扩散基模与整帧数字人路线
上一篇讨论的是 3DGS/NeRF 数字人:系统先训练固定身份的可渲染三维资产,再用音频驱动它。本篇单独讨论另一条正在成形的主线:把通用视频扩散基模改造成数字人生成器。它不只回答“运动变量怎么预测”,而是回答“一个已经学会生成视频的大模型,如何被音频、参考帧、人物身份和流式状态重新约束成数字人系统”。#Yang-et-al.-2025-InfiniteTalk #Huang-et-al.-2025-LiveAvatar
阅读目标
- 前情回顾:3DGS/NeRF 路线适合固定身份资产,但通用生成自由度受 person-specific 设定限制。
- 本篇问题:视频扩散基模怎样接收音频、参考帧和人物身份,并扩展到整帧/全身生成。
- 下一篇衔接:理解生成自由度后,再进入实时流式与蒸馏,讨论低延迟交互系统。
这里的“扩散基模”不是泛指任何用了 diffusion loss 的小模型,而是指一类已经在大规模视频数据上预训练、具备通用视频生成能力的模型,例如 video diffusion transformer、latent video diffusion 或 flow-matching 视频模型。数字人任务在这类基座上追加音频、人物参考、文本、稀疏帧、动作状态或交互状态,让模型从“生成视频”变成“生成一个会说话、会动、能持续存在的人”。OmniAvatar、MultiTalk、InfiniteTalk、HunyuanVideo-Avatar、SkyReels-Audio、Live Avatar 和 StreamAvatar 都属于这个方向的不同切面。#Gan-et-al.-2025-OmniAvatar #Kong-et-al.-2025-MultiTalk #Chen-et-al.-2025-HunyuanAvatar #Fei-et-al.-2025-SkyReelsAudio #Sun-et-al.-2025-StreamAvatar
扩散基模数字人的生成形式
给定视频基座 \(F_\theta\)、参考身份 \(I\)、音频 \(A\)、文本/指令 \(Y\)、历史状态 \(H_t\) 与控制信号 \(C\),数字人生成可以写成:
与局部换嘴不同,\(F_\theta\) 不是只补嘴部像素,而是在视频 latent 或 motion/video token 空间中共同决定脸、头动、身体、背景和时间连续性。
这条路线和传统 talking head 的差别在于“能力来源”不同。SadTalker、VASA-1、Ditto 等工作更像是在专门的运动空间或人脸 latent 中学习音频到运动的映射;扩散基模路线则把已经学到的画面先验、时间建模能力和多模态控制能力保留下来,再用音频适配、LoRA、cross-attention、mask adapter、reference injection、self-forcing 或蒸馏把它收束到数字人任务。整帧/全身生成不是另一条平行路线,而是扩散基模在更大生成范围上的任务形态:模型不只改嘴,还要同时生成脸、头动、身体、衣服、背景和动作。#Tian-et-al.-2024-EMO #Hu-et-al.-2023-AnimateAnyone #Gan-et-al.-2025-OmniAvatar
| 路线 | 能力来源 | 数字人改造重点 | 典型工作 | 主要代价 |
|---|---|---|---|---|
| 局部换嘴 | 原视频帧 | 嘴部/脸部 ROI 与音频同步 | Wav2Lip、MuseTalk | 表达自由度低 |
| 专用 talking head | 3DMM、motion latent、人脸 latent | 音频到表情、头动、姿态 | SadTalker、VASA-1、Ditto | 画面上限受中间表示约束 |
| 视频扩散基模 | 大规模视频生成先验 | 音频/身份/稀疏帧/整帧动作/流式状态注入 | InfiniteTalk、OmniAvatar、LongCat-Video-Avatar、Live Avatar、StreamAvatar | 训练和推理成本高 |
| 绑定资产系统 | 3D 角色、动作库、渲染系统 | 语义动作、表情和交互状态 | SentiAvatar、商业 3D 数字人 | 资产生产和维护成本高 |
从 2023 到 2026,扩散基模数字人不是沿一条直线演进,而是分成四个层级:先用扩散模型证明整帧人像动画的表现力,再把音频注入视频 DiT,然后处理长视频的续接,最后把多步扩散压成流式实时系统。#Hu-et-al.-2023-AnimateAnyone #Tian-et-al.-2024-EMO #Yang-et-al.-2025-InfiniteTalk #Huang-et-al.-2025-LiveAvatar #Sun-et-al.-2025-StreamAvatar
第一层:整帧动画能力
Animate Anyone 证明了扩散模型可以用 ReferenceNet 和 pose guider 把静态人物图像变成可控视频,关键问题是保持参考图的细节一致性与跨帧连续性。它还不是音频驱动数字人,但为后续“参考身份 + 时序生成”的架构奠定了模式。EMO 则把 audio-to-video diffusion 直接用于 expressive portrait video,不经过 3D 模型或 facial landmark,说明音频可以直接驱动扩散生成更丰富的表情和歌唱动作。#Hu-et-al.-2023-AnimateAnyone #Tian-et-al.-2024-EMO
第二层:音频注入视频 DiT
OmniAvatar 把音频条件注入 Wan2.1-T2V-14B 这类视频基座,用 pixel-wise multi-hierarchical audio embedding 同时影响嘴型与身体动作,并用 LoRA 保留基座原有的 prompt-driven control。MultiTalk 面向多人对话视频,提出 L-RoPE 处理多路音频和多人绑定问题,并强调部分参数训练与多任务训练对保留基座指令跟随能力的重要性。HunyuanVideo-Avatar 进一步把 MM-DiT 用于多角色 audio-driven human animation,通过 character image injection、Audio Emotion Module 和 Face-Aware Audio Adapter 处理身份一致、情绪对齐和多角色独立音频注入。#Gan-et-al.-2025-OmniAvatar #Kong-et-al.-2025-MultiTalk #Chen-et-al.-2025-HunyuanAvatar
第三层:长视频与稀疏帧条件
InfiniteTalk 把传统 video dubbing 从“只改嘴”扩展为 sparse-frame video dubbing:保留稀疏关键帧来锚定身份、标志性手势和相机轨迹,其余画面由音频驱动生成。论文明确指出朴素 I2V 会累积误差,朴素 FL2V 会刚性复制参考帧;因此它用 context frames 做块间过渡,用参考帧位置采样调节控制强度。SkyReels-Audio 也把 talking portrait 放在 video diffusion transformer 上,支持多模态条件、无限长生成与编辑,并用 sliding-window denoising 融合跨片段 latent,维持长序列的一致性。#Yang-et-al.-2025-InfiniteTalk #Fei-et-al.-2025-SkyReelsAudio
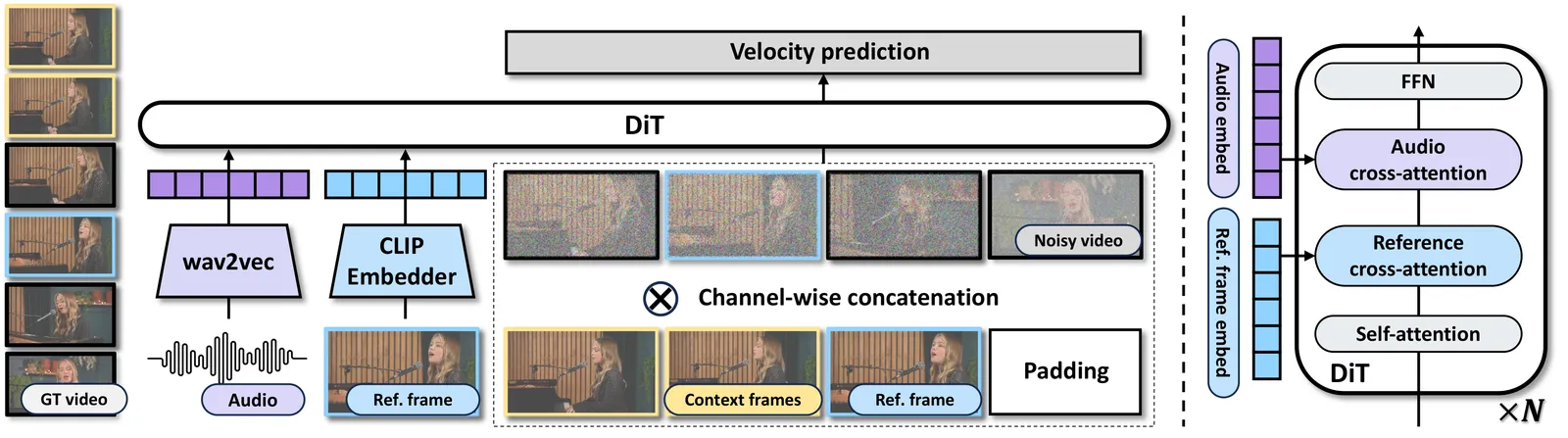
第四层:实时流式基模
Live Avatar 和 StreamAvatar 代表了更系统化的方向:不是只让视频基模更会生成数字人,而是把非因果、多步、离线的视频扩散模型改造成可流式、可长时、可交互的系统。Live Avatar 针对 14B 扩散模型做两阶段训练、长时策略和 Timestep-forcing Pipeline Parallelism,在 5 张 H800 上报告 45 FPS、TTFF 1.21 秒与超过 10,000 秒稳定推演。StreamAvatar 使用两阶段 autoregressive adaptation and acceleration,把高保真人体视频扩散模型改造成实时交互 avatar,并处理 talking/listening 两种会话状态。LLIA 则强调低延迟交互头像,使用 variable-length generation、consistency model training、INT8 量化和 pipeline parallelism,在 RTX 4090D 上报告 384×384 最高 78 FPS、512×512 45 FPS。#Huang-et-al.-2025-LiveAvatar #Sun-et-al.-2025-StreamAvatar #Yu-et-al.-2025-LLIA
| 技术问题 | 典型做法 | 解决什么 | 代表工作 |
|---|---|---|---|
| 身份注入 | ReferenceNet、character image injection、reference cross-attention、reference sink | 让人物外观跨帧一致 | Animate Anyone、HunyuanVideo-Avatar、Live Avatar、StreamAvatar |
| 音频注入 | wav2vec2/audio encoder、audio cross-attention、multi-hierarchical audio embedding、Face-Aware Audio Adapter | 把音素、韵律、情绪映射到脸和身体 | InfiniteTalk、OmniAvatar、HunyuanVideo-Avatar |
| 长时续接 | context frames、sliding-window denoising、KV cache、reference-anchored positional re-encoding | 防止块间跳变和身份漂移 | InfiniteTalk、SkyReels-Audio、Live Avatar、StreamAvatar |
| 基座保留 | LoRA、部分参数训练、多任务训练 | 不破坏视频基模的画质和指令跟随 | OmniAvatar、MultiTalk |
| 实时化 | few-step distillation、consistency model、DMD、自回归蒸馏、量化、TPP | 把多步扩散变成低延迟系统 | Live Avatar、StreamAvatar、LLIA |
flowchart TD B["视频扩散基模
Video DiT / Flow Matching / Latent Diffusion"] --> I["身份条件
reference image / sparse frames"] B --> A["音频条件
wav2vec2 / cross-attention / audio adapter"] B --> C["控制条件
text / pose / mask / emotion"] I --> G["数字人生成器"] A --> G C --> G H["历史状态
context frames / KV cache / reference sink"] --> G G --> O["talking head / full-body / streaming avatar"] G --> R["蒸馏 + 量化 + 并行"] R --> S["实时交互系统"]
图 3:扩散基模数字人的共同结构。核心不是单个模块,而是把通用视频生成基座、身份条件、音频条件、历史状态和实时化策略组合成闭环。
这张图也说明了为什么 InfiniteTalk 和 Live Avatar 可以放在同一条主线下,但不应被混成同一个问题。InfiniteTalk 的主问题是稀疏帧视频配音:怎样在保留关键帧约束的同时生成长视频;Live Avatar 的主问题是实时流式 audio-driven avatar:怎样把 14B 扩散模型从离线多步生成改造成长时低延迟系统。它们共享视频基座、音频条件、长时续接和误差控制这些机制,但任务约束不同,评测重点也不同。#Yang-et-al.-2025-InfiniteTalk #Huang-et-al.-2025-LiveAvatar
整帧/全身生成是扩散基模路线最自然的外延:模型不再只修改嘴部,而要生成完整画面,甚至根据音频同步生成头动、身体姿态、手势、衣服纹理和背景细节。自由度越大,表现力越强,失败空间也越大。OmniAvatar 将任务定位为 audio-driven full-body video generation;LongCat-Video-Avatar 则把自己定义为 unified DiT-based framework,目标是生成长时长、高真实感的 audio-driven human videos。#Gan-et-al.-2025-OmniAvatar #LongCat-Video-Avatar-Page
| 维度 | 局部换嘴 | 整帧/全身生成 |
|---|---|---|
| 生成范围 | 嘴部和局部脸 | 脸、身体、衣服、背景和动作 |
| 身份保持 | 天然较稳,因为原视频保留大部分外观 | 需要参考身份、跨帧注意力和长时锚点共同约束 |
| 动作能力 | 复用原视频动作 | 可生成头动、姿态、手势和舞台表演 |
| 主要风险 | 嘴部边界、牙齿、情绪不一致 | 身份漂移、手部畸变、背景闪烁、长时序漂移 |
OmniAvatar 的关键设计是把 wav2vec2 音频特征变成 pixel-wise multi-hierarchical audio embedding,注入 DiT 多个层级的 latent,让音频同时影响嘴型、表情和更大范围的身体节奏。它基于 Wan2.1-T2V-14B,却用 LoRA 做音频适配而非全量微调;这背后的工程判断是:全量微调可能破坏视频基座原有的画质和文本控制能力,LoRA 反而更容易保住基座先验。#Gan-et-al.-2025-OmniAvatar #OmniAvatar-GitHub
LongCat-Video-Avatar 和 Animate Anyone 提醒我们,不要把“通用视频模型能生成有人说话的片段”等同于“数字人系统已经成立”。真实产品需要固定身份、可控台词、可控情绪、可控时长、可重复生成,还要处理品牌形象和合规审核。整帧路线更适合广告素材、虚拟主播片段、课程开场和可重试的离线内容生产;若业务目标是实时客服,仍需要后面的流式系统、少步蒸馏、量化和降级策略。#LongCat-Video-Avatar-1.5 #Hu-et-al.-2023-AnimateAnyone
视频扩散基模生成几秒 demo 并不难,难的是长对话、长配音和连续互动。长时失败通常来自三类机制:第一,块状生成带来的边界跳变;第二,身份参考与生成帧分布不一致造成的漂移;第三,多步扩散和自回归历史共同放大细小错误。InfiniteTalk 用 context frames 和参考帧采样处理块间连续性;SkyReels-Audio 用 sliding-window denoising 融合片段;Live Avatar 用 History Corrupt、Adaptive Attention Sink 和 Rolling RoPE 抑制长时漂移;StreamAvatar 用 Reference Sink、RAPR 和 Consistency-Aware Discriminator 强化长期稳定。#Yang-et-al.-2025-InfiniteTalk #Fei-et-al.-2025-SkyReelsAudio #Huang-et-al.-2025-LiveAvatar #Sun-et-al.-2025-StreamAvatar
| 失败模式 | 机制来源 | 典型修复 | 对应工作 |
|---|---|---|---|
| 块间跳变 | 每段视频独立生成,缺少动量 | context frames、sliding-window latent fusion | InfiniteTalk、SkyReels-Audio |
| 身份漂移 | 参考帧位置或分布与生成帧不一致 | reference sink、AAS、character injection | Live Avatar、StreamAvatar、HunyuanVideo-Avatar |
| 注意力衰减 | sink 帧与当前块的 RoPE 相对距离超出训练范围 | Rolling RoPE、RAPR | Live Avatar、StreamAvatar |
| 多步推理太慢 | 扩散去噪串行执行 | DMD、consistency distillation、TPP、pipeline parallelism | Live Avatar、LLIA、StreamAvatar |
只要还是多步扩散,模型就天然存在首帧延迟和串行去噪成本。实时化因此不是一个单点优化,而是一组共同约束:采样步数要少,历史状态要可缓存,注意力要因果化,VAE/UNet/DiT 与视频编码要能流水线化,系统还要处理 speaking、listening、idle 等会话状态。LLIA 讨论了 response latency,指出即使生成 FPS 超过播放 FPS,如果初始片段太长,用户仍会感到迟钝;StreamAvatar 和 Live Avatar 则把流式状态设计放到核心位置。#Yu-et-al.-2025-LLIA #Sun-et-al.-2025-StreamAvatar #Huang-et-al.-2025-LiveAvatar
| 工作 | 实时化策略 | 公开指标 | 适用判断 |
|---|---|---|---|
| Live Avatar | DMD/Self-Forcing、长时策略、TPP | 5 H800 上 45 FPS,TTFF 1.21s,10,000+ 秒稳定推演 | 高质量流式 avatar,但依赖多卡系统能力 |
| LLIA | variable-length generation、consistency model、INT8、pipeline parallelism | RTX 4090D 上 384×384 78 FPS,512×512 45 FPS | 更贴近低延迟交互头像 |
| StreamAvatar | 自回归适配、加速、adversarial refinement、Reference Sink/RAPR | 论文强调实时效率和交互自然度,项目页给出系统演示 | 面向 talking/listening 双状态互动 avatar |
| InfiniteTalk | context frames 与分块续接 | 面向无限长稀疏帧配音,非低延迟对话优先 | 长视频配音与内容生成更适合 |
这里需要区分两个“实时”。一个是模型吞吐实时,表示生成速度超过视频播放速度;另一个是交互实时,表示系统可以快速响应用户新输入、打断旧动作、切换听说状态,并在网络与编码链路中保持低延迟。Live Avatar 解决的是 14B 扩散模型能否以流式方式持续生成;LLIA 更直接讨论初始响应延迟;StreamAvatar 把 listening behavior 纳入生成目标。这些约束共同指向一个结论:基模路线若要进入产品,必须同时做算法蒸馏和系统流水线。#Huang-et-al.-2025-LiveAvatar #Yu-et-al.-2025-LLIA #Sun-et-al.-2025-StreamAvatar
扩散基模路线适合表达自由度高、画质要求高、身份/场景变化多、并且可以承担更高算力和工程复杂度的业务。广告、虚拟主播、长视频配音、多角色对话、品牌 IP 内容生产、强表现力直播形象,都可以从基模的视频先验中受益。若业务只要求已有素材换音频,Wav2Lip/MuseTalk 类局部方案仍然更稳;若业务只要求低成本客服头像,轻量 talking head 或绑定资产系统可能更容易上线。#Prajwal-et-al.-2020 #Zhang-et-al.-2024-MuseTalk #Yang-et-al.-2025-InfiniteTalk
| 业务目标 | 是否适合基模路线 | 原因 | 替代路线 |
|---|---|---|---|
| 已有视频多语言配音 | 中等 | InfiniteTalk 类稀疏帧配音可提升全身同步,但成本高于局部换嘴 | Wav2Lip、MuseTalk |
| 短视频虚拟主播 | 高 | 需要画质、身体动作、背景和风格控制 | OmniAvatar、HunyuanVideo-Avatar、SkyReels-Audio |
| 实时互动客服 | 谨慎 | 首帧延迟、并发成本和稳定性比画质更重要 | 轻量 talking head、LLIA 类低延迟方案 |
| 高端实时形象 | 高但昂贵 | Live Avatar/StreamAvatar 类系统能保留基模画质并做流式生成 | 多卡推理、蒸馏、降级策略 |
| 固定 3D 角色长期运营 | 不一定 | 绑定资产和动作库更可控,合规和风格稳定性更强 | SentiAvatar、3D/UE/动作库系统 |
选型边界
扩散基模路线不应被当成“更大的模型一定更好”。它带来更高画质和更大表现空间,也带来更多不可忽略的系统问题:训练数据授权、长时身份漂移、推理成本、并发调度、内容安全和失败兜底。
基于扩散基模的数字人路线,可以理解为视频生成大模型向数字人系统的专门化:先保留基座的画面、时序和多模态先验,再通过音频注入、参考身份、稀疏帧、历史状态、蒸馏和流水线把它约束到可控、可长时、可交互的 avatar。它解释了为什么 InfiniteTalk、OmniAvatar、Live Avatar、StreamAvatar 虽然任务不同,却属于同一条技术主线:它们都在回答“如何把通用视频基模变成会说话的人”。#Yang-et-al.-2025-InfiniteTalk #Gan-et-al.-2025-OmniAvatar #Huang-et-al.-2025-LiveAvatar #Sun-et-al.-2025-StreamAvatar
下一篇将进入实时流式与蒸馏。那里讨论的问题不再是“能生成多自由度画面”,而是“能不能边听边生成、低延迟响应、长时间不漂移”。
- Prajwal et al., “A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild,” 2020.
- Zhang et al., “MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting,” 2024.
- Hu et al., “Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation,” arXiv:2311.17117, 2023.
- Tian et al., “EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions,” arXiv:2402.17485, 2024.
- Kong et al., “Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation,” arXiv:2505.22647, 2025.
- Chen et al., “HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters,” arXiv:2505.20156, 2025.
- Gan et al., “OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation,” arXiv:2506.18866, 2025.
- Omni-Avatar, “OmniAvatar official repository,” GitHub, 2025.
- MeiGen-AI, “LongCat-Video-Avatar project page,” 2026.
- LongCat authors, “LongCat-Video-Avatar 1.5 Technical Report,” arXiv:2605.26486, 2026.
- Fei et al., “SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers,” arXiv:2506.00830, 2025.
- Yang et al., “InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing,” arXiv:2508.14033, 2025.
- Yu et al., “LLIA - Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models,” arXiv:2506.05806, 2025.
- Huang et al., “Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length,” arXiv:2512.04677, 2025.
- Sun et al., “StreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars,” arXiv:2512.22065, 2025.