SentiAvatar
如果只看近几年的 talking head 论文,数字人似乎已经离产品很近:给一张人脸和一段语音,模型能生成自然的口型、表情和头动。但 SentiAvatar 这篇论文提醒我们,会开口说话和像人在互动不是同一个目标。真实交流里,人不仅用词语传达信息,还会点头、耸肩、摊手、后退、前倾、扬眉、迟疑地笑一下。一个数字人如果只对齐了 lip-sync,却身体僵硬、手势泛化、表情和语义脱节,用户很快会感到“它只是视频播放器”,而不是一个可交互角色。#Jin-et-al.-2026
SentiAvatar 的目标正是在这里:构建一个可实时对话的 3D 数字人框架,并用虚拟角色 SuSu 展示系统效果。论文没有把问题简化成“音频驱动手势”,也没有只做“文本到动作”。它认为交互式数字人有三个同时成立的约束:第一,系统需要高质量多模态数据,包含对话文本、语音、全身动作、手部动作和面部表情;第二,动作必须和句子语义匹配,比如“我有点无奈”不能只生成随机摆手;第三,动作还要和语音韵律在帧级别对齐,比如重音、停顿、语速变化都应反映在动作节奏里。#Jin-et-al.-2026
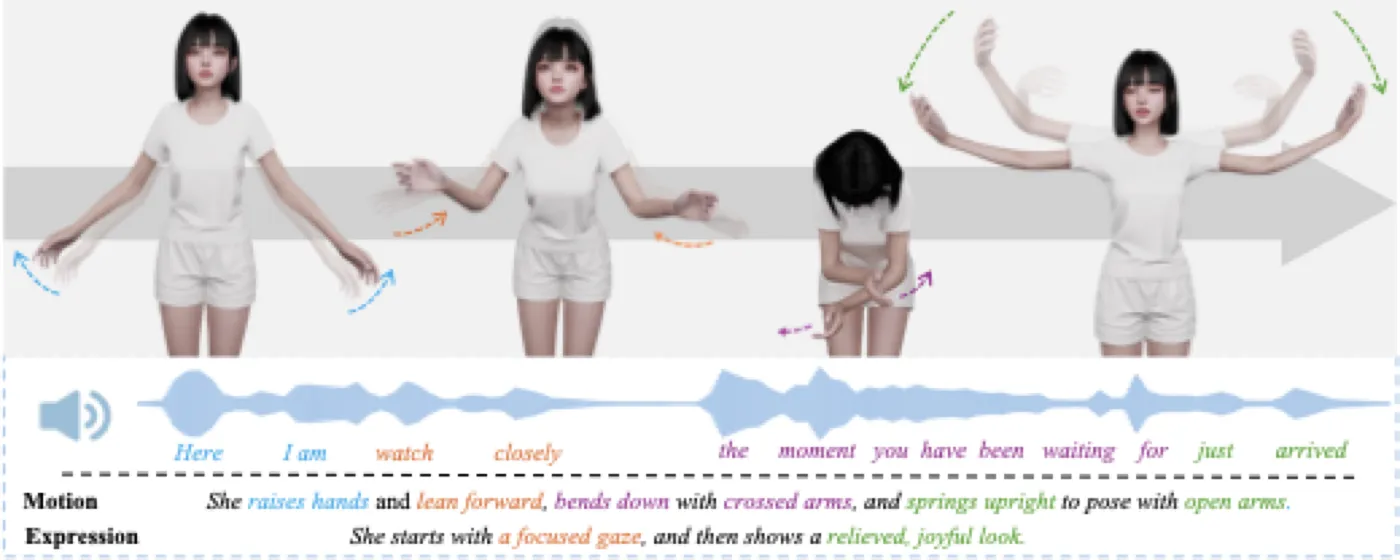
这个拆分非常重要。文本或动作标签擅长描述要做什么,例如“轻轻挥手”“摊开双手表示疑惑”;语音特征擅长描述什么时候动、动多快、哪里停顿。如果只用文本,动作可以对但节奏会飘;如果只用音频,节奏可能对但动作语义常常泛化。SentiAvatar 用 LLM Motion Planner 负责稀疏关键帧的语义规划,再用 Audio-aware Infill Transformer 根据 HuBERT 帧级特征补齐中间帧,让语义与韵律各司其职。
已有路线的错位
现有工作大致分成两类。第一类是 text-to-motion:输入动作描述,输出人体动作序列。这类方法在 HumanML3D、Motion-X 等数据集上发展很快,VQ-VAE、扩散模型、masked modeling 和 Motion LLM 都能生成丰富动作,但它们通常不建模 speech audio,因此很难知道动作应当落在语音的哪个重音或停顿上。第二类是 co-speech gesture:输入语音,输出同步手势或全身动作。这类方法能捕捉节奏,却容易生成“看起来在动但不知道为什么这么动”的泛化动作。#Guo-et-al.-2022 #Guo-et-al.-2024 #Liu-et-al.-2024
| 路线 | 代表能力 | 关键缺口 | SentiAvatar 的回应 |
|---|---|---|---|
| Text-to-motion | 按动作文本生成完整人体运动 | 缺少语音韵律,动作节奏与说话不一定对齐 | 引入 HuBERT audio tokens 与帧级 audio features |
| Audio-driven gesture | 动作节奏跟随语音 | 语义动作弱,常生成通用摆手或身体晃动 | 用 LLM planner 读取动作标签并规划关键帧 |
| 对话角色扮演数据 | 有多轮角色文本 | 通常缺少动捕、表情和音频 | 构建 SuSuInterActs,统一文本、音频、身体和表情 |
这篇论文真正定义的问题
论文中的任务不是从一句话生成一段孤立动作,而是给一个单一角色 SuSu 构建可持续交互的动作表达系统。输入包括当前语音、动作或表情标签、对话语境中的角色设定;输出则包括全身 6D joint rotation、手部动作以及 ARKit blendshape 面部表达。系统还要支持多轮 streaming:上一轮末尾的动作不能和下一轮开头突然断掉。
两个时间尺度
Sentence-level semantic alignment 指句子或动作标签层面的语义匹配:模型要知道当前应该点头、耸肩还是摊手。Frame-level prosody alignment 指帧级语音节奏对齐:动作速度、停顿、爆发点要和 speech onset、重音、语速变化一致。SentiAvatar 的 plan-then-infill 结构正是为了把这两个尺度分开处理。
这样看,SentiAvatar 最有价值的地方不是单个指标,而是问题建模方式。它把数字人从“音频驱动动画”推向“角色一致的多模态行为生成”:数据要围绕一个明确 persona 采集,动作要带语义标签,模型要有 motion foundation prior,还要能在多轮交互中持续生成。
SentiAvatar 的完整模型可以从三条线理解:第一条是表示线,把连续人体动作、面部表情和音频变成离散或连续 token;第二条是身体动作生成线,先由 LLM 规划稀疏 keyframe motion tokens,再由 Infill Transformer 补齐中间帧;第三条是面部生成线,直接从 HuBERT 特征生成 face tokens,因为面部动作和语音音素、重音、语调耦合更紧。#Jin-et-al.-2026
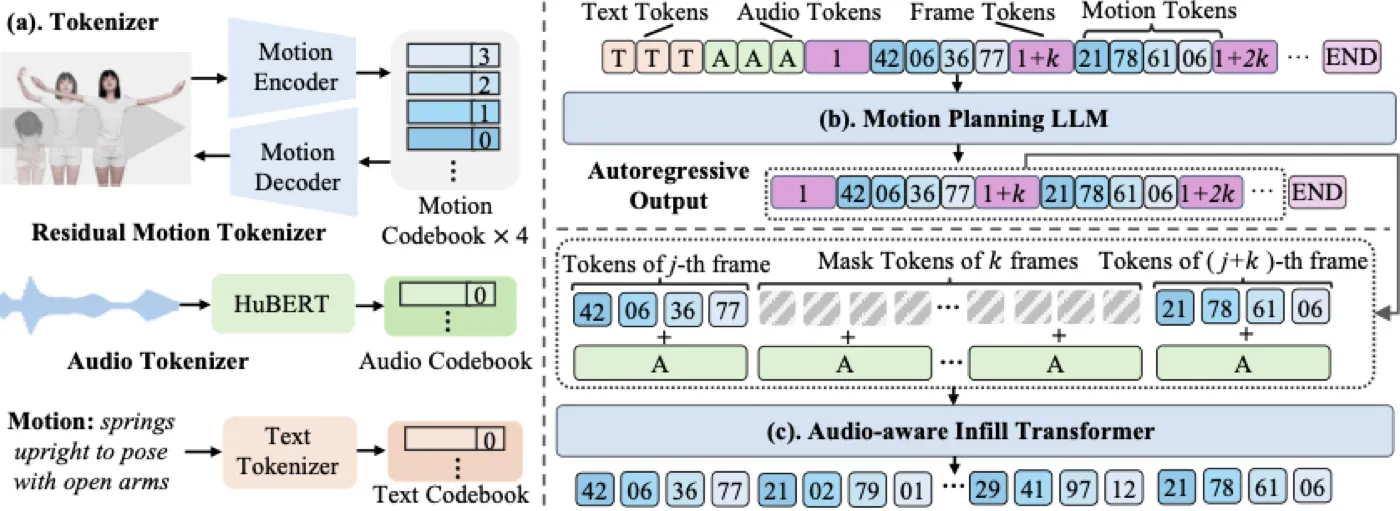
flowchart TD A["输入语音"] --> B["HuBERT feature"] B --> C["K-means sparse audio tokens"] B --> D["dense 768-dim audio features"] E["动作 / 表情标签"] --> F["LLM Motion Planner"] C --> F F --> G["稀疏 body keyframe tokens"] G --> H["Audio-aware Body Infill Transformer"] D --> H H --> I["dense body motion tokens"] I --> J["Motion R-VQVAE Decoder"] J --> K["63-joint full-body motion"] D --> L["Face Infill Transformer"] L --> M["Face R-VQVAE Decoder"] M --> N["51-dim ARKit blendshapes"] K --> O["3D digital human animation"] N --> O
Residual Motion Tokenizer:先把连续运动离散化
身体动作原始表示是连续的 6D rotation。直接让 LLM 输出连续高维时间序列并不自然,因此论文采用 Residual VQ-VAE,把连续 motion 编码成离散 token。Motion encoder 会在时间上做 2 倍下采样,4 层 residual quantization 每层 codebook size 为 512,所以每个时间步对应 4 个 residual codes。为了放进统一 vocabulary,论文给不同层 code 加偏移:
Residual code 的统一编号
这里的 \(r^{k}\) 是第 \(k\) 层 residual quantizer 的 code id。加上偏移后,四层 code 合在一个大小为 \(512\times4=2048\) 的 motion vocabulary 中。
这个设计的直觉类似“粗到细”的动作描述:第一层 code 负责主体动作轮廓,后续 residual code 补充细节。R-VQVAE decoder 最终把 token 还原成连续的 63-joint motion。音频也有两种表示:K-means 量化的 sparse audio tokens 给 LLM 使用,连续的 \(768\)-dim HuBERT features 给 infill 模型使用。
LLM Motion Planner:让大模型只做稀疏语义规划
LLM planner 的职责不是逐帧生成,而是每隔 \(t\) 帧预测一个关键帧 motion token group。给定 motion label \(\mathbf{T}\) 和 sparse audio tokens \(\{a_1,a_{1+t},a_{1+2t},\ldots\}\),模型输出稀疏 keyframes:
Planner 的输入输出
其中 \([S_t]\) 表示 keyframe 间隔,\(\mathbf{r}_i=(r_i^1,r_i^2,r_i^3,r_i^4)\) 是一个时间步的四层 residual token group。默认 \(t=4\),这是消融中语义、质量和同步的最佳平衡点。
为什么不让 LLM 每帧都生成?因为逐帧 token 序列太长,会把语言模型拖进低层动力学细节,反而削弱语义规划能力。SentiAvatar 的做法更像导演分镜:LLM 只决定关键动作节点,后面的 infill 模型负责让动作在两个关键节点之间自然过渡。
Audio-aware Infill Transformer:用语音把空白帧补成节奏
Planner 给出的是稀疏动作骨架,但真正让动作自然的是中间帧。Infill Transformer 在一个 \(t+1\) 帧滑动窗口里看到两端 keyframes,中间 \(t-1\) 帧被 mask,同时输入这一段的 dense HuBERT features:
Infill window
其中 \(\mathbf{h}\in\mathbb{R}^{(t+1)\times768}\) 是帧级 HuBERT 特征。边界 keyframes 锚定动作语义,中间的 speech features 决定加速、停顿和韵律细节。
这个 Transformer Encoder 有 8 层、16 heads、hidden dimension 512,总参数量约 38.5M。音频特征先经过两层 MLP,再与 token embeddings 做 element-wise addition。推理时它不是一次性填完,而是 6 步 iterative refinement:每一步接受置信度最高的预测,剩下 mask 继续 refine。面部路径共享类似思路,但不经过 LLM planner,而是直接由 Face Infill Transformer 从 HuBERT features 生成 face tokens,再由 Face R-VQVAE 解码成 51 维 ARKit blendshape。
这类系统型论文只讲模型结构是不够的。SentiAvatar 的训练流水线分成两条主线:一条是构造 SuSuInterActs,让模型知道 SuSu 这个角色在对话里如何说、如何动、如何表达;另一条是预训练 Motion Foundation Model,让模型先拥有比对话数据更宽的动作先验,再针对 SuSu 做 SFT。#Jin-et-al.-2026
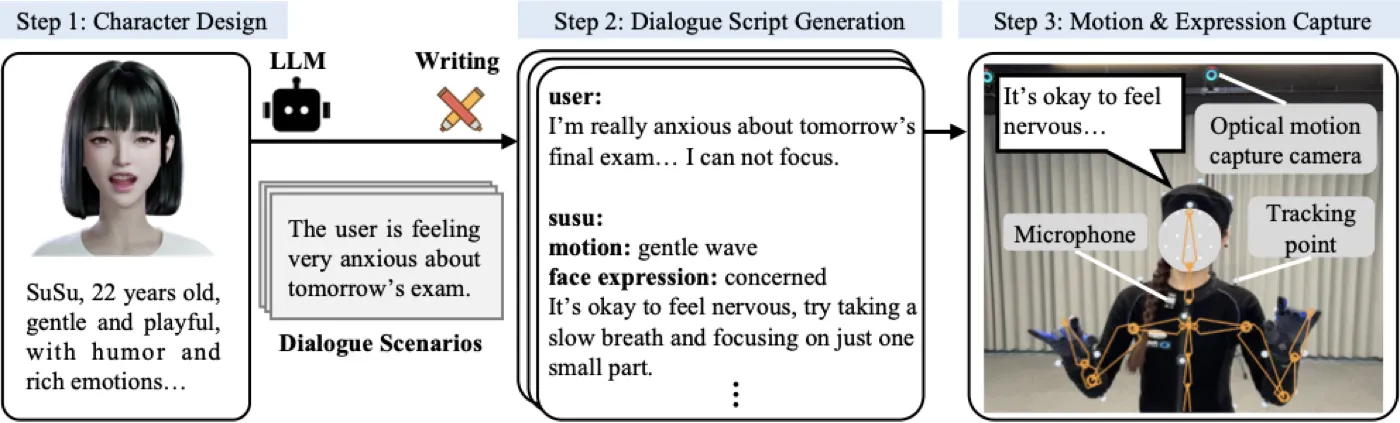
flowchart TD A["SuSu 角色设定"] --> B["对话场景设计"] B --> C["LLM 生成多轮脚本"] C --> D["动作 / 表情标签人工审核"] D --> E["专业演员表演"] E --> F["光学动捕:身体 + 手部"] E --> G["iPhone ARKit:51-dim 表情"] E --> H["同步语音录制"] F --> I["retarget + 20 FPS 对齐"] G --> I H --> I I --> J["SuSuInterActs 21K clips / 36.9h"] K["EmbodyAI / SnapMoGen / Motion-X / Hunyuan distill"] --> L["200,544 seqs / 676.4h"] L --> M["Motion Foundation Model pre-training"] J --> N["R-VQVAE + Infill training + SFT"] M --> N N --> O["SentiAvatar"]
数据阶段:把 persona 固定下来
SuSuInterActs 是一个围绕单一角色的中文多模态对话数据集。它包含 21,133 个 clips、36.9 小时,总计 2,656,484 帧;平均每条样本 6.3 秒、18.7 个中文字符;14,278 条样本有非默认 body action,9,412 条有非默认 expression,12,367 条带 facial data。采集时,专业演员先学习 SuSu 的角色设定和脚本,再进行表演;身体与手部由 optical motion capture 记录,面部由 iPhone ARKit 捕获为 51 维 blendshape,音频同步录制,最后统一 retarget 到 SuSu skeleton 并对齐到 20 FPS。#Jin-et-al.-2026
| 数据项 | 论文披露 | 含义 |
|---|---|---|
| 总样本 | 21,133 clips | 单角色、多轮对话动作片段 |
| 总时长 | 36.9 hours | 面向角色一致性,而非泛化到所有角色 |
| 帧率 | 20 FPS | 动作、音频、表情统一时间基准 |
| 身体表示 | 63 joints, 6D rotation | 覆盖身体与双手动作 |
| 面部表示 | 51-dim ARKit blendshape | 表达眉眼、嘴型和表情变化 |
预训练阶段:先学习更宽的动作世界
只用 37 小时对话数据训练,模型容易困在 SuSu 的聊天动作里。论文因此预训练 Motion Foundation Model:从 EmbodyAI、SnapMoGen、Motion-X 和 Hunyuan distilled motions 聚合 200,544 条 motion sequences,共 676.4 小时。所有动作先 retarget 到统一 skeleton,再由 Motion R-VQVAE tokenized。模型从 Qwen-0.5B 初始化,并向 vocabulary 里加入 motion tokens 与 audio tokens。
Motion Foundation Model 的自回归目标
这里 \(\mathbf{T}\) 是中文动作描述,\(\mathbf{r}_{1:N}\) 是 motion token groups。它让 Qwen-0.5B 先学会“动作语言”,再被微调成 SuSu 的 motion planner。
训练配置:论文披露了什么,没披露什么
| 项目 | 配置 | 说明 |
|---|---|---|
| 训练硬件 | 8 × NVIDIA A100 GPUs | 论文明确披露 |
| R-VQVAE | batch size 128, 100 epochs | motion 与 face R-VQVAE 分别训练 |
| Motion Foundation Model | 10 epochs, per-GPU batch size 128 | 基于 200K sequences 预训练 |
| SFT | 10 epochs, same batch size configuration | 在 SuSuInterActs 上全参数微调 |
| Infill Transformers | batch size 1024, 100 epochs | body 和 face infill 均训练 |
| 优化器 | AdamW | 论文明确披露 |
| 学习率 | \(1\times10^{-4}\) | 配合 cosine annealing schedule |
| CPU / 内存 | 未披露 | 论文与 README 未给出训练机器 CPU/RAM |
| 训练总耗时 | 未披露 | 不能据 GPU 数量臆测 wall-clock time |
| checkpoint 选择 | 未披露 | 论文未说明验证策略或 best checkpoint 标准 |
推理阶段的输入可以理解为一段语音和一个动作标签,输出是可在 3D 引擎或动画系统中使用的 body motion 与 face blendshapes。这里要先区分清楚:SuSu 的外观不是由本文模型逐帧生成的图片或视频;本文模型生成的是驱动已有 3D avatar 的动画参数,包括身体 joint rotations、手势 motion tokens 和面部 blendshapes。开源仓库 README 给出了更工程化的形态:先下载 checkpoints,启动 vLLM service 承载 LLM planner,再运行 batch 或 single-case inference;输出包含 BVH、JSON 与 WAV。#SentiAvatar-GitHub
代码仓库对应关系
仓库中的 motion_generation/single_case_infer.py 是单条音频推理入口;motion_generation/pipeline_infer.py 承担 LLM planner 与 Mask Transformer 插帧;motion_generation/reconstruct_from_tokens.py 负责把 dense motion tokens 解码并重建为可视化动画;scripts/start_vllm_server.sh 启动 vllm_server.py,默认监听 8095 端口;scripts/run_test.sh 则把 batch evaluation 串成两步:先 pipeline 推理生成 pipeline_batch_results.json,再 RVQVAE 重建到 output/reconstructed。
sequenceDiagram participant User as User / Dialogue System participant Audio as HuBERT + K-means participant LLM as vLLM Motion Planner participant Infill as Body & Face Infill participant Decode as R-VQVAE Decoders participant Engine as 3D Engine User->>Audio: speech audio + action_text Audio->>LLM: sparse audio tokens User->>LLM: action / expression label LLM->>Infill: sparse body keyframe tokens Audio->>Infill: dense HuBERT features Infill->>Decode: dense body tokens + face tokens Decode->>Engine: BVH / JSON motion + blendshapes Engine-->>User: expressive interactive avatar
离线 / 单段推理
单段推理时,系统先从 audio waveform 提取 HuBERT features。K-means quantizer 产生 sparse audio tokens,送入 LLM planner;连续 HuBERT features 则以帧级形式送入 body 与 face Infill Transformers。身体路径先生成 sparse keyframe tokens,再经过 6 步 iterative refinement 的 infill,最后由 Motion R-VQVAE decoder 解码为连续 joint rotations。面部路径跳过 LLM planner,直接由 Face Infill Transformer 和 Face R-VQVAE 生成 ARKit blendshape。
| 推理组件 | 输入 | 输出 | 作用 |
|---|---|---|---|
| HuBERT | 语音 waveform | 50 FPS features,下采样到 20 FPS | 提供语音内容与韵律特征 |
| K-means audio tokenizer | HuBERT features | sparse audio tokens | 给 LLM planner 提供粗粒度音频上下文 |
| LLM Motion Planner | 动作标签 + sparse audio tokens | keyframe body tokens | 决定语义动作骨架 |
| Body Infill Transformer | 边界 keyframes + dense audio | dense body tokens | 补齐帧级运动并对齐 prosody |
| Face Infill Transformer | dense audio | face tokens | 生成嘴型、眉眼和表情变化 |
| R-VQVAE Decoders | body / face tokens | joint rotations / blendshapes | 还原连续动画参数 |
Streaming 的关键:跨 utterance 不断裂
多轮对话的难点不是每段都能生成,而是段与段之间不能跳。SentiAvatar 使用 continuation mode:LLM 输入里会带上上一轮末尾的两个 audio-motion keyframe pairs,再拼接当前 motion label 与新的 audio tokens。训练时,如果没有真实连续 utterances,论文就把单条 utterance 切成 pseudo-history 和 target 来模拟这种上下文。到了 Infill Transformer,上一轮最后一个 keyframe 会自然成为新窗口的起始边界。#Jin-et-al.-2026
Continuation mode
前缀保存上一轮末尾的音频与运动 token,使当前轮不是从静止状态重启,而是从已有动作状态继续生成。
论文报告端到端延迟约为 0.3 秒生成约 6 秒输出,并宣称支持 unlimited multi-turn streaming。这里需要谨慎解读:论文正文没有完整披露该延迟测量的 CPU、GPU、batch、vLLM serving 参数和并发设置;因此可以把它视为系统效率证据,但不能直接换算成任何部署环境下的 SLA。开源 README 披露的 checkpoint 规模也提示了工程成本:LLM planner 约 1.1GB,mask transformer 约 276MB,RVQVAE 约 754MB,Chinese HuBERT 约 361MB。#SentiAvatar-GitHub
实验配置表
SentiAvatar 的实验覆盖自建 SuSuInterActs 和公开 BEATv2。SuSuInterActs 用于验证角色对话动作生成;BEATv2 用于检查跨数据集、跨语言的 co-speech gesture 泛化。论文中的 SuSuInterActs split 是 20,982 train、710 validation、542 test;GitHub README 对开源数据 split 写作 Train 19K / Val 635 / Test 1479,二者不完全一致,写复现脚本时应以仓库实际文件为准。#Jin-et-al.-2026 #SentiAvatar-GitHub
| 项目 | 配置 | 是否披露 |
|---|---|---|
| SuSuInterActs split | 20,982 / 710 / 542 | 论文披露 |
| BEATv2 | retrain full pipeline and evaluate on test split | 论文披露 |
| 训练 GPU | 8 × A100 | 论文披露 |
| 优化器 / LR | AdamW, \(1\times10^{-4}\), cosine annealing | 论文披露 |
| R-VQVAE 训练 | batch 128, 100 epochs | 论文披露 |
| Foundation Model 训练 | 10 epochs, per-GPU batch 128 | 论文披露 |
| Infill Transformer 训练 | batch 1024, 100 epochs | 论文披露 |
| 训练时间 | 未披露 | 需显式标注 |
| 推理硬件 | 未完整披露 | 0.3s / 6s 输出缺少硬件上下文 |
| CPU / RAM | 未披露 | 论文与 README 未说明 |
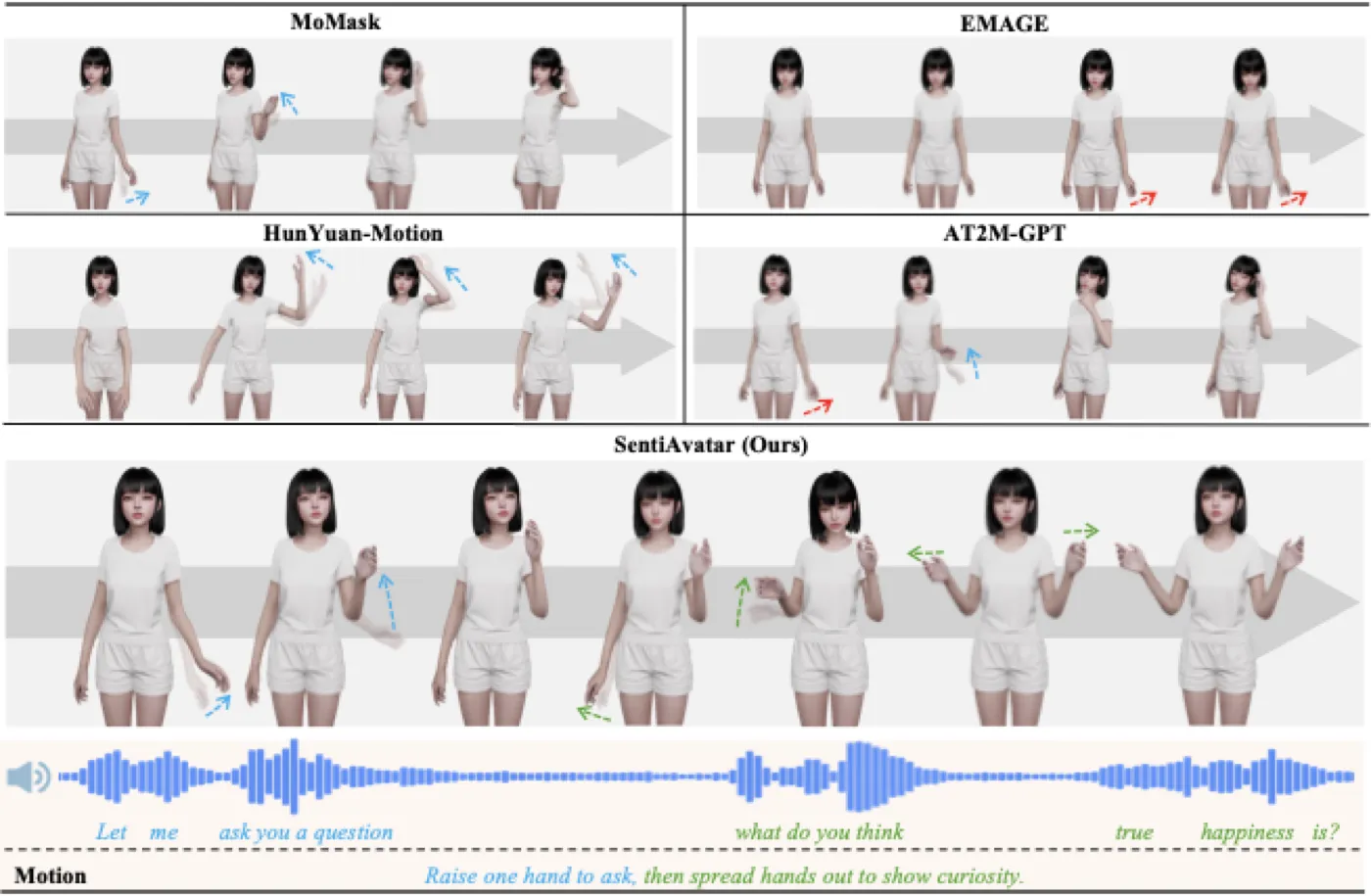
主实验:SentiAvatar 同时赢在语义和同步
| Method | Condition | R@1 ↑ | FID ↓ | ESD ↓ | Diversity ↑ |
|---|---|---|---|---|---|
| Real Motion | — | 62.20 | 0.000 | 0.308 | 22.61 |
| EMAGE | Audio | 5.00 | 441.6 | 0.606 | 12.92 |
| MoMask | Text | 34.55 | 36.25 | 0.471 | 22.03 |
| AT2M-GPT | Audio + Text | 27.52 | 18.491 | 0.503 | 22.36 |
| SentiAvatar | Audio + Text | 43.64 | 8.912 | 0.456 | 22.41 |
这张表最值得看的不是单一最好值,而是三类 baseline 的失败方式。EMAGE 只看音频,ESD 比 text-only 方法更合理,但 R@1 只有 5.00,说明动作语义基本抓不住。MoMask 只看文本,R@1 达到 34.55,但 ESD 仍不如 SentiAvatar,说明语义动作不等于语音节奏。AT2M-GPT 同时看音频和文本,但 token-by-token autoregressive 结构没有显式拆分 plan 与 infill,R@1 只有 27.52。SentiAvatar 的优势来自结构性分工,而不是简单多加一种输入模态。
BEATv2 与用户研究
| Method | Condition | FGD ↓ | BC ↑ | Diversity ↑ |
|---|---|---|---|---|
| EMAGE | Audio + Text | 5.512 | 7.724 | 13.06 |
| SynTalker | Audio + Text | 6.413 | 7.971 | 12.72 |
| Language-of-Motion | Audio | 5.301 | 7.780 | 15.17 |
| SentiAvatar | Audio + Text | 4.941 | 8.078 | 10.56 |
在 BEATv2 上,SentiAvatar 的 FGD 为 4.941、BC 为 8.078,分别超过表中 prior best。用户研究中,10 名参与者按 1–5 Likert scale 评价 semantic、prosody 和 overall,SentiAvatar 分别得到 2.97、3.16、2.99,均高于 MoMask、EMAGE 和 AT2M-GPT。但也要注意,绝对分数并不高,说明系统虽然领先 baseline,但距离真实人类表演仍有明显空间。
消融:为什么必须同时有 planner 和 infill
| Variant | R@1 ↑ | FID ↓ | ESD ↓ | 解读 |
|---|---|---|---|---|
| w/o Pre-training | 42.56 | 8.988 | 0.452 | 预训练增益不大但稳定提升语义与质量 |
| w/o Infill Transformer | 27.52 | 18.491 | 0.503 | 只有稀疏关键帧会损失流畅性和节奏 |
| w/o LLM Planner | 28.06 | 27.567 | 0.421 | 局部同步可能更好,但语义和质量明显崩 |
| Full pipeline | 43.64 | 8.912 | 0.456 | 整体平衡最佳 |
keyframe interval 的消融也印证了 plan-then-infill 的取舍:token-by-token 的 R@1 只有 27.52;\(t=2\) 时序列仍太密,R@1 为 34.21;\(t=8\) 给 infill 更多自由,ESD 最好为 0.439,但 R@1 降到 36.44;默认 \(t=4\) 在 R@1 43.64、FID 8.912、ESD 0.456 上达到最佳平衡。
SentiAvatar 的贡献可以概括为三层。第一层是数据:SuSuInterActs 把角色设定、多轮对话、动作标签、语音、全身动捕、手部动作和面部表情合到一个 corpus 里。第二层是方法:plan-then-infill 把语义规划和韵律补帧拆开,让 LLM 做高层动作规划,让小型 Transformer 做帧级同步。第三层是工程:代码、数据、模型权重和推理脚本开源,使它比很多只展示 demo 的数字人论文更接近可复现系统。#SentiAvatar-GitHub
| 方法 / 系统 | 核心对象 | 强项 | 局限 |
|---|---|---|---|
| Ditto | 单图 talking head 视频 | motion-space diffusion,实时可控头像生成 | 主要聚焦头脸,不覆盖完整 3D 全身交互 |
| EMAGE | co-speech holistic gesture | 音频驱动的身体与表情同步 | 动作语义不如显式 planner 强 |
| MoMask / T2M-GPT | text-to-motion | 动作语义表达强 | 不建模语音韵律 |
| SentiAvatar | 3D 交互数字人 | 语义动作 + 语音节奏 + 多轮 streaming | 单角色数据、依赖显式动作标签、训练成本较高 |
这篇论文的边界
第一,SuSuInterActs 是单角色数据,角色一致性强,但迁移到新角色可能需要新数据或适配。第二,系统依赖 action/expression tags,真实产品里还需要上游 dialogue-to-behavior planner。第三,论文没有披露训练 wall-clock time、CPU/RAM 和完整推理硬件,因此复现成本仍需实际测量。
对工程实践来说,SentiAvatar 给出的启发非常具体:不要试图让一个模型同时负责“理解对话、选择动作、跟随节奏、输出动画参数”。更稳妥的系统设计是分层:LLM 或行为策略模块生成高层 action intent;motion planner 把 intent 转成稀疏 motion keyframes;infill / smoothing 模块处理帧级 prosody 与连续性;最后由 3D engine 或 renderer 执行。这样每层都可以单独替换、评估和优化。
如果把数字人技术看成从“对口型”走向“可交互角色”的连续谱,SentiAvatar 已经越过了单纯 talking head 的边界。它还不是完整产品:上游意图规划、长时记忆、个性化迁移、UE/Unity 中的表情渲染和低端设备部署仍然需要大量工程。但它确实清楚地指出,下一阶段数字人的核心不只是更清晰的视频,而是更一致、更有语义、更懂节奏的身体表达。
参考来源
- Jin, Chuhao et al. (2026). SentiAvatar: Towards Expressive and Interactive Digital Humans. arXiv:2604.02908
- SentiAvatar project. Code, dataset and checkpoints. GitHub: SentiAvatar/SentiAvatar
- Guo, Chuan et al. (2022). Generating Diverse and Natural 3D Human Motions from Text. CVPR 2022
- Guo, Chuan et al. (2024). MoMask: Generative Masked Modeling of 3D Human Motions. arXiv
- Liu, Haiyang et al. (2024). EMAGE: Towards Unified Holistic Co-Speech Gesture Generation. arXiv