数字人论文精读(二十四):UIKA
想象一下:你只需要用手机自拍一张照片,AI 就能在几秒内生成一个 3D 数字分身——这个分身可以从任意角度观看,能做出任何表情,还能以 220 FPS 实时渲染。这不是科幻,而是 CVPR 2026 Highlight 论文 UIKA 做到的事情。
在远程会议、影视制作、VR/AR 等场景中,创建逼真的 3D 头部头像一直是核心需求。传统方法需要专业级多视角相机阵列 + 长时间的逐身份优化训练,成本高昂且无法泛化。近年来,前馈式(feed-forward)方法开始兴起——它们试图从一张或几张图片中"一次前馈"直接生成头像,无需逐身份训练。但现有方法要么只支持单图输入(大视角下退化严重),要么要求固定数量输入(如必须恰好 4 张),要么虽然支持任意数量却缺乏跨帧的显式对应关系。
UIKA 的答案是:用 UV 映射作为"通用语言"来连接不同视角和表情的图像。通过面部对应估计,它把每张输入图像的像素对齐到 canonical UV 空间,再通过创新的双流注意力(screen + UV)和自自适应融合策略,生成高质量、可实时驱动的 3D Gaussian 头部头像。
论文地址:https://arxiv.org/abs/2601.07603 | 代码:https://github.com/zijian-wu/uika | 项目页:https://zijian-wu.github.io/uika-page/

要理解 UIKA 的价值,我们首先需要看清当前方法的格局与缺口。下表展示了 UIKA 与 SOTA 方法在三个关键维度上的对比:
| 方法 | 输入数量 | 前馈 (FF) | Pose-Free (PF) | 实时动画 (RTA) |
|---|---|---|---|---|
| GAGAvatar | 1 | ✓ | ✓ | ✓ |
| LAM | 1 | ✓ | ✓ | ✓ |
| Avat3r | 4 | ✓ | ✗ | ✗ |
| GPAvatar | ≥1 | ✓ | ✓ | ✗ |
| InvertAvatar | ≥1 | ✗ | ✗ | ✗ |
| DiffusionRig | ≥1 | ✗ | ✗ | ✗ |
| UIKA | ≥1 | ✓ | ✓ | ✓ |
可以看到,没有任何已有方法在全部四个维度上同时满足:GAGAvatar 和 LAM 虽然支持单图前馈,但大视角下渲染质量显著退化;Avat3r 虽然支持多视角,但要求固定 4 张输入且需要相机标定;GPAvatar 和 PF-LHM 支持任意数量输入,但缺乏跨帧的显式对应关系,导致多视角信息聚合不够可靠——甚至输入图像越多,效果反而可能退化。
反直觉的发现是:问题的核心不在于"多接收几张图",而在于"如何让不同视角的像素对上号"。不同视角、不同表情的图像在 screen space 中天然没有对齐——左上角的一个像素在第一张图里是左眼,在第二张图里可能是额头。这就是为什么简单地把多张图的特征 concat 起来做 attention 效果有限。
UIKA 的核心洞察:如果能把每张图的人脸像素映射到同一个 canonical UV 空间,就自然解决了跨帧对齐问题。UV 映射是人脸参数化模型的天然属性——FLAME 模型已经定义了每个人脸三角形在 UV 空间中的位置。只要知道每个像素的 UV 坐标,就能把不同图像的像素"汇聚"到同一个 UV 画布上。
什么是 Canonical UV 空间?
UV 空间是 3D 人脸模型(如 FLAME)的二维参数化展开——就像把地球仪摊平成一张世界地图。每个三维人脸顶点都对应 UV 空间中的一个 \((u,v)\) 坐标,这个映射对所有人脸模型是固定的。
Canonical 意味着这个 UV 空间是"标准姿态"下的——不做任何表情、不偏转任何角度。不管输入图像里的人是什么表情、什么角度,只要我们知道每个像素对应 canonical UV 空间的哪个位置,就能把不同图像的内容"贴"到同一张标准地图上,实现跨帧对齐。
类比:不同角度拍的建筑照片,只要知道每张照片的像素对应建筑 CAD 模型的哪个面,就能把所有照片拼成一张完整的建筑立面图。UV 空间就是人脸的"标准 CAD 图纸"。
UIKA 的完整 Pipeline 分为五个阶段,如架构图所示:
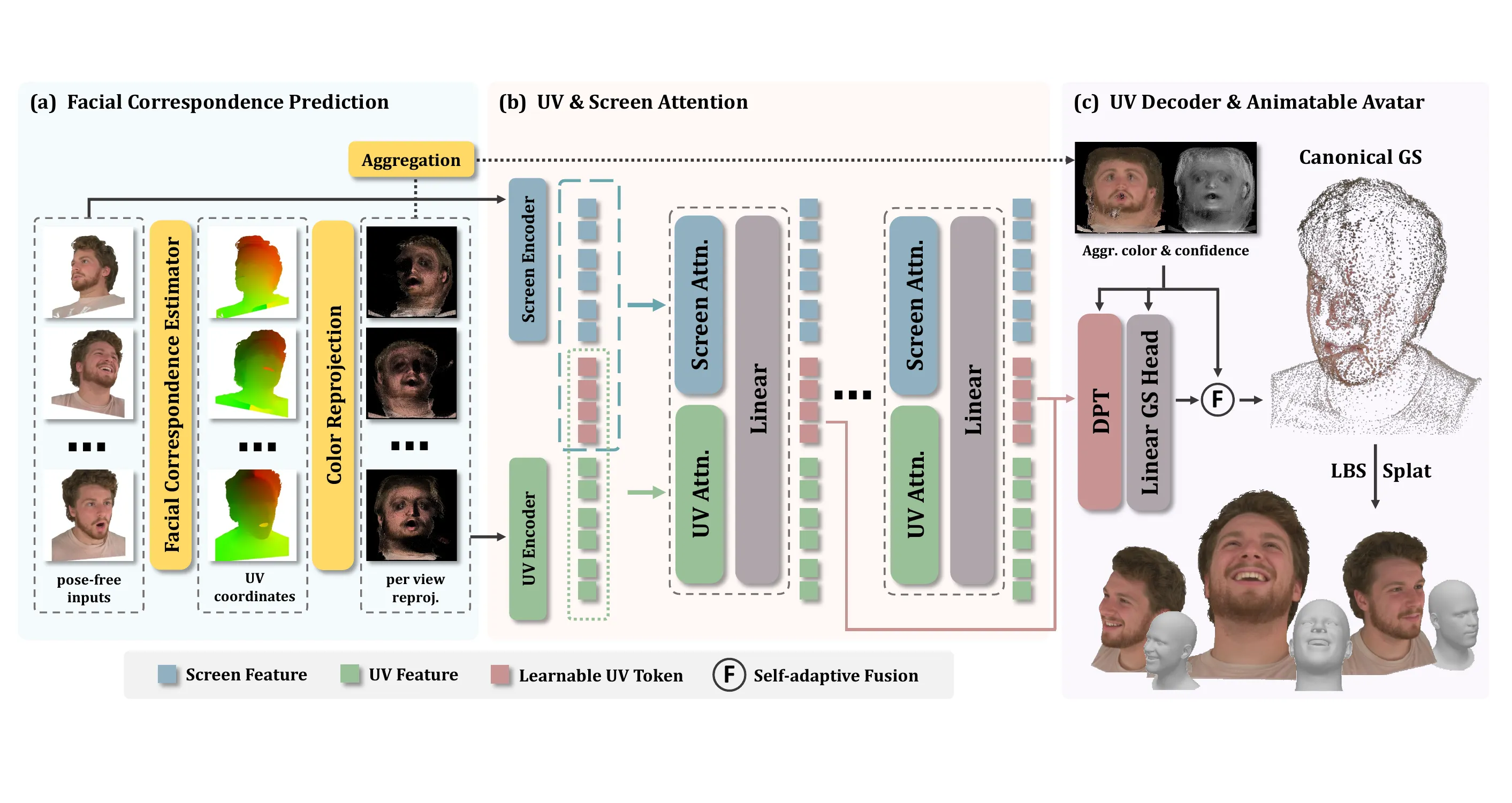
3.1 面部对应估计与颜色重投影
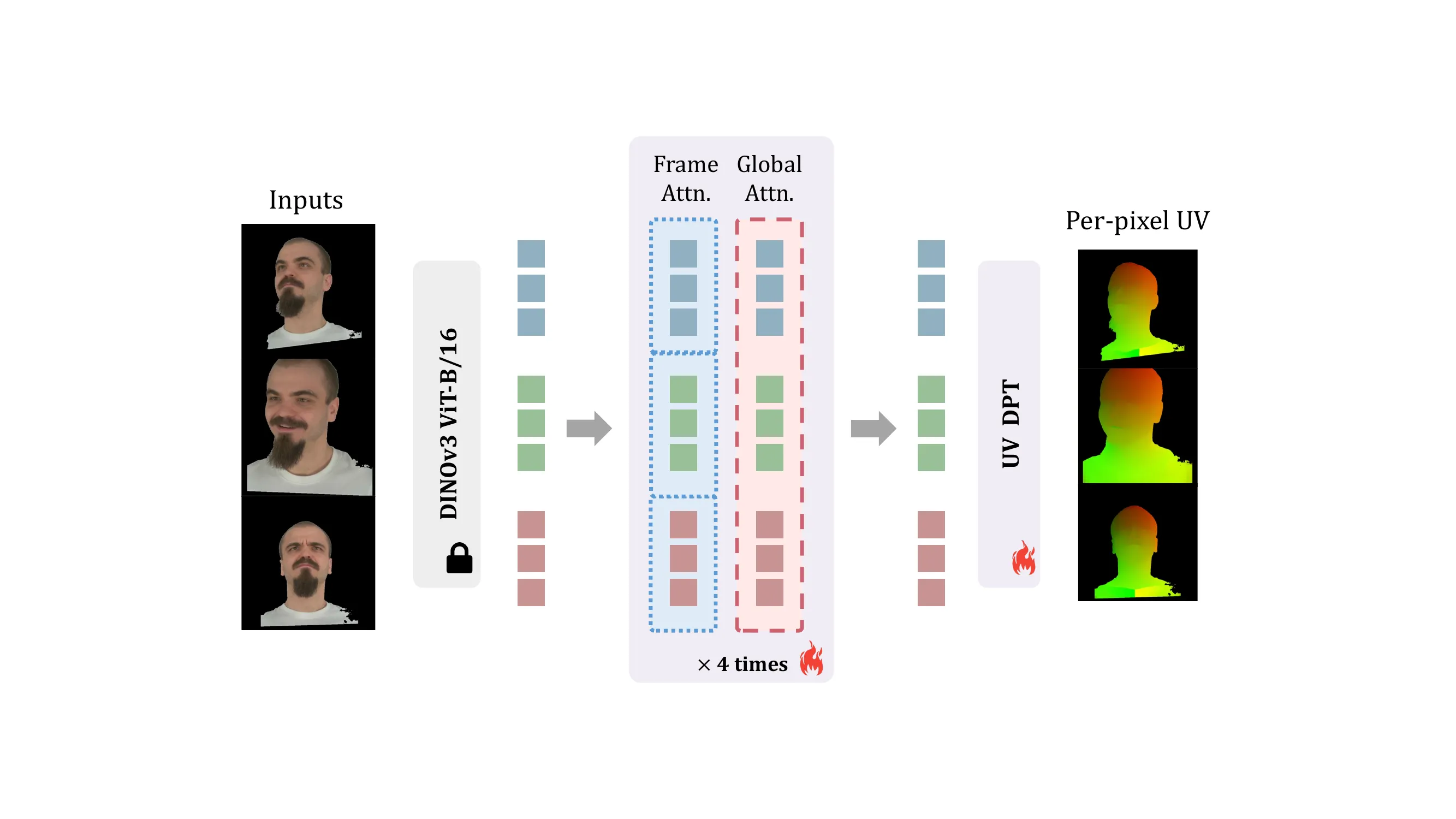
Pipeline 的第一阶段是面部对应估计器(Facial Correspondence Estimator)。给定任意数量 \(N\) 张 pose-free 输入图像 \(\{\mathrm{I}^i_{\text{s}}\}_{i=1}^N\),它逐像素预测 UV 坐标:
其中 \(\mathrm{U}^i = (u, v) \in [0,1]^2\) 是像素级 UV 坐标,\(\mathcal{U}\) 采用 frozen DINOv3 编码器 + 可训练 DPT head 的架构,受 Pixel3DMM 启发 #Giebenhain-et-al.-2026。
什么是 DPT 架构?传入 DPT 的是什么?
DPT(Dense Prediction Transformer)是一种将 ViT(Vision Transformer)从图像分类改造为密集预测任务(如深度估计、语义分割)的架构。它的核心思想是:ViT 在全局 self-attention 过程中天然保留了空间信息,DPT 通过将不同层的 token 重组为多尺度特征图,再融合上采样,就能输出与原图分辨率一致的密集预测结果。
在 UIKA 中,数据流是:输入图像 → frozen DINOv3 编码器 → patch tokens(特征序列)→ 可训练的 DPT head → 像素级 UV 坐标。DINOv3 把 512×512 的输入图像编码为一组 patch 级别的特征向量,DPT head 接收这些特征,通过重组和上采样,最终输出每个像素在 canonical UV 空间中的 \((u,v)\) 坐标。DINOv3 是冻结的(不参与训练),只训练 DPT head 和后续的轻量 CNN fusion 模块,这样既利用了预训练模型的强大视觉表征,又大幅降低了训练开销。
对应估计器的详细架构
补充材料中给出了对应估计器 \(\mathcal{U}\) 的完整网络结构。它由三部分组成:
- Frozen DINOv3 ViT-L/16:提取 patch 级特征,输出 \(\mathcal{N} \times 1024 \times 1024\) 的特征(\(\mathcal{N}\) 为输入图像数)。
- 4 层交替 Attention:受 VGGT 启发,交替使用 Frame Attention(单帧内 self-attention,捕获帧内空间关系)和 Global Attention(跨所有帧 attention,建立帧间对应)。这种层次化设计让网络既能理解局部人脸结构,又能推理全局多视图一致性。
- 可训练 DPT Head:将多尺度特征融合后输出 2 通道 UV 坐标图 \((\in [0,1])\),再乘以输入图像 mask 提取有效人脸区域。

有了 UV 坐标,就可以把每张输入图像从 screen space 重投影到 UV space:
然后对所有重投影图像做逐像素平均,得到聚合 UV 图像 \(\mathrm{I}_{\text{aggr}}\) 和置信度图 \(\gamma_{\text{aggr}}\):
置信度的计算方式很巧妙:\(\gamma_{\text{aggr}} = \operatorname{Norm}(\log(1 + n_{\text{hit}}))\),其中 \(n_{\text{hit}}\) 是该 UV 像素被多少张输入图像"命中"。用 log 压制高频区域(如正脸)的主导地位,让侧脸区域也能获得合理的置信度。
3.2 双流注意力:Screen + UV
这是 UIKA 最核心的创新。已有方法(如 LAM、GPAvatar)只用 screen space 的 cross-attention——learnable tokens 只与原始图像的特征交互,缺乏结构化对应关系。
UIKA 在标准 screen attention 之外,增加了一个 UV attention 分支:
这里 \(\mathcal{Z}\) 是 learnable UV tokens(9216 个,reshape 为 96×96 网格),\(\mathcal{F}_{\text{s}}\) 和 \(\mathcal{F}_{\text{uv}}\) 分别是 screen 和 UV 空间的多尺度特征(由 frozen DINOv3 + 轻量 CNN fusion 模块提取)。
两个 attention 分支的增量直接相加——screen attention 提供局部细节(纹理、边缘),UV attention 提供结构化全局上下文(人脸拓扑、语义区域)。12 层 MM-DiT Transformer 块 #Esser-et-al.-2024 在每个 block 中同时执行两种 attention。
3.3 UV Decoder 与自自适应融合
从 Transformer 的 4 个深度层(\(l=3,6,9,12\))取出 UV tokens,与聚合 UV 图 \(\mathrm{I}_{\text{aggr}}\) 和置信度 \(\gamma_{\text{aggr}}\) 一起送入 UV Decoder:
Decoder 采用 DPT 架构,输出 384×384 的 UV 特征图。通过 FLAME UV rasterization 获取有效 UV mask,从中采样约 130K 个点,经 2 层 FC + per-attribute MLP 解码为 Gaussian 属性。
送入 UV Decoder 的三样东西
UV Decoder 的输入来自三个来源,汇聚了前序所有阶段的成果:
- \(\mathcal{Z}^l\)(多层 UV tokens):从 Transformer 的 \(l=3,6,9,12\) 四个深度层取出的 learnable UV tokens(9216 个,reshape 为 96×96 网格)。这些 tokens 经过 12 层 screen + UV 双流 attention 的反复提炼,已经融合了输入图像的全部语义信息——浅层保留局部细节,深层编码全局结构。
- \(\mathrm{I}_{\text{aggr}}\)(聚合 UV 图像):来自 Phase 1 的颜色重投影与聚合阶段。所有输入图像通过 UV 坐标映射后逐像素平均,得到一张"摊平的人脸纹理图"。它提供了来自真实图像的观测色彩,补足网络预测色可能缺失的细节。
- \(\gamma_{\text{aggr}}\)(置信度图):同样来自聚合阶段,记录每个 UV 像素被多少张输入图像"命中"。它告诉 Decoder 哪些区域观测充分(可信度高)、哪些区域观测不足(需要网络预测来补)。
这三者通过 DPT 架构融合:tokens 提供语义信息,\(\mathrm{I}_{\text{aggr}}\) 提供观测色彩,\(\gamma_{\text{aggr}}\) 作为注意力权重调节两者的贡献——最终输出 384×384 的 UV 特征图。
最关键的设计是自自适应融合(Self-Adaptive Fusion):
每个 Gaussian 学习一个标量融合权重 \(w_k\),在"网络预测色"和"实际观察色"之间动态平衡:
- 当该区域被多张图像覆盖时,\(w_k\) 偏小 → 倾向使用观察色(细节更真实)
- 当该区域被遮挡或覆盖不足时,\(w_k\) 偏大 → 倾向使用预测色(更连贯)
完整超参数一览
补充材料中提供了详细的超参数配置,对复现至关重要:
| 模块 | 超参数 | 值 |
|---|---|---|
| 输入/输出 | 输入分辨率 / 渲染分辨率 | 512×512 |
| 特征提取器 | DINOv3 版本 | ViT-L/16 |
| 特征尺寸 | \(\mathcal{N}\times 1024\times 1024\) | |
| 使用的中间层 | 4, 11, 17, 23 | |
| Transformer | 隐藏维度 / 头数 / 层数 | 1024 / 16 / 12 |
| Learnable UV token 尺寸 | 96×96×1024 | |
| UV Decoder | Gaussian 属性图尺寸 | 384×384 |
| DPT 内部维度 / MLP 维度 | 256 / 512 | |
| MLP 层数 / 激活函数 | 3 / SiLU | |
| Gaussian | 偏移最大范围 / 缩放裁剪 | 0.2 / 0.01 |
| 初始缩放 / 初始密度 | \(\exp(-5.0)\) / 0.1 |
关键看点:DINOv3 用的是 ViT-L/16(比常见的 ViT-B/16 更大),UV tokens 尺寸为 96×96=9216 个 learnable tokens,Transformer 有 12 层、1024 维、16 头,整体规模不小。
这是一种优雅的"soft selection"机制,比硬阈值或全局融合权重精细得多。
3.4 动画驱动:FLAME LBS + 3DGS 渲染
重建的 canonical Gaussian 头像通过 FLAME 的线性混合蒙皮(LBS)驱动动画:
其中 \(\Theta\) 是目标 FLAME pose + expression 参数,\(\Pi\) 是相机参数。渲染通过标准 differentiable Gaussian splatting rasterizer,达到 220 FPS,无需额外神经渲染器(与 GAGAvatar、GPAvatar 等需要额外网络做后处理的方法形成鲜明对比)。
训练数据
UIKA 在四个数据集上联合训练:
- VFHQ:高质量单目人脸视频,提供丰富的身份和表情多样性
- HDTF:高分辨率 talking-head 视频,侧重语音驱动表情
- NeRSemble-v2:多视角 studio 数据集,提供 3D 一致性监督
- 合成数据集:UIKA 自建的大规模多视角合成数据(7500+ 身份,每身份 9 视角 × 13000+ 帧)
合成数据管线是 UIKA 的另一个亮点。传统多视角数据集(如 NeRSemble、RenderMe-360)受限于采集成本,身份数量少且多为 studio 光照,难以泛化到 in-the-wild 场景。UIKA 的解决方案:
flowchart TD A["SphereHead 3D 头部生成器"] --> B["每身份渲染 9 个固定视角"] B --> C["LivePortrait 2D 面部动画"] C --> D["同一 motion library 驱动所有视角"] D --> E["时间同步的多视角序列"] E --> F["7500+ 身份,含极端表情"]
先用 SphereHead #Li-et-al.-2024(在 in-the-wild 图像上训练的 3D 头生成器)渲染 9 个固定视角,再用 LivePortrait #Guo-et-al.-2024 从 motion library 中选取驱动视频统一驱动所有视角,生成时间同步的多视角序列。

合成数据集质量评估
补充材料中通过 Warping Error(WE)评估了合成数据质量:UIKA 的合成数据空间 WE 为 4.252×10⁻²,时间 WE 为 7.868×10⁻⁴,数值上接近真实采集的 NeRSemble-v2(2.377/4.605),远优于 CAP4D 合成数据(10.45/31.27)。这表明 UIKA 的合成管线在身份多样性、表情丰富度和多视图一致性之间取得了平衡。
数据处理
所有数据通过 VHAP tracker 提取 FLAME 2023 的 pose/expression 参数和相机参数,遵循 GaussianAvatars 的预处理协议。输入图像经过人脸检测、扩大 bbox、crop 到 512×512,并随机替换背景为黑/白/灰三色(一种简单但有效的 domain randomization)。
训练采样与损失函数
每次训练迭代,从同一视频随机采样 \(N_{\text{ref}} = 16\) 帧作为 source 输入(重建 canonical 表示),再采样 \(N_{\text{d}} = 8\) 帧作为 target views(驱动 + 监督)。
损失函数由四部分组成:
其中 \(\lambda_{\text{l1}} = 1.0\)、\(\lambda_{\text{lpips}} = 1.0\)、\(\lambda_{\text{ssim}} = 0.1\)、\(\lambda_{\text{reg}} = 0.1\)。L1 + SSIM + LPIPS 的组合是 3DGS/NeRF 领域的标配,offset regularization 防止 Gaussian 飘离 FLAME 表面太远。
| 配置项 | 值 | 披露状态 |
|---|---|---|
| Transformer 架构 | 12 层 MM-DiT,16 注意力头,D=1024 | 完整披露 |
| Learnable UV tokens | 9216 → reshape 96×96 | 完整披露 |
| UV 特征图分辨率 | 384×384×256 | 完整披露 |
| 最终 Gaussian 点数 | ~130K | 完整披露 |
| 训练步数 | 150K | 完整披露 |
| 优化器 | Adam + cosine warm-up LR schedule | 部分披露(β1/β2/weight decay 未给出) |
| 训练硬件 | 32 × NVIDIA H20 GPU | 完整披露 |
| 训练时间 | 约 2 周 | 完整披露 |
| Batch size per GPU | 未披露 | 未披露 |
| 模型总参数量 | 未披露 | 未披露 |
UIKA 的推理链路极其简洁,这得益于其纯前馈设计——无需任何测试时优化或微调:
flowchart TD A["输入: 任意数量 Pose-Free 图像"] --> B["Facial Correspondence Estimator"] B --> C["颜色重投影 & UV 聚合"] C --> D["双空间特征提取 (DINOv3)"] D --> E["12 层 MM-DiT 双流注意力"] E --> F["UV Decoder 解码 Gaussian 属性"] F --> G["自自适应融合"] G --> H["Canonical 3DGS 头像"] H --> I["FLAME 参数驱动 LBS 动画"] I --> J["3DGS Rasterizer 渲染"] J --> K["输出: 220 FPS 实时渲染"]
推理速度是 UIKA 的一大亮点。与 GAGAvatar、GPAvatar 等方法需要额外神经渲染器做后处理不同,UIKA 的 Gaussian 头像直接通过标准 3DGS rasterizer 渲染,达到 220 FPS。对比之下,DiffusionRig 的推理需要约 30 分钟(per identity 微调 + 迭代去噪)。
动画驱动也非常简单:给定目标 FLAME pose 和 expression 参数,通过 LBS 将 canonical Gaussian 变换到 posed space,然后差分光栅化渲染即可。这意味着 UIKA 可以轻松集成到现有的面部捕捉 + 驱动管线中。
实验配置
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 训练数据集 | VFHQ + HDTF + NeRSemble-v2 + 合成数据 | 完整披露 |
| 测试集 (Monocular) | VFHQ(50 clips) + NeRSemble-v2(25 identities) | 完整披露 |
| 测试集 (Multi-view) | NeRSemble-v2(25 identities) | 完整披露 |
| 训练硬件 | 32 × H20 GPU | 完整披露 |
| 推理硬件 | 未披露(单卡即可) | 未完整披露 |
| 评估指标 | PSNR / SSIM / LPIPS / CSIM / AED / APD / AKD | 完整披露 |
| FLAME Tracker | VHAP | 完整披露 |
| 人脸检测 | GAGAvatar 方法 | 完整披露 |
Monocular 设置:单图输入全面领先
在单图输入(monocular)设置下,UIKA 在所有指标上全面超越 GAGAvatar、LAM 和 Portrait4D-v2:
| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | CSIM↑ | AED↓ | APD↓ |
|---|---|---|---|---|---|---|
| Portrait4D-v2 | 21.03 | 0.859 | 0.134 | 0.688 | 0.094 | 0.113 |
| GAGAvatar | 20.34 | 0.850 | 0.160 | 0.693 | 0.071 | 0.075 |
| LAM | 18.29 | 0.810 | 0.206 | 0.602 | 0.104 | 0.112 |
| UIKA | 21.69 | 0.867 | 0.105 | 0.738 | 0.055 | 0.056 |
这些数字说明了什么?PSNR 提升 0.66(vs Portrait4D-v2)看起来不大,但 LPIPS 从 0.134 降到 0.105(↓22%)和 AED 从 0.094 降到 0.055(↓41%)说明 UIKA 在感知质量和表情精度上有质的飞跃。特别是 LAM 的 PSNR 只有 18.29——当 target view 与 source view 差异较大时,仅靠 screen attention 的模型确实撑不住。

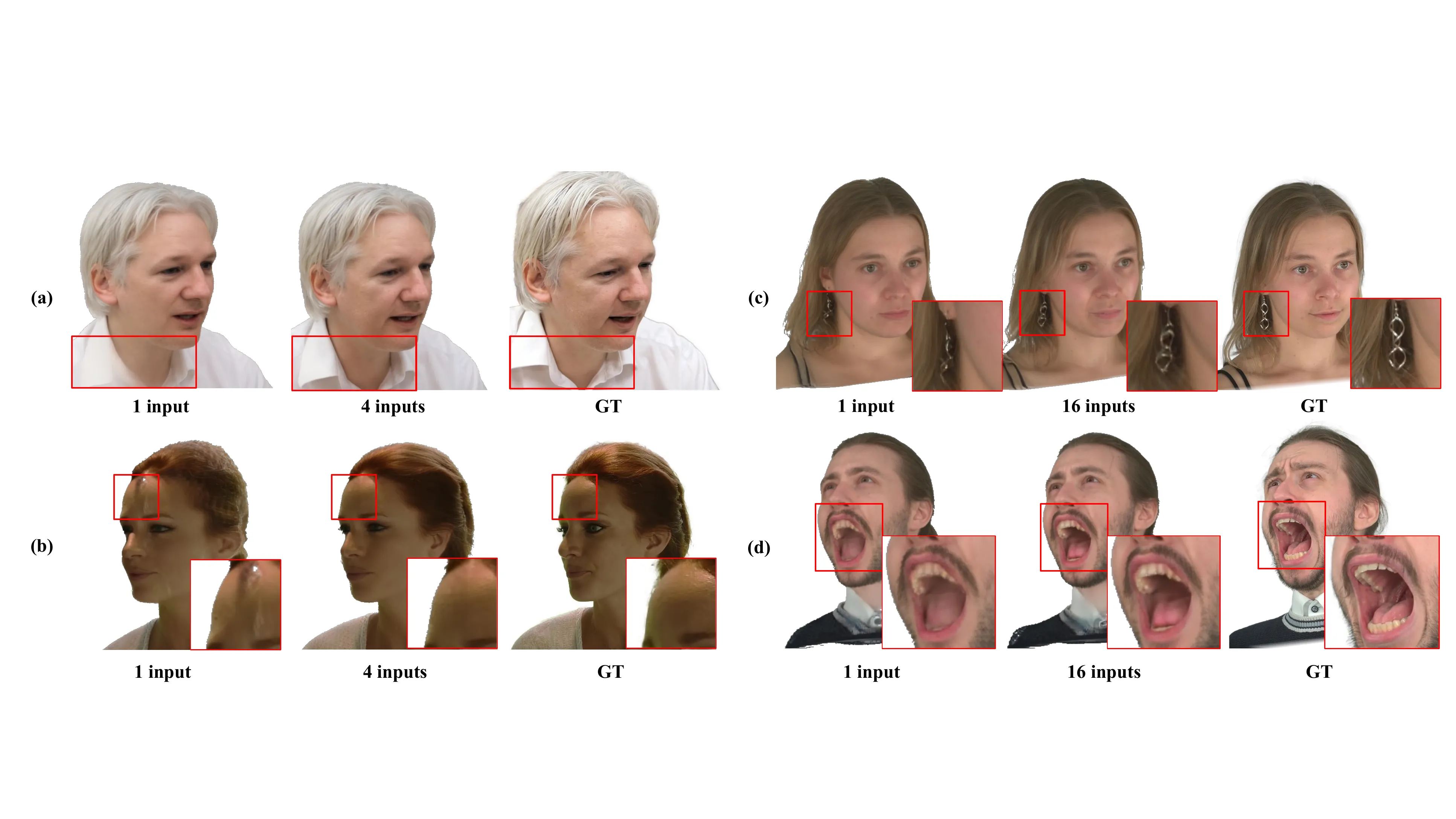
Multi-view 设置:多图输入优势更明显
在多视角输入设置下,UIKA 的优势进一步扩大:
| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | CSIM↑ |
|---|---|---|---|---|
| DiffusionRig | 16.97 | 0.768 | 0.395 | 0.598 |
| GPAvatar | 17.11 | 0.783 | 0.313 | 0.553 |
| InvertAvatar | 16.35 | 0.776 | 0.394 | 0.449 |
| UIKA | 22.50 | 0.855 | 0.120 | 0.740 |
PSNR 领先第二名 5.39 dB——这是巨大的差距。GPAvatar 和 InvertAvatar 虽然支持任意数量输入,但由于缺乏显式对应,多图信息聚合反而可能引入噪声。UIKA 的 UV 引导建模让输入图像越多,重建质量越好——这才是多视角输入的正确打开方式。
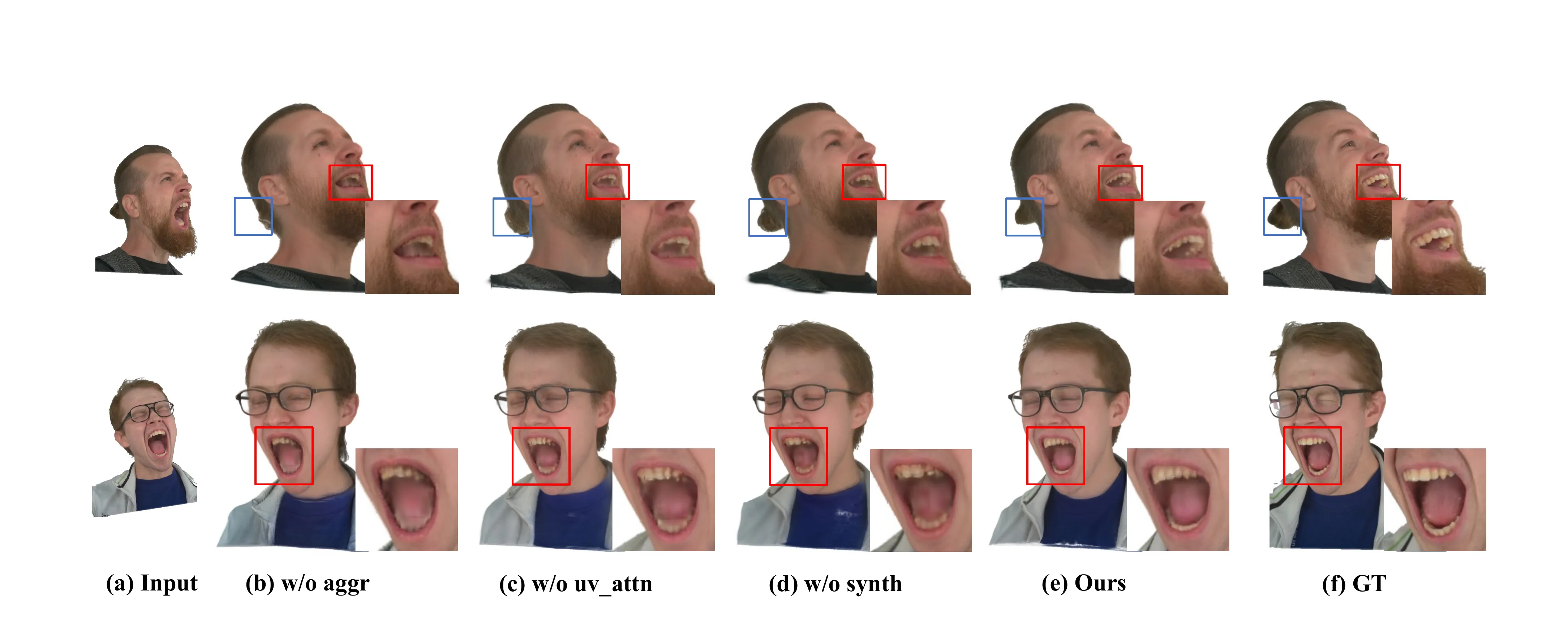
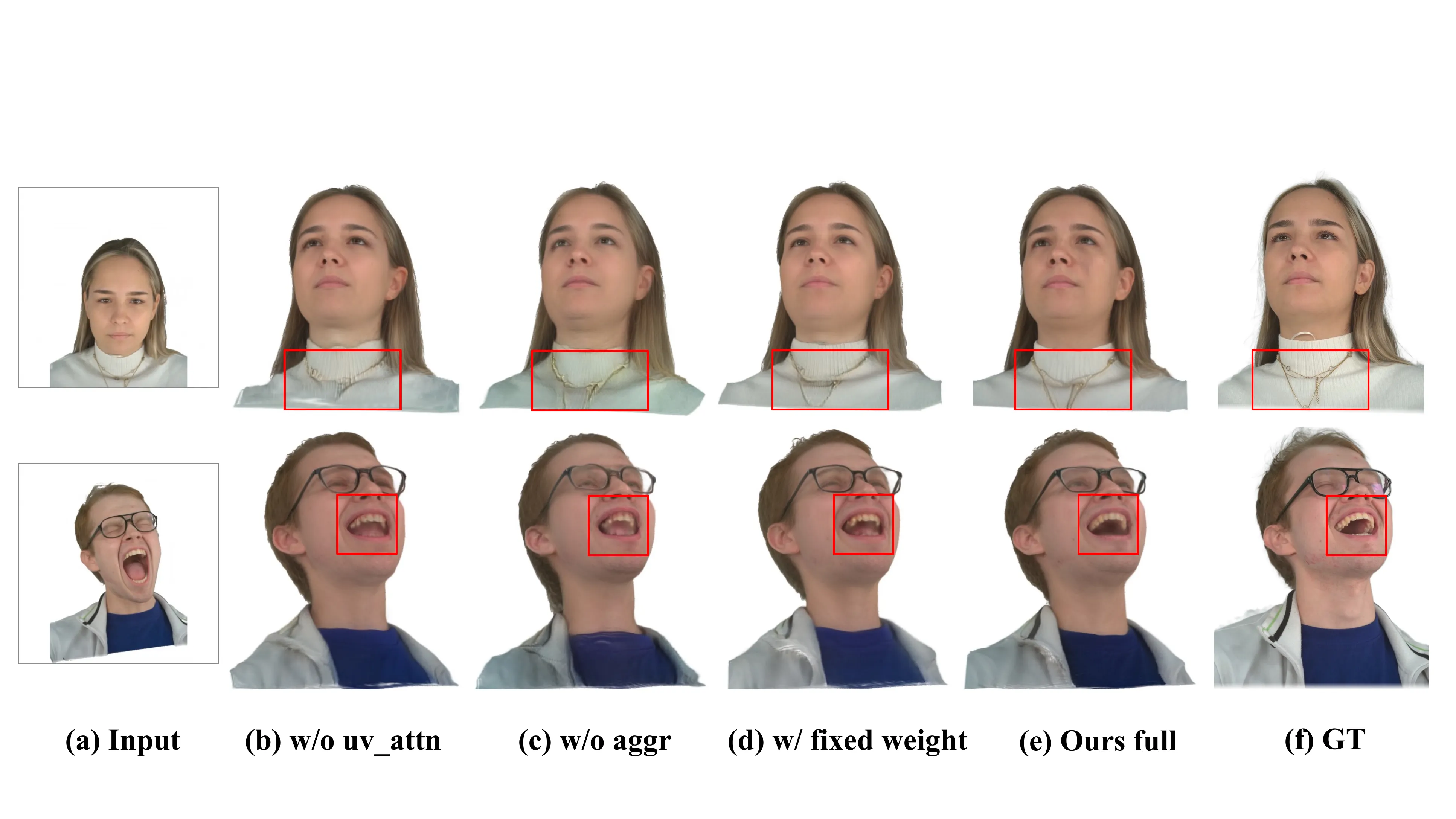
消融实验:每个组件都不可或缺
| 变体 | PSNR↑ | LPIPS↓ | AED↓ |
|---|---|---|---|
| 去掉合成数据 | 21.86 | 0.093 | 0.060 |
| 去掉 UV attention | 22.21 | 0.091 | 0.056 |
| 去掉自自适应融合 | 22.39 | 0.088 | 0.059 |
| UIKA 完整版 | 22.61 | 0.082 | 0.055 |
三个消融的发现:
- 去掉合成数据掉点最多(-0.75 PSNR),说明大规模多视角合成数据对模型的 3D 一致性至关重要
- 去掉 UV attention 掉 0.40 PSNR,主要损失在细节(缺乏结构化全局信息)
- 去掉自自适应融合 掉 0.22 PSNR,颜色连贯性下降
In-the-Wild 泛化
UIKA 在 out-of-domain 数据上也展现了良好的泛化能力,包括 Ava-256 数据集和互联网 in-the-wild 图像。

补充消融:训练数据规模与 Self-Adaptive Fusion
补充材料中提供了两个额外消融,进一步揭示了方法的关键因素:
训练数据消融(来源:补充材料 Fig. abla_data):只用 NeRSemble-v2 训练时,模型几乎无法保留身份信息;加入 VFHQ 后泛化到新身份但极端视角会崩溃;加入合成数据后,身份保持和 3D 一致性都达到最佳。这说明大规模多视角合成数据是 UIKA 泛化能力的关键支柱。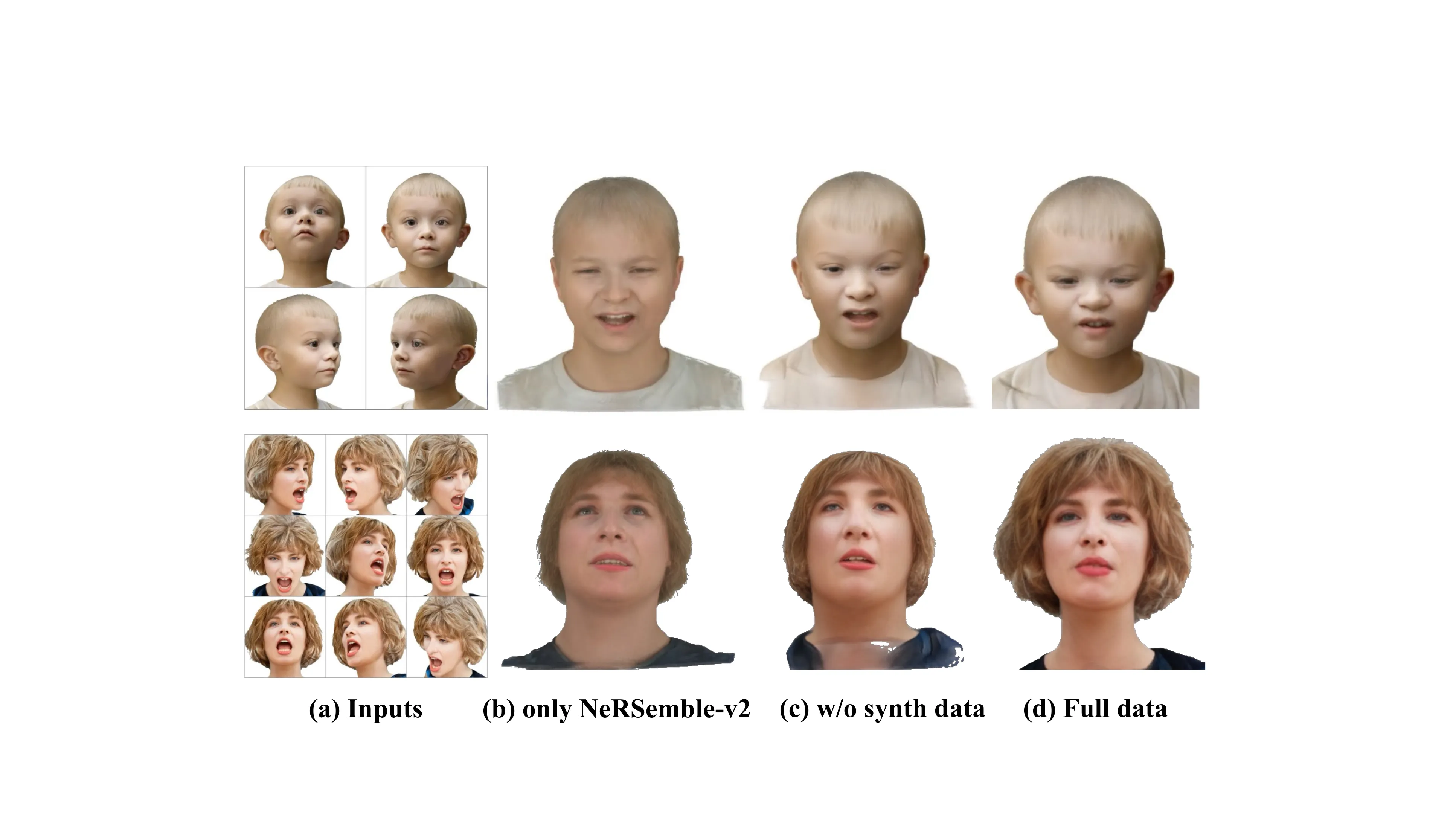
补充对比结果
补充材料中给出了 Monocular 和 Multi-view 设置下的更多可视化对比。在 Monocular 设置下,UIKA 在 VFHQ 和 NeRSemble-v2 上都展现了更强的身份保持和更自然的细节;Multi-view 设置下,随着输入图像增多,优势进一步扩大。


User Study:人类评测也第一
除了定量指标,UIKA 还进行了用户研究(评分 1-5)。在渲染质量(4.37 vs 次优 3.48)、运动一致性(4.17 vs 3.45)和身份保持(4.23 vs 3.54)三个维度上,UIKA 以显著优势领先所有 baseline。这比 PSNR/LPIPS 更能说明问题——用户的眼睛不会骗人。
延迟分析:推理到底有多快?
补充材料中给出了详细的延迟分析。View-Dependent 模块(UV 预测 + Transformer + Decoder)的推理时间随输入图像数 \(N\) 呈 \(O(N^2)\) 增长(受 self-attention 限制):1 张图 1.96s,4 张 3.57s,16 张 12.8s,32 张 32.9s。View-Independent 模块(LBS + 渲染)仅需 5ms(3ms LBS + 2ms 渲染)。总延迟在秒级,远快于需要测试时优化的方法。
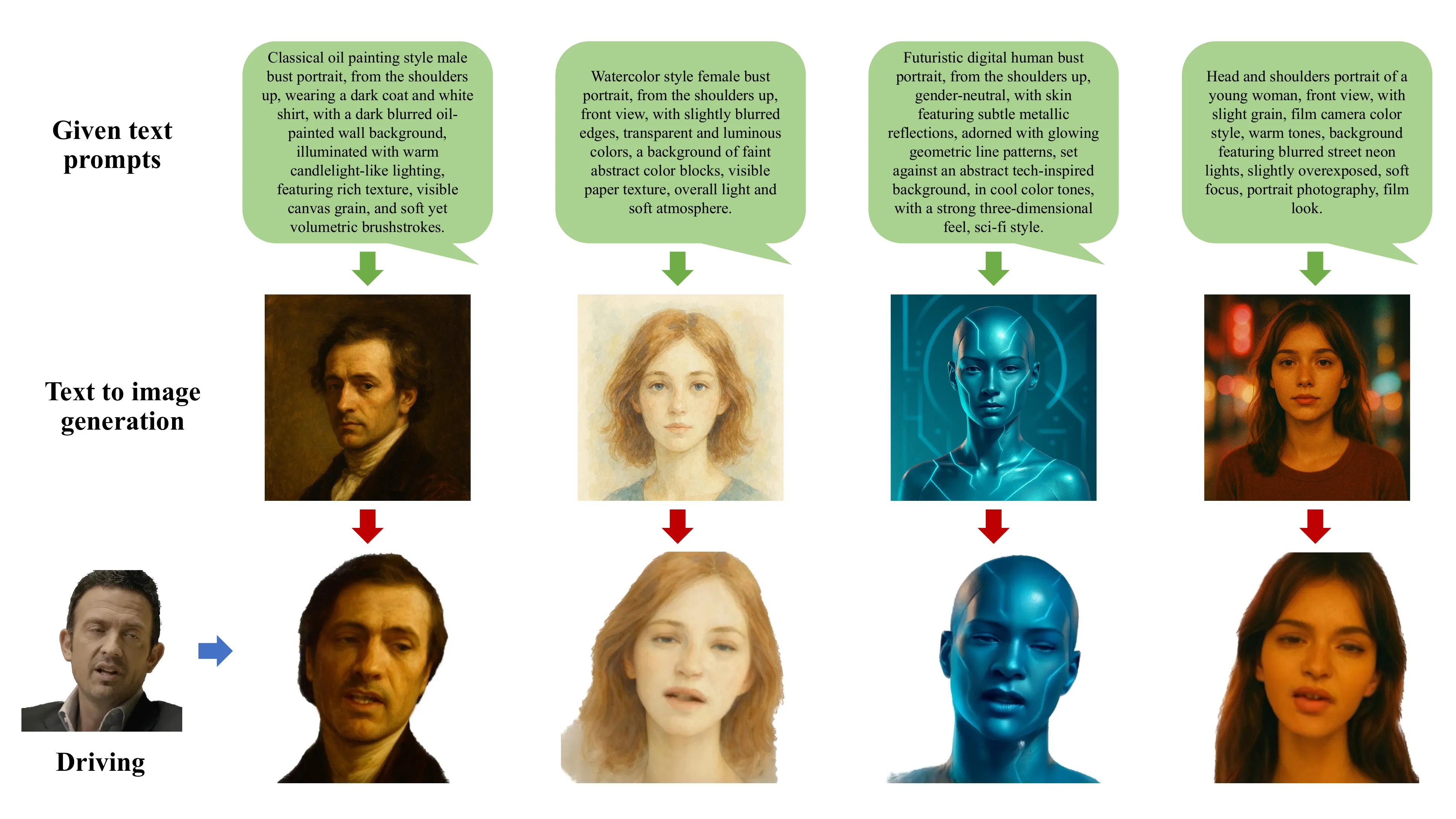
应用展示:从文本到可驱动头像
补充材料还展示了两个有趣的应用:
In-the-Wild 图像重演:UIKA 可以处理互联网上的野生图像,包括卡通风格、素描等非写实风格,证明其泛化能力远超训练数据分布。
与核心竞品的技术对比
| 维度 | UIKA | GAGAvatar | LAM | GPAvatar |
|---|---|---|---|---|
| 核心表示 | 3DGS 直接渲染 | 3DGS + 神经渲染器 | 3DGS + 神经渲染器 | NeRF(慢) |
| 跨帧对应 | UV 显式对应 | 无 | 无 | 无 |
| 注意力 | Screen + UV 双流 | Screen only | Screen only | Screen only |
| 输入灵活性 | 任意数量 | 1 张 | 1 张 | 任意数量 |
| 推理速度 | 220 FPS | 需神经渲染器 | 需神经渲染器 | 慢(NeRF) |
局限性
- FLAME 拓扑依赖:FLAME 模型本身无法表达皱纹、微表情和舌头运动等细粒度面部动态,且头发、胡须、配饰等非皮肤区域无法重建。这是所有 FLAME-based 方法的共同局限。
- 极端侧脸退化:当输入图像只覆盖人脸的一小部分(如纯侧脸),correspondence estimator 可能预测不准,导致 UV 聚合不完整。
- 合成数据偏差:SphereHead + LivePortrait 生成的合成数据虽然规模大,但与真实数据之间仍存在分布偏移,可能影响极端 in-the-wild 场景的表现。
- 对应估计器是关键瓶颈:整个 Pipeline 的质量上限取决于 correspondence estimator 的精度——如果 UV 坐标预测错误,后续所有步骤都会受影响。
- 计算成本随输入数量增长:虽然支持任意数量输入,但 View-Dependent 模块的延迟随 \(N\) 呈 \(O(N^2)\) 增长,32 张图需要 32.9s,且性能提升在超过一定数量后趋于饱和。
我们能带走的启发
1. UV 引导思想可以迁移:不只是人头,任何具有参数化模型的 3D 对象(人手、人体、动物面部)都可以用类似的 UV 引导策略做多视角聚合。这是本文最值得借鉴的元思想。
2. 合成数据是 Feed-Forward 模型的燃料:UIKA 的消融实验清楚地表明,大规模合成数据对模型性能至关重要。7500+ 身份 × 9 视角 × 13000+ 帧的规模远超任何真实采集数据集的覆盖范围。对于数字人方向的从业者,建立自己的合成数据管线可能是 ROI 最高的投入。
3. 双流注意力比单流更强大:Screen attention 抓细节,UV attention 抓结构——这种"互补双流"的设计模式可以推广到其他需要多源信息融合的任务中。
4. 220 FPS 意味着什么:不需要神经渲染器意味着 UIKA 可以在移动端部署。对于钉钉会议等实时通信场景,这是一项关键能力。
论文与代码
-
Wu, Z., Zhou, B., Hu, L., Liu, H., Sun, Y., Wang, X., Cao, X., Shen, Y., & Zhu, H. (2026). UIKA: Fast Universal Head Avatar from Pose-Free Images. CVPR 2026 Highlight.
arXiv:2601.07603 -
Giebenhain, S., Kirschstein, T., Rünz, M., Agapito, L., & Nießner, M. (2026). Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction. ICLR 2026.
-
Chu, X. & Harada, T. (2024). Generalizable and Animatable Gaussian Head Avatar. NeurIPS 2024.
-
He, Y. et al. (2025). LAM: Large Avatar Model for One-Shot Animatable Gaussian Head. SIGGRAPH 2025 Conference Papers.
-
Esser, P. et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML 2024.
-
Li, et al. (2024). SphereHead: 3D Head Generation Model. 用于 UIKA 合成数据管线中的多视角渲染。
-
Guo, J. et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv:2407.03168.
-
Kerbl, B. et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM SIGGRAPH 2023.