数字人论文精读(五):VASA-1,512×512 实时生成的整体面部动力学
想象一下,你在视频会议中只需要一个静态头像图片,加上你的语音,就能实时生成与你说话同步的高质量人脸视频——这不是科幻,而是微软研究院 VASA-1 已经实现的技术突破。VASA-1(Lifelike Audio-Driven Talking Faces Generated in Real Time)在 NeurIPS 2024 上发表,首次实现了 512×512 分辨率下 40 FPS 的实时音频驱动说话人脸生成,启动延迟仅 170ms #Xu et al., 2024。
当前音频驱动的人脸生成技术面临三大核心困境:过度关注唇部同步而忽略面部整体性、头部运动生硬不自然、生成效率低下无法满足实时应用需求。早期工作如 #Suwajanakorn et al., 2017、#Prajwal et al., 2020 专注于唇部生成,保持其他面部特征不变;后续扩展到表情和头部运动 #Wang et al., 2023b、#Yu et al., 2023,但仍采用分离建模的方式。近年来扩散模型虽然大幅提升了生成质量 #Stypułkowski et al., 2024、#Tian et al., 2024,但高昂的计算成本使其难以在实时场景中部署。
VASA-1 提出的核心创新是整体面部动力学生成(Holistic Facial Dynamics Generation, HFDG):将唇部、非唇部表情、眼神、眨眼等所有面部运动统一建模为一个潜在变量,而非分离处理。这种整体性建模配合扩散 Transformer,使得生成的人脸视频不仅唇音同步准确,而且头部运动自然、表情丰富,同时实现了实时推理速度。

实时高质量 Talking Face 的难点
音频驱动的说话人脸生成(Audio-Driven Talking Face Generation)是一个极具挑战性的跨模态生成任务,其核心难点在于:
- 模态对齐精度:音频信号(时域波形或声学特征)需要精确映射到面部运动(唇部开合、表情变化),误差容忍度极低。人眼对唇音同步极其敏感,几十毫秒的偏差都会产生明显的不协调感。
- 运动整体性:人类说话时,唇部动作与表情、眼神、头部姿态高度耦合。例如,说到激动的内容时,不仅嘴部动作幅度增大,还会伴随眉毛上扬、眼睛睁大、头部前倾等整体反应。传统分离建模无法捕捉这种耦合关系。
- 身份保持:生成的人脸必须严格保留输入静态图像的身份特征(面部轮廓、五官比例、皮肤纹理),任何身份信息的泄露都会导致"换脸"感。
- 实时性约束:实际应用(如视频会议、虚拟助手)要求生成延迟控制在几百毫秒内,这对模型架构和推理效率提出了苛刻要求。
核心术语解释
整体面部动力学(Holistic Facial Dynamics)
指将唇部、表情、眼神、眨眼等所有面部运动视为一个统一的时间序列,而非独立的子问题。这种整体性建模能够捕捉面部各组成部分之间的自然关联性,生成更加逼真的面部运动。
扩散 Transformer(Diffusion Transformer)
结合扩散模型和 Transformer 架构的生成模型。扩散模型通过逐步去噪生成高质量样本,Transformer 通过自注意力机制捕捉长程依赖。VASA-1 用扩散 Transformer 生成面部运动序列,在潜在空间而非像素空间操作,大幅提升生成效率。
解耦面部潜在空间(Decoupled Facial Latent Space)
将人脸表征分解为相互独立的多个潜在变量:3D 外观体积、身份编码、头部姿态、面部动力学。解耦使得每个变量可以独立控制,例如保持身份不变而改变表情,或保持表情不变而改变头部姿态。
CAPP(Contrastive Audio and Pose Pretraining)
论文提出的新型评估指标,灵感来自 CLIP #Radford et al., 2021。通过对比学习训练姿态编码器和音频编码器,预测姿态序列和音频是否配对。CAPP 得分越高,说明音频与头部姿态的对齐度越好,是首个数据驱动的音频-姿态度量。
VASA-1 的方法包含三个核心阶段:面部潜在空间构建、扩散 Transformer 生成运动、解码器渲染视频。我们逐一深入每个阶段的设计动机和技术细节。
flowchart TD A["静态人脸图像"] --> B["Phase 1: 面部潜在空间构建"] C["语音音频片段"] --> D["Phase 2: 扩散 Transformer 生成运动"] E["可控信号
(眼神方向/头部距离/情感偏移)"] --> D B --> D D --> F["运动序列
(姿态 + 面部动力学)"] F --> G["Phase 3: 解码器渲染视频"] B --> G G --> H["512×512 说话人脸视频
@ 40 FPS, 170ms 延迟"] style A fill:#e3f2fd style C fill:#e3f2fd style E fill:#e3f2fd style H fill:#c8e6c9 style B fill:#fff3e0 style D fill:#fff3e0 style G fill:#fff3e0
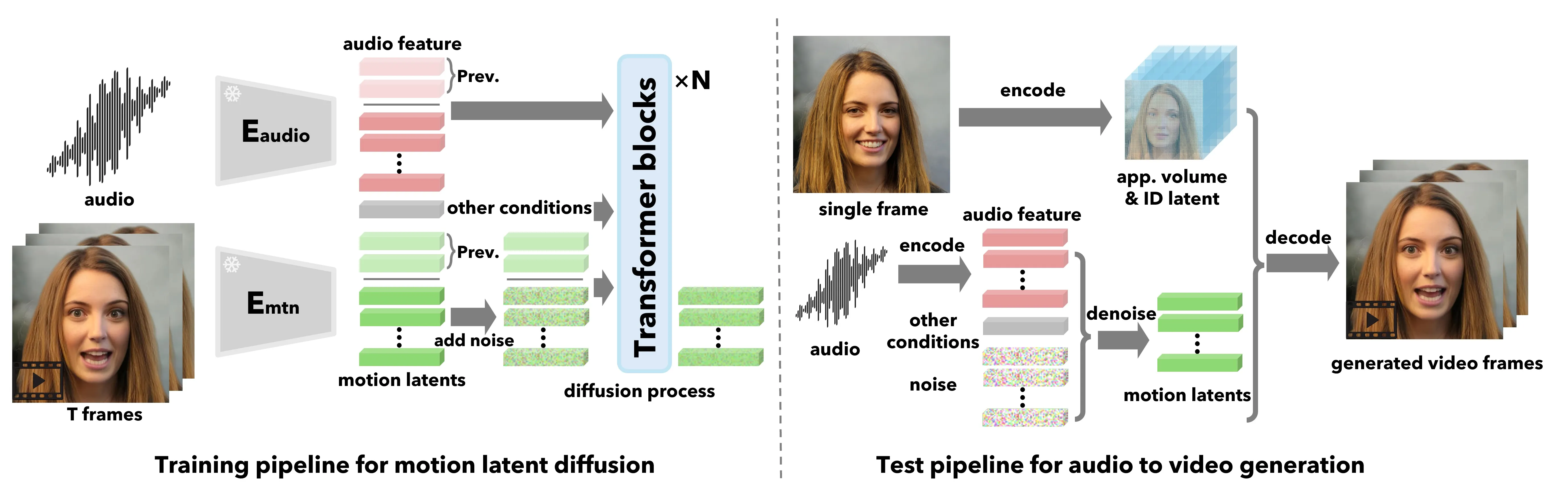
阶段一:表达性强且解耦的面部潜在空间
面部潜在空间是整个方法的基础,其质量直接决定了生成结果的真实感和可控性。VASA-1 基于早期 3D 辅助面部重现框架 #Wang et al., 2021a 进行改进,核心创新是通过新颖的损失函数设计实现更强的解耦。
该框架将人脸表征分解为四个独立的潜在变量:
- Vapp:3D 外观体积,在 canonical 空间中表征 3D 外观细节(五官结构、皮肤纹理)。相比 2D 特征图,3D 体积能够更好地建模深度信息和遮挡关系。
- zid:身份编码,捕获个体的面部轮廓、五官比例等不可变特征。
- zpose:头部姿态,包括旋转(3 自由度)和平移(2 自由度),控制头部的空间朝向。
- zdyn:面部动力学编码,统一编码唇部、非唇部表情、眼神、眨眼等所有面部运动。
解耦学习的核心思想是通过交换潜在变量构建重构损失:将不同图像的潜在变量交叉组合,强制网络学习每个变量的独立语义。例如,将图像 A 的头部姿态交换到图像 B,网络应该能重构出"图像 B 的身份 + 图像 A 的姿态"。
头部姿态与面部动力学一致性损失
为了防止头部姿态和面部动力学纠缠(例如,歪嘴通常伴随倾斜头部),论文提出了关键损失函数 lconsist:
其中 I_i 和 I_j 是同一视频中的随机两帧,Îj,pose_i 是将 I_i 的头部姿态应用到 I_j 的重构结果,Îi,dyn_j 是将 I_j 的面部动力学应用到 I_i 的重构结果。这个损失鼓励网络保持头部姿态和面部动力学的一致性,避免它们在训练中相互干扰。
阶段二:基于扩散 Transformer 的整体面部动力学生成
有了解耦的面部潜在空间,下一个核心问题是如何根据音频生成高质量的运动序列(zpose 和 zdyn)。VASA-1 选择扩散 Transformer 而非传统的 GAN 或自回归模型,原因有三:
- 质量优势:扩散模型已被证明在图像生成任务上优于 GAN #Stypułkowski et al., 2024。
- 长程依赖:Transformer 的自注意力机制能够捕捉音频和运动之间的长程时序依赖,这对于保持运动连贯性至关重要。
- 生成效率:在潜在空间而非像素空间操作,大幅降低了计算量,使得实时生成成为可能。
扩散模型采用 Denoising Score Matching 目标:
其中 Xt 是前向过程添加噪声后的运动序列,H 是 Transformer 网络(预测原始信号而非噪声),C 是条件信号。网络架构包含 8 层 Transformer 编码器,嵌入维度 512,注意力头数 8,参数量仅 29M,非常轻量。

条件信号设计
条件信号的设计是可控性的关键。VASA-1 采用多层级条件:
- 主要条件:音频特征序列 A,使用预训练 Wav2Vec2 #Baevski et al., 2020 提取。
- 辅助可控信号:
- 主眼神方向 g = (θ, φ):球面坐标定义的向量,控制虚拟人的凝视方向。
- 头部距离 d:归一化标量,控制面部尺度(近大远小效果)。
- 情感偏移 e:全局偏移,可以增强或轻微改变情感表达。
- 上下文窗口:前 K 帧音频特征和运动作为当前窗口的条件,实现窗口间的平滑过渡,避免帧间突变。
Classifier-Free Guidance(CFG)
为了进一步提升生成质量,VASA-1 采用 Classifier-Free Guidance 技术。训练时随机丢弃条件,推理时应用:
其中 \(\lambda_A = 0.5\)(音频 CFG),\(\lambda_g = 1.0\)(眼神 CFG)。丢弃概率:音频 0.1,历史窗口 0.5。消融实验表明,合理的 CFG 参数能够显著提升同步性和质量,但过强的 CFG(如 \(\lambda_A = 2.0\))会导致头部抖动和夸张嘴部动作。
阶段三:推理流程与解码器渲染
推理采用滑动窗口策略,确保实时性和连贯性:
- 提取面部潜在变量:从静态人脸图像中提取 Vapp 和 zid。
- 提取音频特征:用 Wav2Vec2 提取音频特征,分割成固定大小的窗口。
- 滑动窗口生成运动:对每个窗口,使用扩散 Transformer 生成 {zpose, zdyn} 序列。条件包括上一窗口的运动和音频、当前窗口的音频、可控信号。
- 解码器渲染:将 3D 外观体积 Vapp、身份编码 zid、运动序列 {zpose, zdyn} 输入解码器,渲染出 512×512 的视频帧。
实时性优化技巧
为了实现实时生成,VASA-1 采用了多项优化:扩散 Transformer 仅 29M 参数,推理时使用 10 步采样(而非标准的 50 步),滑动窗口重叠策略确保帧间平滑。最终在单张 RTX 4090 上实现了 40 FPS 的在线流式模式,启动延迟仅 170ms。
训练数据
VASA-1 的训练数据规模和质量是其成功的关键因素之一:
- VoxCeleb2:约 6K 主体,大规模公开数据集。
- 自建高清数据集:约 3.5K 主体,图像质量更高,包含更多样化的场景和姿态。
- 总数据量:约 500K 片段,每段时长 2-10 秒。
- 数据清洗:使用自训练的质量评估模型 #Su et al., 2020 去除多主体和低质量片段,确保训练数据纯净。
训练配置
训练分为两个阶段:
- 面部潜在空间模型:4 × RTX A6000,训练 7 天。模型参数约 200M。
- 扩散 Transformer:训练 3 天。模型参数仅 29M,非常轻量。
损失函数
面部潜在空间模型的训练损失包括:
- 重构损失:L1 重构损失,确保生成图像与原始图像一致。
- 对抗损失:使用 GAN 判别器提升生成图像的真实感。
- 感知损失:使用预训练 VGG 网络提取特征,计算特征空间的 L1 损失,提升视觉质量。
- 姿态-表情一致性损失:lconsist,防止姿态和表情纠缠。
- 跨身份身份相似性损失:lcross_id,提升身份保持能力。

扩散模型训练
扩散 Transformer 使用标准 DDPM #Ho et al., 2020 训练策略:
- 前向过程:逐步添加高斯噪声,T = 1000 步。
- 反向过程:训练网络预测原始信号 X0 而非噪声。
- 条件丢弃:训练时以 0.1 概率丢弃音频条件,0.5 概率丢弃历史窗口条件,实现 Classifier-Free Guidance。
- 优化器:AdamW,学习率 1e-4,批次大小 256。
评估基准与指标
VASA-1 在两个数据集上进行评估:
- VoxCeleb2 子集:46 主体 × 10 片段 = 460 片段,内容为新闻/访谈。
- OneMin-32:32 个 1 分钟片段,内容为在线教育/辅导。
评估指标包括传统指标(SyncNet Confidence Score SC、SyncNet Distance SD、FVD)和论文提出的新颖指标(CAPP、ΔP):
- SC ↑ / SD ↓:SyncNet Confidence Score 和 Distance,衡量唇音同步质量。
- FVD25 ↓:Fréchet Video Distance,衡量视频生成质量,越小越接近真实视频 #Unterthiner et al., 2019。
- CAPP ↑:Contrastive Audio and Pose Pretraining,衡量音频与头部姿态的对齐度,灵感来自 CLIP。
- ΔP:姿态变化强度,相邻帧姿态角度差的平均值,衡量头部运动的生动程度。
定量结果对比
| 方法 | SC ↑ | SD ↓ | CAPP ↑ | ΔP | FVD25 ↓ |
|---|---|---|---|---|---|
| VoxCeleb2 数据集 | |||||
| MakeItTalk #Zhou et al., 2020 | 4.176 | 15.513 | -0.051 | 0.210 | 304.83 |
| Audio2Head #Wang et al., 2021b | 6.172 | 8.470 | 0.246 | 0.260 | 209.77 |
| SadTalker #Zhang et al., 2023b | 5.843 | 8.813 | 0.441 | 0.275 | 214.51 |
| VASA-1 (Ours) | 8.841 | 6.312 | 0.468 | 0.304 | 105.88 |
| Ours (10% data) | 8.818 | 6.298 | 0.457 | 0.229 | 147.40 |
| Real video | 7.640 | 7.189 | 0.588 | 0.505 | 29.25 |
音频-姿态对齐分析
CAPP 得分 0.468 比次优方法 SadTalker(0.441)高出约 26%,说明 VASA-1 生成的头部运动与音频的对齐度更好。CAPP 指标的有效性通过敏感性验证:时间偏移 ±1 帧导致分数下降 24%(0.608 → 0.462),时间偏移 ±2 帧导致分数下降 66%(0.608 → 0.206)。
视频质量分析
FVD 得分 105.88 比次优方法低约 50%,接近真实视频的 3.6 倍差距(105.88 vs 29.25)。虽然仍有差距,但已远超现有方法。ΔP 得分 0.316 低于真实视频的 0.505,说明头部运动的生动程度仍有提升空间。
推理速度评估
| 模式 | 分辨率 | 帧率 | 启动延迟 | 硬件 |
|---|---|---|---|---|
| 离线批量模式 | 512×512 | 45 FPS | - | 单张 RTX 4090 |
| 在线流式模式 | 512×512 | 40 FPS | 170ms | 单张 RTX 4090 |
实时性突破
40 FPS 的在线流式模式在同类工作中是前所未有的。对比之下,许多基于扩散模型的工作(如 #Stypułkowski et al., 2024、#Tian et al., 2024)虽然质量高,但推理速度远低于实时要求(通常 < 1 FPS)。VASA-1 证明了扩散模型在潜在空间操作可以实现实时生成。
消融实验
CFG 参数影响
| 配置 | λA | λg | SC ↑ | SD ↓ | CAPP ↑ | ΔP | FVD25 ↓ |
|---|---|---|---|---|---|---|---|
| 无 CFG | 0.0 | 0.0 | 7.087 | 7.391 | 0.414 | 0.291 | 117.43 |
| 仅眼神 CFG | 0.0 | 1.0 | 7.134 | 7.345 | 0.421 | 0.290 | 116.55 |
| 仅音频 CFG | 0.5 | 0.0 | 7.087 | 7.391 | 0.414 | 0.291 | 117.43 |
| 标准配置 | 0.5 | 1.0 | 7.957 | 6.635 | 0.465 | 0.316 | 105.88 |
| 强音频 CFG | 2.0 | 1.0 | 8.295 | 6.397 | 0.455 | 0.395 | 104.29 |
观察表明:提高 \(\lambda_g\) 提升眼神控制精度;\(\lambda_A = 0.5\) 平衡了同步性和质量;过高的 \(\lambda_A = 2.0\) 会导致头部抖动和夸张嘴部动作。
损失函数有效性
- 无 lconsist:无法捕捉微妙的面部动力学(如侧视、唇部不对称),姿态和表情纠缠。
- 有 lconsist:成功解耦头部姿态和面部表情,生成结果更自然。
泛化能力验证


- 身份保持:同一运动序列应用于不同身份,保持各自特征(图 5)。
- 姿态-表情解耦:固定姿态改变表情,或固定表情改变姿态,互不干扰(图 6)。
- 分布外输入:非真实感图像(艺术照、卡通)、歌唱音频、非英语语音,仍能生成高质量对齐视频(图 7)。

当前局限
技术局限
- 场景范围:仅处理到上半身躯干,未来需要扩展到全身。
- 3D 建模:缺少显式 3D 人脸模型(如 #Wu et al., 2022、#Wu et al., 2023),神经渲染可能导致纹理粘连。未来可以集成更强的 3D 先验。
- 非刚性元素:未建模头发和衣物运动,未来需要引入更强的视频先验。
- 表达多样性:对话风格和情感仍有限,未来需要增加风格和情感控制。
质量差距
FVD(105.88)vs 真实视频(29.25):仍有 3.6 倍差距。ΔP(0.316)vs 真实视频(0.505):头部运动强度不足。这些差距说明生成的视频虽然质量很高,但与真实视频相比仍有可感知的差异。
伦理考量
伦理与安全
论文明确指出,已训练检测器,准确率 97.8%,能够区分真实视频和 VASA-1 生成的视频。作者反对生成误导性内容,并致力于将该方法用于推进伪造检测研究。初步探索表明,使用 VASA-1 生成训练数据可以显著提升伪造检测模型的泛化能力。
对工程的启发
- 潜在空间操作是关键:扩散模型在像素空间操作成本高昂,但在低维潜在空间操作可以大幅提升效率。VASA-1 的面部动力学编码维度远低于像素维度,这是实时性的基础。
- 整体性建模优于分离建模:将面部运动统一建模比分离建模更自然,能够捕捉各组成部分之间的关联。这种整体性思想可以应用到其他多模态生成任务(如手势生成、身体姿态生成)。
- 解耦是可控性的基础:强表达力 + 高解耦度 = 可控生成。VASA-1 的面部潜在空间既有强表达能力(3D 体积),又有高解耦度(姿态、表情、身份分离),这使得可控信号(眼神、距离、情感)能够精准影响生成结果。
- 新度量推动研究:CAPP 填补了音频-姿态对齐评估的空白,为后续研究提供了更客观的度量。工程实践中,设计合适的评估指标比盲目追求高分更重要。
- 控制接口标准化:眼神、距离、情感等可控信号的设计非常直观,可以作为未来 talking face 系统的标准控制接口。
实际应用建议
VASA-1 的技术非常适合以下实际场景:视频会议(降低带宽需求)、教育辅导(个性化 AI 导师)、医疗康复(为交流障碍人士提供虚拟辅助)、虚拟陪伴(提供情感支持和社会互动)。在这些场景中,实时性和质量同等重要,VASA-1 提供了一个很好的平衡点。
本文属于数字人系列论文精读,推荐延伸阅读以下内容:
- 实时数字人生成 Survey:了解数字人技术的整体发展脉络和主要技术路线。
- SadTalker #Zhang et al., 2023b:基于 3D 系数的高质量 one-shot talking face 生成,是 VASA-1 之前的方法之一。
- Diffused Heads #Stypułkowski et al., 2024:扩散模型击败 GAN 在 talking face 生成上的应用,但非实时。
- AniPortrait #Wei et al., 2024:音频驱动的肖像动画,质量较低但架构简单。
- Emo #Tian et al., 2024:表情丰富的 audio2video 扩散模型,但条件较弱。
参考来源
- Xu, S. et al. (2024). VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time. NeurIPS 2024 (Oral). arXiv:2404.10667
- Baevski, A. et al. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. NeurIPS 2020. arXiv:2006.11477
- Ho, J. et al. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239
- Prajwal, K. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation in the Wild. ACM MM 2020. arXiv:2008.10010
- Radford, A. et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. arXiv:2103.00020
- Su, S. et al. (2020). Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network. CVPR 2020. arXiv:2003.02117
- Suwajanakorn, S. et al. (2017). Synthesizing Obama: Learning Lip Sync from Audio. ACM TOG 2017. arXiv:1707.06859
- Stypułkowski, M. et al. (2024). Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation. WACV 2024. arXiv:2310.09278
- Tian, L. et al. (2024). Emo: Emote Portrait Alive — Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions. arXiv:2402.17485
- Unterthiner, T. et al. (2019). FVD: A New Metric for Video Generation. arXiv:1812.01717
- Wang, T.-C. et al. (2021). One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing. CVPR 2021. arXiv:2011.15126
- Wang, S. et al. (2021). Audio2Head: Audio-Driven One-Shot Talking-Head Generation with Natural Head Motion. IJCAI 2021. arXiv:2103.06975
- Wang, D. et al. (2023). Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis. CVPR 2023. arXiv:2212.08006
- Wei, H. et al. (2024). AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. arXiv:2403.17694
- Wu, Y. et al. (2022). AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars. NeurIPS 2022. arXiv:2209.11064
- Wu, Y. et al. (2023). AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections. SIGGRAPH Asia 2023. arXiv:2309.07237
- Yu, Z. et al. (2023). Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors. CVPR 2023. arXiv:2211.11217
- Zhang, W. et al. (2023). SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. CVPR 2023. arXiv:2211.12196
- Zhou, Y. et al. (2020). MakeItTalk: Speaker-Aware Talking-Head Animation. ACM TOG 2020. arXiv:2006.03771