DSL-FIQA
当我们用手机解锁、刷脸支付、或者让数字人替我们开会时,系统首先需要判断"这张人脸图像够不够好"。模糊、过曝、低分辨率、压缩伪影——这些退化因素会直接导致下游任务(识别、生成、驱动)的失败。Face Image Quality Assessment (FIQA) 就是为此而生的技术。#Chen-et-al.-2024
但 FIQA 领域长期存在一个根本性的概念混淆:"这张脸能被识别系统认出来"和"这张脸看起来质量好不好"是两个完全不同的问题。前者叫 Biometric FIQA (BFIQA),以 MagFace、CR-FIQA 为代表;后者叫 Generic FIQA (GFIQA),以 StyleGAN-IQA 为代表。BFIQA 方法在感知质量评估上表现不佳——ArcFace 在 PIQ23 数据集上的 PLCC 仅 0.59,远低于 GFIQA 方法的 0.74。#Su-et-al.-2023 #Boutros-et-al.-2022
DSL-FIQA 是 Snap Inc. Research 与台湾大学联合提出的 GFIQA 方法,发表在 CVPR 2024。它提出了三个核心贡献:第一,Dual-Set Degradation Learning (DSL) 通过合成退化与真实退化的双向对比学习,首次在全图级别(而非 patch 级别)解耦了退化与内容;第二,Landmark-Guided Transformer 利用 1313 个面部关键点的标识符编码,引导模型关注面部显著区域;第三,CGFIQA-40k 数据集包含 39,312 张图像,专门解决了现有数据集中肤色和性别的严重不平衡问题。#Chen-et-al.-2024
2.1 BFIQA 的目标错位
BFIQA 方法(如 MagFace、CR-FIQA、SER-FIQ)的质量定义是"这张脸对识别系统有多有用"。它们从人脸识别模型的置信度或嵌入不确定性中推导质量分数。这在门禁和安防场景下完全合理——低质量的图像确实会导致识别失败。#Meng-et-al.-2021 #Boutros-et-al.-2022 #Terhorst-et-al.-2020
但这种质量定义与人类感知存在系统性偏差。一张轻微模糊但身份特征清晰的人脸,在 BFIQA 下可能得高分(因为识别模型仍能认出),但在人类观察者看来质量明显不佳。Table 2 的实验数据印证了这一点:ArcFace 在 GFIQA-20k 上 PLCC 达 0.95(因为 GFIQA-20k 的图像质量分布与识别友好度高度相关),但在 PIQ23 上骤降至 0.59——PIQ23 包含设备曝光差异等更贴近真实感知的退化。#Chen-et-al.-2024
2.2 GFIQA 的已有方法与局限
StyleGAN-IQA 是 GFIQA 方向的先驱,它利用 StyleGAN2 的生成先验作为隐式参考,通过比较输入图像与"理想人脸"在生成空间中的距离来评估质量。这个方法在 GFIQA-20k 上取得了 PLCC 0.97 的好成绩,但有一个致命弱点:当输入图像在拍摄角度或质量上与 StyleGAN2 训练数据偏差较大时,性能显著下降。跨数据集零样本测试(CGFIQA-40k → PIQ23)中,StyleGAN-IQA 的 PLCC 仅 0.35。#Su-et-al.-2023
通用 IQA 方法(如 MUSIQ、MANIQA、HyperIQA)虽然在自然图像上表现优异,但它们忽视了人脸的特异性——人类对面部退化(特别是眼睛和嘴巴区域)的敏感度远高于其他区域。一个对自然图像"足够好"的评分,可能对人脸来说远远不够。#Ke-et-al.-2021 #Yang-et-al.-2022
2.3 DSL-FIQA 的 Insight
DSL-FIQA 的核心洞察可以归结为两句话:
- 退化表征必须与内容解耦:现有的 patch-based 对比学习方法(如 ReIQA、CONTRIQUE)假设同一图像内所有 patch 共享相同退化,这在真实场景中不成立——运动模糊可能只影响面部而背景清晰。DSL 通过构造"同内容异退化"的合成集合与"异内容异退化"的真实集合,在整图级别实现退化解耦。#Saha-et-al.-2023
- 质量评估需要面部语义引导:人类对面部显著区域(眼、鼻、嘴)的退化更敏感。关键点信息可以告诉模型"当前 patch 覆盖了哪些面部结构",从而自适应地调整各区域的重要性权重。#Chen-et-al.-2024
DSL-FIQA 的整体架构由三个子网络组成:Degradation Extraction Network(退化提取网络)、Landmark Detection Network(关键点检测网络)和 Core GFIQA Network(核心质量评估网络)。前两者在训练主网络时保持冻结,仅作为预训练的特征提取器使用。#Chen-et-al.-2024
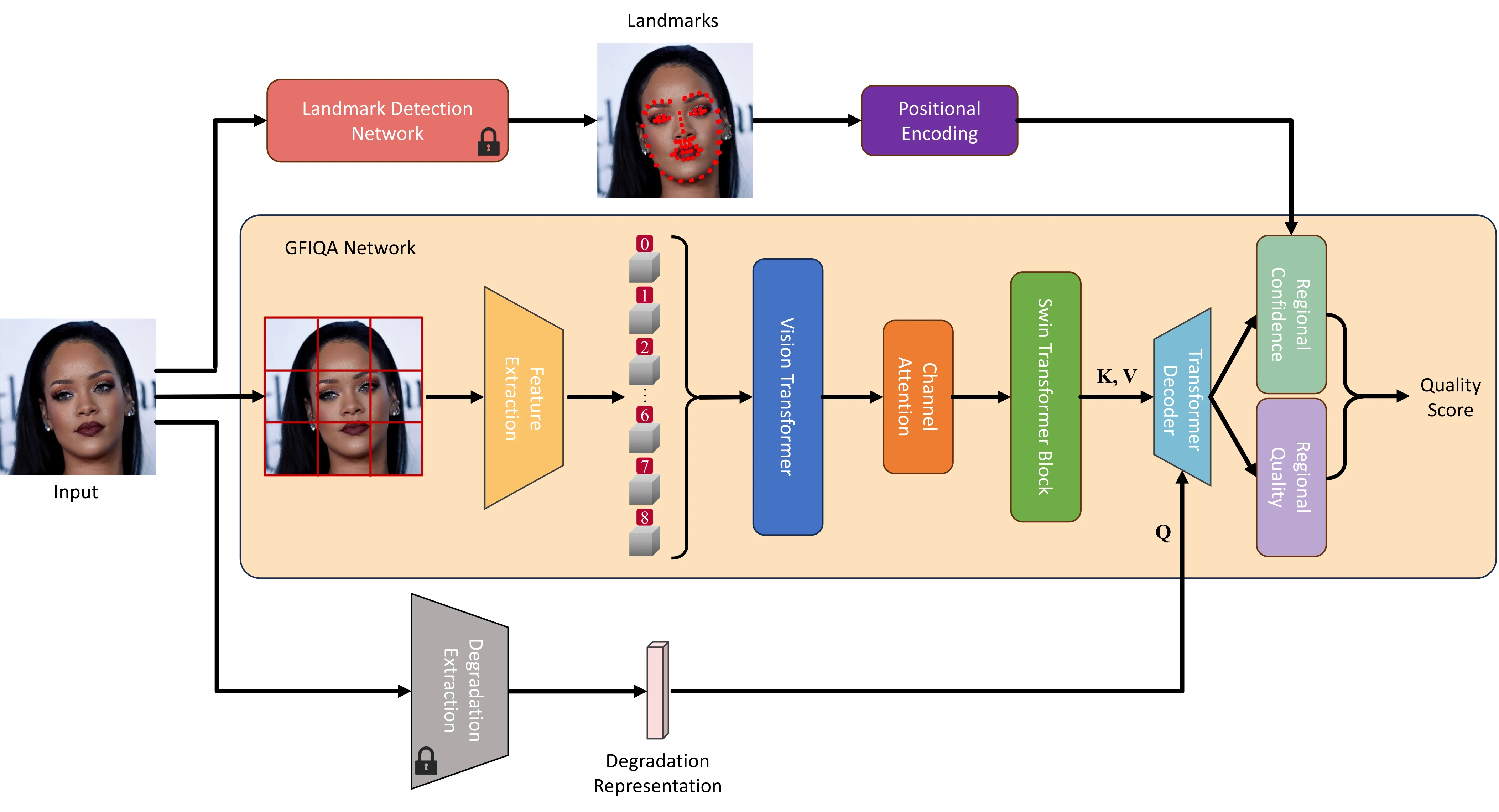
3.1 Degradation Extraction Network:从图像中剥离退化信息
退化提取网络的任务是从输入人脸图像中提取一个全局退化表征向量 $\psi(\boldsymbol{I}; z)$,该向量应尽可能只编码退化信息而与图像内容解耦。
网络架构采用轻量 CNN:6 个 $3 \times 3$ 卷积块(每块含 Batch Normalization + Leaky ReLU),特征经两层 MLP 映射为最终退化表征。总参数量仅 1.27M,输入为完整的 $512 \times 512$ 人脸图像。#Chen-et-al.-2024
为什么不用 patch-based 对比学习?
现有方法(ReIQA、CONTRIQUE)的对比学习在 patch 级别进行,假设同一图像的所有 patch 共享相同退化。这个假设在真实场景中经常不成立:一张照片中面部因运动而模糊但背景清晰,或者局部过曝而其他区域正常。DSL 通过整图级别的对比学习彻底规避了这一假设。t-SNE 可视化(Fig. 4)显示 patch-based 方法的退化表征存在严重重叠,而 DSL 能清晰分离不同退化类型。#Saha-et-al.-2023
3.2 Landmark Detection Network:1313 个关键点的语义引导
关键点检测网络基于 3DMM 模型的商业实现(RetinaFace 商用版本),首先检测 68 个基础关键点,然后通过 3DMM 拟合扩展到 1313 个密集关键点。关键设计决策:输出是关键点的固定标识符(identifier),而非坐标 $(x, y)$。#Chen-et-al.-2024
为什么不用坐标?因为 GFIQA 网络将图像裁剪为多个 $384 \times 384$ patch 处理,在未对齐或裁剪场景下,相同坐标可能对应不同的面部语义。固定标识符方案确保了语义一致性——无论 patch 覆盖面部的哪个区域,"第 42 号关键点"始终代表同一个面部结构。#Chen-et-al.-2024
该网络在低质量合成图像上进行了专门的 fine-tuning,因为 off-the-shelf 的 landmark detector 在严重退化图像上会失效。#Chen-et-al.-2024
3.3 Core GFIQA Network:251M 参数的质量预测引擎
核心质量评估网络是三个子网络中最大的,参数量 251M,主要由预训练的 VGG-19 和 ViT 贡献。其数据流如下:#Chen-et-al.-2024
flowchart TD A["输入图像\n512×512"] --> B["Degradation Network\n(frozen)\n→ 退化表征 d"] A --> C["Landmark Network\n(frozen)\n→ 关键点标识符 l"] A --> D["Crop to\noverlapping patches\n384×384"] D --> E["VGG-19\n(ImageNet)\n→ 底层特征"] E --> F["ViT-B/16\n(ImageNet)\n→ 576 tokens"] F --> G["Channel Attention\n(SE-Net)\n→ 通道精炼"] G --> H["Swin Transformer ×2\n→ 空间精炼特征 F"] H --> I["Transformer Decoder\n← cross-attention(d, F)"] C --> J["Positional Encoding\n(NeRF-style)"] I --> K["Concat(F_decoder, PE(l))"] K --> L["MLP_conf\n→ confidence map"] K --> M["MLP_quality\n→ quality map"] L --> N["Weighted Sum\n→ regional score"] M --> N N --> O["Average over patches\n→ Final MOS"]
图 2:Core GFIQA Network 数据流。退化表征通过 cross-attention 注入 Transformer Decoder(灵感来自 Stable Diffusion 的条件注入),关键点信息仅注入 confidence branch。
几个关键设计选择值得展开说明:
- Cross-attention 注入退化信息:退化表征 $d$ 作为 cross-attention 的 key/value,Swin 输出特征 $F$ 作为 query。这比直接拼接(concatenation)更有效——消融实验显示 cross-attention 比 concat 高 PLCC 0.002(0.9721 vs 0.9703)。设计灵感来自 Stable Diffusion 的条件注入机制。#Chen-et-al.-2024
- 双分支 MLP 输出:confidence branch 接收关键点信息,预测每个区域的置信度权重;quality branch 预测每个区域的质量分数。最终分数 = $\sum_i \text{conf}_i \times \text{quality}_i$。关键点只注入 confidence branch 而非 quality branch,因为关键点的作用是告诉模型"哪些区域更重要",而非直接影响"某个区域的质量是多少"。#Chen-et-al.-2024
- NeRF-style Positional Encoding:对关键点标识符应用正弦位置编码,将离散标识符映射到高维连续空间,增强网络对关键点关系的建模能力。#Mildenhall-et-al.-2020
4.1 Stage 1:Dual-Set Degradation Learning(自监督预训练)
DSL 的核心创新是构造两个互补的图像集合,通过双向对比学习实现退化表征与内容的解耦。
Dual-Set Degradation Learning (DSL)
Set $\mathcal{S}$(Synthetic Set):从单张高质量人脸图像出发,施加 15 种不同的合成退化 + 1 张无退化原图,共 $m = 16$ 张图像。关键性质:内容相同,退化各异。 Set $\mathcal{R}$(Real-world Set):从 GFIQA-20k 数据集中采样 $n = 256$ 张真实人脸图像。关键性质:内容和退化均不同。每个 batch 至少包含一张 MOS > 0.9 的高质量图像作为锚点。退化表征映射通过 Soft Proximity Mapping (SPM) 构建跨集合的对应关系。对于 $\mathcal{S}$ 中的图像 $s_i$,其退化表征 $\psi(s_i)$ 通过 $\mathcal{R}$ 中所有表征的加权线性组合构建"软近邻映射":
直觉上,$\hat{\psi}(s_i)$ 是 $\psi(s_i)$ 在真实退化空间中的"投影"。如果退化提取网络学到了好的内容无关退化表征,那么具有相同退化的合成图像和真实图像应该在表征空间中靠近。
对比损失拉近正样本对 $(\psi(s_i), \hat{\psi}(s_i))$,推远负样本对:
最终损失为双向对比损失,确保合成退化和真实退化在表征空间中的双向对齐:
双向设计的必要性从消融实验中得到了验证:仅用 $\mathcal{S} \to \mathcal{R}$ 方向(DSL-S)PLCC 为 0.9713,仅用 $\mathcal{R} \to \mathcal{S}$ 方向(DSL-R)PLCC 为 0.9709,而双向 DSL 达到 0.9721。#Chen-et-al.-2024
4.2 Stage 2:GFIQA Network(有监督训练)
Stage 1 完成后冻结 Degradation Encoder,训练 Core GFIQA Network。损失函数采用 Charbonnier loss 而非标准 L2:
其中 $\epsilon = 10^{-3}$。Charbonnier loss 在大误差时近似 L1(梯度趋近常数,outlier 鲁棒),在小误差时近似 L2(保证可微性),特别适合 GFIQA 中可能出现的标注噪声。#Chen-et-al.-2024
4.3 训练配置披露
| 配置项 | Degradation Encoder | GFIQA Network | Landmark Network | 状态 |
|---|---|---|---|---|
| 优化器 | Adam | Adam | 原文未明确给出 | 部分披露 |
| 学习率 | $3 \times 10^{-5}$ | $10^{-5}$ | 原文未明确给出 | 部分披露 |
| 训练轮数 | 300 epochs | 100 epochs | 原文未明确给出 | 部分披露 |
| Batch size | 原文未明确给出 | 16 | 原文未明确给出 | 部分披露 |
| GPU | 单卡 A100 80GB | 单卡 A100 80GB | 原文未明确给出 | 部分披露 |
| 训练时长 | ~12 小时 | ~20 小时 | 原文未明确给出 | 部分披露 |
| 温度参数 $\theta$ | 1.0 | — | — | 披露 |
| Charbonnier $\epsilon$ | — | $10^{-3}$ | — | 披露 |
| Checkpoint 选择 | 原文未明确给出 | 原文未明确给出 | — | 未披露 |
| LR Schedule | 原文未明确给出 | 原文未明确给出 | — | 未披露 |
| Weight Decay | 原文未明确给出 | 原文未明确给出 | — | 未披露 |
表:训练配置披露状态。总训练时间约 32 小时(不含 landmark fine-tune)。Degradation Encoder 仅 1.27M 参数,训练 12 小时;GFIQA Network 251M 参数主要来自预训练 backbone。#Chen-et-al.-2024
4.4 15 种合成退化
Set $\mathcal{S}$ 的基础图像来自 FFHQ 的 5000 张高分辨率人脸。每张基础图像施加 15 种合成退化:Low-light、High-light、Blur、Defocus、2x Downsample、Gaussian Noise、Gaussian Blur(kernel 3-31)、JPEG Compression(quality 1-30)、Motion Blur、Sun Flare、ISO Noise、Shadow、Zoom Blur 等,使用 torchvision 和 albumentations 库实现。每次迭代都重新采样退化类型和强度,确保训练多样性。#Chen-et-al.-2024
5.1 为什么不 resize?
推理时面临一个关键设计决策:如何处理不同分辨率的输入?DSL-FIQA 选择不 resize,而是裁剪为多个重叠 patch。这一决策基于 MUSIQ 的发现:resize 会改变图像的感知质量特征——缩小丢失高频细节,放大引入插值伪影——导致质量预测偏离真实感知。裁剪保持了原始像素尺度。#Ke-et-al.-2021
5.2 推理流程
推理时的完整流程如下:
- 输入准备:$512 \times 512$ 人脸图像(已通过 Dlib 对齐)
- 退化表征提取:整图送入 Degradation Network(frozen)→ 退化表征 $d$
- 关键点检测:整图送入 Landmark Network(frozen)→ 1313 个关键点标识符 → Positional Encoding → $PE(l)$
- 多 Patch 裁剪:将 $512 \times 512$ 分割为多个重叠的 $384 \times 384$ patch
- 逐 Patch 推理:每个 patch 独立经过 VGG-19 → ViT → SE → Swin ×2 → Transformer Decoder(cross-attention 注入 $d$)→ 双分支 MLP → 区域加权分数
- Patch 聚合:对所有 patch 的分数取平均 → 最终 MOS $\hat{p} \in [0, 1]$
推理时的关键注意点
- 推理时需处理多个 overlapping crops,实际推理时间约为单 crop 的 $N$ 倍($N$ = crop 数量),原文未给出具体 $N$ 值。
- Landmark detector 在极端退化图像上可能失效,这是整个系统的潜在瓶颈。
- 相比 StyleGAN-IQA 需要 GAN inversion 提取 latent code,DSL-FIQA 无需额外的逆映射步骤,推理更高效。
6.1 实验配置
| 配置项 | GFIQA-20k | PIQ23 | CGFIQA-40k | 状态 |
|---|---|---|---|---|
| 图像数 | 20,000 | 5,116 | 39,312 | 披露 |
| Train / Val / Test | 14K / 2K / 4K | 3,581 / 512 / 1,023 | 27,518 / 3,931 / 7,863 | 披露 |
| 分辨率 | $512 \times 512$ | $512 \times 512$ | $512 \times 512$ | 披露 |
| 标注者数 | 20 人/张 | — | 20 人/张 | 部分披露 |
| 标注量表 | 5 级 ACR | — | 5 级 ACR | 披露 |
| 推理硬件 | 原文未明确给出 | 未披露 | ||
6.2 CGFIQA-40k:解决肤色与性别偏差
CGFIQA-40k 是本文的重要贡献之一。现有数据集存在严重的人口统计学偏差:PIQ23 中 94% 男性、GFIQA-20k 中 81.6% 浅肤色。CGFIQA-40k 通过精心设计的采样策略实现了近乎平衡:51.5% 男性 / 48.5% 女性,53.8% 浅肤色 / 24.9% 中等肤色 / 21.3% 深肤色(Fitzpatrick scale)。#Chen-et-al.-2024
| 数据集 | 规模 | 浅肤色 | 中等肤色 | 深肤色 | 男性 | 女性 |
|---|---|---|---|---|---|---|
| PIQ23 | 5,116 | 74.5% | 9.0% | 16.5% | 94.0% | 6.0% |
| GFIQA-20k | 20,000 | 81.6% | 6.7% | 11.7% | 64.2% | 35.8% |
| CGFIQA-40k | 39,312 | 53.8% | 24.9% | 21.3% | 51.5% | 48.5% |
表:三个数据集的人口统计学分布对比。肤色分类标准:Light = Fitzpatrick I-II, Medium = III-IV, Dark = V-VI。#Chen-et-al.-2024

6.3 主实验:三个数据集全面 SOTA
| 方法 | 类型 | GFIQA-20k PLCC | GFIQA-20k SRCC | PIQ23 PLCC | PIQ23 SRCC | CGFIQA-40k PLCC | CGFIQA-40k SRCC |
|---|---|---|---|---|---|---|---|
| ArcFace | BFIQA | 0.9508 | 0.9510 | 0.5913 | 0.6011 | 0.9722 | 0.9723 |
| CR-FIQA | BFIQA | 0.9593 | 0.9598 | 0.6013 | 0.6021 | 0.9734 | 0.9736 |
| MUSIQ | GIQA | 0.9503 | 0.9518 | 0.7141 | 0.7101 | 0.9750 | 0.9735 |
| MANIQA | GIQA | 0.9614 | 0.9604 | 0.7202 | 0.7180 | 0.9805 | 0.9809 |
| HyperIQA | GIQA | 0.9664 | 0.9674 | 0.7152 | 0.7203 | 0.9722 | 0.9733 |
| ReIQA | GIQA | 0.9437 | 0.9446 | 0.5988 | 0.5961 | 0.9800 | 0.9802 |
| StyleGAN-IQA | GFIQA | 0.9673 | 0.9684 | 0.7013 | 0.7131 | 0.9822 | 0.9821 |
| DSL-FIQA | GFIQA | 0.9745 | 0.9740 | 0.7370 | 0.7333 | 0.9873 | 0.9880 |
表:主实验性能对比(完整 18 方法对比见原文 Table 2)。灰色 = BFIQA 方法,无底色 = 通用 GIQA 方法,加粗 = GFIQA 方法。DSL-FIQA 在三个数据集上全面超越所有对比方法。#Chen-et-al.-2024
几个关键观察:
- BFIQA 方法在 PIQ23 上断崖式下降:ArcFace 从 GFIQA-20k 的 0.95 降至 PIQ23 的 0.59,验证了 BFIQA ≠ GFIQA 的核心论点。
- DSL-FIQA 在 PIQ23 上的优势最大:PLCC 0.737 vs 第二名 StyleGAN-IQA 的 0.701,差距 0.036。PIQ23 包含设备曝光差异等真实世界退化,DSL 的退化解耦在此场景下价值最大。
- CGFIQA-40k 上所有方法都表现更好:数据集规模和多样性的增加对所有方法都有正向影响,但 DSL-FIQA 受益最多。
6.4 消融实验:每个组件贡献多少?
| 配置 | PLCC | SRCC | Δ PLCC |
|---|---|---|---|
| Baseline(无 DSL、无 Landmark) | 0.9682 | 0.9679 | — |
| + Patch-based degradation | 0.9695 | 0.9687 | +0.0013 |
| + DSL-cat(concatenation) | 0.9703 | 0.9701 | +0.0008 |
| + DSL-S(单向 $\mathcal{S} \to \mathcal{R}$) | 0.9713 | 0.9711 | +0.0010 |
| + DSL-R(单向 $\mathcal{R} \to \mathcal{S}$) | 0.9709 | 0.9707 | +0.0006 |
| + DSL(双向) | 0.9721 | 0.9719 | +0.0008 |
| + Landmark Guidance | 0.9731 | 0.9728 | +0.0010 |
| + Positional Encoding | 0.9735 | 0.9731 | +0.0004 |
| + Charbonnier Loss(完整模型) | 0.9745 | 0.9740 | +0.0010 |
表:逐步消融实验(GFIQA-20k)。从 baseline 逐步添加组件,每个组件都有正向贡献。#Chen-et-al.-2024
6.5 退化检索精度:DSL vs Patch-based vs Naive
退化表征质量的直接评估通过退化检索 mAP(mean Average Precision)衡量:给定一张查询图像,在图像库中检索具有相同退化类型的图像。
| 策略 | mAP | 说明 |
|---|---|---|
| Naive(纯合成集训练) | 39.21 | 仅在合成集 $\mathcal{S}$ 上训练对比学习 |
| Patch-based(ReIQA 式) | 52.30 | 同一图像 patch 互为正样本 |
| DSL(本文) | 72.1 | 双集合整图对比学习 |
表:退化检索精度对比(数据来源:补充材料 Table S.2)。Naive 方法 mAP 仅 39.21,说明纯合成退化无法泛化到真实世界;patch-based 方法 52.30,受限于"同图同退化"假设;DSL 达到 72.1,验证了整图级别退化解耦的有效性。主文 Table 4 报告的数值略低(Patch-based 48.2 / DSL 69.3),可能因评估设置不同。#Chen-et-al.-2024
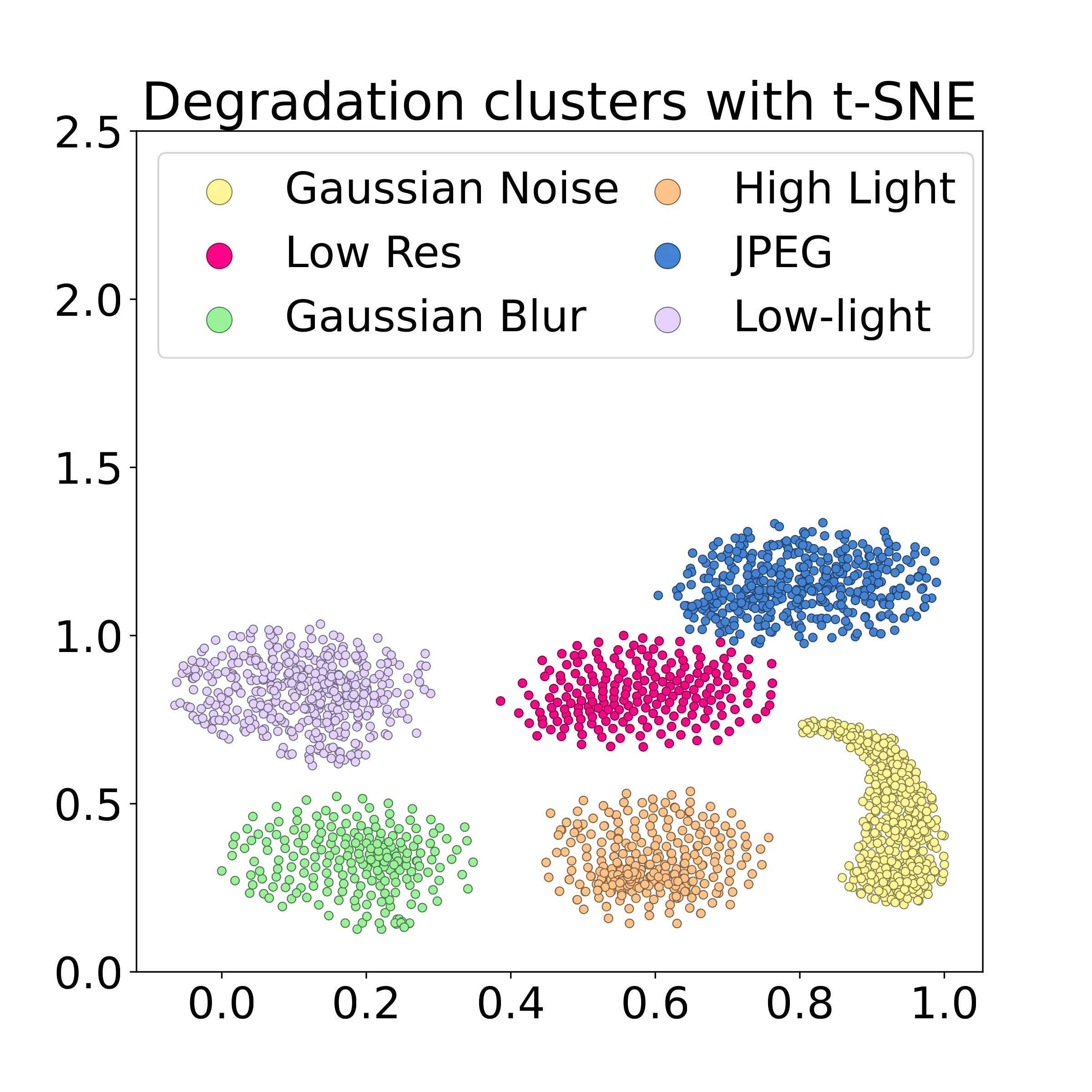
6.6 跨数据集泛化:仍是挑战
在 CGFIQA-40k 上训练的模型 zero-shot 测试 PIQ23(device-exposure subset),PLCC 仅 0.4229 / SRCC 0.4653。虽然在同类方法中最优(StyleGAN-IQA 为 0.3541 / 0.3643),但绝对值仍然较低,说明跨数据集泛化仍是 GFIQA 领域的开放性挑战。#Chen-et-al.-2024
7.1 与竞品方法的定位对比
| 维度 | DSL-FIQA | StyleGAN-IQA | CR-FIQA | MANIQA | FaceQnet |
|---|---|---|---|---|---|
| 质量定义 | 感知质量 (GFIQA) | 感知质量 (GFIQA) | 识别可用性 (BFIQA) | 通用 IQA | 识别可用性 (BFIQA) |
| 退化建模 | 双集合对比学习 | StyleGAN2 先验 | ArcFace 置信度 | ViT 特征 | ResNet50 回归 |
| 面部特异性 | Landmark 引导 | GAN 空间先验 | 识别模型隐式 | 无 | 人脸裁剪 |
| 参数量 | 251M | ~100M+ | ~65M | ~70M | ~25M |
| 训练成本 | ~32h A100 | 未披露 | 未披露 | 未披露 | 未披露 |
| 跨域泛化 | PLCC 0.42 (zero-shot) | PLCC 0.35 | — | — | — |
| 数据集贡献 | CGFIQA-40k | GFIQA-20k | — | — | — |
| 代码可用 | GitHub 81 stars | GitHub | GitHub 144 stars | GitHub | GitHub 264 stars |
7.2 局限性
- 跨数据集泛化仍然困难:zero-shot PLCC 0.42 虽然在同类最优,但距离实用仍有差距。
- Landmark detector 是系统瓶颈:极端姿态、遮挡、非正面人脸可能导致关键点检测失效,进而影响质量预测。
- 多个超参数未披露:crop 数量、PE 维度、landmark fine-tune 细节、LR schedule、weight decay 等原文未明确给出,影响复现。
- 无 License 声明:代码仓库无 License,商业使用存在法律风险。
- 推理效率未量化:多 patch 推理的 crop 数量和总推理时间原文未给出。
7.3 可操作启发
- 对数字人评测的启示:DSL-FIQA 的 GFIQA 定位使其比 BFIQA 方法更适合评估数字人生成帧的感知质量。在数字人评测框架的 L0 层(基础质量筛选),DSL-FIQA 可替代 FaceQnet/CR-FIQA 作为更准确的质量门控。
- 退化解耦的通用价值:DSL 的双集合对比学习思路不仅适用于人脸——任何需要解耦退化与内容的图像质量评估任务(如医学影像、遥感图像)都可以借鉴。
- 数据集聚合偏差的重要性:CGFIQA-40k 的工作证明了 FIQA 模型在偏差数据集上训练后,对不同人群的预测可能存在系统性偏差。这对任何面向用户的 AI 系统都是重要警示。
- Landmark 标识符编码:用固定标识符替代坐标的设计思路,在任何需要空间语义引导但输入可能被裁剪/未对齐的场景中都有参考价值。
一页速查
- 核心创新:Dual-Set Degradation Learning(整图级退化解耦)+ Landmark-Guided Transformer(面部语义引导质量评估)。
- 关键数字:CGFIQA-40k PLCC 0.9873,PIQ23 zero-shot PLCC 0.4229,退化检索 mAP 72.1(vs naive 39.21)。
- 训练成本:单卡 A100 约 32 小时(12h DSL + 20h GFIQA),251M 参数。
- 最大贡献:CGFIQA-40k 数据集(39,312 张,平衡肤色/性别)具有独立价值。
- 最大局限:跨数据集泛化 PLCC 0.42,多个超参数未披露。
参考来源
- Chen, W.-T. et al. (2024). DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer. CVPR 2024. arXiv:2406.09622
- Su, S. et al. (2023). Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model (StyleGAN-IQA / GFIQA-20k). IEEE TMM. arXiv:2207.04904
- Saha, A. et al. (2023). Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild. CVPR 2023. arXiv:2304.00451
- Boutros, F. et al. (2022). CR-FIQA: Face Image Quality Assessment by Confidence-Ranked Face Recognition. CVPR 2023. GitHub
- Meng, Q. et al. (2021). MagFace: A Universal Representation for Face Recognition and Quality Inference. CVPR 2021. arXiv:2103.06627
- Terhorst, P. et al. (2020). SER-FIQ: Unsupervised Estimation of Face Image Quality Based on Stochastic Embedding Robustness. CVPR 2020. arXiv:2003.09332
- Ke, J. et al. (2021). MUSIQ: Multi-scale Image Quality Transformer. ICCV 2021. arXiv:2108.05997
- Yang, S. et al. (2022). MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment. CVPRW 2022. arXiv:2204.08950
- Mildenhall, B. et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV 2020. arXiv:2003.08934