SoulX-FlashHead
音频驱动的 talking head 已经从早期的唇部重绘、3D motion coefficient、隐式关键点,走到今天的 video diffusion transformer。路线越往后,画质和整体一致性越强,但部署压力也越大:扩散模型需要多步去噪,视频 DiT 的时空注意力吃显存,流式交互又要求系统边听边生成。SoulX-FlashHead 这篇技术报告正好卡在这个矛盾点上:它希望保留像素级 latent 的整体表示,又把模型压到 1.3B,并给出能在单张 RTX 4090 上达到 96 FPS 的 Lite 版本。#Yu-et-al.-2026
论文的任务设定是:输入一张参考人像和连续语音,输出无限长、实时、口型同步且身份稳定的 portrait video。这里的“无限长”不是数学意义上的无穷,而是工程意义上的长时持续推理:系统把音频和视频切成 chunk,一段接一段自回归生成;如果每个 chunk 都把上一段的小错误带到下一段,几分钟后就会出现脸型漂移、头饰断裂、口型错拍或背景闪烁。#Yu-et-al.-2026
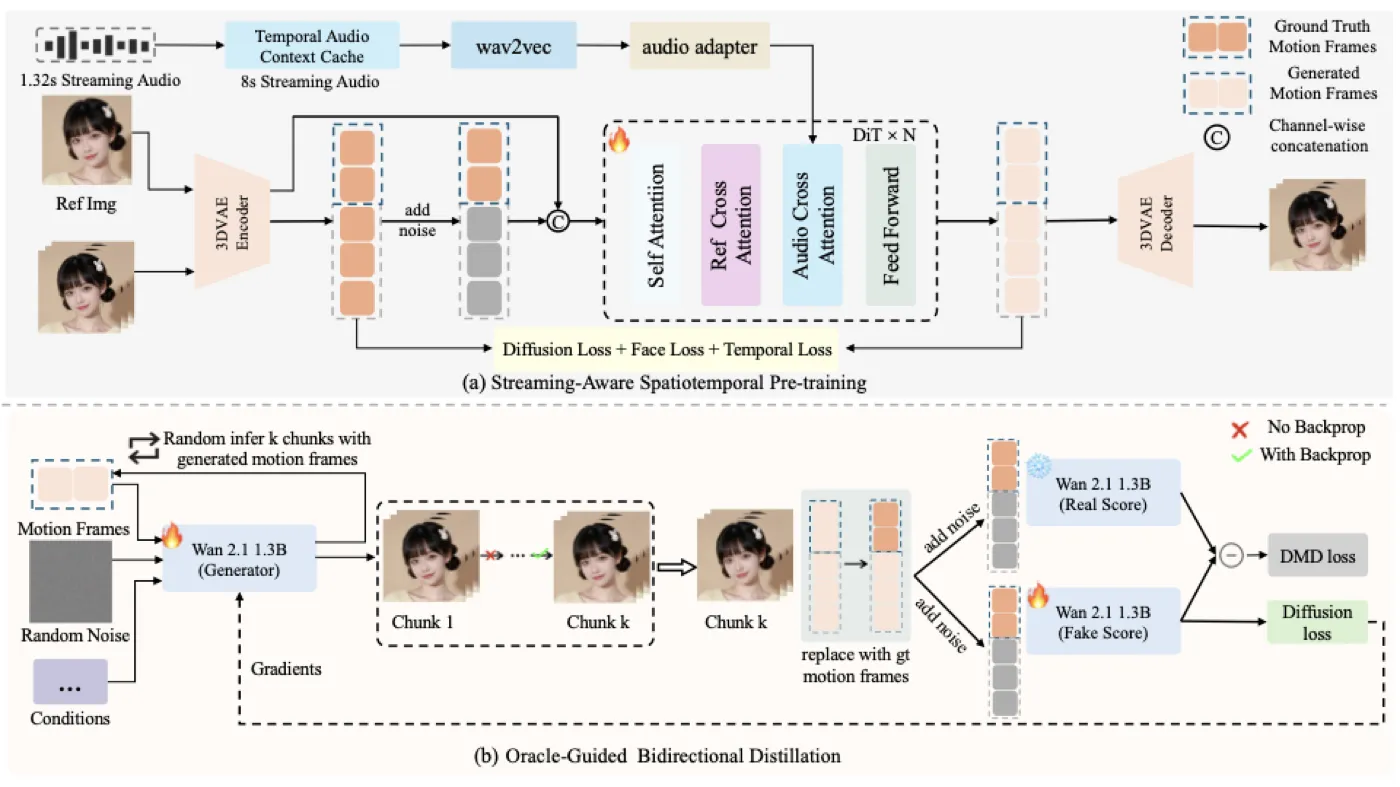
SoulX-FlashHead 的回答是两阶段训练:第一阶段做 Streaming-Aware Spatiotemporal Pre-training,让模型在短音频片段下仍能稳定抽取音频条件;第二阶段做 Oracle-Guided Bidirectional Distillation,用真实 motion history 作为 teacher 的 Oracle 条件,纠正 student 自回归历史中的偏差。简单说,第一阶段解决“听不稳”,第二阶段解决“越生成越漂”。
论文链接:arXiv:2602.07449;项目页:SoulX-FlashHead Project。
四个约束不是独立指标,而是一组互相拉扯的工程条件
SoulX-FlashHead 把现有方法放在四个维度下比较:是否支持 streaming、是否实时、是否能生成无限长序列、是否使用 holistic representation。这里的 holistic representation 指的是用 image/video VAE 在像素级 latent space 建模完整面部纹理和结构,而不是只预测抽象 motion coefficients 或 motion latent。像 SadTalker、Ditto 这类轻量方法更容易实时流式,但表示空间偏运动,难以统一描述头饰、发丝、脸部纹理和背景连接;AniPortrait、Hallo3、Sonic 等高保真路线保留更完整的视觉建模,却通常不支持实时或流式部署。#Yu-et-al.-2026
| 方法类型 | 优势 | 核心短板 | SoulX-FlashHead 的目标 |
|---|---|---|---|
| motion representation | 轻量、快、适合实时 | 面部整体纹理和头饰等像素细节容易断裂 | 保留像素级 latent 表示 |
| large diffusion / DiT | 画质、纹理和整体一致性强 | 多步采样和大模型导致延迟高 | 用 1.3B 主干和蒸馏压缩推理成本 |
| 短片段 streaming | 首帧响应快 | 音频上下文太短,Wav2Vec 特征可能漂移或塌缩 | 引入 8 秒 Temporal Audio Context Cache |
| 长时自回归 | 能持续生成 | 历史预测误差会滚雪球,导致身份漂移 | 用 Oracle-guided distillation 对齐 teacher 与 student |
短音频片段会破坏条件特征
流式交互里,模型不能等完整一句话甚至完整一段音频到齐后再生成。论文提到实时系统通常处理约 1.32 秒的短音频片段;但 Wav2Vec 这类自监督音频模型在过短上下文下容易出现特征分布偏移或 collapse。对 talking head 来说,这不是一个小问题:音频 embedding 的轻微不稳定会直接表现为口型抖动、重音错位和表情节奏不稳。#Baevski-et-al.-2020 #Yu-et-al.-2026
Temporal Audio Context Cache
Temporal Audio Context Cache 是一个固定长度音频队列。它不只使用当前 chunk,而是保留最近一段历史音频,让 Wav2Vec 总是在较稳定的上下文窗口上抽取特征,再切出和当前视频帧对齐的最后若干帧作为驱动条件。
长时自回归会放大历史误差
第二个问题出现在视频历史上。流式模型生成第 \(k\) 个 chunk 时,会把前面生成的 motion frames 当作历史条件。如果第一个 chunk 有一点脸部偏差,第二个 chunk 会在这个偏差上继续预测,后续偏差就可能越来越大。标准 Distribution Matching Distillation 能减少采样步数,但如果 teacher 与 student 使用的历史条件不一致,teacher 的指导并不真正对应 student 推理时面对的漂移状态。#Yin-et-al.-2024 #Yu-et-al.-2026
SoulX-FlashHead 的模型可以从三个层次理解。底层是 3D-VAE,把视频压缩成时空 latent;中层是 1.3B Diffusion Transformer,负责在 latent space 里根据音频和参考图生成运动一致的视频块;上层是两阶段训练与实时推理系统,分别解决流式音频、长时漂移和硬件吞吐。#Yu-et-al.-2026
3D-VAE:Pro 和 Lite 的速度质量分工
论文没有让所有场景共用一个 VAE,而是给 Pro 和 Lite 两个版本设置不同压缩方案。Pro 使用 WAN 2.1 VAE,时空下采样因子为 \(4\times8\times8\),更重视高保真重建和细节保留;Lite 使用 LTX-VAE,压缩因子为 \((32,32,8)\),pixel-to-token ratio 达到 \(8192:1\),约为 WAN 方案的 \(32\times\)。这个选择解释了为什么 Lite 能跑到 96 FPS:速度来自更激进的 latent 压缩,而不是只靠小修小补的 kernel 优化。#Wan-Team-et-al.-2025 #HaCohen-et-al.-2024 #Yu-et-al.-2026
DiT 与 flow matching 目标
主干模型基于 Wan2.1 T2V 1.3B。它把 U-Net 换成 Transformer,在视频 latent 上学习从噪声到数据的向量场。论文给出的基本 flow matching 目标是:
Flow matching loss
其中 \(\mathbf{x}_0\) 与 \(\mathbf{x}_1\) 分别表示噪声和数据端点,模型学习的是中间时间 \(t\) 上的速度场。这个目标本身不专属于数字人,SoulX-FlashHead 的创新在于如何把音频、参考图和历史 motion 条件稳定地注入这个生成过程。
音频条件:8 秒上下文窗口 + pixel-wise cross-attention
Temporal Audio Context Cache 的形式很直接。给定原始音频流 \(\mathcal{A}_{\mathrm{raw}}\),系统维护最大长度 \(T_{\max}=8\mathrm{s}\) 的输入队列:
Audio queue
队列不足 8 秒时用静音补齐,超过 8 秒时保留最近 8 秒。Wav2Vec 对这个稳定窗口编码得到多层音频特征 \(E_{\mathrm{audio}}\in\mathbb{R}^{S\times Layers\times D}\),再取最后 \(N\) 个时间对齐帧作为 \(Z_{\mathrm{cond}}=E_{\mathrm{audio}}[-N:]\),通过 pixel-wise cross-attention 注入 DiT block。
图像条件:channel-wise concatenation 作为身份锚点
很多 portrait generation 方法会用复杂的 cross-attention 或 identity adapter 注入参考图。SoulX-FlashHead 反而选择更直接的 channel-wise concatenation:把参考图 latent 和输入噪声在通道维拼接。这个设计的好处是,参考图以像素对齐的空间先验进入生成过程,能持续约束面部结构、高频纹理和身份细节。对长视频来说,身份保持往往比单帧画质更重要;一个复杂注入模块如果在长时间自回归中逐渐弱化,反而不如稳定的空间拼接可靠。#Yu-et-al.-2026
Oracle-Guided Bidirectional Distillation:让 teacher 不再被错误历史带偏
标准 DMD 的目标是让 student 分布靠近 teacher 分布,从而减少采样步数。但在流式 talking head 里,student 的历史条件来自自己已经生成的 \(\mathbf{m}_{\mathrm{pred}}\),teacher 如果也被迫使用这段有误差的历史,就无法提供清晰的物理纠偏;如果 teacher 使用干净历史而 student 使用错误历史,两者条件又不一致。SoulX-FlashHead 的折中是:student 按推理时的真实方式自回归生成,teacher 使用 ground truth motion frames 作为 Oracle 条件,提供更稳定的目标分布。#Yu-et-al.-2026
Oracle-guided objective
这里 \(\mathbf{m}_{\mathrm{gt}}\) 是真实历史 motion,\(\mathbf{m}_{\mathrm{pred}}\) 是 student 自己滚动生成的历史。KL 项负责分布匹配,latent regression 项负责把第 \(k\) 个 chunk 的轨迹拉回真实 latent 附近。
Stochastic Truncation:只在必要位置反传
如果完整展开 \(K\) 个视频 chunk 的自回归计算图,训练成本会很高。论文采用 Stochastic Truncation Strategy:随机采样截断长度 \(k\),只生成前 \(k\) 个 chunk;反传时仅保留第 \(k\) 个 chunk 中随机 denoising step \(t'\) 的梯度,前序步骤 detach。它牺牲了完整 BPTT 的精确性,换来可承受的显存和训练稳定性。论文设置 \(K=5\),用它模拟长时误差累积。#Yu-et-al.-2026
flowchart TD A["参考图像"] --> B["3D-VAE 编码"] C["实时音频流"] --> D["8 秒 Audio Context Cache"] D --> E["Wav2Vec 多层特征"] E --> F["取最后 N 帧对齐特征"] B --> G["channel-wise concatenation"] F --> H["pixel-wise cross-attention"] G --> I["1.3B DiT"] H --> I J["历史 motion frames"] --> I I --> K["当前视频 chunk"] K --> J K --> L["VAE 解码输出视频"]
图 2:SoulX-FlashHead 推理链路示意。身份由参考图 latent 提供,音频由 8 秒上下文窗口稳定,视频历史以 motion frames 形式自回归进入后续 chunk。
VividHead:从 10K 小时原始视频清洗到 782 小时训练数据
SoulX-FlashHead 的数据集叫 VividHead,包含 330,000 个高质量短片段,时长 3 到 60 秒,总计 782 小时。每个样本包含 \(512\times512\) 图像序列、严格时间对齐的语音音频,以及语言、年龄、族裔等元数据。论文强调只保留单一可见说话人和活跃头部区域,这是为了降低 talking head 训练中最常见的数据噪声:多人入镜、音画不同步、遮挡、场景切换和人脸不可见。#Yu-et-al.-2026
| 数据集 | Speakers | Clips | Hours | Resolution | Language | Source |
|---|---|---|---|---|---|---|
| MEAD | 60 | 281.4K | 39 | 384p | English | Lab |
| HDTF | 362 | 10K | 15.8 | 512p | 未披露 | wild |
| TalkVid | 7,729 | 281.4K | 1,244 | 1080p / 2160p | 15 langs | wild |
| SpeakerVid | 83K | 5.2M | 8.7K | 1080p | 未披露 | wild |
| VividHead | 60K | 330K | 782 | 512p | 15 langs | wild |
Stage 1:Streaming-Aware Spatiotemporal Pre-training
第一阶段的目标不是立刻少步推理,而是先让模型在流式条件下学会稳定的音视频映射。训练中维护 8 秒音频上下文,使用 Wav2Vec 聚合多层语义特征,并模拟两类 motion context:以 \(0.9\) 概率使用开头的 \(n\) 帧 ground truth motion frames,以 \(0.1\) 概率只使用第一帧。这对应持续流式和冷启动两种状态:前者有历史上下文,后者只有参考图或首帧。#Yu-et-al.-2026
Stage 2:Oracle-Guided Bidirectional Distillation
第二阶段继承 Stage 1 模型,并引入 DMD。学生模型按自回归方式连续生成最多 \(K=5\) 个 chunk,每个 chunk 依赖自己前面生成的 motion frames;教师模型则用 ground truth motion frames 作为 Oracle 条件。这样,训练时 student 暴露在推理时会遇到的错误历史中,而 teacher 仍能提供清晰的目标方向。这个设计比单纯 teacher-forcing 更接近真实部署,也比完全使用 predicted history 的 teacher 更稳定。
训练配置:论文披露了什么,没披露什么
| 项目 | 论文披露 | 说明 |
|---|---|---|
| 初始化 | Wan2.1 T2V 1.3B | 作为 DiT baseline,兼顾质量与效率 |
| Stage 1 学习率 | \(2\times10^{-4}\) | 带 warm-up,AdamW 优化器 |
| Stage 1 步数 | 100,000 steps | global batch size 为 256 |
| Stage 2 学习率 | Generator: \(2\times10^{-6}\) Fake Score Network: \(4\times10^{-7}\) | Generator 与 fake score network 更新比例为 1:5 |
| 最大 rollout | \(K=5\) consecutive chunks | 用于模拟长时误差累积 |
| 训练硬件 | 32 NVIDIA H20 GPUs | 每 GPU batch size 为 1 |
| 音频上下文 | \(T_{\max}=8\mathrm{s}\) | 短音频不足时补静音,长音频取最近 8 秒 |
| 数据规模 | VividHead 330K clips / 782h | 从 10K 小时原始视频清洗而来 |
| 训练总时长 | 未披露 | 论文披露 GPU 数与步数,但未披露 wall-clock 时间 |
| 推理 CPU / 内存 | 未披露 | 只披露 GPU 型号和 FPS,对端到端服务部署仍不完整 |
SoulX-FlashHead 的推理不是把整段音频一次性喂给模型,而是一个持续滚动的流式系统。输入端接收实时音频和参考图;音频进入 8 秒 cache 后由 Wav2Vec 编码,系统只截取与当前视频 chunk 对齐的最后 \(N\) 个 audio feature frames;参考图被 VAE 编码成 latent,并通过 channel-wise concatenation 持续注入;上一段生成的 motion frames 作为当前 chunk 的历史条件。当前 chunk 生成后,一方面送入 VAE decoder 输出视频,另一方面回写历史队列,服务下一轮生成。
实时加速栈
论文披露了三层加速。第一层是 Hybrid Sequence Parallelism,通过 xDiT 结合 Ulysses 和 Ring Attention,把 DiT attention 工作负载分散到多 GPU;第二层是 FlashAttention-2,在 kernel 层优化 attention 的内存访问和带宽利用;第三层是 \(\texttt{torch.compile}\),减少 Python runtime overhead,并做图级 fusion。#Dao-et-al.-2023 #Yu-et-al.-2026
| 版本 | 目标 | VAE / 压缩特点 | 论文披露推理硬件 | FPS |
|---|---|---|---|---|
| SoulX-FlashHead Lite | 低延迟交互 | LTX-VAE,\((32,32,8)\) 高压缩 | 单张 RTX 4090 / 实验表中还报告 H20 | 96 FPS |
| SoulX-FlashHead Pro | 高质量生成 | WAN 2.1 VAE,\(4\times8\times8\) 下采样 | 双 RTX 5090;表格中 streaming FPS 为 10.81 | 10.81 FPS 或实时双卡部署 |
Streaming Inference Pipeline
从系统角度看,SoulX-FlashHead 的流式推理包含五个状态:音频 cache、参考图 latent、历史 motion frames、当前 denoising latent、输出视频队列。它的首帧冷启动由训练阶段的 Dynamic Motion Frame Sampling 支撑:模型见过“只有第一帧”的条件,因此不会在第一段视频中强依赖不存在的历史 motion;后续 chunk 则依赖滚动历史,保持动作连续。论文没有披露 chunk 大小、首帧延迟、端到端音频输入延迟、VAE 解码延迟和服务端排队策略,因此 96 FPS 更准确地理解为模型侧吞吐,而不是完整产品链路的用户可感知延迟。
推理披露边界
论文充分披露了模型 FPS、GPU 型号和若干 kernel 优化,但没有完整披露端到端 streaming latency、chunk duration、网络传输、音频前处理和渲染播放队列。因此工程复现时不能把 96 FPS 直接等同于用户侧 10ms 级交互延迟。
评测设置与指标
论文从 HDTF 和 VFHQ 各采样 75 个视频做评测,对比 SadTalker、AniPortrait、EchoMimic、Ditto、Hallo3 和 Sonic。指标覆盖五类:FID 衡量帧级分布质量,FVD 衡量视频时间一致性,Sync-C 衡量音视频同步置信度,Sync-D 衡量唇部动态距离,FPS 衡量推理效率。这个指标组合比只看 FID/FVD 更适合数字人,因为 talking head 的核心体验还包括 lip-sync、时间稳定性和实时性。#Yu-et-al.-2026
| 评测项目 | 论文披露 | 缺失项与影响 |
|---|---|---|
| 数据集 | HDTF、VFHQ,各采样 75 videos | 采样列表未披露,复现实验需要自行确认样本划分 |
| 基线 | SadTalker、AniPortrait、EchoMimic、Ditto、Hallo3、Sonic | 不同方法是否统一分辨率和推理配置未完全披露 |
| 指标 | FID、FVD、Sync-C、Sync-D、FPS | 未报告身份保持指标、人脸检测失败率或用户主观评分 |
| 推理硬件 | 表格说明 FPS 在单 NVIDIA H20 上测量;摘要和项目页强调 RTX 4090 上 Lite 96 FPS | 不同硬件口径需要区分,不能混作同一测试条件 |
| 训练硬件 | 32 NVIDIA H20 GPUs | 未披露训练 wall-clock 和能耗 |
HDTF:Pro 质量领先,Lite 保持实时
| 方法 | Streaming | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | FPS ↑ |
|---|---|---|---|---|---|---|
| Ditto | 是 | 12.35 | 199.13 | 3.57 | 10.49 | 45.04 |
| Hallo3 | 是 | 15.95 | 160.94 | 3.18 | 10.72 | 0.16 |
| Sonic | 否 | 13.53 | 113.31 | 5.17 | 8.69 | - |
| SoulX-FlashHead Lite | 是 | 11.37 | 126.52 | 4.21 | 9.49 | 96 |
| SoulX-FlashHead Pro | 是 | 9.97 | 111.38 | 5.73 | 8.77 | 10.81 |
| SoulX-FlashHead Pro | 非流式 | 8.31 | 103.14 | 6.04 | 8.46 | - |
HDTF 的结果显示了 Pro 与 Lite 的清晰分工。Pro 非流式版本在 FID、FVD、Sync-C、Sync-D 上全部最好;Pro 流式版本在 streaming 方法里也明显优于 Hallo3、Ditto 和 EchoMimic。Lite 的意义不在于每个质量指标都第一,而是以 96 FPS 保持 FID 11.37 和 FVD 126.52:相比 Ditto,它速度更快且 FID/FVD 更好;相比 Hallo3,它质量和速度都更均衡。#Yu-et-al.-2026
VFHQ:复杂自然视频下的同步优势更明显
| 方法 | Streaming | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | FPS ↑ |
|---|---|---|---|---|---|---|
| SadTalker | 是 | 29.80 | 191.81 | 4.49 | 8.78 | 1.60 |
| Ditto | 是 | 27.67 | 254.05 | 3.31 | 10.26 | 41.24 |
| Hallo3 | 是 | 23.45 | 171.00 | 4.19 | 9.60 | 0.11 |
| SoulX-FlashHead Lite | 是 | 16.95 | 167.90 | 4.70 | 8.66 | 96 |
| SoulX-FlashHead Pro | 是 | 14.05 | 140.27 | 5.53 | 8.01 | 10.81 |
| SoulX-FlashHead Pro | 非流式 | 13.67 | 133.69 | 5.60 | 7.81 | - |
VFHQ 更接近复杂自然人脸视频,因此 Sync-C 与 Sync-D 的提升尤其关键。Pro streaming 的 Sync-C 达到 5.53,显著高于 SadTalker 的 4.49、Ditto 的 3.31 和 Hallo3 的 4.19;Lite streaming 的 Sync-C 也达到 4.70,同时保持 96 FPS。这说明 Temporal Audio Context Cache 并不是只在简单数据上稳定,而是在更复杂的自然视频中也能减少短音频条件造成的同步波动。#Yu-et-al.-2026
60 秒长视频:看的是错误是否积累

长视频定性图揭示了不同表示路线的失败模式。运动空间方法可能速度快,但嘴型和音频会逐渐错拍;高保真扩散方法如果不处理自回归误差,时间推移后会出现身份漂移;缺少 holistic pixel latent 的方法还会让头饰和人物结构分离。SoulX-FlashHead 用 Oracle-guided distillation 抑制误差扩散,用参考图 channel concatenation 保住身份和空间结构,因此在 60 秒长序列中保持更稳定的口型、脸部结构和整体一致性。#Yu-et-al.-2026
和 Live Avatar、Ditto、Hallo3 的关系
| 方法 | 表示空间 | 实时策略 | 长时稳定策略 | 适合场景 |
|---|---|---|---|---|
| Ditto | motion-space diffusion | 小模型、运动空间生成 | 天然轻量,但整体像素一致性弱 | 低成本实时 talking head |
| Hallo3 | video diffusion transformer | 高质量但推理慢 | 流式能力有限,长时会积累误差 | 离线高质量肖像动画 |
| Live Avatar | 大规模视频生成模型 | 多 GPU pipeline parallelism | History Corrupt、AAS、Rolling RoPE | 多卡高质量实时服务 |
| SoulX-FlashHead | 1.3B DiT + pixel/video latent | Lite VAE 压缩、FlashAttention、torch.compile | Temporal Audio Cache + Oracle-guided distillation | 消费级 GPU 上的实时流式数字人 |
SoulX-FlashHead 的价值在于给出了一条中间路线:它不像 motion-space 方法那样牺牲 holistic representation,也不像 14B 级系统那样默认需要多卡流水线。1.3B 的尺度让它仍可利用 DiT 的生成能力,同时又能通过 Lite VAE 和蒸馏进入单卡实时区间。这对面试数字人、实时陪伴、语音助手 avatar 和轻量直播互动都很有参考意义。
局限性:脸和头强,全身与手势还弱
论文在结论中明确承认,当前框架受 1.3B 参数规模限制,对复杂物理动态的理解不如更大 foundation model。生成主要优化在脸部和头部区域,对大幅度身体运动和复杂手势的合成还不够精确。这个局限很重要:如果产品目标是半身或全身数字人,SoulX-FlashHead 的流式 talking head 能力不能直接替代 co-speech gesture、3D avatar motion 或 Gaussian avatar 方案。#Yu-et-al.-2026
工程启发
如果目标是实时面部数字人,优先关注三件事:短音频上下文是否稳定、长时自回归是否有纠偏机制、参考图身份是否以强空间先验注入。SoulX-FlashHead 的三个对应答案分别是 8 秒 Audio Cache、Oracle-guided distillation 和 channel-wise reference concatenation。
更进一步,如果要把它扩展成完整交互数字人,可能需要把 SoulX-FlashHead 放在一个更大的系统里:语音理解和 TTS 负责对话,SoulX-FlashHead 负责头像区域的高质量流式生成,身体和手势由动作空间模型或 3D avatar 模块负责,最后在渲染层做统一合成。这样才能同时获得实时口型、表情稳定、身体动作和产品级交互闭环。
参考资料
- Yu, Tan, Qian Qiao, Le Shen, et al. 2026. SoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads.
- Baevski, Alexei, et al. 2020. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.
- Yin, Tianwei, et al. 2024. One-step Diffusion with Distribution Matching Distillation.
- Wan Team, et al. 2025. Wan: Open and Advanced Large-Scale Video Generative Models.
- HaCohen, Yoav, et al. 2024. LTX-Video: Realtime Video Latent Diffusion.
- Dao, Tri, et al. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.