MuseTalk
MuseTalk 的核心任务是 one-shot video dubbing:给定一段已有视频和一段新音频,只修改嘴部相关区域,让人物像是在说新的内容,同时尽量保留原视频里的身份、头动、眼动、身体、背景和镜头运动。论文特别区分了 talking head generation 与 video dubbing:前者常从单张图和音频生成整段说话视频,模型会自行决定头动和眼动;后者则是 Video-to-Video,目标是在保留原视频动态的前提下改写唇形。#Zhang-et-al.-2024-MuseTalk
这个任务的工程价值很直接:影视配音、多语言课程、短视频本地化、客服头像和会议 avatar 都可能已经有原始视频或固定形象,真正需要低延迟生成的是“嘴部如何跟新音频同步”。如果用大扩散模型整帧生成,视觉上限高,但多步 denoising 很难低成本实时;如果用传统 GAN 或像素空间换嘴,速度快,但容易牺牲牙齿细节、身份一致性和边界质量。MuseTalk 的判断是:把生成范围收缩到脸部 ROI,再把生成空间压到 VAE latent,用单步 U-Net 做 inpainting,可以在质量与实时性之间取得更实用的折中。#Zhang-et-al.-2024-MuseTalk #MuseTalk-GitHub

MuseTalk 论文里最值得注意的不是“用了 U-Net”这种表层架构,而是它把局部换嘴的训练冲突讲清楚了。视频配音需要同时满足三件事:第一,生成区域要清晰,尤其是牙齿、嘴角和唇边;第二,嘴型必须跟音频同步,静音时闭嘴,说话时开合正确;第三,身份不能漂移,不能把参考帧的嘴型、肤色或局部纹理错误复制到目标帧。#Zhang-et-al.-2024-MuseTalk
问题在于,这三件事对应的训练信号并不天然一致。只用重建损失,模型会倾向于平均化,牙齿和嘴角被抹平;加入 adversarial loss,判别器会推动局部纹理更真实,但模型可能偷懒复制参考图里已经存在的嘴型;加入 SyncNet loss,模型更愿意根据音频调整嘴部开合,但视觉边界可能变糊。论文观察到,如果在随机初始化或能力不足的模型上直接联合优化 adversarial loss 与 sync loss,训练会不稳定,且 SyncNet loss 难以收敛。#Zhang-et-al.-2024-MuseTalk
视频配音的局部生成形式
给定参考帧 \(I_t^{ref}\)、源帧/遮挡帧 \(I_t^s\)、音频特征 \(A_t^{mel}\) 和嘴部区域 mask,MuseTalk 学习一个单步生成器 \(G\),在 VAE latent 空间输出嘴部相关区域,再融合回原视频:
这不是扩散模型的多步采样,而是 latent inpainting 的单步预测。
| 训练目标 | 带来的好处 | 单独使用的风险 | MuseTalk 的处理 |
|---|---|---|---|
| 重建 / perceptual loss | 稳定、保身份、学基础纹理 | 牙齿与嘴角过度平滑 | 放在第一阶段,先训练 facial abstraction |
| SyncNet loss | 推动嘴型跟音频同步 | 嘴部边界和牙齿可能变糊 | 第二阶段引入,并用 DMS 避免偷看嘴型 |
| GAN loss | 提升清晰度和真实感 | 可能复制参考图嘴型,忽视音频 | 第二阶段引入 face/lip 两个判别器 |
这就是 MuseTalk 设计两阶段训练和 spatio-temporal sampling 的根本原因:先让模型学会“像一个人脸局部 inpainting 模型”,再让它在更强的视觉和同步目标下微调;同时通过采样策略切断训练数据里的捷径,迫使模型真正从音频学习嘴部运动。#Zhang-et-al.-2024-MuseTalk
MuseTalk 的实现采用预训练 VAE 和来自 Latent Diffusion 的 multimodal U-Net 结构。视频帧先被裁剪成脸部 ROI,并 resize 到 \(256\times256\);图像由冻结 VAE 编码到 latent;音频由轻量 Whisper-Tiny 编码;音频 embedding 经重排后通过 cross-attention 融入 U-Net。官方 README 也强调:虽然结构类似 Stable Diffusion 的 U-Net,但 MuseTalk 不是 diffusion model,它不做多步去噪,而是在 latent space 中单步 inpainting。#Zhang-et-al.-2024-MuseTalk #MuseTalk-GitHub
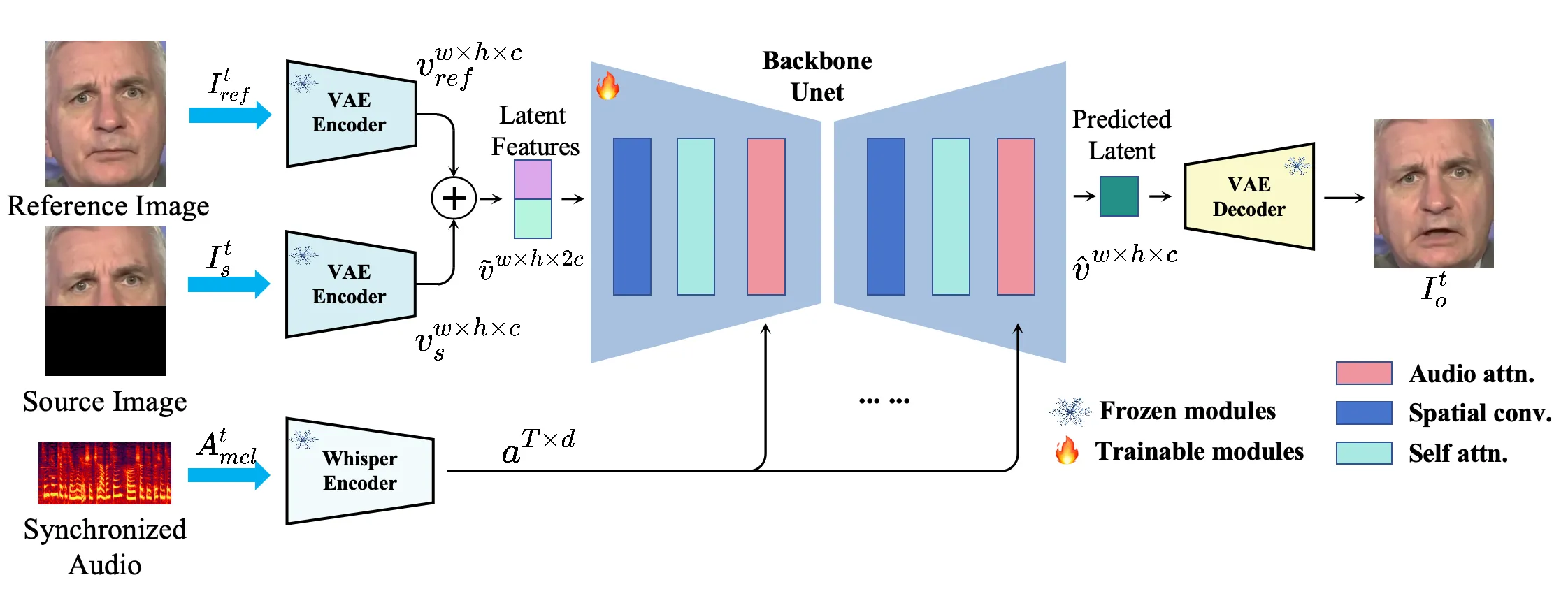
Audio-visual fusion:音频不是简单拼接,而是 cross-attention 条件
MuseTalk 的音频侧使用 Whisper-Tiny,而不是更重的语音大模型。这样做有两个好处:一是语音特征足够表达音素和短时口型变化,二是推理成本可控。图像侧的 U-Net 借用 Stable Diffusion 风格结构,把音频 embedding 作为 encoder hidden states 注入 cross-attention。这样,生成器在每个空间位置预测 latent 时都可以访问当前音频上下文。#Zhang-et-al.-2024-MuseTalk
用更直观的话说,MuseTalk 没有让模型“重新拍一遍视频”,而是给它一个局部修图任务:原视频已经告诉你这个人是谁、头怎么动、光怎么打、背景是什么;音频告诉你嘴应该怎么动;U-Net 只需要在压缩后的 latent 空间里把这两者对齐。这个设定解释了它为什么能比整帧扩散更快,也解释了它为什么不负责生成新头动和上半身动作。
flowchart LR V["输入视频 / 图像帧"] --> C["人脸检测与 ROI 裁剪"] C --> E["VAE encode: z_s / z_ref"] A["输入音频"] --> W["Whisper-Tiny audio encoder"] W --> P["audio positional / feature projection"] E --> U["Multimodal U-Net
single-step latent inpainting"] P --> U U --> D["VAE decode"] D --> B["Face parsing / blending"] B --> O["配音后视频"]
为什么 latent inpainting 比像素换嘴更合适
像素空间直接生成嘴部区域看似简单,但模型要同时处理高频纹理、边界融合、口腔结构和音频同步,训练很容易不稳。latent 空间把 \(256\times256\) 的视觉细节压缩到更低维的表示中,让 U-Net 学到更抽象的嘴部形状和局部纹理。论文的实验结果显示,MuseTalk 在 HDTF 上 FID 为 6.52、CSIM 为 0.86,在 VFHQ 上 FID 为 7.07、CSIM 为 0.85,视觉质量和身份保持都优于多种 GAN 基线,并且保留 30 FPS 实时潜力。#Zhang-et-al.-2024-MuseTalk
MuseTalk 的训练分成两个阶段。第一阶段叫 Facial Abstract Pretraining,目标是让模型先学会稳定的人脸局部 inpainting;第二阶段叫 Lip-Sync Adversarial Finetuning,目标是在已有基础能力上加入 adversarial loss 与 SyncNet loss,让嘴部更清晰、更同步。论文训练配置很具体:第一阶段使用 8 张 NVIDIA H20 GPU,batch size 为每卡 32,训练 200,000 steps,AdamW 学习率 \(2\times10^{-5}\),耗时约 60 小时;第二阶段继续训练 20,000 steps,每卡 batch size 降到 2,学习率 \(5\times10^{-6}\),耗时约 30 小时。#Zhang-et-al.-2024-MuseTalk
第一阶段:Facial Abstract Pretraining
第一阶段不急着加入 GAN 和 SyncNet,而是使用更稳定的重建损失。论文给出的目标函数是:
其中 \(I_t^o\) 是生成图,\(I_t^{gt}\) 是真实帧,\(V\) 是 VGG19 feature extractor,\(\lambda_{vgg}=0.01\)。只用 \(L_1\) 容易把牙齿和嘴角抹平,perceptual loss 则帮助模型学习高频过渡纹理。#Zhang-et-al.-2024-MuseTalk
Informative Frame Sampling:让训练更像推理
过去很多 GAN-based video dubbing 方法随机选参考图 \(I_t^{ref}\),但训练时参考图和 ground truth 往往姿态不同;推理时参考图和目标帧却更接近同一视频当前帧。这会造成 train-inference gap。MuseTalk 的 Informative Frame Sampling 先基于 pose 和 lip similarity 找候选帧,再选择更有信息量的参考源对。实验里,候选比例 \(k\) 取视频长度的 50% 时效果最好;随机采样只有 FID 9.24、CSIM 0.79、LSE-C 4.41,而 IFS 50% 达到 FID 6.52、CSIM 0.86、LSE-C 6.53。#Zhang-et-al.-2024-MuseTalk
第二阶段:Lip-Sync Adversarial Finetuning
第二阶段加入两个判别器:一个看整张脸 \(D_{face}\),一个看嘴部区域 \(D_{lip}\)。嘴部判别器的输入不是 resize 后的小块,而是基于 lip landmarks 扩展到固定大小的区域,因为 resize 会破坏嘴部形状。对抗损失写成:
同时,SyncNet loss 使用 \(N=16\) 对音频和图像帧计算余弦相似度:
最终第二阶段目标为:
其中 \(\lambda_{adv}=0.1\),\(\lambda_{sync}=0.05\)。#Zhang-et-al.-2024-MuseTalk
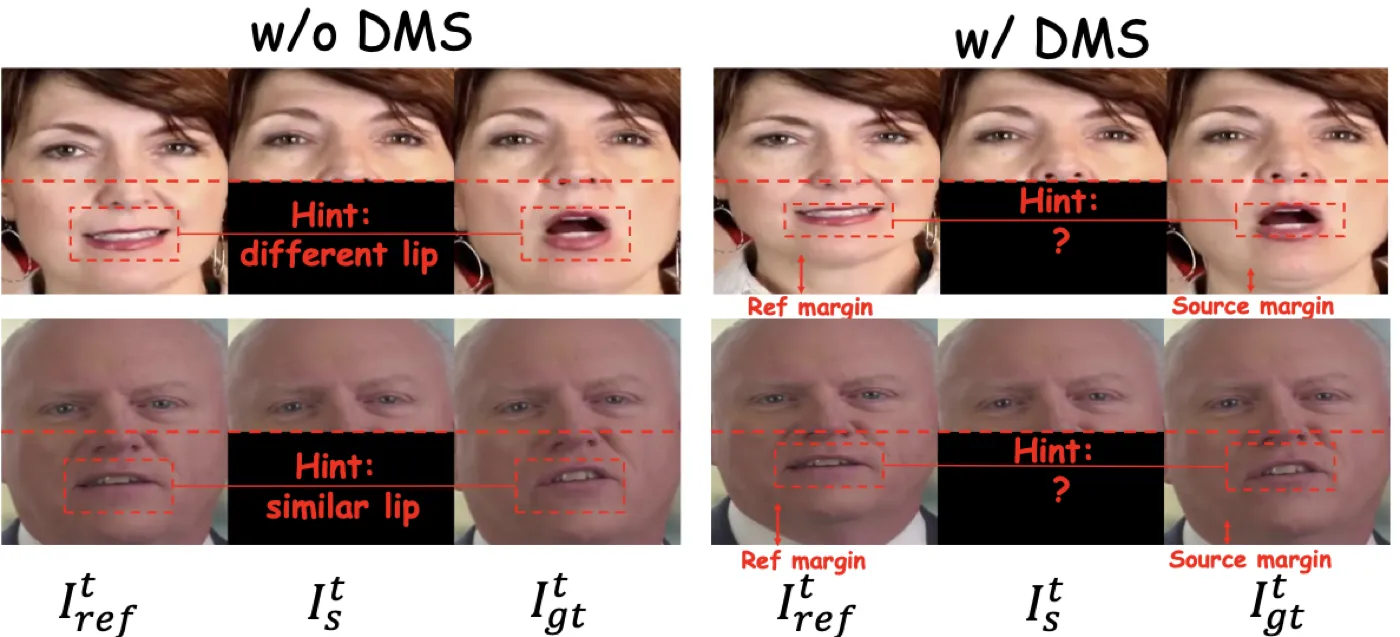
Dynamic Margin Sampling:堵住训练数据里的“提示泄漏”
DMS 是本文最有工程味的设计。论文观察到,如果参考帧、源帧和目标帧的裁剪区域存在固定几何关系,模型可以通过鼻子到下巴边界的位置推断目标嘴巴开合,而不是从音频学习嘴型。这会导致模型复制参考嘴型,特别是参考图露齿时更明显。DMS 在裁剪 \(I_t^{ref}\) 和 \(I_t^{gt}\) 时独立引入随机 chin margin,让未遮挡区域不再可靠透露嘴部开合,从而迫使模型依赖音频。消融显示,独立且适中的 \(\mathcal{N}(10,10)\) margin 优于共享 margin 或过大的 \(\mathcal{N}(20,20)\) margin。#Zhang-et-al.-2024-MuseTalk
推理时,MuseTalk 的链路非常工程化。官方代码会先抽帧或读取图像目录,检测人脸与 bounding box,把脸部区域裁成 \(256\times256\),用 VAE 编码成 latent;音频侧用 Whisper 提取特征,并按视频 fps 切成 chunks;随后 datagen 把音频 chunk 与图像 latent 组成 batch,U-Net 在 timestep 0 上单步预测 latent,VAE decode 回图像,最后再把生成脸部区域 resize 回原 bbox,用 face parsing 和 blending 融合到原帧,并通过 ffmpeg 合成视频。#MuseTalk-GitHub
| 步骤 | 代码/模块 | 作用 | 实时性影响 |
|---|---|---|---|
| 抽帧与 fps | ffmpeg, get_video_fps | 把输入视频变成帧序列 | 离线预处理可缓存,实时链路需流式化 |
| 人脸检测与裁剪 | get_landmark_and_bbox | 定位 ROI,保存 bbox 坐标 | 首次耗时,代码支持缓存坐标 |
| 图像 latent | vae.get_latents_for_unet | 把 256² crop 压到 U-Net latent | 可预计算或随帧缓存 |
| 音频特征 | AudioProcessor, WhisperModel | 得到和视频 fps 对齐的音频 chunk | 决定音画同步窗口 |
| 单步生成 | unet.model(..., timesteps=0) | 预测嘴部 latent | 核心模型耗时,没有多步扩散 |
| 融合输出 | FaceParsing, get_image, ffmpeg | 贴回原帧并编码视频 | 端到端延迟还受后处理/编码影响 |
官方 README 报告 MuseTalk 1.5 可以在 NVIDIA Tesla V100 上达到 30fps+,论文也报告在 256×256 resolution、preloaded data 的条件下达到 30 FPS。这里要特别注意“preloaded data”这个边界:论文数字证明模型主体具备实时潜力,但真实产品还要把音频采集、VAD/TTS、网络传输、视频编码、客户端缓冲和并发调度算进去。#Zhang-et-al.-2024-MuseTalk #MuseTalk-GitHub
30 FPS 不等于端到端 33ms
MuseTalk 的 30 FPS 主要说明局部生成模块可以实时;如果接到在线数字人系统,还需要单独压测音频前处理、坐标检测、VAE 编解码、融合、视频编码、WebRTC 和客户端播放缓冲。
从系统选型看,MuseTalk 适合作为“已有视频/固定头像 + 新音频”的 lip-sync backend。它不适合单独承担语义手势、上半身动作、眼神意图或主动头动生成。如果需要完整交互数字人,可以把它放在更大系统里:TTS 生成音频,MuseTalk 负责嘴部同步,LivePortrait/Ditto/专人 3DGS 负责更完整的动作层,最后统一进入编码和推流链路。
实时链路预算:30 FPS 之外还要看哪些段
| 链路段 | 能否缓存 | MuseTalk 里的对应模块 | 工程风险 |
|---|---|---|---|
| 人脸检测与 bbox | 固定视频可缓存 | get_landmark_and_bbox / saved coord | 检测失败或 bbox 偏移会直接破坏融合边界 |
| VAE encode | 固定输入视频可预计算 | vae.get_latents_for_unet | 实时摄像头输入则不能完全离线 |
| 音频特征 | 离线音频可预切 chunk | AudioProcessor / Whisper-Tiny | 在线 TTS 或麦克风输入会引入首帧等待 |
| U-Net forward | 不可缓存 | unet.model(..., timesteps=0) | 这是核心生成开销,但没有多步扩散采样 |
| VAE decode 与融合 | 不可完全缓存 | VAE decode / face parsing / blending | 边缘、牙齿、肤色和运动模糊会暴露 artifact |
| 编码与传输 | 取决于系统 | ffmpeg / WebRTC 外围链路 | 论文 FPS 不包含完整 p95/p99 播放体验 |
MuseTalk 的实验使用 HDTF 与 VFHQ。论文说明原始数据经过过滤,最终训练数据约 24 小时;补充材料给出过滤前后时长:HDTF 从 15.75 小时过滤到 15.32 小时,VFHQ 从 18.36 小时过滤到 8.43 小时。过滤原因很实际:VFHQ 这类数据里可能有人在画面中不说话而音频来自画外人,这种“脏数据”会直接破坏 video dubbing 训练。评测时随机选择 HDTF 的 26 个视频和 VFHQ 的 10 个视频,其余用于训练;测试协议模拟真实场景,视频和音频独立来源,参考图来自当前帧。#Zhang-et-al.-2024-MuseTalk
| 配置项 | MuseTalk 论文披露 |
|---|---|
| 训练数据 | HDTF + VFHQ,过滤后总时长约 24 小时 |
| 测试数据 | HDTF 26 个视频,VFHQ 10 个视频 |
| 输入分辨率 | 脸部 ROI 裁剪并 resize 到 \(256\times256\) |
| 训练硬件 | 8× NVIDIA H20 GPU |
| 第一阶段 | 200k steps,每卡 batch size 32,AdamW,lr \(2\times10^{-5}\),约 60 小时 |
| 第二阶段 | 20k steps,每卡 batch size 2,lr \(5\times10^{-6}\),约 30 小时 |
| 损失权重 | \(\lambda_{vgg}=0.01\),\(\lambda_{adv}=0.1\),\(\lambda_{sync}=0.05\) |
| 推理硬件 | NVIDIA V100,256×256,preloaded data,30 FPS |
| CPU/内存 | 论文未披露 |
主实验:视觉质量与身份保持最强,同步分数不是第一
在 HDTF 上,MuseTalk 的 FID 为 6.52,CSIM 为 0.86,LSE-C 为 6.53;在 VFHQ 上,FID 为 7.07,CSIM 为 0.85,LSE-C 为 4.77。对比 Wav2Lip,HDTF FID 从 11.55 降到 6.52,VFHQ FID 从 14.99 降到 7.07;对比 LatentSync,MuseTalk 的视觉质量更好,但 LSE-C 略低,LatentSync 在 HDTF 上 LSE-C 为 7.90。论文的解释是,LatentSync 这类 diffusion 方法 lip-sync 很强但非实时;MuseTalk 则更强调视觉清晰度、身份保持和实时性的平衡。#Zhang-et-al.-2024-MuseTalk
| 方法 | 类型 | HDTF FID↓ | HDTF CSIM↑ | HDTF LSE-C↑ | VFHQ FID↓ | VFHQ CSIM↑ | VFHQ LSE-C↑ |
|---|---|---|---|---|---|---|---|
| Wav2Lip | GAN | 11.55 | 0.84 | 7.42 | 14.99 | 0.82 | 5.84 |
| VideoRetalking | GAN | 11.29 | 0.80 | 7.59 | 15.83 | 0.79 | 6.13 |
| DI-Net | GAN | 6.94 | 0.80 | 5.96 | 15.03 | 0.71 | 3.37 |
| IP-LAP | GAN | 10.16 | 0.86 | 4.47 | 10.95 | 0.85 | 3.88 |
| LatentSync | Diffusion | 8.41 | 0.84 | 7.90 | 9.89 | 0.82 | 6.79 |
| MuseTalk | GAN | 6.52 | 0.86 | 6.53 | 7.07 | 0.85 | 4.77 |
表注:上表聚焦论文 Table 1 中与开源/常见研究 baseline 相关的对比项;原论文还包含 SyncLab 与 Ground Truth 行。SyncLab 的 LSE-C 较高,Ground Truth 用作真实视频参考,不应与可部署模型直接混为一类。

用户研究与消融
论文还做了用户研究:使用来自 HDTF 和 VFHQ 的 36 对不同步音视频,10 名参与者从视觉质量、身份一致性和 lip-sync accuracy 三方面按 1 到 5 分评分,总计 360 个评分。方法名被隐藏,视频顺序随机打乱,以减少偏置。结果显示,MuseTalk 在视觉质量和身份一致性上得分最高;lip-sync quality 高于多数实时/GAN 基线,但低于 LatentSync,因此更准确的结论是“视觉质量、身份保持和实时性折中更强”,而不是同步分数全面第一。#Zhang-et-al.-2024-MuseTalk

消融结论也很清楚:IFS 的 \(k=50\%\) 在 FID、CSIM 和 LSE-C 上最好;DMS 中独立、适中的随机 margin 最好。过大的 margin 会让模型过度关注背景并产生 artifact;共享 margin 会重新引入“鼻子/下巴位置提示嘴型”的信息泄漏。换句话说,MuseTalk 的性能不是单靠更大模型堆出来的,而是靠任务设定、训练阶段和采样策略共同稳定住。#Zhang-et-al.-2024-MuseTalk
官方仓库 TMElyralab/MuseTalk 当前包含推理代码、实时推理代码、训练代码和权重下载说明。README 写明 MuseTalk 1.5 的 inference codes、training codes 和 model weights 均已开放,并推荐 Python 3.10、CUDA 11.7、PyTorch 2.0.1、MMLab 组件和 FFmpeg。仓库主许可证为 MIT,这让它比很多只放 demo 或非商用权重的项目更容易进入 PoC,但商用时仍要单独审查依赖、模型权重、输入素材肖像权和声音权。#MuseTalk-GitHub #MuseTalk-License
| 路径 | 职责 | 论文对应关系 |
|---|---|---|
scripts/inference.py | 离线视频/图片推理,抽帧、音频特征、latent 生成、融合和编码 | Inference Pipeline |
scripts/realtime_inference.py | 实时推理线程、队列、流式处理和帧输出 | 实时部署实现 |
train.py | 训练入口 | 两阶段训练与损失组合 |
musetalk/models/unet.py | 条件 U-Net 主体 | latent inpainting generator |
musetalk/models/vae.py | VAE 编解码封装 | VAE latent space |
musetalk/loss/syncnet.py | 同步损失相关模块 | SyncNet loss |
musetalk/loss/discriminator.py | 判别器实现 | face/lip adversarial loss |
musetalk/data/sample_method.py | 训练采样策略 | IFS/DMS 相关逻辑 |
代码层面最值得注意的是缓存思想。scripts/inference.py 会将人脸检测得到的坐标保存成 pkl,后续可以通过 use_saved_coord 复用;输入帧列表和 latent 也会构建 cycle,用于让生成序列在视频边界更平滑。实时版则引入线程、队列和预处理材料,说明上线时不能只看 U-Net 一次 forward 的耗时,还要把检测、缓存、融合和编码串起来优化。#MuseTalk-GitHub
对复现者来说,最容易踩坑的不是模型结构,而是环境和素材。仓库依赖 PyTorch、diffusers、mmcv/mmdet/mmpose、FFmpeg、Whisper 和人脸解析组件;输入视频如果脸部检测不稳定、嘴部遮挡严重、原视频音画不同步或 bbox 位置不合适,生成结果都会明显受影响。README 还特别提到 face region center point 会显著影响结果,这与论文里的 DMS/裁剪讨论是一致的:对局部换嘴来说,ROI 定义本身就是模型质量的一部分。#MuseTalk-GitHub #Zhang-et-al.-2024-MuseTalk
MuseTalk 的定位应该非常明确:它是 lip-sync/video dubbing 路线里的强工程模块,而不是完整交互数字人的终局方案。和 Wav2Lip 相比,它用 latent inpainting 与两阶段训练显著改善视觉质量和身份保持;和 LatentSync 这类扩散 video dubbing 方法相比,它牺牲部分同步指标上限,换来单步推理和 30 FPS 实时潜力;和 VASA-1、Ditto、READ 这类 motion-space 或 latent dynamics 方法相比,它不尝试生成完整脸部动态,而是专注于局部嘴部重绘。#Zhang-et-al.-2024-MuseTalk #Prajwal-et-al.-2020 #VASA1-2024 #Ditto-2025 #Wang-et-al.-2025-READ
适合使用 MuseTalk 的场景
- 已有视频重配音:原视频质量高,只需要换语言或换音频。
- 固定头像实时 PoC:先验证音频、推理、编码和播放链路。
- 局部 lip-sync backend:作为更大数字人系统中的嘴部修复模块。
- 成本敏感场景:不希望用多步扩散模型承担整帧生成成本。
不适合把 MuseTalk 误当成完整数字人
如果业务要求单张图冷启动、主动头动、眼神意图、手势、上半身和语义情绪,MuseTalk 需要和 motion generation 或 video generation 模块组合使用;单独使用它只能保证嘴部配音链路。
容易失败的场景
| 失败场景 | 为什么会失败 | 上线前怎么测 |
|---|---|---|
| 大角度侧脸或频繁转头 | 嘴部 ROI 和融合边界不稳定,参考帧信息不足 | 加入侧脸、低头、转头样本,单独统计检测失败率 |
| 手、麦克风、字幕遮挡嘴部 | 模型会在遮挡区域错误补嘴,融合后产生突兀 artifact | 构造遮挡测试集,检查 mouth mask 与 face parsing 输出 |
| 原视频本身音画不同步 | 参考动态和新音频不一致,会放大同步错觉 | 上线前先做原视频 sync 检测和坏样本过滤 |
| 低清、强压缩或强运动模糊 | VAE latent 与融合区域缺少可恢复细节 | 按码率、分辨率、运动模糊分桶评测 FID/人工偏好 |
| bbox 中心点偏移 | 嘴部区域与原脸边界错位,牙齿和下巴最容易露馅 | 复用官方关于 face region center point 的提示,人工巡检 bbox |
这篇论文给实时数字人的启发是:工程可用性往往来自“把任务缩小”。很多高表现力模型试图一次生成完整人脸甚至全身,视觉上很吸引人,但在线系统最先需要的是稳定、可控、可压测的模块。MuseTalk 把任务限定在视频配音和嘴部 latent inpainting,于是可以把训练冲突、采样策略、ROI 裁剪、缓存和实时推理都做得更清楚。这也是它值得放进实时数字人 survey 的原因:它不是最终答案,但很适合当第一阶段 PoC 和局部能力基线。
参考来源
- Zhang, Y. et al. (2024). MuseTalk: Real-Time High-Fidelity Video Dubbing via Spatio-Temporal Sampling. arXiv:2410.10122
- TMElyralab. MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting. GitHub repository
- TMElyralab/MuseTalk LICENSE. MIT License
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. ACM Multimedia 2020. arXiv:2008.10010
- Xu, S. et al. (2024). VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time. arXiv:2404.10667
- Li, T. et al. (2025). Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis. Project page
- Wang, H. et al. (2025). READ: Real-time and Efficient Asynchronous Diffusion for Audio-driven Talking Head Generation. arXiv:2508.03457