Teller
Teller 的目标是实时流式 audio-driven portrait animation。论文把挑战拆成两层:第一,扩散式 talking-head 模型虽然能生成高质量视频,但逐帧或多步去噪推理太慢;第二,许多快模型能动嘴和转头,却容易忽略脖子、耳环、衣领等细小部位与语音节奏之间的自然联动 #Zhen-et-al.-2025。
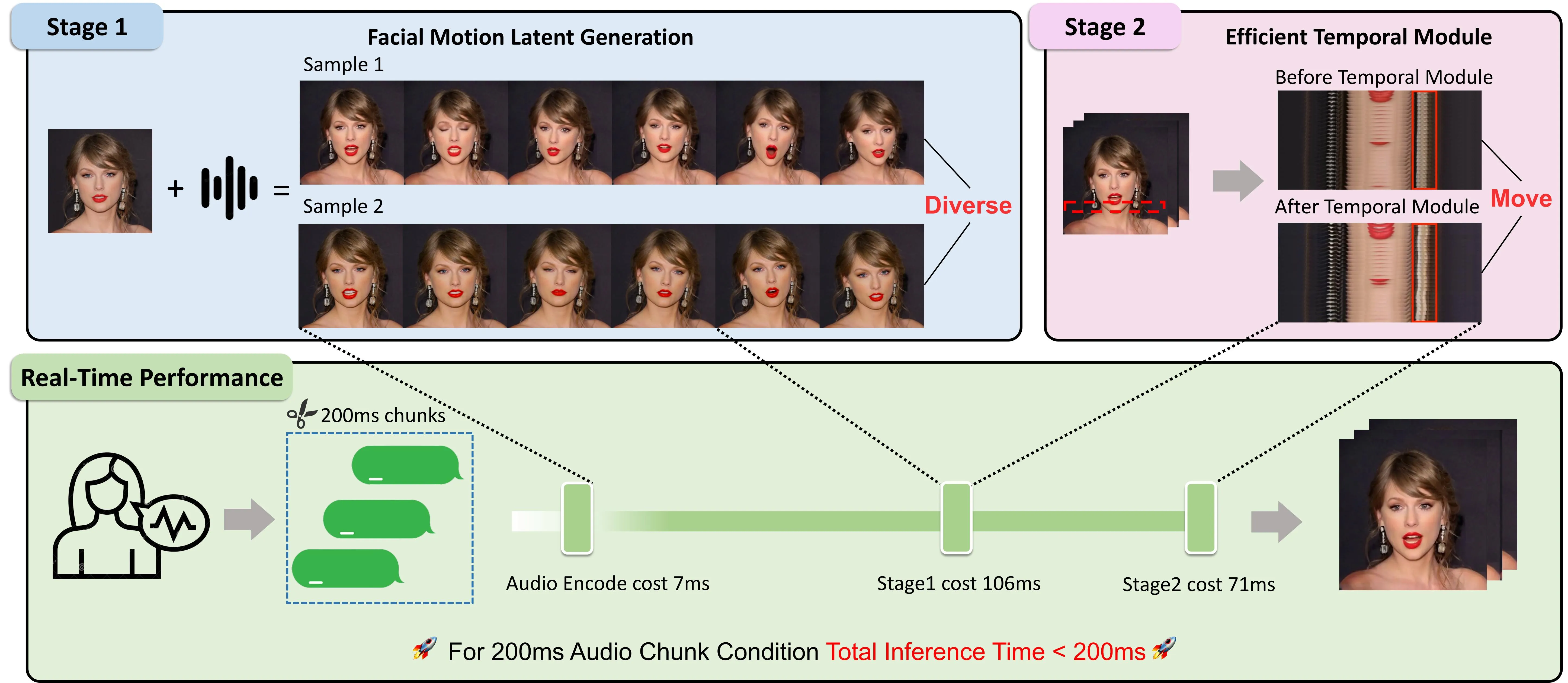
论文给出的核心速度对比很直接:生成 1 秒 25 fps 视频时,Hallo 需要 20.93s,而 Teller 需要 0.92s;在 4 张 NVIDIA H800 的设置下,Teller 以 200ms 音频块为条件,报告达到最高 25 FPS 的实时流式性能 #Zhen-et-al.-2025。
Residual VQ:把运动变成可自回归预测的符号
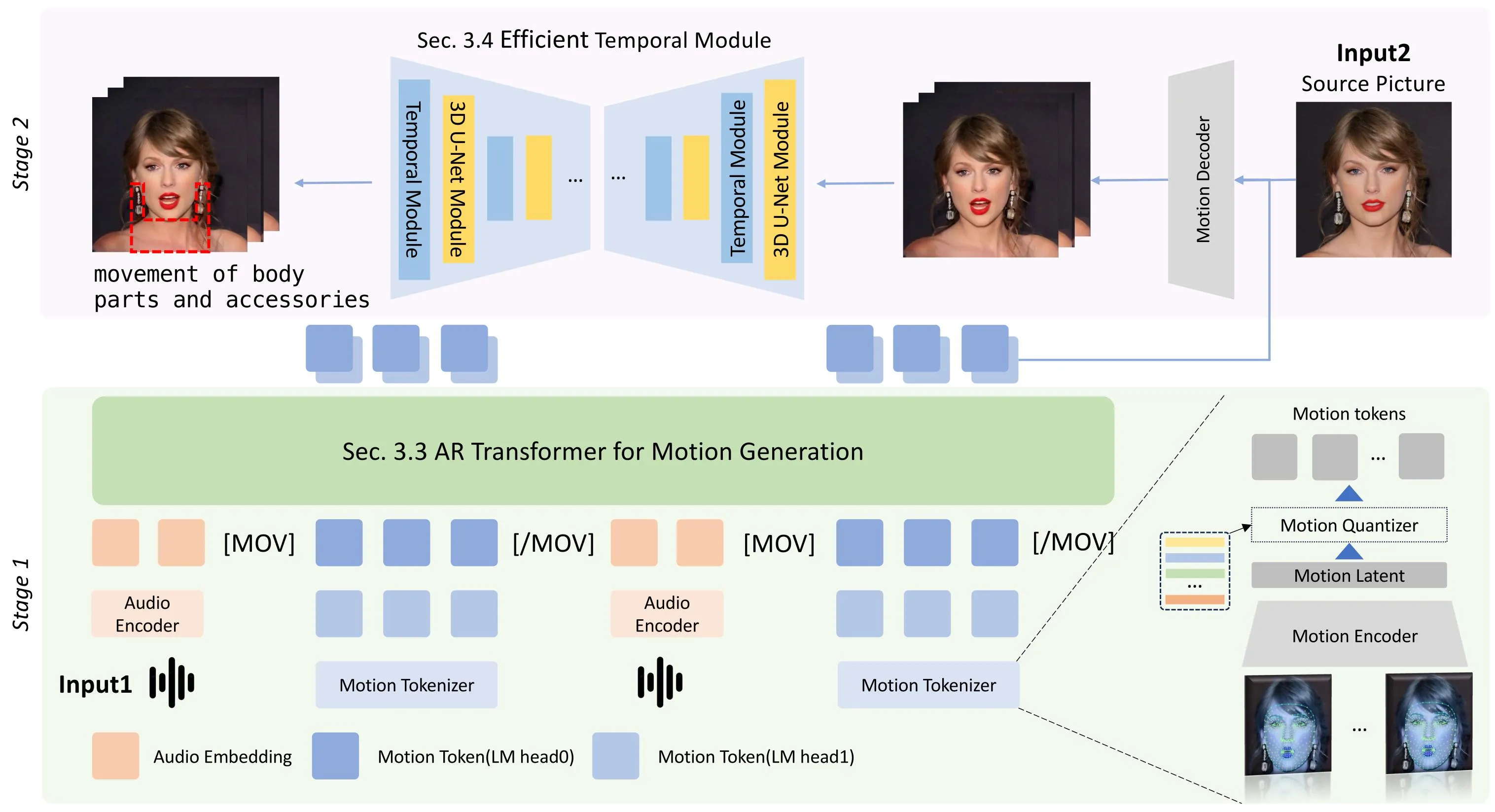
Teller 仍然站在 implicit-keypoint-based animation 的基础上:先从隐式关键点模型中抽取 facial motion latent,再用 Residual Vector Quantization 把连续运动压成离散 token。论文最终采用 4 帧作为一个 motion unit,每帧包含 25 个三维 latent keypoints,即 \(4\times25\times3\) 的运动信息,并压缩为 32 个 RVQ motion tokens #Zhen-et-al.-2025。
Motion token
这里的 token 不是文本 token,而是被 RVQ 离散化的人脸运动片段。它把连续关键点运动变成有限码本索引,使音频到运动可以被写成 next-token prediction 问题。
论文把 RVQ 的训练目标写成重建误差与 commitment loss 的组合。直观说,encoder 要把连续运动映射到码本附近,decoder 要能从量化后的 token 还原运动,commitment loss 则避免编码结果在码本之间飘动 #Zhen-et-al.-2025。
AR Transformer:用音频条件预测运动 token
有了离散 token,Teller 把运动生成改写成条件自回归建模:给定音频条件 \(c\) 和过去的 motion tokens,预测下一个 token 的分布 \(P(t_i\mid c,t_{<i})\)。音频由 Whisper encoder 提取;为了满足实时流式,音频和视频都按 200ms 分块处理,每个音频块变成 \([10\times512]\) embedding,每个视频块对应 32 个 RVQ tokens #Zhen-et-al.-2025。
为了加速 token 生成,Teller 不是一次预测一个 token,而是让输入由 token pair 构成,并用两个 LM head 预测一对输出 token。论文还加入两个 head loss 的平衡正则项,使两个 head 的学习不要明显失衡 #Zhen-et-al.-2025。
Stage 1:FMLG 训练
Stage 1 的任务是学习 Facial Motion Latent Generation。训练数据包含 AV Speech 过滤后的 662 小时和 VFHQ 过滤后的 2 小时用于预训练,另有 32 小时互联网 talking-head 视频用于 supervised fine-tuning;验证与对比使用 HDTF 过滤后的 0.83 小时、RAVDESS 过滤后的 0.55 小时,以及 0.49 小时互联网数据 #Zhen-et-al.-2025。
实现细节披露较完整:预训练采用类似 Qwen1.5-4B 的架构但随机初始化,在 8×8 NVIDIA A800 机器上训练,batch size 1024,AdamW 优化器,cosine learning rate 从 \(10^{-4}\) 衰减到 \(10^{-6}\),训练 40 epochs;SFT 仍使用 8×8 A800,batch size 512,学习率从 \(10^{-5}\) 到 \(10^{-6}\),训练 10 epochs #Zhen-et-al.-2025。
Stage 2:ETM 训练
Stage 1 解决“实时生成脸部运动”的主问题,但论文认为 neck muscles、earrings 等细节仍会显得僵硬。Teller 因此引入 Efficient Temporal Module:先用 VAE encoder 编码视频帧,再用 3D U-Net 抽取时空特征,把特征 reshape 到沿时间维 self-attention 的形态,最后通过 residual connection 合回空间特征 #Zhen-et-al.-2025。
ETM 训练时使用真实序列的前 5 帧和后续 5 帧的重建结果,既做整体重建损失,也做 region-specific mask 重建损失。mask 由 MediaPipe landmark 生成,重点覆盖脖子、耳环等与真实感强相关的小区域 #Zhen-et-al.-2025。
| 项目 | 披露状态 | 论文信息 | 影响 |
|---|---|---|---|
| 预训练数据 | 已披露 | AV Speech 662h + VFHQ 2h | 为音频-视觉运动建模提供大规模基础 |
| SFT 数据 | 已披露 | 互联网 talking-head 视频 32h | 适配目标 talking-head 任务 |
| Stage 1 预训练硬件 | 已披露 | 8×8 NVIDIA A800 | 训练成本非常高 |
| Stage 1 batch / optimizer | 已披露 | batch 1024,AdamW | 可复现性较好 |
| Stage 1 学习率 | 已披露 | 1e-4 → 1e-6,40 epochs | 预训练 schedule 明确 |
| Stage 1 SFT | 已披露 | batch 512,1e-5 → 1e-6,10 epochs | 微调 schedule 明确 |
| Stage 2 | 已披露 | 8×8 A800,batch 1024,1e-4 → 1e-6,30 epochs | ETM 训练配置明确 |
| 推理硬件 | 已披露 | 4 NVIDIA H800 | 实时指标依赖高端多卡环境 |
| 官方代码 | 未识别 | CVF 元数据未给出代码仓库 | 源码级复现仍需等待公开实现 |
Teller 的普通推理链路可以拆成四步。第一步,Whisper encoder 将当前 200ms 音频块编码为 \([10\times512]\) audio embedding。第二步,AR Transformer 根据历史 motion tokens 和当前音频条件预测新的 RVQ motion tokens。第三步,motion decoder 把 tokens 还原为连续 motion latent,并驱动隐式关键点动画模型生成初步视频帧。第四步,ETM 对连续帧进行时序细化,修复脖子、耳环和细小身体运动 #Zhen-et-al.-2025。
flowchart TD A["200ms audio chunk"] --> B["Whisper encoder: 10×512 embedding"] B --> C["AR Transformer"] D["previous motion tokens"] --> C C --> E["RVQ motion tokens"] E --> F["motion decoder"] F --> G["implicit-keypoint animation"] G --> H["Stage 1 frames"] H --> I["ETM temporal refinement"] I --> J["streaming portrait video"]
Streaming Inference Pipeline
流式场景的关键是每个 chunk 的处理时间必须低于 chunk 自身长度。论文报告在 4 NVIDIA H800 上,200ms 音频输入的 Whisper 编码平均 7ms;Stage 1 平均 106ms,其中 AR Transformer 每 16 tokens 平均 6ms,motion decoder 平均 10ms;Stage 2 平均 71ms,其中 VAE encoder/decoder 平均 25ms,Temporal Module 平均 21ms。三部分相加低于 200ms,因此系统可以按 200ms 粒度持续输出 #Zhen-et-al.-2025。
HDTF 表格中,Teller 的 FVD 为 173.463,低于 Hallo 的 174.191、SadTalker 的 233.673、EchoMimic 的 290.190 和 AniPortrait 的 235.099;Sync-C 为 7.696、Sync-D 为 7.536,也优于表中其它生成方法;但 FID 21.352 略差于 Hallo 的 20.639 #Zhen-et-al.-2025。
RAVDESS 表格中,Teller 报告 FID 20.352、FVD 429.288、Sync-C 4.496、Sync-D 7.936。它在 FVD 与 Sync-C 上领先,FID 略差于 Hallo 的 19.826,Sync-D 则略差于 SadTalker 的 7.621 #Zhen-et-al.-2025。这说明 Teller 的优势更集中在“速度 + 时序一致性 + 同步综合表现”,而不是每个静态质量指标都第一。
| HDTF | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ | Time |
|---|---|---|---|---|---|
| SadTalker | 25.257 | 233.673 | 6.297 | 8.263 | 26.08s |
| EchoMimic | 25.678 | 290.190 | 6.746 | 8.107 | 37.77s |
| AniPortrait | 28.161 | 235.099 | 4.547 | 10.657 | 29.36s |
| Hallo | 20.639 | 174.191 | 7.497 | 7.741 | 20.93s |
| Teller | 21.352 | 173.463 | 7.696 | 7.536 | 0.92s |
| RAVDESS | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ |
|---|---|---|---|---|
| SadTalker | 32.343 | 487.924 | 4.304 | 7.621 |
| EchoMimic | 21.058 | 668.675 | 3.292 | 9.096 |
| AniPortrait | 30.696 | 476.197 | 2.321 | 11.542 |
| Hallo | 19.826 | 537.478 | 4.062 | 8.552 |
| Teller | 20.352 | 429.288 | 4.496 | 7.936 |
消融:Whisper 条件和多头预测的取舍
音频条件编码器消融显示,Whisper 的 Sync-C / Sync-D 为 7.696 / 7.536,而 funcodec 为 4.286 / 10.373。论文据此认为 ASR 模型捕捉语音细节的能力更适合精确唇形同步 #Zhen-et-al.-2025。
单头与多头架构消融更微妙:single-head 的 FID、FVD、Sync-C、Sync-D 分别为 22.110、172.553、7.790、7.474;multi-head 为 21.352、173.463、7.696、7.536。single-head 同步略好,但 multi-head 提供更强实时潜力,论文最终选择多头 token-pair 预测 #Zhen-et-al.-2025。

| Audio encoder | Sync-C↑ | Sync-D↓ |
|---|---|---|
| funcodec | 4.286 | 10.373 |
| Whisper | 7.696 | 7.536 |
| Architecture | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ |
|---|---|---|---|---|
| Single-Head | 22.110 | 172.553 | 7.790 | 7.474 |
| Multi-Head | 21.352 | 173.463 | 7.696 | 7.536 |
Teller 值得放进数字人系列,是因为它把 talking head 从“视频生成模型”重新表述为“音频条件下的运动 token 流生成”。这个改写很重要:一旦运动被离散化,系统就可以借鉴语言模型的自回归预测、chunk streaming、top-k sampling 和多头并行预测;视频生成不再每次都从像素或 latent diffusion 开始 #Zhen-et-al.-2025。
局限也很清楚。第一,CVF 页面和论文没有给出官方代码仓库,源码级实现仍需等待公开。第二,25 FPS 与低于 200ms 的 chunk 延迟是在 4×H800 推理设置下报告的,消费级显卡、端侧设备或云端多租户服务都需要重新测量。第三,ETM 虽然修复小部位运动,但依赖额外二阶段模型和 MediaPipe 区域 mask,工程链路比单纯的隐式关键点驱动更复杂 #Zhen-et-al.-2025。
复习速查
- 核心路线:隐式关键点 motion latent → RVQ motion tokens → AR Transformer → ETM。
- 实时关键:200ms chunk,Whisper 7ms + Stage 1 106ms + Stage 2 71ms,低于 chunk 时长。
- 代表数字:Hallo 20.93s vs Teller 0.92s for one second video generation;最高 25 FPS。
- 主要风险:多卡 H800 环境、无公开源码、ETM 增加工程复杂度。
参考来源
- Zhen, D., Yin, S., Qin, S., Yi, H., Zhang, Z., Liu, S., Qi, G., & Tao, M. (2025). Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 21075-21085. CVF HTML · PDF
- Zhen et al. (2025). Teller Supplementary Material. CVF supplemental zip, including supplementary PDF and demo videos. Supplemental
- Guo, J. et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv:2407.03168. arXiv
- Xu, M. et al. (2024). Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation. arXiv:2406.08801. arXiv
- Wei, H. et al. (2024). AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. arXiv:2403.17694. arXiv