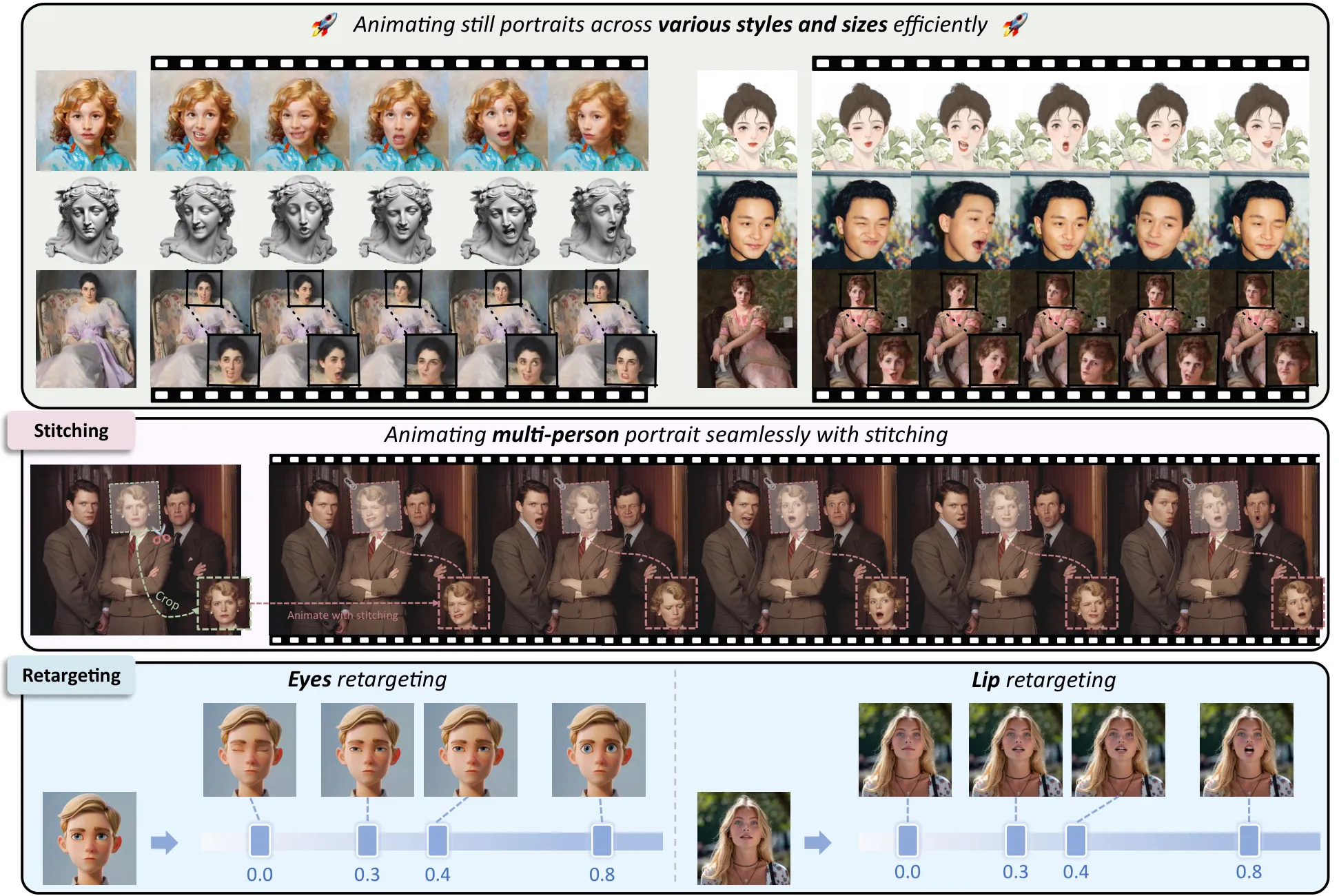
数字人论文精读(十三):LivePortrait,用隐式关键点把肖像动画做快、做稳、做可控
LivePortrait 要解决的是经典肖像动画问题:给定一张静态源肖像,用驱动视频中的头部姿态、表情、眼睛和嘴部运动,把源肖像「活起来」。论文明确没有沿着主流 diffusion portrait animation 继续堆生成质量,而是选择扩展 implicit-keypoint-based framework,因为这条路线在计算效率、可控性、工程稳定性之间更容易取得平衡 #Guo-et-al.-2024。
论文摘要给出的三个数字很关键:训练数据扩到约 6900 万高质量帧;推理在 RTX 4090 + PyTorch 上达到 12.8ms;官方释放了推理代码和模型 #Guo-et-al.-2024。这意味着 LivePortrait 更像一个「工程系统论文」:论文贡献不只在网络结构,而在数据、训练策略、控制模块、推理流程和开源落地之间形成闭环。
从 Face Vid2vid 继承来的骨架
LivePortrait 以 Face Vid2vid 为基座:外观特征提取器 $\mathcal{F}$ 把源图像映射成 3D appearance feature volume;运动侧提取 canonical implicit keypoints、head pose、expression deformation 和 translation;warping module $\mathcal{W}$ 根据源/驱动关键点变形特征体;decoder $\mathcal{G}$ 输出目标帧 #Guo-et-al.-2024。
隐式关键点(Implicit Keypoints)
这里的关键点不是人脸 2D landmark 的直接替代,而是一个紧凑的中间运动表征。它通过 canonical keypoints、旋转、尺度、表情形变和平移组合出源关键点与驱动关键点,再交给 warping module 做特征变形。
Face Vid2vid 原始变换可写作:
LivePortrait 加入 scale factor,把尺度从 expression deformation 里剥离出来,降低训练难度并减少跨身份驱动时的纹理闪烁 #Guo-et-al.-2024:
为什么它能控制眼睛和嘴?
论文的一个经验发现是:紧凑隐式关键点可以看成一种 implicit blendshapes。它不像 3DMM blendshape 那样有显式语义维度,但可以通过小型 MLP 学到「眼睛更开一点」「嘴巴闭合一点」「肩部贴回源图」这样的局部 deformation offset #Guo-et-al.-2024。
Stage I:Base Model Training
第一阶段训练基础动画模型。训练目标是让 appearance extractor $\mathcal{F}$、motion extractor $\mathcal{M}$、warping module $\mathcal{W}$ 和 decoder $\mathcal{G}$ 形成完整可驱动链路。论文明确说这一阶段从零训练,数据包括公开视频数据、AAHQ 风格图像、收集的 4K 肖像视频、200 小时 talking head 视频、私有 LightStage 数据,以及若干风格化肖像视频/图像 #Guo-et-al.-2024。
数据处理也很工程化:长视频切成 30 秒以内 clip,用 face tracking / recognition 保证单人,用 KVQ 过滤低质量片段;过滤后得到约 6900 万视频帧、约 1.89 万身份,以及 6 万静态风格化肖像 #Guo-et-al.-2024。
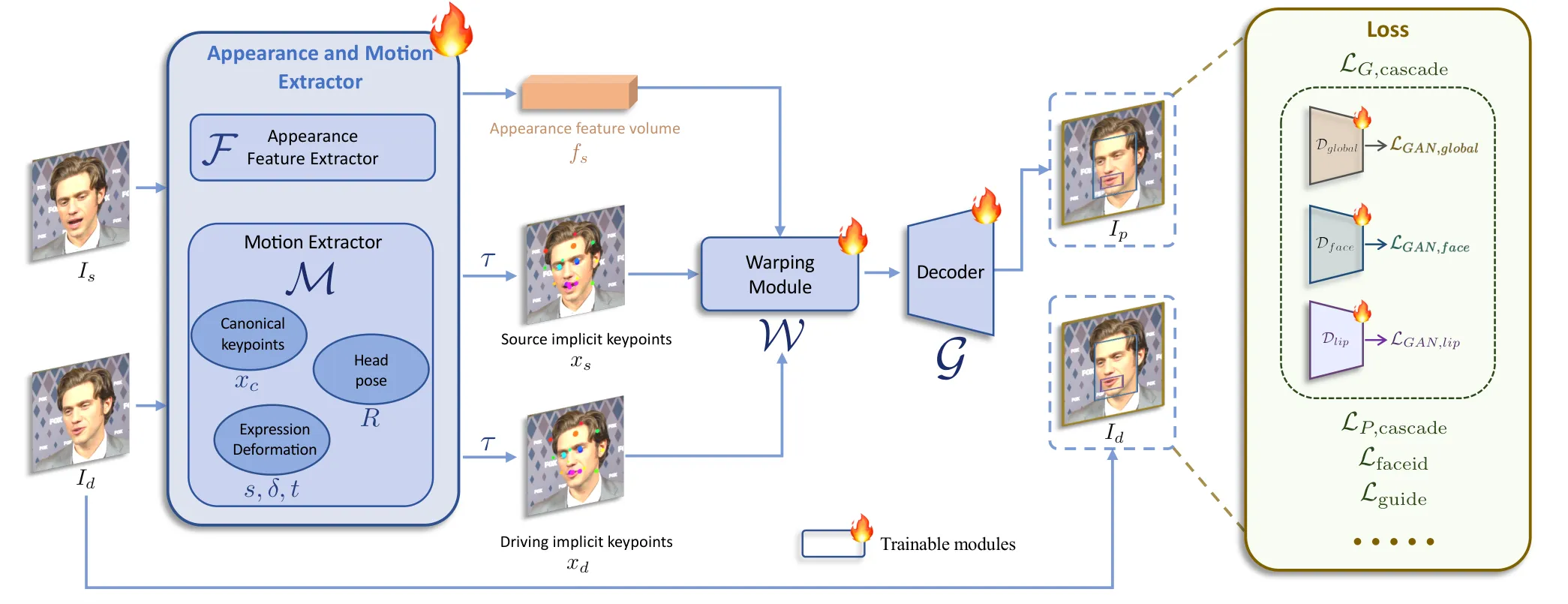
第一阶段总目标可以概括为:
其中 landmark-guided implicit keypoints optimization 很关键:论文认为单靠无监督关键点很难学到眨眼、眼球运动这类微表情,因此选择 10 个来自眼睛和嘴部的 2D landmarks,用 Wing loss 约束对应的隐式关键点投影 #Guo-et-al.-2024。
Stage II:Stitching and Retargeting
第二阶段不再动基础生成链路,而是冻结 appearance / motion extractor、warping module 和 decoder,只训练 stitching module、eyes retargeting module 与 lip retargeting module #Guo-et-al.-2024。这是 LivePortrait 工程感最强的地方:基础模型负责「会动」,小 MLP 负责「贴得稳、眼嘴可控」。
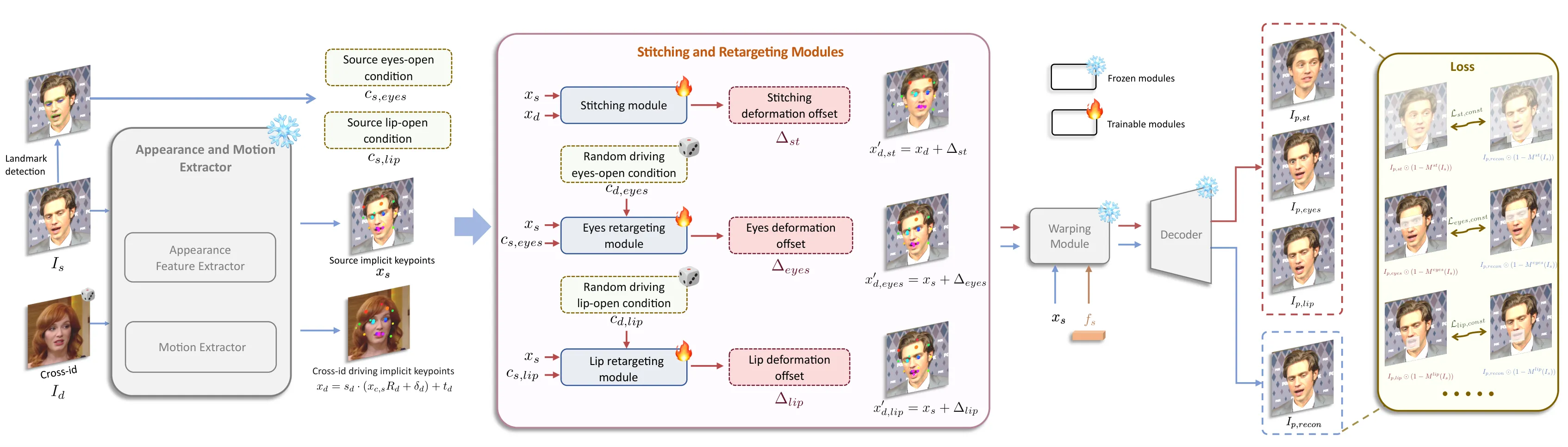
Stitching module
Stitching module $\mathcal{S}$ 接收源/驱动隐式关键点,预测 driving keypoints 的 deformation offset:
它的目的不是让脸更像,而是让生成头像贴回原始图像空间时肩膀、脖子、背景边界不产生明显错位。论文还特别使用 cross-id motion 增加训练难度,以提升跨身份 stitching 泛化 #Guo-et-al.-2024。
Eyes / lip retargeting modules
Eyes retargeting 解决「小眼睛驱动大眼睛时闭眼不完整」的问题;lip retargeting 类似,还支持把输入源图先规范到闭嘴状态,便于后续驱动 #Guo-et-al.-2024。两者都输出 $K\times3$ 的关键点偏移,并且论文指出 eyes / lip 的 deformation offsets 可以解耦并线性叠加。
论文中的 inference 公式把第 0 帧驱动作为 anchor,用相对姿态、相对表情和相对平移组合出第 $i$ 帧 driving keypoints #Guo-et-al.-2024:
官方代码里的实际流程
官方 GitHub README 声明仓库是论文的 official PyTorch implementation,并提供推理代码和模型下载入口 #LivePortrait-GitHub。在 src/live_portrait_pipeline.py 中,make_motion_template() 会逐帧收集 scale、R、exp、t、kp、x_s、c_eyes、c_lip;execute() 则负责源图/视频加载、驱动视频或 .pkl motion template 加载、裁剪、关键点提取、相对运动组合、retargeting、stitching、paste-back 与视频输出 #LivePortrait-Code。
- 源输入处理:源可以是图片或视频;图片会裁剪并 resize 到 256×256,必要时保留 crop-to-original 的 paste-back 变换。
- 驱动处理:驱动可以是视频、图片或预先生成的
.pklmotion template;README 也说明 motion template 可加速推理并保护隐私 #LivePortrait-GitHub。 - 运动模板:逐帧提取 motion extractor 输出,并计算眼睛/嘴巴开合 ratio。
- 相对运动组合:默认
flag_relative_motion=True,用驱动首帧作为相对参考。 - 控制与贴回:默认
flag_stitching=True、flag_pasteback=True、flag_normalize_lip=True,而flag_eye_retargeting和flag_lip_retargeting默认关闭,可按需开启 #LivePortrait-Code。
系统/工程型方法最怕只看效果图不看配置。论文披露了主要训练硬件、时间、输入输出、优化器和 MLP 结构,但完整训练代码、私有数据与所有 loss 权重并未完全公开 #Guo-et-al.-2024。
| 项目 | 披露状态 | 值 / 说明 |
|---|---|---|
| Stage I 硬件 | 已披露 | 8 NVIDIA A100 GPUs |
| Stage I 时间 | 已披露 | 约 10 天,从零训练 |
| Stage II 时间 | 已披露 | 约 2 天,只训练 stitching / retargeting 模块 |
| 输入 crop | 已披露 | 256×256 aligned crop |
| 输出分辨率 | 已披露 | 512×512 |
| Batch size | 已披露 | 104 |
| 优化器 | 已披露 | Adam, lr=2e-4, beta1=0.5, beta2=0.999 |
| Stitching MLP | 已披露 | [126, 128, 128, 64, 65] |
| Eyes retargeting MLP | 已披露 | [66, 256, 256, 128, 128, 64, 63] |
| Lip retargeting MLP | 已披露 | [65, 128, 128, 64, 63] |
| 完整训练数据 | 部分未披露 | 包含私有 LightStage 与内部收集视频,无法完整复现 |
| 完整 loss 权重 | 部分未披露 | 主文给出损失项与符号,部分权重未在已检查文本中完整列出 |
| 训练代码 | 未披露 / 公开仓库偏推理 | 官方 GitHub 提供推理代码和预训练权重入口 |
结果怎么读?
Self-reenactment 中,论文在 TalkingHead-1KH 和 VFHQ 上报告 LivePortrait 在 PSNR、SSIM、LPIPS、$\mathcal{L}_1$、CSIM 和 eye direction MAE 上整体领先;例如 TalkingHead-1KH 上 Ours 的 PSNR 为 32.0082、SSIM 为 0.8193、LPIPS 为 0.0664、CSIM 为 0.9125、MAE 为 7.0535 #Guo-et-al.-2024。

Cross-reenactment 中,论文也承认并非所有指标都第一:LivePortrait 在多数生成质量和运动准确性指标上优于先前 diffusion / non-diffusion 方法,但 TalkingHead-1KH 的 FID 由 diffusion-based AniPortrait 更好,两个数据集上的 CSIM 由 X-Portrait 更好 #Guo-et-al.-2024。这反而说明论文没有把结果包装成全方位碾压,而是更强调可控、稳定和速度的工程平衡。
论文局限
- 复现门槛高:核心训练数据包含私有和内部收集部分,完整复现 6900 万帧训练并不现实。
- 训练侧公开不足:官方仓库重点是推理;训练代码、完整 loss 权重和数据清洗细节需要进一步核验。
- 隐式控制仍是经验性的:论文说隐式关键点可作为 implicit blendshapes,但这主要是实验观察,不是显式可解释的 3D blendshape basis。
- 伦理风险存在:官方 README 明确提示 portrait animation 有 deepfake 滥用风险,并声明生成结果可能包含有助于检测的视觉 artifacts #LivePortrait-GitHub。
为什么它值得放进数字人系列?
如果把数字人分成「高质量生成」和「实时可控工程」两条线,LivePortrait 明显属于后者。它不是用扩散模型暴力生成每一帧,而是把源图外观特征缓存起来,用运动表征驱动 warping,再用 decoder 还原。这种路线天然适合实时、交互、低延迟和多端部署。
Sources
- Guo, Jianzhu et al. (2024). LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control. arXiv:2407.03168. arXiv · HTML · PDF
- LivePortrait Official Project Page. liveportrait.github.io
- KlingAIResearch / KwaiVGI. LivePortrait official PyTorch implementation README. GitHub
- LivePortrait official inference implementation:
src/live_portrait_pipeline.pyandsrc/config/inference_config.py, downloaded from the official GitHub repository on 2026-06-09.