的是让 expression 更依赖音频而不是参考图。#Wen-et-al.-2020 #Mu-et-al.-2025
这个设计还有一个额外好处:Audio-to-FLAME 模块是可替换的。论文指出,可以用 EmoTalk、EMOTE、DiffPoseTalk 等其它 FLAME coefficient generation 方法替换它,也可以引入 Audio-DVP 式 talking style 控制,让同一个 FLAP 视频生成器获得不同说话风格。换句话说,FLAP 把“如何从音频得到 3D 头部控制”与“如何把 3D 控制渲染成视频”拆开了。#Peng-et-al.-2023 #Danecek-et-al.-2023 #Sun-et-al.-2024 #Wen-et-al.-2020 #Mu-et-al.-2025
论文在 CelebV-Text 上随机采样 30 个视频做评估。音频驱动任务对比 SadTalker、EDTalk、EchoMimic、AniPortrait、Hallo、Hallo2;视频驱动任务对比 MCNet、EDTalk、EchoMimic、LivePortrait、X-Portrait。指标包括 FID、FVD、FaceIQA、Sync-C、Sync-D 和 H-IQA。#Mu-et-al.-2025
| 任务 | 方法 | FID↓ | FVD↓ | FaceIQA↑ | Sync-C↑ | Sync-D↓ | H-IQA↑ | 备注 |
|---|---|---|---|---|---|---|---|---|
| Audio-driven | FLAP | 136.54 | 399.78 | 0.6254 | 7.8617 | 8.2916 | 0.4592 | FID、FVD、Sync-C 最优;控制性 4★ |
| Audio-driven | AniPortrait | 137.27 | 581.01 | 0.6518 | 7.6117 | 8.3738 | 0.4920 | 视觉质量指标强,但控制性弱于 FLAP |
| Audio-driven | Hallo2 | 141.54 | 483.95 | 0.5993 | 7.7184 | 8.0047 | 0.4241 | Sync-D 最优 |
| Video-driven | FLAP | - | - | 0.6107 | 7.7837 | 9.8302 | 0.4644 | 只用 3D 系数驱动,而非完整 driving video |
| Video-driven | X-Portrait | - | - | 0.6544 | 5.8181 | 10.2428 | 0.4795 | 视觉强但 lip sync 弱 |
| Video-driven | EDTalk | - | - | 0.4159 | 8.4260 | 9.2331 | 0.3018 | 同步强但视觉质量弱 |
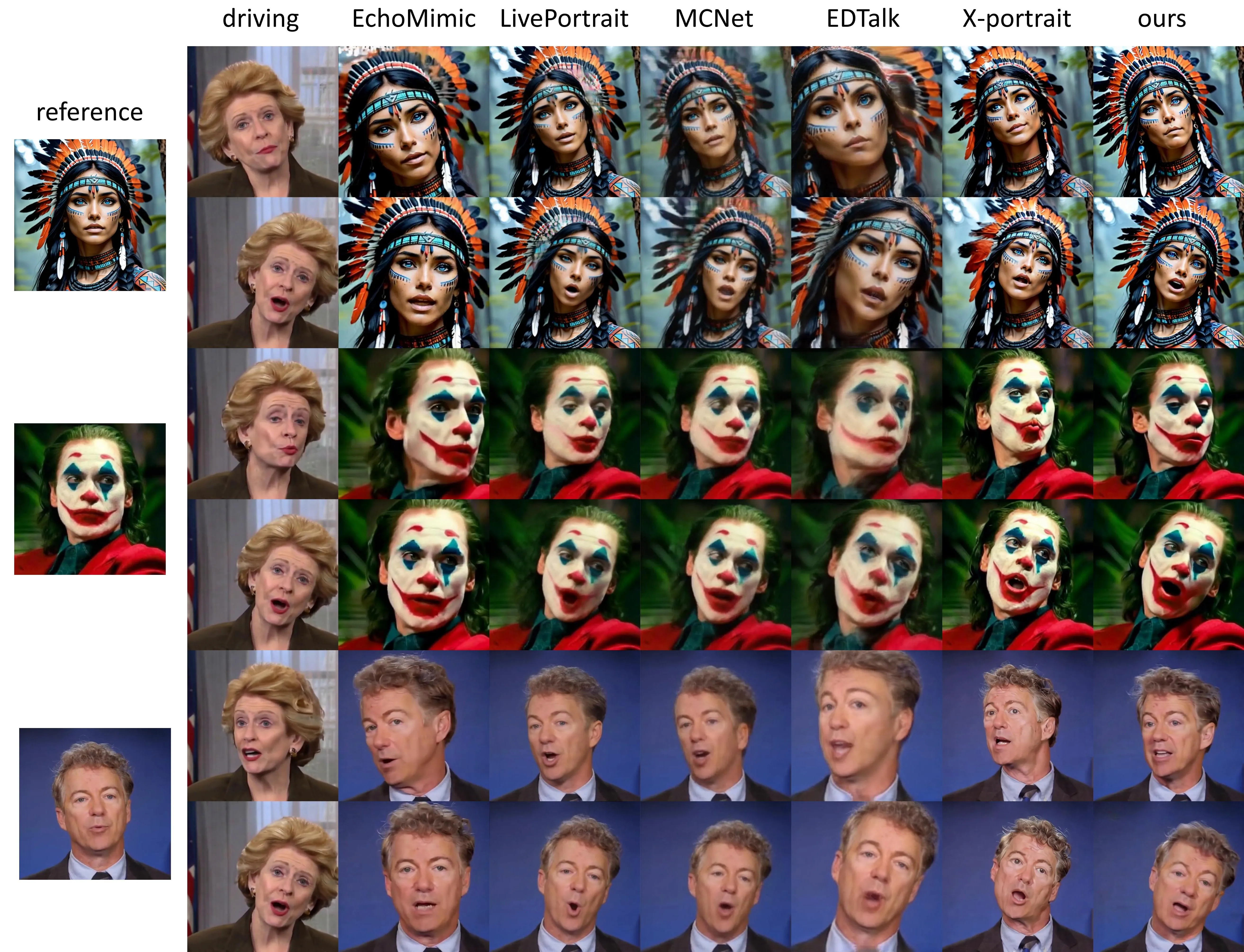
实验结论可以分两层读。第一层是指标:FLAP 在 audio-driven 表格中拿到最优 FID、FVD 和 Sync-C,说明它没有为了控制性显著牺牲生成质量和唇形同步。第二层是任务定义:FLAP 的可控性表格给到 4★,因为它同时支持 audio-driven、video-driven、pose/expression disentanglement 和角度级头姿控制;这一点比单个 FID 数字更能说明论文贡献。#Mu-et-al.-2025
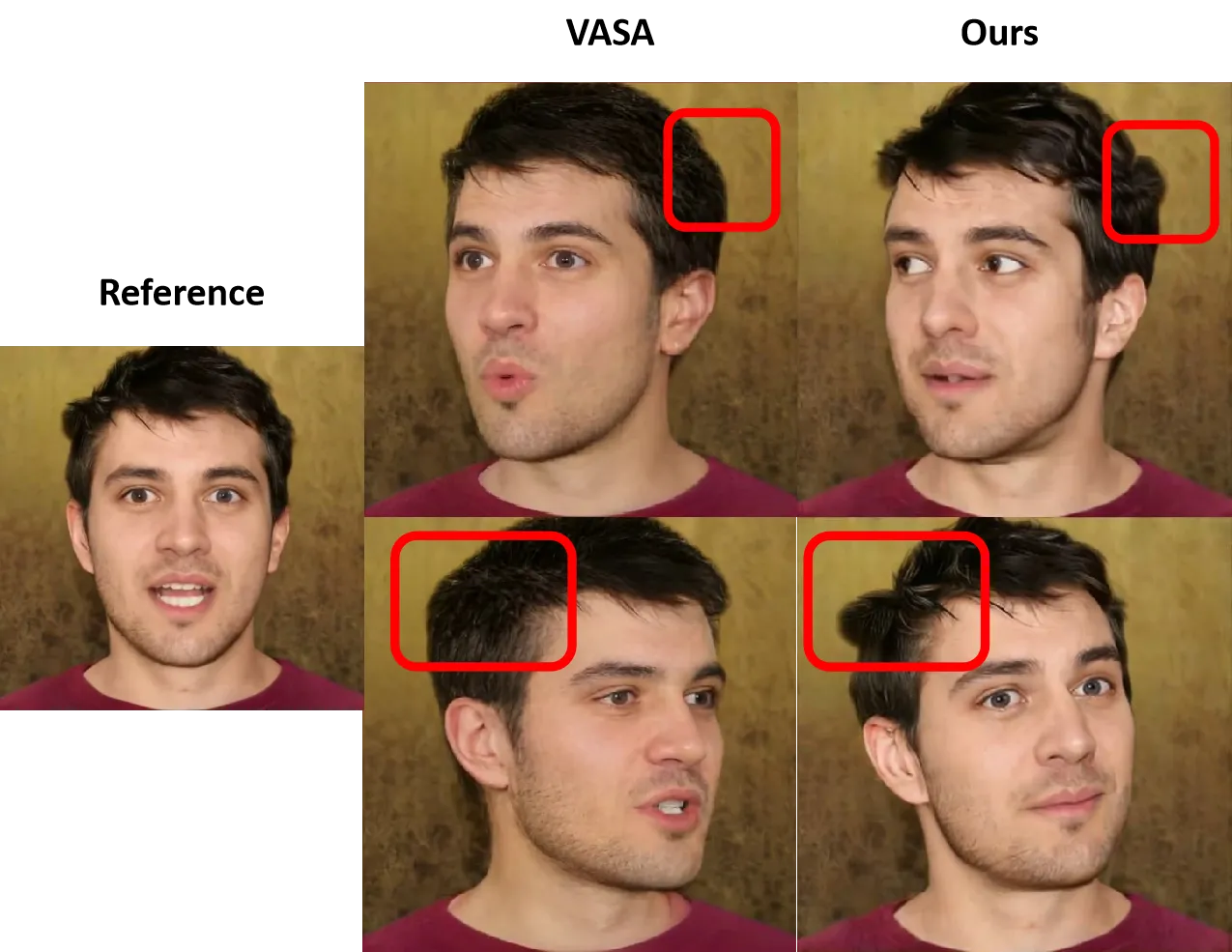
FLAP 的最大启发是:数字人可控生成不一定要在“传统 3D pipeline”和“端到端扩散”之间二选一。传统 3D head model 提供可解释、可编辑、可组合的控制坐标;扩散模型提供高质量视频生成能力。把两者接起来,就能得到既自然又可控的 talking head 系统。#Mu-et-al.-2025
但风险也很明确。第一,FLAP 依赖 FLAME fitting,单目拟合误差会直接污染控制条件,PFT 只能缓解泄漏,不能从根上消除所有重建错误。第二,Audio-to-FLAME 模块决定了音频到表情/头动的上游质量;如果音频情绪、韵律或说话风格预测错了,后面的扩散生成再强也只是忠实渲染错误控制。第三,论文 v1 没有披露代码、硬件、优化器、学习率、batch size、推理速度与采样步数,工业复现还缺关键信息。#Mu-et-al.-2025
复习速查
- FLAP 的核心变量:每帧 3D head coefficients,包含 head pose、eyes、jaw、eyelids 和 expression。
- 最重要训练策略:PFT,先学头部全局运动,再冻结相关层学习表情,最后视频训练。
- 与 VASA-1 的差异:VASA-1 偏 motion latent + motion-to-video renderer;FLAP 偏显式 3D head condition + diffusion generator。
- 与 LivePortrait 的差异:LivePortrait 强在工程速度和驱动视频重定向;FLAP 强在音频自动生成与角度/系数级用户控制。
- 与 EchoMimic / AniPortrait / Hallo 的差异:FLAP 不把 2D landmark 或弱音频条件作为主控制,而是把 3D 可编辑系数作为主条件。
参考来源
- Mu, L. & Liu, B. (2025). FLAP: Fully-controllable Audio-driven Portrait Video Generation through 3D head conditioned diffusion model. arXiv:2502.19455v1. arXiv HTML
- Li, T. et al. (2017). Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics. FLAME project
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. arXiv:2112.10752
- Xu, S. et al. (2024). VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time. NeurIPS 2024. arXiv:2404.10667
- Guo, J. et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv preprint. arXiv:2407.03168
- Chen, Z. et al. (2024). EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions. arXiv preprint. arXiv:2407.08136
- Wei, H. et al. (2024). AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. arXiv preprint. arXiv:2403.17694
- Xu, M. et al. (2024). Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation. arXiv preprint. arXiv:2406.08801
- Cui, J. et al. (2024). Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation. arXiv preprint. arXiv:2410.07718
- Wen, X. et al. (2020). Photo-realistic Audio-driven Video Portraits. IEEE Transactions on Multimedia. arXiv:2002.10137
- Peng, Z. et al. (2023). EmoTalk: Speech-Driven Emotional Disentanglement for 3D Face Animation. ICCV 2023. CVF Open Access
- Danecek, R. et al. (2023). Emotional Speech-Driven Animation with Content-Emotion Disentanglement. SIGGRAPH Asia 2023. Project page
- Sun, Z. et al. (2024). DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models. ACM TOG. arXiv:2310.00434