OmniAvatar
传统音频驱动数字人很容易把问题收缩到脸部:嘴型同步、头动、表情自然度。OmniAvatar 选择的是另一条路线:输入单张参考图、驱动音频和文本提示,输出带唇形同步、身体运动和场景控制的 avatar video。它把 avatar 放回视频生成大模型的 full-frame 空间里,而不是先裁出脸部再贴回去。
这个定位决定了 OmniAvatar 的优点和代价。优点是它可以继承 Wan2.1 的世界知识、构图、风格和文本可控性,让语音不只控制嘴,也影响半身、全身和场景中的动作。代价是它不是实时系统,论文也明确把 diffusion inference slow 作为限制;它更适合作为质量优先的 full-body/full-frame avatar baseline,而不是视频会议里的低延迟形象。#OmniAvatar-2025
为什么不能只做口型条件
如果音频只进入脸部模块,模型很容易得到“嘴同步、身体僵硬”的结果。OmniAvatar 的论文动机是:语音不仅包含 phoneme,也包含韵律、情绪、停顿和节奏,这些信息会影响手势、躯干和整体姿态。因此它需要把音频注入视频 latent 的空间层级,而不是只做 mouth ROI 或 face landmark control。#OmniAvatar-2025
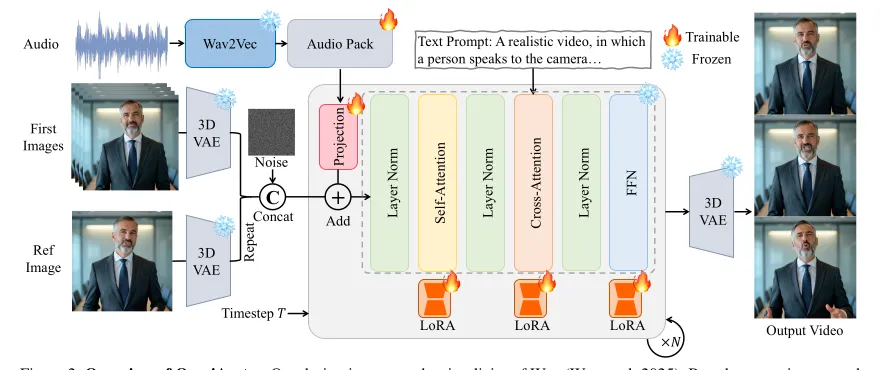
OmniAvatar 的第一件事是解决时间对齐。Wan2.1 的视频 latent 由 3D VAE 压缩,时间维有 factor 4;音频特征来自 Wav2Vec2,帧率和视频 latent 不一致。Audio Pack 先 padding、rearrange 音频特征,使其与压缩后的视频 latent frames 对齐,再用线性层映射到 audio latent。#OmniAvatar-2025
Pixel-wise multi-hierarchical embedding
OmniAvatar 将投影后的 audio latent 加入选定 DiT blocks 的 video latent 中,注入范围从第二层到中间层,并使用 unshared weights。这里的 pixel-wise 不是最终 RGB 像素,而是指视频 latent 的空间位置都能接收音频条件;multi-hierarchical 指不同深度的 DiT 层都能获得音频信号。#OmniAvatar-2025
这解释了 OmniAvatar 与很多口型同步模型的差异:音频不再只是局部嘴部条件,而是进入视频生成模型的中间表征。模型因此有机会把韵律映射到身体运动,把文本提示映射到场景和动作,把参考图嵌入映射到身份保持。
OmniAvatar 没有直接 full fine-tune Wan2.1。论文在 attention 和 FFN 层加入 LoRA,LoRA rank / alpha 为 128 / 64。这样做的核心原因不是简单省参数,而是避免全量训练破坏基础视频模型的 prompt controllability。对于 avatar 生成,文本提示仍要控制场景、动作、背景、情绪和人物姿态;如果全量训练把模型过度拉向音频同步任务,可能会牺牲这些通用能力。#OmniAvatar-2025

训练与推理配置
OmniAvatar 使用 AVSpeech 作为主要数据源,原始规模超过 4700 小时,经 SyncNet 和 Q-Align 过滤后得到 774,207 个样本,约 1320 小时,长度 3–20 秒。训练使用 64 张 A100 80GB,学习率 \(5\times10^{-5}\),最大 latent token 长度 30,000,audio CFG dropout 10%。推理时使用 25 个 denoising steps,audio/text CFG 为 4.5,并用 13 帧 overlap 改善长视频时序一致性。#OmniAvatar-2025
| 维度 | 论文披露配置 | 解释 |
|---|---|---|
| 基础模型 | Wan2.1-T2V-14B | 继承大视频模型的构图、风格和文本控制能力 |
| 音频特征 | Wav2Vec2 + Audio Pack | 解决音频帧与视频 latent 帧的时间对齐问题 |
| 适配方式 | attention / FFN LoRA,rank / alpha 为 128 / 64 | 加入音频驱动能力,同时减少破坏基础模型能力的风险 |
| 训练资源 | 64×A100 80GB,lr \(5\times10^{-5}\) | 质量优先路线,训练门槛显著高于轻量实时系统 |
| 推理配置 | 25 steps,audio/text CFG 4.5,13-frame overlap | 支持长视频一致性,但论文未给实时 FPS |
OmniAvatar 的训练/推理关键信息
OmniAvatar 在 talking-face 和 semi-body 两个设置上评估。Talking face 结果中,Ours 的 FID 为 66.5、FVD 为 692、Sync-C 为 6.32、Sync-D 为 8.38、IQA 为 2.63、ASE 为 1.51;Semi-body 结果中,Ours 的 FID 为 67.6、FVD 为 664、Sync-C 为 7.12、Sync-D 为 8.05、IQA 为 3.75、ASE 为 2.25。消融里 Frozen-DiT 的 Sync-C 为 4.26,Full-Training 为 5.58,LoRA+SHE 为 6.58,最终方法为 7.13。#OmniAvatar-2025

| 问题 | 可以怎么说 | 不能怎么说 |
|---|---|---|
| 身体运动 | 它比只做脸部同步的模型更重视半身/全身动作 | 不能说它提供严格可控的骨骼或 3D 姿态 |
| 情绪控制 | 它支持 prompt-based facial expression / emotion control | 不能说它像情绪参考迁移方法那样显式建模情绪源 |
| 多角色 | 它可生成复杂场景中的 avatar 视频 | 不能说它已解决多角色说话人区分;论文把复杂文本控制列为限制 |
| 实时性 | 它是质量优先的 diffusion avatar baseline | 不能说它是 realtime digital human 系统 |
OmniAvatar 的能力边界
这些边界很重要。OmniAvatar 的价值在于说明 full-frame video foundation model 可以通过音频 latent injection 变成 avatar generator,但它不是 3D 可渲染资产,也不是低延迟流式系统。它更接近“高质量生成式 avatar 基线”,为 InfiniteTalk、Live Avatar 等长视频或实时系统提供一个质量参照。
在 avatar 调研里,OmniAvatar 应该放入“full-frame / full-body 2D video foundation model route”。它与 EMO2 都把 avatar 从脸部扩展到身体,但 EMO2 的中间层是 MANO hand end-effector,OmniAvatar 的中间层是视频 latent 中的音频注入。它与 ChatAnyone 都追求上半身或身体运动,但 ChatAnyone 的路线是紧凑运动空间 + warping GAN 实时渲染,OmniAvatar 是大视频模型 + diffusion inference。它与 One Shot, One Talk 的差异更明显:后者更接近 3DGS/mesh asset,OmniAvatar 则是一次性生成 full-frame video。
| 方法 | 中间表示 | 输出形态 | 优势 | 短板 |
|---|---|---|---|---|
| OmniAvatar | audio latent injected into Wan2.1 video latent | full-frame avatar video | 文本控制、场景、身体运动与唇形同步统一建模 | 推理慢,多角色复杂控制仍难 |
| EMO2 | MANO hand motion + ReferenceNet | upper-body video | 手势 end-effector 思路清晰 | 非实时,非 3D asset |
| ChatAnyone | face/body keypoints + MANO injection | realtime upper-body portrait video | 30 FPS 级工程闭环 | 生成范围和画面自由度较小 |
| One Shot, One Talk | SMPL-X / mesh / 3DGS-like renderable representation | 可渲染 avatar asset | 几何和重用性更强 | 资产构建和注册成本更高 |
OmniAvatar 与相邻路线对比
读完这篇论文应记住什么
- 任务边界:OmniAvatar 是 full-frame audio-driven avatar generation,不是实时 talking head。
- 核心机制:Audio Pack 对齐音频与视频 latent,pixel-wise multi-hierarchical embedding 将音频注入 DiT 多层。
- 训练策略:LoRA 是为了适配音频驱动并保留 Wan2.1 的文本提示能力。
- 评估重点:除了 FID/FVD,也要看 Sync-C、Sync-D、IQA、ASE 以及提示控制案例。
参考来源
- OmniAvatar Authors (2025). OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation. arXiv:2506.18866