Hallo
Hallo 要解决的是 audio-driven portrait image animation:给定一张静态肖像和一段语音,生成与语音同步、视觉高保真且时间一致的说话肖像视频。#Xu-et-al.-2024-Hallo
论文把任务困难拆成两个层面:第一,音频不仅要控制嘴唇,还要协调表情和头姿;第二,生成结果不能只是一帧帧好看,而要在视频时间轴上保持连贯。#Xu-et-al.-2024-Hallo 这两个要求放在一起,就会让传统中间表示路线很尴尬:3DMM、landmark 或隐式运动系数更容易控制,却会受限于表示精度;端到端扩散模型更有画质潜力,却容易把音频—视觉对齐学得过于粗糙。#Xu-et-al.-2024-Hallo
这种拆法很符合直觉。同一句音频里,音素主要决定嘴唇开合,语气和节奏会影响表情,停顿和强调又可能带来头部姿态变化。如果把整张脸都放进一个统一 audio-visual cross-attention,模型会得到一个“全脸平均”的驱动信号;Hallo 则让不同区域各自接收音频条件,再用自适应融合把它们合回 diffusion denoiser。#Xu-et-al.-2024-Hallo
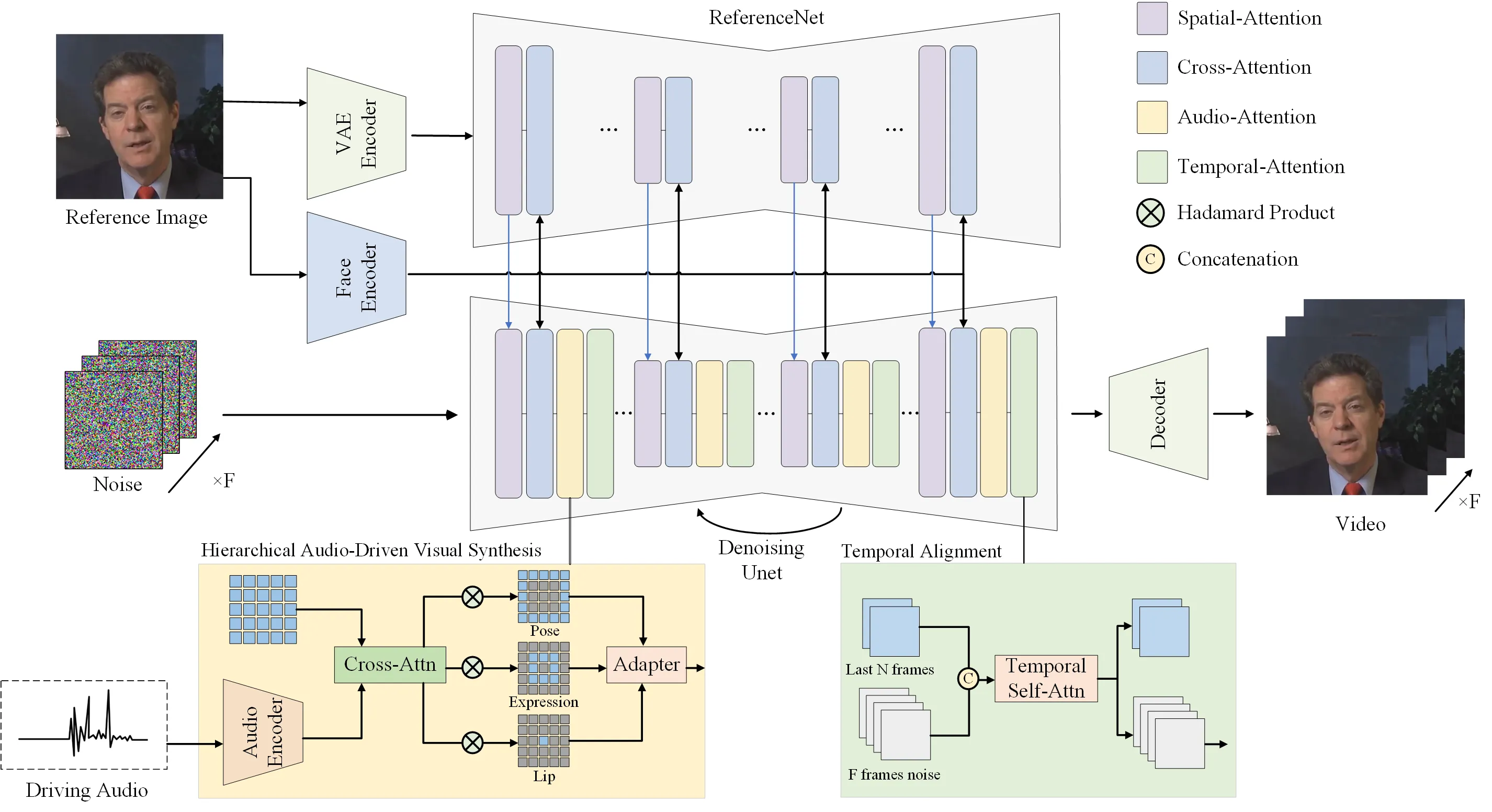
从 Stable Diffusion 改成音频驱动视频生成
Hallo 基于 Stable Diffusion 1.5 的 latent diffusion 体系:图像先由 VAE 编码到 latent space,UNet-based denoising model 在扩散时间步上预测噪声,再由 VAE decoder 还原图像。不同的是,Hallo 不再把文本作为主要条件,而是用音频和参考人脸条件驱动肖像运动。#Xu-et-al.-2024-Hallo
UNet denoiser 的角色
在 Hallo 中,UNet denoiser 是真正执行扩散去噪的视频生成主体。它接收 noisy latents、时间步、参考图像条件、音频条件和区域 mask 相关条件,逐步恢复出与音频同步的视频 latent。论文强调该网络与 ReferenceNet、temporal alignment 和 HADVS 共同构成最终生成架构。#Xu-et-al.-2024-Hallo
ReferenceNet:让生成结果像同一个人
ReferenceNet 是一个与 denoising UNet 层数相同的 Stable Diffusion UNet,用来从参考图像中提取全局视觉纹理、人物身份和背景信息,并把相同空间分辨率上的特征注入 diffusion backbone。#Xu-et-al.-2024-Hallo 换句话说,ReferenceNet 主要回答“这个人是谁、画面长什么样”,音频分支和 HADVS 主要回答“这一帧该怎么动”。
Face embedding 与 audio embedding
Hallo 使用预训练 face encoder 抽取身份特征,而不是直接用 CLIP 泛化视觉特征;音频侧使用 wav2vec,并拼接 wav2vec 最后 12 层 embedding,以获得更丰富的语音语义和运动提示。论文还为每个视频帧抽取对应 5 秒音频片段,再通过线性层投影为每帧的 audio embedding。#Xu-et-al.-2024-Hallo
flowchart TD A["参考肖像"] --> B["Face encoder / ReferenceNet"] C["驱动音频"] --> D["wav2vec + audio projection"] A --> E["MediaPipe landmarks"] E --> F["lip / expression / pose masks"] D --> G["Hierarchical audio-visual cross attention"] F --> G B --> H["Denoising UNet"] G --> H I["Temporal alignment: previous 2 frames"] --> H H --> J["VAE decoder"] J --> K["Talking portrait video"]
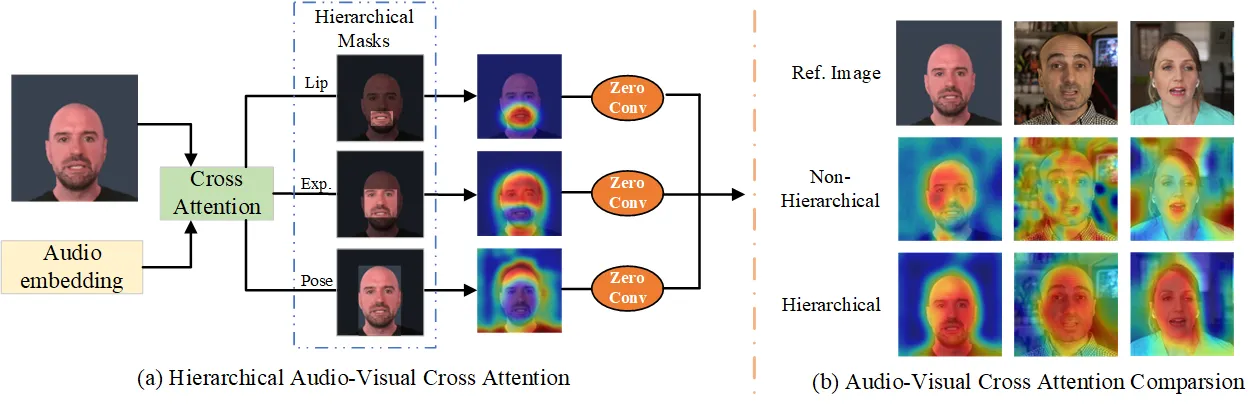
Hierarchical Audio-Driven Visual Synthesis(HADVS)是 Hallo 最值得细读的模块。论文先用 MediaPipe 从参考脸上预测 landmark,再构造 lip、expression、pose 三个区域 mask:唇部 mask 来自 lip bounding box,表情 mask 是 expression bounding box 扣掉 lip 区域,pose mask 则覆盖剩余区域。#Xu-et-al.-2024-Hallo
区域 mask 的数学定义
如果 $Y_{lip}$ 和 $Y_{exp}$ 分别表示 lip 与 expression landmark bounding box 对应的二值区域,那么 Hallo 使用:
这里的重点不是公式复杂,而是把“嘴唇—表情—姿态”变成 denoising UNet 内部可见的空间分区。#Xu-et-al.-2024-Hallo
接下来,模型先对每一帧 noisy latent 和对应 audio embedding 做 cross-attention,得到音频驱动的视觉响应;然后分别用 $M_{pose}$、$M_{exp}$、$M_{lip}$ 切出姿态、表情、唇部三类响应;最后用卷积式 adaptive module 融合这些层级输出。#Xu-et-al.-2024-Hallo
Temporal alignment:长视频为什么需要前 2 帧
Hallo 在 temporal alignment 中使用前一推理 step 的 2 帧作为 motion frames,并把它们与 latent noise 沿时间轴拼接,再通过 temporal self-attention blocks 处理序列一致性。#Xu-et-al.-2024-Hallo 在长视频推理时,上一 clip 的最后 2 帧会作为下一 clip 的初始帧,从而以增量方式生成更长视频。#Xu-et-al.-2024-Hallo
Stage 1:单帧生成能力
第一阶段使用 reference image 与 target video frame pairs 训练单帧生成能力;VAE encoder/decoder 和 facial image encoder 被固定,ReferenceNet 与 denoising UNet 的 spatial cross-attention 权重参与优化。#Xu-et-al.-2024-Hallo 论文描述中,每个训练视频 clip 含 14 帧,训练时从同一视频中随机取一帧作 reference frame,再取另一帧作 target image。#Xu-et-al.-2024-Hallo
Stage 2:视频序列与音频对齐
第二阶段输入 reference image、audio 与 target video,冻结 ReferenceNet 和 denoising UNet 的 spatial modules,重点训练 hierarchical audio-visual cross-attention,让音频作为 motion guidance 与 lip、expression、pose 视觉区域建立关系。#Xu-et-al.-2024-Hallo 同时,motion modules 被引入以增强 temporal coherence,并用 AnimateDiff 权重初始化。#Xu-et-al.-2024-Hallo
GitHub README 中披露的训练入口
官方 README 披露了可用训练流程:先用 scripts.data_preprocess 的 step 1 把视频转帧、抽取音频并生成 mask;step 2 用 InsightFace 生成 face embeddings、用 Wav2Vec 生成 audio embeddings;随后用 extract_meta_info_stage1.py 与 extract_meta_info_stage2.py 生成 metadata JSON;训练通过 accelerate launch ... scripts.train_stage1 --config ./configs/train/stage1.yaml 这类命令启动。#Hallo-GitHub
| 项目 | 论文/README 披露 | 状态 |
|---|---|---|
| 硬件 | 8 NVIDIA A100 GPUs | 披露 |
| 训练阶段 | Stage 1 单帧;Stage 2 视频序列与音频对齐 | 披露 |
| 训练步数 | 两个阶段各 30,000 steps | 披露 |
| Batch size | 4 | 披露 |
| 分辨率 | 512×512 | 披露 |
| 学习率 | 1e-5 | 披露 |
| 第二阶段帧数 | 每个 training instance 产生 14 frames,并拼接前 2 个 ground-truth frames | 披露 |
| Dropout 条件 | reference image、guidance audio、motion frames 以 0.05 概率 drop | 披露 |
| Motion module 初始化 | AnimateDiff weights | 披露 |
| 优化器类型 | 论文正文未明确列出 | 未披露 |
| 完整训练耗时 | 论文正文未明确列出 | 未披露 |
| 完整数据许可 | 论文说明来源与清洗规则,但未逐项列出许可 | 未披露 |
推理阶段输入是一张 source image 和一段 driving audio,网络输出由音频驱动的肖像动画视频。#Xu-et-al.-2024-Hallo README 对输入有明确约束:source image 应裁成正方形,脸部占图像 50%–70%,正脸且旋转角小于 30°;driving audio 必须是 WAV,且仓库模型说明训练数据只包含英文,因此要求英文语音与清晰人声。#Hallo-GitHub
脚本级流程
官方 scripts/inference.py 的当前主分支实现把推理模型组织成 reference_unet、denoising_unet、face_locator、imageproj 和 audioproj 五类核心模块;推理时先预处理参考图像,得到 face region、face embedding、full/face/lip mask,再预处理 16kHz audio 得到 wav2vec embedding。#Hallo-GitHub
脚本还从配置中读取 pose_weight、face_weight、lip_weight 并组成 motion scale,这与论文所说的 visual synthesis weights 对应:用户可以在一定程度上调节 pose、face/expression 和 lip 三类视觉运动权重。#Hallo-GitHub
| 推理环节 | 输入/输出 | 作用 | 披露状态 |
|---|---|---|---|
| Source image preprocessing | source image → pixels、face masks、face embedding | 定位脸部与身份条件 | README / inference.py 披露 |
| Audio preprocessing | WAV → wav2vec embeddings | 提取音频 motion guidance | README / inference.py 披露 |
| Reference branch | reference image latent → texture/context features | 保持身份、纹理和背景 | 论文 / 代码披露 |
| Denoising branch | noisy latent + conditions → denoised latent | 生成视频 latent | 论文 / 代码披露 |
| Temporal stitching | 上一 clip 最后 2 帧 → 下一 clip 初始帧 | 提升长视频连续性 | 论文披露 |
| 采样步数 | 正文未明确列出默认步数 | 影响速度与质量 | 未披露 |
| 实时性 | 论文给出不同分辨率耗时,但未声称实时产品级延迟 | 部署判断 | 部分披露 |
数据集与评估指标
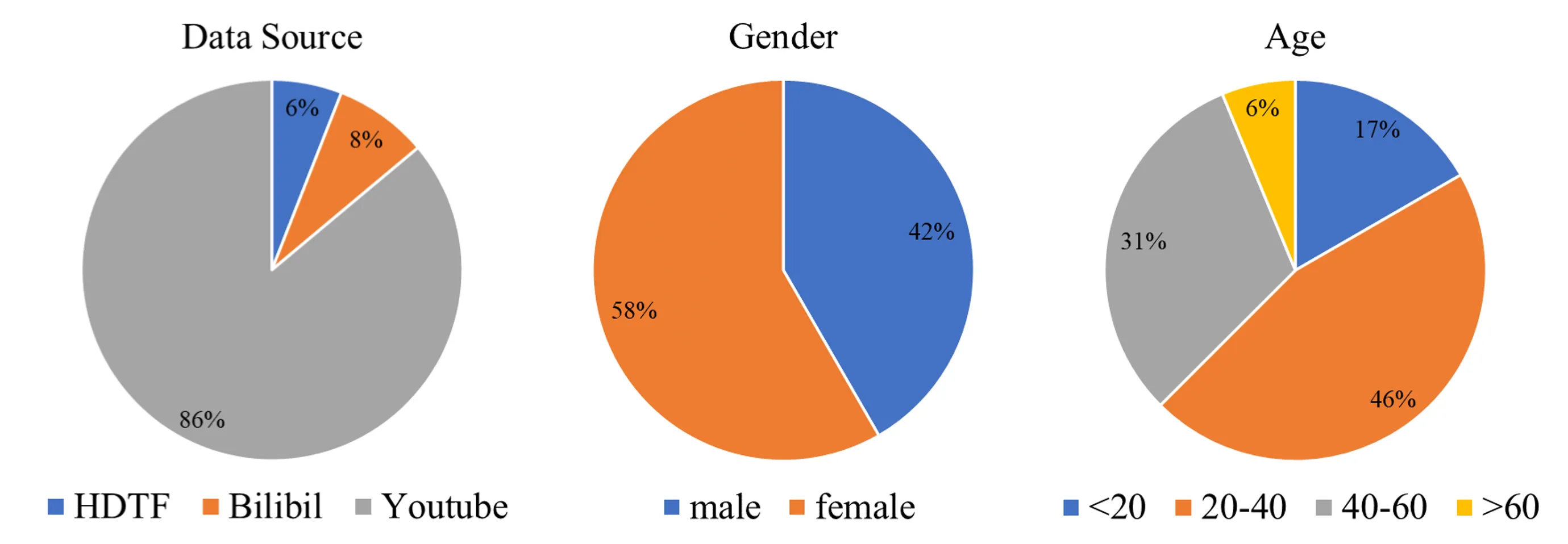
论文训练数据来自 HDTF、Bilibili 与 YouTube,原始总量为 2209 IDs / 164.32 小时;清洗后保留 1823 IDs / 108.86 小时。#Xu-et-al.-2024-Hallo 清洗规则包括保留单人说话且唇音一致的视频,排除场景切换、明显相机运动、过大面部运动和完整侧脸镜头。#Xu-et-al.-2024-Hallo
评估指标包括 FID、FVD、Sync-C、Sync-D 和 E-FID;其中 FID/FVD 衡量图像与视频分布质量,Sync-C/Sync-D 衡量唇音同步,E-FID 用 Inception 特征评估生成图像质量。#Xu-et-al.-2024-Hallo
核心量化结果
| 数据集 | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | E-FID ↓ | 论文结论 |
|---|---|---|---|---|---|---|
| HDTF | 20.545 | 173.497 | 7.750 | 7.659 | 7.951 | 图像/视频质量和时间一致性最强,唇音同步接近 real video |
| CelebV | 44.578 | 377.117 | 7.191 | 7.984 | 78.495 | FID、FVD、Sync-C、E-FID 均为表中最优 |
| Wild | 23.266 | 239.647 | 6.924 | 7.969 | 34.731 | 复杂条件下仍保持较强鲁棒性 |
HDTF 表中,Hallo 的 FID 20.545、FVD 173.497、E-FID 7.951 均优于 SadTalker、Audio2Head、DreamTalk 和 AniPortrait;Sync-C 7.750 虽低于 Audio2Head 的 8.024,但整体质量与同步指标更均衡。#Xu-et-al.-2024-Hallo
消融:为什么必须三层都用
HADVS 的消融很直接:只做 full audio-visual cross attention 时,HDTF FVD 为 193.062、Sync-C 为 6.499;最终使用 lip + expression + pose 三个区域后,FVD 降到 173.497,Sync-C 升到 7.750。#Xu-et-al.-2024-Hallo 这说明 Hallo 的收益不只是来自更大的扩散 backbone,而来自音频条件进入视觉空间的方式变化。
| 消融项 | 关键结果 | 解读 |
|---|---|---|
| Full attention baseline | FID 20.581 / FVD 193.062 / Sync-C 6.499 | 画质可以,但唇音同步和视频一致性不足 |
| Lip + Exp + Pose | FID 20.545 / FVD 173.497 / Sync-C 7.750 | 三层区域注意力综合最优 |
| Zero convolution fusion | FVD 173.497 / Sync-C 7.750 / E-FID 7.951 | 融合机制优于 self attention 和 direct addition 的综合指标 |
| CFG λa=3.5, λi=3.5 | FID 23.167 / FVD 195.179 / Sync-C 7.658 | 论文采用的视觉保真与运动多样性折中配置 |
效率:不是实时论文,而是扩散路线的成本说明
效率表显示,512×512 推理使用 HADVS 时需要 9.77GB 显存、1.63 秒;去掉 HADVS 后为 9.76GB、1.63 秒;256×256 为 6.62GB、0.46 秒;1024×1024 为 20.66GB、10.29 秒。#Xu-et-al.-2024-Hallo 因此更准确的读法是:HADVS 几乎不增加推理时间,但整个方法仍是偏离线高质量生成,而不是 Ditto 那类实时交互系统。
论文明确把未来工作分成四类:增强 audio-visual synchronization、提升 temporal coherence、优化 computational efficiency、改进 expression/pose diversity control。#Xu-et-al.-2024-Hallo 这些局限都指向同一个事实:端到端扩散模型提升了画质和自然度,但要进入稳定产品,还需要更低延迟、更强可控性和更可靠的长时一致性。
复现和使用时的风险点
README 明确说明当前模型训练数据仅为英文,因此中文、唱歌、强噪声或极端情绪语音都可能出现泛化风险;同时,输入人像要求正脸、脸部占比 50%–70%,这意味着任意野图并不一定适合直接推理。#Hallo-GitHub
README 还单独写了 social risks and mitigations:音频驱动肖像动画可能被用于 deepfake,涉及肖像和声音的隐私、同意与误用问题,因此需要伦理准则、透明数据政策、知情同意和负责任使用。#Hallo-GitHub
本文要点复盘
- 核心问题:音频要同时对齐 lip、expression 和 pose,而不是只驱动嘴部。
- 核心模块:HADVS 用区域 mask 与分层 cross-attention 改写音频条件进入视觉 latent 的路径。
- 生成骨架:ReferenceNet 保身份和纹理,UNet denoiser 做扩散生成,temporal alignment 用前 2 帧增强连续性。
- 实验结论:Hallo 在 HDTF、CelebV 和 Wild 上取得较强 FID/FVD/E-FID 与同步表现,HADVS 消融证明三层区域注意力有效。
- 主要局限:效率、长时一致性、音频视觉精细同步和多样性控制仍是后续关键问题。
参考来源
- Xu, Mingwang, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, and Siyu Zhu. “Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation.” arXiv:2406.08801, 2024. arXiv
- arXiv TeX source for “Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation.” Retrieved from arXiv e-print source, 2026-06-09. Source
- Fudan Generative Vision. “hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation.” GitHub repository and README. GitHub
- Hallo project page. Project website