数字人论文精读(一):Wav2Lip,用唇形同步专家把任意视频精准对口型
本文属于「数字人系列」的论文精读支撑,在数字人系列(一):实时数字人生成 Survey中,我们从技术演进和应用场景梳理了数字人生成的完整图景。本文将聚焦于数字人生成的核心技术之一——音频驱动的唇形同步(Audio-driven Lip Sync),深入解读 Wav2Lip 这篇开创性论文。如果读者对唇形同步在数字人整体架构中的定位感兴趣,可以参阅本系列第二篇数字人系列(二):换嘴与视频配音路线,其中系统对比了多种技术路径。
为什么唇形同步这么难?
想象一下,你正在看一部外语电影,配音演员的声音很专业,但角色的嘴唇动作完全对不上——这种"对口型失败"(lip-sync error)会瞬间破坏沉浸感。在数字人、视频翻译、CGI 动画等应用场景中,唇形同步(lip synchronization)是决定真实感的关键因素。然而,让计算机自动生成与音频精确匹配的嘴唇运动,却是一个极具挑战性的跨模态生成任务#Prajwal et al., 2020。
Lip Sync(唇形同步)是指生成的嘴唇运动轨迹与驱动音频的时序精确匹配,达到人类难以察觉的差异程度。这与一般的说话人脸生成(talking face generation)不同——后者可能只关注"人在说话",而唇形同步要求"嘴唇的每个开合都对应正确的音素"。
之前的方法为什么不行?
让我们看看 Wav2Lip 之前的主流方案。Speech2Vid#Jamaludin et al., 2019 是首个端到端的音频驱动人脸生成方法,它用 GAN 架构直接从音频生成人脸视频。LipGAN#Prajwal et al., 2019 引入了视觉质量判别器来提升生成质量。但它们都有一个共同问题:同步精度不足。在论文的评测中,这些方法在 LRS2 测试集上的 LSE-D(Lip Sync Error-Distance)指标高达 10.61~14.76,意味着每秒视频中会有多次明显的同步失误。
根本原因在于:缺乏足够强的唇形同步约束。之前的方法要么只用简单的 L1/L2 损失,要么用的判别器不够"专业",无法准确判断细微的音素-嘴型对应关系。
前置知识:音素与时间动态
音素(phoneme)是人类语言中最小的语音单位。不同的音素对应不同的嘴唇形状,如 /b/ 需要双唇闭合,/i/ 需要嘴唇向两侧拉伸。音素不是瞬时的——一个音素通常持续 100-200 毫秒,这要求模型必须有时间建模能力来捕捉动态变化。
在 25 fps 的视频中,5 帧约等于 200 毫秒,正好覆盖一个完整音素的时长。这就是 Wav2Lip 选择 5 帧时间窗口的直觉依据。
整体架构 Pipeline
Wav2Lip 的核心洞察是:用一个预训练的唇形同步专家判别器,来强制生成器学习精确的音素-嘴型对应。这个专家判别器在大规模唇读(lip reading)数据集上训练,能准确判断任意音频-视频对是否同步。关键设计是:训练生成器时冻结这个判别器的权重,不让它被生成器的伪影"带偏"#Prajwal et al., 2020。
整体架构包含三个核心模块:
- 音频编码器:从原始音频提取 mel-spectrogram 特征
- 人脸编码器:从参考人脸帧提取特征
- 生成器:融合音频和人脸特征,生成目标嘴唇区域
- 唇形同步专家判别器:评估生成的嘴唇与音频的同步性(冻结权重)
- 视觉质量判别器:评估生成的人脸质量(fine-tune)
flowchart TD
A["输入: 参考人脸帧"] --> D["人脸编码器"]
B["输入: 驱动音频"] --> C["音频编码器"]
C --> E["跨模态注意力融合"]
D --> E
E --> F["生成器: 生成嘴唇区域"]
F --> G["输出: 同步人脸视频"]
G --> H["唇形同步专家判别器"]
G --> I["视觉质量判别器"]
B --> H
H -.->|冻结权重, 不更新| J["L_sync 损失"]
I --> K["L_adv 对抗损失"]
F --> L["L_recon 重构损失"]
F --> M["L_perceptual 感知损失"]
J --> N["总损失 L_total"]
K --> N
L --> N
M --> N
N -.->|优化| F
style H fill:#ffcccc
style I fill:#ccffcc
style J fill:#ffcccc
style K fill:#ccffcc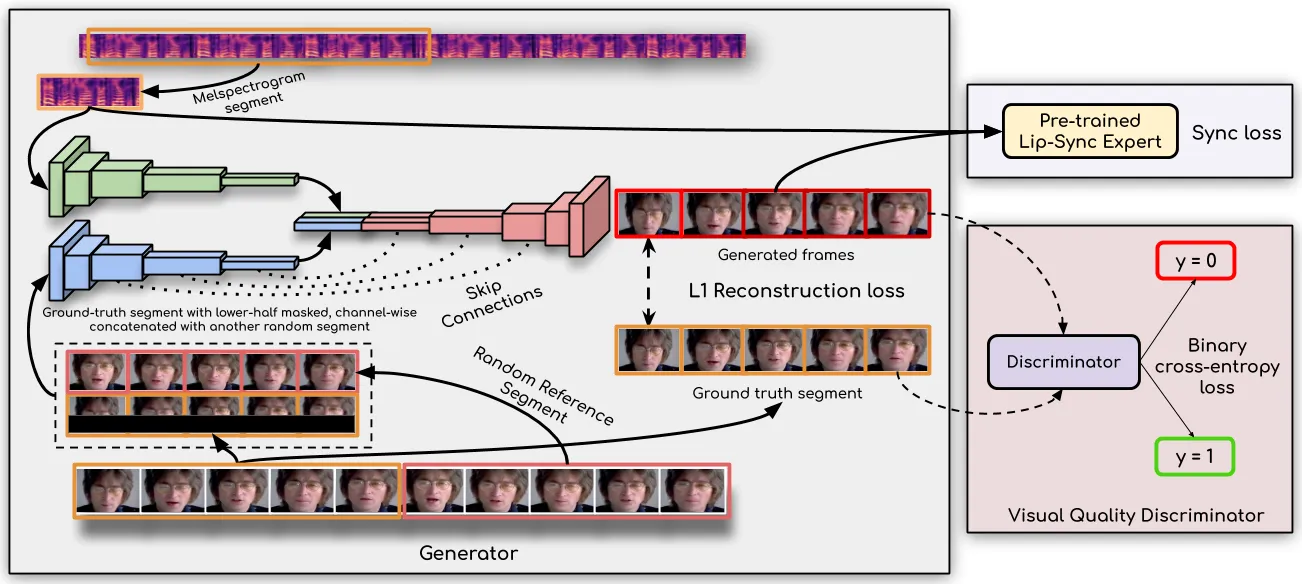
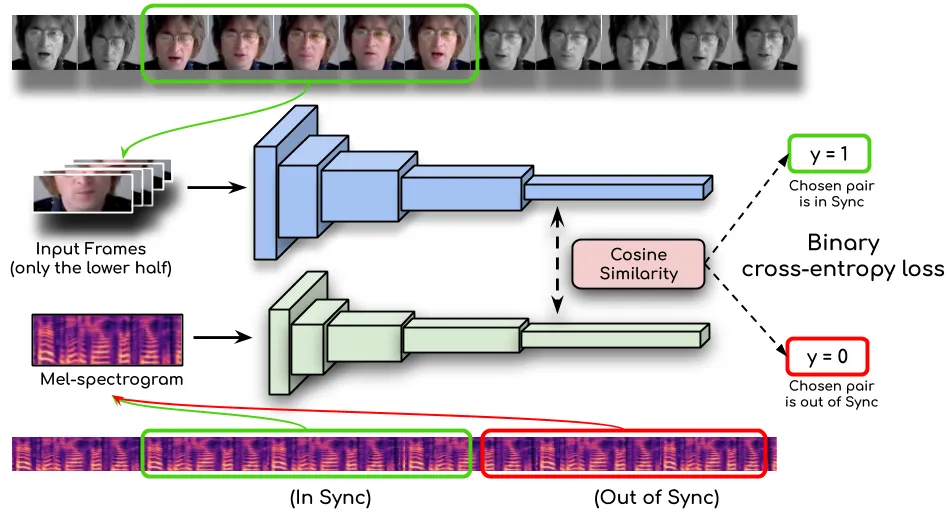
唇形同步专家判别器:SyncNet
这是 Wav2Lip 的核心创新。唇形同步专家判别器的架构直接来自 SyncNet#Chung and Zisserman, 2016,它在大规模唇读数据集 LRS2 上预训练,专门用于判断音频和视频是否同步#Prajwal et al., 2020。
SyncNet 判别器定义
SyncNet 是一个双流网络,包含音频编码器和视频编码器。音频编码器处理 80 维 mel-spectrogram,视频编码器处理 96×96 的嘴唇区域图像。两个编码器输出特征后,通过计算余弦相似度来衡量同步性。相似度越高表示越同步,越低表示越不同步。
记音频编码器输出为 $v$、视频编码器输出为 $s$,同步概率定义为两者归一化后的余弦相似度:
其中 $\epsilon$ 是防止除零的小常数。训练 SyncNet 时用对比目标拉近真实同步对、推远不同步对。
关键设计选择:Wav2Lip 使用 5 帧的时间窗口(Tv = 5)来输入视频序列。这个选择不是随意的——5 帧在 25 fps 下对应 200 毫秒,正好覆盖一个音素的典型时长。论文的消融实验证实,更大的时间窗口(Tv = 5)比单帧(Tv = 1)有更好的判别能力#Prajwal et al., 2020。
反直觉发现:冻结比 fine-tune 更好
一个自然的想法是:为什么不对判别器进行 fine-tune,让它适应生成器的输出风格?论文的消融实验给出了反直觉的答案:fine-tune 反而降低了同步精度。当判别器在生成器生成的含伪影人脸上 fine-tune 后,它会开始学习识别这些伪影作为"真实"特征,而不是专注于真正的音素-嘴型对应关系。结果就是,判别器会把真实的不同步音频-视频对误判为同步,因为它"没见过"这么干净的真实人脸#Prajwal et al., 2020。
生成器结构
生成器的任务是融合音频和人脸特征,生成目标嘴唇区域。它采用跨模态注意力机制,让音频特征关注人脸的嘴唇区域,同时保持人脸的身份、姿态等不变属性#Prajwal et al., 2020。
输入包含两部分:
- 音频输入:16kHz 采样率的原始音频,预处理为 80 维 mel-spectrogram(25ms 窗口,10ms 步长)
- 人脸输入:参考人脸帧,通常是 96×96 的嘴唇区域(cropped from lower face)
生成器输出与输入人脸相同大小的嘴唇区域图像,然后可以将其与原图融合生成完整的人脸视频。
损失函数设计
Wav2Lip 的总损失函数包含四个部分:
其中各分量的含义如下:
- Lrecon:L1 重构损失,约束生成图像与真实图像在像素层面的接近
- Lperceptual:感知损失,使用 VGG 网络的特征距离,让生成图像在语义层面更真实
- Lsync:唇形同步损失,来自唇形同步专家判别器。它把生成嘴型送入冻结的 SyncNet,最大化与音频的同步概率,等价于最小化负对数同步分数:
$$\mathcal{L}_{\text{sync}}=\frac{1}{N}\sum_{i=1}^{N}-\log\bigl(P_{\text{sync}}^{(i)}\bigr)$$
其中 $N$ 是一个 batch 内的样本数,$P_{\text{sync}}^{(i)}$ 是第 $i$ 个生成嘴型与对应音频的同步概率
- Ladv:对抗损失,来自视觉质量判别器,用 GAN 对抗训练提升视觉质量
超参数设置为:$\lambda_{\text{perceptual}} = 0.01$,$\lambda_{\text{sync}} = 1.0$,$\lambda_{\text{adv}} = 0.002$。注意 Lsync 的权重最高,体现了同步准确性是首要目标#Prajwal et al., 2020。
数据集与预处理
Wav2Lip 在 LRS2 数据集上训练,这是一个大规模的唇读数据集,包含超过 45000 个视频,总时长超过 100 小时#Chung et al., 2018。LRS2 的优势在于:视频都是"in-the-wild"的真实场景,包含各种姿态、光照、表情,这确保了模型的泛化能力。
音频预处理:
- 采样率:16000 Hz
- mel-spectrogram:80 维
- 窗口大小:25 ms
- 步长:10 ms
视频预处理:
- 人脸检测:使用 dlib 或 MTCNN 检测人脸关键点
- 嘴唇区域裁剪:基于 68 个关键点中的嘴唇区域,裁剪 96×96 的图像
- 时间序列:每次取连续 5 帧作为输入
训练策略
训练分为两个阶段:
- 阶段一:预训练唇形同步专家判别器。在 LRS2 上训练 SyncNet,学习判断音频-视频同步性的能力。这个判别器训练好后权重冻结,不再更新。
- 阶段二:训练生成器。使用冻结的判别器作为监督,同时训练视觉质量判别器和生成器。优化器使用 Adam,学习率 1e-4。
为什么冻结判别器权重?
这是 Wav2Lip 最关键的设计决策之一。论文的消融实验清楚地展示了 fine-tune 的危害:
| 策略 | Tv (帧数) | Off-sync 准确率 | LSE-D ↓ | LSE-C ↑ |
|---|---|---|---|---|
| Fine-tuned | 3 | 72.3% | 10.14 | 3.214 |
| Frozen | 3 | 87.4% | 6.386 | 7.789 |
| Fine-tuned | 5 | 73.6% | 9.953 | 3.508 |
| Frozen | 5 | 91.6% | 6.386 | 7.789 |
可以看到,在 Tv = 5 的情况下,冻结权重的判别器准确率达到 91.6%,而 fine-tune 后只有 73.6%。这意味着 fine-tune 后判别器损失了近 20% 的判别能力!这就是为什么 Wav2Lip 必须冻结判别器权重的原因#Prajwal et al., 2020。
训练陷阱:不要被伪影带偏
这个发现有深刻的启示:当我们在训练生成器时,如果判别器的目标是学习"真实"数据分布,那么让它适应生成器的"不完美"输出是危险的。生成器的伪影会成为判别器的"新真实",导致判别器失去对真正真实的敏感度。这是许多 GAN 训练中常见的模式崩塌变种。
LRS2 测试集结果
论文在 LRS2 的三个测试集上评估了 Wav2Lip,并与 Speech2Vid、LipGAN 等基线方法对比。主要指标包括:
- LSE-D(Lip Sync Error-Distance):衡量唇形同步误差,越小越好
- LSE-C(Lip Sync Error-Confidence):同步置信度,越大越好
- FID(Fréchet Inception Distance):衡量图像质量,越小越好
| 方法 | LSE-D ↓ | LSE-C ↑ | FID ↓ |
|---|---|---|---|
| Speech2Vid | 14.76 | 1.121 | 19.31 |
| LipGAN | 10.61 | 2.857 | 12.87 |
| Wav2Lip (ours) | 6.843 | 7.265 | 15.65 |
| Wav2Lip + GAN | 7.318 | 6.851 | 11.84 |
可以看到,Wav2Lip 在 LSE-D 上比 LipGAN 提升了 35.4%(从 10.61 降到 6.843),在 LSE-C 上提升了 154%(从 2.857 提升到 7.265)。这是一个巨大的性能飞跃!值得注意的是,Wav2Lip+GAN 的视觉质量(FID = 11.84)优于 LipGAN,但同步精度略有下降,体现了质量与同步的权衡#Prajwal et al., 2020。
真实场景评测:ReSyncED
为了更贴近实际应用,论文收集了一个新的评测数据集 ReSyncED(Real-world Evaluation Dataset),包含三类真实视频#Prajwal et al., 2020:
- Dubbed:配音视频,如外语电影或实时翻译的演讲,原始嘴唇与翻译语音不同步
- Random:随机配对的音频-视频对,模拟最极端的不同步
- TTS:文本转语音生成的合成语音,测试对合成语音的适应能力
评测采用定量指标(LSE-D、LSE-C)和人工评估(14 位评审员,评分 1-5)相结合。人工评估维度包括:
- Sync Accuracy:同步准确度
- Visual Quality:视觉质量
- Overall Experience:整体体验
- Preference:用户偏好(单选投票)
| 视频类型 | 方法 | Sync Acc. | Visual Qual. | Overall Exp. | Preference |
|---|---|---|---|---|---|
| Dubbed | Unsynced Orig. | 0.21 | 4.81 | 3.07 | 3.15% |
| LipGAN | 2.98 | 3.91 | 3.45 | 2.35% | |
| Wav2Lip | 4.13 | 3.87 | 4.04 | 34.3% | |
| Wav2Lip + GAN | 4.08 | 4.12 | 4.13 | 60.2% | |
| TTS | Unsynced Orig. | 0.11 | 4.67 | 3.32 | 8.32% |
| LipGAN | 2.87 | 3.69 | 3.14 | 1.64% | |
| Wav2Lip | 3.98 | 3.87 | 3.92 | 41.2% | |
| Wav2Lip + GAN | 3.85 | 4.13 | 4.05 | 51.2% |
结果显示,Wav2Lip 在所有场景下都显著优于之前的方法。特别值得注意的是,用户偏好率超过 90%——即超过 90% 的评审员更偏好 Wav2Lip 生成的视频,而非原始的不同步视频或 LipGAN 的结果#Prajwal et al., 2020。这是首次有方法在真实场景评测中显著优于原始不同步视频。
TTS 语音的挑战
论文发现 TTS 生成的语音同步精度略低于自然语音(3.98 vs 4.13),这是因为 TTS 语音的韵律(prosody)与自然语音不同,模型在训练时主要见过自然语音。这提示我们,如果要支持 TTS 语音,需要在训练数据中加入合成语音样本。
消融实验:时间窗口的影响
论文还研究了时间窗口大小 Tv 对判别器性能的影响。结果显示:
- Tv = 1(单帧):Off-sync 准确率 55.6%,LSE-D 10.33
- Tv = 3:Off-sync 准确率 87.4%,LSE-D 6.386
- Tv = 5:Off-sync 准确率 91.6%,LSE-D 6.386
更大的时间窗口能捕捉更完整的音素动态,但计算成本也随之增加。Tv = 5 是在性能和效率之间的最佳平衡#Prajwal et al., 2020。
局限性分析
尽管 Wav2Lip 取得了突破性进展,但仍存在一些局限性:
- 极端姿态:侧脸、背光、快速头部运动等极端场景下,性能会下降。这是因为训练数据中这类样本较少,且嘴唇检测和裁剪在这些场景下不稳定。
- TTS 语音:如前所述,TTS 语音的韵律不同导致同步精度下降。需要在训练时加入合成语音样本。
- 视觉伪影:在复杂光照或低分辨率视频上,仍会产生可见的伪影。虽然 Wav2Lip+GAN 改善了视觉质量,但与真实视频相比仍有差距。
- 表情控制:Wav2Lip 只控制嘴唇运动,不控制表情和头姿态。这意味着生成的人脸表情可能与音频的情感不匹配。
伦理警示:Deepfake 的双刃剑
Wav2Lip 的强大能力也带来了被滥用的风险。论文强调了公平使用的重要性,建议任何使用 Wav2Lip 生成的内容必须明确标注为合成内容。同时,开源此模型也有助于推动 Deepfake 检测技术的发展#Prajwal et al., 2020。
对数字人工程的启发
Wav2Lip 对数字人工程有以下重要启示:
- 同步准确性优先:在数字人应用中,唇形同步是决定真实感的第一要素。Wav2Lip 证明,用预训练的专家判别器可以实现极高的同步精度。
- 判别器冻结策略:当目标是学习特定分布(如音素-嘴型对应)时,不要让判别器适应生成器的不完美输出。冻结预训练判别器是一个有效的策略。
- 时间建模的重要性:唇形同步不仅是空间对齐,更是时间对齐。5 帧时间窗口的设计捕捉了音素的动态变化,这是单帧方法无法做到的。
- 质量与同步的权衡:在实际应用中,需要根据场景选择同步优先还是质量优先。Wav2Lip 同时发布两个模型,体现了工程思维的灵活性。
- 评测框架的重要性:论文提出了新的评测指标和数据集,这为后续研究提供了可靠的基准。数字人工程也需要建立类似的评测体系。
如果你对数字人唇形同步技术感兴趣,以下是本系列的相关文章:
- 数字人系列(一):实时数字人生成 Survey——从技术演进和应用场景梳理数字人生成的完整图景
- 数字人系列(二):换嘴与视频配音路线——系统对比多种唇形同步技术路径
参考来源
- Prajwal, K.R., Mukhopadhyay, R., Philip, J., Jha, A., Namboodiri, V., & Jawahar, C.V. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. Proceedings of the 28th ACM International Conference on Multimedia (ACM MM). arXiv:2008.10010
- Rudrabha, W. (2020). Wav2Lip: Accurately Lip-syncing Videos In The Wild. https://github.com/Rudrabha/Wav2Lip
- Chung, J.S., & Zisserman, A. (2016). Out of time: automated lip sync in the wild. Workshop on Multi-view Lip-reading, ACCV.
- Jamaludin, A., Chung, J.S., & Zisserman, A. (2019). You said that?: Synthesising talking faces from audio. International Journal of Computer Vision, 127(11-12), 1767-1779.
- Prajwal, K.R., Mukhopadhyay, R., Philip, J., Jha, A., Namboodiri, V., & Jawahar, C.V. (2019). Towards Automatic Face-to-Face Translation. Proceedings of the 27th ACM International Conference on Multimedia (ACM MM), 1428-1436.
- Chung, J.S., Jamaludin, A., & Zisserman, A. (2018). You said that?. arXiv preprint arXiv:1705.02966.