实时数字人生成 Survey
本文讨论的“实时数字人”不是泛泛的虚拟人概念,而是一个可验证的生成任务:输入一张人像、一个已有视频或一个固定数字人资产,再输入语音或文本,系统输出与内容同步的视频人物。最低要求是口型同步;更高要求是自然表情、眼动、头动、上半身姿态、手势、身份一致性、低延迟和持续流式稳定性。这个任务横跨 lip-sync、talking head synthesis、portrait animation、audio-to-motion、video diffusion、NeRF/3DGS rendering、WebRTC 与合规治理。
实时数字人需要同时放在 talking head synthesis 和在线交互系统两个框架下理解。已有 survey 的共识是:Meng et al. 的三段式框架把方法归纳为 portrait generation、driving mechanisms 和 editing techniques;Rakesh et al. 进一步把 THG 拆成 image/audio/text/video、2D/3D、NeRF、diffusion、parameter efficiency 等工程范式,并系统整理 datasets、losses 与 metrics;Zhang et al. 的实践型综述则强调 2021—2025 年间领域正在从 frame-level realism 转向 semantic alignment、temporal coherence 和 perceptual quality。对于实时数字人来说,还必须额外加入端到端延迟、流式稳定性、部署成本和合规治理,因为业务真正关心的不是单帧好不好看,而是系统能否在持续交互中稳定工作。#Meng-et-al.-2024-THSTaxonomy #Rakesh-et-al.-2025-THGSurvey #Zhang-et-al.-2026-PracticeSurvey
flowchart LR A["输入条件"] --> A1["已有视频 + 新音频"] A --> A2["单图 + 音频"] A --> A3["文本 + 参考风格"] A --> A4["固定角色 + 训练视频"] A1 --> B1["唇部 editing / dubbing"] A2 --> B2["talking head / portrait animation"] A3 --> B3["text-driven audio-visual generation"] A4 --> B4["NeRF / 3DGS / 轻量专人模型"] B1 --> C["实时数字人系统"] B2 --> C B3 --> C B4 --> C C --> D["端到端延迟、质量、合规、成本"]
图 1:实时数字人不是单一路线。输入条件不同,决定了可用方法、训练成本和上线风险。
实时数字人的第一层分界不是模型名字,而是输入条件。已有视频配新音频,最自然地落在 Wav2Lip、MuseTalk、RealTalk 这类唇部 editing / video dubbing 路线;单图配语音,则进入 SadTalker、VASA-1、Ditto、READ 这类 talking head / motion generation 路线;固定主播或品牌形象,可以考虑 Ultralight-Digital-Human、NeRF 或 3DGS 专人建模;上半身虚拟主播还必须额外处理手势、身体节奏和语义动作。#Prajwal-et-al.-2020 #Zhang-et-al.-2023 #Xu-et-al.-2024 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Ultralight-Digital-Human-GitHub
这也是为什么“能生成 talking head”不等于“能上线实时数字人”。MuseTalk 更接近视频配音和唇部区域重绘,LivePortrait 是 motion-driven portrait animation,Ultralight 需要每人 3 到 5 分钟训练视频,VASA-1 虽然报告 512×512 up to 40 FPS 和 negligible starting latency,但截至 2026-06-08 未见官方公开代码/权重。2025 年的新路线进一步扩展了边界:Ditto 把扩散放入 motion space,READ 把 diffusion transformer 做成实时异步生成,OmniTalker 尝试把 TTS 与 talking head 统一建模,ChatAnyone 把上半身动作纳入实时生成,SyncAnimation 与 EGSTalker 则把 NeRF/3DGS 推向专人实时渲染。#Li-et-al.-2025-Ditto #Wang-et-al.-2025-READ #Wang-et-al.-2025-OmniTalker #Qi-et-al.-2025-ChatAnyone #Liu-et-al.-2025-SyncAnimation #Zhu-et-al.-2025-EGSTalker
| 输入条件 | 优先路线 | 实时性主要瓶颈 | 不应误判为 |
|---|---|---|---|
| 已有视频 + 新音频 | lip editing / video dubbing | 口型同步、局部重绘、编码链路 | 任意身份冷启动数字人 |
| 单图 + 音频 | 3DMM、latent dynamics、motion-space diffusion | 头动、表情、长时一致性、首帧延迟 | 完整上半身主播 |
| 固定身份 + 训练视频 | NeRF / 3DGS / 轻量专人模型 | 建模成本、身份授权、专人资产维护 | 通用泛化模型 |
| 文本 + 参考风格 | LLM→TTS→THG 或端到端多模态 | 语音风格、音画一致、级联误差 | 单一视觉生成模型 |
实时数字人的技术边界可以拆成六个相互约束的问题:任务输入决定系统能否冷启动,驱动信号决定动作来源,中间表示决定可控性和泛化,生成器决定画质与延迟,数据集/指标决定评测可信度,部署链路决定是否真的能上线。Song et al. 2023 已经把 talking head generation 放在数字人应用语境下讨论 dataset availability、key technologies 和 evaluation strategies;Meng et al. 2024 进一步把技术链条拆成 portrait generation、driving mechanisms 和 editing techniques;Zhang et al. 2026 则显示近五年研究重点正在转向 speech-to-motion representation、style/emotion-aware animation、high-fidelity diffusion、dataset trend 与 evaluation protocol。#Song-et-al.-2023-Survey #Meng-et-al.-2024-THSTaxonomy #Zhang-et-al.-2026-PracticeSurvey
这六个问题之间没有免费的最优解。只做唇部 editing,系统延迟和身份稳定性最好,但表情、头动和上半身动作受限;使用 3DMM 或显式 motion coefficients,可控性和可解释性更强,但细粒度肌肉与强情绪表达容易受参数空间限制;把视频压到 latent 或 motion space,再用 diffusion 或 transformer 生成动态,可以提升自然度,却必须解决多步采样、缓存和长时一致性;NeRF/3DGS 专人建模能获得更好的三维一致性,但冷启动、资产维护和授权成本更高。#Rakesh-et-al.-2025-THGSurvey #Li-et-al.-2025-Ditto #Wang-et-al.-2025-READ #Zhu-et-al.-2025-EGSTalker
| 结构问题 | 关键选择 | 直接影响 |
|---|---|---|
| 任务输入 | 已有视频、单图、固定资产、文本、语音 | 决定是否能冷启动,以及是否需要每人训练 |
| 驱动信号 | audio、text、pose、driving video、emotion | 决定口型、头动、表情、手势从哪里来 |
| 中间表示 | landmark、3DMM、implicit keypoint、latent dynamics、motion space | 决定可控性、泛化性和长时稳定性 |
| 生成器 | 局部重绘、GAN、U-Net、diffusion、transformer、NeRF、3DGS | 决定画质上限、推理延迟和部署复杂度 |
| 数据集与指标 | LRS、VoxCeleb、HDTF、MEAD、CelebV-HQ;同步、身份、时序、主观偏好 | 决定实验结论能否迁移到真实业务分布 |
| 部署链路 | 模型推理、后处理、编码、WebRTC、缓存、并发、合规 | 决定论文 FPS 能否变成产品 SLA |
数字人 survey 最容易犯的错误,是把 video dubbing、talking head、portrait animation、3D avatar 和上半身交互体都叫成“数字人生成”。它们共享口型同步、身份保持和实时性约束,但输入条件、输出自由度和失败模式完全不同。MuseTalk 图 1 可以用来说明这个边界:talking head generation 通常从单图和音频生成整段说话视频,模型需要负责头动、眼动和表情;video dubbing 是 Video-to-Video 任务,目标是在保留原视频头动、眼动和场景动态的前提下重绘嘴部。#Zhang-et-al.-2024-MuseTalk

| 任务类型 | 典型输入 | 典型输出 | 代表工作 | 核心风险 |
|---|---|---|---|---|
| Video dubbing / 换嘴配音 | 已有视频 + 新音频 | 保留头动、眼动、背景,只重绘嘴部或脸部 ROI | MuseTalk、Wav2Lip、RealTalk | 只能解决口型与局部真实感,不负责完整行为生成 |
| Talking head generation | 单张人像 + 音频 | 生成头部视频,包含口型、表情、头动和眼动 | SadTalker、VASA-1、Ditto、READ | 长时稳定、身份保持和自然头动都比换嘴更难 |
| Portrait animation / 驱动肖像动画 | 源图 + driving video、pose 或 motion signal | 把驱动运动迁移到目标肖像 | LivePortrait、AnimateAnyone | 如果业务只有音频,还需要额外 audio-to-motion 模块 |
| 3D avatar / 绑定数字人 | 固定角色资产、语音、文本、动作标签和对话上下文 | 全身 3D 动作、手势、面部表情和多轮交互 | SentiAvatar | 资产绑定、动作语义、语音韵律和多轮状态必须同时设计 |
| Upper-body interactive avatar | 人像或角色 + 音频/文本 + 风格控制 | 头、脸、手势、身体节奏同步生成 | ChatAnyone、SyncAnimation | 只看 lip-sync 会低估身体动作对真实感的影响 |
| Streaming foundation-model avatar | 参考帧 + 长音频/文本流 | 长时、低延迟、可持续生成的数字人视频 | Live Avatar、OmniTalker | 大模型实时化、长时漂移、并行推理和成本是主要瓶颈 |
核心任务
给定身份外观条件 \(I\)、驱动条件 \(D\) 和实时系统状态 \(S_t\),生成视频帧序列 \(\hat{X}_{1:T}\),使其在身份、口型、表情、头动、时间一致性和端到端延迟上同时满足约束。
| 术语 | 核心含义 | 典型输入 | 典型输出 | 容易误判的地方 |
|---|---|---|---|---|
| Lip-sync / speech-to-lip | 让嘴部运动与语音音素同步 | 已有脸部帧或视频 + 音频 | 同步的嘴部区域或局部人脸 | 它是最低层能力,不等于完整 talking head |
| Video dubbing | 在原视频上替换新音频对应的唇形 | 原视频 + 新音频 | 保留原头动、眼动、身体和背景的视频 | 不是从单图生成完整人,只是改写局部动态 |
| Talking head generation | 生成会说话的头部视频 | 单张人像或参考视频 + 音频/文本 | 口型、表情、头动、眼动共同变化的头部视频 | 通常不包含上半身手势和长期交互状态 |
| Portrait animation | 把驱动运动迁移到目标肖像 | 源图 + driving video、pose 或 motion signal | 按驱动信号运动的肖像视频 | 如果只有音频,还需要额外 audio-to-motion 模块 |
| 3D avatar | 围绕绑定资产生成动作、表情和交互行为 | 角色资产 + 文本/语音/动作标签/上下文 | 3D 身体、手势、面部表情和多轮互动 | 它不是纯视觉生成模型,而是资产、动作和系统的组合 |
| 实时数字人系统 | 把生成模型放进在线交互链路 | ASR/LLM/TTS/音视频流/用户状态 | 可持续、低延迟、可部署的视频人物 | 论文 FPS 不等于端到端产品 SLA |
这个公式看似简单,但它把很多被混在一起的任务拆开了。Wav2Lip 的 \(I\) 通常来自已有视频帧,\(D\) 是新音频,目标是嘴部区域同步;SadTalker 的 \(I\) 是单张图,\(D\) 是音频,先生成 3DMM motion coefficients;LivePortrait 的 \(D\) 更常见是驱动视频或运动信号;MuseTalk 的任务是 video dubbing,重点是保持原视频头动和眼动,只改嘴部;VASA-1、Ditto、READ 则试图在 latent 或 motion space 中生成更完整的脸部动态。#Prajwal-et-al.-2020 #Zhang-et-al.-2023 #Guo-et-al.-2024-LivePortrait #Zhang-et-al.-2024-MuseTalk #Xu-et-al.-2024 #Li-et-al.-2025-Ditto #Wang-et-al.-2025-READ
实时性也必须拆成模型实时和系统实时。论文里的 FPS 往往只覆盖渲染或生成模型的一段;真实业务还包括音频采集、VAD/ASR/TTS、特征提取、motion prediction、video generation、后处理、编码、WebRTC 传输和客户端播放缓冲。VASA-1 报告 512×512 up to 40 FPS,MuseTalk 报告 256×256 30 FPS on NVIDIA V100,LivePortrait 报告 12.8ms on RTX 4090,RealTalk 报告 30 FPS on V100,ChatAnyone 报告 512×768 up to 30 FPS on 4090。这些数字只能证明“路线有实时潜力”,不能直接等于产品 SLA。#Xu-et-al.-2024 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Ji-et-al.-2024-RealTalk #Qi-et-al.-2025-ChatAnyone
最常见误判
“单图可生成”“论文可实时”“开源可跑”“适合商用”是四个不同问题。选型时必须先看输入条件,再看实时指标,再看许可证和部署链路。
2020—2021:lip-sync 先成为独立模块
Zhang et al. 对 2021—2025 年 100 多篇 talking-head 工作的 longitudinal analysis 显示,领域不是沿着单一路线前进,而是在数据集、指标和模型范式上同步迁移:早期更关注 frame-level realism 与 lip synchronization,随后逐步转向 semantic alignment、temporal coherence、expression naturalness 和 driving-signal alignment。这个变化解释了为什么实时数字人不能只按“像不像”排序,而要同时看语义动作、长时稳定和系统延迟。#Zhang-et-al.-2026-PracticeSurvey
这一阶段的核心共识是:如果嘴型不对,数字人立即失真。Wav2Lip 的贡献不是完整数字人,而是把 speech-to-lip generation 做成可迁移模块,并引入 lip-sync expert/discriminator 作为强约束。它奠定了一个后续长期有效的工程事实:即使系统已经有 3DMM、diffusion 或 NeRF 渲染,口型同步仍然可以作为独立评测和修复模块存在。#Prajwal-et-al.-2020
2022—2023:单图 talking head 和显式运动系数
SadTalker 代表了从局部嘴部修复到完整单图说话头的转变。它把音频映射到 expression coefficients 和 head pose,再通过 3D-aware face render 合成视频。这个阶段的优势是可解释、可控、适合做 baseline;局限是 3DMM 的表达上限有限,细粒度肌肉、眼神和强情绪运动容易不自然。#Zhang-et-al.-2023
2023—2024:扩散模型带来表现力,也带来延迟
EMO、AnimateAnyone 说明视频扩散可以显著提升表现力。EMO 直接从单图和音频生成 talking/singing portrait video,绕开 3D 模型和 landmarks;AnimateAnyone 用 reference image 与 pose sequence 做可控角色动画。它们推动了身份保持、长视频一致性和情绪表现,但多步去噪让低延迟交互变得困难。#Tian-et-al.-2024 #Hu-et-al.-2023
2024:实时路线开始分化
VASA-1 证明 face latent dynamics 可以在单图语音驱动中兼顾口型、表情和头动,并报告 512×512 up to 40 FPS;MuseTalk 选择更窄的 video dubbing 任务,在 VAE latent 中做单步生成,报告 256×256 30 FPS on V100;LivePortrait 反其道而行,不追多步扩散,而是扩大 implicit-keypoint 框架,在约 69M frames 上训练并报告 12.8ms on RTX 4090。这个阶段的关键词不是“谁统一一切”,而是“不同路线为实时性牺牲不同东西”。#Xu-et-al.-2024 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait
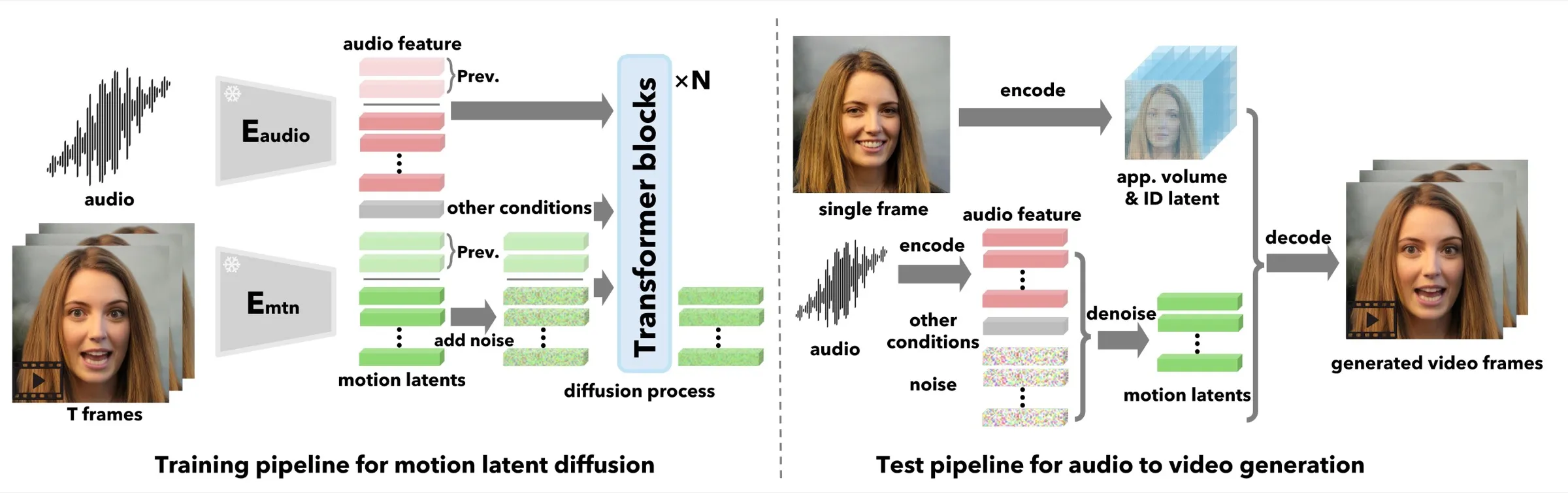
2025:动作空间扩散、实时扩散和上半身交互
2025 年的新变化是扩散不再只意味着慢。Ditto 把扩散放进 motion space,让模型主要学习“怎么动”,再由高效动画器渲染;READ 用 temporal VAE、SpeechAE 和 asynchronous noise scheduler 把 diffusion transformer 推向 1:1 time ratio;ChatAnyone 用层级 motion diffusion 生成脸和上半身控制信号,再用高效生成器达到 512×768 up to 30fps on 4090;OmniTalker 则把 TTS 与 talking head 合并到 0.8B 的统一模型,报告 single RTX 4090 上 25 FPS。NeRF/3DGS 路线也继续发展,SyncAnimation 面向音频驱动上半身和 talking head,EGSTalker 用 3DGS 与 3—5 分钟训练视频追求专人实时渲染。#Li-et-al.-2025-Ditto #Wang-et-al.-2025-READ #Qi-et-al.-2025-ChatAnyone #Wang-et-al.-2025-OmniTalker #Liu-et-al.-2025-SyncAnimation #Zhu-et-al.-2025-EGSTalker
| 阶段 | 代表工作 | 核心转变 | 实时性含义 |
|---|---|---|---|
| 2020 | Wav2Lip | 口型同步成为独立可训练目标 | 适合局部模块化部署 |
| 2023 | SadTalker | 单图 + 音频 → 3DMM motion coefficients | 可解释但不天然实时 |
| 2024 | VASA-1 / MuseTalk / LivePortrait | latent dynamics、latent inpainting、implicit keypoints 并行分化 | 研究标杆与工程路线开始分离 |
| 2025 | Ditto / READ / ChatAnyone / EGSTalker | motion-space diffusion、实时 diffusion、上半身、3DGS | 实时不再只靠 GAN/轻量模型,扩散也开始系统化降延迟 |
任务分类回答“要生成什么”,技术路线分类回答“用什么中间表示和生成器来生成”。二者不能混用:lip-sync 是一个可独立训练和评测的同步模块;3D 绑定路线强调资产、骨骼、blendshape 和动作计划;motion-space diffusion 把扩散放到运动空间而不是像素空间;基模/大模型路线则把数字人纳入视频生成基础模型,再用蒸馏、缓存和并行系统解决实时性。
| 技术路线 | 核心表示 | 适配任务 | 代表工作 | 关键取舍 |
|---|---|---|---|---|
| Lip-sync / 局部重绘 | 嘴部 ROI、SyncNet/audio-visual speech feature、VAE latent | video dubbing、换嘴、配音本地化 | Wav2Lip、MuseTalk、RealTalk | 实时友好,但嘴以外动态通常不生成 |
| 3DMM / 显式运动系数 | expression coefficients、head pose、3D-aware render | 单图 talking head、可解释 baseline | SadTalker | 可控易诊断,但受参数化脸模型上限限制 |
| Implicit keypoints / motion retargeting | 隐式关键点、stitching、retargeting control | portrait animation、motion-driven avatar | LivePortrait | 速度快、动画自然,但音频输入需另接 motion predictor |
| Latent dynamics / face latent | 可解耦 face latent、audio-conditioned dynamics | 单图语音驱动 talking face | VASA-1 | 质量与实时性标杆,但工程可得性取决于代码/权重开放 |
| Motion-space diffusion / 动作空间扩散 | motion space、LivePortrait-style motion、streaming renderer | 实时 talking head、可控表情头动 | Ditto | 保留扩散表达力,同时避开像素级扩散开销 |
| Real-time diffusion transformer | video latent、speech latent、asynchronous noise schedule | 实时 audio-driven talking head | READ | 把扩散推向 1:1 time ratio,但系统复杂度更高 |
| 3D 绑定 / 行为生成 | 骨骼、手部动作、ARKit blendshape、motion foundation tokens | 3D avatar、多轮交互、语义动作 | SentiAvatar | 更像交互角色系统,重点从“画脸”转向“规划行为” |
| NeRF / 3DGS 专人渲染 | radiance field、Gaussian deformation、专人训练视频 | 固定主播、品牌角色、专人客服 | SyncAnimation、EGSTalker | 三维一致性强,但冷启动和资产维护成本高 |
| 基模 / 大模型流式路线 | 视频扩散基模、DMD 蒸馏、KV cache、pipeline parallelism | 长时流式数字人、LLM 视频助手 | Live Avatar、OmniTalker | 画质和泛化潜力高,但成本、长时漂移和实时系统设计最重 |
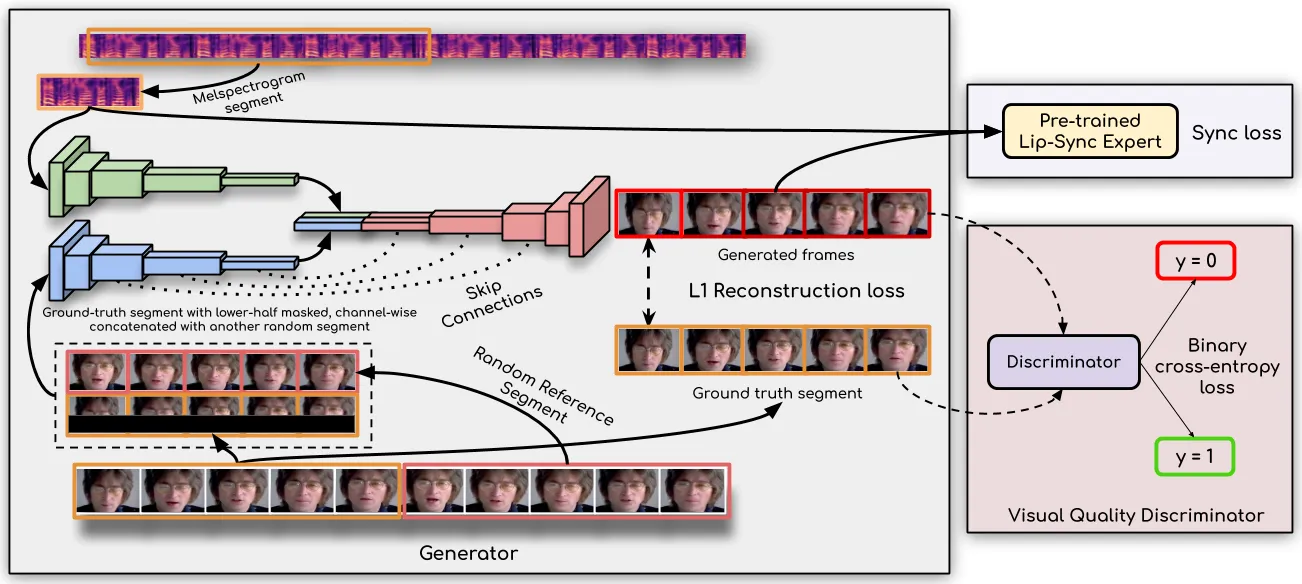
路线一:唇部 editing / video dubbing
这是最容易产品化的路线,也是最容易被低估的路线。它不追求从零生成一个完整人,而是在已有人脸视频或人脸区域上重绘嘴部。Wav2Lip 的优势是口型约束强,MuseTalk 进一步把任务放到 latent inpainting 和 one-shot video dubbing 中,报告 256×256 30 FPS on V100。RealTalk 则把 3D facial prior 与身份对齐网络结合,报告 30 FPS on V100。局限是嘴以外的表情、眼动、身体动作大多来自原视频或额外模块。#Prajwal-et-al.-2020 #Zhang-et-al.-2024-MuseTalk #Ji-et-al.-2024-RealTalk
路线二:3DMM / 显式运动系数
3DMM 路线把表情和头姿变成可解释参数。SadTalker 用 ExpNet 预测表情系数,用 PoseVAE 生成自然头动,再用渲染器回到像素。它的优点是结构清晰、容易诊断,适合做可解释 baseline;缺点是参数化人脸模型会限制细节,上限不如大规模生成模型。#Zhang-et-al.-2023
路线三:隐式关键点 / motion-driven portrait animation
LivePortrait 说明非扩散路线仍然有强生命力。它基于 implicit keypoints、stitching 和 retargeting control,在约 69M high-quality frames 上训练,报告 PyTorch 环境 RTX 4090 上 12.8ms。它适合作为肖像动画引擎:给定源图像和运动信号,可以快速输出自然动画。但如果业务输入只有音频,仍要补 audio-to-motion。#Guo-et-al.-2024-LivePortrait
路线四:face latent dynamics / 单图语音驱动
VASA-1 的启发是:不要直接在像素空间预测每一帧,而是在表达性强、可解耦的 face latent space 中生成整体脸部动态,再解码成视频。它能同时处理口型、表情、头动和控制信号,报告 512×512 up to 40 FPS。局限也很现实:截至 2026-06-08 未见官方公开代码/权重,工程团队不能把它当成短期可依赖组件。#Xu-et-al.-2024
路线五:高表现力 video diffusion
EMO、AnimateAnyone 代表的是表现力上限。EMO 用 Audio2Video diffusion 从单图和音频生成说话/唱歌肖像,训练数据超过 250 小时并覆盖中文、英文、演讲、影视和唱歌;AnimateAnyone 用 ReferenceNet 与 Pose Guider 保持身份和姿态控制,适合全身角色动画。这条路线回答“自然度可以到哪里”,但不直接回答“能否低延迟交互”。#Tian-et-al.-2024 #Hu-et-al.-2023
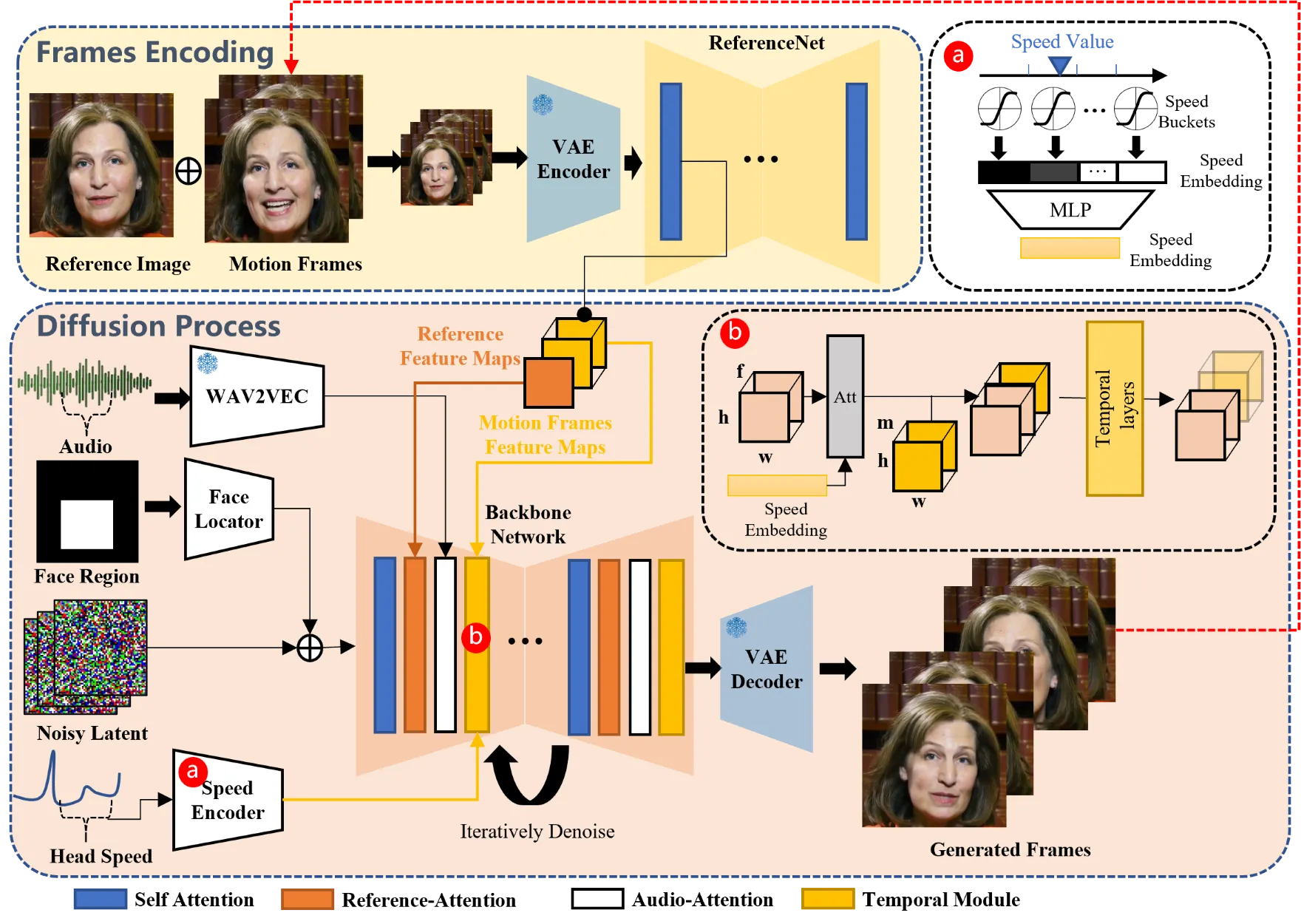
路线六:motion-space diffusion / 动作空间扩散
这是 2025 年最值得关注的折中路线。Ditto 不让扩散模型直接画视频,而是在 LivePortrait 风格的 motion space 中生成运动,再交给高效 renderer。这样既保留扩散模型对多样动作和语义控制的表达力,又避免像素级视频扩散的巨大开销。READ 进一步从 video latent 和 speech latent 的时空压缩入手,用 temporal VAE、SpeechAE、Audio-to-Video DiT 和 asynchronous noise scheduler 追求 1:1 time ratio。#Li-et-al.-2025-Ditto #Wang-et-al.-2025-READ
路线七:NeRF / 3DGS 专人实时渲染
NeRF 与 3DGS 路线通常不追求任意身份冷启动,而是用专人训练换取渲染质量、视角一致性和实时性。SyncAnimation 把 NeRF 用于音频驱动上半身、头部和唇形同步;EGSTalker 用 3DGS、hash triplane、KAN 和 efficient spatial-audio attention,只需 3—5 分钟训练视频来构建专人说话头。它适合固定主播、品牌代言人、客服形象,不适合“用户上传任意照片马上生成”。#Liu-et-al.-2025-SyncAnimation #Zhu-et-al.-2025-EGSTalker
路线八:上半身、手势和语义动作
真实数字人不只是头。ChatAnyone 明确指出,已有实时方法主要关注头动,难以生成与头部同步的身体动作和细粒度表情控制。它用 efficient hierarchical motion diffusion 从音频生成脸和身体控制信号,再用 hybrid control fusion generator 生成 512×768 上半身视频,报告 4090 上 up to 30fps。这个方向的重要性在于,用户对“像真人”的感知很大一部分来自停顿、点头、手势和身体节奏。#Qi-et-al.-2025-ChatAnyone
路线九:text-driven / 端到端多模态
传统交互数字人通常是 LLM → TTS → audio-driven talking head 的级联系统。OmniTalker 认为级联会带来冗余计算、误差累积和音视频风格不一致,因此用统一双分支 diffusion transformer 同时生成 speech 和 talking head,模型规模约 0.8B,报告 single RTX 4090 上 25 FPS。它还不是所有业务的默认答案,但提示了一个方向:未来实时数字人可能不再把语音和视频分成两个后处理模块,而是统一建模“说什么、怎么说、脸怎么动”。#Wang-et-al.-2025-OmniTalker
Survey 论文反复强调 datasets 和 evaluation protocols,因为 talking head 的“好”不是一个单指标问题。常见数据集包括 LRS2/LRS3、VoxCeleb/VoxCeleb2、HDTF、MEAD、CelebV-HQ、TalkingHead-1KH 等;不同数据集覆盖的人数、语言、分辨率、情绪、姿态和场景差异很大。Wav2Lip 主要围绕 speech-to-lip generation;SadTalker 使用 3DMM 运动系数相关训练与评测;LivePortrait 把训练规模扩展到约 69M high-quality frames;EMO 自建超过 250 小时的多样音视频数据;ChatAnyone 和 OmniTalker 则需要更复杂的多模态数据管线。#Prajwal-et-al.-2020 #Zhang-et-al.-2023 #Guo-et-al.-2024-LivePortrait #Tian-et-al.-2024 #Qi-et-al.-2025-ChatAnyone #Wang-et-al.-2025-OmniTalker
| 数据集/数据来源 | 使用或相关模型 | 在论文里的用途 | 横向比较边界 |
|---|---|---|---|
| LRS2 / LRS3 | Wav2Lip、SyncNet 系列基线 #Prajwal-et-al.-2020 | 训练/评测 audio-visual speech 与 lip-sync,对口型同步很敏感 | 更像口型同步数据,不覆盖完整数字人交互中的情绪、手势和长时状态 |
| VoxCeleb / VoxCeleb2 | 多篇 talking head / speaker video 工作常作身份泛化来源,survey 中作为通用人脸说话视频数据集讨论 #Meng-et-al.-2024-THSTaxonomy #Rakesh-et-al.-2025-THGSurvey | 提供真实场景、多身份、多姿态的说话人视频 | 噪声、姿态、裁切和分辨率差异大,不能直接代表高清数字人质量 |
| HDTF | Wav2Lip、MuseTalk、RealTalk、LatentSync 等 video dubbing / talking face 方法常用或对比 #Prajwal-et-al.-2020 #Zhang-et-al.-2024-MuseTalk #Ji-et-al.-2024-RealTalk | 高清 talking face 训练与评测;MuseTalk 在 HDTF 上报告 FID、CSIM、LSE-C | 适合看脸部质量和口型,但不一定覆盖强情绪、上半身动作和在线交互状态 |
| VFHQ / CelebV-HQ / TalkingHead-1KH | MuseTalk 使用 VFHQ;LivePortrait 使用大规模 high-quality frames;survey 将 CelebV-HQ / TalkingHead-1KH 归为高质量肖像与 talking head 来源 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Rakesh-et-al.-2025-THGSurvey | 提升高质量肖像、身份保持、姿态和视觉多样性 | 许可证、清洗质量、人物授权和采样分布必须单独核查 |
| MEAD | 情绪 talking head 和表情控制工作常用;survey 用它说明情绪标签数据的价值 #Meng-et-al.-2024-THSTaxonomy #Rakesh-et-al.-2025-THGSurvey | 提供情绪类别和强度标签,适合评估表情控制 | 受控采集与真实业务分布仍有差距,不能替代开放场景测试 |
| 自建大规模音视频 | EMO 超过 250 小时多样音视频;OmniTalker 使用多阶段多模态训练数据 #Tian-et-al.-2024 #Wang-et-al.-2025-OmniTalker | 覆盖说话、唱歌、语言、风格和复杂表现力 | 数据不可复现时,只能把结果看成能力上限参考,不能直接公平横比 |
| 专人 3—5 分钟视频 | EGSTalker、Ultralight-Digital-Human、NeRF/3DGS 专人路线 #Zhu-et-al.-2025-EGSTalker #Ultralight-Digital-Human-GitHub | 为固定身份建立个性化渲染或轻量模型 | 质量和一致性好,但冷启动成本高,不适合任意用户上传即生成 |
指标也必须分层。Lip-sync 可以看 LSE-C、LSE-D、SyncNet score 或 landmark mouth distance;视觉质量可以看 FID、FVD、LPIPS、PSNR/SSIM 或人工偏好;身份保持可以看 ArcFace 相似度;运动自然度可以看 landmark accuracy、head pose distribution、temporal jitter;实时系统还要看 p50/p95/p99 latency、cold start、吞吐、显存和失败率。Zhang et al. 特别指出,PSNR、SSIM 这类低层视觉指标不足以捕捉 temporal coherence、emotional intent 或 semantic correctness;更合理的协议通常应结合自动指标与 MOS 人工评测,评分人数、置信区间和测试样本量应按具体 benchmark 设定。单看一个指标会误导:一个模型可能 LSE 很好但脸僵,一个模型视觉质量高但延迟不可交互,一个模型 demo 漂亮但授权和许可证不满足商用。#Zhang-et-al.-2026-PracticeSurvey
| 评测维度 | 常见指标 | 使用或相关模型 | 能说明什么 / 不能说明什么 |
|---|---|---|---|
| 口型同步 | LSE-C、LSE-D、SyncNet score、LMD | Wav2Lip、MuseTalk、RealTalk、LatentSync、InfiniteTalk 等 lip-sync / dubbing 方法 #Prajwal-et-al.-2020 #Zhang-et-al.-2024-MuseTalk #Ji-et-al.-2024-RealTalk | 说明音频与嘴部运动是否对齐;不代表表情、眼神、头动和身体节奏自然 |
| 视觉质量 | FID、FVD、LPIPS、PSNR/SSIM、人工偏好 | MuseTalk 报告 FID;InfiniteTalk / video generation 类方法常报告 FID/FVD;survey 强调 PSNR/SSIM 不足以代表感知质量 #Zhang-et-al.-2024-MuseTalk #Zhang-et-al.-2026-PracticeSurvey | 说明图像或视频是否清晰真实;不代表实时,也不代表身份授权或音画同步 |
| 身份保持 | CSIM、ArcFace similarity、ID score | MuseTalk 报告 CSIM;LivePortrait、VASA-1、Ditto 等肖像动画方法也需要身份保持评估 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Xu-et-al.-2024 #Li-et-al.-2025-Ditto | 说明生成脸是否仍像输入身份;不代表嘴型、情绪或语义动作准确 |
| 运动自然度 | landmark error、pose distribution、temporal stability、head/body motion preference | SadTalker、VASA-1、Ditto、ChatAnyone、SyncAnimation 这类会生成头动、表情或上半身动作的方法更需要该类指标 #Zhang-et-al.-2023 #Xu-et-al.-2024 #Li-et-al.-2025-Ditto #Qi-et-al.-2025-ChatAnyone #Liu-et-al.-2025-SyncAnimation | 说明表情、头动、身体动作是否稳定自然;不保证口型同步,也不覆盖业务语义合理性 |
| 系统实时性 | FPS、RTF / 1:1 time ratio、p95/p99 latency、cold start、显存、吞吐 | VASA-1、MuseTalk、LivePortrait、RealTalk、READ、ChatAnyone、OmniTalker 都给出不同形式的实时性数字 #Xu-et-al.-2024 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Ji-et-al.-2024-RealTalk #Wang-et-al.-2025-READ #Qi-et-al.-2025-ChatAnyone #Wang-et-al.-2025-OmniTalker | 说明模型或系统是否具备交互部署潜力;论文 FPS 不能替代端到端 p95/p99 压测 |
实时数字人的算力问题分两类:训练成本和推理成本。训练成本决定团队能否自研或微调;推理成本决定产品能否在线服务。LivePortrait 用约 69M frames 提升泛化和控制能力,这意味着它的训练规模不是普通业务团队轻易复刻的;EMO 构建超过 250 小时多样音视频数据,说明高表现力扩散路线的数据和训练成本很高;OmniTalker 约 0.8B 模型并强调多阶段训练和大规模多模态数据;EGSTalker 虽然每个身份只需 3—5 分钟训练视频,但这仍然意味着每个主播要走专人建模流程。#Guo-et-al.-2024-LivePortrait #Tian-et-al.-2024 #Wang-et-al.-2025-OmniTalker #Zhu-et-al.-2025-EGSTalker
推理成本更接近业务现实。VASA-1 报告 512×512 up to 40 FPS;MuseTalk 报告 256×256 30 FPS on V100;LivePortrait 报告 12.8ms on RTX 4090;RealTalk 报告 30 FPS on V100;ChatAnyone 报告 512×768 up to 30fps on 4090;OmniTalker 报告 single RTX 4090 上 25 FPS;READ 把目标定义为 real-time diffusion-transformer 并声称达到 1:1 time ratio。这些数字来自不同硬件、分辨率、任务定义和实现环境,不能直接横排冠军。#Xu-et-al.-2024 #Zhang-et-al.-2024-MuseTalk #Guo-et-al.-2024-LivePortrait #Ji-et-al.-2024-RealTalk #Qi-et-al.-2025-ChatAnyone #Wang-et-al.-2025-OmniTalker #Wang-et-al.-2025-READ
Meng et al. 还提醒,large-angle head pose、data bias、temporal consistency,以及大型预训练模型带来的 adaptability 和 computational requirements,都会限制 talking head synthesis 的真实可用性。对实时数字人来说,这些不是论文讨论区里的边角问题:侧脸、遮挡、低码率、特定人群数据不足、模型显存和冷启动时延,都会直接变成线上失败案例。#Meng-et-al.-2024-THSTaxonomy
| 方法 | 任务定位 | 训练/数据成本 | 已披露推理信息 | 工程解读 |
|---|---|---|---|---|
| VASA-1 | 单图语音驱动 talking face | 训练细节需看论文;截至 2026-06-08 未见官方公开代码/权重 | 512×512 up to 40 FPS,negligible starting latency | 研究标杆,短期不可直接依赖 |
| MuseTalk | 视频配音/唇部 latent inpainting | 两阶段训练,任务窄;8×H20 训练约 90 小时 | 256×256,30 FPS on V100 | 适合 PoC 和配音链路 |
| LivePortrait | motion-driven portrait animation | 约 69M frames | 12.8ms on RTX 4090 | 很适合作为动画引擎,需要 audio-to-motion |
| RealTalk | 实时 audio-driven face generation | 3D facial prior + identity alignment | 30 FPS on NVIDIA V100 | 局部真实感和实时性折中 |
| ChatAnyone | 上半身实时 portrait video | 层级 motion diffusion + GAN 生成器 | 512×768 up to 30fps on 4090 | 代表头部到上半身交互的升级 |
| OmniTalker | text-driven speech + video | 约 0.8B,多模态训练 | single RTX 4090 上 25 FPS | 减少 TTS→THG 级联延迟和风格错配 |
| EGSTalker | 3DGS 专人 talking head | 每身份 3—5 分钟训练视频 | 强调高推理速度,具体部署需复测 | 固定形象友好,冷启动不友好 |
flowchart TD
A["用户输入音频 / 文本"] --> B["VAD / ASR / TTS / prosody"]
B --> C["motion prediction"]
C --> D{"avatar backend"}
D --> E["lip editing
Wav2Lip / MuseTalk / RealTalk"]
D --> F["portrait animation
LivePortrait / Ditto"]
D --> G["latent diffusion
VASA-1 / READ"]
D --> H["专人渲染
NeRF / 3DGS"]
E --> I["postprocess / super-resolution"]
F --> I
G --> I
H --> I
I --> J["encode / WebRTC"]
J --> K["client buffer / playback"]
K --> L["p95 / p99 体验延迟"]
图 5:端到端实时链路。模型 FPS 只覆盖其中一段,产品体验由整条链路决定。
| 论文/项目 | 路线 | 输入条件 | 数据/算力锚点 | 优势 | 主要限制 |
|---|---|---|---|---|---|
| Wav2Lip | lip-sync expert | 视频/图像 + 音频 | LRS2 等口型同步任务 | 口型同步强,可做模块 | 不是完整表情/头动数字人 |
| SadTalker | 3DMM motion coefficients | 单图 + 音频 | CVPR 2023 baseline | 可解释、单图友好 | 细节和实时性上限有限 |
| EMO | Audio2Video diffusion | 单图 + 音频 | 超过 250 小时多语种音视频 | 表现力强,可说可唱 | 多步扩散不适合低延迟默认方案 |
| AnimateAnyone | pose-to-video diffusion | 参考图 + pose sequence | 角色动画任务 | 身份保持和全身姿态控制强 | 不是 audio-driven 实时数字人 |
| VASA-1 | face latent dynamics | 单图 + 音频 | 512×512 up to 40 FPS;截至 2026-06-08 未见官方公开代码/权重 | 质量与实时性标杆 | 商用不可直接依赖 |
| MuseTalk | latent inpainting dubbing | 视频/人脸区域 + 音频 | 256×256 30 FPS on V100 | 实时配音友好 | 任务是改嘴,不是完整冷启动数字人 |
| LivePortrait | implicit keypoints | 源图 + motion signal | 69M frames,12.8ms on 4090 | 高效可控肖像动画 | 需要驱动运动或 audio-to-motion |
| Ditto | motion-space diffusion | 单图 + 音频 | 项目页提供 Code 入口;流式推理需结合仓库与 license 复核 | 可控、实时、工程可复现 | 自然性和 renderer 依赖仍需评测 |
| READ | 实时 diffusion transformer | 参考图 + speech | 1:1 time ratio,temporal VAE + SpeechAE | 把扩散推进实时框架 | 新方法,需复现和商用评估 |
| ChatAnyone | hierarchical motion diffusion | 人像 + 音频 + 可选风格 | 512×768 up to 30fps on 4090 | 覆盖上半身、手势和风格控制 | 系统复杂度高 |
| OmniTalker | text-driven multimodal | 文本 + 参考视频 | 约 0.8B,single RTX 4090 上 25 FPS | 减少 TTS 与 THG 级联问题 | 端到端系统落地仍需验证 |
| SyncAnimation | NeRF upper-body | 音频 + 专人资产 | RTX 4090 上 41 FPS;面向实时上半身 talking avatar | 头、唇、上半身同步 | 专人建模和训练成本 |
| EGSTalker | 3DGS deformation | 3—5 分钟训练视频 + 音频 | 3DGS + KAN + ESAA | 固定身份高效渲染 | 不适合任意身份冷启动 |
如果目标是最快 PoC
先选局部或固定形象路线。已有视频配音、客服头像、直播口型同步,可以优先验证 MuseTalk、Wav2Lip、RealTalk 或 Ultralight-Digital-Human。PoC 的目标不是一次性追求最高表现力,而是测端到端链路:音频输入、模型推理、后处理、编码、WebRTC、客户端播放、p95 延迟和失败恢复。#Zhang-et-al.-2024-MuseTalk #Prajwal-et-al.-2020 #Ji-et-al.-2024-RealTalk #Ultralight-Digital-Human-GitHub
如果目标是产品化数字人
更稳妥的架构是模块化:用 lip-sync backend 保证嘴型,用 LivePortrait/Ditto 类 motion backend 补表情头动,用 WebRTC/缓存/异步队列保证实时性。这样可以逐步替换模块,而不是被一个未开源模型或一个高成本 diffusion pipeline 锁死。#Guo-et-al.-2024-LivePortrait #Li-et-al.-2025-Ditto #CyberVerse-GitHub
如果目标是长期自研
应关注 latent dynamics、motion-space diffusion、real-time diffusion transformer、text-driven unified generation 和 upper-body interaction。VASA-1、READ、Ditto、OmniTalker、ChatAnyone 是更值得跟踪的研究方向;EMO 和 AnimateAnyone 则帮助判断高表现力视频生成的上限。长期跟踪论文池时,也可以把 Awesome Talking Head Generation 这类维护型列表作为入口,用来发现新论文、项目页和代码仓库,但关键结论仍应回到原始论文与官方实现核验。#Xu-et-al.-2024 #Wang-et-al.-2025-READ #Li-et-al.-2025-Ditto #Wang-et-al.-2025-OmniTalker #Qi-et-al.-2025-ChatAnyone #Tian-et-al.-2024 #Hu-et-al.-2023 #Awesome-Talking-Head-Generation-GitHub
| 业务场景 | 优先路线 | 不建议优先 | 原因 |
|---|---|---|---|
| 视频配音/换嘴 | Wav2Lip、MuseTalk、RealTalk | 全身扩散生成 | 局部任务更快、更便宜、更可控 |
| 固定客服/主播 | Ultralight、NeRF/3DGS、LivePortrait 后端 | 任意身份冷启动 | 固定身份可以用训练成本换稳定性 |
| 单图互动头像 | VASA-1 类 latent、Ditto、READ | 纯 Wav2Lip | 需要口型以外的表情头动 |
| 上半身虚拟主播 | ChatAnyone、AnimateAnyone 思路、SyncAnimation | 只修嘴方案 | 身体节奏和手势会影响真实感 |
| LLM 视频助手 | OmniTalker 或模块化 LLM→TTS→THG | 只看离线视频质量 | 交互系统要控制延迟和风格一致性 |
问题一:口型对了,脸为什么还是假
口型同步只是最低门槛。真实说话包含眼动、眉毛、脸颊、下巴、头部微动和停顿节奏。Wav2Lip 类路线能解决局部嘴型,但如果其他区域静止,用户仍会感觉“嘴在动,脸没说话”。这也是 VASA-1、Ditto、ChatAnyone 这类方法继续建模整体动态的原因。#Prajwal-et-al.-2020 #Xu-et-al.-2024 #Li-et-al.-2025-Ditto #Qi-et-al.-2025-ChatAnyone
问题二:实时扩散如何保持长时一致性
扩散模型擅长高质量生成,但长时视频会遇到身份漂移、表情漂移、clip boundary 和延迟问题。READ 的 asynchronous noise scheduler、EMO 的 Motion Frame、Ditto 的 streaming inference 都是在处理“连续生成”而不是“生成一个短 demo”。未来的关键不是单次生成多漂亮,而是长会话里是否稳定。#Wang-et-al.-2025-READ #Tian-et-al.-2024 #Li-et-al.-2025-Ditto
问题三:语义动作如何从文本和语音中来
手势不是随机摆动。点头、摊手、强调、停顿和目光方向应当与语义和情绪一致。ChatAnyone 开始把上半身动作纳入实时数字人,但“从 LLM 文本和语音 prosody 生成语义手势”仍然没有形成通用标准。#Qi-et-al.-2025-ChatAnyone #Hu-et-al.-2023
问题四:数据集缺少业务分布
公开视频数据集通常不等于客服、直播、教育、会议和陪伴场景。多语种、方言、快语速、笑声、打断、沉默、侧脸、遮挡、低码率、移动端摄像头和弱网都会暴露问题。Meng et al. 已经把 large-angle head pose、data bias 和 temporal consistency 列为关键挑战;Zhang et al. 的 2021—2025 longitudinal analysis 也显示,训练集与测试集开始分离,评测正在从 IID holdout 走向更强调泛化、expressiveness 和 controllability 的协议。实时数字人的测试集因此必须包含业务分布,而不能只复用公开视频 benchmark。#Meng-et-al.-2024-THSTaxonomy #Rakesh-et-al.-2025-THGSurvey #Zhang-et-al.-2026-PracticeSurvey
问题五:合规和授权不是发布前才处理
单图和语音驱动天然有 deepfake 风险。业务设计时必须默认需要肖像授权、声音授权、水印、生成标识、滥用检测和日志审计。CyberVerse 这类系统框架还要注意 GPLv3 等许可证约束;开源模型的代码许可、权重许可和训练数据许可也要分别审查。#CyberVerse-GitHub
推荐路线
- 第一阶段:实时链路 PoC。选择 MuseTalk / Wav2Lip / RealTalk / Ultralight 这类任务窄、可运行、延迟可测的方案,先验证端到端链路。
- 第二阶段:补全脸部动态。引入 LivePortrait、Ditto 或自研 audio-to-motion,把嘴型、表情、头动、眼动和历史状态连接起来。
- 第三阶段:走向交互体。跟踪 VASA-1、READ、OmniTalker、ChatAnyone、3DGS/NeRF,把语义、声音、上半身和流式系统统一起来。
这篇 survey 的最终结论是:实时数字人已经具备试点价值,但还没有一个“单图 + 语音 + 高清 + 情绪 + 手势 + 商用合规 + 低成本 + 低延迟”的通用开箱模型。最稳妥的做法是把系统拆成可替换模块,并对每个模块建立独立评测:口型同步、身份保持、表情自然度、头动稳定性、上半身动作、端到端延迟、并发吞吐、许可证和授权。这样既能利用开源项目快速推进,也能为长期自研保留接口。
参考来源
- Song, Y. et al. (2023). A Survey on Talking Head Generation. Journal of Computer-Aided Design & Computer Graphics. DOI:10.3724/SP.J.1089.2023.19782
- Meng, M., Zhao, Y., Zhang, B., Zhu, Y., Shi, W., Wen, M., & Fan, Z. (2024). A Comprehensive Taxonomy and Analysis of Talking Head Synthesis: Techniques for Portrait Generation, Driving Mechanisms, and Editing. arXiv:2406.10553
- Zhang, Z. et al. (2026). Talking-Head Generation in Practice. OpenReview
- Rakesh, V. K. et al. (2025). Advancing Talking Head Generation: A Comprehensive Survey of Multi-Modal Methodologies, Datasets, Evaluation Metrics, and Loss Functions. arXiv:2507.02900
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. ACM Multimedia 2020. arXiv:2008.10010
- Zhang, W. et al. (2023). SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. CVPR 2023. arXiv:2211.12194
- Tian, L. et al. (2024). EMO: Emote Portrait Alive — Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions. arXiv:2402.17485
- Hu, L. et al. (2023). Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation. arXiv:2311.17117
- Xu, S. et al. (2024). VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time. NeurIPS 2024. arXiv:2404.10667
- Zhang, Y. et al. (2024). MuseTalk: Real-Time High-Fidelity Video Dubbing via Spatio-Temporal Sampling. arXiv:2410.10122
- Guo, J. et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv:2407.03168
- Ji, X. et al. (2024). RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network. arXiv:2406.18284
- Li, T. et al. (2025). Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis. Project page
- Wang, H. et al. (2025). READ: Real-time and Efficient Asynchronous Diffusion for Audio-driven Talking Head Generation. arXiv:2508.03457
- Qi, J. et al. (2025). ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model. arXiv:2503.21144
- Wang, Z. et al. (2025). OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication. arXiv:2504.02433
- Liu, Y. et al. (2025). SyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation. arXiv:2501.14646
- Zhu, T. et al. (2025). EGSTalker: Real-Time Audio-Driven Talking Head Generation with Efficient Gaussian Deformation. arXiv:2510.08587
- Harlan Hong. Awesome Talking Head Generation. GitHub repository
- Anliyuan. Ultralight-Digital-Human. GitHub repository
- Jin, C. et al. (2026). SentiAvatar: Towards Expressive and Interactive Digital Humans. arXiv:2604.02908
- Huang, J. et al. (2025). Live Avatar: Real-Time Streaming Digital Human Generation with Foundation Video Models. 本站精读
- CyberVerse. Realtime digital human agent framework. GitHub repository