实时流式与蒸馏
前面几篇分别讲了局部换嘴、运动空间、3DGS/NeRF、扩散基模路线和整帧/全身生成。它们回答的是“生成什么”和“生成空间如何被约束成数字人”。本文回答另一个问题:如果用户正在说话,数字人能否边听边生成,端到端延迟是否足够低,长时间会不会漂移。这是实时数字人从内容生成走向交互系统的分水岭。
阅读目标
- 前情回顾:整帧生成提升表现力,但推理成本更高。
- 本篇问题:LiveAvatar、LongLive-2.0、DMD、Self-Forcing 分别解决实时链路的哪一层瓶颈。
- 下一篇衔接:系统路线最终要落到训练资源、推理成本、benchmark 和产品选型。
实时数字人不是单个视频模型的 FPS 问题。端到端链路通常包括 ASR 或音频切片、语音/语义状态、avatar 推理、视频编码、网络传输和播放缓冲。哪怕模型单帧很快,若需要等待长音频窗口或长视频上下文,也无法做到自然打断和实时响应。
端到端延迟分解
其中 $T_{model}$ 只是系统延迟的一部分,流式设计要同时压缩音频窗口、模型采样步数和播放缓冲。
graph LR A["音频特征
20-50 ms"] --> B["运动预测
30-150 ms"] B --> C["渲染
10-80 ms"] C --> D["后处理
5-20 ms"] D --> E["视频编码
5-30 ms"] E --> F["网络传输
10-50 ms"] F --> G["客户端缓冲
50-200 ms"] G --> H["端到端体验"]
图 1:实时数字人的端到端延迟预算。FPS 只是局部指标,交互体验取决于整条链路,模型推理常常不是最大瓶颈。
延迟环节的典型耗时分析
在实际部署中,每个环节的耗时取决于具体实现和硬件配置。以下是典型配置下的耗时范围:
| 环节 | 典型耗时 | 影响因素 | 优化策略 |
|---|---|---|---|
| 音频特征提取 | 20-50 ms | 采样率、特征维度 | 预计算 MFCC/HuBERT、流式特征提取 |
| 运动预测(Avatar 模型) | 30-150 ms | 模型大小、分辨率 | 少步蒸馏、模型量化、批处理 |
| 渲染(像素生成) | 10-80 ms | 分辨率、生成器类型 | 低分辨率生成 + 超分、GPU 渲染 |
| 后处理 | 5-20 ms | 滤波、对齐、平滑 | GPU 加速、简化流程 |
| 视频编码(H.264/H.265) | 5-30 ms | 码率、GOP 大小 | 硬件编码器、自适应编码 |
| 网络传输 | 10-50 ms | 网络抖动、距离 | WebRTC、边缘部署、QUIC |
| 客户端缓冲 | 50-200 ms | 缓冲策略、容错要求 | 动态缓冲、预测预取 |
可以看到,即便模型推理优化到 30-50 ms,其他环节的累积延迟仍然很容易突破 300 ms 阈值。关键瓶颈往往不在模型本身,而在于音频窗口长度、编码参数配置和网络抖动缓冲。对于语音交互场景,首帧延迟(从用户说话开始到 avatar 开始响应)比单帧生成速度更重要,因为它直接影响用户感知的响应速度。如果模型需要等待 2-3 秒的音频上下文才能生成第一帧,即便后续每帧只需 20 ms,用户也会觉得系统迟钝。
graph LR IN["音频流"] --> W["滑动窗口"] W --> RB["环形缓存"] RB --> AV["流式 Avatar 模型"] AV --> OUT["输出帧"] AV --> ST["历史帧 + 隐藏状态"] ST -.->|"状态回写"| RB OUT --> Q["发送队列"] Q -.->|"队列满:丢帧/降码率"| AV
图 2:流式推理流水线。音频经滑动窗口、环形缓存进入流式 Avatar,历史帧与隐藏状态回写缓存形成持续会话回路;背压控制在队列满时丢帧或降码率。
实际做系统时,最先该定的不是模型,而是 SLA:首帧是否要在几百毫秒内出现,用户打断时是否能立刻停止旧动作,TTS 新片段到达时 avatar 是否能自然衔接。若这些约束没有写清,后面很容易出现"模型看起来 30 FPS,但产品仍然像离线视频播放器"的错位。实时数字人的技术评审应把音频窗口长度、模型批处理策略、视频编码参数、网络抖动和播放缓冲一起看。
LiveAvatar 的定位是 real-time human avatar rendering from textual description,强调实时驱动和可交互渲染。它代表一类系统思路:不只追求离线视频质量,而是让 avatar 能在输入流到来时持续更新状态。#LiveAvatar-Project
NVIDIA LongLive-2.0 则直接面向 streaming talking head generation。项目页和技术报告强调 long video、low-latency streaming、consistency 与 audio-driven dynamics。它把问题从“生成一段视频”改写为“维护一个可持续的生成状态”,这对客服、直播助理、实时讲解员等场景更关键。#LongLive-2-Project #LongLive-2-Report
VASA-1 和 Wav2Lip 的实时性边界
VASA-1 的论文标题就强调 real-time talking faces,报告的生成速度已经达到实时级,因此它更接近“模型推理速度可实时”的 talking face 方案。但它仍不等同于完整流式数字人系统:真正上线还要处理音频切片、状态缓存、编码传输、播放缓冲和用户打断。#Xu-et-al.-2024-VASA1
Wav2Lip 则更像高精度 lip-sync 模型:输入一段视频和音频,输出嘴型同步后的视频。原始形态偏离线处理,不天然解决首帧延迟、音频流输入和长时状态维护;经过裁脸、批处理、推理加速和 WebRTC 管线改造后,可以被工程化成近实时或实时嘴型同步模块。#Prajwal-et-al.-2020-Wav2Lip
| 模型 | 实时性判断 | 注意点 |
|---|---|---|
| VASA-1 | 接近实时 / 论文宣称实时 | 主要说明模型生成速度,不代表完整低延迟流式产品链路 |
| Wav2Lip | 原版偏离线,可工程化近实时 | 适合做嘴型同步模块,但需要额外流式采集、缓存和编码传输 |
| LongLive-2.0 / LiveAvatar | 更偏流式系统路线 | 显式讨论持续状态、低延迟和长时一致性 |
flowchart LR A["音频流"] --> B["短窗口特征"] B --> C["状态缓存"] C --> D["流式 avatar 模型"] D --> E["视频帧"] E --> F["编码 / 传输 / 播放"] D -.->|"状态回写"| C
扩散模型质量高,但多步采样天然慢。Distribution Matching Distillation 的核心目标是让学生生成器的分布直接匹配教师扩散模型的分布,从而把多步教师蒸馏成少步甚至一步学生。DMD2 进一步改进了 distribution matching 目标和训练稳定性,被广泛用于少步图像/视频扩散蒸馏讨论。#Yin-et-al.-2024-DMD #Yin-et-al.-2024-DMD2
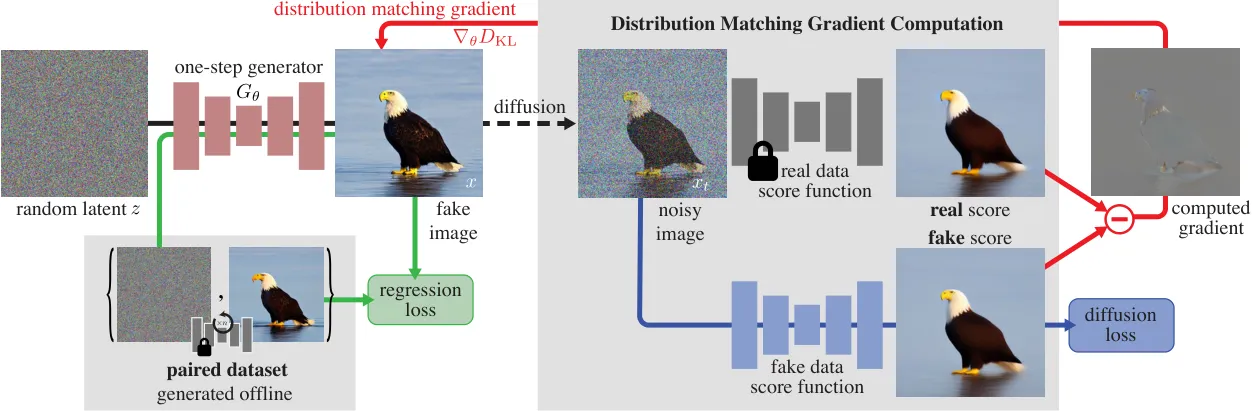
对数字人而言,DMD 的意义不是“又一种 loss”,而是把整帧/全身生成从离线内容生产推向实时交互的关键桥梁。若一个 avatar DiT 需要几十步去噪,它可以生成漂亮短片;但如果要和用户对话,模型必须在很短时间内完成一帧或一个小片段。
DMD 的直觉目标
学生生成器 $G_\theta$ 直接学习条件 $c$ 下教师扩散模型的生成分布,而不是在推理时重复完整去噪链。
一个容易被忽略的反直觉结论是:少步蒸馏不必然以画质为代价。初代 DMD 依赖一个昂贵的 LPIPS 回归损失来稳定训练(需要预计算大量噪声-图像对,构建成本高达数百 A100 天),且学生质量被绑定在教师的采样路径上,难以超越教师。DMD2 移除了回归损失,改用双时间尺度更新(fake score 多更新几次再更新一次生成器)稳定训练,并在判别器上加入 GAN 损失让学生可以直接利用真实数据。结果是学生不仅追平、甚至超越了教师:在 ImageNet 64×64 上,DMD2 的一步学生达到约 1.28 FID,反而优于需要数百步的 EDM 教师(约 2.32 FID)。对工程团队的启示是,把“蒸馏”默认理解为“降质换速度”是过时的——选对蒸馏方案,少步模型可以同时拿到低延迟和高画质。#Yin-et-al.-2024-DMD #Yin-et-al.-2024-DMD2
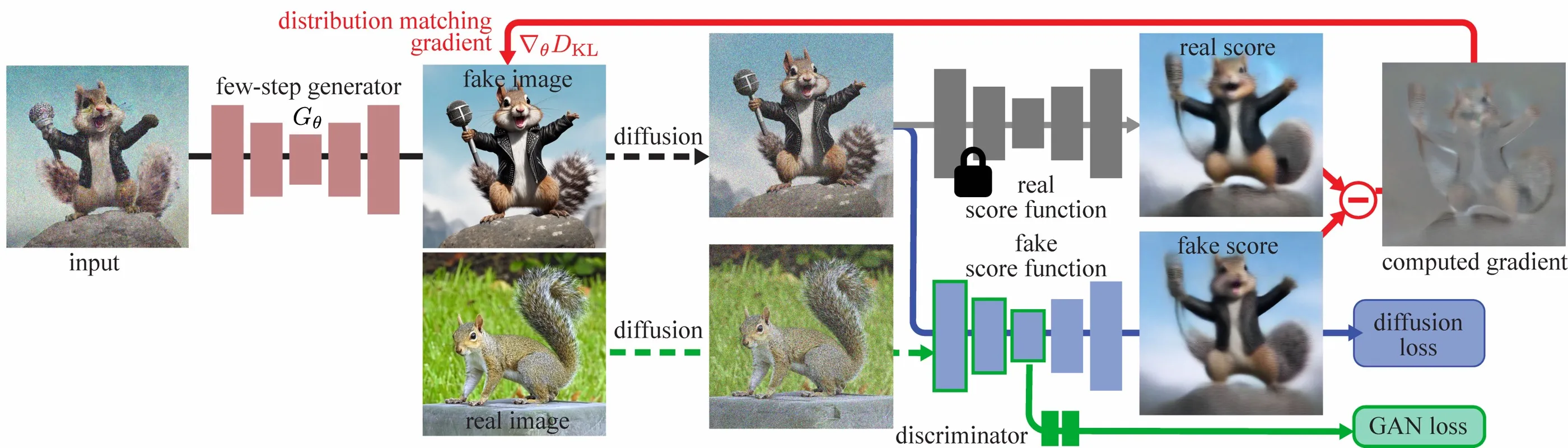
对实时 avatar 来说,蒸馏不是孤立优化,而是和分辨率、帧率、缓存策略一起决定体验。一步或少步模型可能牺牲一部分细节,但换来更稳定的交互延迟;多步模型画质更好,却可能让首帧等待和持续延迟不可接受。产品上要把“画质指标”和“交互指标”分开看:离线生成可以容忍几秒等待,在线对话则更关心用户说完一句话后 avatar 是否能马上接住。
还有一个现实问题是并发。单路 demo 能跑不代表平台能跑。客服、直播助理或在线陪伴场景需要同时服务多路会话,模型推理必须和音频切片、TTS、编码器、WebRTC 传输共同排队。蒸馏节省出来的不是单纯的毫秒,而是并发预算和调度空间。没有这层系统视角,少步扩散很容易只停留在论文指标上。
蒸馏与量化的工程实践
在数字人场景中,蒸馏和量化通常组合使用,形成一条从训练到部署的加速链。知识蒸馏(Knowledge Distillation)可以让小模型学习大模型的"经验",包括动作节奏、表情细节和嘴型同步度;而量化则通过降低数值精度来压缩计算量,从 FP32 降到 FP16 可以减少一半显存占用,INT8 量化则能进一步减少显存和计算开销。
实际部署时,数字人模型常转换为 ONNX 或 TensorRT 格式,以利用推理引擎的优化能力。ONNX 提供跨平台兼容性,适合多语言框架集成;TensorRT 则针对 NVIDIA GPU 深度优化,能在保持精度的同时显著提升推理速度。对于延迟敏感的场景,单步生成(one-step generation)是最理想的目标,但往往需要在质量上做取舍。一个工程实践中的平衡策略是:核心动作预测用蒸馏后的 DiT 做 2-3 步生成,嘴型和表情细节用轻量级网络在单步内完成,整体延迟仍能控制在可接受范围。
| 技术 | 精度损失 | 速度提升 | 适用场景 |
|---|---|---|---|
| FP32 → FP16 | 几乎无 | 1.5-2x | 追求高质量,愿意接受部分加速 |
| INT8 量化 | 1-2% 视觉差异 | 2.5-4x | 资源受限场景,高并发需求 |
| 2步 → 1步蒸馏 | 3-5% 动作细节损失 | 2x | 极低延迟需求 |
| ONNX 转换 | 无 | 1.2-1.8x | 跨平台部署 |
| TensorRT 优化 | 无 | 2-3x | NVIDIA GPU 环境 |
流式推理的工程挑战:从单帧到持续状态
把数字人从"生成一段视频"变成"持续响应音频流",需要解决一系列工程问题。这些问题在论文中很少讨论,但在实际部署中往往是项目成败的关键。
滑动窗口与首帧延迟
音频驱动的 avatar 模型通常需要一定长度的音频上下文才能生成稳定的动作。传统做法是等待 2-3 秒音频再开始生成,但这会导致首帧延迟过高。流式系统采用滑动窗口策略:维护一个固定长度(如 500ms)的音频缓冲区,每收到新音频就更新窗口并触发推理。这样首帧延迟可以压缩到窗口长度 + 推理时间,通常在 600-800ms 内。
但滑动窗口带来新问题:窗口边缘的音频特征可能不完整,导致动作突变。解决方案是重叠窗口(overlap-add)或渐变混合:相邻窗口的输出帧按权重混合,避免跳变。这需要额外的 GPU 内存和计算开销,但对体验至关重要。
环形缓存与状态管理
实时 avatar 不能每帧都从头生成,必须维护一个状态缓存:包括历史帧的特征、音频上下文、模型内部隐藏状态等。环形缓存(ring buffer)是常用数据结构,它用固定大小的数组循环存储最近 N 帧的状态,避免无限增长的内存占用。
状态管理的难点在于一致性:当用户打断、切换话题或网络抖动导致音频中断时,缓存中的旧状态可能与新输入不匹配。好的实现会检测这种不一致并主动重置状态(如插入过渡帧或短暂静态头像),而不是让模型强行衔接导致崩坏。
异步队列与背压控制
实时链路中,音频接收、特征提取、模型推理、视频编码、网络发送是并行流水线。如果某个环节变慢(如 GPU 负载高导致推理延迟增加),上游环节会继续产生数据,下游环节会积压,最终导致缓冲溢出或延迟飙升。背压控制(backpressure)机制会在队列满时通知上游降速或丢帧,而不是无限堆积。
实践中,背压策略需要和业务优先级结合:语音交互场景中,最新音频比历史音频更重要,可以丢弃旧帧;直播场景中,画面连续性比实时性更重要,可以增加缓冲但降低码率。没有通用的最优策略,只有针对场景的权衡。
LivePortrait 与 Ultralight-Digital-Human:实时能力的两极
在实时数字人生态中,LivePortrait 和 Ultralight-Digital-Human 代表了两种不同的设计哲学,适用于截然不同的场景。
| 维度 | LivePortrait | Ultralight-Digital-Human |
|---|---|---|
| 定位 | 高质量肖像动画 | 超轻量移动端数字人 |
| 模型大小 | ~200MB | ~10MB |
| 推理延迟 | 30-50ms(GPU) | <20ms(CPU/移动GPU) |
| 画质 | 高(接近照片级) | 中(卡通化或低分辨率) |
| 全身支持 | 否(仅面部) | 否(仅面部) |
| 部署环境 | 服务器 GPU | 手机、嵌入式、浏览器 |
| 适用场景 | 云端实时客服、直播助理 | App 内置 avatar、AR 滤镜、离线演示 |
LivePortrait 的优势是画质和表情细腻度,适合对真实感有要求的云端服务;Ultralight-Digital-Human 的优势是极低资源消耗,可以在手机上实时运行,适合 C 端 App 或边缘场景。选型时不要只看"哪个效果更好",而要看"我的部署环境和用户设备是什么"。如果目标是微信小程序里的数字人客服,Ultralight 路线可能比 LivePortrait 更实际;如果目标是企业级视频会议数字人,LivePortrait 配合 WebRTC 推流才是正解。
WebRTC 传输层:被低估的体验瓶颈
许多团队把全部精力放在模型优化上,却忽略了传输层对体验的决定性影响。即使模型能在 30ms 内生成一帧,如果网络传输增加 200ms 抖动,用户感知到的延迟仍然是 230ms。
WebRTC 是实时数字人的事实标准传输协议,但它本身不提供"数字人友好"的保障。几个关键点:
- 自适应码率:网络差时自动降低视频分辨率和帧率,保证音频优先。数字人场景中,音频清晰度比画面更重要,因为用户主要靠听获取信息。
- 边缘部署:将推理节点部署在离用户最近的 CDN 边缘,减少 RTT。国内业务建议至少覆盖华北、华东、华南三个区域。
- 客户端缓冲策略:播放器缓冲太小会导致卡顿,太大会增加延迟。动态缓冲算法根据网络状况实时调整,目标是在"流畅"和"实时"之间找到平衡点。
- FEC 与重传:前向纠错(FEC)比 TCP 重传更适合实时场景,因为它不需要等待 ACK,但会增加带宽开销。数字人视频通常可以容忍少量丢帧,但不能容忍长时间卡顿。
Self-Forcing 关注自回归视频生成中的 training-inference gap。训练时模型常常看见更“干净”的历史帧,推理时却必须依赖自己生成过的帧;误差会沿时间积累,造成闪烁、身份漂移和动作崩坏。Self-Forcing 将模型自己的生成轨迹纳入训练,使模型学会处理推理时真实会遇到的历史状态。#Zhou-et-al.-2025-Self-Forcing
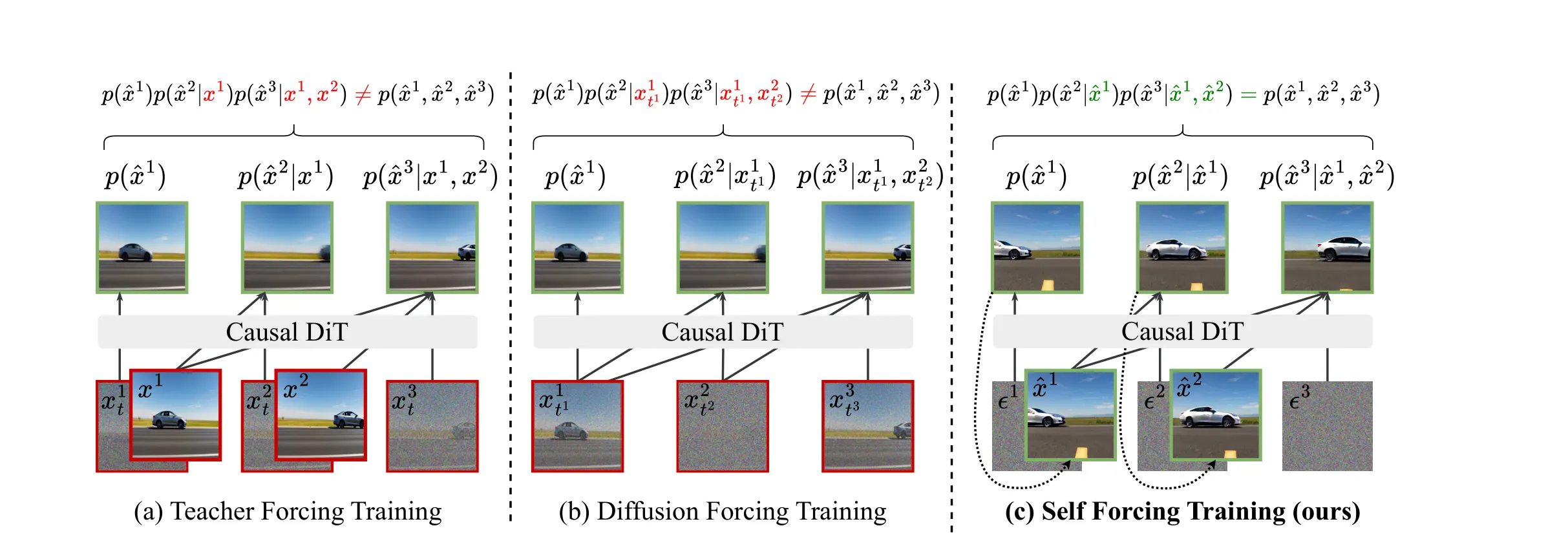
这对数字人尤其重要。实时 avatar 的每一帧都可能成为下一帧的条件,嘴型错误、头动抖动、身份漂移都会被后续帧继承。如果只在短 clip 上评估,很容易低估长对话中的漂移风险。
Self-Forcing 的实测数据说明这种训练-推理对齐能直接转化为系统收益:在单张 H100 上它把延迟从基线 Wan2.1 的上百秒压到约 0.45–0.69 秒,吞吐量达到约 17 FPS,相当于约 150× 的端到端加速,同时生成质量(VBench 等指标)持平甚至略优。值得一提的是,它与同样用少步扩散的 CausVid 有本质区别:CausVid 让模型去匹配 teacher/diffusion forcing 产生的“非真实推理”分布,而 Self-Forcing 在训练中走自己的自回归 rollout,匹配的是推理时真正会遇到的分布,因此能从根本上抑制误差累积,而不是把误差换个地方。对做长对话 avatar 的团队来说,这正是“demo 很顺、上线越聊越崩”这一典型问题的对症解法。#Zhou-et-al.-2025-Self-Forcing
| 技术 | 解决瓶颈 | 对数字人的意义 |
|---|---|---|
| Streaming | 等待完整输入导致的首帧延迟 | 边听边生成,支持打断 |
| DMD / 少步蒸馏 | 多步采样慢 | 压低每帧/每片段生成时间 |
| Self-Forcing | 长时序误差积累 | 提升长对话稳定性 |
| 缓存与状态管理 | 重复计算和状态漂移 | 支撑持续在线会话 |
四个检查问题
- 首帧延迟:用户开始说话后多久看见 avatar 响应?
- 持续延迟:长对话中是否稳定低延迟?
- 漂移控制:一分钟后身份、嘴型和表情是否仍稳定?
- 吞吐成本:一个 GPU 能支撑几个并发会话?
下一篇会把这些模型和系统能力转化成选型表:轻量换嘴、中量 talking head、重量整帧 avatar 和系统级实时平台分别适合什么业务。
参考来源
- LiveAvatar project page. Project page
- NVIDIA LongLive-2.0 project page. Project page
- NVIDIA Research. LongLive-2.0 technical report / paper materials. Official materials
- Xu, S. et al. (2024). VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time. arXiv:2404.10667
- Prajwal, K. R. et al. (2020). A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild. arXiv:2008.10010
- Yin, T. et al. (2024). One-step Diffusion with Distribution Matching Distillation. arXiv:2311.18828
- Yin, T. et al. (2024). Improved Distribution Matching Distillation for Fast Image Synthesis. arXiv:2405.14867
- Zhou, X. et al. (2025). Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion. arXiv:2506.08009
- NVIDIA. TensorRT optimization for real-time inference. TensorRT documentation
- WebRTC Working Group. Real-time communication and optimization techniques. WebRTC official resources
- Jacob, B. et al. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. arXiv:1712.05877