数字人论文精读(二十三):LAM,单图生成可动画 Gaussian 头像的纯 3D 实时管线
从一张照片生成可被任意表情驱动的 3D 数字人,是视频会议、直播、游戏和 AR/VR 的核心需求。这个任务看似简单,实则面临一个根本矛盾:高质量重建需要大量数据,而实时动画要求极简管线。
过去两年的技术路线大致分三条。2D 方法(StyleHEAT、Diffusion-based)生成快但缺乏显式 3D 结构,极端姿态下容易失真且无法自由视点。NeRF 方法(GPAvatar、Portrait4D-v2)几何一致性好,但渲染速度仅 4–20 FPS,难以实时部署。3D Gaussian Splatting 方法(GAGAvatar)兼顾质量与速度,却依赖 2D neural post-processing 网络做最终 refinement——这意味着它不是纯 3D 方案,也无法直接集成到传统渲染管线或移动端。
LAM(Large Avatar Model)#He et al., 2025 给出了肯定回答。它从单张图片出发,通过一次前向传播生成 canonical space 中的 3D Gaussian avatar,随后用标准 FLAME LBS + blendshapes 动画——整个过程没有任何额外的神经网络或后处理步骤。在 A100 上达到 280.96 FPS,在 iPhone 16 上通过 WebGL 达到 35 FPS,同时在 VFHQ 和 HDTF 基准上全面超越现有 SOTA。
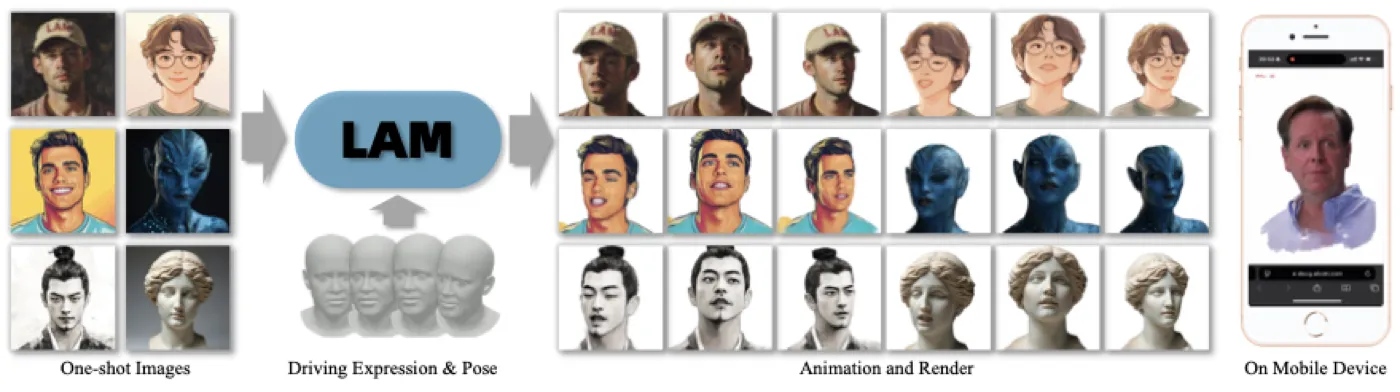
要理解 LAM 的设计动机,需要先看清三条技术路线各自卡在哪里。
2D 方法:没有 3D 就没有自由
2D 方法用 warping field 或 diffusion model 直接在像素空间合成新表情。它们的问题根植于表示本身:没有显式 3D 结构,就无法保证多视角一致性,也无法在大姿态变化下保持身份稳定。即使引入 3DMM 作为条件(如 SadTalker),也只是"借用"3D 信息做引导,最终输出仍是 2D 图像,无法接入传统 3D 渲染管线。
NeRF 方法:质量换速度
NeRF 路线(GPAvatar #GPAvatar, 2024、Portrait4D-v2 #deng2024portrait4d2)用隐式神经场建模几何与外观,几何一致性和细节表现力优秀。但 volume rendering 的计算复杂度决定了其 FPS 上限:GPAvatar 在 A100 上仅 4.23 FPS,Portrait4D-v2 为 9.62 FPS。对于需要实时交互的场景,这个数字远远不够。
GAGAvatar:快了,但不纯
GAGAvatar #GAGAvatar, 2024 是首个 one-shot 3DGS 头像方法,A100 上达 67.12 FPS,质量也不错(PSNR 21.83)。但它有一个关键妥协:生成的 Gaussian avatar 需要经过一个 2D neural post-processing 网络 才能得到最终结果。这带来两个问题:(1)额外的 NN 使得整个管线无法直接集成到 WebGL/OpenGL 等传统渲染管线;(2)后处理网络的计算开销限制了移动端部署的可能性。
LAM 的 Insight
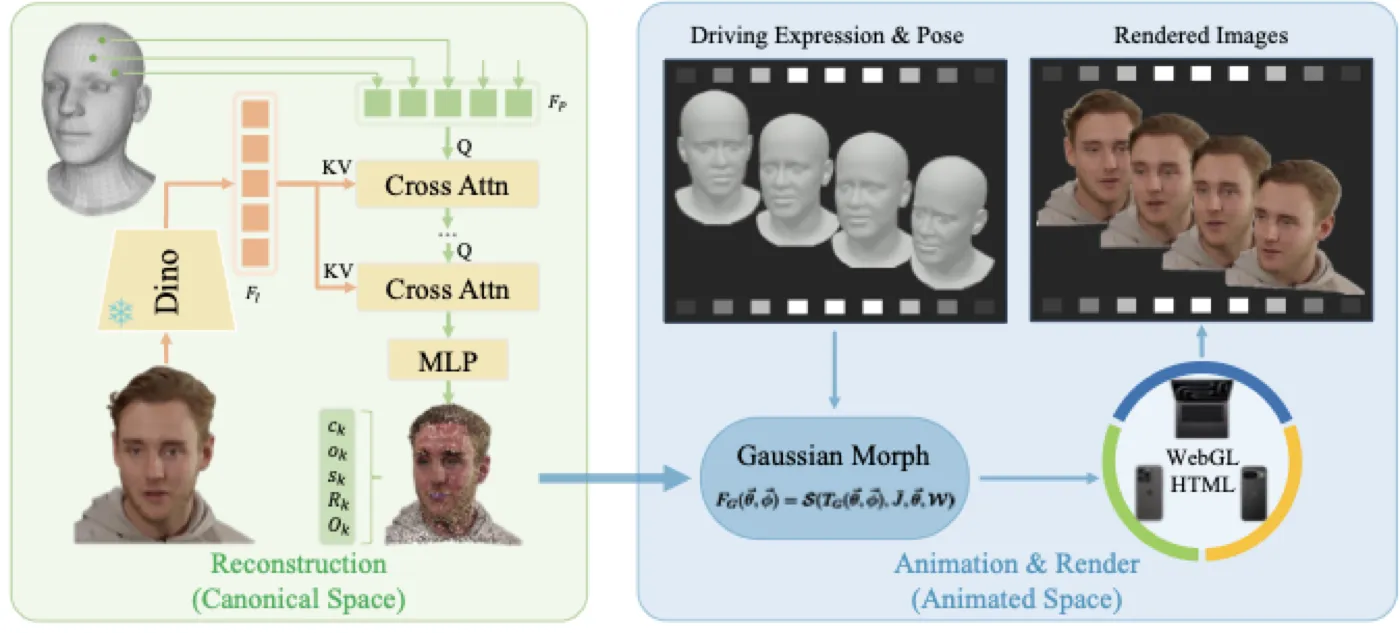
这个 insight 将问题从"如何用一个 NN 去 deform Gaussian"转化为"如何让 Gaussian 天然可被 LBS 动画"。代价是需要解决一个新问题:如何从单张图片准确预测 canonical space 中 8 万多个 Gaussian 的属性?LAM 用 Transformer cross-attention + DINOv2 多尺度特征来回答这个问题。
LAM 的方法可以概括为三个关键设计决策的组合。我们逐一拆解。
设计一:显式点云 + FLAME 形状先验
之前的 one-shot 方法(GAGAvatar、LGM #LGM)普遍使用 tri-plane 隐式表示来编码 3D 形状。Tri-plane 的优势是紧凑,但劣势同样明显:它是纯学习的表示,不包含任何人脸几何先验。模型必须从零学会"鼻子在哪里、眼睛是什么形状",这在单图条件下极其困难。
LAM 的做法截然不同:直接用 FLAME 模型的 canonical vertices 作为 Gaussian 点的初始位置。FLAME #Li et al., 2017 是一个参数化 3D 人脸模型,其顶点分布编码了人脸拓扑、五官位置和比例等强先验。将这些顶点作为 Gaussian 的锚点,相当于告诉模型"这些点大概在脸的什么位置",大幅降低了从单图重建几何的难度。
但原始 FLAME 只有 5,023 个顶点,不足以描述头发、胡须、牙齿等细节。LAM 使用 mesh subdivision 算法进行两次细分:每次迭代在每条边的中点添加新顶点,每个三角面分裂为四个新面,同时对新顶点的 blendshapes 属性取边两端顶点的平均值。两次细分后得到 81,424 个顶点,作为 81,424 个 Gaussian 点的初始化。消融实验表明,点数从 5K 增加到 80K,PSNR 从 20.96 提升到 22.65,FPS 从 705 降到 281——80K 是质量与速度的最佳平衡点。
设计二:Canonical Space 统一重建
如果在原始姿态和表情下重建 Gaussian avatar,模型需要同时学习"这个人长什么样"和"当前是什么姿态"两个耦合的问题。更麻烦的是,不同训练样本的姿态/表情各不相同,模型必须在高度变化的输入空间中保持一致的重建质量。
LAM 选择将所有 avatar 重建在同一个 canonical space 中——即 FLAME 的标准中性表情和正面姿态。推理时,再通过确定性的 LBS + blendshapes 将 canonical avatar 动画到目标姿态。这样做有两个好处:(1)重建问题被简化为"在中性姿态下重建一个人",消除了姿态/表情变化带来的干扰;(2)动画由纯矩阵运算完成,无需额外 NN。
消融实验验证了这一设计的价值:canonical space 重建(PSNR 22.65)比直接在 reference pose 下重建(PSNR 20.96)高出 1.69 dB。
设计三:Raw Image Features Cross-Attention
有了几何锚点和统一的重建空间,下一个问题是:如何让每个 3D 点"看到"图像中对应的纹理和细节?
之前的方法(如 TransHuman #transhuman)只在"painted image features"上做 cross-attention——即先将图像特征投影到 3D 表面再查询。这种方式丢失了全局上下文信息。LAM 直接使用 DINOv2 #Oquab et al., 2023 提取的原始多尺度图像特征 作为 cross-attention 的 key/value。DINOv2 是在 1.42 亿张图片上自监督训练的 ViT,其特征同时包含局部细节(发丝、皱纹)和全局语义(脸型、肤色)。
具体实现上,LAM 冻结 DINOv2 权重,融合浅层和深层特征得到 \(F_I\)。每个 FLAME 顶点的坐标经过 NeRF-style positional encoding 后由 MLP 投影为 learnable query feature \(F_P\)。然后通过 10 层 stacked cross-attention(16 heads, 1024 dim)让点特征与图像特征交互:
其中 \(\mathcal{C}_i\) 是第 \(i\) 层 cross-attention 模块,\(F_{P_1} = F_P\)。Self-attention 建模点之间的几何关系("这个点在鼻子旁边"),cross-attention 从图像中采样对应区域的外观。最终,每个点的特征通过一个 Linear decoding header 映射为 Gaussian 属性:
其中 \(c_k \in \mathbb{R}^3\) 是颜色,\(o_k \in \mathbb{R}\) 是不透明度,\(s_k \in \mathbb{R}^3\) 是各轴 scale,\(R_k \in SO(3)\) 是旋转,\(O_k \in \mathbb{R}^3\) 是位置 offset(用于补充 FLAME 未建模的细节如头发)。消融显示,raw features(PSNR 22.65)比 painted features(PSNR 20.87)高出 1.78 dB,是所有消融中贡献最大的设计。
flowchart TD
A["Input Image 512×512"] --> B["DINOv2 (frozen)"]
B --> C["Multi-scale Features F_I"]
D["FLAME Canonical Vertices\n(81,424 points)"] --> E["PosEnc + MLP"]
E --> F["Learnable Query F_P"]
C --> G["Stacked Cross-Attention ×10\n(16 heads, 1024 dim)"]
F --> G
G --> H["Decoding Header (Linear)"]
H --> I["Gaussian Attributes\n{c, o, s, R, O}"]
I --> J["Canonical GS Avatar\nḠ = T̄ + B_S(β) + O"]
J --> K["LBS + Blendshapes\n(no NN)"]
K --> L["Gaussian Splatting Renderer"]
L --> M["Output Image"]
LAM 的训练流程围绕一个核心思路展开:从同一视频中采样多帧,用一帧重建 canonical avatar,用其余帧作为驱动目标进行监督。
数据构造
训练数据集为 VFHQ #vfhq,包含 15,204 个视频片段、约 300 万帧,涵盖多种访谈场景。对每帧执行以下预处理:(1)人脸检测并扩大 bounding box 裁剪感兴趣区域;(2)resize 到 \(512 \times 512\);(3)背景去除(跟随 GPAvatar #GPAvatar, 2024 的流程);(4)使用 GaussianAvatar #GaussianAvatar 的方法跟踪相机姿态和 FLAME 参数。
每个训练 batch 从同一视频中随机采样 \(N_f = 8\) 帧:第 1 帧作为 reference image(用于重建 canonical avatar),其余 7 帧同时作为 driving images(提供目标 FLAME 参数)和 target images(提供 RGB 监督信号)。
损失函数
总损失由四项组成:
- \(\mathcal{L}_1\):渲染 RGB 与 ground truth 的 L1 loss,保证像素级保真度
- \(\mathcal{L}_{lpips}\):感知损失,约束纹理和结构相似性
- \(\mathcal{L}_{mask}\):渲染 silhouette 与 GT mask 的 L1 loss,约束轮廓准确性
- \(\mathcal{L}_o = \|O - \epsilon\|_2\):offset 正则化,约束预测的位置偏移不要过大(\(\epsilon\) 接近 0),防止点飞散破坏 LBS 动画
超参数设置为 \(\lambda_1 = \lambda_2 = \lambda_3 = 1\),\(\lambda_4 = 0.1\)。Offset 正则权重较小,允许点在合理范围内偏离 FLAME 表面以覆盖头发等细节,同时不至于破坏动画稳定性。
优化策略
使用 ADAM 优化器 + cosine warm-up learning rate schedule,训练 200 epochs。DINOv2 backbone 全程冻结,不参与梯度更新。
训练配置披露
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 数据集 | VFHQ (15,204 clips, 3M frames) | ✅ 论文披露 |
| 图像分辨率 | 512 × 512 | ✅ 论文披露 |
| Backbone | DINOv2 (frozen) | ✅ 论文披露(具体变体未明确) |
| Transformer | 10 layers, 16 heads, 1024 dim | ✅ 论文披露 |
| Gaussian 点数 | 81,424 (FLAME subdiv 2×) | ✅ 论文披露 |
| 采样帧数 \(N_f\) | 8 | ✅ 论文披露 |
| 优化器 | ADAM | ✅ 论文披露 |
| LR Schedule | Cosine warm-up | ✅ 论文披露 |
| Epochs | 200 | ✅ 论文披露 |
| Loss 权重 | λ₁=λ₂=λ₃=1, λ₄=0.1 | ✅ 论文披露 |
| 学习率初始值 | — | ❌ 未披露 |
| Batch size | — | ❌ 未披露 |
| Weight decay / β₁, β₂ | — | ❌ 未披露 |
| Warmup 步数/比例 | — | ❌ 未披露 |
| 训练 GPU 配置 | — | ❌ 未披露 |
| 总训练时长 | — | ❌ 未披露 |
LAM 的推理分为两个阶段:一次性的 avatar 重建,和可重复的实时动画+渲染。前者需要 GPU 前向传播,后者完全是确定性的矩阵运算。
Stage 1: Canonical Avatar 重建(一次性)
给定输入图片 \(I\),DINOv2 提取特征 → Transformer cross-attention → decoding header → 得到 canonical Gaussian avatar \(\bar{G}\)。这个过程只需执行一次,耗时取决于 GPU 性能。重建完成后,\(\bar{G}\) 和预计算的关节位置 \(\bar{J} = \mathbf{J}(\vec{\beta})\) 被缓存,后续动画不再需要网络。
Stage 2: 实时动画 + 渲染(每帧)
给定目标 FLAME 参数 \((\vec{\theta}, \vec{\phi})\),动画过程完全由标准 LBS 完成:
其中 \(B_P\) 和 \(B_E\) 分别是 pose 和 expression corrective blendshapes,\(\mathcal{S}\) 是标准 linear blend skinning 函数,\(\mathcal{W}\) 是 skinning weights。这些全部是从 FLAME 继承的确定性运算,没有任何神经网络参与。动画后的 Gaussian 点直接送入 Gaussian Splatting renderer 生成输出图像。
为什么这很重要
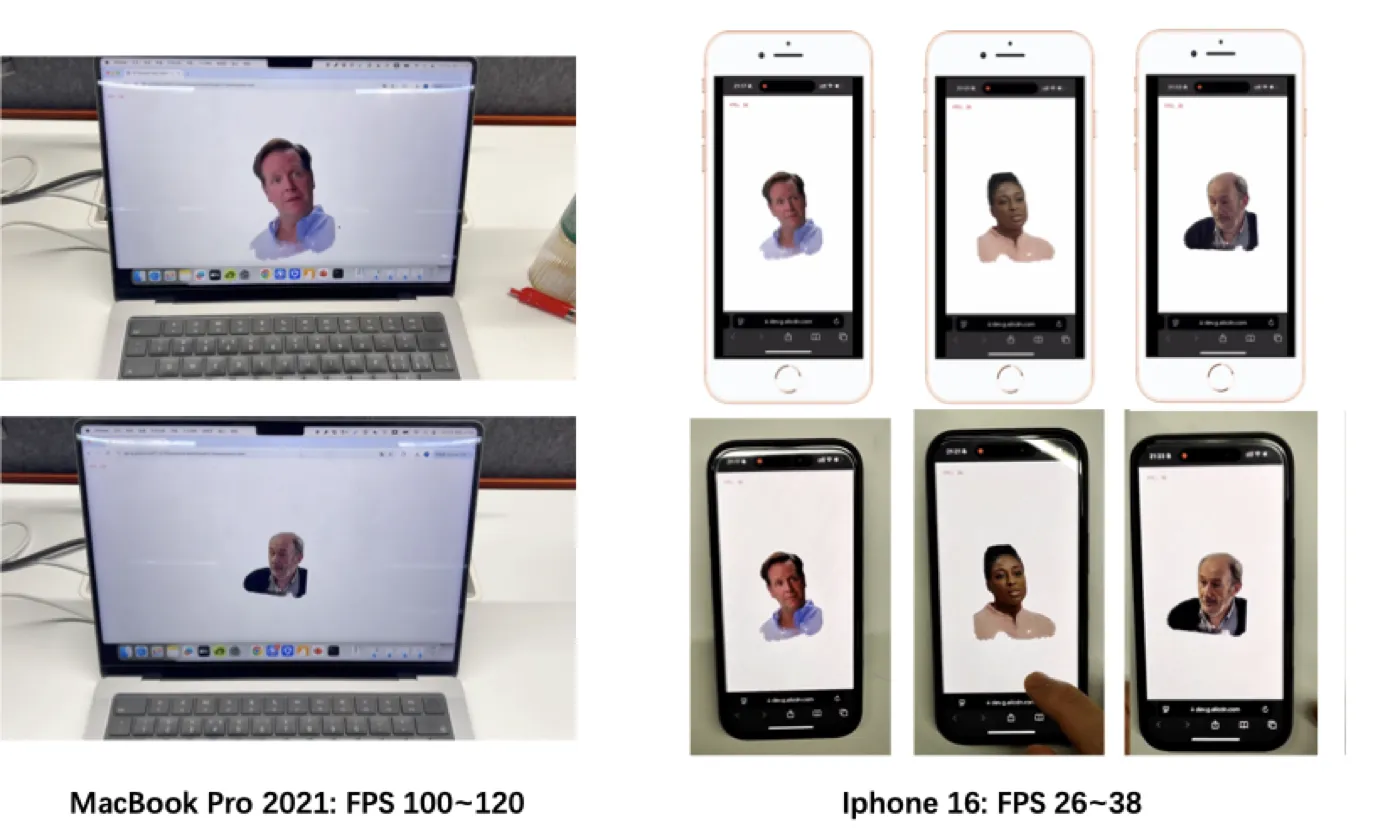
因为动画和渲染不包含任何 NN,整个管线可以直接移植到 WebGL/OpenGL/Vulkan 等传统图形 API。这是 LAM 能在移动端实时运行的根本原因——不需要 PyTorch/TensorFlow runtime,只需要一个标准的 GPU 着色器。
WebGL 跨平台部署
LAM 选择 WebGL 作为跨平台实现框架。具体工程细节:
- Blendshapes 和 LBS 信息作为 texture 传入 GLSL vertex shader
- 使用 transform feedback 进行高效 GPU 并行计算
- 自研 WebGL 版 Gaussian Splatting renderer
- 最终交付物是一个 HTML 网页 + JavaScript,可在任意现代浏览器中运行
Text/Image-to-Avatar 扩展管线
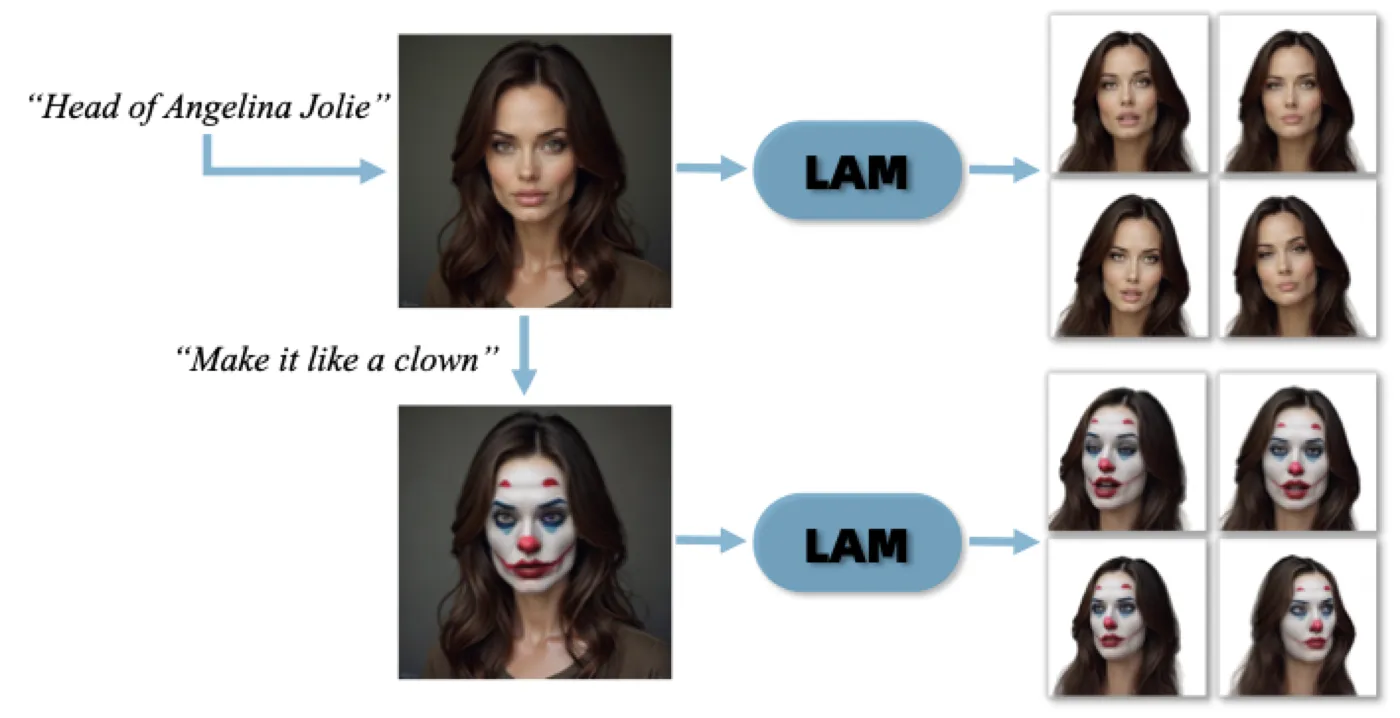
LAM 的另一个实用特性是可以无缝对接现有的 2D 生成/编辑模型:
- Text-to-Avatar:用 Stable Diffusion #stablediffusion 等 T2I 模型根据文本提示生成人像图片 → LAM 前向传播 → 可动画 3D avatar
- Style Editing:用 I2I 模型(如 InstructPix2Pix)修改输入图片的风格(年龄、卡通化、妆容等)→ LAM 重建 → 风格化的可动画 3D avatar
这之所以可行,是因为 DINOv2 的特征泛化性足够强,且 Transformer 架构在大规模数据上训练后能适应各种图像风格。不同于之前的 3D 编辑方法需要迭代训练,LAM 的风格编辑是 单次前向传播 完成的。
实验配置
| 配置项 | 值 | 披露状态 |
|---|---|---|
| 训练数据集 | VFHQ (15,204 clips, 3M frames) | ✅ 论文披露 |
| 评估数据集 | VFHQ test split + HDTF (19 clips) | ✅ 论文披露 |
| 图像分辨率 | 512 × 512 | ✅ 论文披露 |
| 推理硬件 (benchmark) | NVIDIA A100 | ✅ 论文披露 |
| 移动端测试设备 | MacBook M1 Pro, iPhone 16, Xiaomi 14 | ✅ 论文披露 |
| 推理框架 | PyTorch (GPU) / WebGL (跨平台) | ✅ 论文披露 |
| FPS 测量方式 | 排除 avatar 重建和 FLAME 估计,100 帧平均 | ✅ 论文披露 |
| 训练 GPU 配置 | — | ❌ 未披露 |
| 训练时长 | — | ❌ 未披露 |
主实验结果:VFHQ
| Method | Self Reenactment | Cross Reenactment | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | CSIM↑ | AED↓ | APD↓ | AKD↓ | CSIM↑ | AED↓ | APD↓ | |
| StyleHeat | 18.43 | 0.706 | 0.317 | 0.504 | 0.186 | 0.224 | 5.678 | 0.374 | 0.261 | 0.311 |
| GPAvatar | 21.04 | 0.807 | 0.150 | 0.772 | 0.132 | 0.189 | 4.226 | 0.564 | 0.255 | 0.328 |
| Real3DPortrait | 20.88 | 0.780 | 0.154 | 0.801 | 0.150 | 0.268 | 5.971 | 0.663 | 0.296 | 0.411 |
| Portrait4D-v2 | 21.34 | 0.791 | 0.144 | 0.803 | 0.117 | 0.187 | 3.749 | 0.656 | 0.268 | 0.273 |
| GAGAvatar | 21.83 | 0.818 | 0.122 | 0.816 | 0.111 | 0.135 | 3.349 | 0.633 | 0.253 | 0.247 |
| LAM | 22.65 | 0.829 | 0.109 | 0.822 | 0.102 | 0.134 | 2.059 | 0.651 | 0.250 | 0.356 |
LAM 在 self-reenactment 上全面领先:PSNR 比 GAGAvatar 高 0.82 dB,LPIPS 低 11%,AKD 从 3.349 降到 2.059(降幅 38%),说明关键点对齐精度大幅提升。Cross-reenactment 中 CSIM 略逊于 Real3DPortrait,但 AED 最优,表明表情驱动准确性更好。
主实验结果:HDTF
在 HDTF 数据集上,LAM 同样取得 self-reenactment 全面 SOTA:PSNR 23.43(vs GAGAvatar 23.13),SSIM 0.873(vs 0.863),LPIPS 0.097(vs 0.103)。
推理速度对比
| A100 GPU FPS | LAM 跨平台 FPS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| StyleHeat | ROME | HideNeRF | CVTHead | Real3D | P4D-v2 | GAGAvatar | LAM | MacBook M1 Pro | iPhone 16 | Xiaomi 14 |
| 19.82 | 11.21 | 9.73 | 18.09 | 4.55 | 9.62 | 67.12 | 280.96 | 120 | 35 | 26 |
这个数字说明什么?LAM 在 A100 上比 GAGAvatar 快 4.2 倍,比 Portrait4D-v2 快 29 倍。更重要的是,它是唯一一个能在移动端达到实时帧率(≥25 FPS)的方法。iPhone 16 上 35 FPS 意味着流畅的实时交互体验。
消融实验
| 设计选择 | PSNR | FPS | 分析 |
|---|---|---|---|
| LAM-5K (5,143 points) | 20.96 | 705.63 | 点数太少,无法描述头发等细节 |
| LAM-20K (20,426 points) | 21.43 | 562.97 | 中间态,质量和速度都居中 |
| LAM-80K (81,424 points) | 22.65 | 280.96 | 最佳 trade-off |
| Tri-plane query (80K) | 21.33 | 280.96 | 隐式表示不如显式点云 (-1.32) |
| Reference Pose (PE, 80K) | 20.96 | 280.96 | 非 canonical space 重建 (-1.69) |
| Painted features (80K) | 20.87 | 280.96 | painted 不如 raw features (-1.78) |
四个消融中贡献最大的两个设计是 raw image features cross-attention(-1.78 dB)和 canonical space reconstruction(-1.69 dB)。这说明"如何从图像中提取信息"和"在什么空间下重建"比"用什么查询表示"更重要。点数从 5K 到 80K 的提升也很显著(+1.69 dB),但代价是 FPS 从 705 降到 281。

核心技术对比
| 维度 | LAM | GAGAvatar | GPAvatar | Portrait4D-v2 |
|---|---|---|---|---|
| 核心表示 | Explicit GS + FLAME vertices | Image-plane tri-plane + GS | Tri-plane + NeRF | 4D NeRF |
| 形状先验 | FLAME vertices (explicit) | None (learned) | Tri-plane (implicit) | Implicit |
| 动画机制 | LBS + blendshapes (no NN) | 2D neural post-processing | Expression field (NN) | Deformation field (NN) |
| 后处理 | None | 2D refinement NN | None | None |
| FPS (A100) | 280.96 | 67.12 | 4.23 | 9.62 |
| 移动端 | ✅ WebGL | ❌ | ❌ | ❌ |
| PSNR (VFHQ) | 22.65 | 21.83 | 21.04 | 21.34 |
LAM 的独特定位在于:它是目前唯一同时满足 one-shot、纯 3D、无后处理 NN、移动端实时 四个条件的方法。GAGAvatar 速度快但不是纯 3D;GPAvatar 和 Portrait4D-v2 是纯 3D 但太慢。LAM 通过 FLAME canonical space + LBS 的设计,将动画从"神经变形"转化为"确定性矩阵运算",从根本上解决了速度与纯 3D 之间的矛盾。
局限性
已知局限
- 舌头运动:FLAME 不建模 tongue blendshapes,LAM 无法复现舌头相关表情
- 动态皱纹:消除 2D 后处理后,expression-dependent 的细节(如笑纹、皱眉纹)无法充分建模
- Expression neutralization:FLAME 表达力有限 + 单图输入,限制了中性化能力
- FLAME 估计误差传播:视频中 FLAME 参数估不准会直接影响重建质量
这些局限本质上来自两个源头:FLAME 模型的表达能力上限,以及单图输入的信息量上限。前者可以通过升级到更丰富的参数化模型(如包含舌头的 FLAME++)缓解;后者可能需要引入视频或多图输入来补充信息。
可操作的启发
- Canonical space 是一种通用的解耦策略:不仅在数字人领域,任何需要将"内容"与"变换"分离的任务(如物体重建、动作迁移)都可以考虑在 canonical space 下重建,再用确定性变换动画。这比学习一个 neural deformation field 更快、更可解释、更易部署。
- 显式几何锚点 > 隐式表示:当有可靠的形状先验可用时(FLAME、SMPL、mano 等),用它初始化显式点云比从零学习隐式表示更高效。这个思路可以推广到手部、身体等其他部位的 one-shot 重建。
- "无后处理"是工程落地的关键:学术研究往往追求指标最优而忽略部署复杂度。LAM 证明了消除后处理 NN 不仅不会显著降低质量(反而提升),还能打开移动端部署的大门。在做数字人相关工程时,应优先考虑管线的简洁性和可移植性。
- DINOv2 特征的泛化性值得充分利用:LAM 能处理 T2I 生成的图片和风格化编辑后的图片,说明 DINOv2 特征对域变化有很强的鲁棒性。在其他 3D 重建任务中,也可以考虑用 DINOv2 替代定制 encoder。
参考来源
- He, Y. et al. (2025). LAM: Large Avatar Model for One-shot Animatable Gaussian Head. arXiv:2502.17796
- Li, T. et al. (2017). Learning a model of facial shape and expression from 4D scans. ACM TOG (SIGGRAPH Asia)
- Kerbl, B. et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM TOG (SIGGRAPH)
- Oquab, M. et al. (2023). DINOv2: Learning Robust Visual Features without Supervision. arXiv:2304.07193
- GAGAvatar (2024). One-shot Animatable Gaussian Avatar Generation. Project page: aigc3d.github.io
- GPAvatar (2024). Generalizable One-shot Neural Head Avatar. Project page available.
- Ye, Z. et al. (2024). Real3D-Portrait: One-shot Realistic Portrait Animation. arXiv:2401.08503
- Deng, X. et al. (2024). Portrait4D-v2: Pseudo Multi-View Augmented 4D Representation for One-Shot Head Avatar Reconstruction.
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752
- VFHQ Dataset. High-quality face video dataset for talking head generation.
- Deng, J. et al. (2019). ArcFace: Additive Angular Margin Loss for Deep Face Recognition. CVPR 2019
- Zakharov, E. et al. (2019). Few-Shot Adversarial Learning of Realistic Neural Talking Head Models. ICCV 2019
- Zakharov, E. et al. (2019). Few-Shot Adversarial Learning of Realistic Neural Talking Head Models. ICCV 2019
- GaussianAvatar (2024). Photorealistic Animatable Human Avatars from Monocular Videos. Project page available.
- LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation. Project page available.
- TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering. Project page available.