CompTok:通过双量化器解耦语义与像素特征
我的研究方向是:以码本为核心设计高效的图像表示方法。核心思路是将图像编码为离散 token 序列,通过可学习的码本在离散空间中完成特征的紧凑表示。我关注的主要问题有两个:
- 如何设计码本及码本所采用的量化策略。
- 如何把原始特征信息高效地进行量化。
核心困难:语义与细节的解耦
然而,图像中包含了两种不同类型的信息:
- 语义信息:图像的内容和类别("是什么"),如"这是一只猫"、"这是一个房间"——这类信息抽象、全局,但对像素级的精确度要求不高
- 细节信息:图像的纹理和结构("长什么样"),如毛发的走向、光影的渐变——这类信息具体、局部,但对重建质量至关重要
在高效压缩的场景下,我希望在有限的 token 数量内同时保留这两类信息。但现有的单码本方案将所有 token 混在一起量化,无法区分哪部分 token 负责语义、哪部分负责细节。这导致一个两难困境:如果你追求高压缩比(少 token),语义保留好了但细节丢失严重;如果你追求细节保真度(多 token),又失去了压缩的意义。
理想的做法是:在有限的 token 预算内,让一部分 token 专心承载语义,另一部分专心承载细节。两者在码本层面就是分离的。
CompTok 建立在 TiTok 的 1D tokenizer 框架之上。TiTok (NeurIPS 2024) 的核心贡献是把传统图像 tokenizer 的 2D 空间 grid 表示(如 256×256 图像 → 16×16 = 256 个 patch-aligned tokens)替换为 1D latent sequence,将一张 256×256 图像压缩到仅 32 个离散 token。
TiTok 最大的优势在于,它将一张图片转成了一维的结构——这就像用一段语义稠密的"话"来描述这张图片。每个 token 不局限于固定的空间位置,而是汇聚全局信息,因此可以用更少的 token 表达图像的语义内容。但代价是,这种"高度概括"不可避免地会丢失细节信息——就像一段话可以准确描述"一只橙猫坐在窗台上",但无法精确还原每一根毛发的走向和光影的渐变。
TiTok 的架构

graph TB
subgraph Enc[编码 Enc]
A[输入图像] --> B[Patchify]
B --> C[patches]
C --> D[ViT Encoder]
E[可学习的 latent tokens
K 个] --> D
D --> F[K 个 latent tokens]
end
subgraph VQ[量化 VQ]
F --> G[Codebook lookup]
G --> H[K 个离散索引]
end
subgraph Dec[解码 Dec]
H --> I[ViT Decoder]
J[mask tokens] --> I
I --> K[重建图像]
end
关键设计在于 latent tokens:编码器输入时除了图像 patch 序列,还拼接了 K 个可学习的 token embedding。经过 ViT 的自注意力编码后,这些 latent tokens 汇聚了全局图像信息,而图像 patches 则被丢弃。解码时再将 K 个量化后的 latent tokens 与 mask tokens 一起送入 ViT 解码器,一次性 unmask 所有 mask token,在单次前向中完成整张图像的重建。
详细的 TiTok 综述和演进路线参见:TiTok 与 1D Visual Tokenizer:研究现状与演进方向。
TiTok 的局限
这种语义稠密的 1D 表示本质上是在用有限的 token 容量去同时表达语义和细节两类信息。但由于所有 token 共享同一个码本,码本中的码字必须同时兼顾语义抽象和像素保真——这导致了一个两难的选择:追求语义压缩就会牺牲细节重建,追求细节保真又会稀释语义表达的密度。
这带来了 CompTok 的核心动机:
换句话说,CompTok 希望将 TiTok 的单码本、全压缩范式扩展为双量化器、可调节范式——不是简单地压缩图像,而是有选择地保留不同类型的信息。
CompTok 的核心是一个双量化器结构——这是我基于当前想法设计的最简单的基线架构:
- 输入图像经过 Patchify 得到 $N$ 个 patches,并额外添加 $M$ 个可学习的 semantic tokens
- 所有 $N + M$ 个 tokens 一起通过 共享 Encoder,利用自注意力让语义 token 与图像 token 相互交换信息
- Encoder 输出的 tokens 分为两路:
- $N$ 个 image tokens → Image Quantizer(像素级码本)
- $M$ 个 semantic tokens → Semantic Quantizer(语义级码本)
- 两组量化后的 tokens 拼接,送入 Decoder 重建图像
graph TB
subgraph Enc[编码 Enc]
A[输入图像] --> B[Patchify]
B --> C[patches]
C --> D[Shared ViT Encoder]
E[semantic tokens
M 个] --> D
end
D --> F
D --> G
subgraph Img[图像量化]
F[image tokens N 个] --> H[Random Mask
visible 比例 = v]
H --> I[Image Quantizer]
end
subgraph Sem[语义量化]
G[semantic tokens M 个] --> J[Semantic Quantizer]
end
subgraph Dec[解码 Dec]
I --> K
J --> K[Concat]
K --> L[Decoder]
L --> M[重建图像]
end
v 参数:通过随机 mask 控制压缩率
在训练和推理过程中,为了能让模型以不同的 bits per pixel (bpp) 工作,我对 image tokens 施加一次随机 mask。参数 v 表示 mask 后的 visible 比例:
其中 $N_{\text{total}}$ 是 image tokens 的总数,$N_{\text{visible}}$ 是随机 mask 后保留的 image token 数量。当 $v = 1.00$ 时,所有 image tokens 都可见,重建质量最高但 bpp 最大;当 $v = 0.00$ 时,所有 image tokens 都被 mask 掉,只有 semantic tokens 参与重建,bpp 最小但细节损失最大。
需要强调的是,这只是一个最基本、最朴素的设计——我没有对两个码本之间的关系做任何特殊的设计,也没有引入额外的对齐或交互机制。后续实验将检验:即使在这种最简单的双量化器设计下,语义-细节解耦是否至少不会损害重建效果?以及这种设计能否让 TiTok 支持单模型多 bpp 的灵活压缩?
为了验证这种最简单的双量化器解耦是否可行——或者说,至少不会损害重建质量——我进行了一组 v 参数扫描实验。固定模型结构,只改变 image tokens 的随机 mask 比例。使用 LPIPS 作为重建质量的评估指标。
更重要的是,通过这种设计,TiTok 首次具备了用一个模型处理不同 bpp 下图像 token-based 压缩的能力:只需要在推理时调节 v,就能在压缩率和重建质量之间连续切换,无需为每个 bpp 训练独立的模型。

| 实验配置 | v(mask 后 visible 比例) | BPP↓ | LPIPS↓ | 说明 |
|---|---|---|---|---|
maskgit | 1.00 | 0.0391 | 0.1963 | 标准 VQ baseline;无 latent tokens |
mtok/s1/v~0.00 | 0.00 | 0.0117 | 0.3016 | 所有 image tokens 被 mask,仅语义 token |
mtok/s1/v~0.25 | 0.25 | 0.0234 | 0.2436 | 25% image tokens 可见 |
mtok/s1/v~0.50 | 0.50 | 0.0352 | 0.2163 | 50% image tokens 可见 |
mtok/s1/v~1.00 | 1.00 | 0.0586 | 0.1926 | 全部 image tokens 可见 |
titok/s1 | 0.00 | 0.0117 | 0.3433† | 1D Tokenizer(仅 71k 步) |
BPP 按 256×256 图像估算;MTok 计入 64 个 semantic tokens 与 v × 256 个 visible image tokens。MaskGIT 的 v 仅作全像素 token 可见的类比标注,它没有额外 latent tokens;TiTok 对应仅 latent tokens 的 1D tokenizer,表中记作 v=0.00。† titok/s1 仅训练到 71k 步,未完全收敛。
关键发现
- 解耦至少不损害重建:v = 1.00(全图像 token)时,双量化器结构的 LPIPS = 0.1926,略优于标准 MaskGIT baseline 的 0.1963。说明简单地分出独立语义量化器并没有破坏重建能力,反而可能因共享 Encoder 的信息交换而微幅提升。
- 单调的率失真曲线:v 从 0.00 → 0.25 → 0.50 → 1.00,LPIPS 从 0.3016 单调下降到 0.1926。v 可以作为单个连续参数控制整个率失真曲线。
- 单模型覆盖多 bpp:仅需训练一个模型,推理时通过调节 v 即可在 0 ~ 最大 bpp 之间切换——这是传统固定 token 数量的 tokenizer 做不到的。
- 完全 mask 的退化下限:v = 0.00 时 LPIPS = 0.3016,比 MaskGIT 的 0.1963 差距明显——这本身就是合理的:语义 token 本就不以重建为目的,丢失像素信息是预期的行为。
失败的尝试:多步推理的不可行性
在完成 v 参数扫描后,我曾希望更进一步——在推理阶段通过多步推理来逐步优化生成效果。但直到开始写代码才发现,这在 TiTok 的框架下是不可能的。
原因在于 TiTok 的两阶段训练策略:
- 第一阶段:以预训练好的 MaskGIT-VQGAN 的码字作为训练目标,通过 CE loss 训练 tokenizer
- 第二阶段:直接训练一步重建——latent tokens + mask tokens → 一次性输出完整图像
由于第二阶段训练的存在,decoder 已经失去了对逐步重建被 mask 的码字的能力——它只学会了"看到 mask 就一次性补全"。要想实现推理时的多步迭代优化,必须抛弃第二阶段训练,但这又意味着 decoder 永远学不会高质量重建。
CompACT Tokenizer:相同的思路,已经做出来了
后来我发现,CompACT Tokenizer(Kim et al., 2026)基本上已经把我的想法实现了。它的实现思路与我几乎完全一致,但已经先做出来了。站内文章:CompACT Tokenizer:面向决策时规划的紧凑潜空间世界模型。
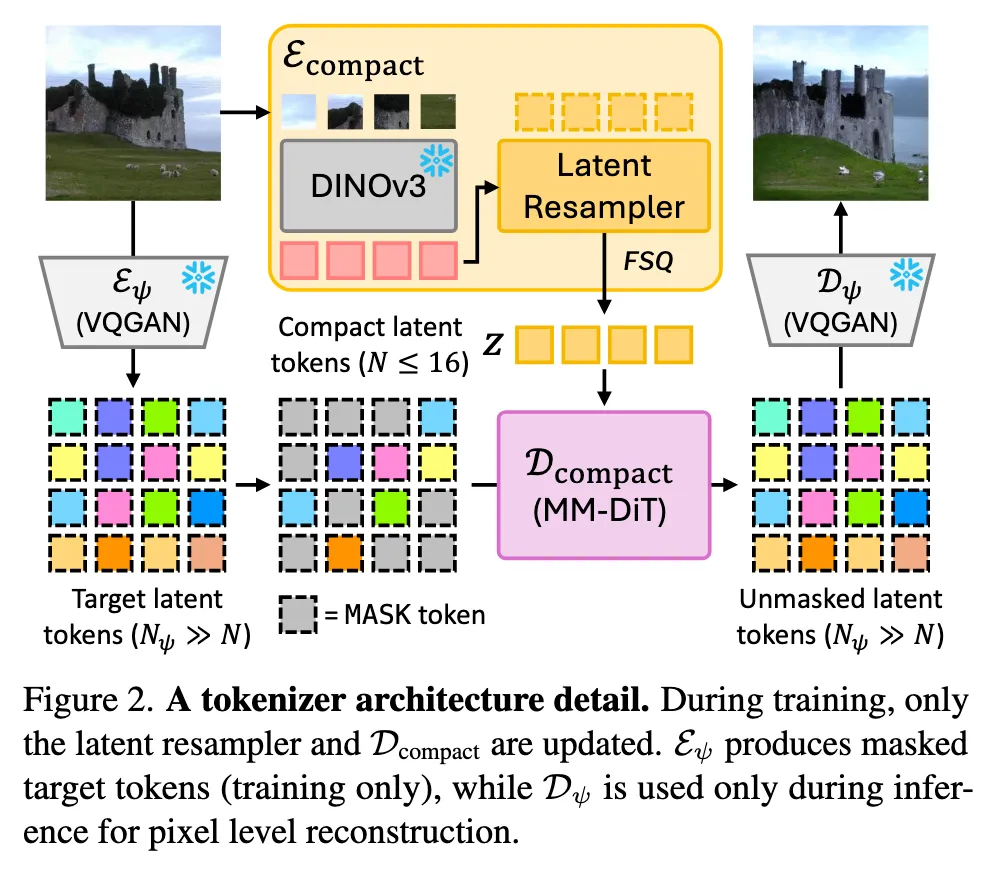
CompACT 的核心设计:
- Encoder 解耦:使用冻结的 DINOv3 提取语义特征,通过 Latent Resampler(交叉注意力)聚合为少量紧凑 token
- 生成式解码:引入 MaskGIT-VQGAN 的 latent tokens 作为中间表示,compact token 通过生成式解码(而非直接重建)恢复像素信息——但因为面向机器人领域,它不需要重建细节,只要语义信息足够做决策就行
- 舍弃 VQGAN Decoder 训练:训练时只更新 Latent Resampler 和 Dcompact,VQGAN 的编码器 Eψ 只用于产生掩码目标 token,解码器 Dψ 仅在推理时固定使用——这是"抛弃第二阶段训练"想法的工程化实现
当前 CompTok 的最简设计暴露了两个主要局限:
- Encoder 未解耦:用一个共享 Encoder 同时提取语义和图像特征,两种不同性质的信息在编码阶段就混合在一起
- Quantizer 之间缺少对齐:两个码本是完全独立量化的,它们之间没有任何交互或对齐机制来协调各自承担的信息量,如何分配完全由 v 硬编码
更先进的基于 token 的方法(TokenFlow、SemHiTok)在 Encoder 和 Quantizer 层面都做出了解耦设计——但它们的目标是统一理解与生成 (UMM),而非压缩。CompTok 可以从中借鉴思路,用于图像压缩。
TokenFlow:双编码器 + 共享映射
TokenFlow (ByteDance, CVPR 2025) 的核心在于 Encoder 端的彻底解耦。完整解读见站内文章:TokenFlow:双码本共享映射实现统一多模态理解与生成。

TokenFlow 在 Encoder 端的设计要点:
- Semantic Encoder:从预训练的 CLIP/SigLIP 初始化,保持 unfrozen 以持续适应 tokenizer 训练
- Pixel Encoder:标准的卷积编码器,专注低层视觉特征
- 共享映射:两个码本使用相同的索引映射,保证同一位置产生一致的 code 索引——这建立了一种隐式的量化器耦合
SemHiTok:冻结语义编码器 + 层级码本
SemHiTok (中山大学 × 华为, ICLR 2026) 则选择了另一条路线——冻结语义编码器,在码本端做层级分解。完整解读见站内文章:SemHiTok:语义引导的层级码本。

SemHiTok 的设计要点:
- 冻结的语义编码器(SigLIP):与 TokenFlow 的 unfrozen 策略相反——SemHiTok 认为冻结才能保持语义空间的稳定性
- SGHC 层级码本:先确定语义 code,再在对应 sub-codebook 内量化像素——这是 Quantizer 端的一种显式的层级解耦
- 分阶段训练:先训练语义码本,冻结后再训练像素 sub-codebooks,避免梯度冲突
DecQ:反其道而行之,从语义模型浅层提取细节

与 SemHiTok 冻结语义编码器、只用深层特征的思路不同,DecQ(Detail-Condensing Queries)走了完全相反的路线——它同样冻结预训练视觉基础模型(VFM),但通过 cross-attention 从 VFM 的 中间层/浅层 提取细粒度信息来补充深层语义的缺失。
DecQ 的核心发现是:
- VFM 的深层特征包含丰富语义但丢失了颜色、纹理等低层细节
- VFM 的浅层特征保留了图像细节但语义不够抽象
- 通过一组可学习的 detail-condensing queries 对 VFM 各层做 cross-attention,可以同时获取深层语义 + 浅层细节,且不修改 VFM 的任何参数
具体来说,DecQ 在冻结的 VFM 编码器(如 DINOv2)上引入少量(仅 8 个)可学习的查询向量,通过 cross-attention 从 VFM 的中间特征图中提取细节信息。这些查询的预测被联合到生成过程中——不仅用于重建,还参与扩散去噪——从而在不破坏语义空间的条件下同时改善了重建和生成质量:PSNR 从 19.13 dB 提升到 22.76 dB,且生成训练加速 3.3×。
MagVIT-v2:Lookup-Free Quantization (LFQ)
除了 Encoder 和码本耦合策略的差异,最近的工作在 Quantizer 本身的形式 上也做出了根本性的改变——从基于查找的 VQ 转向 lookup-free 的二元量化。站内文章:MAGVIT-v2:Lookup-Free Quantization 与因果 tokenizer、Infinity:Bitwise AR 与无限词表。

MAGVIT-v2 (LFQ) 的核心创新是 Lookup-Free Quantization。传统 VQ 需要计算 latent vector 与所有码本的 L2 距离(O(Kd) 复杂度),LFQ 则将码本空间分解为 log₂K 个独立二元变量——每维只取 -1 或 +1。量化的唯一操作是 sign() 函数,复杂度 O(d)。这使得词表可以轻松扩展到 2^18 = 262K 而计算成本几乎不变。
Infinity:Binary Spherical Quantization (BSQ)
Infinity 在 LFQ 的基础上进一步做了两个重要的扩展:


- Binary Spherical Quantization (BSQ):在 LFQ 的基础上引入 L2 归一化,编码器输出在归一化后做 sign() 量化。d=64 时词表达到 2^64,重建 rFID 首次超越连续 SD VAE
- Bitwise Self-Correction (BSC):训练中随机翻转部分 bits 模拟推理错误,迫使模型学会识别和纠正错误。这个机制天然适合抗噪压缩场景——在压缩传输过程中 bits 可能翻转,BSC 学习的正是这种纠错能力
- 直接输出二进制编码:BSQ 的每个维度输出为 -1 或 +1,等价于二进制 0/1。这意味着压缩后的表示本身就是 bitstream,无需额外的熵编码
EF-LIC:无熵编码的固定长度量化
EF-LIC(清华团队, 2026)从一个完全不同的角度切入 Quantizer 的设计——它关心的不是量化后的 tokens 如何表示语义或细节,而是量化后的索引如何变成比特流。

EF-LIC 的实践方案是:将编码器输出分组,前几组用大码本(1024),后几组用小码本(128),每组使用 RVQ 残差量化。由于每组索引分布趋近均匀,可以直接用固定长度编码拼接成比特流,无需任何熵编码。最终实现 67.86% BD-rate 降低,编码加速 10 倍,解码 67 倍。
回顾三个 Part 的核心启示:在 Encoder 端,TokenFlow 的双编码器、SemHiTok 的冻结编码器、DecQ 的跨层特征提取,分别代表了三种不同的解耦策略;在 Quantizer 端,LFQ 和 BSQ 将量化从 O(Kd) 的查表简化为 O(d) 的符号函数,而 EF-LIC 则从编码端证明了固定长度量化的理论可行性。它们共同指向一个方向:更简单、更可并行化的量化与编码方案,正在逐步取代传统的熵编码 + VQ 组合。CompTok 可以在这些思路之上,探索语义-细节分离与无熵编码的统一框架。
待完成的实验
- 与 SemHiTok / TokenFlow 的系统对比:在相同分辨率、相同 LLM backbone 下比较 rFID 和理解指标
- v 的连续控制:如果 v 可以在推理时调节,CompTok 将成为一个"可伸缩"的统一 tokenizer——理解任务用低 v,生成任务用高 v
开放问题
- 两个码本的容量分配:Image Quantizer 和 Semantic Quantizer 各自需要多少码字?码本容量是否能够随 v 动态调整?(如果使用的是 LFQ 的话。
- 共享 Encoder vs 独立 Encoder:当前设计使用共享 Encoder,让两组 token 通过自注意力交换信息。如果换成独立 Encoder,效果应该会更好?
- v 与任务的适配:是否可以在训练中引入一个可学习的门控,让模型自动决定每个 image token 的 mask 策略?
说实话,虽然做了很久的实验,但是因为一直不知道应该如何去做,所以进展其实基本等于没有。目前 CompTok 的研究还处于一个相当初级的阶段。完成 v 参数扫描实验后,对于接下去怎么走,我其实心里也有些迷茫。
Encoder 的选择
看了最新的论文(TokenFlow、SemHiTok、DecQ),直觉上 Encoder 可能确实需要拆成两个独立的模块——一个负责语义,一个负责细节。但有一个现实的问题:图像压缩需要考虑时间成本和计算成本。双编码器意味着近两倍的编码计算量,对于压缩场景来说能够接受吗?Encoder 的解耦到底值不值得付出这个代价?
Quantizer 的选择
Quantizer 层面,LFQ 的方向看起来很有吸引力——它不仅消除了查表操作、直接输出二进制编码,而且可以通过编码长度(bit 数)天然控制信息容量。如果把 CompTok 的双量化器结构换成 LFQ,v 的含义可能不再是 token 级别的 mask,而是 bit 级别的 mask——对于同一个 token 的不同 bits,可以分别控制哪些 bits 可见、哪些被 mask。这使得压缩率的调节更加细粒度,也更接近率失真优化的本质。
一个可能的新方向:抗噪压缩
坦率地说,我在目前的研究方向上积累了太多的失败感,而且思路有些固化了,并且我感觉做到现在基本上什么像样的成果也没有。继续沿着原来的思路做,可能也没办法提出真正有效的想法。而且看了这些最新的进展,我感觉一方面我不知道怎么改进,另一方面我现在的进度也完全追不上。我在想,是不是可以转换一下思路,直接放弃目前的思路,转做新的方向。
这个方向的核心问题变为:如何在编码端以最少的 bits 保留语义和细节信息,使得在传输过程中即使部分 bits 受损,解码端仍能恢复出可用的图像——而不是追求极致的无损重建。这可能是一条更务实、也更有实际应用场景的路线。
但这只是现阶段的一些不成熟的想法。
参考来源
- SemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook (Chen et al., ICLR 2026)
- TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation (Qu et al., 2024)
- VILA-U: Towards a Unified Foundation Model for Visual Language and Generation (Wu et al., 2024c)
- Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation (Wu et al., 2024a)
- SDE: Semantic-Decoupled Encoder for Unified Image Tokenizer (Xie et al., 2025)
- MaskGIT: Masked Generative Image Transformer (Chang et al., CVPR 2022)
- TiTok: 1D Tokenizer for Efficient Image Generation (Yu et al., 2024)