换嘴、视频配音与 Talking Head
上一篇总览把数字人拆成了局部换嘴、单图 talking head、整帧/全身生成、流式实时系统和业务选型几条路线。本文像一本书中的第二章,先从最容易落地的换嘴与视频配音切入,再把边界扩展到 talking head 与 portrait animation。它的核心问题不是“能不能生成一个完整的人”,而是“音频、视频、参考头像、驱动运动和人物资产分别承担什么角色”。
阅读目标
- 前情回顾:局部换嘴是实时数字人最常见的工程入口。
- 本篇问题:lip-sync、video dubbing、talking head 与 portrait animation 的边界分别在哪里,运动来源、控制粒度和实时成本如何变化。
- 任务边界:本文同时说明 lip-sync、video dubbing、talking head 与 portrait animation 的输入输出差异。
- 下一篇衔接:当局部换嘴不够时,先进入运动空间路线,再讨论扩散基模与整帧生成。
换嘴路线通常接收一个已有视频或人脸帧,再用新音频重绘嘴部和局部面部区域。它保留原视频的大部分信息:身份、背景、衣服、镜头运动、身体动作和光照都来自原素材。模型真正需要生成的是与音频同步的嘴型、下巴和部分脸部纹理。Wav2Lip 的输入就是视频/图像与音频,目标是让 speech-to-lip generation 在野外视频中准确同步。#Prajwal-et-al.-2020
局部换嘴的生成形式
给定原始帧 $x_t$、音频特征 $a_{t-k:t+k}$ 和编辑区域 $m_t$,局部路线可以理解为:
mask 外保留原帧,mask 内由模型根据音频生成。
先把任务边界说清楚
很多论文、产品页和开源仓库都会使用 talking head、lip-sync、portrait animation 这些词,但它们默认的输入并不相同。最窄的 lip-sync 是“已有视频 + 新音频 → 嘴部重绘后的视频”;video dubbing 更强调把一段已有视频翻译或重新配音;single-image talking head 要从一张参考头像和音频生成整段头像视频;person-specific 3DGS/NeRF talking head 通常要先用目标人物视频训练一个身份资产,推理时再输入音频、姿态、眼部或相机轨迹。它们都可能被叫作 audio-driven,但工程边界完全不同。
| 任务形态 | 典型输入 | 模型真正生成什么 | 输出 | 不能默认得到什么 |
|---|---|---|---|---|
| 局部 lip-sync / video dubbing | 原视频或人脸帧 新音频 嘴部/脸部 mask | 嘴型、牙齿、下巴 和局部脸部纹理 | 保留原镜头与身体动作 的配音视频 | 不会自动重写 全身动作、镜头和情绪表演 |
| 单图 talking head | 参考人像 音频 可选表情/姿态控制 | 整张头像帧 或中间运动表示 | 同一头像说话的视频 | 身份长期稳定、复杂侧脸 和身体通常仍弱 |
| portrait animation | 源图 驱动视频或 motion template | 姿态、表情、眼睛、嘴部 等运动迁移结果 | 源身份复用驱动动作 后的头像动画 | 通常不是纯音频输入 也不一定生成新语义动作 |
| person-specific 3DGS/NeRF talking head | 目标人物训练视频 身份资产 音频 + pose/expression/eye 等条件 | 每帧三维表示的变形参数 或渲染结果 | 固定身份的高帧率 talking head 视频 | 不能只凭音频推断 完整表情、头动、眼神和身体 |
| 稀疏帧 video dubbing / 扩散基模 | 输入视频或稀疏参考帧 新音频 | 更大范围的视频重演 包括口型、头动、姿态和情绪 | 更像重新表演后的 配音视频 | 低延迟实时交互 和精确可控通常更难 |
表 1:Talking head 任务边界。不同任务都可能使用音频,但输入条件、生成对象和默认能力完全不同。
核心变量不是模型名,而是运动来源
从局部换嘴往 talking head 走,真正变化的是运动来源。Wav2Lip 与 MuseTalk 大多继承原视频的头动、身体、镜头和背景,只把嘴部区域改成与新音频同步;LivePortrait 把动作交给驱动视频或 motion template;AniPortrait 与 Hallo 试图从音频预测更完整的脸部运动;Teller 把运动离散成 motion tokens 来满足流式交互;FLAP 用 FLAME 3D head coefficients 提供显式控制;EGSTalker 一类 3DGS 方法则通过固定身份资产换取渲染稳定性。#Prajwal-et-al.-2020 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024 #Wei-et-al.-2024 #Xu-et-al.-2024-Hallo #Zhen-et-al.-2025 #Mu-et-al.-2025 #EGSTalker-GitHub
flowchart LR A["新音频"] --> L["局部嘴部运动"] V["原视频"] --> B["身份 / 背景 / 镜头 / 身体"] D["驱动视频或 motion template"] --> K["隐式关键点 / retargeting"] A --> M["mesh / landmarks / motion latent"] A --> T["streaming motion tokens"] C["3D head coefficients
或 3DGS / NeRF 身份资产"] --> R["显式可控渲染"] L --> O["局部配音视频"] B --> O K --> P["portrait animation"] M --> P T --> S["实时 talking head"] R --> S
图 1:从换嘴到 talking head 的运动来源图。局部换嘴复用原视频,portrait animation 复用外部驱动,音频驱动 talking head 需要额外预测或控制运动表示,3DGS/NeRF 则通常依赖固定身份资产。
| 路线 | 运动从哪里来 | 控制粒度 | 优势 | 主要代价 | 产品层 |
|---|---|---|---|---|---|
| 局部 lip-sync / video dubbing | 新音频驱动嘴部 头动和身体主要来自原视频 | 嘴部与局部脸部 | 低成本 低漂移 容易实时 | 表情和动作 不会随新语义完整重演 | 配音 客服头像 口型修复 MVP |
| 隐式关键点 / motion template | 驱动视频 或缓存的运动模板 | 姿态、表情、眼睛、嘴部 整体迁移 | 推理快 可贴回 可做眼嘴 retargeting | 通常需要 明确运动来源 | 视频驱动头像 批量内容制作 |
| 音频到中间运动表示 | 音频先预测 mesh landmarks motion latent | 脸部运动 头姿 表达层级 | 可解释 可编辑 易复用 | 中间表示质量 限制最终视频上限 | 单图 talking portrait 可控播报 |
| 流式 motion token | 音频块 自回归预测未来运动 token | 短时运动序列 | 面向交互式 低延迟 | 训练成本高 需要缓冲和时序模块 | 实时语音助手 交互数字人 |
| 3D / 显式可渲染表示 | 3D head coefficients 或人物 3DGS/NeRF 资产 | 头部角度 眼睛 下颌 表情和相机 | 身份稳定 控制粒度高 | 需要拟合/训练资产 输入条件更复杂 | 固定身份播报 可控数字演员 |
表 2:从局部换嘴到流式 talking head 的路线变化。关键差别是运动来源、控制粒度、推理延迟和身份稳定性的取舍。
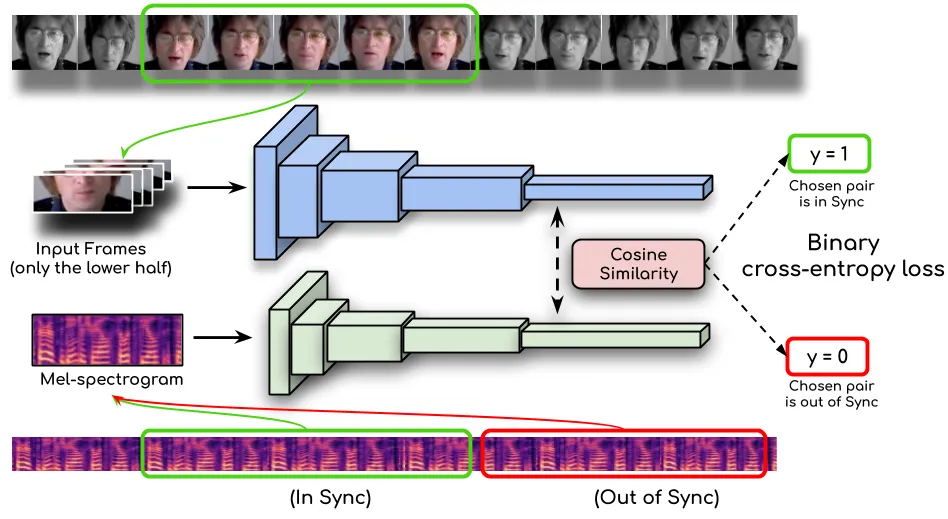
局部换嘴路线的核心假设是:视频里大部分东西已经成立,模型只需要让嘴部区域服从新音频。Wav2Lip 把这个问题做成了清晰的监督目标:生成器负责合成嘴部区域,lip-sync expert/discriminator 判断音频和嘴部运动是否同步,让“嘴型对不对”不再只依赖主观观察。这个设计使 Wav2Lip 成为后续 talking head、video dubbing 和口型修复系统经常引用的基线。#Prajwal-et-al.-2020
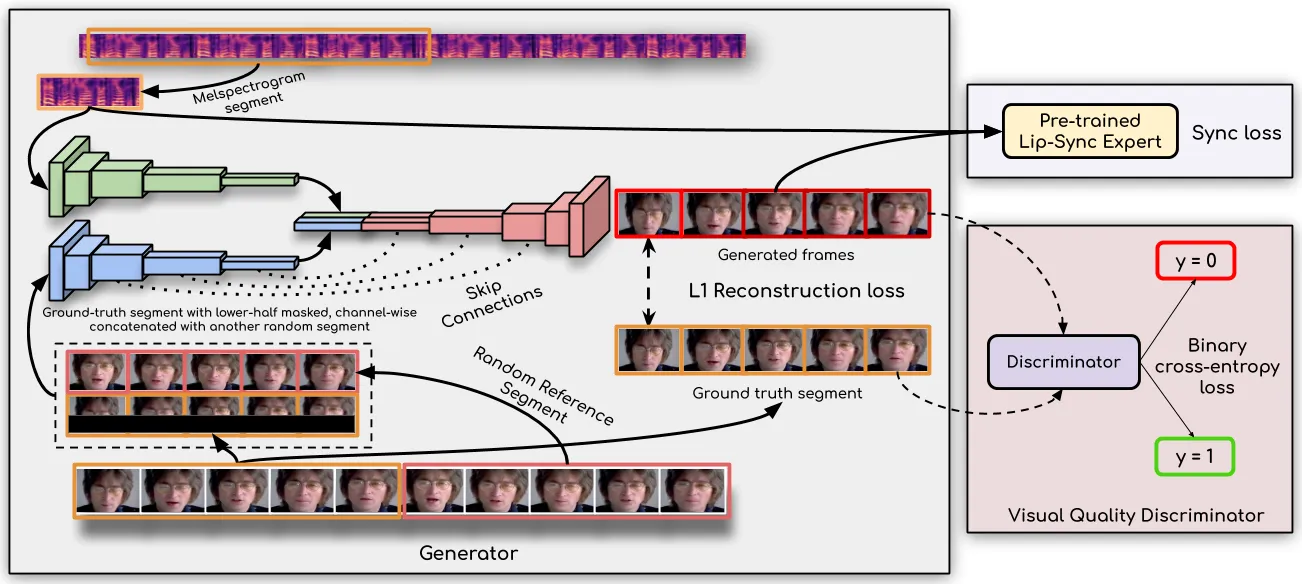
Wav2Lip 适合作为数字人系统里的底层模块:已有视频换一段音频、课程视频重配音、低成本客服头像,或者作为更大视频生成模型的口型修复器。它不负责重新设计头部姿态,也不负责生成身体动作。开源仓库当前 README 同时引导用户使用 Sync.so 商业 API,并说明 commercial version 质量高于旧开源模型;工程引用时要区分论文模型、旧开源实现和商业服务三个对象。#Wav2Lip-GitHub
MuseTalk 把局部换嘴推进到 latent space inpainting。它不是在像素空间逐点画嘴巴,而是在 VAE latent 中对口型区域补全;项目和论文信息给出的代表速度是 256×256、NVIDIA V100 上 30 FPS。这个数字说明局部 latent 重绘具备实时潜力,但生产上线仍要重新测端到端延迟、音频缓冲、视频编解码和推流链路。#Zhang-et-al.-2024-MuseTalk
MuseTalk 的边界同样清楚:它适合视频配音、实时口型替换、会议 avatar 和低分辨率实时 backend;不适合被误当成“单张照片直接生成完整数字人”的统一方案。它采用 MIT License,同时依赖项中包含 MIT、Apache-2.0 等多种许可证,商用时应同时审阅主许可证、依赖许可证和模型权重条款。#MuseTalk-License
graph LR V["原视频/头像
身份·镜头·身体·背景"] --> M["保留非嘴部区域"] A["新音频"] --> F["音频特征"] F --> R["嘴部区域重绘
latent inpainting"] M --> R R --> O["配音后视频
仅嘴部被改写"]
图 5:局部换嘴路线的工程边界。它复用原视频的大部分信息,只在音频相关区域做局部重绘。
局部路线的工程失败模式
局部换嘴真正上线时,失败往往不是“模型完全不会说话”,而是边界细节破坏可信度:牙齿闪烁、嘴唇边界糊、下巴和脸颊不跟随音频、侧脸或遮挡时出现空洞纹理。多语言配音还会引入韵律错配:原视频的点头、停顿和眼神服务于原语言,新语言语速变化后,只重绘嘴巴会显得动作节奏不合拍。
| 能力 | 局部换嘴擅长 | 局部换嘴不擅长 | 工程检查项 |
|---|---|---|---|
| 口型 | 音素级嘴型同步 | 强情绪下的全脸肌肉协同 | LSE-D/LSE-C 快语速样本 多语言样本 |
| 身份 | 保留原视频外观 | 从单图冷启动生成新视频 | 肤色漂移 牙齿闪烁 嘴角边界 |
| 动作 | 复用原视频头动和身体 | 根据新语义生成手势 | 停顿与点头 语气与眼神 身体节奏 |
| 实时 | 局部计算量小,适合 PoC | 高清长视频仍需工程优化 | FPS RTF TTFF 峰值显存 |
表 3:局部换嘴路线的能力边界。它强在口型和身份复用,弱在语义动作和完整表演。
一旦任务从“修嘴”变成 talking head,系统就不能再把头动、眼神和表情默认交给原视频。此时必须选择一种运动表示:隐式关键点、2D landmarks、3D mesh、motion tokens、FLAME coefficients,或者 3DGS/NeRF 这类显式可渲染资产。表示不同,决定了模型能控制什么、能实时到什么程度,以及身份是否稳定。
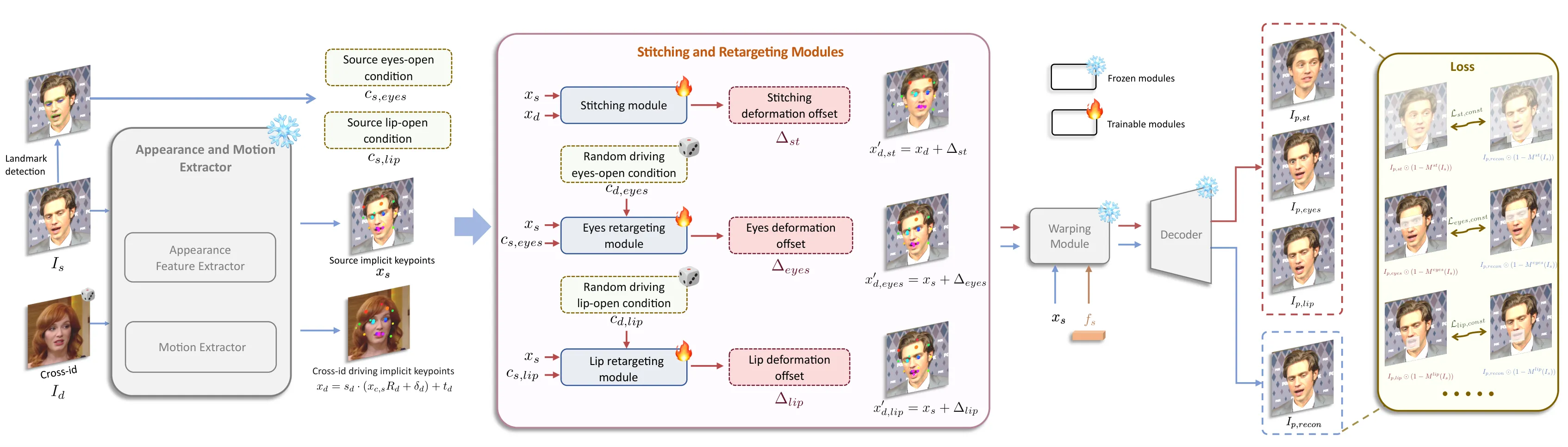
LivePortrait:驱动视频提供运动,模型负责迁移和贴回
LivePortrait 不是纯音频 talking head。它更接近高效 portrait animation:源图提供身份外观,驱动视频或 motion template 提供姿态、表情、眼睛和嘴部运动;模型通过隐式关键点与 feature warping 迁移运动,再用 stitching 和 eyes/lip retargeting 修正贴回后的细节。这个路线的优势是速度快、动作自然、身份替换直观;限制是运动来源通常来自外部驱动,而不是只凭音频自动生成。#Guo-et-al.-2024
AniPortrait:音频先变成 3D/2D 运动条件,再交给视频生成器
AniPortrait 的主线是把音频翻译成更可解释的运动中间层:音频首先预测 3D facial mesh 和 head pose,再投影成 2D landmarks,最后由扩散视频生成模块渲染成 portrait animation。它的意义不在于“又换了一种生成器”,而在于把音频到视频的问题拆成“音频到运动”和“运动到图像”两步。这样做可以让头姿、脸部轮廓和嘴部运动更容易被检查,但最终质量也会受中间运动表示的误差约束。#Wei-et-al.-2024
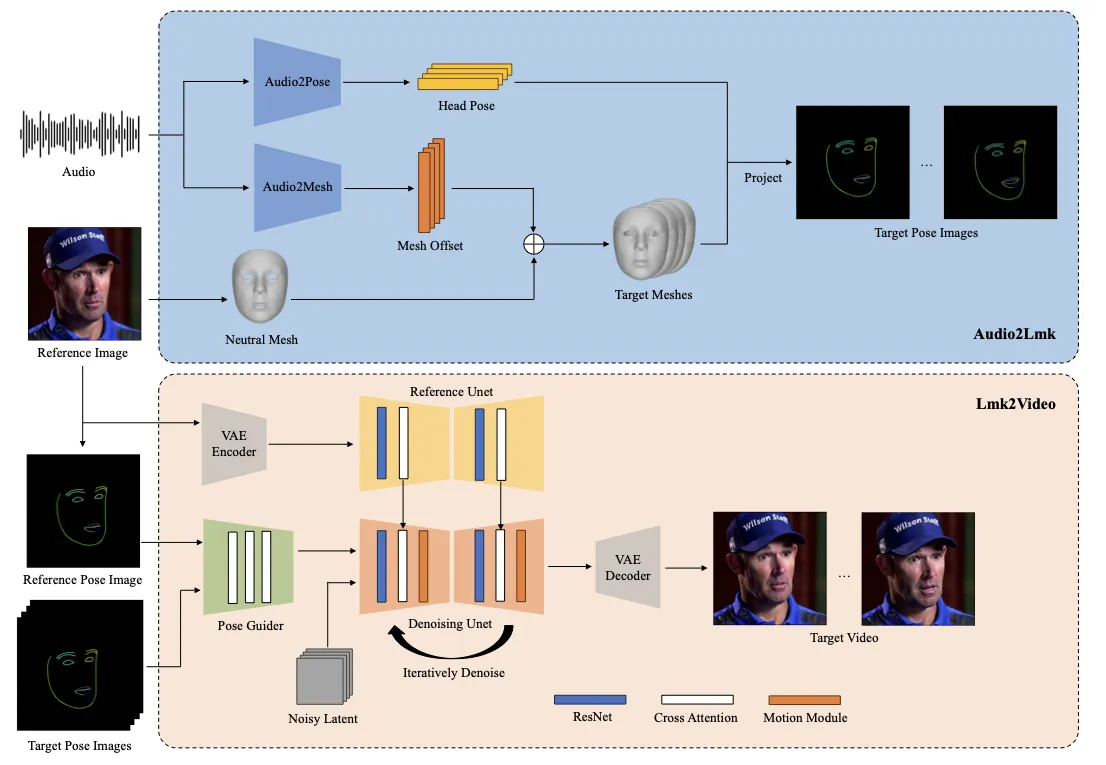
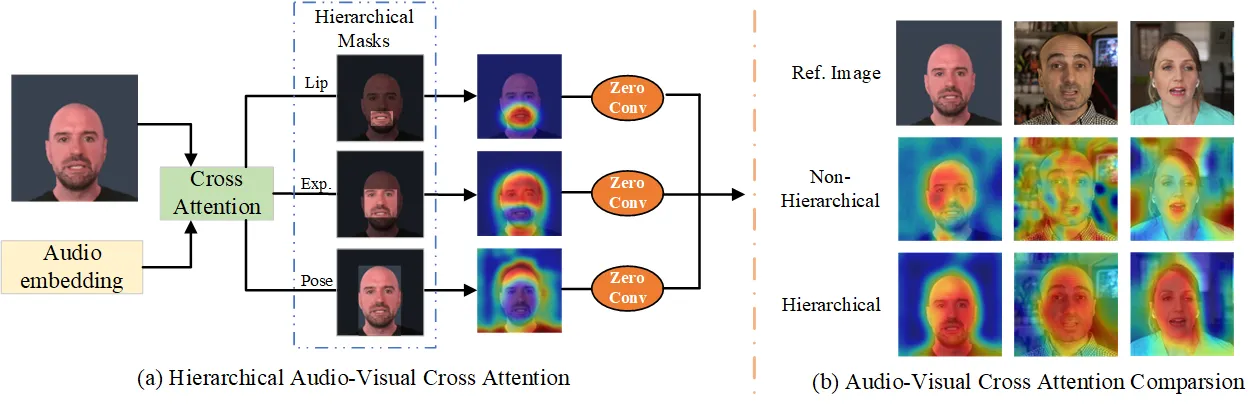
Hallo:把音频条件拆成 lip、expression、pose 三个视觉层级
Hallo 的出发点是:同一段音频并不只对应嘴巴。低层音素影响嘴唇开合,中层语气影响表情,高层韵律影响头姿和节奏。因此 Hallo 在 latent diffusion 框架中使用分层音频—视觉对齐,把音频信号分别注入 lip、expression 和 pose 相关的视觉层级。它比局部换嘴覆盖更多脸部运动,但也更依赖训练数据、时序稳定性和身份保持机制。#Xu-et-al.-2024-Hallo
| 方法 | 输入 | 运动表示 | 生成方式 | 适合场景 | 主要限制 |
|---|---|---|---|---|---|
| LivePortrait | 源图 驱动视频或 motion template | 隐式关键点 stitching / retargeting | 运动迁移 特征贴回 | 复用动作 换身份 批量头像动画 | 通常不是纯音频输入 需要外部运动来源 |
| AniPortrait | 参考头像 音频 | 3D mesh head pose 2D landmarks | 运动条件 扩散视频生成 | 音频驱动单图头像 可解释运动链路 | 中间表示误差 会传递到最终视频 |
| Hallo | 参考头像 音频 | lip / expression / pose 分层视觉条件 | latent diffusion hierarchical attention | 更完整的脸部运动 离线高质量生成 | 训练和推理更重 身份与时序稳定更难 |
表 4:三类非局部换嘴方法的差异。LivePortrait 需要外部运动,AniPortrait 显式构造运动中间层,Hallo 在扩散空间做分层音频视觉对齐。
如果业务目标是交互式数字人,问题会从“生成一段好看的视频”变成“语音输入不断到来时,头像能不能边听边动”。Teller 的路线是把连续人脸运动离散成 motion tokens,再按 200ms 音频块自回归预测后续运动;生成器只需要跟随 token 序列补齐视频细节。它的核心不是更大的图像模型,而是把低延迟、缓冲、预测窗口和时序一致性写进模型结构。#Zhen-et-al.-2025
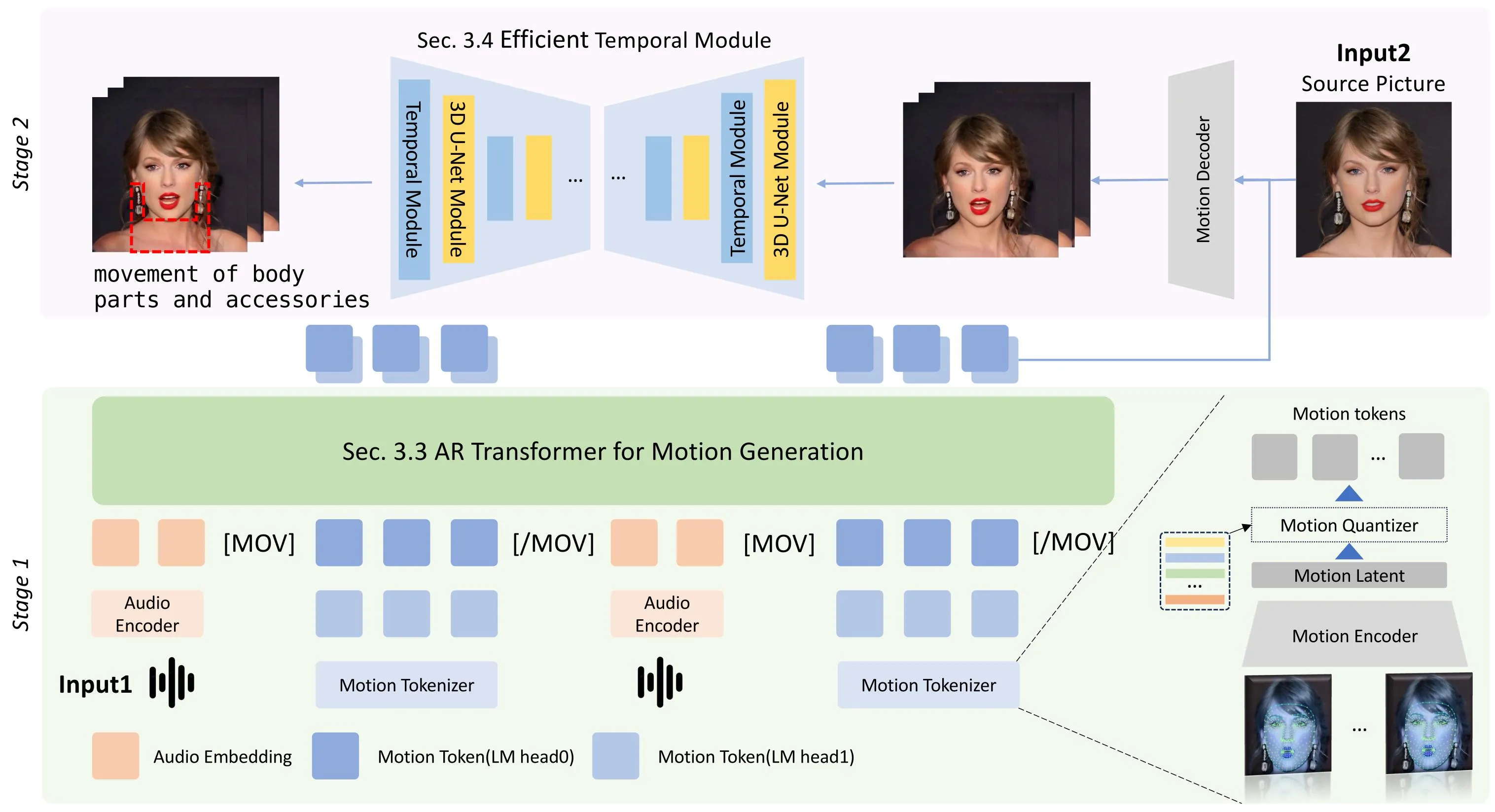
如果业务目标是精确控制,FLAP 给出的是另一种解法。它把 FLAME 3D head coefficients 作为扩散条件,让头部角度、眼睛、下颌、眼睑和表情可以被单独控制。这样做牺牲了一部分“端到端自动生成”的简洁性,但换来了明确的编辑接口:需要强控制播报、虚拟主持、可审查表情轨迹时,显式 3D head condition 比纯 latent motion 更容易被工程系统接管。#Mu-et-al.-2025
3DGS/NeRF 固定身份路线解决的是第三种约束:身份稳定和可渲染资产。EGSTalker 一类方法通常先为目标人物训练或拟合一个可渲染资产,推理时再输入音频、眼部、相机或头部轨迹等条件。它更接近“新音频 + 固定身份资产 + 参考表情/眼部/姿态轨迹”的实时 3D talking head,而不是“只给音频就自动生成完整表情”的通用模型。#EGSTalker-GitHub
不要把 3DGS talking head 误读成纯音频模型
EGSTalker 的训练和推理依赖目标人物序列里的额外驱动信号。代码中 eye_f 由 au.csv 的 AU45_r 眼部 Action Unit 得到;custom audio 推理时,音频可以换成新音频,但眼部 blink/AU、相机姿态和头部轨迹仍不是音频网络自动生成的。这个输入条件决定了它更适合固定身份资产和实时渲染,而不是开放身份的通用音频头像生成。
| 路线 | 核心对象 | 主要输入 | 解决什么 | 主要代价 |
|---|---|---|---|---|
| Teller | motion tokens | 流式音频块 历史运动 token | 低延迟交互 连续语音驱动 | 训练复杂 需要专门缓冲和预测策略 |
| FLAP | FLAME 3D head coefficients | 音频 头部/眼睛/下颌/表情控制 | 可编辑 可审查 强控制播报 | 需要显式控制信号 链路更复杂 |
| 3DGS/NeRF | 固定身份可渲染资产 | 人物训练视频 音频 眼部/相机/姿态条件 | 身份稳定 高帧率渲染 固定角色运营 | 需要拟合/训练资产 泛化到新身份成本高 |
表 5:实时、可控和固定身份三类目标的差异。Teller 解决流式延迟,FLAP 解决显式控制,3DGS/NeRF 解决身份资产和渲染稳定。
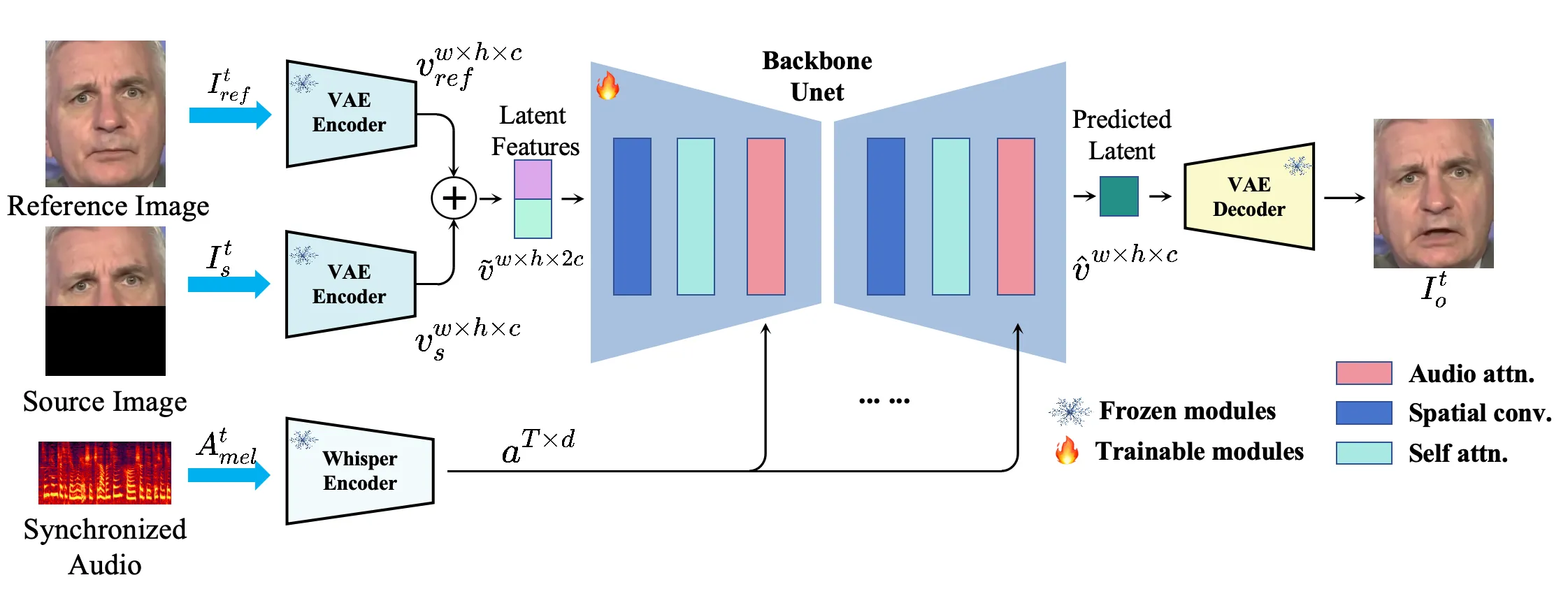
InfiniteTalk 面向 unlimited-length talking video generation 和 sparse-frame video dubbing。按任务目标看,它仍然处理“给已有视频或稀疏参考帧重新配音”的问题;按技术路线看,它已经不是传统换嘴,而是把 Wan2.1-I2V-14B 这类视频扩散基模改造成音频驱动生成器。项目说明中,它给定输入视频与音频轨,生成准确口型同步的新视频,同时对齐 head movements、body posture 和 emotional expression。这意味着模型不只是修嘴,而是在参考帧约束下让原视频像被新音频重新表演。#InfiniteTalk-GitHub #InfiniteTalk-Paper

这个任务更接近影视本地化和长视频多语言配音。新语言的语速、停顿和重音可能与原视频不同,只修嘴会显得头动和手势不合拍。InfiniteTalk 试图利用稀疏帧约束保留身份与场景,再用音频驱动更长范围的口型、头部和身体动态。从工程实现看,它构建在 Wan2.1-I2V-14B 这类大型 image-to-video DiT 基座之上,配合 wav2vec2 类音频编码器,支持 480P/720P 输出;默认采用 40 步扩散,并可借助蒸馏 LoRA 在质量和速度之间取舍。因此它更偏向后期制作,而不是低延迟客服 avatar。#InfiniteTalk-GitHub
flowchart LR V["输入视频 / 稀疏参考帧"] --> I["身份与场景约束"] A["新音频"] --> M["口型 / 韵律 / 情绪"] I --> G["视频扩散 dubbing generator"] M --> G G --> O["新配音视频
口型·头动·身体·情绪重演"]
图 13:稀疏帧 video dubbing 的生成边界。它不只重绘嘴巴,而是在参考帧约束下重新组织口型、头动、身体姿态和情绪节奏。
数字人视频配音的评测必须分层。局部换嘴最先看同步,单图 talking head 还要看身份保持、头姿自然度和长时稳定,流式系统必须看 FPS、RTF、TTFF、首帧缓存和峰值显存,长视频 dubbing 还要看稀疏参考帧之间的插值稳定和语义节奏。Teller 按 200ms 音频块拆分生成链路并报告分阶段延迟,正说明交互式数字人不能只看离线视频质量。#Zhen-et-al.-2025
| 指标 | 含义 | 适用边界 | 容易漏掉什么 |
|---|---|---|---|
| LSE-D | Lip Sync Error - Distance 嘴部关键点与音频同步误差 | 快速评估口型同步 | 表情、身份、纹理和身体动作 |
| LSE-C | Lip Sync Error - Confidence 专家判别器同步置信度 | 判断音频与嘴部运动是否一致 | 可能被局部伪影和判别器偏差影响 |
| FID / FVD | 图像/视频分布距离 | 图像质量和长时序稳定性 | 口型是否对齐、控制是否准确 |
| MOS | 真人主观评分 | 综合自然度、身份保持和观感 | 成本高、主观性强、难以高频回归 |
| FPS / RTF / TTFF | 帧率、实时系数、首帧时间 | 实时交互和线上链路 | 离线画质、长视频稳定和合规风险 |
表 6:常见评测指标的含义与适用边界。LSE-D/LSE-C 专注同步,FID/FVD 关注图像/视频质量,MOS 反映用户综合体验。
这些指标经常互相冲突:局部换嘴可以有很好的 LSE,但表情和身体不一定自然;扩散视频可以有更好的整体观感,却牺牲实时性;3D/显式表示能提高可控性和身份稳定,但需要额外重建、拟合或身份资产训练。因此评测表应该按业务目标分层,而不是把所有方法塞进一个总分。
决策清单
- 已有视频轻量重配音:优先 MuseTalk / Wav2Lip 这类局部路线,先验证口型同步、媒体链路和边界伪影。
- 视频驱动头像动画:优先 LivePortrait 这类隐式关键点和 retargeting 路线,前提是业务能提供驱动视频或运动模板。
- 单图音频 talking portrait:考虑 AniPortrait / Hallo 这类音频到运动或分层扩散路线,重点评估身份稳定和长时序一致性。
- 交互式低延迟:关注 Teller 这类 streaming motion token 设计,指标必须包含音频 chunk、缓冲、TTFF 和端到端 RTF。
- 强控制播报:需要指定头部角度、眨眼、下颌和表情时,优先考虑 FLAP 这类显式 3D head condition。
- 固定身份数字演员:3DGS/NeRF 路线适合长期运营的固定角色,但要接受人物资产训练和额外驱动条件。
- 影视级本地化:只换嘴通常不够,需要 InfiniteTalk 这类稀疏帧 video dubbing 或整帧扩散重演。
商用许可与合规风险
将数字人技术商用时,必须同时审查模型权重条款、依赖许可证和肖像权/声音权。Wav2Lip 开源版本与商业服务需要区分;MuseTalk 采用 MIT License,但模型权重和依赖许可证仍需单独确认;InfiniteTalk 代码、权重和演示公开,但仍需检查 Wan2.1 基座、wav2vec2 音频编码器以及下游部署地区的授权要求。无论技术路线如何,人物肖像和声音的使用都必须获得授权。
下一篇会专门进入运动空间路线:SadTalker、VASA-1、Ditto 等工作不再只是在局部区域修嘴,而是先生成表情、头姿、眼神或 motion representation,再由渲染器还原目标身份。理解这条主线之后,再进入扩散基模、整帧和全身生成会更自然。
参考来源
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. ACM Multimedia 2020. arXiv:2008.10010
- Rudrabha/Wav2Lip official repository README. GitHub repository
- Zhang, Y. et al. (2024). MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting. arXiv:2410.10122
- TMElyralab/MuseTalk LICENSE. MIT License and dependency notices
- Xu, H. et al. (2026). EmoTaG: Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization. arXiv:2603.21332
- ZhuTianheng. EGSTalker official code repository. GitHub repository
- MeiGen-AI. InfiniteTalk: Unlimited-length talking video generation. GitHub repository
- InfiniteTalk authors. InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing. arXiv PDF
- Guo, Jianzhu et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv:2407.03168
- Wei, Huawei et al. (2024). AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. arXiv:2403.17694
- Xu, Ming et al. (2024). Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation. arXiv:2406.08801
- Zhen, Rui et al. (2025). Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation. arXiv:2503.18429
- Mu, Jiteng and Liu, Cheng-Yin. (2025). FLAP: Fully-controllable Audio-driven Portrait Animation with 3D head Condition. arXiv:2504.08277