SA-ICM:给机器看的边缘压缩
上一篇 边缘图像压缩调研 的结论是:当图像只剩稀疏轮廓时,压缩对象不应再被理解成自然图像纹理,而应被理解成结构、连通性和任务可用性。SA-ICM 正好是这条线在学习式图像压缩中的一个具体例子:它不再问“怎样把图像重建得更像原图”,而是问“机器识别到底需要哪些图像信息”。论文的答案很激进:主要保留物体和背景的边缘结构,主动丢掉大量纹理细节 #Shindo-et-al.-2024。
这篇论文全名是 Image Coding for Machines with Edge Information Learning Using Segment Anything,作者为 Takahiro Shindo、Kein Yamada、Taiju Watanabe 和 Hiroshi Watanabe,来自早稻田大学,发表于 IEEE ICIP 2024,arXiv 版本为 2403.04173v3,官方代码在 github.com/final-0/SA-ICM #Shindo-et-al.-2024。它的贡献不是重新发明一个图像压缩骨干网络,而是把 Segment Anything Model 生成的分割边缘变成训练监督,训练一个 Learned Image Compression 模型只编码/解码边缘信息 #SAM-2023。
这篇值得细读的原因有两个。第一,它把“边缘图像压缩”从传统二值图、链码、线段编码推进到了 end-to-end learned compression 的语境。第二,它把“机器视觉压缩”的评价目标讲得很清楚:如果解码图像是给 YOLO、Mask-RCNN、Panoptic-DeepLab 或 YOLOv7 用的,那么码率-精度曲线比 PSNR 更重要 #Choi-Bajic-2022。
系列定位
本篇是“边缘图像压缩”系列第二篇。第一篇解决“为什么边缘/轮廓图应作为结构图压缩”的问题;本篇则读一个具体学习式方法:SA-ICM 如何把 SAM 边缘先验变成训练信号。后续如果继续扩展,可以沿着 VCM/FCM、红外目标检测、语义图压缩和结构保持近无损压缩四条线继续写。
普通学习式图像压缩通常优化一个 rate-distortion 目标:编码器输出 latent \(y\),概率模型估计码率 \(\mathcal{R}(y)\),解码器输出 \(\hat{x}\),训练时最小化码率与像素失真。SA-ICM 论文把这类人类视觉压缩写成 #Shindo-et-al.-2024:
普通 LIC:面向人类视觉的 rate-distortion 目标
这里 \(y\) 是编码器输出,\(\mathcal{R}(y)\) 是由 CompressAI 计算的 bitrate,\(x\) 是输入图像,\(\hat{x}\) 是解码图像,\(\lambda\) 控制码率与失真的权衡 #CompressAI-2020。
但 Image Coding for Machines, ICM 的前提是:机器识别需要的信息量通常少于人类视觉重建需要的信息量 #Choi-Bajic-2022。人眼会在意脸部纹理、衣服褶皱、草地细节、水面波纹;检测器、分割器或跟踪器却可能更关心物体轮廓、边界位置、背景结构和显著几何关系。这个差异使得“低码率下尽量重建整张图”不再是唯一合理目标。
这个问题也嵌在更大的标准化背景里。MPEG 近年推进了 Video Coding for Machines, VCM 与 Feature Coding for Machines, FCM 两条路线:前者仍在像素域压缩视频但针对机器分析任务优化,后者则直接压缩神经网络中间特征,用于 split inference 场景 #MPEG-VCM #FCM-Overview。JPEG 委员会也在推进 JPEG AI,这是首个基于端到端学习的国际图像编码标准,虽然 JPEG AI 主要面向图像压缩本身,但其压缩域表示和 AI 任务友好性也与 ICM 共享问题意识 #JPEG-AI。
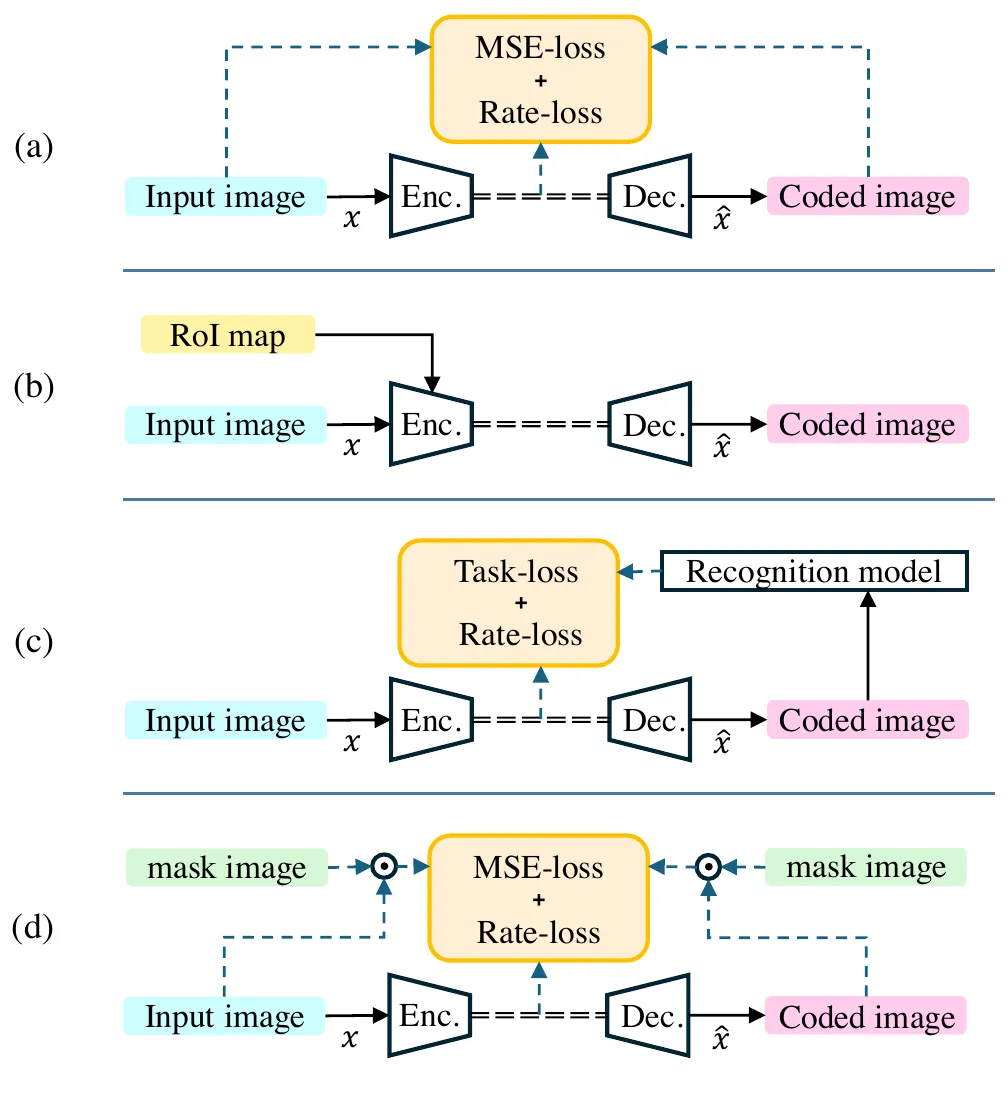
早期 ICM 可以粗分为三条路线:ROI-based、Task-loss-based 和 Region Learning-based。ROI-based 方法用 ROI map 指导编码,把更多 bit 分给物体区域;Task-loss 方法直接把识别模型输出放进训练目标;Region Learning 方法则用 mask 加权 MSE,让 codec 在训练中学会哪些区域更重要 #Choi-Bajic-2018 #Object-ICM-2024。SA-ICM 继承的是第三条路线,但它认为原来的物体区域 mask 仍然保留了太多纹理,而且背景结构保留不足。
作者与实验室背景
一作 Takahiro Shindo 的研究主线高度集中在 Image Coding for Machines:从 VVC + YOLO 特征、Object Region Learning,到 SA-ICM、Delta-ICM 和后续的 contour feature learning 扩展,形成了一条连续路线 #Shindo-Homepage。通讯作者 Hiroshi Watanabe 是早稻田大学 Advanced Multimedia Systems Lab 教授,长期从事图像/视频编码和多媒体分发研究,曾在 NTT 人机界面实验室从事图像/视频编码研发 #Watanabe-Profile。
| 路线 | 核心做法 | 优点 | SA-ICM 看到的问题 |
|---|---|---|---|
| ROI-based | 编码端输入 ROI map,重点区域分配更多 bit | 直观,可兼顾部分人眼质量 | 编码端要生成 ROI,负担大;背景任务不一定好 |
| Task-loss | 用检测/分割模型输出作为 loss | 直接优化任务性能 | 容易绑定特定模型,换任务可能要重训 |
| Region Learning | 训练时用 mask 加权 MSE,测试时不需要 mask | 推理轻量,不依赖任务模型 | COCO 物体区域 mask 类别有限,背景结构保留不足 |
| SA-ICM | SAM 分割图 → Canny 边缘 → 加权 MSE | 保留边缘结构、减少纹理、测试零额外输入 | 依赖 SAM/Canny 生成质量,复现细节披露不足 |
SA-ICM 最直接的前置工作是同一团队的 Image Coding for Machines with Object Region Learning,也可以称为 Object-ICM #Object-ICM-2024。Object-ICM 的想法很朴素:COCO 数据集中有人工标注的物体 mask,那么训练 LIC 时只在物体区域计算重建损失,背景区域可以粗糙一些。它的 Region Learning 损失可写成 #Shindo-et-al.-2024:
Object-ICM / RL-based ICM 损失
其中 \(m_x\) 是 COCO 的二值物体区域 mask,\(\odot\) 是逐元素乘。mask 不进入编码器或解码器,只改变训练损失。
这个想法解决了 ROI-based 方法的一个痛点:测试时不需要额外 ROI map,也不需要编码端运行识别模型。但它也留下了一个新问题:如果只保 COCO 的物体区域,背景会被非常粗糙地重建;这对目标检测可能够用,但对语义分割、全景分割这类依赖背景结构的任务就不够 #Shindo-et-al.-2024。
SA-ICM 的改动非常集中:用 SAM 的自动分割能力生成全图 segmentation map,再用 Canny 从 segmentation map 中提取边缘。这样得到的 mask 不再是“物体内部区域”,而是“显著区域的边界线”。作者设置了三个 SAM 置信度阈值 \(\alpha\in\{0.98,0.93,0.48\}\),\(\alpha\) 越小,SAM 输出的 mask 越多,Canny 检出的边缘也越多 #Shindo-et-al.-2024。

这里的关键不是“用 SAM 做分割”,而是“用 SAM 生成训练监督”。SAM 本身不会部署在压缩器推理链路中;它只在训练前离线生成 mask。换句话说,SA-ICM 把 SAM 从一个 segmentation foundation model 改造成了一个 importance prior generator。这个转译很巧:分割模型负责告诉 codec 哪些空间结构值得保留,codec 在训练后内化这种偏好,测试时仍然只是输入图像、输出压缩表示和重建图像 #SAM-2023 #Shindo-et-al.-2024。
SA-ICM 的训练流水线可以拆成三步。第一步,对训练图像 \(x\) 运行 SAM,得到 segmentation map;第二步,用 Canny edge detector 从 segmentation map 提取边缘,得到 \(\mathrm{sam}_x(\alpha)\);第三步,用这个边缘 mask 同时乘到原图和重建图上,只在边缘位置计算 MSE #Shindo-et-al.-2024。
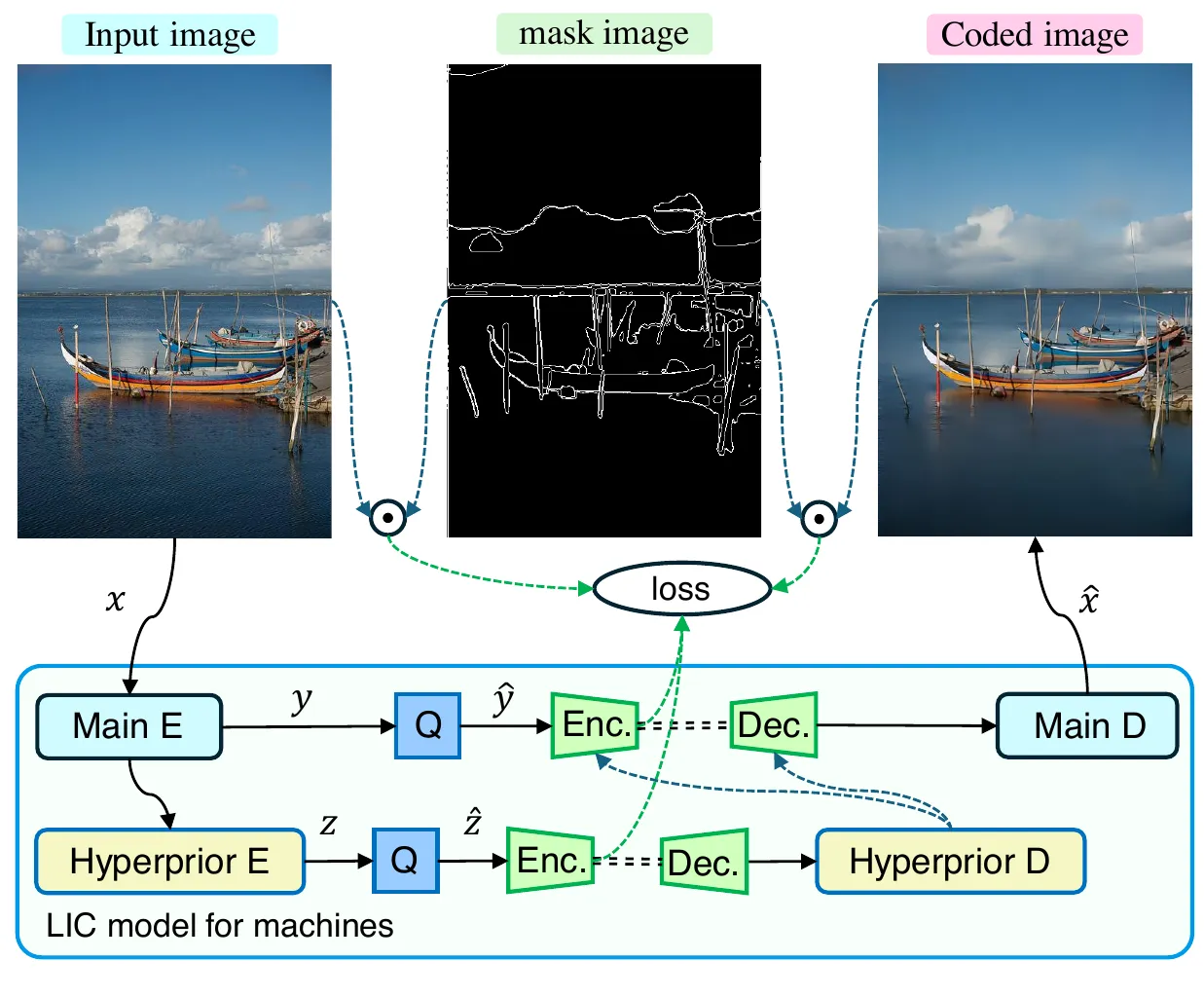
SA-ICM 的核心损失
这就是 SA-ICM 的 Eq. (5)。它和 Object-ICM 的 Eq. (3) 在形式上几乎完全相同,唯一替换是 \(m_x\to\mathrm{sam}_x(\alpha)\)。实验中作者固定 \(\lambda=0.05\),通过改变 \(\alpha\) 得到多个码率-精度工作点 #Shindo-et-al.-2024。
这套设计的直觉可以用一句话解释:让梯度只在边缘位置大声说话。如果某个像素不在 \(\mathrm{sam}_x(\alpha)\) 中,那么它对 MSE 几乎没有贡献;如果它位于物体边界、背景结构边缘或显著轮廓上,那么重建错误会被保留下来并反向传播。训练久了以后,codec 学到的不是“还原整张图”,而是“优先还原边缘”。
论文 Fig. 4 的视觉结果很好地说明了这种偏好。Object-ICM 仍然会保留物体区域内较多纹理;SA-ICM 则更彻底地去掉纹理,例如大象皮肤褶皱、草地碎屑、水面细浪、羊毛细节都会被磨平,但主体轮廓、前景/背景边界和显著结构仍然存在 #Shindo-et-al.-2024。

SA-ICM 不直接压缩二值边缘图,而是训练一个图像 codec 只重建边缘信息。从任务目标看,它和传统链码/线段编码有同一个底层逻辑:把边缘结构视为比纹理更重要的信息载体。
论文的第二个贡献是 SA-NeRV。NeRV 的基本思想是把一段视频嵌入到一个神经网络中:输入帧索引,输出对应视频帧;视频压缩可以转化为模型剪枝、量化和权重编码 #NeRV-2021。普通 NeRV 优化的是 L1 与 SSIM 组合,目标仍然偏向人类视觉重建:
NeRV 原始损失
其中 \(T\) 是视频总帧数,\(\beta\) 是 L1 与 SSIM 的平衡系数。SA-ICM 论文没有披露 \(\beta\) 的具体取值 #Shindo-et-al.-2024。
SA-NeRV 在这个基础上叠加了一项 mask 区域的 L1/SSIM 损失。也就是说,网络仍然要尽量重建整帧,但还会额外被惩罚:如果边缘 mask 区域重建不好,就多扣分 #Shindo-et-al.-2024。
SA-NeRV 损失
结构上,它就是“普通 NeRV 损失 + 边缘区域 NeRV 损失”。这相当于告诉网络:整帧可以粗一点,但物体位置和形状要记牢。
这个迁移说明 SA-ICM 的想法并不局限于某个 LIC backbone。它可以被理解为一种训练监督范式:只要模型有重建损失,就可以把 SAM 边缘 mask 乘进去,让重建目标从人眼纹理偏向机器可用边缘。
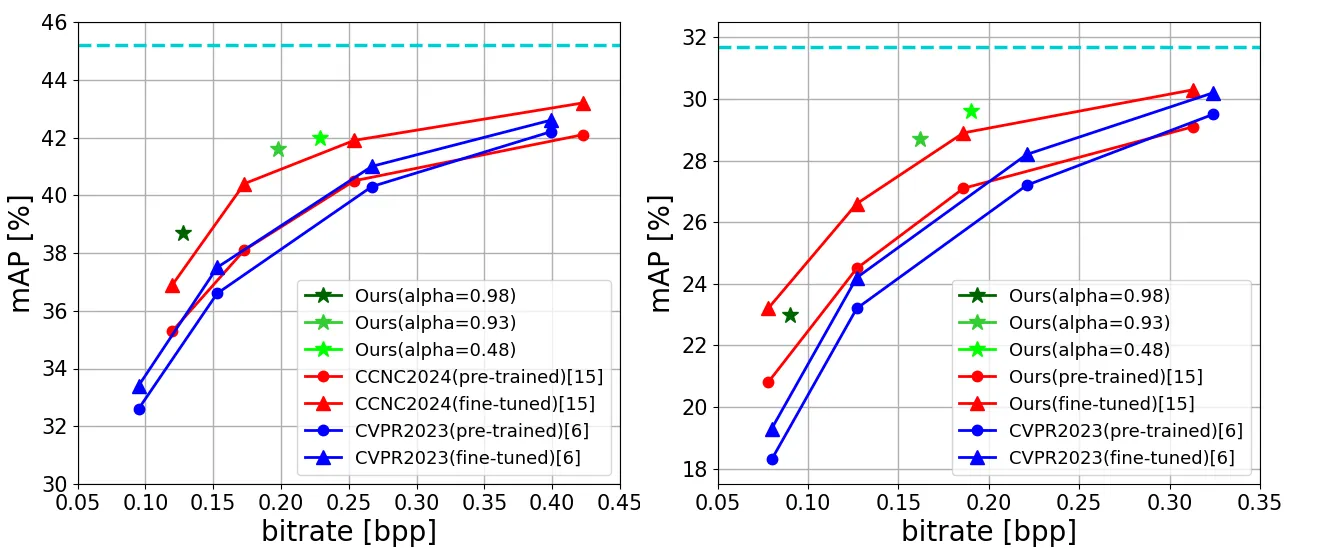
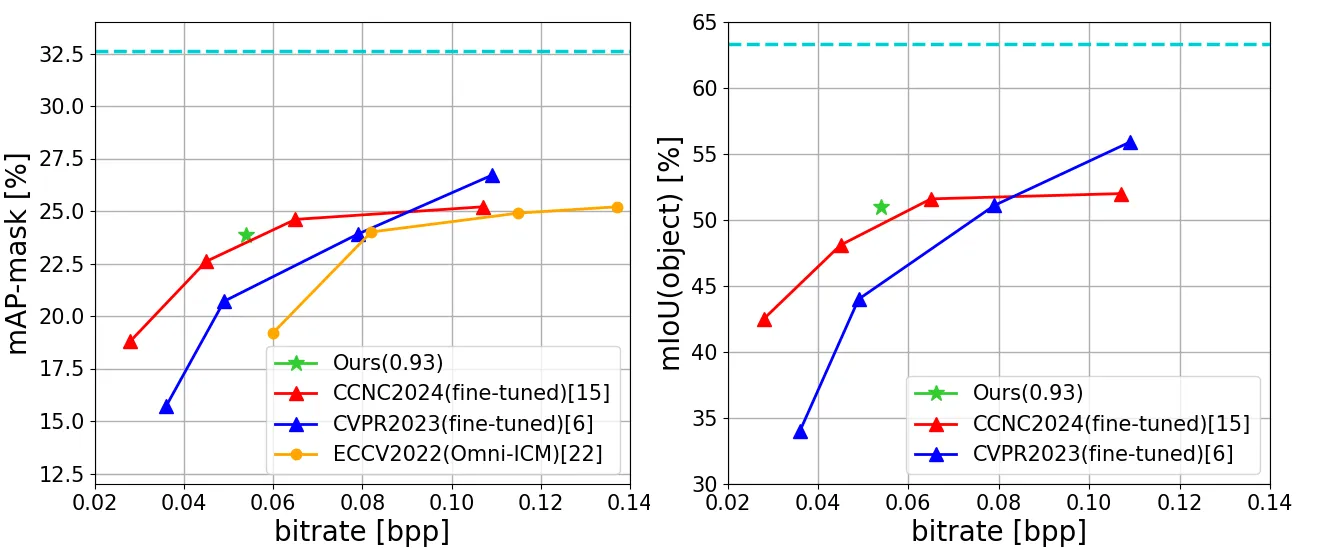
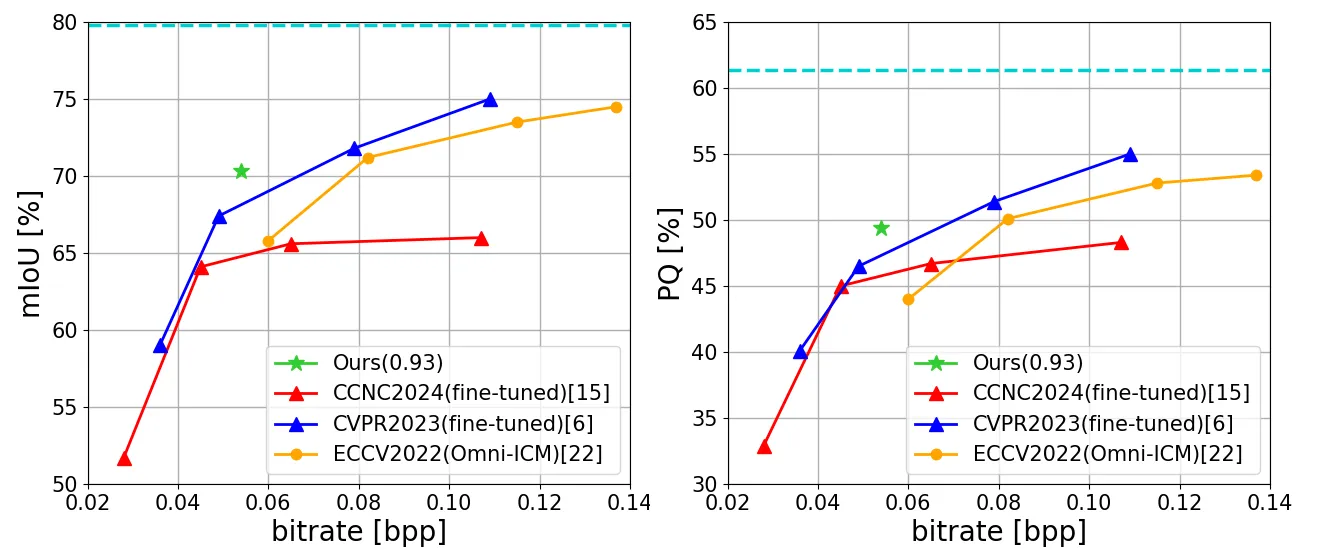
SA-ICM 的实验不以 PSNR 为主,而以机器视觉任务精度作为纵轴。作者先用 COCO-train 生成 SAM mask,设置 \(\alpha\in\{0.98,0.93,0.48\}\),用 Liu et al. 的 Mixed Transformer-CNN LIC 模型作为 backbone,并固定 \(\lambda=0.05\) 训练多个 SA-ICM 工作点 #LIC-TCM-2023 #Shindo-et-al.-2024。
官方仓库给出了推理脚本和预训练权重,README 中提供了 icm_78.pth.tar、icm_93.pth.tar 两档 ICM 权重,以及在压缩图像上训练的 yolov5_78.pt 和 yolov5_93.pt;测试阶段约 11GB 显存 GPU 即可运行,例如 1080 Ti 或 2080 Ti #SA-ICM-Code。这说明 SA-ICM 至少在推理侧是相对轻量的,但训练成本、优化器、学习率、batch size 和 epoch 在论文中没有完整披露。
| 实验维度 | 设置 |
|---|---|
| 训练 mask 来源 | COCO-train 图像经 SAM + Canny 生成 |
| SAM 阈值 | \(\alpha=0.98,0.93,0.48\) |
| LIC backbone | Liu et al. 2023 Mixed Transformer-CNN / LIC-TCM |
| 码率权衡 | \(\lambda=0.05\) |
| 检测模型 | YOLOv5,COCO 与 VisDrone;YOLOv5 使用压缩训练集 fine-tune |
| 实例分割/检测 | Mask-RCNN,COCO |
| 实例/全景分割 | Panoptic-DeepLab,Cityscapes |
| 视频实验 | SFU-HW-Objects-v1 的 C/D 类序列,YOLOv7 评估 |
这里有一个细节必须注意:YOLOv5 实验中,作者将训练数据也压缩后用于 fine-tune YOLOv5;而 Mask-RCNN 和 Panoptic-DeepLab 部分并没有同样描述 fine-tune 流程 #Shindo-et-al.-2024。所以 Fig. 5 与 Fig. 6-8 在严格意义上不是完全同一种评估协议。写论文或复现时,不能把它们简单混成“所有任务都零适配”。
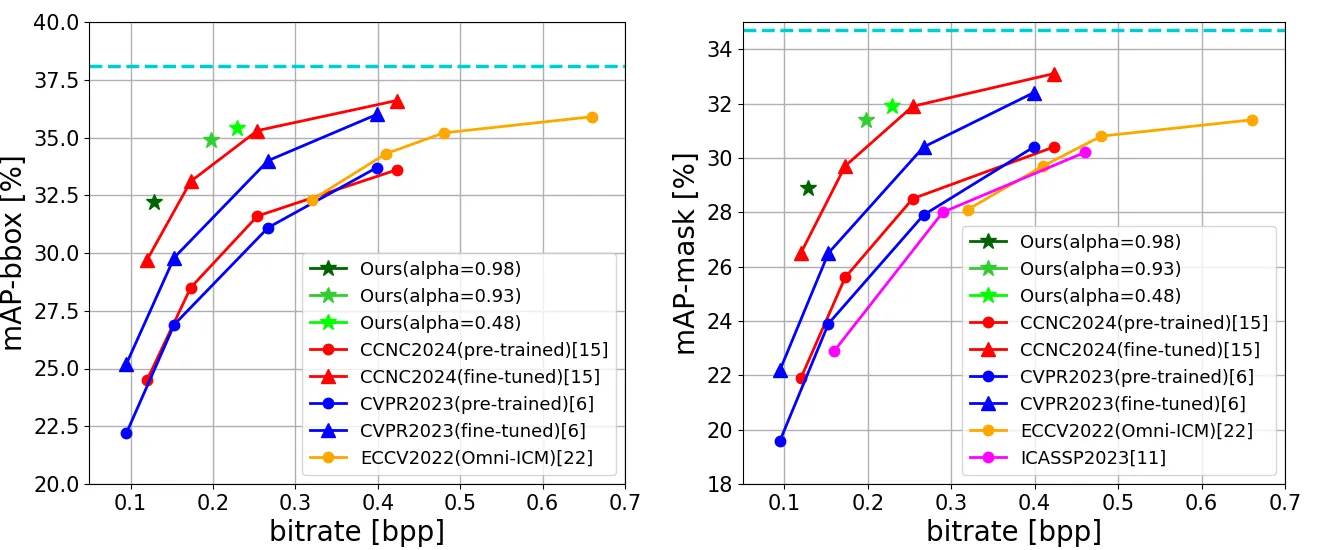
Panoptic-DeepLab 的两张图更能说明 SA-ICM 相对 Object-ICM 的核心价值。原 RL-based 方法只保物体区域,因此背景信息粗糙;而语义分割/全景分割恰恰需要背景结构。SA-ICM 的边缘 mask 会覆盖更多背景结构轮廓,所以在 Cityscapes 的实例分割和全景分割上更稳 #Panoptic-DeepLab-2020 #Shindo-et-al.-2024。
SA-NeRV 实验使用 SFU-HW-Objects-v1 数据集。该数据集包含 18 段带目标检测标注的 raw video sequences,并被用于 MPEG VCM 标准化活动中的 Common Test Condition #SFU-HW-Objects-2021。论文选择 C 类和 D 类序列,共 8 段,使用预训练 YOLOv7 测量 NeRV 与 SA-NeRV 解码视频上的目标检测 mAP #YOLOv7-2023 #Shindo-et-al.-2024。

| Sequence | NeRV mAP % | SA-NeRV mAP % | 提升 |
|---|---|---|---|
| BQMall | 28.03 | 28.24 | +0.21 |
| BasketballDrill | 34.26 | 34.93 | +0.67 |
| PartyScene | 34.34 | 34.61 | +0.27 |
| RaceHorsesC | 80.99 | 81.77 | +0.78 |
| BQSquare | 27.84 | 29.80 | +1.96 |
| BasketballPass | 23.29 | 24.88 | +1.59 |
| BlowingBubbles | 41.83 | 48.84 | +7.01 |
| RaceHorsesD | 89.12 | 88.98 | -0.14 |
Table 1 的结果是 8 段中 7 段 SA-NeRV 优于 NeRV,提升最大的是 BlowingBubbles,mAP 从 41.83 提升到 48.84,增加 7.01;唯一退步的是 RaceHorsesD,从 89.12 降到 88.98,差距只有 0.14 #Shindo-et-al.-2024。论文措辞也比较克制,用的是 “for most sequences” 而不是 “for all sequences”。
SA-ICM 的想法干净、图示直观、实验任务覆盖面也不错;但如果从复现和严谨比较角度看,仍有不少缺口。最重要的是,论文 Fig. 5-8 主要对比的是原 RL-based / Object-ICM 路线,并没有把 ROI-based 和 Task-loss-based 方法重新拿来实测。因此,“SA-ICM 最优”的范围更准确地说是:在作者设定的 RL-based 对比框架内,它比 Object-ICM 更好 #Object-ICM-2024 #Shindo-et-al.-2024。
| 未披露项 | 为什么重要 |
|---|---|
| SA-NeRV 的 \(\alpha\) 取值 | 视频实验的边缘密度无法精确复现 |
| NeRV 损失中的 \(\beta\) | L1 与 SSIM 权重会影响边缘/纹理平衡 |
| 优化器、学习率、batch size、epoch | 深度学习实验基本复现条件缺失 |
| GPU 型号、训练时长、显存 | 无法估计训练成本;README 只说测试约 11GB 显存足够 #SA-ICM-Code |
| SAM 模型大小 | ViT-B/L/H 的 mask 质量和速度不同 |
| Canny 阈值 | 边缘 mask 密度直接依赖 Canny 参数 |
| YOLOv5 fine-tune 细节 | Fig. 5 的检测结果与 fine-tune 协议强相关 |
此外,论文将 \(\alpha\) 当成码率-精度曲线的扫描变量,但 \(\alpha\) 和 \(\lambda\) 并不等价。\(\lambda\) 改的是 rate-distortion 权重,\(\alpha\) 改的是边缘 mask 内容;一个调优化强度,一个调监督区域。论文在实验中用改变 \(\alpha\) 的方式得到多个 compression performance points,但没有给出理论解释或 BD-rate 类型统计 #Shindo-et-al.-2024。
论文摘要说 SA-ICM 会在编码端去除人脸信息,具有隐私保护收益;Fig. 4 也确实显示人脸纹理被抹掉。但论文没有做人脸检测率、身份识别准确率或 privacy attack 的定量实验。因此这只能作为定性附带收益,而不是严格隐私保证。
SA-ICM 的技术难度不在于网络结构,而在于问题设定。它没有设计新的熵模型,没有提出复杂的 transformer block,也没有让 SAM 进入推理链路。它只是把 SAM 的 segmentation map 取边缘,再把这些边缘作为 MSE 的空间权重。正是这个小改动,把学习式图像压缩的目标从“复原纹理”推向“保留机器任务需要的结构”。
从边缘图像压缩系列的角度看,SA-ICM 是一个很好的现代样本。传统路线会直接压缩二值边缘图,例如 RLE、JBIG2、链码、线段编码;SA-ICM 则训练一个神经 codec,让它输出“接近边缘图的自然图像重建”。两者形式不同,但内核相同:纹理不是第一优先级,结构才是。
当然,下一步真正有研究价值的问题不是“复现 SA-ICM”,而是问:边缘是否总是足够?不同任务需要哪类边缘?纹理、颜色、热强度和几何结构之间怎样分配码率?如果这些问题能被系统回答,边缘图像压缩就不只是一个小众红外问题,而会成为 Coding for Machines 中一条重要的结构优先路线。
参考来源
- Shindo, T., Yamada, K., Watanabe, T., & Watanabe, H. (2024). Image Coding for Machines with Edge Information Learning Using Segment Anything. IEEE ICIP 2024 / arXiv:2403.04173. arXiv HTML
- final-0. SA-ICM official implementation. GitHub
- Choi, H., & Bajić, I. V. (2022). Scalable Image Coding for Humans and Machines. IEEE Transactions on Image Processing, 31, 2739–2754. arXiv
- Choi, H., & Bajić, I. V. (2018). High Efficiency Compression for Object Detection. ICASSP 2018. arXiv
- Shindo, T., Watanabe, T., Yamada, K., & Watanabe, H. (2024). Image Coding for Machines with Object Region Learning. IEEE CCNC / arXiv:2308.13984. arXiv
- Kirillov, A. et al. (2023). Segment Anything. ICCV 2023. arXiv
- Chen, H. et al. (2021). NeRV: Neural Representations for Videos. NeurIPS 2021. arXiv
- Liu, J., Sun, H., & Katto, J. (2023). Learned Image Compression with Mixed Transformer-CNN Architectures. CVPR 2023. arXiv
- Bégaint, J., Racapé, F., Feltman, S., & Pushparaja, A. (2020). CompressAI: a PyTorch library and evaluation platform for end-to-end compression research. arXiv
- Cheng, B. et al. (2020). Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. CVPR 2020. arXiv
- Choi, H. et al. (2021). A dataset of labelled objects on raw video sequences. Data in Brief, 34:106701. DOI
- Wang, C.-Y., Bochkovskiy, A., & Liao, H.-Y. M. (2023). YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. CVPR 2023. arXiv
- MPEG. Video Coding for Machines exploration. MPEG Standards
- Streaming Learning Center. Real-Time Feature Coding for Machines: Inside the New MPEG Standard. Article
- JPEG Committee. JPEG AI. Official page
- Takahiro Shindo. Personal homepage and publications. Homepage
- Waseda University. Hiroshi Watanabe researcher profile. Profile