DiffSHEG
在数字人 co-speech motion generation 领域,表情和手势长期被当作两个独立问题处理。一边是 speech-driven facial animation 的成熟管线——从 VOCA 到 FaceFormer,语音到口型的映射已经相当精准;另一边是 co-speech gesture generation——CaMN、DiffGesture、DiffuseStyleGesture 等扩散模型在生成自然手势上取得了显著进展。但这两个方向彼此独立,结果是:表情对口型,手势跟节奏,但它们的组合往往不自然——一个正在微笑点头的角色,手势却僵硬地垂在两侧。#Chen-et-al.-2024-DiffSHEG
DiffSHEG(Diffusion-based Speech-driven Holistic Expression and Gesture generation)正是为了解决这个 split 问题。它提出一个核心观察:表情和手势之间存在天然的不对称依赖关系。表情可以独立于手势存在——一个人可以只微笑不挥手;但手势往往伴随表情变化——挥手的动作本身就包含了面部和身体姿态的调整。基于这个直觉,DiffSHEG 设计了 uni-directional information flow:表情预测结果单向流入手势生成器,而不是反过来,也不是简单拼接。#Chen-et-al.-2024-DiffSHEG
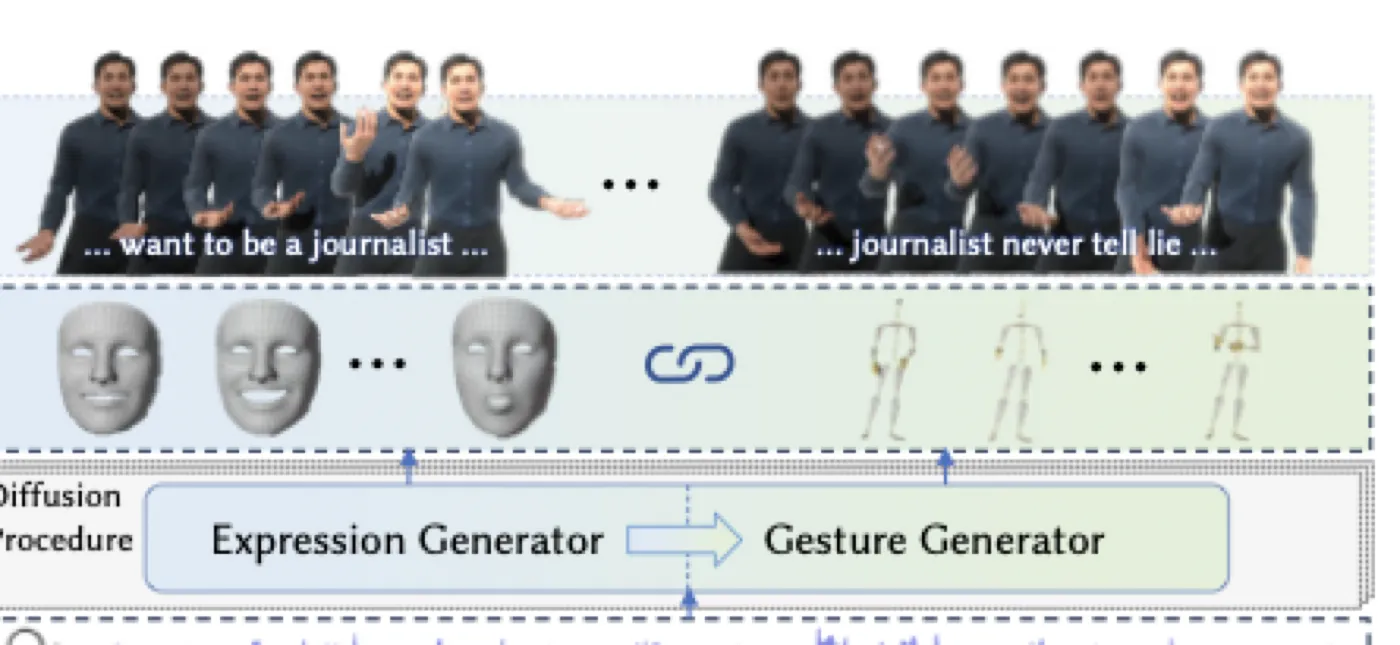
论文的第二大贡献是 FOPPAS(Fast Outpainting-based Partial Autoregressive Sampling)。扩散模型通常需要固定长度的输入,但真实场景中语音是 streaming 的、任意长度的。FOPPAS 用 outpainting 而非 train-time autoregressive 来实现任意长序列生成:相邻 clip 之间有重叠帧,上一 clip 的末尾作为下一 clip 的已知部分,通过 outpainting 补齐剩余帧。配合 DDIM 25 步采样,DiffSHEG 在 3090 上达到 31.5 FPS 的实时推理速度。#Chen-et-al.-2024-DiffSHEG
独立生成 vs 联合生成
已有 co-speech 方法大致分为两类。第一类专注 gesture generation,代表有 CaMN(LSTM + 多模态条件融合)、DiffGesture(扩散模型)、DiffuseStyleGesture(风格化扩散)、ListenDenoiseAction(LDA,基于 ConvNet 的扩散去噪)。这些方法在 BEAT 数据集上能生成自然手势,但表情生成是事后独立训练的,缺乏联合约束。第二类专注 expression generation,如 FaceFormer、CodeTalker,它们擅长口型对齐,但完全不管手势。#Chen-et-al.-2024-DiffSHEG
TalkSHOW 和 LS3DCG 是少数同时处理表情和手势的方法,但它们的做法是分别建模再拼接:TalkSHOW 用 encoder-decoder 做表情、VQ-VAE 做手势,两条路径独立;LS3DCG 用共享 speech encoder 但独立 face/body/hand decoder。这种独立建模导致两个问题:一是手势 VQ-VAE 的 codebook 有限,会丢失高频动作细节,导致动作显得"慢";二是表情和手势之间没有显式交互,联合分布的质量无法保证。#Chen-et-al.-2024-DiffSHEG
| 路线 | 代表方法 | 关键局限 | DiffSHEG 的回应 |
|---|---|---|---|
| 独立 gesture | CaMN, DiffGesture, DSG, LDA | 表情独立生成,联合分布不匹配 | UniEG-Transformer 统一建模 |
| 独立 expression | FaceFormer, CodeTalker | 不管手势 | 表情作为手势条件流入 |
| 分别建模 | TalkSHOW, LS3DCG | VQ-VAE 丢失高频动作;独立路径无交互 | 扩散模型保留细节;单向信息流 |
| 固定长度扩散 | DDPM + Repaint | 推理极慢(0.44 FPS),不可实时 | FOPPAS + DDIM 25 步 |
论文真正定义的问题
DiffSHEG 解决的是一个明确的多输入多输出(MIMO)问题:给定任意长语音 audio \( \mathbf{A} \),生成 \( N \) 帧的 holistic motion \( \mathbf{M} = \text{Concat}(\mathbf{G}, \mathbf{E}) \),其中 \( \mathbf{G} \) 是关节旋转(axis-angle,\( \mathbb{R}^{3J} \)),\( \mathbf{E} \) 是 blendshape 权重(\( \mathbb{R}^{C_{exp}} \))。训练时用滑动窗口切 clip,推理时通过 FOPPAS 拼接任意长序列。关键约束是:生成的动作必须同时满足分布匹配(FMD/FED/FGD)、同步性(BA/SRGR/PCM)、多样性(Div)和实时性(>30 FPS)。#Chen-et-al.-2024-DiffSHEG
两个尺度的对齐
分布对齐(Fréchet distances):生成的动作分布与真实分布之间的 Fréchet 距离,衡量整体质量。帧级同步(BA/SRGR/PCM):每个时间步的动作是否与对应帧的语音节奏对齐。DiffSHEG 在这两个尺度上都取得了 SOTA。
DiffSHEG 的架构由三个核心组件构成:Speech Encoder、Motion-Speech Fusion Residual Block 和 Style-aware Transformer Block。这三个组件按顺序堆叠 \( n \) 次,构成 UniEG-Transformer 的完整去噪网络。组件之上,是贯穿全局的 uni-directional expression-to-gesture 信息流设计。#Chen-et-al.-2024-DiffSHEG
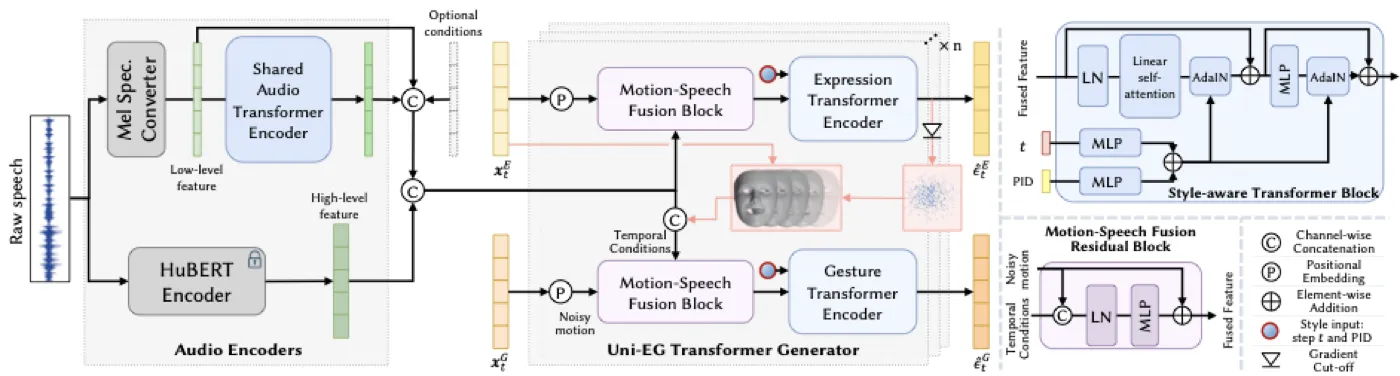
flowchart TD A["Raw Audio"] --> B["Mel-Spectrogram"] A --> C["HuBERT Feature"] B --> D["Shared Transformer Encoder"] D --> E["Mid-level Audio Feature"] C --> F["Motion-Speech Fusion Residual Block"] E --> F F --> G["Style-aware Transformer Block"] G --> H["Expression Branch"] G --> I["Gesture Branch"] H --> J["Predicted Expression x̂0(t)^E"] J -->|"detach gradient"| I I --> K["Predicted Gesture Noise ε̂_t^G"] H --> L["Predicted Expression Noise ε̂_t^E"]
Speech Encoding:双通道语音特征
DiffSHEG 使用两种互补的语音特征。Mel-spectrogram 是低层韵律特征,捕捉语音的能量、音高和节奏变化,帧率与 motion 对齐后形状为 \( N \times C_{mel} \)。HuBERT 是高层语义特征,从预训练的 HuBERT 模型中提取,携带语音内容信息,被插值到与 motion 相同的时间分辨率。两种特征都送入一个共享的 Transformer Encoder,提取中级语音特征,然后分别注入表情和手势分支。#Chen-et-al.-2024-DiffSHEG
从源码看,音频处理的完整链路是:
# datasets/beat.py & datasets/show.py 中的音频处理
# 1. Mel-Spectrogram: librosa 提取,128 维
# 2. HuBERT: 预训练模型提取,1024 维 → 可选 encoder 压缩到 128 维
# 3. 共享 Transformer Encoder: 8 层,hidden_size=256
# 4. 中级特征注入 Fusion Block消融实验验证了这个双通道设计的必要性:去掉 HuBERT 后,手势指标(FGD)明显恶化;去掉 Mel 后,表情指标(FED)下降;去掉中级音频 Transformer 编码器后,所有指标都显著变差。#Chen-et-al.-2024-DiffSHEG
Motion-Speech Fusion Residual Block:比简单拼接更好的融合
与 DiffGesture 使用的简单线性投影不同,DiffSHEG 设计了 Motion-Speech Fusion Residual Block。它的输入是 motion feature 与 speech feature 的通道拼接,经过 LayerNorm + MLP 后,预测一个 residual 加到原始 motion feature 上。源码中的实现位于 models/transformer.py 的 LinearTemporalDiffusionTransformerLayer_2 类:
# models/transformer.py: LinearTemporalDiffusionTransformerLayer_2
# feat_proj: nn.Linear(pre_proj_dim, latent_dim)
# pre_proj_dim = latent_dim + aud_latent_dim [+ expression_dim]
# 将 motion + audio + (optional expression) 拼接后投影到 latent_dim
self.feat_proj = nn.Linear(pre_proj_dim, latent_dim)论文附录中的收敛曲线显示,这个 residual block 可以将训练收敛速度提升 2~4 倍。直觉上,MLP residual block 让网络学习"在当前 motion 特征的基础上,语音信息应该带来什么调整",而不是从头学习 motion-speech 的联合表示。#Chen-et-al.-2024-DiffSHEG
Style-aware Transformer Block:用 AdaIN 注入全局条件
这个 block 的核心是 AdaIN(Adaptive Instance Normalization)风格化。源码中 StylizationBlock 的实现非常清晰:
# models/transformer.py: StylizationBlock
class StylizationBlock(nn.Module):
def forward(self, h, emb):
# emb: 时间步 t + person ID 的融合嵌入
emb_out = self.emb_layers(emb).unsqueeze(1) # B, 1, 2D
scale, shift = torch.chunk(emb_out, 2, dim=2) # 各 B, 1, D
h = self.norm(h) * (1 + scale) + shift # AdaIN 风格化
h = self.out_layers(h)
return h时间步 \( t \) 通过 sinusoidal embedding 编码,person ID 通过 embedding lookup 编码,两者相加后送入 AdaIN 的 scale/shift 预测网络。这个设计让每个 Transformer block 都能感知当前扩散步和说话人身份,从而在不同去噪阶段调整行为。#Chen-et-al.-2024-DiffSHEG
此外,DiffSHEG 使用 linear self-attention(而非 full self-attention)来节省计算。源码中 LinearTemporalSelfAttention 的关键操作是:
# models/transformer.py: LinearTemporalSelfAttention
query = F.softmax(query.view(B, T, H, -1), dim=-1) # softmax over head_dim
key = F.softmax(key.view(B, T, H, -1), dim=1) # softmax over time
value = (value * src_mask).view(B, T, H, -1)
attention = torch.einsum('bnhd,bnhl->bhdl', key, value) # H, D, D
y = torch.einsum('bnhd,bhdl->bnhl', query, attention).reshape(B, T, D)这个 linear attention 的复杂度是 \( O(T \cdot H \cdot D^2) \) 而非标准 attention 的 \( O(T^2 \cdot D) \),在长序列上能显著加速。#Chen-et-al.-2024-DiffSHEG
Uni-directional Expression-to-Gesture 信息流:核心创新
这是 DiffSHEG 最重要的设计决策。在扩散去噪的每一步 \( t \),表情分支先预测当前步的干净表情 \( \hat{x}_{0(t)}^E \):
然后,这个预测的表情 \( \hat{x}_{0(t)}^E \) 被 concat 到手势分支的 motion-speech 融合输入中,同时切断梯度(detach),防止手势训练的梯度影响表情编码器。
消融实验从四个角度验证了这个设计:
| 变体 | 说明 | FMD ↓ | FED ↓ | FGD ↓ |
|---|---|---|---|---|
| DiffSHEG (Full) | 完整单向表情→手势 | 324.67 | 331.72 | 438.93 |
| w/o \( \hat{x}_0^E \) | 不给手势分支表情信息 | 369.97 | 366.37 | 477.00 |
| w/o Detach | 不切断梯度 | 375.98 | 384.31 | 475.19 |
| Naive Concat | 简单拼接表情和手势 | 354.60 | 354.60 | 497.28 |
| Reverse Direction | 手势→表情的反向 | 357.56 | 369.72 | 472.38 |
源码中这个单项信息流的实现位于 runner.py 的 build_models 函数和 transformer.py 的 LinearTemporalDiffusionTransformerLayer_2 中。当 opt.expCondition_gesture_only 为 'pred' 时,模型在训练中使用预测的表情;为 'gt' 时使用 ground truth 表情。推理时始终使用预测表情。opt.ablation 参数控制 no_x0(去掉表情信息流)、no_detach(不切断梯度)、reverse_ges2exp(反向信息流)等消融变体。#Chen-et-al.-2024-DiffSHEG
数据准备
DiffSHEG 在两个公开数据集上训练和评估:
| 数据集 | 规模 | 帧率 | 动作表示 | 表情表示 | 训练 clip 长度 |
|---|---|---|---|---|---|
| BEAT | 4 个说话人,多模态标注 | 15 FPS | axis-angle rotation (141 维) | blendshape weights (51 维) | 34 帧 |
| SHOW | 4 个说话人,SMPLX 参数 | 30 FPS | SMPLX body (129 维) | SMPLX expression (103 维) | 88 帧 |
BEAT 使用 axis-angle 旋转表示(而非 Euler angles),因为旋转的欧拉角表示在生成时容易产生不连续性,而 axis-angle 的平滑性更好。SHOW 数据集使用 SMPLX 参数,包含完整的 body + hand + expression。#Chen-et-al.-2024-DiffSHEG
训练配置
| 项目 | BEAT 配置 | SHOW 配置 | 披露状态 |
|---|---|---|---|
| GPU | 5 × 3090 | 5 × 3090 | 论文披露 |
| Batch size | 2500 | 950 | 论文披露 |
| Epochs | 1000 | 1600 | 论文披露 |
| 优化器 | 未披露 | 未披露 | 需显式标注 |
| 学习率 | 未披露 | 未披露 | 需显式标注 |
| 学习率调度 | 未披露 | 未披露 | 需显式标注 |
| 扩散步数(训练) | 1000 | 1000 | 论文披露 |
| 扩散步数(推理) | DDIM 25 | DDIM 25 | 论文披露 |
| 训练时间 | 未披露 | 未披露 | 需显式标注 |
| 位置编码 | sinusoidal | sinusoidal | 论文披露 |
| 分类器无关引导 | 未使用 | 使用(cond_scale=1.15) | 论文披露 |
需要注意的是,论文正文只披露了 batch size 和 epoch 数,优化器、学习率、训练时间等关键配置未在论文中说明。从源码 options/train_options.py 可以看到默认 lr=2e-4,但这是代码默认值,不一定是论文实验使用的确切值。Batch size 2500(BEAT)看起来很大,但这是因为 BEAT 的 clip 只有 34 帧,且是 5 卡分布式训练,每卡约 500。#Chen-et-al.-2024-DiffSHEG
Loss 函数:噪声预测 + 速度 + Huber 三合一
DiffSHEG 的损失函数是三个分量的加权和:
其中 \( \mathcal{L}_t \) 是标准的扩散噪声预测 MSE loss,\( \mathcal{L}_v \) 是 velocity loss——鼓励预测的帧间速度与真实速度一致,\( \mathcal{L}_\delta \) 是 Huber loss——对 motion reconstruction 的鲁棒损失。权重设置为 \( \lambda_t=10, \lambda_v=1, \lambda_\delta=1 \)。#Chen-et-al.-2024-DiffSHEG
源码中 ddpm_beat_trainer.py 的 backward_G 方法体现了这个三合一设计:
# trainers/ddpm_beat_trainer.py: backward_G
loss_model_pred = self.mse_criterion(self.fake_noise, self.real_noise).mean(dim=-1)
loss_model_pred = (loss_model_pred * self.src_mask).sum() / self.src_mask.sum()
self.loss_model_pred = 1000 * loss_model_pred # λ_t ≈ 10 * 1000
if self.opt.add_vel_loss and self.epoch > self.opt.vel_loss_start:
loss_vel_rec = self.mse_criterion(self.fake_vel, self.real_vel).mean(dim=-1)
loss_vel_rec = (loss_vel_rec * self.src_mask[:, :-1]).sum() / self.src_mask[:, :-1].sum()
self.loss_vel_rec = 100 * loss_vel_rec # λ_v ≈ 1 * 100
self.final_loss += loss_vel_rec
# Huber loss (self.huber_loss) 在后续计算中引入velocity loss 有一个延迟启动策略:在训练的前 vel_loss_start 个 epoch 只使用噪声预测 loss,之后才加入 velocity loss。这避免了训练初期模型尚未学会基本去噪时就被 velocity loss 干扰。#Chen-et-al.-2024-DiffSHEG
扩散模型通常需要固定长度的输入,且 DDPM 的 1000 步采样极慢。DiffSHEG 通过两个关键设计解决了这个问题:FOPPAS 实现任意长序列生成,DDIM 25 步实现实时推理。#Chen-et-al.-2024-DiffSHEG
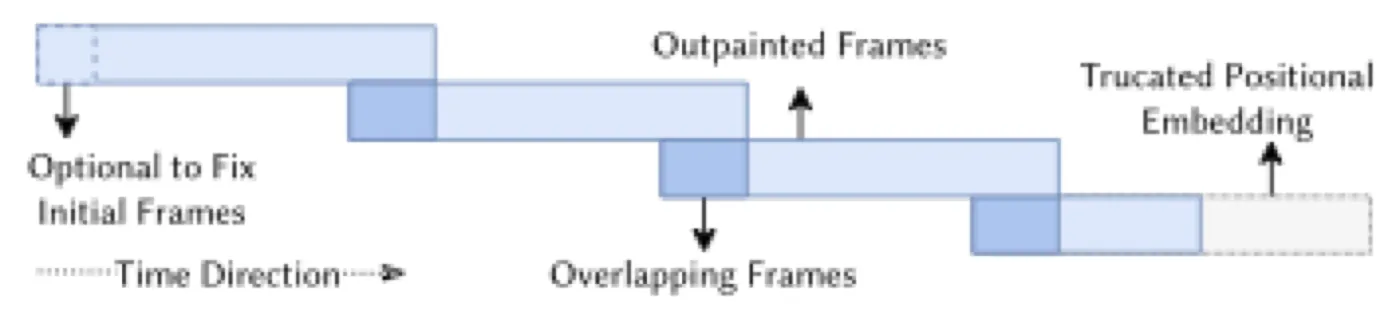
flowchart TD A["Start: First Clip"] --> B["DDIM 25-step Sampling"] B --> C["Save Last L_o frames"] C --> D["Next Clip: Set First L_o = Saved"] D --> E["Outpaint Remaining L - L_o"] E --> F["Blend Boundary at Last 2 Steps"] F --> G["More Audio?"] G -->|"Yes"| C G -->|"No"| H["Done"]
FOPPAS 的核心机制
FOPPAS(Fast Outpainting-based Partial Autoregressive Sampling)的关键思想是:不在训练时引入自回归依赖,而是在推理时通过 outpainting 实现相邻 clip 的平滑过渡。具体来说:
- 第一 clip:overlap_len = 0,完全自由生成。
- 后续 clip:前 \( L_o \) 帧设为上一 clip 的最后 \( L_o \) 帧(known region),剩余 \( L - L_o \) 帧通过 outpainting 生成(unknown region)。
- Blending:在最后两个去噪步,对重叠区域做线性 blending,消除边界不一致。
- 最后 clip:如果剩余帧数不够一个完整 clip,利用 Transformer 不带位置编码的特性,drop 掉多余的 positional embedding,生成较短 clip。
源码中 FOPPAS 的实现位于 gaussian_diffusion.py 的 ddim_sample_loop 方法和 scheduler.py 的 get_schedule_jump_cjm_ddim 函数。重叠帧数通过 --overlap_len 参数控制,BEAT 上默认 4 帧,SHOW 上默认 10 帧。--jump_n_sample 参数控制跳帧采样(每隔 N 帧采样一次),可以进一步加速。#Chen-et-al.-2024-DiffSHEG
实时性能分析
| 配置 | 推理速度 | 说明 |
|---|---|---|
| DDPM 1000 步 + Repaint | 0.44 FPS | 不可实时,2068.1s 生成 900 帧 |
| DDIM 25 步 + FOPPAS (BEAT) | 31.5 FPS (3090), 55+ FPS (A100) | 实时,28.6s 生成 900 帧 |
| DDIM 25 步 + FOPPAS (SHOW) | 50+ FPS (A100) | 实时,配置文件确认 |
31.5 FPS 意味着 DiffSHEG 在 3090 上生成速度已经超过 BEAT 的 15 FPS 播放速度,可以实时驱动数字人。这个速度包含了音频编码(Mel + HuBERT)的时间。在 A100 上,BEAT 推理可达 55+ FPS,SHOW 可达 120+ FPS(配合 jump_n_sample=2)。#Chen-et-al.-2024-DiffSHEG
实验配置
| 项目 | 配置 | 披露状态 |
|---|---|---|
| BEAT 训练数据 | 4 个说话人,34 帧 clip,15 FPS | 论文披露 |
| SHOW 训练数据 | 4 个说话人,88 帧 clip,30 FPS | 论文披露 |
| BEAT 测试数据 | 64 段长序列,约 1 分钟/段 | 论文披露 |
| 训练 GPU | 5 × 3090 | 论文披露 |
| 推理 GPU | 单卡 3090 | 论文披露 |
| 优化器 | 未披露 | 源码默认 lr=2e-4,但未经验证 |
| 训练时间 | 未披露 | 论文与 README 均未说明 |
| CPU / RAM | 未披露 | 论文与 README 未说明 |
主实验结果
| 方法 | FMD ↓ | FED ↓ | FGD ↓ | Div ↑ | BA ↑ | SRGR ↑ |
|---|---|---|---|---|---|---|
| Ground Truth | — | — | — | 0.651 | 0.915 | 0.994 |
| CaMN | 1055.52 | 1324.00 | 1635.44 | 0.479 | 0.793 | 0.197 |
| DiffGesture | 12142.70 | 586.45 | 23700.91 | 0.625 | 0.929 | 0.096 |
| DiffuseStyleGesture | 1261.59 | 998.25 | 1907.58 | 0.688 | 0.919 | 0.204 |
| LDA | 688.25 | 510.345 | 997.62 | 0.603 | 0.923 | 0.215 |
| DiffSHEG (Ours) | 324.67 | 331.72 | 438.93 | 0.539 | 0.914 | 0.251 |
这张表有几个值得解读的点。第一,DiffSHEG 在三个 Fréchet 距离上全面碾压 baseline,尤其是 FMD(整体分布)和 FGD(手势分布)的领先幅度很大,说明 UniEG-Transformer 的联合分布建模确实有效。第二,DiffGesture 的 Div 最高(0.742),但 FMD 和 FGD 也最差——这是因为它的 jittering 现象被 diversity 指标误判为"多样性",实际上是不自然的抖动。第三,LDA 的 BA 最高(0.921),但 SRGR 只有 0.215,说明它对节拍敏感但对语义重音不敏感。#Chen-et-al.-2024-DiffSHEG
SHOW 数据集结果
| 方法 | FMD ↓ | FED ↓ | FGD ↓ | Div ↑ | PCM ↑ |
|---|---|---|---|---|---|
| Ground Truth | — | — | — | 0.703 | — |
| LS3DCG | 0.00230 | 0.00229 | 0.00478 | 0.708 | 0.981 |
| TalkSHOW (Re-train) | 0.00278 | 0.00408 | 0.00328 | 0.618 | 0.894 |
| DiffSHEG (Ours) | 0.00184 | 0.00161 | 0.00271 | 0.923 | 0.912 |
在 SHOW 数据集上,DiffSHEG 同样在三个 Fréchet 距离上全面领先,且 Div(0.701)接近真实数据(0.703)。LS3DCG 的 PCM 最高(0.981),但它的定性结果有明显的手臂抖动,再次说明 PCM 这类逐帧指标在抖动动作上可能虚高。#Chen-et-al.-2024-DiffSHEG

用户研究
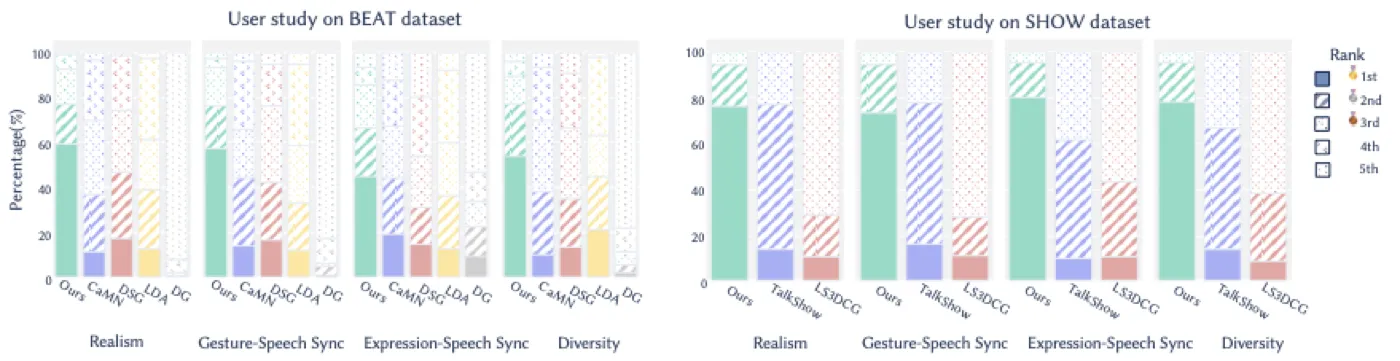
用户研究招募了 22 名不同背景的参与者,评估 BEAT 上 8 段 1 分钟视频和 SHOW 上 12 段 10 秒视频。四个评估维度是:holistic realism(整体真实感)、expression-speech synchronism(表情-语音同步)、gesture-speech synchronism(手势-语音同步)、holistic diversity(整体多样性)。DiffSHEG 在所有维度上显著领先 baseline,验证了定量指标的结论。#Chen-et-al.-2024-DiffSHEG
消融实验:每个设计决策都有据可查
除了 Part 3 中已讨论的 uni-directional flow 消融外,论文还进行了以下消融:
音频编码器消融:去掉 HuBERT 后 FGD 恶化 57 点;去掉 Mel 后 FED 恶化 56 点;去掉中级音频 Transformer 编码器后所有指标全面恶化。这说明低层(Mel)和高层(HuBERT)特征互补,中级编码器对特征融合至关重要。
Motion-Speech Residual Block 消融:附录中的训练曲线显示,使用 residual block 的收敛速度比简单线性投影快 2-4 倍,验证了其加速训练的效果。
敏捷度与平滑度分析:论文附录还分析了加速度误差(AE)、速度均值(Vel)和局部速度标准差(MLVS)。DiffSHEG 的 AE 为 0.628(接近 CaMN 的 0.617,远好于 DiffGesture 的 5.210),Vel 为 0.821(最接近 GT 的 0.863)。这说明 DiffSHEG 在保持运动敏捷度的同时,不会产生抖动。#Chen-et-al.-2024-DiffSHEG
DiffSHEG 的贡献可以概括为三个层次。第一层是方法创新:UniEG-Transformer 的 uni-directional expression-to-gesture 信息流,用极简的设计(detach 梯度 + concat 特征)解决了联合生成中表情与手势的依赖建模问题。消融实验证明了这个设计不仅是"work",而且是"最优的 work"——反向信息流、不切断梯度、简单拼接都不如它好。第二层是工程创新:FOPPAS 把扩散模型的任意长序列生成从"训练时就要考虑"变成"推理时灵活配置",配合 DDIM 25 步实现实时推理。这对数字人产品的落地非常关键。第三层是评估完整性:定量(Fréchet 距离 + 同步 + 多样性)、定性(demo video + 对比图)、用户研究(22 人 × 4 维度),三维评估构成完整证据链。#Chen-et-al.-2024-DiffSHEG
| 方法 / 系统 | 核心对象 | 强项 | 局限 |
|---|---|---|---|
| Ditto | 单图 talking head | motion-space diffusion,实时可控 | 不覆盖全身动作 |
| SentiAvatar | 3D 交互数字人 | plan-then-infill 语义+节奏拆分 | 单角色数据、依赖显式标签 |
| TalkSHOW | co-speech 全身动作 | 同时处理表情和手势 | VQ-VAE 丢失高频,独立建模无交互 |
| DiffSHEG | co-speech 表情+手势联合 | 单向信息流 + 实时任意长推理 | 固定说话人、未开源权重、训练配置未完全披露 |
源码分析:代码质量与可复现性
DiffSHEG 的代码(GitHub: JeremyCJM/DiffSHEG)结构清晰,核心模块职责分明:
| 模块 | 文件 | 职责 |
|---|---|---|
| 模型定义 | models/transformer.py | UniEG-Transformer 核心:PositionalEncoding、StylizationBlock、LinearTemporalSelfAttention、LinearTemporalDiffusionTransformerLayer |
| 扩散过程 | models/gaussian_diffusion.py | DDPM 训练与采样、DDIM 采样、Repaint outpainting |
| 训练器 | trainers/ddpm_beat_trainer.py | BEAT 训练循环、loss 计算、FGD 评估 |
| 数据加载 | datasets/beat.py, datasets/show.py | BEAT 和 SHOW 数据预处理、音频特征提取 |
| 配置系统 | options/base_options.py | 全部命令行参数定义,支持消融与 rebuttal 模式 |
| 推理入口 | runner.py | 训练/测试/自定义音频推理的统一入口 |
代码中值得注意的工程细节:
- 消融实验参数化:
--ablation支持no_x0、no_detach、reverse_ges2exp,--rebuttal支持noMelSpec、noHuBert、noMidAud,所有消融变体通过命令行切换,不需要改代码。 - LDA 崩溃修复:附录中披露 LDA 在推理时会出现数值崩溃(infinity),代码中通过替换为最近正常 clip 来修复,这是一个重要的实现细节。
- Classifier-free guidance:SHOW 数据集上使用
--classifier_free --cond_scale 1.15,--null_cond_prob 0.2控制训练时随机丢弃条件的概率。 - 权重未开源:Google Drive 链接需要手动下载,且未在 README 中提供 checksum 验证。
局限与未来方向
DiffSHEG 有几个值得注意的局限。第一,它只建模了固定说话人——BEAT 的 4 个说话人和 SHOW 的 4 个说话人,没有 zero-shot 泛化到新说话人的能力。第二,它依赖 axis-angle 或 SMPLX 参数作为中间表示,从语音到最终渲染还有一段距离(需要 motion retargeting → 3D mesh → rendering)。第三,训练配置未完全披露——优化器、学习率、训练时间等关键信息缺失,对复现不友好。第四,虽然论文声称"arbitrary length",但 FOPPAS 的 outpainting 质量在极长序列(>5 分钟)上的退化情况未被评估。#Chen-et-al.-2024-DiffSHEG
从数字人产品化的角度看,DiffSHEG 最值得借鉴的是它的信息流设计哲学:不是把两个模态强行拼在一起,而是分析它们的因果依赖关系,让信息沿自然方向流动。这个思路在更复杂的数字人系统中同样适用——面部表情、头部姿态、手势、身体动作之间存在复杂的因果关系,强制对称建模反而不如尊重这种不对称性来得有效。
参考文献与来源
- Chen, J., Liu, Y., Wang, J., Zeng, A., Li, Y., & Chen, Q. (2024). DiffSHEG: A Diffusion-Based Approach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation. CVPR 2024. arXiv:2401.04747
- DiffSHEG GitHub Repository. github.com/JeremyCJM/DiffSHEG
- DiffSHEG Project Page. jeremycjm.github.io/proj/DiffSHEG
- DiffSHEG Demo Video. YouTube
- Liu, H., et al. (2022). BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis. ECCV 2022.
- Yi, H., et al. (2023). TalkSHOW: Generating Holistic 3D Human Motion from Speech. CVPR 2023.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020.
- Song, J., Meng, C., & Ermon, S. (2021). Denoising Diffusion Implicit Models. ICLR 2021.
- Lugmayr, A., et al. (2022). RePaint: Inpainting using Denoising Diffusion Probabilistic Models. CVPR 2022.
- Hsu, W. N., et al. (2021). HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM TASLP.