运动空间数字人路线
上一篇讨论的是局部换嘴与视频配音:模型主要保留原视频,只在嘴部或脸部局部区域重绘。运动空间路线把问题向前推进一步:它不满足于“让嘴型同步”,而是先把人脸或头像表示成一组可生成、可控制、可渲染的运动变量,再预测这些变量随音频变化的时间序列。SadTalker 使用 3DMM motion coefficients,VASA-1 在整体面部动力学 latent space 中生成运动,Ditto 则明确提出 motion-space diffusion。#Zhang-et-al.-2023-SadTalker #Xu-et-al.-2024-VASA #Li-et-al.-2025-Ditto
阅读目标
- 前情回顾:局部换嘴稳定、便宜,但表达力被原视频动作限制。
- 本篇问题:为什么把音频先映射到运动空间,比直接生成像素或视频 latent 更适合实时 talking head。
- 下一篇衔接:运动空间路线强调低维、可控和实时;扩散基模路线则依赖通用视频生成先验,换取更高自由度和更强画面表现。
“在 motion space 里操作”不是指模型一定不用扩散,也不是指一定使用 3DMM。它描述的是一种任务分解:数字人系统先把人物外观、身份纹理和背景从“运动”里拆出去,再让生成模型只预测“怎么动”。运动可以是 3DMM 的表情系数和头姿,可以是解耦面部 latent,可以是 keypoints、expression deformation、rotation、translation 组成的 motion representation。渲染器再把这些运动变量作用到参考身份上,得到最终视频。#Zhang-et-al.-2023-SadTalker #Xu-et-al.-2024-VASA #Li-et-al.-2025-Ditto
3DMM(3D Morphable Model,三维可变形人脸模型)
3DMM 是一种用低维参数表示三维人脸的统计模型。它把“这张脸是谁”“脸上是什么表情”“头朝哪个方向”拆成几组系数:身份系数描述脸型和五官比例,表情系数描述张嘴、皱眉、微笑等形变,头姿系数描述旋转和平移。SadTalker 关注的不是重新生成整张脸,而是根据音频预测随时间变化的表情系数和头姿系数,再交给渲染器还原成视频。#Zhang-et-al.-2023-SadTalker
运动空间生成形式
给定参考身份 \(I_{ref}\)、音频 \(A_{1:T}\)、运动编码器 \(E_m\)、运动生成器 \(G_m\) 与渲染器 \(R\),motion space 路线可以抽象为:
关键点在于:生成模型的主要目标是 \(\hat{m}_{1:T}\),也就是低维运动序列,而不是完整像素帧。
| 路线 | 生成目标 | 身份与纹理 | 优势 | 主要限制 |
|---|---|---|---|---|
| 局部换嘴 | 嘴部/脸部 ROI | 来自原视频 | 稳定、便宜、易落地 | 表情、头动、手势受限 |
| 运动空间 | 表情、头姿、眼神、关键点或面部 latent | 由参考图像和渲染器保留 | 低维、实时、可控 | 上限受运动表示和渲染器限制 |
| 视频扩散基模 | 视频 latent / frames / tokens | 由视频基座和参考条件共同生成 | 表现自由度高,能生成身体和背景 | 成本高,长时稳定和实时化困难 |
这条路线的技术判断很清楚:如果业务目标是单图 talking head、实时客服头像、会议 avatar、直播助手,模型没有必要每一帧都重新生成身份纹理、头发、背景和衣服。更合理的做法是让生成模型负责运动,让渲染器负责外观。这样不仅降低计算量,也让系统更容易做控制、编辑和失败兜底。
SadTalker 是这条路线中最典型的显式表示方案。它把单图说话人生成转化为“从音频预测 3DMM 运动系数”:ExpNet 负责预测与音频强相关的表情系数,PoseVAE 负责生成与音频弱相关但影响自然度的头部姿态。两组运动系数再驱动 3D-aware face render,从源图像合成说话视频。#Zhang-et-al.-2023-SadTalker
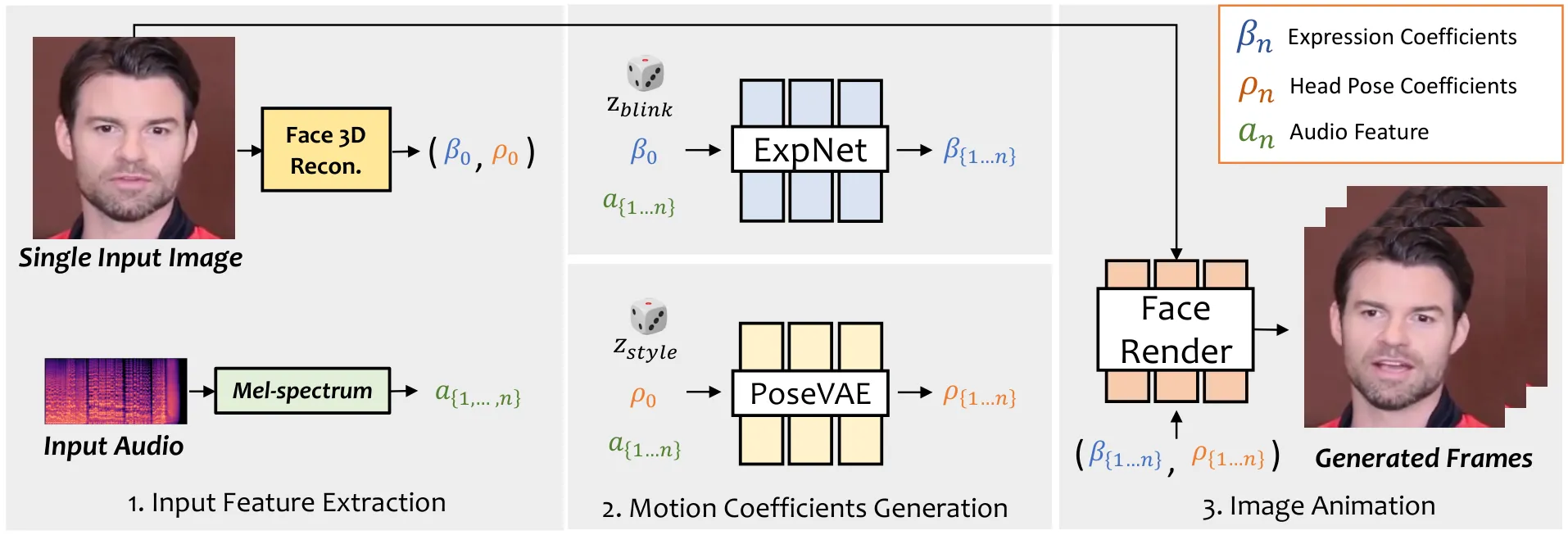
SadTalker 的关键不是“使用 3DMM”这个名词,而是它把音频驱动问题拆成两个统计性质不同的子问题。嘴型和部分表情与音素强相关,适合确定性回归;头部运动与语义、情绪、说话习惯和节奏弱相关,同一句话可以点头说,也可以摇头说,因此更适合用生成模型建模分布。这个拆分解释了为什么很多只回归嘴型的方法看起来同步却不自然:真实说话不是一条嘴唇轨迹,而是一组协同运动。
VASA-1 延续了“先生成运动,再渲染视频”的思路,但它不再满足于显式 3DMM 系数。论文提出 holistic facial dynamics generation,将唇部、非唇部表情、眼神、眨眼和头部姿态作为整体面部动力学来建模,并在面部潜在空间中用 diffusion transformer 生成运动序列。公开信息显示,VASA-1 在 512×512 分辨率下报告 40 FPS,启动延迟约 170ms。#Xu-et-al.-2024-VASA
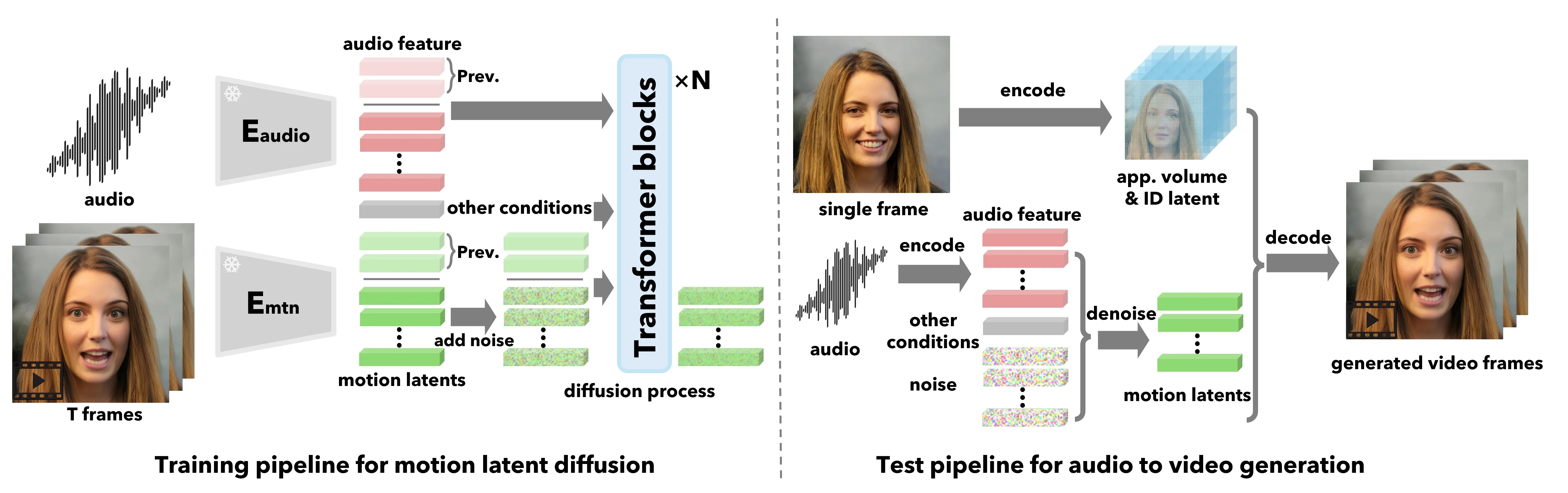
VASA-1 对 motion space 路线的推进在于“整体性”。SadTalker 把表情和头姿拆开建模,有利于可解释和稳定;VASA-1 则强调真实对话中的脸部运动不是独立部件拼接。一个人在强调某个词时,嘴部开合、眉眼、眨眼、头动距离和情绪偏移会一起变化。若每个部件分开生成,再在视频里拼起来,可能每个局部都合理,但整体节奏仍然僵硬。
| 维度 | SadTalker | VASA-1 | 变化含义 |
|---|---|---|---|
| 运动表示 | 3DMM 表情系数 + 头姿 | 整体面部动力学 latent + head movement | 从显式参数走向更高容量的潜在表示 |
| 生成目标 | 分路预测表情和头动 | 统一生成脸部整体动态 | 从解耦稳定性走向整体自然性 |
| 实时性声明 | 偏方法基线,实时性不是核心卖点 | 512×512、40 FPS、约 170ms 启动延迟 | motion space 开始支撑实时产品指标 |
| 可控性 | 系数可解释,便于局部调试 | 支持姿态、表情等控制,但表示更隐式 | 控制粒度与表示容量之间需要折中 |
这也带来新的边界:latent space 的表达能力更强,但解释性弱于 3DMM;扩散模型能生成更自然的分布,但如果没有足够快的采样和高效渲染,就会丢掉实时优势。VASA-1 的意义在于证明 motion-space diffusion 可以同时追求自然度和实时性,而不是只能在低维系数里做简单回归。
Ditto 把 motion space 这个判断讲得最直接:扩散模型不应在冗余的视频/图像潜空间里同时处理身份纹理、背景、头发、牙齿和运动,而应只生成低维、可控、接近语义的面部运动。论文使用 LivePortrait 风格的 motion extractor,单帧图像被分解为 canonical keypoints、expression deformation、head rotation 和 translation;Conditional DiT 生成 motion sequence,one-shot renderer 再把运动渲染回目标身份。#Li-et-al.-2025-Ditto
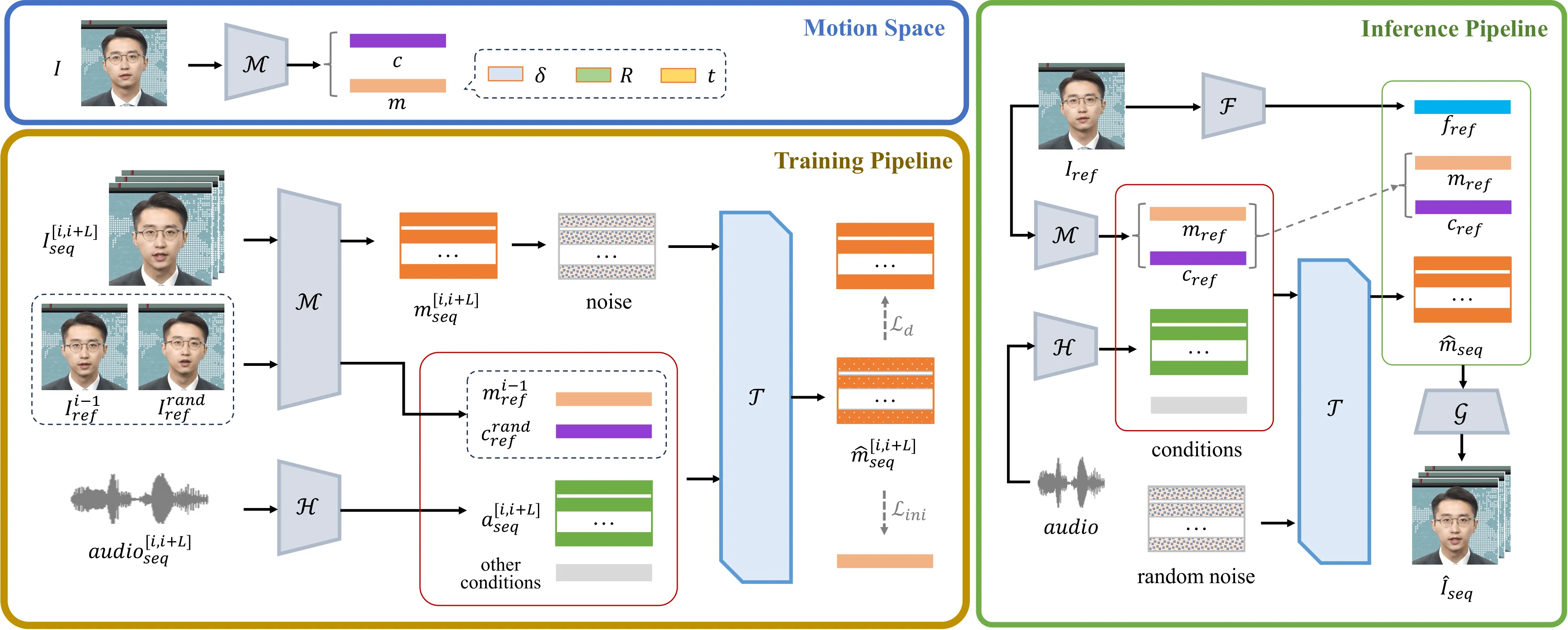
Ditto 与 VASA-1 的关系可以理解为“同一方向的工程化推进”。VASA-1 证明了整体面部动力学 latent + diffusion transformer 能做到高质量实时;Ditto 则更强调可控、开源和流式推理。它报告 Online RTF 0.895、首帧延迟 385ms、10 步 DiT 去噪和 265D 运动表示,并围绕 gaze correction、emotion control、initial motion conditioning 和 streaming inference 做系统优化。#Li-et-al.-2025-Ditto
flowchart TD A["参考人像"] --> B["Motion Extractor"] B --> C["identity-agnostic motion space
expression / rotation / translation"] D["音频流"] --> E["Audio Encoder"] F["控制信号
gaze / emotion / initial motion"] --> G["Conditional DiT"] C --> G E --> G G --> H["motion sequence"] A --> I["Appearance Feature"] H --> J["One-shot Renderer"] I --> J J --> K["realtime talking-head video"]
图 4:运动空间路线的共同链路。参考图像提供身份与外观,音频和控制信号生成运动序列,渲染器负责把运动还原成目标身份的视频。
| 子路线 | 代表工作 | 运动空间是什么 | 生成模型 | 适合场景 |
|---|---|---|---|---|
| 显式 3DMM 系数 | SadTalker | 表情系数、头姿系数 | ExpNet + PoseVAE | 可解释 baseline、单图说话头、低成本研究复现 |
| 整体面部动力学 latent | VASA-1 | 唇部、表情、眼神、眨眼和头动的整体潜变量 | Diffusion Transformer | 高质量实时 talking face、视频会议 avatar |
| 显式 motion representation + DiT | Ditto | keypoints、expression deformation、rotation、translation | Conditional DiT | 可控实时数字人、开源推理链路、交互场景 |
这张 taxonomy 也解释了为什么 SadTalker、VASA-1 和 Ditto 可以放在同一篇里。它们并不是都用了同一种模型,而是都遵循同一个任务分解:音频不直接生成最终像素,而是先驱动运动表示;身份和纹理由参考图像/渲染器保留。模型升级的主线,是从显式但容量有限的 3DMM,走向容量更高的面部 latent,再走向既可控又可实时部署的 motion representation + diffusion。
时间线
| 阶段 | 代表工作 | 关键变化 | 对数字人系统的意义 |
|---|---|---|---|
| 2023 | SadTalker | 从音频生成 3DMM motion coefficients | 把单图 talking head 变成可解释运动预测问题 |
| 2024 | VASA-1 | 在整体面部动力学 latent 中做扩散生成 | 证明 motion-space diffusion 可以支撑 512×512 实时生成 |
| 2025 | Ditto | 用显式 motion representation、Conditional DiT 和流式推理 | 把 motion-space diffusion 推向可控、开源、实时系统 |
对 motion space 路线做工程选型时,不能只看生成质量,也不能只看“实时”两个字。更关键的问题是:训练阶段需要多少 GPU,推理阶段能不能单卡实时,首帧延迟能不能撑住交互体验。公开论文和项目页对这些信息披露并不均匀,因此下面只记录论文或官方项目明确给出的数字;未披露的地方不做猜测。#Zhang-et-al.-2023-SadTalker #Xu-et-al.-2024-VASA #Li-et-al.-2025-Ditto #OpenTalker-SadTalker #Microsoft-VASA-Project #AntGroup-Ditto
| 代表工作 | 训练资源披露 | 推理硬件披露 | 推理性能披露 | 工程含义 |
|---|---|---|---|---|
| SadTalker | 论文与官方 README 未系统给出训练 GPU 规模 | 官方 README 提供本地、Colab、HuggingFace、WebUI 等推理入口,但未给统一 benchmark 硬件 | 没有把实时 FPS/RTF 作为核心指标报告 | 更适合作为低门槛 baseline 和可解释方案;上线时需要自己重测目标机器上的吞吐和延迟 |
| VASA-1 | 论文披露数据规模和训练设置细节,但未给出完整训练 GPU 规模 | 项目页披露在线流式模式在单张 NVIDIA RTX 4090 桌面 GPU 上评估 | 512×512 在线生成最高约 40 FPS,启动延迟约 170ms | 证明 latent motion diffusion 可以单卡实时,但由于代码和模型未完整开放,复现成本不能只按推理数字估计 |
| Ditto | 论文披露使用 8 张 NVIDIA A100 训练,batch size 1024,500 epochs | 论文推理环境为 12 核 Intel Xeon Platinum 8369B、1 张 NVIDIA A100、100G 内存;官方仓库测试环境也标注 A100 与 TensorRT 8.6.1 | 512×512 head region:离线 RTF 0.635;在线 RTF 0.895,FFD 385ms;full-body 在线 RTF 0.914,FFD 392ms | 训练侧仍是多 A100 研究/工业成本,推理侧通过 motion space、10-step DiT、TensorRT 和流式模块优化压到单 A100 实时 |
Ditto 的数字尤其能说明这个差别。论文训练用了 8 张 A100,这是典型工业训练预算;但在线推理只报告 1 张 A100,且 RTF 小于 1、首帧延迟低于 400ms。换句话说,motion space 并不是把所有计算都消掉,而是把大部分不可实时的学习成本放到离线训练,把在线阶段压缩成“音频特征提取 → 运动生成 → 快速渲染”的流式链路。#Li-et-al.-2025-Ditto #AntGroup-Ditto
Motion space 路线适合“身份固定、背景相对稳定、交互实时、需要可控表情/眼神/头姿”的数字人任务。客服头像、视频会议 avatar、在线讲解员、直播助理和移动端轻量数字人,都更关心低延迟、稳定身份和可控失败,而不是每帧都重新生成复杂背景。此时,运动空间路线通常比视频扩散基模更容易上线。
| 业务目标 | 推荐路线 | 原因 | 风险 |
|---|---|---|---|
| 低成本单图说话人 | SadTalker/3DMM 系数 | 表示清楚、依赖少、适合作为 baseline | 表情和头动自然度有限 |
| 高质量实时头像 | VASA-1 类整体动力学 latent | 更强整体表情和头动建模 | 复现与部署取决于模型/代码可用性 |
| 可控实时产品 | Ditto 类 motion-space diffusion | 低维目标、可控信号、流式推理更适合产品 | 运动表示和 renderer 决定视觉上限 |
| 全身、背景、场景生成 | 视频扩散基模 | 需要更大画面自由度 | 成本、长时稳定和实时化难度更高 |
选型边界
运动空间路线不是“低端方案”。它是一种把生成问题收缩到可控空间的系统设计。若产品核心是实时对话和稳定头像,它往往比整帧视频生成更合适;若产品核心是固定身份资产、高 FPS 渲染和三维一致性,就需要进入下一篇的 3DGS/NeRF 路线。
SadTalker、VASA-1 和 Ditto 可以共同归入 motion space 路线,因为它们都把数字人生成拆成“运动生成”和“外观渲染”两层。SadTalker 选择显式 3DMM motion coefficients,VASA-1 选择整体面部动力学 latent,Ditto 选择更工程化的 motion representation + Conditional DiT。三者的共同逻辑是:音频先驱动运动,运动再驱动视频。#Zhang-et-al.-2023-SadTalker #Xu-et-al.-2024-VASA #Li-et-al.-2025-Ditto
这条路线解决的是实时 talking head 的核心矛盾:既要自然运动,又要低延迟和可控性。下一篇讨论 3DGS/NeRF 显式可渲染表示:当目标人物固定时,系统可以先训练一个可复用的三维头像资产,再用音频实时驱动它。
- Zhang et al., “SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation,” CVPR 2023. arXiv
- Xu et al., “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time,” NeurIPS 2024. arXiv
- Li et al., “Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis,” ACM MM 2025. arXiv
- OpenTalker/SadTalker official repository. GitHub
- Microsoft Research VASA-1 project page. Project page
- Ant Group Ditto official repository. GitHub