3DGS 与 NeRF 数字人路线
本篇在系列中的位置
上一篇讨论的是运动空间路线:模型把音频映射到 3DMM 系数、面部 latent 或 motion representation,再由渲染器还原目标身份。本文进入另一条必须单独看的路线:3D/显式可渲染资产。它既包括 NeRF 与 3D Gaussian Splatting 这类可渲染表示,也包括 SMPL-X、FLAME、ARKit、BVH 和 motion tokens 这类可驱动资产接口。它的核心问题不是“怎样零样本生成任意人”,而是“当目标人物、角色资产或身体骨架相对固定时,能不能先建立一个可复用资产,再用音频、表情、身体动作和对话语义实时驱动它”。AD-NeRF、RAD-NeRF、ER-NeRF 把 talking head 带入神经辐射场;TalkingGaussian、GaussianTalker、GSTalker 与 EGSTalker 把路线推进到 3DGS deformation;SentiAvatar、EMAGE、AudioAvatar 和 Co-speech 3D Meshes 则说明 3D 资产路线不能只看头像渲染,还必须覆盖 rigged avatar、motion controller 和 full-body avatar。#Guo-et-al.-2021-AD-NeRF #Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF #Li-et-al.-2025-TalkingGaussian #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker #Zhu-et-al.-2025-EGSTalker #Zhang-et-al.-2026-SentiAvatar #Liu-et-al.-2024-EMAGE #Xing-et-al.-2026-AudioAvatar #Alexanderson-et-al.-2024-CoSpeechMesh
阅读目标
- 前情回顾:motion space 让“怎么动”变成可生成变量,但外观仍依赖渲染器。
- 本篇问题:固定身份数字人为什么值得先建三维可渲染资产,以及 3DGS 如何把实时渲染变成路线优势。
- 下一篇衔接:3DGS/NeRF 适合专人资产;扩散基模路线则面向更通用、更大自由度的视频生成。
路线定义:先训练一个人,再实时驱动这个人
NeRF/3DGS 数字人与单图 talking head 的最大差别,是它通常采用 person-specific 设定:系统先收集目标人物一小段视频,训练出这个人的三维可渲染表示;上线时再输入新音频、视角或控制信号,驱动这个表示生成说话视频。这样做牺牲了“随便给一张图就能生成”的便利性,却换来更强的身份一致性、三维稳定性和可控渲染边界。#Zhu-et-al.-2025-EGSTalker #Guo-et-al.-2021-AD-NeRF
NeRF 与 3DGS 在这里分别是什么
NeRF(Neural Radiance Field)把一个人头表示成连续神经场:给定空间位置和视角,网络预测颜色与密度,再通过体渲染合成图像。3D Gaussian Splatting 则把头部表示成大量 Gaussian primitives,每个 Gaussian 携带位置、尺度、旋转、不透明度和球谐颜色参数,再通过 rasterization 快速渲染。前者更像“用网络查询场”,后者更像“把很多可学习的半透明椭球投到屏幕上”。#Kerbl-et-al.-2023-3DGS
这条路线的业务边界很清楚:如果产品是固定主播、客服形象、品牌代言人、虚拟老师或长期运营的 IP 角色,前期花几分钟视频和数小时训练成本是可以接受的;如果产品要求用户上传任意一张照片后立即生成,person-specific NeRF/3DGS 就不是最合适的第一选择。换句话说,它不是通用生成模型的替代品,而是固定身份数字人的高质量渲染资产路线。
| 路线 | 训练对象 | 生成时输入 | 优势 | 主要限制 |
|---|---|---|---|---|
| 局部换嘴 | 通用模型 | 原视频 + 新音频 | 便宜、稳定、工程链路短 | 头动、表情和三维一致性受原视频限制 |
| motion space | 通用或半通用模型 | 参考图 + 音频 + 运动条件 | 低维、可控、实时潜力强 | 渲染器和运动表示限制画面上限 |
| NeRF / 3DGS | 目标人物资产 | 新音频、眼部/姿态/相机条件 | 身份稳定、三维一致、适合专人实时头像 | 冷启动训练、资产维护和授权成本高 |
| 视频扩散基模 | 大规模视频先验 | 音频、参考帧、文本、历史状态 | 自由度高,可生成身体与场景 | 成本高,长时一致和实时化困难 |
先分清两张表:任务 taxonomy 和技术路线 taxonomy
3D/显式资产路线容易被误读成“NeRF 和 3DGS 论文集合”。更准确的切法应该先看任务,再看技术路线。任务 taxonomy 回答“用户到底要生成什么”:固定身份 talking portrait、实时 3DGS talking head、全身/手势/表情 motion controller、mesh-conditioned co-speech video、单图生成 3D avatar,还是一个可编辑的 hybrid asset system。技术路线 taxonomy 回答“系统用什么中间表示和接口实现它”:NeRF、3DGS、rigged mesh、SMPL-X/FLAME/ARKit motion controller、mesh-conditioned rendering,或 mesh/rig + 3DGS/NeRF + diffusion prior 的混合系统。#Xu-et-al.-2024-AvatarSurvey #Wu-et-al.-2024-3DGSSurvey #Ding-et-al.-2024-TalkingHeadSurvey
| 任务类型 | 典型输入 | 典型输出 | 代表工作 | 评测重点 |
|---|---|---|---|---|
| Person-specific talking portrait | 目标人物短视频 + 新音频 | 固定身份说话头像/上半身视频 | AD-NeRF, RAD-NeRF, ER-NeRF | 身份、口型、视角一致、PSNR/LPIPS/FPS |
| Real-time 3DGS talking head | 视频、音频、眼动或视角条件 | 实时 Gaussian talking head | TalkingGaussian, GaussianTalker, GSTalker, EGSTalker | 训练时间、FPS、嘴部稳定、同步 |
| Rigged avatar / motion controller | 语音、文本、行为标签、历史动作 | body/hand/face motion、BVH 或 JSON | SentiAvatar, EMAGE, Speech-driven Gestures | 动作自然、语义匹配、可导出、可接现有资产 |
| Mesh-conditioned co-speech video | 音频 + 3D mesh 或 avatar assets | 半身或上身说话视频 | Co-speech 3D Meshes | 身体/手部几何 grounding、视频质量、速度 |
| Single-image / generated 3D avatar | 单图、音频、视频先验 | full-body talking avatar video 或 3D asset | AudioAvatar | 身份、多视一致、全身运动、冷启动成本 |
| 技术路线 | 核心表示 | 适合任务 | 优势 | 限制 |
|---|---|---|---|---|
| NeRF talking portrait | 隐式辐射场 / hash grid | 专人 talking portrait | 三维一致、高保真 | 训练和体渲染成本高,编辑接口弱 |
| 3DGS talking head | Gaussian primitives + deformation | 实时 talking head | 渲染快、显式、训练成本下降 | Gaussian 本身没有骨架、拓扑和语义部件 |
| Rigged mesh / motion controller | SMPL-X、FLAME、ARKit、joint rotations、motion tokens | 全身手势、表情、对话 motion | 动作可解释、可导出、可接游戏/直播资产 | photoreal rendering 依赖外部 renderer |
| Mesh-conditioned video | SMPL-X mesh、depth、normal、UV texture | co-speech upper-body video | 身体和手部几何 grounding 强 | 不等于自由视角 3D asset |
| Hybrid asset system | mesh/rig + NeRF/3DGS + diffusion/controller | 可控高保真数字人 | 兼顾外观、控制和生成自由度 | 系统复杂,接口和评测还未统一 |
SentiAvatar 应该放在这张图里,但不能简单归入 NeRF 或 3DGS。它的输出是 body joint rotations、hand motion、ARKit facial coefficients 和 BVH/JSON;它更像 3D avatar 的 motion foundation model 与 interactive controller。它与 3DGS/NeRF 的关系是上下游互补:SentiAvatar 负责“怎么动”,3DGS/NeRF 或游戏引擎资产负责“怎么渲染”。#Zhang-et-al.-2026-SentiAvatar
从 NeRF 到 3DGS:路线转折来自“渲染速度”
NeRF 阶段:先证明三维场能被语音驱动
AD-NeRF 的核心贡献,是把 talking head 从二维图像翻译问题推进到三维神经场问题。它把目标人物拆成 head NeRF 与 torso NeRF:头部负责嘴形、面部和视角相关外观,躯干分支负责肩颈和背景衔接;音频特征不再只是驱动一个 2D generator,而是参与查询神经辐射场的动态颜色和密度。这样做的好处是,模型可以在同一个三维场里维持身份、姿态和背景一致;代价是每个身份都要训练一个场,体渲染也非常慢。EGSTalker 汇总的量级很直观:AD-NeRF 训练时间达到 167.6h,推理只有 0.04 FPS。#Guo-et-al.-2021-AD-NeRF #Zhu-et-al.-2025-EGSTalker
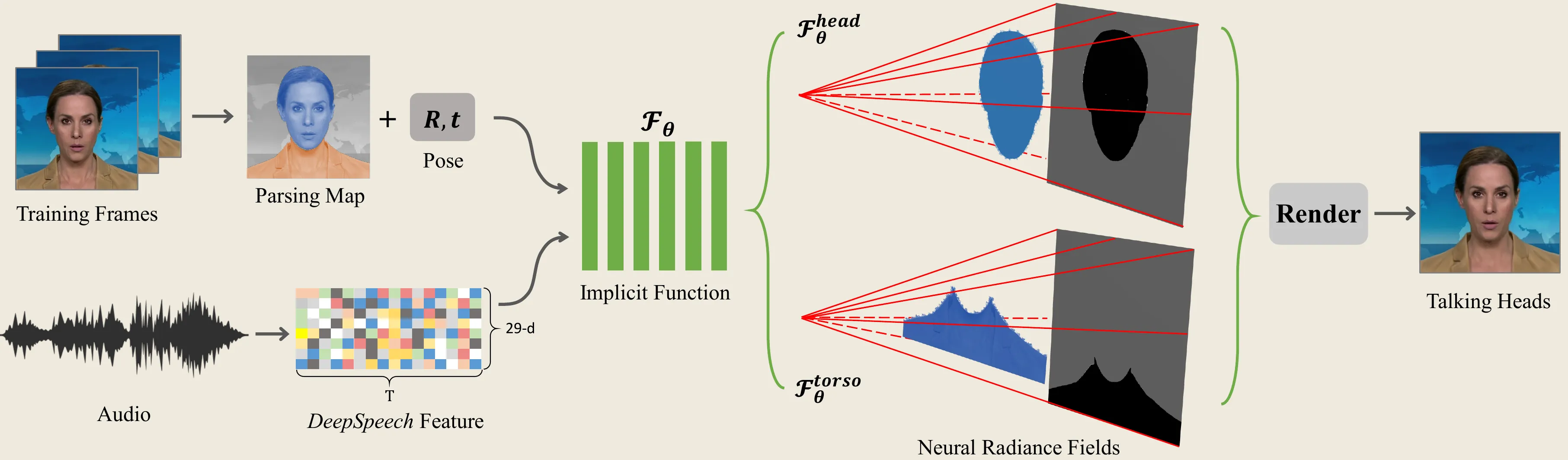
RAD-NeRF 和 ER-NeRF 都在回答同一个问题:如果 NeRF 的三维一致性有价值,怎样让它更接近实时?RAD-NeRF 用 audio-spatial decomposition 把音频相关动态与空间表示拆开,并引入更高效的编码与训练策略,目标是减少每条 ray 上反复查询神经网络的成本。ER-NeRF 则进一步强调 region-aware:嘴部、面部其他区域、躯干对音频的敏感程度并不一样,模型应该把区域差异显式纳入表示,而不是让所有空间位置以同样方式响应语音。两者都不是路线终点,但它们把问题从“能不能用 NeRF 做 talking head”推进到“如何把三维场的不同区域和音频条件解耦”。#Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF
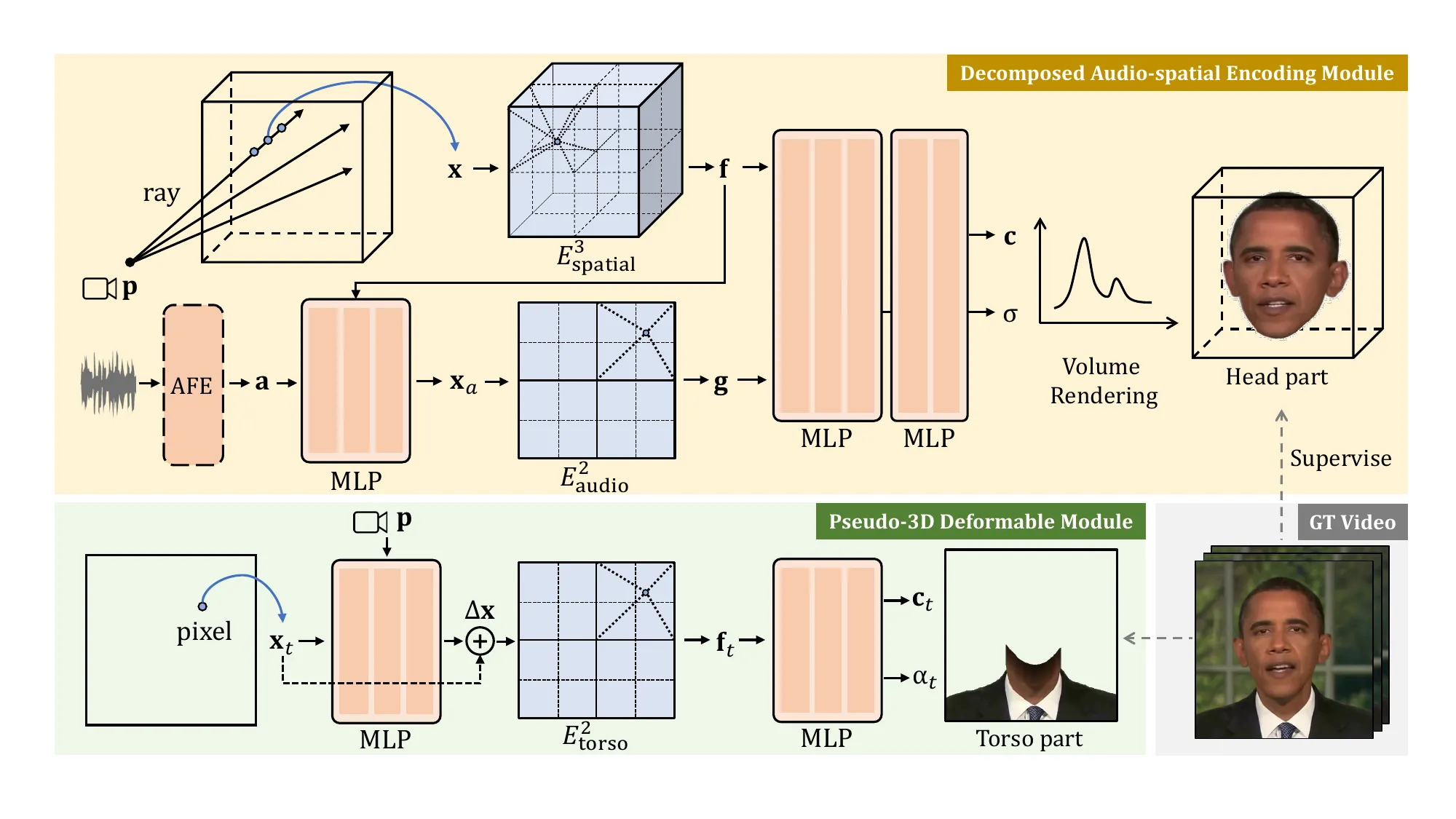
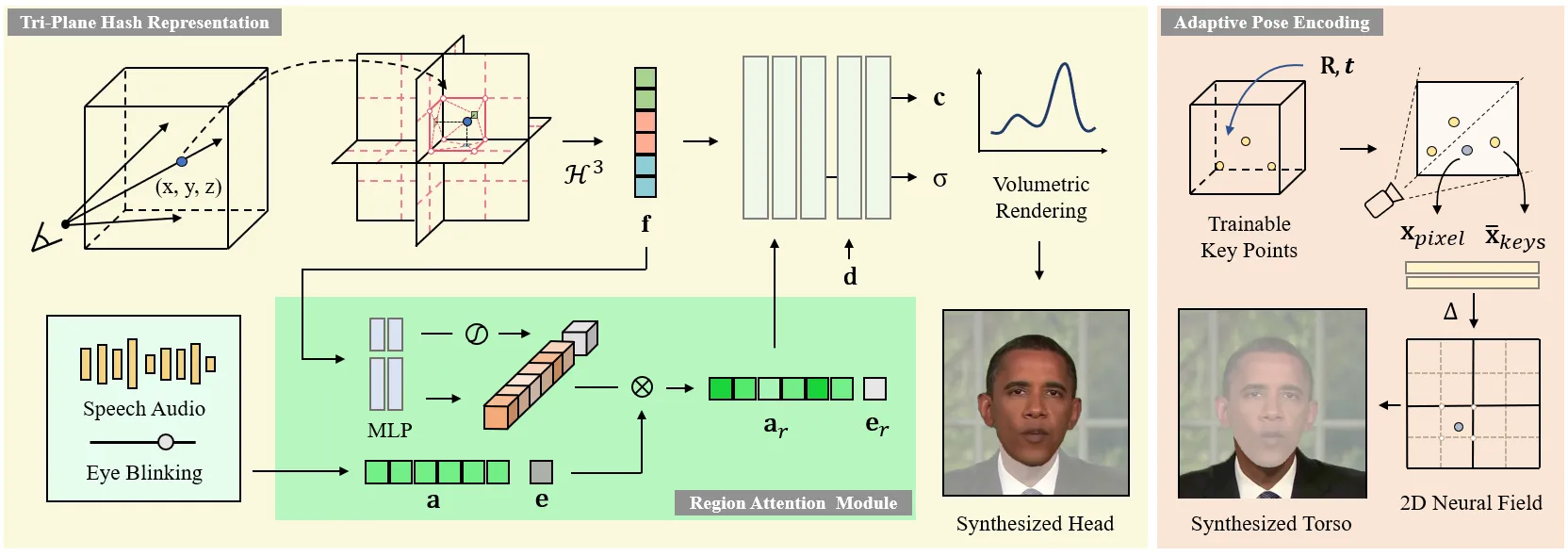
3DGS 阶段:把渲染瓶颈从体采样换成 rasterization
3DGS talking head 的出现,不是因为 NeRF 的问题定义错了,而是因为 NeRF 的渲染方式太贵。3D Gaussian Splatting 把场表示成一组显式 Gaussian primitives,渲染时把这些 primitives 投影到屏幕并做 rasterization;对数字人来说,这意味着固定身份的外观资产仍然可以先训练出来,但实时阶段不用沿每条 ray 反复采样神经场。TalkingGaussian 把“结构持久性”作为核心目标:动态表情不应该破坏头部基础结构,因此它用 deformation-based radiance field 框架驱动 Gaussian,而不是每帧重新生成外观。#Kerbl-et-al.-2023-3DGS #Li-et-al.-2025-TalkingGaussian
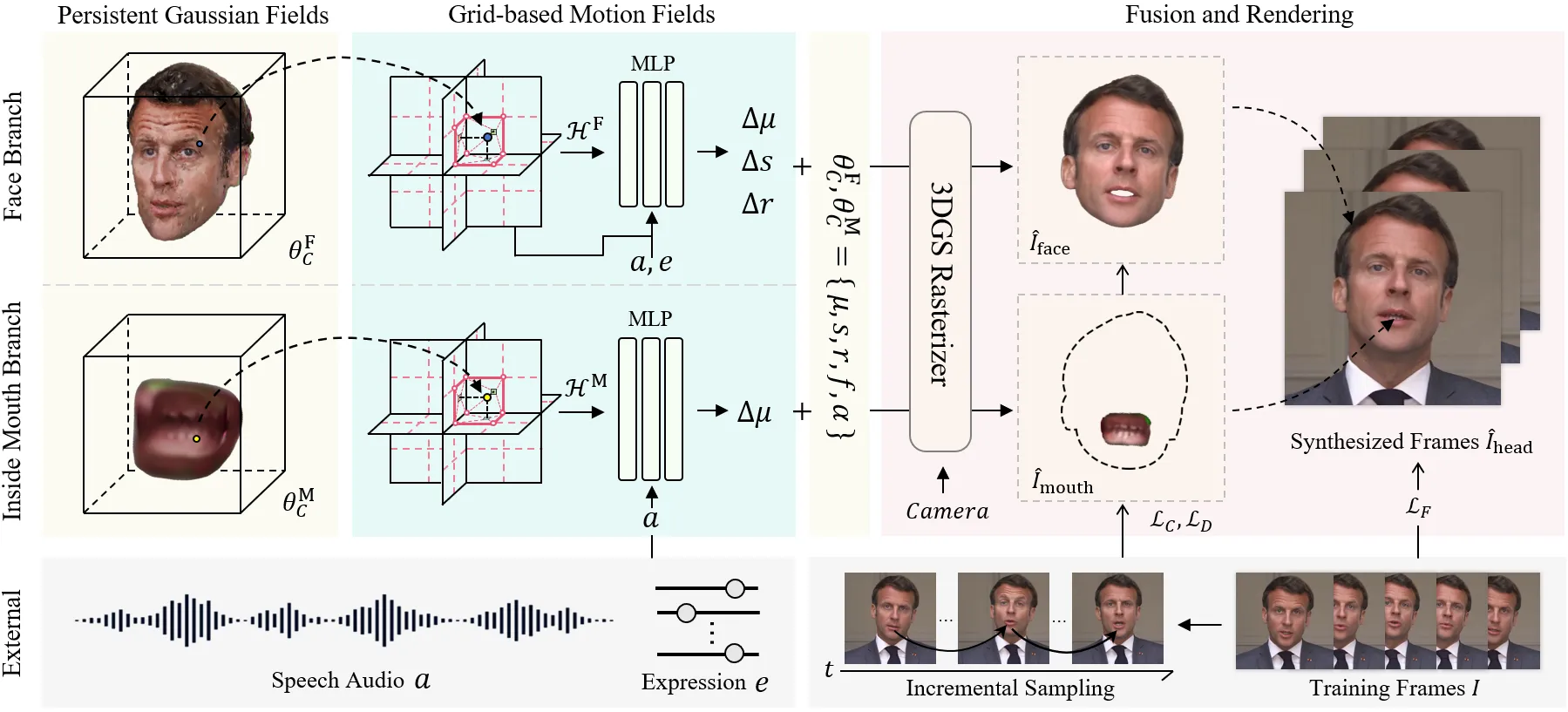
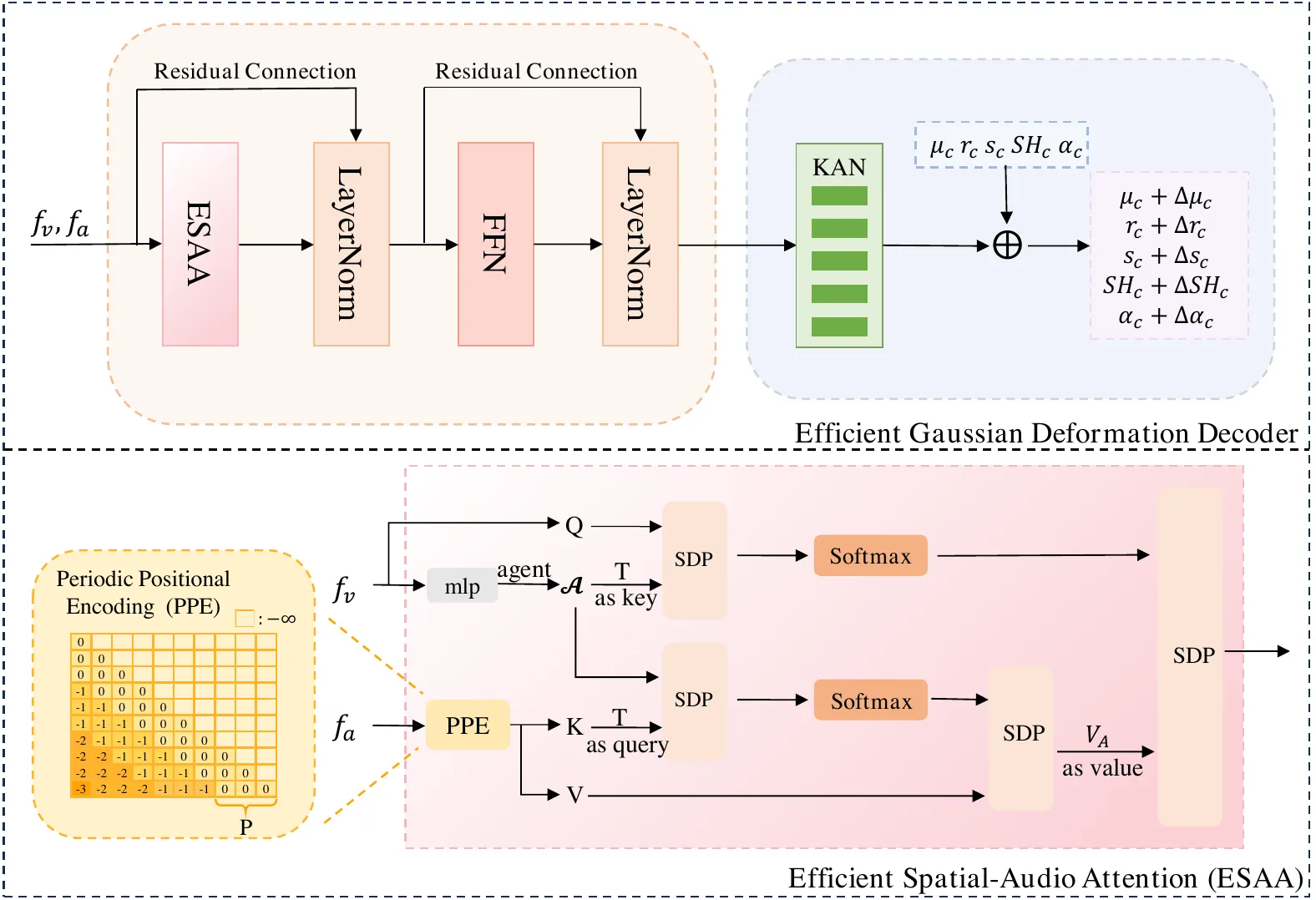
GaussianTalker 和 GSTalker 进一步把问题具体化为“音频如何控制 Gaussian”。GaussianTalker 不是简单把音频直接映射到像素,而是先把音频翻译为 speaker-specific FLAME motion,再用 FLAME 驱动绑定的 Gaussians 渲染说话头;这使音频、身份化运动和显式 3D 表示之间有了可解释接口。GSTalker 则把目标压得更工程化:用 deformable Gaussian Splatting 做快速训练和实时渲染,论文 HTML 中展示了 GSTalker 与 AD-NeRF、RAD-NeRF、ER-NeRF 的同帧对比,说明 3DGS 路线开始把训练时间、FPS 和视觉质量放进同一个工程坐标系里比较。#Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker
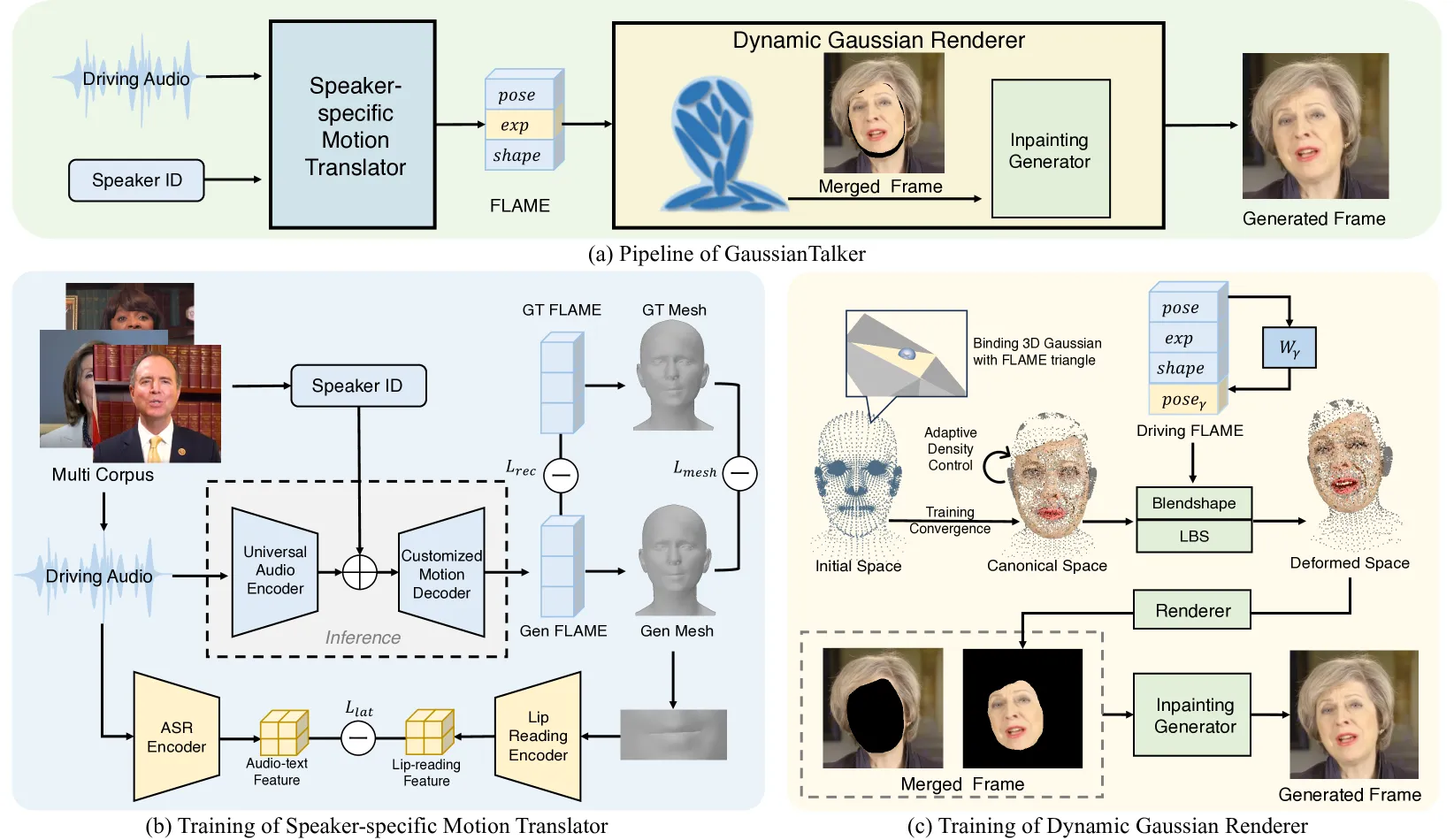
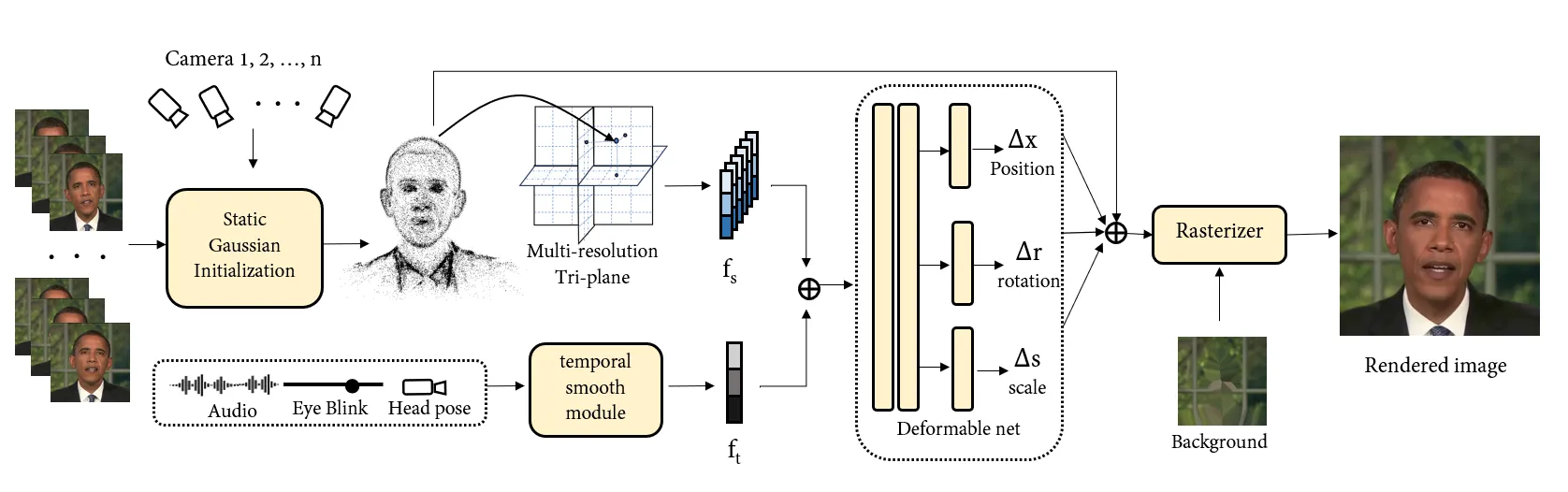
EGSTalker 阶段:当渲染足够快,瓶颈转向音频—空间交互
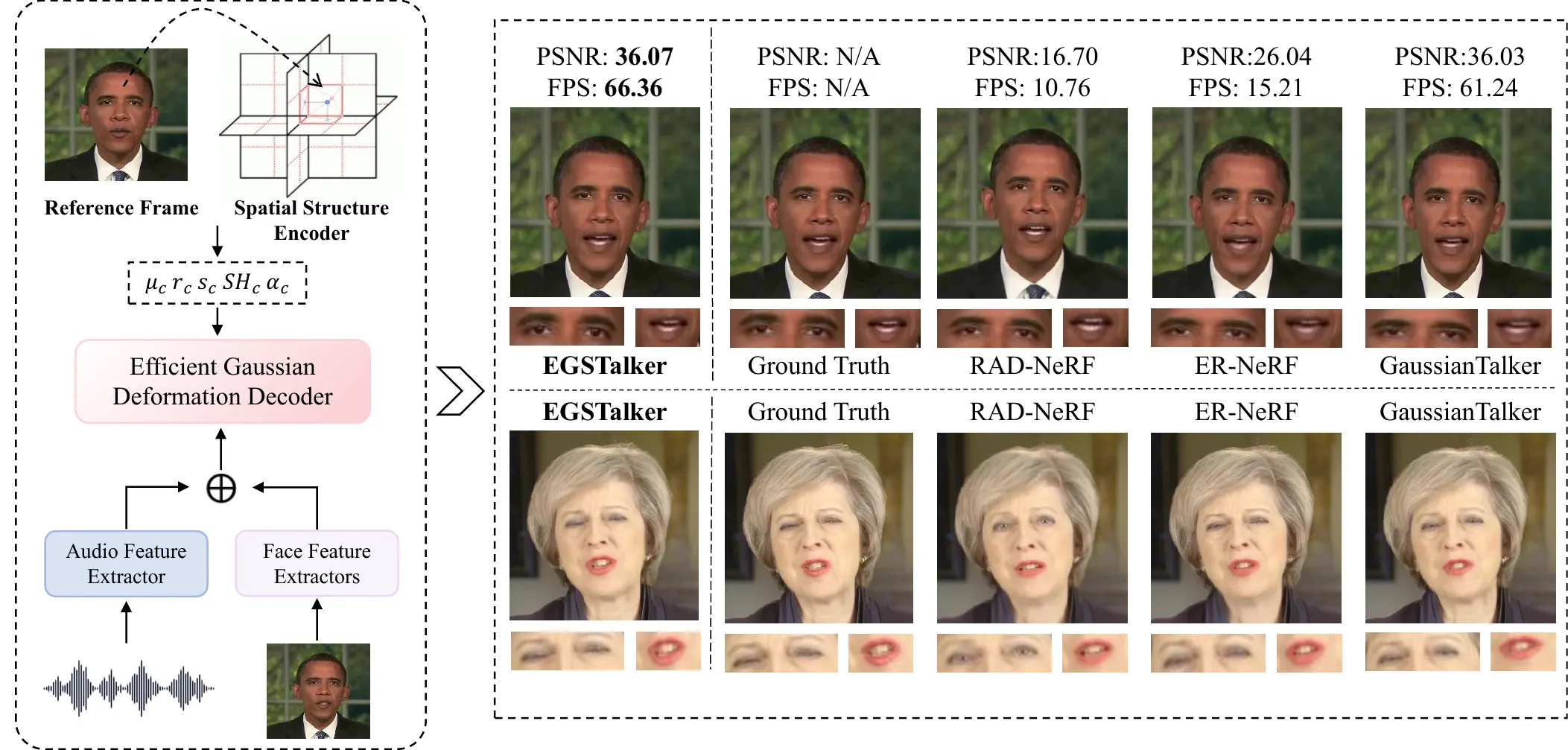
EGSTalker 的实验表提供了一个直观量级:AD-NeRF 训练时间为 167.6h、FPS 为 0.04;ER-NeRF 训练时间为 8.9h、FPS 为 15.21;TalkingGaussian、GaussianTalker 和 EGSTalker 这类 3DGS 方法则把 FPS 推到 70.42、59.24 和 68.51。这里不能只看“谁更快”,而要看路线变化:从 NeRF 到 3DGS,核心收益是把渲染从昂贵的体采样转向高效 rasterization;从早期 3DGS 到 EGSTalker,核心问题又变成如何让音频条件以足够低的代价影响大量空间 primitives。#Zhu-et-al.-2025-EGSTalker #Li-et-al.-2025-TalkingGaussian #Cho-et-al.-2024-GaussianTalker
| 阶段 | 代表工作 | 核心表示 | 关键问题 | 路线意义 |
|---|---|---|---|---|
| NeRF talking portrait | AD-NeRF | 音频条件神经辐射场 | 训练与渲染成本高 | 证明三维场可用于音频驱动头像 |
| 实时 NeRF 优化 | RAD-NeRF, ER-NeRF | 分解/区域感知 NeRF | 如何加速并保持区域运动自然 | 把 NeRF 推向实时 talking portrait |
| 3DGS talking head | TalkingGaussian, GaussianTalker, GSTalker | 动态 Gaussian primitives | 音频如何控制 Gaussian deformation | 把渲染速度变成产品优势 |
| 高效 3DGS deformation | EGSTalker | 静态 Gaussian + 音频驱动 deformation | 如何降低 spatial-audio interaction 成本 | 把 3DGS talking head 做到更稳的实时折中 |
统一结构:资产层、驱动层、渲染层分开看
前面按时间线看完代表论文后,可以把 3D/显式资产路线压缩成三层。第一层是 asset layer:系统从目标人物视频中学习 head NeRF、hash-grid radiance field 或 Gaussian primitives,用来保存身份、几何、肤色、发型和基础外观。第二层是 drive layer:音频、眼部状态、相机姿态、FLAME/ARKit 系数或历史状态被编码成动态控制信号。第三层是 render layer:NeRF 用 volume rendering 合成图像,3DGS 用 rasterization 渲染变形后的 Gaussian。#Guo-et-al.-2021-AD-NeRF #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker #Zhu-et-al.-2025-EGSTalker
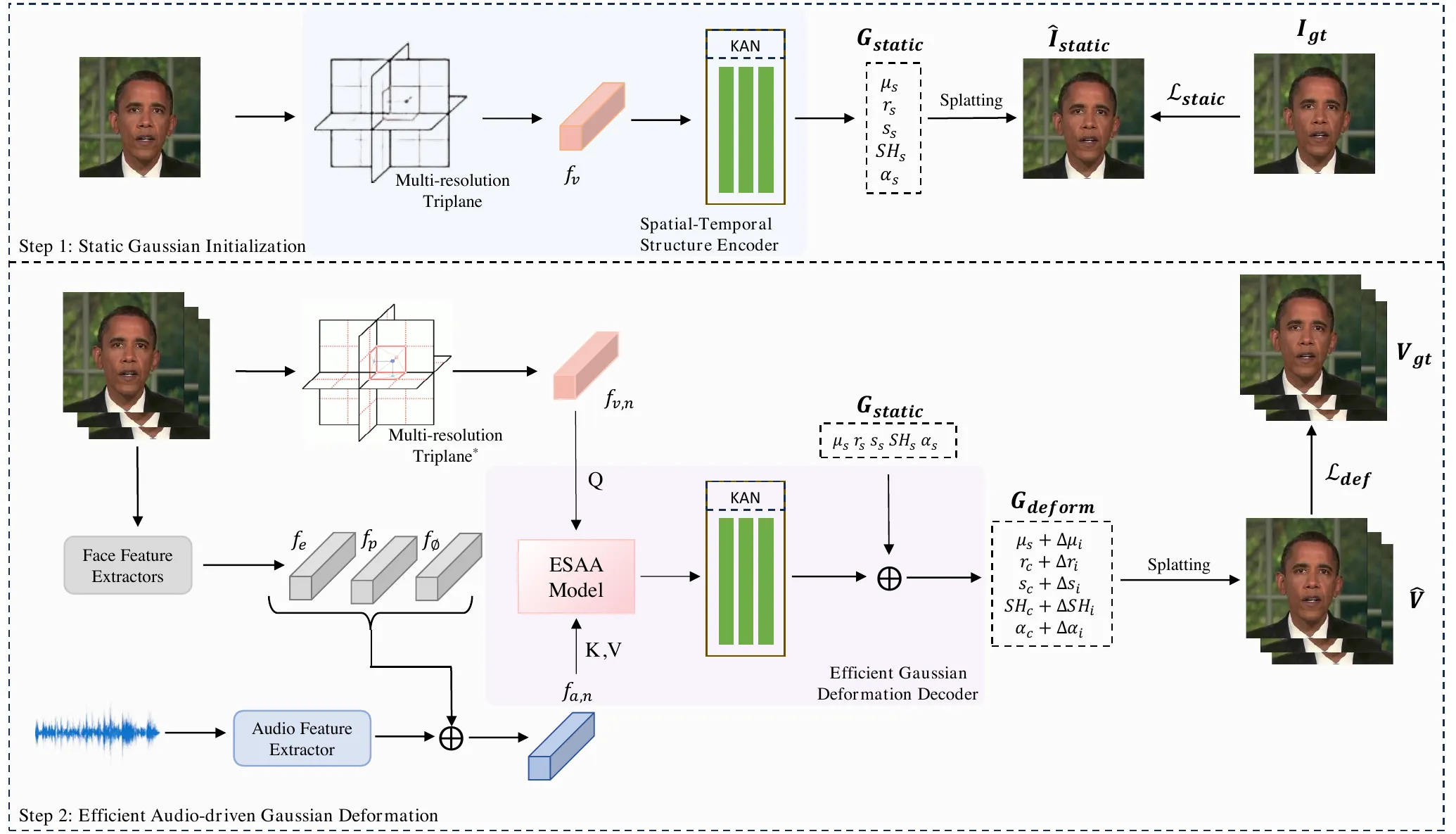
这三层结构比“某篇论文用了什么模块”更重要。AD-NeRF 的 head/torso NeRF、RAD-NeRF 的 audio-spatial decomposition、ER-NeRF 的 region-aware 表示、GaussianTalker 的 audio-to-FLAME-to-Gaussian、GSTalker 和 EGSTalker 的 deformable Gaussian,本质上都在调整三层之间的接口:资产层保存什么,驱动层控制什么,渲染层以多大代价把它变成视频。#Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker
用抽象形式写,这条路线可以表示为:
其中 \(V_{id}\) 是目标人物训练视频,\(A_{1:t}\) 是音频条件,\(e_t\) 是眼部或表情辅助条件,\(c_t\) 是相机/姿态条件。关键不是公式本身,而是分工:身份资产提前训练,实时阶段只预测与当前音频相关的动态偏移。
flowchart LR V["目标人物训练视频"] --> A["资产层:NeRF / 3DGS / mesh"] A --> G["身份、几何、纹理、基础外观"] S["新音频"] --> D["驱动层:audio / eye / pose / FLAME"] E["表情、眼神、相机、历史状态"] --> D G --> D D --> O["动态层:radiance field 或 Gaussian deformation"] O --> R["渲染层:volume rendering / rasterization"] R --> I["Talking head / avatar video"]
这个结构解释了为什么 3DGS 路线特别适合“固定人设”的商业数字人。系统不需要每帧重新想象这个人长什么样,只要让一个已经建好的资产按照音频动起来。它也解释了主要工程风险:训练视频如果没有覆盖足够表情、头动和视角,资产会稳定地复现训练集偏差;授权和隐私也更敏感,因为系统保存的是一个可复用的目标人物资产。
证据怎么读:速度、同步和画质不是同一个问题
3DGS 路线的优势首先体现在速度上。EGSTalker 的 self-driven 实验给出了一个较完整的量级坐标:AD-NeRF 训练 167.6h、推理 0.04 FPS;ER-NeRF 训练 8.9h、15.21 FPS;TalkingGaussian 训练 1.5h、70.42 FPS;GaussianTalker 训练 4.5h、59.24 FPS;EGSTalker 训练 3.7h、68.51 FPS。这个表不能简单读成“3DGS 全面胜出”,而应该读成路线瓶颈迁移:NeRF 阶段瓶颈主要是体渲染和每条 ray 的网络查询;3DGS 阶段瓶颈转向音频条件如何低成本控制大量空间 primitives。#Zhu-et-al.-2025-EGSTalker #Guo-et-al.-2021-AD-NeRF #Li-et-al.-2023-ER-NeRF
| Method | 表示路线 | PSNR ↑ | FID ↓ | LMD ↓ | LSE-C ↑ | 训练时间 ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|
| AD-NeRF | NeRF | 25.794 | 18.289 | 2.932 | 5.105 | 167.6h | 0.04 |
| ER-NeRF | Region-aware NeRF | 26.047 | 7.637 | 2.547 | 7.054 | 8.9h | 15.21 |
| TalkingGaussian | 3DGS | 35.21 | 3.398 | 2.538 | 6.963 | 1.5h | 70.42 |
| GaussianTalker | 3DGS | 36.034 | 2.431 | 2.614 | 6.964 | 4.5h | 59.24 |
| EGSTalker | 3DGS + ESAA | 36.070 | 2.424 | 2.536 | 6.966 | 3.7h | 68.51 |
指标还说明了一个容易忽略的问题:像素重建质量不等于同步质量。EGSTalker 的消融中,去掉 ESAA 和 PPE 后 PSNR 反而从 36.070 升到 36.415,LPIPS 从 0.0223 降到 0.0218;但 LMD 从 2.536 变差到 2.638,LSE-C 从 6.966 降到 6.430。这说明模型更会复原平均外观,不代表更会跟随当前音频做正确口型。#Zhu-et-al.-2025-EGSTalker

把头像放回数字人系统:motion controller 与 full-body asset
如果只看 NeRF/3DGS talking head,3D 资产路线会被误解成“更快的头像渲染器”。但完整数字人还需要身体、手势、情绪、表情和对话行为。SentiAvatar 的定位正好补上这一层:它不是把语音直接渲染成 RGB 视频,而是把文本、语音、行为标签和上下文转成 body joint rotations、hand motion、ARKit facial coefficients,并输出 BVH/JSON 这类可接入现有 3D 资产与渲染引擎的控制流。它报告 SuSuInterActs 包含 21K clips、约 37h 交互动作数据,并在 6s motion 输出上约 0.3s 完成推理;这些数字说明它更像实时 avatar controller,而不是视频渲染论文。#Zhang-et-al.-2026-SentiAvatar
EMAGE 与 Speech-driven 3D Conversational Gestures 进一步说明,speech-driven avatar 的难点不是嘴形一个局部,而是 face、body、hands 和 global motion 的协同。EMAGE 使用 SMPL-X/FLAME 风格的整体动作表示,围绕 BEAT2 这样的多说话人动作数据建模;早期 speech-driven gesture 工作则从视频中学习 3D conversational gestures,把 audio-to-motion 作为独立问题来处理。它们和 3DGS/NeRF 可以组合:controller 输出动作,renderer 负责外观。#Liu-et-al.-2024-EMAGE #Yoon-et-al.-2021-SpeechGestures
Co-speech 3D Meshes 代表另一种中间形态:系统先预测 SMPL-X 风格的 mesh,再把 depth、normal、UV texture 等几何条件送入视频生成器。它不是自由视角、可复用的完整 3D avatar,但它证明 mesh 可以作为 speech-driven upper-body video 的强几何约束。AudioAvatar 则把单图 full-body avatar 与 3DGS particle motion、diffusion teacher 结合起来,试图降低“必须先拍一段专人视频再训练”的门槛;但它在本文证据链里主要支撑的是 full-body / hybrid asset 方向,不能仅凭 FID/FVD 推断已经满足端到端实时交互。#Alexanderson-et-al.-2024-CoSpeechMesh #Xing-et-al.-2026-AudioAvatar
flowchart LR A["语音 / 文本 / 对话上下文"] --> C["Motion controller"] C --> M["Face coefficients / joints / hands / BVH"] M --> R1["Rigged mesh / game engine avatar"] M --> R2["NeRF / 3DGS deformation"] M --> R3["Mesh-conditioned video generator"] R1 --> O["Interactive digital human"] R2 --> O R3 --> O
这张接口图也解释了 SentiAvatar 的归类:它依赖 3D avatar 和 motion asset,但它不是 NeRF/3DGS 表示本身。更好的组织方式是:NeRF/3DGS 是外观与渲染层,SentiAvatar/EMAGE 是动作与控制层,mesh-conditioned video 和 AudioAvatar 是 full-body / hybrid asset 的过渡形态。
| 指标族 | 衡量对象 | 适合任务 | 常见误用 |
|---|---|---|---|
| PSNR / SSIM / LPIPS | 像素与感知重建质量 | NeRF/3DGS talking portrait | 跨数据集直接排名,忽略同步和身份 |
| FID / FVD | 图像或视频分布质量 | 视频生成、full-body avatar | 把分布质量等同于可控性 |
| LSE-C / LSE-D / LMD | 唇同步和 landmark 误差 | audio-driven talking head | 把口型同步等同于表情自然 |
| FGD / BC / Diversity / R@K | 动作分布、节奏和语义检索 | gesture / motion controller | 和 PSNR/FPS 混在一张表里比较 |
| FPS / latency | 模型或渲染速度 | 实时系统 | 把 renderer FPS 当作端到端交互延迟 |
因此,算力也要分层看。AD-NeRF、RAD-NeRF、ER-NeRF 说明 NeRF talking portrait 的瓶颈主要在训练和体渲染;GSTalker 与 EGSTalker 把训练压到小时级,并把渲染推到几十 FPS 量级;SentiAvatar 的 6s motion 输出约 0.3s 说明 controller 可以很快,但不包含最终 photoreal renderer;AudioAvatar 在本文证据链中不能仅凭 FID/FVD 断言它已满足实时交互。正确读法是:先确认它报告的是 motion、renderer、generator 还是完整端到端系统,再决定它能支撑哪种产品。#Guo-et-al.-2021-AD-NeRF #Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF #Chen-et-al.-2024-GSTalker #Zhu-et-al.-2025-EGSTalker #Zhang-et-al.-2026-SentiAvatar #Xing-et-al.-2026-AudioAvatar
产品选型:3D 资产路线适合“固定资产”,不适合所有场景
3DGS/NeRF 路线最适合固定身份、高频使用、画质和稳定性要求高的数字人:例如金融客服、虚拟讲师、品牌主播、企业 IP、长期直播助手和可授权明星分身。此时前期采集和训练不是浪费,而是把身份一致性、三维稳定性和渲染速度沉淀为可复用资产。EGSTalker 使用 3–5 分钟训练视频,并报告 3.7h 训练耗时与 68.51 FPS,这类数字正好说明它更像“资产生产管线”,而不是“一次性生成工具”。#Zhu-et-al.-2025-EGSTalker
不适合的场景也同样明确。第一,用户上传任意照片立即生成,需要的是单图 talking head 或视频扩散基模,而不是先训练一个 NeRF/3DGS 资产。第二,广告级全身表演、复杂镜头、多人互动和动态背景,更依赖视频基模或全身生成路线。第三,如果产品主要追求低成本口型同步,Wav2Lip、MuseTalk 或轻量局部重绘仍然更简单。3DGS 的优势来自“固定人 + 高频调用 + 可训练资产”,离开这个前提,它的冷启动成本会变成负担。
选型判断
- 选 3DGS/NeRF:目标人物固定、可采集训练视频、需要三维稳定和高 FPS 渲染。
- 选 motion space:需要单图或少量参考输入、强调可控运动和低延迟 talking head。
- 选扩散基模:需要整帧、全身、背景、长视频或更大视觉自由度。
- 选局部换嘴:已有原视频,只需要替换语音和嘴型,同步稳定性比动作自由度更重要。
小结与下一篇衔接
NeRF/3DGS 数字人路线的核心不是“更像 3D”,而是把固定身份变成可训练、可复用、可实时驱动的三维渲染资产。NeRF 证明了音频驱动神经头像的三维一致性,RAD-NeRF 和 ER-NeRF 尝试把它推向更快、更区域感知的 talking portrait;3DGS 则把快速 rasterization 引入这个问题,使 TalkingGaussian、GaussianTalker、GSTalker 和 EGSTalker 能把实时性作为主要卖点。#Tang-et-al.-2022-RAD-NeRF #Li-et-al.-2023-ER-NeRF #Li-et-al.-2025-TalkingGaussian #Cho-et-al.-2024-GaussianTalker #Chen-et-al.-2024-GSTalker #Zhu-et-al.-2025-EGSTalker
下一篇进入扩散基模数字人。与 3DGS/NeRF 相比,扩散基模不再只服务于一个固定身份资产,而是借助大规模视频先验处理更高自由度的整帧生成、长时一致、身体动作和复杂场景。因此二者不是谁取代谁:3DGS/NeRF 更像专人资产路线,扩散基模更像通用视频生成路线。
- Guo et al., “AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis,” ICCV 2021 / arXiv:2103.11078. arXiv
- Tang et al., “Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition,” arXiv:2211.12368. arXiv
- Li et al., “Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis,” ICCV 2023 / arXiv:2307.09323. arXiv
- Kerbl et al., “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” ACM TOG 2023 / arXiv:2308.04079. arXiv
- Li et al., “TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting,” arXiv:2404.15264. arXiv
- Cho et al., “GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting,” arXiv:2404.14037. arXiv
- Chen et al., “GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting,” arXiv:2404.19040. arXiv
- Zhu et al., “EGSTalker: Real-Time Audio-Driven Talking Head Generation with Efficient Gaussian Deformation,” arXiv:2510.08587. arXiv
- Xu et al., “A Survey on 3D Human Avatar Modeling -- From Reconstruction to Generation,” arXiv:2406.04253. arXiv
- Wu et al., “A Survey on 3D Gaussian Splatting,” arXiv:2401.03890. arXiv
- Ding et al., “A Survey of Talking Head Synthesis Techniques: Portrait Generation, Driving Mechanisms, and Editing,” 2024. arXiv
- Zhang et al., “SentiAvatar: Towards Expressive and Interactive Digital Humans,” arXiv:2604.02908. arXiv
- Liu et al., “EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling,” arXiv:2401.00374. arXiv
- Yoon et al., “Learning Speech-driven 3D Conversational Gestures from Video,” arXiv:2102.06837. arXiv
- Alexanderson et al., “Co-speech Gesture Video Generation with 3D Human Meshes,” ECCV 2024. Project
- Xing et al., “AudioAvatar: Personalized Audio-driven Whole-body Talking Avatars,” CVPR 2026. CVF