InfiniteTalk 论文精读
上一篇 InfiniteTalk 源码解读,我们顺着 wan/multitalk.py 的生成循环,把「无限长怎么实现、音频怎么注入」这些工程问题读通了。但代码只告诉你「怎么做」,不告诉你「为什么这么做」——为什么是稀疏帧而不是逐帧?为什么朴素的图生视频模型不行?参考帧到底该从哪里采样?
这一篇,我们回到论文本身(#IT-paper,arXiv:2508.14033),把这些「为什么」补齐。论文的价值在于它做了一件代码看不到的事:先诊断病因,再开药方。它系统地分析了两个朴素方案如何失败,再用一套消融实验证明自己的设计为什么是对的。这是一篇典型的「问题驱动」论文,读起来很解气。

在进入正文前,先把这篇论文会反复出现的概念用一句话讲清楚。读者只需有基础的深度学习背景即可。
| 术语 | 一句话解释 |
|---|---|
| 视频配音(Video Dubbing) | 给一段原视频换上新音频,并修改人物动作使之与新语音同步——本质是「音频驱动的视频到视频生成」。 |
| 稀疏帧配音(论文自创) | 本文提出的新范式:不逐帧约束原视频,只保留稀疏的参考关键帧,其余画面按音频自由生成全身动作。 |
| Flow Matching | 一种扩散类生成训练范式,学习一个把「噪声」搬运到「数据」的速度场(velocity field),比传统 DDPM 预测噪声更直接、采样更快。 |
| DiT | Diffusion Transformer,用 Transformer 替代 U-Net 做扩散去噪的骨干网络。 |
| I2V / FL2V | Image-to-Video(单帧条件生成视频)/ First-Last-frame-to-Video(首尾帧条件)——本文用作对照的两个朴素 baseline。 |
| Context frames(上下文帧) | 上一块视频结尾的若干帧,作为下一块的「动量信息」注入,实现块间平滑过渡。 |
| 软条件(Soft Conditioning) | 参考帧只做「弱约束」——锚定身份但不强行复制动作,让动作能随音频自由变化。 |
传统视频配音把任务窄化成嘴部区域重绘(oral region inpainting):只改嘴,冻结头、脸、身体。#IT-paper 问题在于,静态的肢体语言会和有情绪的语音冲突——论文举的例子很传神:激情澎湃的台词配上一具僵硬的身躯,观众的沉浸感瞬间崩塌。
于是论文把任务重新形式化:给定源视频 latent $x_0$ 和目标音频 $a$,输出一段视频,让嘴型、表情、身体动作都与新音频有机同步,同时只用稀疏关键帧 $x_{ref}$ 来锚定身份、情绪节奏、标志性手势和相机轨迹。
朴素方案为什么失败:一次诚实的失败诊断
论文最精彩的部分,是它没有直接抛方法,而是先认真分析「最直观的两个做法为什么不行」。这部分对应论文 3.2 节和 Fig.2。

- I2V(只用上一块尾帧当参考):运动很灵活,但缺乏对原始关键帧的持续锚定,导致误差累积——身份逐渐偏离原演员、背景色调一块块漂移,时间越长越糟(图 2 左,frame 1500 已经面目全非)。
- FL2V(首尾帧同时约束):消除了累积误差,但走向另一个极端——模型在对应时间戳刚性复制参考帧,这与「软条件」需求矛盾,动作被锁死、无法随音频变化(图 2 右,frame 81 处动作硬切)。
- 两者的共病:都只依赖静态图像条件(I2V 一帧、FL2V 两帧),缺少应当在块间传递的动量信息,所以都有块间突兀过渡。
一个清晰的权衡(论文原话提炼)
I2V 用累积误差换运动流畅,FL2V 用运动僵硬换参考保真。InfiniteTalk 的全部设计,就是为了同时拿到「流畅」和「保真」——这正是后面 context frames 和软条件采样要解决的两件事。
底座的传承:Wan2.1 → MultiTalk → InfiniteTalk
先厘清一个容易混淆的点。论文在实现细节里明确写道:模型构建在 MeiGen-MultiTalk 之上 #MultiTalk——一个 14B 参数、支持音频驱动图生视频的 DiT。而 MultiTalk 这一前作本身又建立在阿里通义万相 Wan2.1 #Wan 之上(这层关系来自 MultiTalk 自己的论文,本文未在正文展开)。所以整条传承链是:
flowchart LR WAN["Wan2.1-I2V-14B
(阿里通义万相
通用视频扩散底座)"] --> MT["MeiGen-MultiTalk
(音频驱动多人对话
InfiniteTalk 直接前作)"] MT --> IT["InfiniteTalk
(稀疏帧配音
+ 无限长流式)"]
图 3:底座传承。InfiniteTalk 真正自己贡献的,是稀疏帧范式 + 上下文帧续接 + 软条件采样,而非从头训练视频大模型。
3.1 用 Flow Matching 建模音频驱动生成
论文采用 conditional flow matching #flowmatch 训练。直觉上,它学习一个随时间变化的「速度场」,把高斯噪声逐步搬运到真实视频分布。给定条件 $c=\{y, a, x_{ref}\}$(文本、音频、参考帧),先在噪声分布 $p$ 和数据分布 $q$ 之间做线性插值:
对应的含噪样本由 $x_t = (1-t)\,x_1 + t\,x_0$ 得到,其中 $x_1 \sim \mathcal{N}(0, I)$ 是高斯噪声、$x_0$ 是真实视频 latent。模型 $v_\theta$ 被训练去匹配「速度」$\frac{dx_t}{dt}$,目标函数为:
这就是上一篇源码里 noise_pred = latent + noise_pred * dt 那行更新的理论来源——它在用 ODE 沿速度场积分。一个很实用的训练细节:训练只需要「视频 + 它自带的音轨」,不需要成对的配音数据(同一个人说不同话的对照),这大大降低了数据门槛。
3.3 条件注入:三次拼接把一切喂给 DiT
这是方法的核心机制,对应论文式 (3)。模型把噪声 latent、上下文帧、参考帧和一个指示 mask 在不同维度上拼接成一个张量,一次性喂给 DiT:
其中 $z_1$ 在时间维拼接「干净的上下文帧 + 含噪的待生成帧」,$z_2$ 把参考帧零填充到同样时长,$m$ 是标记「哪一帧是参考帧」的 0/1 mask,最后三者在通道维拼接。这正是上一篇源码里 y = torch.concat([msk, y], dim=1) 和那个「第一帧 mask=1 其余=0」的数学原型。
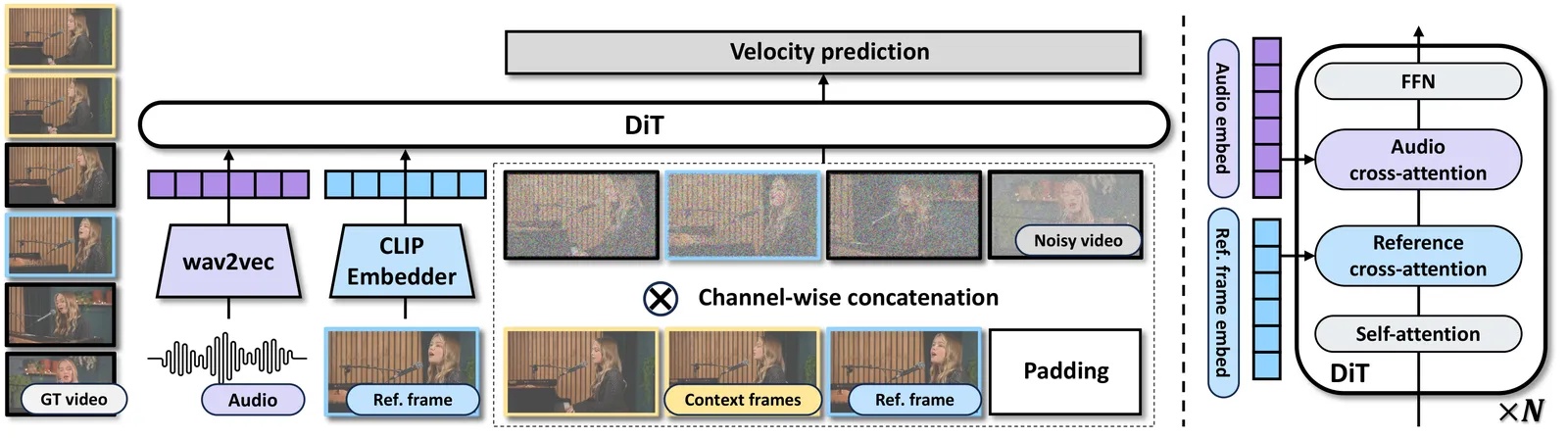
参考帧除了走 VAE 进 latent,还会经 CLIP 视觉模型编码成 $z_{ref}$,通过 reference cross-attention 注入;音频经 wav2vec2 编码后通过 audio cross-attention 注入。如图 4 右侧,每个 DiT Block 的顺序是 Self-attention → Reference cross-attention → Audio cross-attention → FFN,两路 cross-attention 职责分明:一路管「你是谁」,一路管「你说什么」。
自回归续接:无限长的来源
论文 3.3 把无限长讲得比代码更本质:整段长视频通过自回归地生成小块得到。第一块用输入视频首帧当参考、无上下文帧;之后每一块,取上一块输出的最后 $4(t_c-1)+1$ 帧作为上下文帧,把动量传递下去。这正是上一篇源码里 cond_frame = videos[:, :, -cur_motion_frames_num:] 的论文表述——「上下文帧」和源码里的「motion frame」是同一个东西。
如果说 context frames 解决了「流畅」,那软条件就是解决「保真但不僵硬」的钥匙,对应论文 3.4。这一章是全文最有洞察力的部分。
论文想要的是自适应的控制强度:当参考帧和上下文帧很像时,控制应该弱(让模型自由发挥);当参考帧和上下文帧差异很大时,控制应该强(保证身份和背景一致)。怎么做到?答案出人意料地简单——调整训练时参考帧的采样位置。
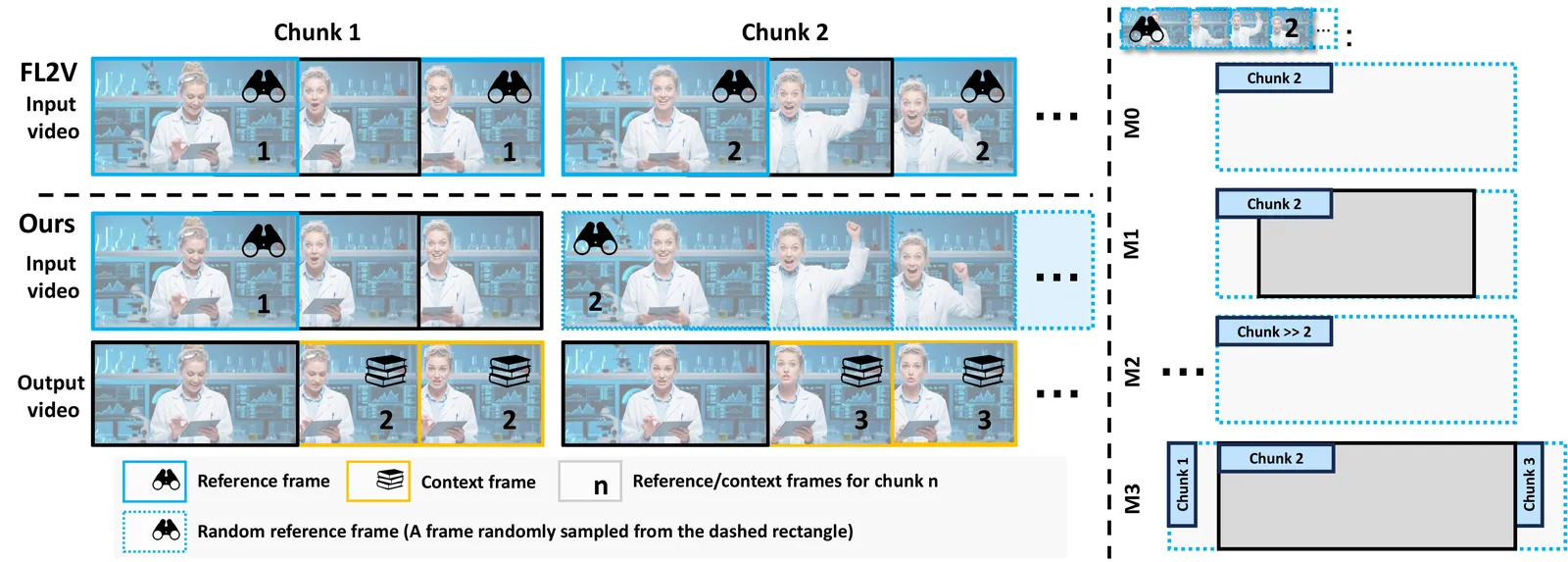
| 变体 | 采样策略 | 问题 / 效果 |
|---|---|---|
| M0 | 当前块内随机采样 | 控制过强,在任意时间戳乱复制参考动作(如在平静语句里突然拍额头) |
| M1 | 只取首帧或尾帧 | 等同 FL2V 的刚性,强制在块边界复制参考姿态,违背语音情绪 |
| M2 | 远块(间隔 >5 秒) | 控制够弱,但引入累积色彩/背景误差,保真不足 |
| M3 ✅ | 邻块(1 秒内) | 最优:既保身份/相机又不精确复制,且彻底消除累积误差 |
核心结论:chunk-level 距离是控制强度的主导因素
参考帧离当前块越近(M3),控制越「软」恰到好处——锚定视觉一致性的同时,解放表情/头部/身体随音频自由运动。距离太远(M2)保真崩坏,固定边界(M1)又扼杀动态。一个采样位置的选择,就调出了「软条件」。这是非常优雅的设计。
相机控制是个附加能力:InfiniteTalk 单独使用时无法精确复刻原视频的细微运镜,论文用两个即插即用插件补足——SDEdit #SDEdit(把源视频加进初始噪声、从 $t_0$ 开始去噪)和 Uni3C #Uni3C(ControlNet 式注入相机轨迹)。论文也诚实指出 Uni3C 会破坏背景,需要权衡。

实验设置(超参数全公开)
- 基座:MeiGen-MultiTalk(14B DiT);音频编码 wav2vec2;参考图编码 CLIP/H
- 训练数据:约 2000 小时包含说话人的视频;64 张 NVIDIA H100 80G 训练
- 分块:上下文帧 9 张图($t_c=3$ 个 context latent),chunk 长 81 帧,每次自回归产出 72 帧
- 评测:HDTF + CelebV-HQ(重脸部)+ EMTD(重全身);每集采 40 个、打乱音轨,共 120 视频;480×480 分辨率
- 指标:FID(单帧质量)、FVD(时序连贯)、Sync-C/Sync-D(唇同步)、CSIM(身份保持)+ 人工评测(17 人 340 份)
那个「FID 反而更差」的诚实发现
这是全文最值得玩味的地方。在和传统配音方法(MuseTalk/LatentSync)对比时,InfiniteTalk 的 FID/FVD 反而更差(HDTF 上 FID 26.11 vs 14~16)。论文没有藏着掖着,而是直接解释原因:
「LatentSync 和 MuseTalk 只编辑嘴部区域,视频其余部分原样保留,使它们的 FID/FVD 极佳……因此这些指标并不能反映真实的视觉质量差异。」
换句话说,一个极端的「作弊解」是把输入直接当输出——它会拿到完美的 FID/FVD/CSIM,但完全没有动起来。InfiniteTalk 因为真的在重新生成全身动作,单帧指标自然不占优。但在真正衡量「动得对不对」的 Sync-C 上,它全面领先(HDTF 9.35 vs 8.99/7.17)。这提醒我们:评估生成任务时,指标的语义比数值更重要。
| 对比(EMTD 数据集) | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ | CSIM↑ |
|---|---|---|---|---|---|
| OmniAvatar | 29.47 | 308.14 | 6.93 | 8.55 | 0.694 |
| MultiTalk(前作) | 33.80 | 315.33 | 8.13 | 7.50 | 0.702 |
| InfiniteTalk | 33.27 | 314.68 | 8.34 | 7.36 | 0.709 |
和音频驱动 I2V 模型对比(上表,Table 2),InfiniteTalk 在 Sync-C 领先的同时,FID/FVD/CSIM 都与最强对手相当或略优,没有为了同步牺牲画质。
消融实验:M3 赢在哪
| 变体 | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ |
|---|---|---|---|---|
| M0(块内随机) | 32.69 | 322.04 | 8.51 | 7.31 |
| M1(首尾帧) | 32.21 | 307.21 | 7.96 | 8.11 |
| M2(远块) | 42.17 | 376.53 | 8.23 | 7.44 |
| M3(邻块) | 32.55 | 312.17 | 8.60 | 7.16 |
消融(Table 3,EMTD)完美印证了 3.4 的理论:M3 的 Sync-C 最高(8.60)、Sync-D 最低(7.16);而 M2 远块采样的 FVD 暴涨到 376.53,验证了「距离太远导致累积误差」的判断。人工评测(Table 4)更直接——InfiniteTalk 的唇同步排名 1.11、身体同步 1.09(越低越好),把 MuseTalk(2.57)和 LatentSync(2.32/1.92)甩开一大截。

把论文的方法逐条映射回上一篇读过的源码,能看到一个少见的「论文与实现高度一致」的样本:
| 论文概念 | 对应代码(wan/multitalk.py) |
|---|---|
| 式 (3) 通道拼接 $z=\mathrm{concat}(z_1,z_2,m)$ | y = torch.concat([msk, y], dim=1) + mask 首帧=1 |
| 上下文帧 $x_{context}$(论文 3.3) | cond_frame = videos[:, :, -cur_motion_frames_num:](motion frame) |
| 自回归续接(取上块尾 $4(t_c-1)+1$ 帧) | audio_start_idx += (frame_num - cur_motion_frames_num) 滑窗 |
| flow matching 速度场更新(式 2/4) | latent = latent + noise_pred * dt |
| reference / audio cross-attention(Fig.4) | multitalk_model.py DiT Block 两路 cross-attn |
有一点论文讲得比代码清楚:论文揭示了「上下文帧」就是为了传递动量信息这一动机,而代码里它只是名为 motion_frame 的几个张量索引操作——读了论文,才知道那几行索引为什么存在。反过来,代码也补充了论文没细说的工程细节:色彩校正(缓解长视频色偏)、双路 CFG、APG #APG 抗过饱和。论文与代码互为表里。
局限
- 缺乏全身动作-音频对齐的自动指标:论文坦言现有 beat consistency、Sync-C 都无法准确衡量大幅头动下的同步,只能靠人工评测——这是整个领域的开放问题。
- 相机控制不内生:精细运镜要靠 SDEdit/Uni3C 外挂,且 Uni3C 会损背景。
- 重算力:14B 基座、2000 小时数据、64 张 H100——复现门槛极高。
可迁移的启发
三条可以拿走用的经验
1. 用「采样位置」当控制旋钮:M0-M3 的故事说明,有时候不需要改架构或加 loss,仅仅改变训练数据的采样策略(参考帧离得多近),就能调出想要的「软硬」控制强度。这个思路可迁移到任何「条件生成」任务。
2. 先诊断 baseline 失败模式,再设计:论文用 I2V/FL2V 的对照把「累积误差 vs 突兀过渡」这个权衡讲透,方法就成了水到渠成的解药。这是写好一篇方法论文的范式。
3. 警惕「指标作弊解」:FID 越低不一定越好——把输入当输出就能刷爆 FID。评估生成任务时,永远先问「这个指标的极端最优解是什么样」。
回到数字人系列:这两篇 InfiniteTalk(源码 + 论文)让我们完整看清了「重型扩散路线」的全貌——从一行 latent 索引到一个 flow matching 公式,从一张失败案例图到一次采样策略消融。它和系列前面的轻量路线(Ultralight)一起,构成了理解音频驱动数字人的两块基石。
参考来源
- Yang, S., Kong, Z., Gao, F., et al. InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing. arXiv:2508.14033
- MeiGen-AI. InfiniteTalk(官方实现). github.com/MeiGen-AI/InfiniteTalk
- Kong, Z., et al. Let Them Talk: Audio-driven Multi-person Conversational Video Generation (MultiTalk). arXiv:2505.22647
- Team Wan / Alibaba. Wan: Open and Advanced Large-Scale Video Generative Models. arXiv:2503.20314
- Liu, X., Gong, C., Liu, Q. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. arXiv:2209.03003
- Baevski, A., et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv:2006.11477
- Meng, C., et al. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. arXiv:2108.01073
- Cao, C., et al. Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation. arXiv:2504.14899
- Sadat, S., et al. Eliminating Oversaturation and Artifacts of High Guidance Scales (APG). arXiv:2410.02416