整帧与全身生成路线
上一篇讲的是基于扩散基模的数字人路线:视频大模型通过音频、参考帧和流式状态被约束成会说话的人。本文进入系列的第六章:整帧与全身生成。这里模型不再只负责嘴部,而要同时处理身份、脸、头动、衣服、身体、手势、背景和长时序一致性。
阅读目标
- 前情回顾:运动空间与扩散基模分别扩大了运动自然度和生成自由度。
- 本篇问题:整帧/全身生成如何扩大自由度,又为什么更难。
- 下一篇衔接:整帧质量还不够,实时交互需要流式系统和蒸馏。
换嘴方案的自由度小:原视频提供大部分视觉信息,模型只修改局部区域。整帧/全身方案的自由度大:模型要生成完整画面,甚至要根据音频生成头动、身体姿态和手势。自由度越大,表现力越强,但失败空间也越大。OmniAvatar 将任务定位为 audio-driven full-body video generation;LongCat-Video-Avatar 则将自己描述为 unified DiT-based framework,用于生成长时长、高真实感的 audio-driven human videos。#Gan-et-al.-2025 #LongCat-Video-Avatar-Page
| 维度 | 局部换嘴 | 整帧/全身生成 |
|---|---|---|
| 生成范围 | 嘴部和局部脸 | 脸、身体、衣服、背景和动作 |
| 身份保持 | 天然较稳 | 需要跨帧强约束 |
| 动作能力 | 复用原视频动作 | 可生成头动、姿态和手势 |
| 成本 | 轻到中等 | 中重到系统级 |
| 失败模式 | 嘴部边界、牙齿、情绪不一致 | 身份漂移、手崩、背景闪烁、长时序漂移 |
OmniAvatar 面向 Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation。根据论文页面和仓库,它强调 full-body、lip-sync accuracy 和 natural movements,并使用 pixel-wise multi-hierarchical audio embedding 等策略,让音频在 latent 空间中影响不同层级的动作。#Gan-et-al.-2025 #OmniAvatar-GitHub
这类方法的难点是音频信号本身并不唯一决定身体动作。同一句话可以严肃地说、兴奋地说、边点头边说,也可以边摊手边说。全身 avatar 因此需要把音素、韵律、情绪、语义和身份风格分层建模。
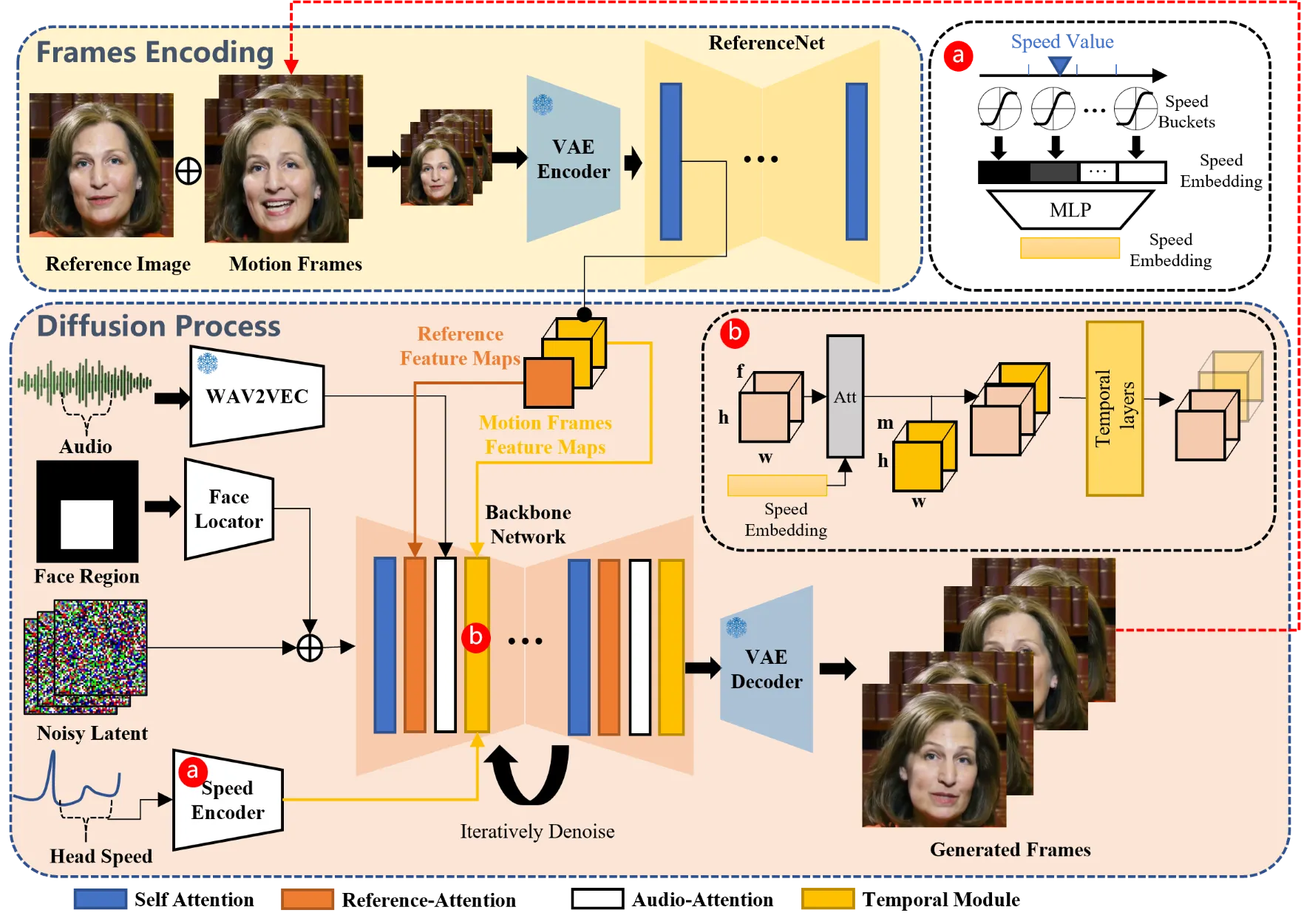
OmniAvatar 在工程上有两个值得注意的设计。其一,它没有沿用主流的 cross-attention 注入音频,而是用 pixel-wise multi-hierarchical audio embedding,把 wav2vec2 提取的音频特征直接注入 DiT 多个层级的 latent,从而同时驱动嘴型和更大范围的身体动作。其二,它基于 Wan2.1-T2V-14B 大基座,却用 LoRA(低秩适应)做音频适配训练,而非全量微调——消融实验显示 LoRA 方案在 FVD(664 对全量 715)和唇音同步 Sync-C(7.13 对 5.58)上反而优于全量训练,因为全量微调容易破坏基座原有的画质与文本控制能力。它在 HDTF 数据集上取得 SOTA(FID≈37.3、FVD≈382、Sync-C≈7.62)。但它也继承了 Wan 基座的弱点:手部生成质量不稳定,长视频存在颜色偏移和误差传播,且 25 步扩散无法直接实时,需要配合蒸馏加速。#Gan-et-al.-2025 #OmniAvatar-GitHub
flowchart TD A["音频"] --> B["音素 / 韵律 / 情绪特征"] R["参考身份"] --> C["身份与外观约束"] B --> D["嘴型与表情"] B --> E["头动与身体节奏"] C --> G["Avatar generator"] D --> G E --> G G --> O["全身数字人视频"]
LongCat-Video-Avatar 项目页称其为 unified DiT-based framework,目标是生成 super-realistic、long-duration audio-driven human videos。LongCat-Video-Avatar 1.5 Technical Report 进一步强调开源发布、商业级部署差距缩小,以及 lip motion、facial expression、head pose 和 body gesture 的综合质量。#LongCat-Video-Avatar-Page #LongCat-Video-Avatar-1.5
DiT 路线的优势在于统一建模能力:它能在更大空间范围和更长时间范围内处理人物、背景和动作。但它同时带来显著训练/推理成本,也更依赖大规模数据、显存、并行优化和严格的长时序评测。产品团队不能只看短 demo,还要测身份是否在 1 分钟后仍稳定、手势是否和语义一致、背景是否闪烁。
mindmap
root(("整帧/全身
失败空间"))
身份
"1 分钟后身份漂移"
"脸部细节变化"
动作
"手指变形"
"手势与语义不符"
场景
"背景闪烁/漂移"
"衣服纹理抖动"
长时序
"累积误差"
"时序一致性下降"
图 1:整帧/全身路线的失败空间。生成范围越大,身份、动作、场景和长时序约束越需要同时评测。
这也是整帧路线和局部路线的产品分界线。局部换嘴失败时,通常是嘴部区域不自然;整帧生成失败时,可能是人物身份变了、手指变形、衣服纹理闪烁、背景突然漂移,或者动作与语义完全不搭。它的收益是表现力,成本是 QA 难度和失败兜底难度。因此,整帧 avatar 更适合离线内容生产、广告素材、虚拟主播片段和可重试场景;如果是实时客服,除非有很强的系统优化和降级策略,否则不应把它作为第一落地方案。
DiT vs UNet vs GAN:全身生成的架构取舍
整帧/全身数字人的底座架构选择直接决定了训练成本、推理速度和长时序稳定性。当前主流有三条路线:
| 架构 | 代表工作 | 训练成本 | 推理速度 | 长时序稳定性 | 适用场景 |
|---|---|---|---|---|---|
| GAN | 早期 talking head | 低(单卡数天) | 快(实时) | 差(模式崩塌、身份漂移) | 轻量实时、低质量容忍 |
| UNet + Diffusion | SadTalker、部分换嘴 | 中(多卡数周) | 慢(多步去噪) | 中(依赖条件控制) | 离线高质量、可控生成 |
| DiT | LongCat、OmniAvatar、LTX | 高(多卡数月) | 慢(但可蒸馏加速) | 好(全局注意力建模) | 长视频、全身、统一音视频 |
GAN 的优势是推理极快,适合实时场景,但训练不稳定、长时序容易崩塌,且难以扩展到全身高分辨率。UNet + Diffusion 在画质和可控性上取得平衡,但多步去噪导致推理延迟高,不适合直接用于实时交互。DiT 是当前全身生成的主流方向,它通过 Transformer 的全局注意力机制更好地建模长距离依赖(如手势与语义的一致性、背景与人物的协调),但训练成本显著更高,且原始推理速度同样受限于多步采样。
对产品团队而言,架构选择不是纯技术问题,而是成本-质量-延迟三角权衡。如果业务只需要"有人说话"的效果,GAN 或轻量 UNet 足够;如果需要全身动作、长视频一致性和商业级画质,DiT 是更合理的选择,但必须配套蒸馏、量化和流式系统设计。没有一种架构能同时满足所有约束。
quadrantChart title 全身生成底座架构的成本-稳定性定位 x-axis "训练/推理成本低" --> "训练/推理成本高" y-axis "长时序稳定性差" --> "长时序稳定性好" quadrant-1 "高成本高稳定" quadrant-2 "低成本高稳定" quadrant-3 "低成本低稳定" quadrant-4 "高成本低稳定" "GAN": [0.2, 0.2] "UNet + Diffusion": [0.5, 0.55] "DiT": [0.85, 0.85]
图 2:三类底座架构的取舍定位。GAN 成本最低但长时序最弱,DiT 稳定性最好但成本最高,产品需在成本-质量-延迟三角中权衡。
全身生成的核心失败模式与评测方法
整帧/全身生成的失败模式比局部换嘴更隐蔽,也更难自动化检测。以下是产品 QA 中最常遇到的五类问题:
- 手部畸变:手指数量错误、关节弯曲不自然、握持物体穿模。这是扩散模型的通病,因为手部在训练数据中姿态多样且标注稀疏。
- 背景闪烁:人物运动时背景纹理抖动或突变。通常是因为模型没有显式的背景-前景分离机制,导致两者耦合生成。
- 身份漂移:长视频中人脸特征逐渐变化,30 秒后已不像原参考图。这是自回归生成的误差累积问题,Self-Forcing 等技术正在缓解但未根治。
- 手势与语义不一致:说"欢迎"时双手交叉、说"拒绝"时点头微笑。音频-动作对齐需要语义理解,仅靠音素驱动无法解决。
- 唇音同步衰减:前 10 秒口型准确,之后逐渐偏移。长时序评测必须覆盖 1 分钟以上片段,短 demo 无法暴露此问题。
对应的评测方法也应分层:短时序(<10s)用 LSE-D/LSE-C 测唇音同步、FID/FVD 测画质;中时序(10-60s)加入身份相似度(ArcFace cosine)、动作连贯性(光流一致性);长时序(>1min)必须引入主观 MOS 评分和人工质检,因为自动指标对缓慢漂移不敏感。产品验收标准应明确写出"1 分钟视频身份相似度 ≥ 0.85、唇音同步 LSE-D ≤ 8.0、无可见手部畸变"等具体阈值,而非模糊的"效果良好"。
AnimateAnyone 的输入是 reference image 与 pose sequence,目标是 consistent and controllable image-to-video synthesis for character animation。它不是音频驱动 talking head,但它展示了 reference identity 与 pose control 在全身动画中的价值。#Hu-et-al.-2023


LTX-Video / LTX-2.3 更接近通用视频生成底座。官方资料称 LTX-Video 是 DiT-based video generation model,LTX-2.3 模型卡强调 synchronized video and audio within a single model。它对数字人的意义在于提供未来统一音视频底座的可能性,但当前仍需要专门的口型、身份、身体和流式控制模块。#LTX-Video-GitHub #LTX-2.3-HuggingFace
这里容易出现一个判断误区:看到通用视频模型能生成“有人说话”的片段,就把它等同于数字人系统。真实产品并不是这样。数字人需要固定身份、可控台词、可控情绪、可控时长、可重复生成,还要能处理用户输入、品牌形象和合规审核。通用视频模型更像强大的底座材料,而 avatar 模型还需要把身份保持、口型同步、姿态控制和长时序一致性做成可调用接口。
因此,整帧路线的合理使用方式通常不是“直接替代所有轻量方案”,而是成为高表现力生产层。可以先用它生成虚拟主播片段、广告素材、课程开场和高质量示范,再用轻量 talking head 或局部换嘴承担实时互动部分。这样既利用整帧模型的表现力,又避免把实时链路压在最重的生成模型上。
决策清单
- 广告、短视频、离线内容生产:整帧/全身路线值得试。
- 实时客服:不应直接押注重型整帧生成。
- 固定虚拟主播:可以用全身模型生产素材,再用轻量实时模块在线驱动。
- 长期自研:关注 LongCat、OmniAvatar 和通用音视频 DiT 的融合趋势。
下一篇会讨论为什么“生成质量高”还不等于“能实时交互”:流式状态、无限长度、少步蒸馏和训练-推理鸿沟才是实时数字人的下一道门槛。
参考来源
- Gan, Q. et al. (2025). OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation. arXiv:2506.18866
- Omni-Avatar. OmniAvatar official repository. GitHub repository
- MeiGen-AI. LongCat-Video-Avatar project page. Project page
- LongCat authors. LongCat-Video-Avatar 1.5 Technical Report. arXiv:2605.26486
- Hu, L. et al. (2023). Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation. arXiv:2311.17117
- Tian, L. et al. (2024). EMO: Emote Portrait Alive — Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions. arXiv:2402.17485
- Lightricks. LTX-Video official repository. GitHub repository
- Lightricks. LTX-2.3 model card. Hugging Face