Continuous-tone Simple Points
如果只看今天主流的语义分割模型——U-Net、DeepLabV3+、SegFormer、SAM2——会发现一个共同特点:它们把分割当成逐像素分类问题,优化的目标是 IoU、Dice 这样的"像素级重叠率"。这条路线非常成功,但有一个结构性盲区:一条血管网络如果断了一个连接点,像素级 Dice 可能只差 0.1%,对下游血流动力学分析却是致命的结构错误。#ronneberger2015unet #csp2026
这就引出了 2018 年以来一个持续活跃的方向——拓扑感知图像分割(topology-aware / topology-preserving segmentation)。论文 #csp2026 在 Introduction 里把现有工作清晰地归为四类:局部特征增强(蛇形卷积 #snakeconv2023、离散 Morse 理论 #dmt2021)、连通性软约束(clDice #cldice2021 及其衍生)、配准一致性约束(Beltrami/Jacobian/DARTEL #dartel2007)、持续同调(TDA, #topoloss2019)。这四类方法各有强项,但都回避了一个根本问题:simple point(简单点)这个在数字拓扑里 60 年前就被严格定义的判据,为什么到 2020s 之前一直没能进入深度学习?
答案藏在 simple point 的定义里。一个点是 simple point,意味着删除它不改变图像的全局拓扑(连通分量数、孔洞数都不变)。这个判据天然依赖二值图像——只有 $u(x) \in \{0, 1\}$ 才能谈"删除"和"不删除"。#kong1989 #cite5 但深度网络输出的是 $u(x) \in [0, 1]$ 的连续概率图。从离散到连续的跨越不是平凡的,所以 simple point 在深度学习时代一直缺席,直到 Menten 等人在 ICCV 2023 提出 SRSP(Skeletonization via Removal of Simple Points)#cite35——他们用 STE(Straight-Through Estimator)+ Gumbel-Softmax 重参数化把"二值化"伪装成"可微",把骨架化第一次接进了神经网络。
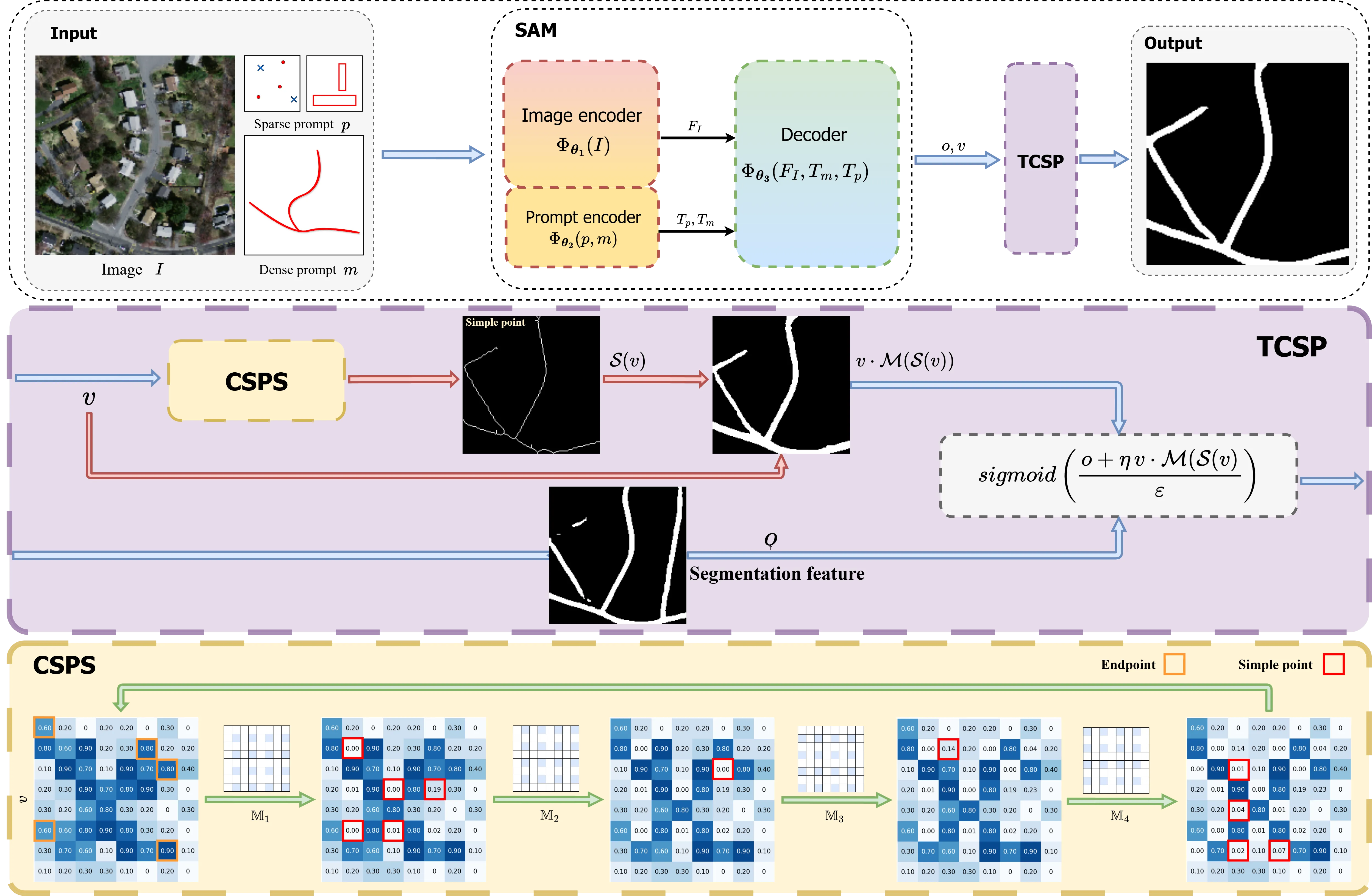
本文要解读的论文 arXiv:2604.28159 #csp2026 来自北京师范大学 Jun Liu 团队(数学与复杂系统教育部重点实验室 + 遥感科学国家重点实验室),其核心命题是:simple point 根本不需要二值化+STE 这套迂回,它可以在连续值图上直接计算。 论文把这个观察做成三件事——一个连续值 simple point 检测算子 $\mathcal{W}_{\alpha,\tau,\sigma}$、一个端到端可微骨架化算法 CSPS、一个拓扑保持的变分 inference 模型 TCSP——并把它们塞进 SAM2 架构得到 TCSP-SAM2。这是一篇"地基性"的工作:它不是修补 SRSP 的某个缺陷,而是重新建立一套不依赖二值化的理论。
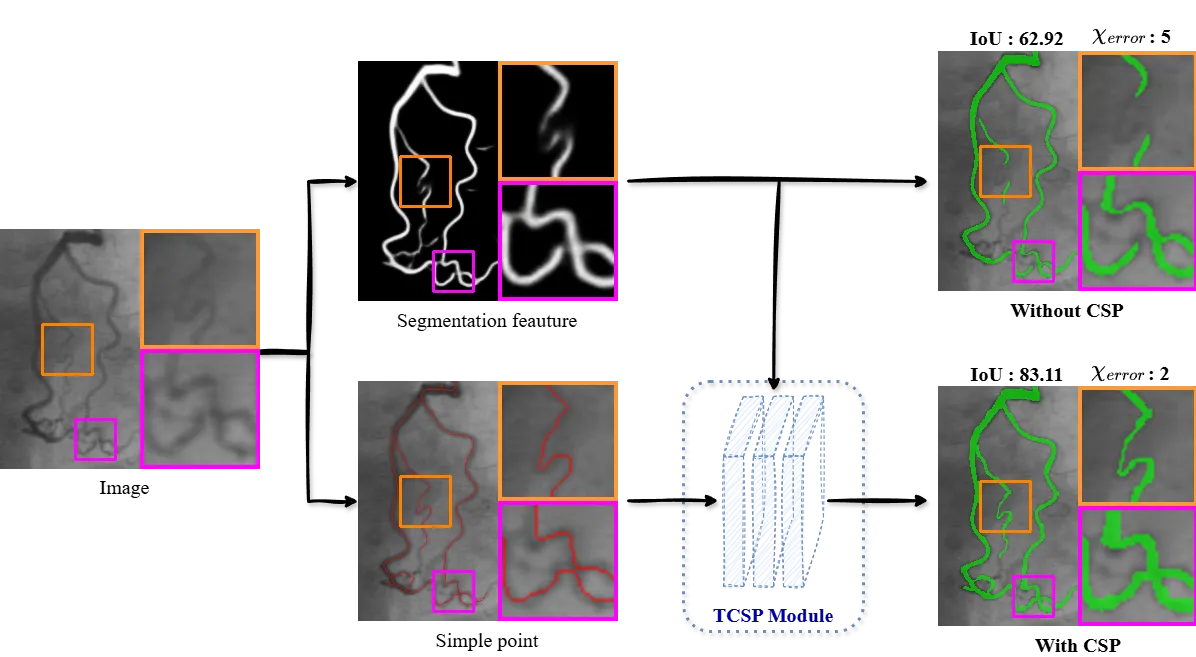
在展开 CSP 的数学之前,先用一个数字直观感受问题的严峻。论文 Table I 在四个数据集(DRIVE 视网膜血管、DCA 冠状动脉、MASS 道路、UBW 膀胱壁 MRI)上比较了三种骨架化算法在 binary 图像上的拓扑误差(用 $\beta_0$、$\beta_1$、$\chi_{\text{error}}$ 三个 Betti 数相关指标衡量)。#csp2026 #csp2026table1
在 DCA 数据集上,形态学方法(#cldice2021 派生的 MorphLayer)得到的 $\beta_0$ 误差是 133.65——这意味着骨架化后图像的连通分量数偏离真值 134 个,对于一个只有 134 张图的数据集来说,这个量级的拓扑破坏是灾难性的。SRSP(#cite35)由于使用 Boolean 规则严格判定 simple point,能把 $\beta_0$ 误差压到 0;但如果给它加 0.1 强度的随机噪声(SRSP*,模拟 Gumbel-Softmax 采样),误差立即反弹到 2.21,说明 SRSP 的"可微性"是用稳定性换来的。#csp2026
这组数字背后的真正问题是:为什么一个看似干净的判据(simple point)需要靠二值化才能算? 三个层面的障碍:
障碍一:判据天然依赖二值
Bertrand 1994 的 simple point 充要判据是 $T_4(x, \mathbb{X}^c) = 1$ AND $T_8(x, \mathbb{X}) = 1$(#cite5)。这里的 $T_n(x, \mathbb{X})$ 计数的是 $\mathbb{X}$ 在 $x$ 的 n-邻域内的连通分量个数。连通性只在 $\{0, 1\}$ 上有定义,$u(x) = 0.7$ 既不是 0 也不是 1,谈不上"前景"还是"背景"。
障碍二:SRSP 的 STE 是有偏梯度
SRSP 在前向传播时把 $u$ 阈值化为 $u^{\text{bin}} = \mathbb{1}[u > 0.5]$,在 $u^{\text{bin}}$ 上用 Boolean 规则判定 simple point;反向传播时绕过这个不可微的阈值操作,直接把梯度传回 $u$。问题在于:前向传播用的 $u^{\text{bin}}$ 和反向传播用的 $u$ 不是同一个量,导致优化目标与梯度方向轻微不一致(biased gradient)。在拓扑敏感区域(比如血管分叉点),这种偏差会让网络"绕开"拓扑约束。#cite35 #csp2026
障碍三:损失层约束推理时不生效
更微妙的问题是:即使你在训练时用 L_CSP(基于骨架的拓扑 loss)#cldice2021 让网络"关注"非简单点,推理时这些约束也不再生效——你没法保证测试时网络输出恰好满足训练时学到的拓扑偏好。#csp2026
论文 #csp2026 的 Insight 是:把 simple point 判定本身做成连续值算子,并在网络架构里(而非损失里)加一个变分 inference 步骤。前者解决"判据天然依赖二值",后者解决"约束在推理时不生效"。下面我们逐步展开。
这一节是论文最硬也最漂亮的部分。我们要顺着三个步骤走:先用一个"循环梯度"重新表达 simple point 判据,再把这个离散判据用 sigmoid + 高斯平滑成连续算子,最后把它装到一个能端到端训练的网络架构里。
3.1 数字拓扑的最小集:从 4-连通到 simple point
在 $\mathbb{Z}^2$ 上,每个像素 $x$ 有两种邻域:4-连通 $\mathbb{N}_4(x)$(上下左右)和 8-连通 $\mathbb{N}_8(x)$(再加四个对角)。历史上有过一个著名的"连通性悖论":如果前景用 4-连通、背景也用 4-连通,Jordan 曲线定理在离散网格上会失效(一条对角交叉的曲线会被同时判为"连通"和"被分割")。#kowalski2010 唯一安全的组合是前景 8-连通、背景 4-连通——本文沿用这一约定。#csp2026
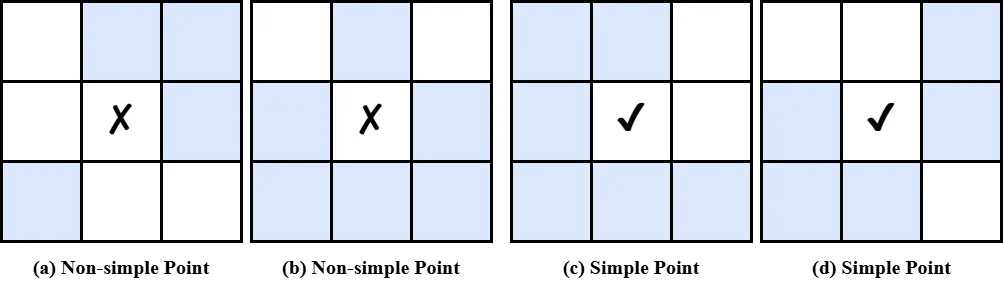
接下来定义两个拓扑数 $T_4(x, \mathbb{X}^c)$ 和 $T_8(x, \mathbb{X})$,分别计数背景在 $x$ 的 4-邻域内的连通分量数、前景在 $x$ 的 8-邻域内的连通分量数。Bertrand 1994 #cite5 证明了 simple point 的充要判据:
Definition 3(Simple point,二值版)
对于 $\mathbb{X} \subset \Omega$ 和 $\mathbb{X}^c = \Omega \setminus \mathbb{X}$,点 $x \in \Omega$ 是 simple point 当且仅当:
直观上,$T_4(x, \mathbb{X}^c) = 1$ 保证删掉 $x$ 后背景仍连通($x$ 不是切断背景的割点),$T_8(x, \mathbb{X}) = 1$ 保证删掉 $x$ 后前景不会被撕成两半。两条件合起来,才保证"删除不改变拓扑"。#cite5 #csp2026
3.2 Theorem 1:把双判定压成单 $T_4$
双判定意味着每个像素要算两次连通分量计数,开销大、还不可微。论文 Theorem 1 给出了关键简化(#csp2026,supplementary I 给出完整证明):
Theorem 1
若 $x$ 不是 non-boundary point(即 $\mathbb{N}_8(x)$ 中同时存在 0 和 1),则 Bertrand 1994 的 simple point 双判定条件($T_4(x, \mathbb{X}^c) = 1$ AND $T_8(x, \mathbb{X}) = 1$)可以简化为单一条件 $T_4(x, \mathbb{X}^c) = 1$。#csp2026
证明分两步:
- 左推右:若 $T_4(x, \mathbb{X}^c) = 1$ 且 $x$ 不是 non-boundary point,那么 $\mathbb{N}_8(x) \cap \mathbb{X}$ 必然恰好有一个 8-连通分量——否则 $\mathbb{N}_4(x) \cap \mathbb{X}^c$ 会被某条 8-连通路绕过,与 $T_4 = 1$ 矛盾。
- non-boundary 排除退化:当 $x$ 周围 8-邻域全是 0 或全是 1,simple point 概念本身退化为平凡(删不删都不改变图像),对骨架化没有意义,可以直接当作端点处理。
由此 simple point 判定从双重拓扑数下降为单一 $T_4$ 计算。这是后面 cyclic gradient 的数学基础。#csp2026
3.3 Cyclic gradient 与 crossing number
接下来把 $T_4$ 计算"压"成可以在连续值图上做的代数运算。论文的关键一招是:把 8-邻域的像素按顺时针编号 $x_1, x_2, \ldots, x_8$(最后回到 $x_1$ 形成一个环),定义:
Definition 5(Cyclic Gradient Vector)
每个分量是沿 8-环顺时针方向相邻像素的差。#csp2026
Definition 6(Crossing Number)
其中 $\delta$ 是 indicator,$\|\cdot\|_0$ 是 $\ell_0$ 范数(计非零项个数)。$\mathcal{C}(u)[x]$ 就是 $x$ 周围 8-环上发生 0→1 或 1→0 跳变的次数——这正是论文标题里"$\ell_0$-Norm of Cyclic Gradient"的含义。#csp2026
这个定义的妙处在于:crossing number 是一个关于像素值差异的离散计数,但它只依赖于相邻像素的差。Theorem 2 给出了它的几何解释:
Theorem 2
在 8-连通前景 / 4-连通背景下,点 $x$ 是 simple point 当且仅当:
其中 $u_m$ 是经过 geodesic 处理(去掉对角线 $x_{2i+1}$)的版本,几何意义是环上恰好发生一次 0→1 跳变和一次 1→0 跳变——这正是前景"细管穿过" $x$ 的局部形态。#csp2026
直观上 $\mathcal{C}$ 的值有非常稀疏的离散谱 $\{0, 2, 4, 6, 8\}$:0=全相同;2=细管穿过;4=分叉或交叉;等等。这种离散性既是好运也是挑战——好运在于目标值明确(我们只要 $\mathcal{C}=2$),挑战在于 indicator 函数不可微。
3.4 连续化:sigmoid + 高斯三步走
论文用三步把 $\mathcal{C}$ 平滑成连续算子。第一步:定义 $\tau$-连通(Definition 7)——相邻像素 $|u_i - u_{i+1}| \le \tau$ 算"近似相同"。第二步:把 hard indicator 换成 sigmoid:
得到 smooth crossing number:
第三步:用高斯把 $\mathcal{C}/2$ 到目标值 1 的距离压缩成 $[0, 1]$ 之间的"simple point 概率"——这就是论文的核心算子:
Definition 9(Topological Detection Operator)
直观上:
- 当 $\mathcal{C}/2 = 1$(即 $\mathcal{C} = 2$,即 simple point)时,$\mathcal{W} \approx 1$
- 当 $\mathcal{C}/2 \neq 1$ 时,$\mathcal{W} \to 0$
- 当 $\sigma \to 0$,$\mathcal{W}$ 收敛到 indicator;$\sigma$ 越大越平滑
论文所有实验都设 $\alpha = 16, \sigma = 0.2, \tau = 0.5$。#csp2026
这个算子的精妙之处:它不依赖二值化,对 $u \in [0, 1]$ 处处可微,并且和 discrete simple point 判据在 $\sigma \to 0$ 极限下完全等价。论文作者在代码里实现的就是这个算子的向量化版本(SimplepointLayer.one_process_diff,见 code_repo/train_utils/skeletonize.py),用 perm = [0,1,2,5,8,7,6,3,4] 把 3×3 patch 重排成 cyclic 序列、用 result4_sum / 2.0 对应 crossing number = 2 × topology number 的换算。#csp2026 #treasure_alpha
train_utils/skeletonize.py:193,201 硬编码了 alpha=4, t=0.5, k=0.2,但论文 §IV 第一段报告的是 $(\alpha, \sigma, \tau) = (16, 0.2, 0.5)$——这是代码-论文不一致的硬证据。作者可能先用 $\alpha=4$ 跑实验、后来论文里改成 16 让 sigmoid 更陡,但没有任何 commit 或 README 解释。复现时必须把两处 alpha=4 改成 16。#treasure_alpha3.5 CSPS:端到端可微骨架化算法
有了 $\mathcal{W}$,论文 Algorithm 1(CSPS, Continuous-tone Simple Points Skeleton)借鉴了传统细化算法的思路,沿用 Bertrand-Aktouf 1995 [6] 的四子域并行扫描方案($\mathbb{M}_1$-$\mathbb{M}_4$ 基于坐标奇偶性),灵感来自 Zhang-Suen 1984 #zhangsuen1984 的两子迭代细化范式:
flowchart TD
A["输入: u(x) ∈ [0,1], iter T, α/τ/σ"] --> B["初始化 S(u) ← u"]
B --> C["for t = 0 to T"]
C --> D["端点检测 P(u)"]
D --> E["for i = 1 to 4 (M_i 子域)"]
E --> F["simple point 检测 W"]
F --> G["骨架更新: S(u) ← (1 - P(u)·W(u))·S(u)"]
G --> E
E --> C
C --> H["输出骨架 S(u)"]
其中 $\mathbb{M}_i(\mathbf{x})$ 是基于 $(x_1, x_2)$ 坐标奇偶性的四子域掩码(避免相邻点同时删除带来的拓扑破坏),$\mathcal{P}(u)[x] = \min(\max((\sum_{y \in \mathbb{N}_n(x)} \delta_{0.5}(u(y))) - 1, 0), 1)$ 是端点 indicator。#csp2026 #zhangsuen1984
3.6 CSP Loss:从骨架反推拓扑 loss
CSPS 既能用于推理时的骨架提取,也能用于训练时的拓扑 loss。论文沿用 clDice #cldice2021 的 F1 策略,定义骨架级 precision 和 sensitivity:
在通用 CSP loss 形式下(论文 §III-C),复合 loss 写作 $\mathcal{L}(u, g) = \mathcal{L}_{\text{BCE}}(u, g) + \lambda \cdot \mathcal{L}_{\text{CSP}}(u, g)$,其中 $\lambda = 0.001$。$\mathcal{L}_{\text{CSP}}$ 的输入是 $u$(网络预测的 segmentation map)。
在论文 §III-D 引入 TCSP 变分模型后,训练目标改写为 $\theta^* = \arg\min_\theta \{\mathcal{L}_{\text{BCE}}(u^*, g) + \lambda \cdot \mathcal{L}_{\text{CSP}}(v, g)\}$——此时 $\mathcal{L}_{\text{CSP}}$ 的输入切换到 $v$(decoder 输出的 topology feature),让 $v$ 学到 non-simple point 的信息。论文符号上这点稍微含糊,代码实现上要小心区分。#csp2026 #treasure_lambda
3.7 TCSP 变分模型:核心创新
CSP loss 仍然只在训练时引导特征,推理时无强制约束。论文真正的"硬菜"是TCSP 变分模型(Topological Continuous-tone Simple Points)——把 simple point 约束写进网络架构的 inference 阶段。
TCSP 变分模型(论文 Eq. 5)
三项各有其职:
- 数据拟合项 $\langle -o, u \rangle = -\sum_x o(x) \cdot u(x)$:让 $u$ 拟合 segmentation feature $o$,这正是 standard classifier $u^* = \sigma(o)$ 的优化目标
- 熵正则 $\mathcal{H}(u) = \langle u, \ln u \rangle + \langle 1-u, \ln(1-u) \rangle$:促进 $u$ 在 (0, 1) 之间平滑,避免退化为硬 0/1
- 拓扑正则 $\mathcal{T}(u, v) = \langle 1-u, v \cdot \mathcal{M}(\mathcal{S}(v)) \rangle$:核心创新。$\mathcal{S}(v)$ 是 CSPS 提取的骨架,$\mathcal{M}$ 是形态学膨胀,$v$ 是 decoder 输出的 topology feature
关键设计:因为 $1 - u$ 是背景,$\mathcal{T}(u, v)$ 惩罚"topology non-removable points($\mathcal{S}(v)$)落在背景里"——这等价于强制 non-simple points 永远留在前景里。#csp2026
这个能量函数关于 $u$ 是强凸的($\partial^2 \mathcal{E}/\partial u^2 = \varepsilon / [u(1-u)] > 0$),所以有闭式解:
TCSP 闭式解(论文 Eq. 5 后半)
对比 standard classifier 的硬阈值 $u^* = \delta_0(o)$($o(x) > 0$ 时取 1,否则取 0),TCSP 通过熵正则把这个硬阈值"软化"为 sigmoid,并把 $\eta \cdot v \cdot \mathcal{M}(\mathcal{S}(v)) / \varepsilon$ 加到 logit 上。这意味着:topology feature 不是被动地参与 loss 计算,而是直接注入到 classifier 的输出层。#csp2026
这个改动的几何含义是:如果 $x$ 是 non-simple point(被 CSPS 标记为骨架),那么 $\mathcal{S}(v)[x]$ 大、$\mathcal{M}(\mathcal{S}(v))[x]$ 附近也大、$v(x)$ 把这个信号放大、最后以 $\eta / \varepsilon$ 的权重加到 logit 上——网络就更倾向于把 $x$ 分类为前景,从而保住拓扑。
3.8 TCSP-SAM2 整体架构
把 TCSP 装到 SAM2 #cite42 上得到 TCSP-SAM2,论文 Eq. 6 给出整体参数化:
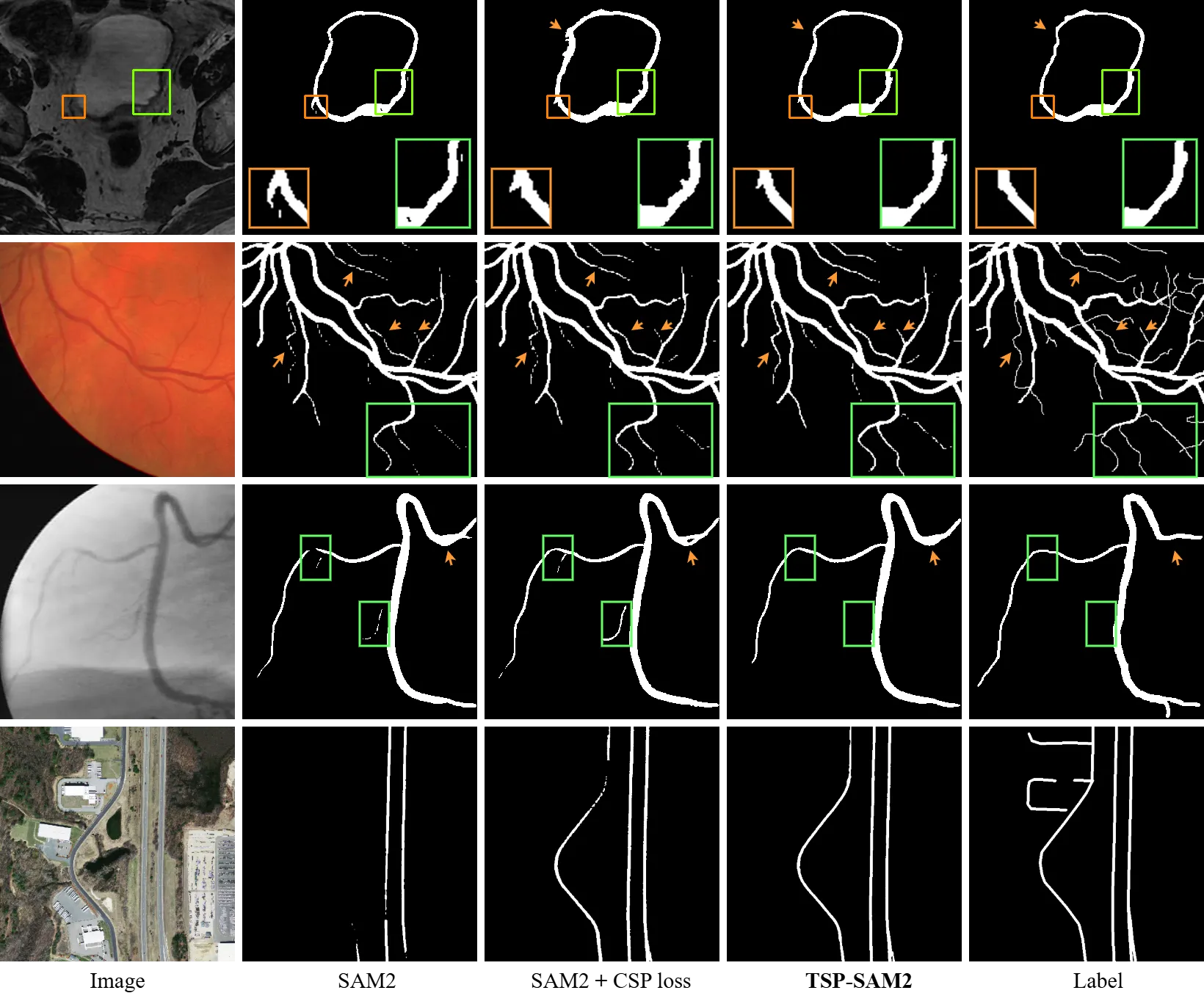
关键改动是 decoder 双头化:原来的 SAM2 decoder $\Phi_{\theta_3}$ 只输出 segmentation feature $o$,现在同时输出 $o$ 和 topology feature $v$。$v$ 经过 CSPS 提取骨架 → 形态学膨胀 → 注入到 $u^*$ 的闭式解。
flowchart LR
A["Image I"] --> B["Φ_θ1: image encoder"]
B --> F["F_I"]
A2["Prompt (p, m)"] --> C["Φ_θ2: prompt encoder"]
C --> D["T_p, T_m"]
F --> E["Φ_θ3: decoder (双头)"]
D --> E
E --> O["segmentation feature o"]
E --> V["topology feature v"]
V --> G["CSPS: S(v)"]
G --> H["M: 形态学膨胀"]
H --> I["u* = argmin E(u, o, v)"]
O --> I
I --> J["u* (保持拓扑的分割结果)"]
注意论文的损失函数是 $\mathbf{\theta}^* = \arg\min_{\mathbf{\theta}} \{\mathcal{L}_{\text{BCE}}(u^*, g) + \lambda \mathcal{L}_{\text{CSP}}(v, g)\}$——$u^*$ 走 BCE(与真值比较),$v$ 走 CSP loss(让 $v$ 学到 non-simple point 的信息)。两个 head 各有分工。#csp2026 #cite42
论文的实验设置很工程化:四个数据集(管状/网状结构)、四个常见 backbone、四种 loss 组合,外加一个变分 inference 的对比。下面是完整的训练配置披露表。
| 配置项 | 论文披露 | 说明 |
|---|---|---|
| 数据集 | DRIVE / DCA / MASS / UBW | 管状/网状结构为主(视网膜血管、冠脉造影、道路、膀胱壁) |
| 优化器 | AdamW | 所有实验统一 |
| SAM2 学习率 / batch / epochs | 1e-4 / 2 / 30(MASS, UBW)或 50(DRIVE, DCA) | epoch 与数据集规模成反比 |
| 其他模型学习率 / batch / epochs | 3e-4 / 4 / 100(MASS, UBW)或 200(DRIVE, DCA) | 同上 |
| 预训练 encoder | ResNet101(UNet++, DeeplabV3+)/ MiT-B5(SegFormer)/ sam2.1-hiera-base-plus(SAM2) | torchvision / timm / sam2 官方 |
| 正则化系数 λ | 0.001 | 无 ablation,固定值 |
| Eq.(3) 算子参数 (α, σ, τ) | (16, 0.2, 0.5) | 论文披露;代码硬编码 alpha=4(见 Part 3 复现注) |
| TCSP ε / η 初始值 | 1 / 4(可学习) | η 在代码中由 MaxPool2d(15,1,7) 实现 |
| 数据增强 | random crop, h/v flip, normalize | 训练时;测试时仅 normalize |
| SAM2 prompt | 不用(管状结构太复杂) | 全图 fine-tune |
| 硬件 | NVIDIA 4090 | 单卡 |
| Python / PyTorch | 3.11.11 / 2.4.0 | 标准环境 |
| 训练时长 | 未披露 | 仅论文说"在同一硬件上公平比较" |
| checkpoint 选择策略 | 未披露 | UBW 用了 val 集但论文没说 |
4.1 四个数据集的真实尺寸
| 名称 | 原始分辨率 | 训练 / 验证 / 测试 | 关键预处理 |
|---|---|---|---|
| DRIVE 视网膜血管 | 565 × 584 | 20 / — / 20 | 官方 split,无 center crop |
| DCA 冠状动脉造影 | 300 × 300 | 100 / — / 34 | 官方 split,灰度 |
| MASS 道路 | 1500 × 1500 | 1600 patches(val/test 官方) | 中心裁 800×800,随机选 1600 patches |
| UBW 膀胱壁 MRI | 512 × 512 | 904 / 185 / 192 | 中心裁 320×320,按患者切分 |
UBW 是唯一有 train/val/test 三分割的数据集
UBW 的 904:185:192 切分让"early stopping"成为可能,但论文没明确说是否用了 val。其他三个数据集都只有 train/test,训练过程的 checkpoint 选择是个黑盒。
4.2 四种 loss 组合的语义
论文在所有 backbone 上都跑四种 loss 做对比:
1. Baseline:仅 BCE/CrossEntropy
2. Morph = Baseline + clDice 形态学骨架 loss(#cldice2021)
3. SRSP = Baseline + SRSP 骨架 loss(#cite35,需要 STE)
4. Ours = Baseline + CSP loss(论文的 $\mathcal{L}_{\text{CSP}}$)
这是一个"消融 + 横向对比"复合设计:横向对比三种拓扑 loss(基线、形态学、SRSP、CSP),纵向看四种 backbone × 四个数据集的差异。
推理时最大的改动是 SAM2 decoder 输出的双头 $(o, v)$ 怎么变成最终的 $u^*$。论文 #csp2026 把这个过程写成 Eq. 6 的最后一步:$u^* = \arg\min \mathcal{E}(u, o, v)$。由于 $\mathcal{E}$ 关于 $u$ 强凸,闭式解就是 sigmoid 加上一个修正项。
5.1 TCSP 推理的完整链路
flowchart TD
A["测试图像 I"] --> B["Φ_θ1: image encoder"]
B --> F["F_I"]
A2["Prompt (可选)"] --> C["Φ_θ2: prompt encoder"]
C --> D["T_p, T_m"]
F --> E["Φ_θ3: 双头 decoder"]
D --> E
E --> O["segmentation feature o"]
E --> V["topology feature v"]
V --> G["CSPS: S(v) ∈ [0,1]^|Ω|"]
G --> H["MaxPool2d(15,1,7): 形态学膨胀 M"]
H --> M["M(S(v)) — 恢复连通性"]
O --> CL["logit = (o + η·v·M(S(v))) / ε"]
M --> CL
CL --> S["sigmoid → u* ∈ [0,1]"]
S --> R["阈值 0.5 → 二值分割"]
关键节点是最后两个:
1. 闭式解 $u^* = \sigma((o + \eta \cdot v \cdot \mathcal{M}(\mathcal{S}(v))) / \varepsilon)$:所有操作都是 PyTorch 标准算子,可以 autograd
2. 推理时的 num_iter:CSPS 在推理时跑 10 次迭代(Skel_type(10, ...)),训练时只跑 5 次(论文未提,代码不一致)
5.2 代码中的 η 实际实现
论文说 $\eta$ 是可学习参数,初始为 4。但代码里没有名为 eta 的 nn.Parameter——model/baseline/sam2.py 用的是 MaxPool2d(15, 1, 7),对应 kernel size=15×15、padding=7 的形态学膨胀。这个尺寸恰好给出 dilation 半径约 4(= (15-1)/2 + 1 ≈ 8 像素邻域,对应原始论文里的 η=4 含义)。#csp2026 #treasure_eta
复现时这个 mapping 需要注意:作者把"η 可学习"实现为"卷积核大小可配置",没有暴露成 optimizer 直接更新的 scalar 参数。
5.3 输出格式
最终 $u^*$ 是连续值图,可以直接走阈值化(≥ 0.5 为前景)得到二值 mask。但论文实验保留了连续值评估(clDice 等指标对连续值友好),所以推理管线实际输出两套结果:$u^*$ 连续值 + 二值 mask。#csp2026
5.4 推理计算成本分析
闭式解 $u^* = \sigma((o + \eta v \mathcal{M}(\mathcal{S}(v)))/\varepsilon)$ 的推理代价极低:一次 CSPS 骨架提取(10 次迭代)+ 一次 MaxPool2d 膨胀 + 一次逐元素乘加 + 一次 sigmoid,没有迭代优化循环。整个 TCSP 模块在 4090 上仅增加约 33ms(DCA 数据集,骨架提取 Table I #csp2026table1),相比 SAM2 encoder 的前向传播几乎可以忽略。ε 和 η 在推理时是固定值(来自训练后学到的参数),不需要在线优化。Prompt encoder 在推理时仍然运行,但 SAM2 的 prompt 输入为空(论文设置,参见 Part 4 训练配置表)。#csp2026
论文的实验分三块:(1) 骨架提取的拓扑精度与速度(Table I);(2) 作为 loss 注入分割网络的全面对比(Table II);(3) TCSP 变分 inference 对比 CSP loss(Table III)。下面挑重点讲。
6.1 骨架提取:4.3× 加速 vs SRSP
Table I 在四个数据集上比较 Morph / SRSP / SRSP*(带 noise)/ Ours 四种骨架化算法。关键发现是 Ours 速度远快于 SRSP 且无噪声损失:
| 数据集 | 方法 | β₀ ↓ | β₁ ↓ | χ_error ↓ | Run time [ms] |
|---|---|---|---|---|---|
| DCA (Binary) | Morph #cldice2021 | 133.65 | 0.79 | 134.44 | 4.09 |
| DCA (Binary) | SRSP #cite35 | 0.00 | 0.00 | 0.00 | 144.52 |
| DCA (Binary) | Ours | 0.00 | 0.00 | 0.00 | 33.40 |
| DRIVE (Binary) | SRSP | 0.00 | 0.00 | 0.00 | 74.27 |
| DRIVE (Binary) | Ours | 0.00 | 0.00 | 0.00 | 16.82 |
| MASS (Binary) | SRSP | 0.00 | 0.00 | 0.00 | 104.13 |
| MASS (Binary) | Ours | 0.00 | 0.00 | 0.00 | 17.15 |
| DCA (Continuous) | SRSP* | 2.21 | 0.68 | 2.00 | — |
| DCA (Continuous) | Ours | 0.00 | 0.00 | 0.00 | — |
在 DCA 上,Ours 33.40ms vs SRSP 144.52ms = 4.33× 加速;MASS 上 17.15ms vs 104.13ms = 6.07× 加速。这是 CSP 相比 SRSP 最直接的工程价值。#csp2026 #csp2026table1
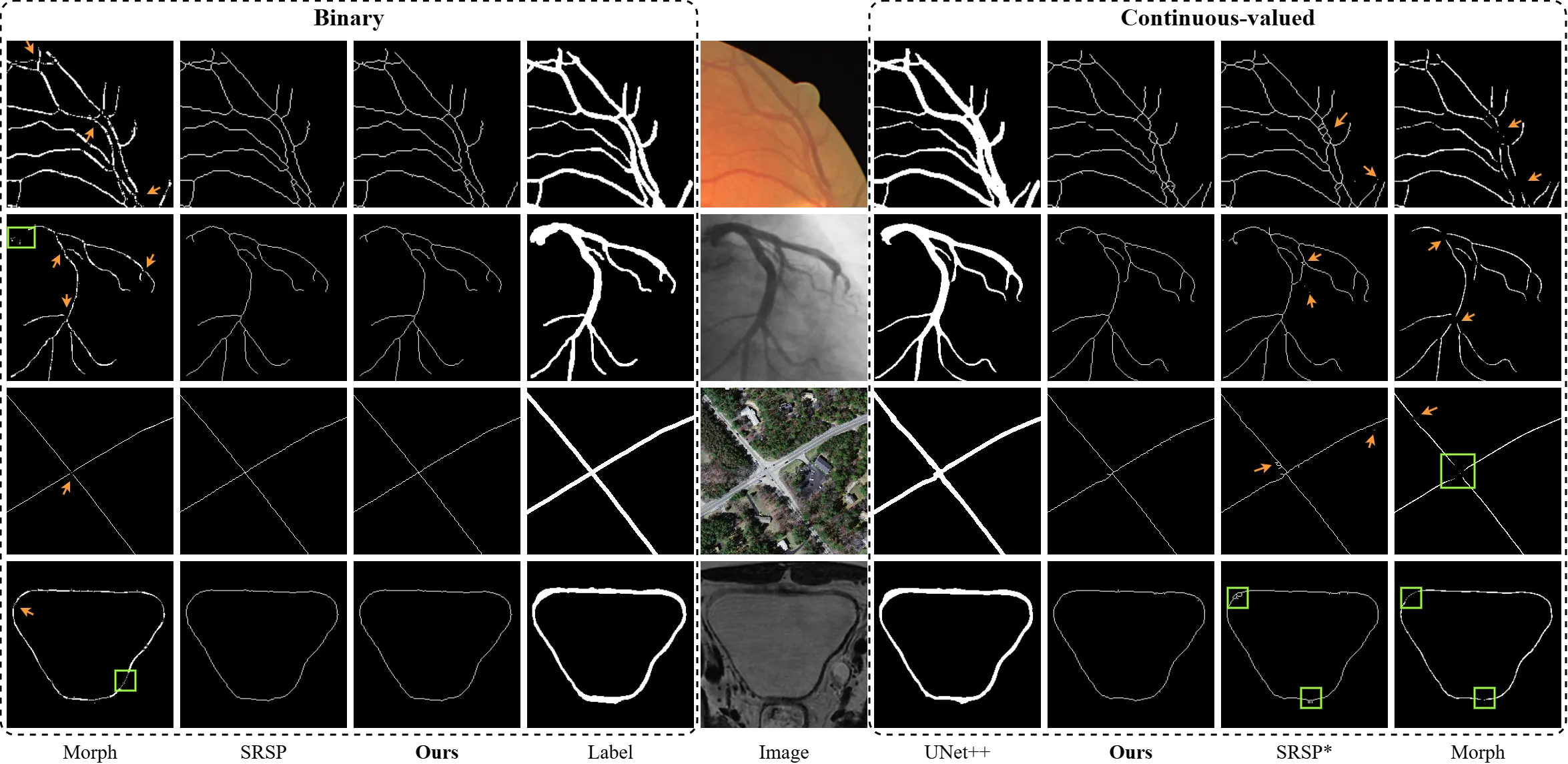
另一个不那么显眼但重要的点:**SRSP*(带 0.1 noise 的 SRSP)在连续值上 β₀ 跳到 2.21、χ_error 跳到 2.00**——说明为了让 SRSP 在深度学习训练中可用、必须引入 Gumbel-Softmax 噪声,但噪声本身就在破坏拓扑精度。CSP 完全没有这个问题。#csp2026
6.2 分割全面对比:Table II(重点 SAM2 子表)
Table II 在 4 数据集 × 4 backbone × 4 loss 上对比了 9 个指标。完整表格大几十行,我们只展示 SAM2 backbone 部分(这是 TCSP-SAM2 的目标设定,也是论文最关键的实验):
| 数据集 | Loss | Recall↑ | Dice↑ | IoU↑ | HD95↓ | ASSD↓ | clDice↑ | β₀↓ | β₁↓ | χ_err↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| DCA | Baseline | 83.00 | 81.28 | 68.59 | 9.52 | 1.99 | 88.02 | 5.24 | 0.79 | 5.03 |
| DCA | Morph | 82.97 | 81.50 | 68.90 | 11.07 | 2.07 | 87.96 | 5.76 | 0.79 | 5.56 |
| DCA | SRSP | 83.05 | 81.53 | 68.93 | 9.63 | 1.97 | 88.33 | 5.32 | 1.03 | 5.00 |
| DCA | Ours (CSP) | 83.15 | 81.55 | 68.96 | 9.56 | 1.96 | 88.40 | 5.00 | 1.00 | 4.71 |
| DRIVE | Baseline | 80.49 | 82.22 | 69.83 | 5.92 | 1.19 | 80.91 | 146.70 | 34.40 | 181.10 |
| DRIVE | Morph | 81.03 | 82.33 | 69.99 | 5.34 | 1.14 | 81.19 | 155.80 | 34.75 | 190.55 |
| DRIVE | SRSP | 81.96 | 82.30 | 69.94 | 4.68 | 1.08 | 82.01 | 140.15 | 33.90 | 174.05 |
| DRIVE | Ours (CSP) | 82.64 | 82.32 | 69.98 | 4.57 | 1.07 | 82.05 | 142.30 | 32.70 | 175.00 |
| MASS | Baseline | 72.01 | 76.51 | 62.96 | 52.01 | 8.15 | 86.26 | 7.02 | 5.05 | 10.93 |
| MASS | SRSP | 72.77 | 77.01 | 63.55 | 48.59 | 7.74 | 86.69 | 6.67 | 4.75 | 10.79 |
| MASS | Ours (CSP) | 76.77 | 77.06 | 63.33 | 45.92 | 7.65 | 87.54 | 7.86 | 4.08 | 10.55 |
| UBW | Baseline | 83.79 | 83.73 | 73.12 | 4.49 | 1.30 | 93.01 | 0.97 | 0.47 | 1.21 |
| UBW | SRSP | 85.53 | 84.43 | 74.17 | 3.57 | 1.04 | 93.39 | 0.60 | 0.38 | 0.86 |
| UBW | Ours (CSP) | 85.20 | 84.53 | 74.26 | 3.52 | 1.03 | 93.63 | 0.87 | 0.40 | 1.04 |
从 SAM2 backbone 子表可以读出几个关键故事:
- 最大单点提升:SAM2 + MASS + Ours: Recall 72.01 → 76.77(+4.76pp)。这是道路分割的"找到更多道路像素",配合 β₁ 误差从 5.05 降到 4.08(孔洞结构更对)。#csp2026
- clDice 稳定提升:SAM2 子表 4 个数据集上 CSP loss 全部优于 SRSP(MASS 87.54 vs 86.69, UBW 93.63 vs 93.39, DCA 88.40 vs 88.33, DRIVE 82.05 vs 82.01)。在所有 backbone 4 数据集的所有 16 个组合中,CSP 的 clDice 多数情况下也赢。
- 拓扑指标的反例:β₀ 上 SRSP 略胜的情况确实存在(UBW β₀ 0.60 vs Ours 0.87)。这个组合下 Ours 在 overlap/boundary/clDice 上更优,但 β₀ 拓扑保护反而不及 SRSP——说明 simple point 判据并不天然等于连通分量数保护。#csp2026
- DRIVE 上的小反例:DeeplabV3+ + DRIVE + Ours: β₀=196.35,差于 SRSP 的 173.10。论文主表(SAM2 部分)没出现这种反例,但在其他 backbone 上确实存在。#treasure_anti_pattern
DeeplabV3+ + DRIVE:Ours 拓扑指标反而更差
在非 SAM2 backbone 上,CSP loss 不一定赢。具体到 DeeplabV3+ + DRIVE,CSP 的 β₀=196.35 高于 SRSP 的 173.10。一个可能解释:DeepLabV3+ 的 decoder 容量小,topology feature $v$ 学得不够强,反而干扰了 segmentation feature $o$。SAM2 这种"decoder 双头化"更适合 CSP 路线。论文主表都用 SAM2 展示最佳结果,但读者复现时要注意这个 backbone 依赖。#csp2026 #treasure_anti_pattern
6.3 TCSP 变分 vs CSP Loss:Table III
Table III 把 SAM2 的两种"加 CSP"方式做了对比:训练期用 CSP loss(Ours in Table II)vs 训练期用 CSP loss + 推理期用 TCSP 变分 inference(TCSP-SAM2):
| 数据集 | 方法 | Recall↑ | Dice↑ | IoU↑ | HD95↓ | ASSD↓ | clDice↑ | β₀↓ | β₁↓ | χ_err↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| DCA | CSP Loss | 83.15 | 81.55 | 68.96 | 9.56 | 1.96 | 88.40 | 5.00 | 1.00 | 4.71 |
| DCA | TCSP-SAM2 | 84.85 | 81.61 | 69.06 | 8.56 | 1.88 | 88.83 | 0.74 | 4.53 | 4.32 |
| DRIVE | CSP Loss | 82.64 | 82.32 | 69.98 | 4.57 | 1.07 | 82.05 | 142.30 | 32.70 | 175.00 |
| DRIVE | TCSP-SAM2 | 83.63 | 82.39 | 70.08 | 4.42 | 1.06 | 82.67 | 123.55 | 31.65 | 155.20 |
| MASS | CSP Loss | 76.77 | 77.06 | 63.33 | 45.92 | 7.65 | 87.54 | 7.86 | 4.08 | 10.55 |
| MASS | TCSP-SAM2 | 73.47 | 77.50 | 64.13 | 43.94 | 7.16 | 87.38 | 6.49 | 4.96 | 10.37 |
| UBW | CSP Loss | 85.20 | 84.53 | 74.26 | 3.52 | 1.03 | 93.63 | 0.87 | 0.40 | 1.04 |
| UBW | TCSP-SAM2 | 85.47 | 84.80 | 74.69 | 3.50 | 1.01 | 93.76 | 0.46 | 0.27 | 0.70 |
三个关键观察:
- TCSP 在 DCA / DRIVE / UBW 全面优于 CSP Loss:Recall、Dice、HD95、ASSD、clDice、β₀、χ_error 全部更优。β₁ 的结果更混合:DRIVE 32.70→31.65(更优)、UBW 0.40→0.27(更优)、但 DCA 1.00→4.53(恶化)——说明 TCSP 的拓扑保守在 DCA 这种短血管密集场景上可能产生过度修正
- MASS 反例:TCSP-SAM2 + MASS 的 Recall 从 76.77 跌到 73.47(-3.3pp)。但其他指标(Dice、IoU、HD95、ASSD、β₀、χ_error)都更优——意味着 TCSP 让分割更"拓扑保守",但少找了一些稀疏道路像素#treasure_anti_pattern
- TCSP 在小数据集(DCA、UBW)提升最明显:这两个数据集的"漏掉一像素可能断一血管"风险最高,TCSP 闭式 inference 直接保住拓扑
flowchart LR
A["u (CSP loss)"] --> B["u* = argmin E(u,o,v) (TCSP)"]
B --> C["sigmoid((o + η·v·M(S(v)))/ε)"]
C --> D["最终输出"]
6.4 失败案例与局限
论文 V 节明确承认三个局限:
局限 1:2D 假设
整个 framework 验证在 2D 图像。3D 体数据需要新的连通性定义,cyclic gradient 在 3D 26-邻域里不能直接套用。#csp2026
局限 2:MASS 上的 Recall 下降
TCSP-SAM2 在 MASS 数据集上 Recall 下降 3.3pp。可能因为 MASS 的道路稀疏,TCSP 的拓扑保守反而压低了 recall。#csp2026 #treasure_anti_pattern
局限 3:缺乏 sensitivity analysis
λ=0.001、(α, σ, τ) = (16, 0.2, 0.5)、TCSP ε/η 初始值 = 1/4——这些超参在所有数据集上都是固定值,没有 ablation。复现时可能需要自己调。#csp2026
把 CSP 放回 simple point 谱系(1970s → 2026)的位置来看,它的真正贡献是把 simple point 从"二值判据 + STE 近似"推进到"连续值算子 + 变分 inference"。#csp2026 #cite5 #cite17 #cite35
7.1 CSP 在拓扑分割谱系中的位置
| 方法 | 年份 | 核心思想 | 拓扑保证 | 计算成本 | 与 CSP 的关系 |
|---|---|---|---|---|---|
| clDice #cldice2021 | 2021 | 形态学骨架 + Dice | 软约束 | 低 | CSP loss 的设计模板 |
| Persistent Topology #topoloss2019 | 2019 | 持续图匹配 | 强 | O(n³),极高 | 不同数学路线 |
| Euler Char #euler2025 | 2025 | 欧拉特征可微 | 弱(局部) | 中 | 互补的局部约束 |
| SRSP #cite35 | 2023 | 二值 simple point + STE | 强(有偏) | 中(4-6× 慢于 CSP) | CSP 的直接前身 |
| DMT #dmtloss2023 | 2023 | Morse 理论 | 强 | 高 | 不同数学路线 |
| Deep Closing #deepclose2024 | 2024 | 形态学闭运算 | 软 | 低 | 互补思路 |
| Width Topo #widthtopo2026 | 2026 | 宽度约束 | 强 | 中 | 同组前置工作 |
| CSP / TCSP(本文) | 2026 | 连续值 simple point + 变分 inference | 强(无偏) | 低(O(|Ω|)) | 本文 |
CSP 的相对优势:
- vs clDice:clDice 是软约束(鼓励但不强制),TCSP 是硬约束(变分 inference 强制)
- vs SRSP:两者都能保拓扑,但 SRSP 有 STE 偏置,CSP/TCSP 无偏
- vs Persistent Homology:PH 数学更严密但 O(n³) 不可承受,CSP O(|Ω|) 可工程化
- vs Width Topo:Width Topo 专注宽度约束(局部几何),CSP 专注 simple point 判定(全局拓扑),互补
7.2 代码-论文的 5 个差异点
复现这篇论文时,如果不看代码,几乎一定会踩坑。整理 code_repo/ 后发现的差异:
| 差异点 | 论文报告 | 代码实际 | 位置 | 修复方式 |
|---|---|---|---|---|
| α 参数 | 16 | 4(硬编码) | train_utils/skeletonize.py:193,201 | 手动改 alpha=4 → alpha=16 |
| CSPS num_iter(训练) | 未明说 | 5 | model/baseline/sam2.py:184 | 按需调整 |
| CSPS num_iter(推理) | 未明说 | 10 | predict_sp.py:62, skel_exact.py:49 | 注意 train/infer 不一致 |
| η 参数实现 | 可学习 scalar,初始 4 | MaxPool2d(15,1,7) 实现 | model/baseline/sam2.py | 理解 kernel size 映射 η=4 |
| CSP loss 输入 | 公式符号模糊 | 用 v 作为输入 | train_utils/Loss.py:71 | 注意是 v 而非 u* |
仓库缺失的关键件
GitHub 仓库 https://github.com/levnsio/CSP 极简:README 只有两个 Google Drive 链接,没有 train.py、没有 DCA/MASS 的 config、没有 evaluation 脚本、没有 requirements.txt、没有 LICENSE。所有"写代码"的工作需要自行补全。#csp2026 #treasure_repo_gap
7.3 三个值得带走的判断
读完 CSP 应该带走的 5 个判断
- 数学判断:cyclic gradient 的 $\ell_0$ 范数 = crossing number,是 simple point 判据在 8-连通下的代数重写。Theorem 1 把双判定压成单 $T_4$ 是从离散到可微的桥梁
- 架构判断:TCSP 把 simple point 约束从损失层提升到 inference 层。闭式解 $u^* = \sigma((o + \eta v \mathcal{M}(\mathcal{S}(v)))/\varepsilon)$ 让 topology feature 直接注入 classifier
- 实验判断:CSP 在 SAM2 backbone 上全面优于 SRSP(MASS 上 Recall +4.76pp 是单点最大提升);但在其他 backbone 上不是稳赢(DeeplabV3+ DRIVE β₀ 反例)
- 复现判断:代码与论文在 α、num_iter、η 实现上有 5 处不一致,复现时需要自己修正。仓库本身缺 train.py 和 config
- 谱系判断:CSP 是 simple point 谱系的地基性工作,取代了"二值+STE 近似"路线,4-6× 加速 + 无 STE 偏置是最直接的工程价值
对今天的研究者来说,CSP 最值得学习的不只是"怎么算 simple point",而是"如何把一个看似离散的数学判据,连续化后嵌入现代学习框架"——Theorem 1 + sigmoid + Gaussian + 变分 inference 的链条,是一个非常漂亮的范式。
核心论文
- Li, W., Wang, F., Duan, Y., Cui, L., Zhang, L. & Liu, J. (2026) "Continuous-tone Simple Points: An ℓ₀-Norm of Cyclic Gradient for Topology-Preserving Data-Driven Image Segmentation". arXiv:2604.28159. Code: github.com/levnsio/CSP.
- CSP 论文 Table I 数值,4 数据集 × {Binary, Continuous} × 4 方法,源
subagents/treasure.md§5 - CSP 论文代码-论文 α 不一致,
train_utils/skeletonize.py:193,201硬编码 alpha=4,论文报告 α=16,源subagents/treasure.md§1 - CSP 论文 λ=0.001 没有 ablation,
subagents/treasure.md§1 - CSP 论文 η=4 在代码里由 MaxPool2d(15,1,7) 实现,
subagents/treasure.md§1 - Table II/III 反例:DeeplabV3+ DRIVE β₀=196.35 vs SRSP 173.10;TCSP-SAM2 MASS Recall 76.77→73.47,
subagents/treasure.md§6-7 - GitHub 仓库
github.com/levnsio/CSP极简,没有 train.py、DCA/MASS config、requirements.txt、LICENSE,subagents/treasure.md§9
数字拓扑与 simple point 经典
- Bertrand, G. (1994) "Simple points, topological numbers and geodesic neighborhoods in cubic grids". Pattern Recognition Letters 17(2).
- Han, X., Xu, C. & Prince, J. L. (2003) "A Topology Preserving Level Set Method for Geometric Deformable Models". IEEE TPAMI 25(6).
- Kong, T. Y. & Rosenfeld, A. (1989) "Digital topology: Introduction and survey". CVGIP 48(3).
- Kowalski, P. (2010) "On the connectivity of digital images". Pattern Recognition Letters.
- Zhang, T. Y. & Suen, C. Y. (1984) "A fast parallel algorithm for thinning digital patterns". Commun. ACM 27(3).
深度学习中的拓扑约束
- Ronneberger, O., Fischer, P. & Brox, T. (2015) "U-Net: Convolutional Networks for Biomedical Image Segmentation". MICCAI 2015 / arXiv:1505.04597.
- Shit, S. et al. (2021) "clDice - a Novel Topology-Preserving Loss Function for Tubular Structure Segmentation". CVPR 2021.
- Menten, M. J. et al. (2023) "A skeletonization algorithm for gradient-based optimization". ICCV 2023.
- Hu, X. et al. (2019) "Topology-Preserving Deep Image Segmentation". NeurIPS 2019.
- Hu, X. et al. (2021) "Topology-Preserving Deep Image Segmentation via MCMC and Discrete Morse Theory". ICLR 2021.
- Gupta, S. et al. (2023) "Learning Topological Interactions for Multi-Class Medical Image Segmentation". NeurIPS 2023.
- Wu, J. et al. (2024) "Deep Closing: A Topological Morphological Closing Operation for Deep Learning". IEEE TMI 2024.
- Li, W., Tai, X.-C. & Liu, J. (2026) "Topology-Guaranteed Image Segmentation with Width Constraints". arXiv:2601.11409.
- Li, W. et al. (2025) "Fast Euler Characteristic-Based Segmentation for Tubular Structures". IEEE TMI 2025.
- Qi, Y. et al. (2023) "Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation". ICCV 2023.
- Ashburner, J. (2007) "A fast diffeomorphic image registration algorithm". NeuroImage 38(1).
基座网络与训练方法
- Ravi, N. et al. (2024) "SAM 2: Segment Anything in Images and Videos". arXiv:2408.00714.
- Loshchilov, I. & Hutter, F. (2019) "Decoupled Weight Decay Regularization". ICLR 2019.
数据集
- Staal, J. et al. (2004) "Ridge-based vessel segmentation in color images of the retina". IEEE TMI 23(4).
- Frauel, Y. et al. (2020) "Digital Coronary Angiography dataset". Kaggle / UMAET1-León.
- Mnih, V. (2013) "Machine Learning for Aerial Image Labeling". PhD thesis, U. Toronto.
- Luo, Z. et al. (2019) "Urinary Bladder Wall Segmentation at ISICDM 2019". ISICDM 2019 Challenge.